找到 253 个相关的AI工具
DeerFlow 是一个深度研究框架,旨在结合语言模型与如网页搜索、爬虫及 Python 执行等专用工具,以推动深入研究工作。该项目源于开源社区,强调贡献回馈,具备多种灵活的功能,适合各类研究需求。
Search-R1 是一个强化学习框架,旨在训练能够进行推理和调用搜索引擎的语言模型(LLMs)。它基于 veRL 构建,支持多种强化学习方法和不同的 LLM 架构,使得在工具增强的推理研究和开发中具备高效性和可扩展性。
Llama-3.1-Nemotron-Ultra-253B-v1 是一个基于 Llama-3.1-405B-Instruct 的大型语言模型,经过多阶段的后训练以提升推理和聊天能力。该模型支持高达 128K 的上下文长度,具备较好的准确性和效率平衡,适用于商业用途,旨在为开发者提供强大的 AI 助手功能。
Fin-R1 是一个专为金融领域设计的大型语言模型,旨在提升金融推理能力。由上海财经大学和财跃星辰联合研发,基于 Qwen2.5-7B-Instruct 进行微调和强化学习,具有高效的金融推理能力,适用于银行、证券等核心金融场景。该模型免费开源,便于用户使用和改进。
Jamba 1.6 是 AI21 推出的最新语言模型,专为企业私有部署而设计。它在长文本处理方面表现出色,能够处理长达 256K 的上下文窗口,采用混合 SSM-Transformer 架构,可高效准确地处理长文本问答任务。该模型在质量上超越了 Mistral、Meta 和 Cohere 等同类模型,同时支持灵活的部署方式,包括在本地或 VPC 中私有部署,确保数据安全。它为企业提供了一种无需在数据安全和模型质量之间妥协的解决方案,适用于需要处理大量数据和长文本的场景,如研发、法律和金融分析等。目前,Jamba 1.6 已在多个企业中得到应用,如 Fnac 使用其进行数据分类,Educa Edtech 利用其构建个性化聊天机器人等。
Inception Labs 是一家专注于开发扩散式大语言模型(dLLMs)的公司。其技术灵感来源于先进的图像和视频生成系统,如 Midjourney 和 Sora。通过扩散模型,Inception Labs 提供了比传统自回归模型快 5-10 倍的速度、更高的效率和更强的生成控制能力。其模型支持并行文本生成,能够纠正错误和幻觉,适合多模态任务,并且在推理和结构化数据生成方面表现出色。公司由斯坦福、UCLA 和康奈尔大学的研究人员和工程师组成,是扩散模型领域的先驱。
OpenManus 是一个开源的智能代理项目,旨在通过开源的方式实现类似于 Manus 的功能,但无需邀请码即可使用。该项目由多个开发者共同开发,基于强大的语言模型和灵活的插件系统,能够快速实现各种复杂的任务。OpenManus 的主要优点是开源、免费且易于扩展,适合开发者和研究人员进行二次开发和研究。项目背景源于对现有智能代理工具的改进需求,目标是打造一个完全开放且易于使用的智能代理平台。
Instella 是由 AMD GenAI 团队开发的一系列高性能开源语言模型,基于 AMD Instinct™ MI300X GPU 训练而成。该模型在性能上显著优于同尺寸的其他开源语言模型,并且在功能上与 Llama-3.2-3B 和 Qwen2.5-3B 等模型相媲美。Instella 提供模型权重、训练代码和训练数据,旨在推动开源语言模型的发展。其主要优点包括高性能、开源开放以及对 AMD 硬件的优化支持。
GPT-4.5是OpenAI发布的最新语言模型,代表了当前无监督学习技术的前沿水平。该模型通过大规模计算和数据训练,提升了对世界知识的理解和模式识别能力,减少了幻觉现象,能够更自然地与人类进行交互。它在写作、编程、解决问题等任务上表现出色,尤其适合需要高创造力和情感理解的场景。GPT-4.5目前处于研究预览阶段,面向Pro用户和开发者开放,旨在探索其潜在能力。
Gemini 2.0 Flash-Lite 是 Google 推出的高效语言模型,专为长文本处理和复杂任务优化。它在推理、多模态、数学和事实性基准测试中表现出色,具备简化的价格策略,使得百万级上下文窗口更加经济实惠。Gemini 2.0 Flash-Lite 已在 Google AI Studio 和 Vertex AI 中全面开放,适合企业级生产使用。
Phi-4-mini-instruct 是微软推出的一款轻量级开源语言模型,属于 Phi-4 模型家族。它基于合成数据和经过筛选的公开网站数据进行训练,专注于高质量、推理密集型数据。该模型支持 128K 令牌上下文长度,并通过监督微调和直接偏好优化来增强指令遵循能力和安全性。Phi-4-mini-instruct 在多语言支持、推理能力(尤其是数学和逻辑推理)以及低延迟场景下表现出色,适用于资源受限的环境。该模型于 2025 年 2 月发布,支持多种语言,包括英语、中文、日语等。
DeepSeek 是由 High-Flyer 基金支持的中国 AI 实验室开发的先进语言模型,专注于开源模型和创新训练方法。其 R1 系列模型在逻辑推理和问题解决方面表现出色,采用强化学习和混合专家框架优化性能,以低成本实现高效训练。DeepSeek 的开源策略推动了社区创新,同时引发了关于 AI 竞争和开源模型影响力的行业讨论。其免费且无需注册的使用方式进一步降低了用户门槛,适合广泛的应用场景。
AlphaMaze 是一个专注于提升大型语言模型(LLM)视觉推理能力的项目。它通过文本形式描述的迷宫任务来训练模型,使其能够理解和规划空间结构。这种方法不仅避免了复杂的图像处理,还通过文本描述直接评估模型的空间理解能力。其主要优点是能够揭示模型如何思考空间问题,而不仅仅是能否解决问题。该模型基于开源框架,旨在推动语言模型在视觉推理领域的研究和发展。
AlphaMaze 是一款专为解决视觉推理任务而设计的解码器语言模型。它通过针对迷宫解谜任务的训练,展示了语言模型在视觉推理方面的潜力。该模型基于 15 亿参数的 Qwen 模型构建,并通过监督微调(SFT)和强化学习(RL)进行训练。其主要优点在于能够将视觉任务转化为文本格式进行推理,从而弥补传统语言模型在空间理解上的不足。该模型的开发背景是提升 AI 在视觉任务上的表现,尤其是在需要逐步推理的场景中。目前,AlphaMaze 作为研究项目,暂未明确其商业化定价和市场定位。
Smithery是一个基于Model Context Protocol的平台,允许用户通过连接各种服务器来扩展语言模型的功能。它为用户提供了一个灵活的工具集,能够根据需求动态增强语言模型的能力,从而更好地完成各种任务。该平台的核心优势在于其模块化和可扩展性,用户可以根据自己的需求选择合适的服务器进行集成。
Moonlight-16B-A3B 是由 Moonshot AI 开发的一种大规模语言模型,采用先进的 Muon 优化器进行训练。该模型通过优化训练效率和性能,显著提升了语言生成的能力。其主要优点包括高效的优化器设计、较少的训练 FLOPs 和卓越的性能表现。该模型适用于需要高效语言生成的场景,如自然语言处理、代码生成和多语言对话等。其开源的实现和预训练模型为研究人员和开发者提供了强大的工具。
DeepHermes 3 是 NousResearch 开发的先进语言模型,能够通过系统性推理提升回答准确性。它支持推理模式和常规响应模式,用户可以通过系统提示切换。该模型在多轮对话、角色扮演、推理等方面表现出色,旨在为用户提供更强大和灵活的语言生成能力。模型基于 Llama-3.1-8B 微调,参数量达 80.3 亿,支持多种应用场景,如推理、对话、函数调用等。
Lora 是一款为移动设备优化的本地语言模型,通过其 SDK 可以快速集成到移动应用中。它支持 iOS 和 Android 平台,性能与 GPT-4o-mini 相当,拥有 1.5GB 大小和 24 亿参数,专为实时移动推理进行了优化。Lora 的主要优点包括低能耗、轻量化和快速响应,相比其他模型,它在能耗、体积和速度上都有显著优势。Lora 由 PeekabooLabs 提供,主要面向开发者和企业客户,帮助他们快速将先进的语言模型能力集成到移动应用中,提升用户体验和应用竞争力。
PaliGemma 2 mix 是 Google 推出的升级版视觉语言模型,属于 Gemma 家族。它能够处理多种视觉和语言任务,如图像分割、视频字幕生成、科学问题回答等。该模型提供不同大小的预训练检查点(3B、10B 和 28B 参数),可轻松微调以适应各种视觉语言任务。其主要优点是多功能性、高性能和开发者友好性,支持多种框架(如 Hugging Face Transformers、Keras、PyTorch 等)。该模型适用于需要高效处理视觉和语言任务的开发者和研究人员,能够显著提升开发效率。
Mistral Saba 是 Mistral AI 推出的首个专门针对中东和南亚地区的定制化语言模型。该模型拥有 240 亿参数,通过精心策划的数据集进行训练,能够提供比同类大型模型更准确、更相关且更低成本的响应。它支持阿拉伯语和多种印度起源语言,尤其擅长南印度语言(如泰米尔语),适用于需要精准语言理解和文化背景支持的场景。Mistral Saba 可通过 API 使用,也可本地部署,具有轻量化、单 GPU 系统部署和快速响应的特点,适合企业级应用。
OLMoE 是由 Ai2 开发的开源语言模型应用,旨在为研究人员和开发者提供一个完全开放的工具包,用于在设备上进行人工智能实验。该应用支持在 iPhone 和 iPad 上离线运行,确保用户数据完全私密。它基于高效的 OLMoE 模型构建,通过优化和量化,使其在移动设备上运行时保持高性能。该应用的开源特性使其成为研究和开发新一代设备端人工智能应用的重要基础。
Podscript 是一个强大的音频转录工具,它利用语言模型和语音到文本(STT)API,为播客和其他音频内容生成高质量的转录文本。该工具支持多种流行的STT服务,如Deepgram、AssemblyAI和Groq,并且可以处理YouTube视频的自动生成字幕。Podscript的主要优点是其灵活性和易用性,用户可以通过简单的命令行界面或方便的Web界面来操作。它适用于播客创作者、内容制作者以及需要快速转录音频的用户。Podscript是开源的,用户可以根据自己的需求进行定制和扩展。
Xwen-Chat由xwen-team开发,为满足高质量中文对话模型需求而生,填补领域空白。其有多个版本,具备强大语言理解与生成能力,可处理复杂语言任务,生成自然对话内容,适用于智能客服等场景,在Hugging Face平台免费提供。
LLM Codenames 是一个基于语言模型的创意命名工具。它利用先进的自然语言处理技术,能够根据用户输入的关键词或主题,快速生成一系列独特且富有创意的名称。这种工具对于需要进行品牌命名、产品命名或创意写作的用户来说非常实用。它可以帮助用户节省大量时间和精力,避免命名过程中的重复劳动。LLM Codenames 的主要优点是其高效性和创意性,能够提供多样化的命名选择,满足不同用户的需求。该工具目前以网站形式提供服务,用户可以通过浏览器直接访问使用,无需安装任何软件。
Deeptrain 是一个专注于视频处理的平台,旨在将视频内容无缝集成到语言模型和AI代理中。通过其强大的视频处理技术,用户可以像使用文本和图像一样轻松地利用视频内容。该产品支持超过200种语言模型,包括GPT-4o、Gemini等,并且支持多语言视频处理。Deeptrain 提供免费的开发支持,仅在生产环境中使用时才收费,这使得它成为开发AI应用的理想选择。其主要优点包括强大的视频处理能力、多语言支持以及与主流语言模型的无缝集成。
Exa & Deepseek Chat App是一个开源的聊天应用,旨在通过Exa的API进行实时网络搜索,并结合Deepseek R1语言模型进行推理,以提供更准确的聊天体验。该应用基于Next.js、TailwindCSS和TypeScript构建,使用Vercel进行托管。它允许用户在聊天中获取最新的网络信息,并通过强大的语言模型进行智能对话。该应用免费开源,适合开发者和企业用户使用,可作为聊天工具的开发基础。
DeepSeek-R1-Distill-Llama-8B 是 DeepSeek 团队开发的高性能语言模型,基于 Llama 架构并经过强化学习和蒸馏优化。该模型在推理、代码生成和多语言任务中表现出色,是开源社区中首个通过纯强化学习提升推理能力的模型。它支持商业使用,允许修改和衍生作品,适合学术研究和企业应用。
该产品是一个基于Qwen2.5-32B的4位量化语言模型,通过GPTQ技术实现高效推理和低资源消耗。它在保持较高性能的同时,显著降低了模型的存储和计算需求,适合在资源受限的环境中使用。该模型主要面向需要高性能语言生成的应用场景,如智能客服、编程辅助、内容创作等。其开源许可和灵活的部署方式使其在商业和研究领域具有广泛的应用前景。
ReaderLM v2是由Jina AI推出的参数量为1.5B的小型语言模型,专门用于HTML转Markdown转换和HTML转JSON提取,具有卓越的准确性。该模型支持29种语言,能处理高达512K个token的输入和输出组合长度。它采用了新的训练范式和更高质量的训练数据,较前代产品在处理长文本内容和生成Markdown语法方面有重大进步,能熟练运用Markdown语法,擅长生成复杂元素。此外,ReaderLM v2还引入了直接HTML转JSON生成功能,允许用户根据给定的JSON架构从原始HTML中提取特定信息,消除了中间Markdown转换需求。
MiniMax-Text-01是一个由MiniMaxAI开发的大型语言模型,拥有4560亿总参数,其中每个token激活459亿参数。它采用了混合架构,结合了闪电注意力、softmax注意力和专家混合(MoE)技术,通过先进的并行策略和创新的计算-通信重叠方法,如线性注意力序列并行主义加(LASP+)、变长环形注意力、专家张量并行(ETP)等,将训练上下文长度扩展到100万token,并能在推理时处理长达400万token的上下文。在多个学术基准测试中,MiniMax-Text-01展现出了顶级模型的性能。
MiniMax-01是一个具有4560亿总参数的强大语言模型,其中每个token激活459亿参数。它采用混合架构,结合了闪电注意力、softmax注意力和专家混合(MoE),通过先进的并行策略和创新的计算-通信重叠方法,如线性注意力序列并行主义加(LASP+)、varlen环形注意力、专家张量并行(ETP)等,将训练上下文长度扩展到100万tokens,在推理时可处理长达400万tokens的上下文。在多个学术基准测试中,MiniMax-01展现了顶级模型的性能。
fullmoon是一款由Mainframe开发的本地智能应用,允许用户在本地设备上与大型语言模型进行聊天。它支持完全离线操作,优化了Apple硅芯片的模型运行,提供了个性化的主题、字体和系统提示调整功能。作为一款免费、开源且注重隐私的应用,它为用户提供了一种简单、安全的方式来利用强大的语言模型进行交流和创作。
MiniCPM-o 2.6是MiniCPM-o系列中最新且功能最强大的模型。该模型基于SigLip-400M、Whisper-medium-300M、ChatTTS-200M和Qwen2.5-7B构建,拥有8B参数。它在视觉理解、语音交互和多模态直播方面表现出色,支持实时语音对话和多模态直播功能。该模型在开源社区中表现优异,超越了多个知名模型。其优势在于高效的推理速度、低延迟、低内存和功耗,能够在iPad等终端设备上高效支持多模态直播。此外,MiniCPM-o 2.6易于使用,支持多种使用方式,包括llama.cpp的CPU推理、int4和GGUF格式的量化模型、vLLM的高吞吐量推理等。
rStar-Math是一项研究,旨在证明小型语言模型(SLMs)能够在不依赖于更高级模型的情况下,与OpenAI的o1模型相媲美甚至超越其数学推理能力。该研究通过蒙特卡洛树搜索(MCTS)实现“深度思考”,其中数学策略SLM在基于SLM的流程奖励模型的指导下进行测试时搜索。rStar-Math引入了三种创新方法来应对训练两个SLM的挑战,通过4轮自我演化和数百万个合成解决方案,将SLMs的数学推理能力提升到最先进水平。该模型在MATH基准测试中显著提高了性能,并在AIME竞赛中表现优异。
PatronusAI/Llama-3-Patronus-Lynx-70B-Instruct是一个基于Llama-3架构的大型语言模型,旨在检测在RAG设置中的幻觉问题。该模型通过分析给定的文档、问题和答案,评估答案是否忠实于文档内容。其主要优点在于高精度的幻觉检测能力和强大的语言理解能力。该模型由Patronus AI开发,适用于需要高精度信息验证的场景,如金融分析、医学研究等。该模型目前为免费使用,但具体的商业应用可能需要与开发者联系。
CAG(Cache-Augmented Generation)是一种创新的语言模型增强技术,旨在解决传统RAG(Retrieval-Augmented Generation)方法中存在的检索延迟、检索错误和系统复杂性等问题。通过在模型上下文中预加载所有相关资源并缓存其运行时参数,CAG能够在推理过程中直接生成响应,无需进行实时检索。这种方法不仅显著降低了延迟,提高了可靠性,还简化了系统设计,使其成为一种实用且可扩展的替代方案。随着大型语言模型(LLMs)上下文窗口的不断扩展,CAG有望在更复杂的应用场景中发挥作用。
PRIME-RL/Eurus-2-7B-PRIME是一个基于PRIME方法训练的7B参数的语言模型,旨在通过在线强化学习提升语言模型的推理能力。该模型从Eurus-2-7B-SFT开始训练,利用Eurus-2-RL-Data数据集进行强化学习。PRIME方法通过隐式奖励机制,使模型在生成过程中更加注重推理过程,而不仅仅是结果。该模型在多项推理基准测试中表现出色,相较于其SFT版本平均提升了16.7%。其主要优点包括高效的推理能力提升、较低的数据和模型资源需求,以及在数学和编程任务中的优异表现。该模型适用于需要复杂推理能力的场景,如编程问题解答和数学问题求解。
Eurus-2-7B-SFT是基于Qwen2.5-Math-7B模型进行微调的大型语言模型,专注于数学推理和问题解决能力的提升。该模型通过模仿学习(监督微调)的方式,学习推理模式,能够有效解决复杂的数学问题和编程任务。其主要优点在于强大的推理能力和对数学问题的准确处理,适用于需要复杂逻辑推理的场景。该模型由PRIME-RL团队开发,旨在通过隐式奖励的方式提升模型的推理能力。
Memory Layers at Scale 是一种创新的内存层实现方式,通过可训练的键值查找机制,在不增加浮点运算次数的情况下为模型增加额外的参数。这种方法在大规模语言模型中尤为重要,因为它能够在保持计算效率的同时,显著提升模型的存储和检索能力。该技术的主要优点包括高效扩展模型容量、降低计算资源消耗以及提高模型的灵活性和可扩展性。该项目由 Meta Lingua 团队开发,适用于需要处理大规模数据和复杂模型的场景。
Sonus AI是一个以Sonus-1模型为核心的大型语言模型,它重新定义了语言理解和计算的边界。Sonus-1以其卓越的复杂问题解决能力而著称,远超过典型的语言模型。Sonus AI提供了增强的搜索和实时信息检索功能,确保用户能够访问到最新和最精确的信息。此外,Sonus AI还计划推出开发者友好的API,以便将Sonus-1的强大能力集成到各种应用中。Sonus AI的产品背景信息显示,它是一个面向未来的技术,旨在通过先进的AI能力提升用户的工作效率和信息获取的准确性。
HuatuoGPT-o1-70B是由FreedomIntelligence开发的医疗领域大型语言模型(LLM),专为复杂的医疗推理设计。该模型在提供最终响应之前,会生成一个复杂的思考过程,反映并完善其推理。HuatuoGPT-o1-70B能够处理复杂的医疗问题,提供深思熟虑的答案,这对于提高医疗决策的质量和效率至关重要。该模型基于LLaMA-3.1-70B架构,支持英文,并且可以部署在多种工具上,如vllm或Sglang,或者直接进行推理。
HuatuoGPT-o1-7B是由FreedomIntelligence开发的医疗领域大型语言模型(LLM),专为高级医疗推理设计。该模型在提供最终回答之前,会生成复杂的思考过程,反映并完善其推理。HuatuoGPT-o1-7B支持中英文,能够处理复杂的医疗问题,并以'思考-回答'的格式输出结果,这对于提高医疗决策的透明度和可靠性至关重要。该模型基于Qwen2.5-7B,经过特殊训练以适应医疗领域的需求。
YuLan-Mini是由中国人民大学AI Box团队开发的一款轻量级语言模型,具有2.4亿参数,尽管仅使用1.08T的预训练数据,但其性能可与使用更多数据训练的行业领先模型相媲美。该模型特别擅长数学和代码领域,为了促进可复现性,团队将开源相关的预训练资源。
这是一个由斯坦福大学研究团队开发的多模态语言模型框架,旨在统一3D人体动作中的言语和非言语语言。该模型能够理解并生成包含文本、语音和动作的多模态数据,对于创建能够自然交流的虚拟角色至关重要,广泛应用于游戏、电影和虚拟现实等领域。该模型的主要优点包括灵活性高、训练数据需求少,并且能够解锁如可编辑手势生成和从动作中预测情感等新任务。
LiveKit Plugins Turn Detector是一个用于LiveKit Agents的插件,它通过使用定制的开放权重模型来确定用户何时完成发言,从而引入了端对端的发言结束检测。相较于传统的声学活动检测(VAD)模型,该插件利用专门为此任务训练的语言模型,提供了一种更准确、更稳健的发言结束检测方法。目前版本仅支持英文,不建议用于其他语言。
FACTS Grounding是Google DeepMind推出的一个全面基准测试,旨在评估大型语言模型(LLMs)生成的回应是否不仅在给定输入方面事实准确,而且足够详细,能够为用户提供满意的答案。这一基准测试对于提高LLMs在现实世界中应用的信任度和准确性至关重要,有助于推动整个行业在事实性和基础性方面的进步。
Clio是Anthropic公司开发的一种自动化分析工具,旨在隐私保护的前提下分析真实世界中的语言模型使用情况。它通过将对话抽象化成主题聚类,帮助我们了解用户如何在日常中使用Claude AI模型,类似于Google Trends工具。Clio的主要优点在于它能够在不侵犯用户隐私的情况下提供对AI模型使用情况的洞察,这对于提高AI模型的安全性至关重要。Anthropic公司非常重视用户数据的保护,Clio的设计体现了这一点,通过多层隐私保护措施确保用户隐私。
Phi-4是微软Phi系列小型语言模型的最新成员,拥有14B参数,擅长数学等复杂推理领域。Phi-4通过使用高质量的合成数据集、精选有机数据和后训练创新,在大小与质量之间取得了平衡。Phi-4体现了微软在小型语言模型(SLM)领域的技术进步,推动了AI技术的边界。Phi-4目前已在Azure AI Foundry上提供,并将在未来几周登陆Hugging Face平台。
P-MMEval是一个多语言基准测试,覆盖了基础和能力专业化的数据集。它扩展了现有的基准测试,确保所有数据集在语言覆盖上保持一致,并在多种语言之间提供平行样本,支持多达10种语言,涵盖8个语言家族。P-MMEval有助于全面评估多语言能力,并进行跨语言可转移性的比较分析。
DeepSeek-V2.5-1210是DeepSeek-V2.5的升级版本,它在多个能力方面进行了改进,包括数学、编码和写作推理。模型在MATH-500基准测试中的性能从74.8%提高到82.8%,在LiveCodebench (08.01 - 12.01)基准测试中的准确率从29.2%提高到34.38%。此外,新版本优化了文件上传和网页摘要功能的用户体验。DeepSeek-V2系列(包括基础和聊天)支持商业用途。
Proofreading AI是一个在线AI校对工具,它利用先进的语言模型GPT-4/4o来校对文档,提供精确的结果。这个工具不仅可以纠正语法错误、拼写错误,还能检测抄袭、去除抄袭内容、检测AI生成文本、人性化AI文本、生成引用和改写文本。Proofreading AI的主要优点包括无缝上传文档、即时下载校正后的文档、以及提供多种写作辅助工具。它的背景信息显示,Proofreading AI提供了比传统校对工具更多的功能,并且价格相对实惠。
INTELLECT-1 Chat是一个由全球合作训练的10B参数语言模型驱动的聊天工具。它代表了人工智能领域中大规模语言模型的最新进展,通过分散式训练,提高了模型的多样性和适应性。这种技术的主要优点包括能够理解和生成自然语言,提供流畅的对话体验,并且能够处理大量的语言数据。产品背景信息显示,这是一个首次展示分散式训练可能性的演示,易于使用且富有趣味性。价格方面,页面提供了登录以保存和重访聊天的功能,暗示了可能的付费或会员服务模式。
OLMo-2-1124-13B-DPO是经过监督微调和DPO训练的13B参数大型语言模型,主要针对英文,旨在提供在聊天、数学、GSM8K和IFEval等多种任务上的卓越性能。该模型是OLMo系列的一部分,旨在推动语言模型的科学研究。模型训练基于Dolma数据集,并公开代码、检查点、日志和训练细节。
OpenScholar是一个检索增强型语言模型(LM),旨在通过首先搜索文献中的相关论文,然后基于这些来源生成回答,来帮助科学家有效地导航和综合科学文献。该模型对于处理每年发表的数百万篇科学论文,以及帮助科学家找到他们需要的信息或跟上单一子领域最新发现具有重要意义。
OLMo 2 13B是由Allen Institute for AI (Ai2)开发的一款基于Transformer的自回归语言模型,专注于英文学术基准测试。该模型在训练过程中使用了高达5万亿个token,展现出与同等规模的全开放模型相媲美或更优的性能,并在英语学术基准上与Meta和Mistral的开放权重模型竞争。OLMo 2 13B的发布包括所有代码、检查点、日志和相关的训练细节,旨在推动语言模型的科学研究。
OLMo 2是由Ai2推出的最新全开放语言模型,包括7B和13B两种规模的模型,训练数据高达5T tokens。这些模型在性能上与同等规模的全开放模型相当或更优,并且在英语学术基准测试中与开放权重模型如Llama 3.1竞争。OLMo 2的开发注重模型训练的稳定性、阶段性训练干预、最先进的后训练方法和可操作的评估框架。这些技术的应用使得OLMo 2在多个任务上表现出色,特别是在知识回忆、常识、一般和数学推理方面。
Tülu 3是一系列开源的先进语言模型,它们经过后训练以适应更多的任务和用户。这些模型通过结合专有方法的部分细节、新颖技术和已建立的学术研究,实现了复杂的训练过程。Tülu 3的成功根植于精心的数据管理、严格的实验、创新的方法论和改进的训练基础设施。通过公开分享数据、配方和发现,Tülu 3旨在赋予社区探索新的和创新的后训练方法的能力。
Lingma SWE-GPT是一个开源的大型语言模型,专注于软件工程领域的任务,旨在提供智能化的开发支持。该模型基于Qwen系列基础模型,经过额外训练以增强其在复杂软件工程任务中的能力。它在软件工程智能代理的权威排行榜上表现出色,适合需要自动化软件改进的开发团队和研究人员。
Nous Research专注于开发以人为中心的语言模型和模拟器,致力于将AI系统与现实世界用户体验对齐。我们的主要研究领域包括模型架构、数据合成、微调和推理。我们优先开发开源、人类兼容的模型,挑战传统的封闭模型方法。
browser-use是一个开源的网页自动化库,允许大型语言模型(LLM)与网站进行交互,通过简单的接口实现复杂的网页操作。该技术的主要优点包括对多种语言模型的通用支持、交互元素自动检测、多标签页管理、XPath提取、视觉模型支持等。它解决了传统网页自动化中的一些痛点,如动态内容处理、长任务解决等。browser-use以其灵活性和易用性,为开发者提供了一个强大的工具,以构建更加智能和自动化的网页交互体验。
OuteTTS-0.1-350M是一款基于纯语言模型的文本到语音合成技术,它不需要外部适配器或复杂架构,通过精心设计的提示和音频标记实现高质量的语音合成。该模型基于LLaMa架构,使用350M参数,展示了直接使用语言模型进行语音合成的潜力。它通过三个步骤处理音频:使用WavTokenizer进行音频标记化、CTC强制对齐创建精确的单词到音频标记映射、以及遵循特定格式的结构化提示创建。OuteTTS的主要优点包括纯语言建模方法、声音克隆能力、与llama.cpp和GGUF格式的兼容性。
Meta 开发的自回归语言模型,采用优化架构,适合资源受限设备。优点多,如集成多种技术,支持零样本推理等,价格免费,面向自然语言处理研究人员和开发者。
MobileLLM-600M是由Meta开发的自回归语言模型,采用了优化的Transformer架构,专为资源受限的设备端应用而设计。该模型集成了SwiGLU激活函数、深度薄架构、嵌入共享和分组查询注意力等关键技术。MobileLLM-600M在零样本常识推理任务上取得了显著的性能提升,与之前的125M/350M SoTA模型相比,分别提高了2.7%/4.3%的准确率。该模型的设计理念可扩展至更大模型,如MobileLLM-1B/1.5B,均取得了SoTA结果。
MobileLLM-350M是由Meta开发的自回归语言模型,采用优化的Transformer架构,专为设备端应用设计,以满足资源受限的环境。该模型整合了SwiGLU激活函数、深层薄架构、嵌入共享和分组查询注意力等关键技术,实现了在零样本常识推理任务上的显著准确率提升。MobileLLM-350M在保持较小模型尺寸的同时,提供了与更大模型相媲美的性能,是设备端自然语言处理应用的理想选择。
MobileLLM-125M是由Meta开发的自动回归语言模型,它利用优化的变换器架构,专为资源受限的设备端应用而设计。该模型集成了包括SwiGLU激活函数、深度薄架构、嵌入共享和分组查询注意力等多项关键技术。MobileLLM-125M/350M在零样本常识推理任务上相较于前代125M/350M SoTA模型分别取得了2.7%和4.3%的准确率提升。该模型的设计理念可有效扩展到更大模型,MobileLLM-600M/1B/1.5B均取得了SoTA结果。
MobileLLM是一种针对移动设备优化的小型语言模型,专注于设计少于十亿参数的高质量LLMs,以适应移动部署的实用性。与传统观念不同,该研究强调了模型架构在小型LLMs中的重要性。通过深度和薄型架构,结合嵌入共享和分组查询注意力机制,MobileLLM在准确性上取得了显著提升,并提出了一种不增加模型大小且延迟开销小的块级权重共享方法。此外,MobileLLM模型家族在聊天基准测试中显示出与之前小型模型相比的显著改进,并在API调用任务中接近LLaMA-v2 7B的正确性,突出了小型模型在普通设备用例中的能力。
SimpleQA是OpenAI发布的一个事实性基准测试,旨在衡量语言模型回答简短、寻求事实的问题的能力。它通过提供高正确性、多样性、挑战性和良好的研究者体验的数据集,帮助评估和提升语言模型的准确性和可靠性。这个基准测试对于训练能够产生事实正确响应的模型是一个重要的进步,有助于提高模型的可信度,并拓宽其应用范围。
AudioLM是由Google Research开发的一个框架,用于高质量音频生成,具有长期一致性。它将输入音频映射到离散标记序列,并将音频生成视为这一表示空间中的语言建模任务。AudioLM通过在大量原始音频波形上训练,学习生成自然且连贯的音频续篇,即使在没有文本或注释的情况下,也能生成语法和语义上合理的语音续篇,同时保持说话者的身份和韵律。此外,AudioLM还能生成连贯的钢琴音乐续篇,尽管它在训练时没有使用任何音乐的符号表示。
CoI-Agent是一个基于大型语言模型(LLM)的智能代理,旨在通过链式思维(Chain of Ideas)的方式革新研究领域的新想法开发。该模型通过整合和分析大量数据,为研究人员提供创新的思路和研究方向。它的重要性在于能够加速科研进程,提高研究效率,帮助研究人员在复杂的数据中发现新的模式和联系。CoI-Agent由DAMO-NLP-SG团队开发,是一个开源项目,可以免费使用。
Spirit LM是一个基础多模态语言模型,能够自由混合文本和语音。该模型基于一个7B预训练的文本语言模型,通过持续在文本和语音单元上训练来扩展到语音模式。语音和文本序列被串联为单个令牌流,并使用一个小的自动策划的语音-文本平行语料库,采用词级交错方法进行训练。Spirit LM有两个版本:基础版使用语音音素单元(HuBERT),而表达版除了音素单元外,还使用音高和风格单元来模拟表达性。对于两个版本,文本都使用子词BPE令牌进行编码。该模型不仅展现了文本模型的语义能力,还展现了语音模型的表达能力。此外,我们展示了Spirit LM能够在少量样本的情况下跨模态学习新任务(例如ASR、TTS、语音分类)。
Zamba2-7B是由Zyphra团队开发的一款小型语言模型,它在7B规模上超越了当前领先的模型,如Mistral、Google的Gemma和Meta的Llama3系列,无论是在质量还是性能上。该模型专为在设备上和消费级GPU上运行以及需要强大但紧凑高效模型的众多企业应用而设计。Zamba2-7B的发布,展示了即使在7B规模上,前沿技术仍然可以被小团队和适度预算所触及和超越。
LLMWare.ai是一个为金融、法律、合规和监管密集型行业设计的AI工具,专注于私有云中的小型专业化语言模型和专为SLMs设计的AI框架。它提供了一个集成的、高质量的、组织良好的框架,用于开发AI代理工作流、检索增强生成(RAG)和其他用例的LLM应用程序,包括许多核心对象,以便开发者可以立即开始。
o1 in Medicine是一个专注于医学领域的人工智能模型,旨在通过先进的语言模型技术,提升医学数据的处理能力和诊断准确性。该模型由UC Santa Cruz、University of Edinburgh和National Institutes of Health的研究人员共同开发,通过在多个医学数据集上的测试,展示了其在医学领域的应用潜力。o1模型的主要优点包括高准确率、多语言支持以及对复杂医学问题的深入理解能力。该模型的开发背景是基于当前医疗领域对于高效、准确的数据处理和分析的需求,尤其是在诊断和治疗建议方面。目前,该模型的研究和应用还处于初步阶段,但其在医学教育和临床实践中的应用前景广阔。
Platea AI是一个提供高质量提示信息的平台,用户可以快速地获取和比较不同语言模型提供商和模型的结果。它支持并行运行提示,并能快速比较结果,帮助用户选择最合适的模型。
Entropy-based sampling 是一种基于熵理论的采样技术,用于提升语言模型在生成文本时的多样性和准确性。该技术通过计算概率分布的熵和方差熵来评估模型的不确定性,从而在模型可能陷入局部最优或过度自信时调整采样策略。这种方法有助于避免模型输出的单调重复,同时在模型不确定性较高时增加输出的多样性。
WebLLM是一个高性能的浏览器内语言模型推理引擎,利用WebGPU进行硬件加速,使得强大的语言模型操作可以直接在网页浏览器内执行,无需服务器端处理。这个项目旨在将大型语言模型(LLM)直接集成到客户端,从而实现成本降低、个性化增强和隐私保护。它支持多种模型,并与OpenAI API兼容,易于集成到项目中,支持实时交互和流式处理,是构建个性化AI助手的理想选择。
AMD-Llama-135m是一个基于LLaMA2模型架构训练的语言模型,能够在AMD MI250 GPU上流畅加载使用。该模型支持生成文本和代码,适用于多种自然语言处理任务。
SFR-Judge 是 Salesforce AI Research 推出的一系列评估模型,旨在通过人工智能技术加速大型语言模型(LLMs)的评估和微调过程。这些模型能够执行多种评估任务,包括成对比较、单项评分和二元分类,同时提供解释,避免黑箱问题。SFR-Judge 在多个基准测试中表现优异,证明了其在评估模型输出和指导微调方面的有效性。
Show-Me是一个开源应用程序,旨在提供传统大型语言模型(如ChatGPT)交互的可视化和透明替代方案。它通过将复杂问题分解成一系列推理子任务,使用户能够理解语言模型的逐步思考过程。该应用程序使用LangChain与语言模型交互,并通过动态图形界面可视化推理过程。
Llama-3.1-Nemotron-51B是由NVIDIA基于Meta的Llama-3.1-70B开发的新型语言模型,通过神经架构搜索(NAS)技术优化,实现了高准确率和高效率。该模型能够在单个NVIDIA H100 GPU上运行,显著降低了内存占用,减少了内存带宽和计算量,同时保持了优秀的准确性。它代表了AI语言模型在准确性和效率之间取得的新平衡,为开发者和企业提供了成本可控的高性能AI解决方案。
Stability AI是一个专注于生成式人工智能技术的公司,提供多种AI模型,包括文本到图像、视频、音频、3D和语言模型。这些模型能够处理复杂提示,生成逼真的图像和视频,以及高质量的音乐和音效。公司提供灵活的许可选项,包括自托管许可和平台API,以满足不同用户的需求。Stability AI致力于通过开放模型,为全球每个人提供高质量的AI服务。
DataGemma是世界上首个开放模型,旨在通过谷歌数据共享平台的大量真实世界统计数据,帮助解决AI幻觉问题。这些模型通过两种不同的方法增强了语言模型的事实性和推理能力,从而减少幻觉现象,提升AI的准确性和可靠性。DataGemma模型的推出,是AI技术在提升数据准确性和减少错误信息传播方面的重要进步,对于研究人员、决策者以及普通用户来说,都具有重要的意义。
Chat With Your Docs 是一个Python应用程序,允许用户与多种文档格式(如PDF、网页和YouTube视频)进行对话。用户可以使用自然语言提问,应用程序将基于文档内容提供相关回答。该应用利用语言模型生成准确答案。请注意,应用仅回应与加载的文档相关的问题。
ell是一个轻量级的语言模型编程库,它将提示视为函数,而不是简单的字符串。ell的设计基于在OpenAI和创业生态系统中多年构建和使用语言模型的经验。它提供了一种全新的编程方式,允许开发者通过定义函数来生成发送给语言模型的字符串提示或消息列表。这种封装方式为用户创建了一个清晰的接口,用户只需关注LMP所需的数据。ell还提供了丰富的工具,支持监控、版本控制和可视化,使得提示工程从一门黑艺术转变为一门科学。
rStar是一个自我博弈相互推理方法,它通过将推理过程分解为解决方案生成和相互验证,显著提升了小型语言模型(SLMs)的推理能力,无需微调或使用更高级的模型。rStar通过蒙特卡洛树搜索(MCTS)和人类推理动作的结合,构建更高质量的推理轨迹,并通过另一个类似能力的SLM作为鉴别器来验证这些轨迹的正确性。这种方法在多个SLMs上进行了广泛的实验,证明了其在解决多样化推理问题方面的有效性。
MiniCPM3-4B是MiniCPM系列的第三代产品,整体性能超越了Phi-3.5-mini-Instruct和GPT-3.5-Turbo-0125,与许多近期的7B至9B模型相当。与前两代相比,MiniCPM3-4B具有更强大的多功能性,支持函数调用和代码解释器,使其能够更广泛地应用于各种场景。此外,MiniCPM3-4B拥有32k的上下文窗口,配合LLMxMapReduce技术,理论上可以处理无限上下文,而无需大量内存。
Zamba2-mini是由Zyphra Technologies Inc.发布的小型语言模型,专为设备端应用设计。它在保持极小的内存占用(<700MB)的同时,实现了与更大模型相媲美的评估分数和性能。该模型采用了4bit量化技术,具有7倍参数下降的同时保持相同性能的特点。Zamba2-mini在推理效率上表现出色,与Phi3-3.8B等更大模型相比,具有更快的首令牌生成时间、更低的内存开销和更低的生成延迟。此外,该模型的权重已开源发布(Apache 2.0),允许研究人员、开发者和公司利用其能力,推动高效基础模型的边界。
Phi-3是微软Azure推出的一系列小型语言模型(SLMs),具有突破性的性能,同时成本和延迟都很低。这些模型专为生成式AI解决方案设计,体积更小,计算需求更低。Phi-3模型遵循微软AI原则开发,包括责任、透明度、公平性、可靠性和安全性、隐私和安全性以及包容性,确保了安全性。此外,Phi-3还提供了本地部署、准确相关回答、低延迟场景部署、成本受限任务处理和定制化精度等功能。
Grok-2是xAI的前沿语言模型,具有最先进的推理能力。此次发布包括Grok家族的两个成员:Grok-2和Grok-2 mini。这两个模型现在都在𝕏平台上发布给Grok用户。Grok-2是Grok-1.5的重要进步,具有聊天、编程和推理方面的前沿能力。同时,xAI引入了Grok-2 mini,一个小巧但功能强大的Grok-2的兄弟模型。Grok-2的早期版本已经在LMSYS排行榜上以“sus-column-r”的名字进行了测试。它在整体Elo得分方面超过了Claude 3.5 Sonnet和GPT-4-Turbo。
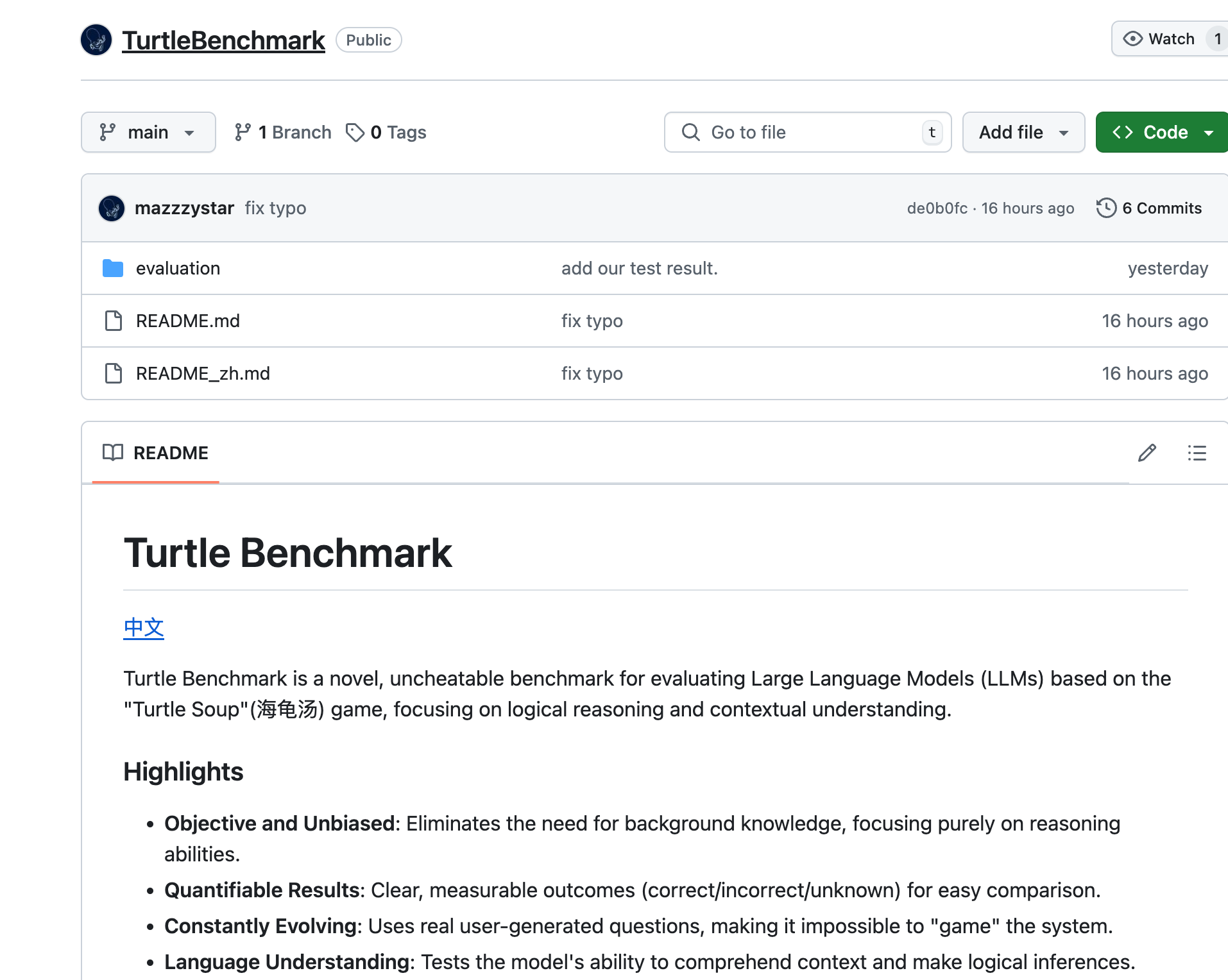
Turtle Benchmark是一款基于'Turtle Soup'游戏的新型、无法作弊的基准测试,专注于评估大型语言模型(LLMs)的逻辑推理和上下文理解能力。它通过消除对背景知识的需求,提供了客观和无偏见的测试结果,具有可量化的结果,并且通过使用真实用户生成的问题,使得模型无法被'游戏化'。
Qwen2-Math是一系列基于Qwen2 LLM构建的专门用于数学解题的语言模型。它在数学相关任务上的表现超越了现有的开源和闭源模型,为科学界解决需要复杂多步逻辑推理的高级数学问题提供了重要帮助。
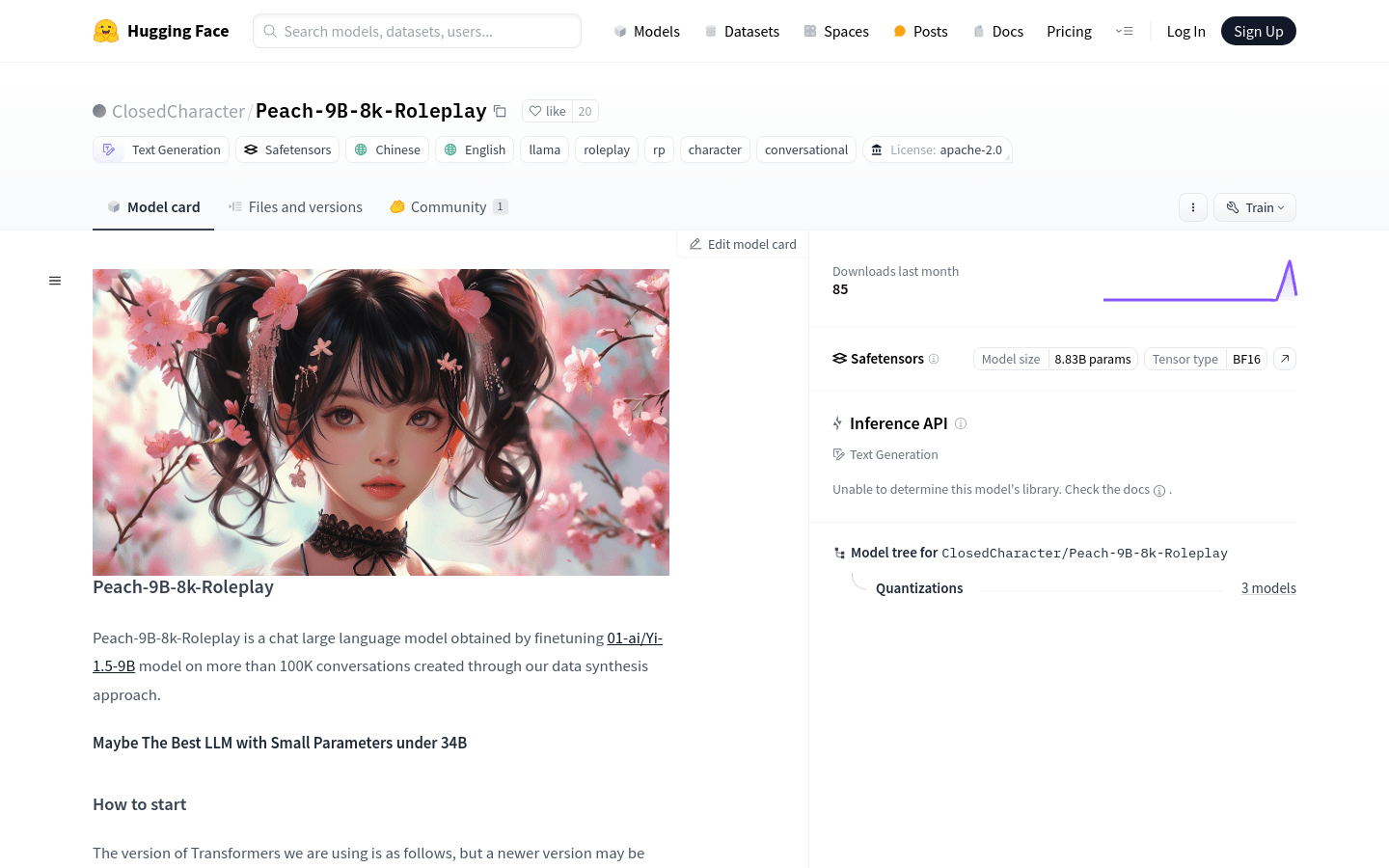
Peach-9B-8k-Roleplay是一个经过微调的大型语言模型,专门用于角色扮演对话。它基于01-ai/Yi-1.5-9B模型,通过数据合成方法在超过100K的对话上进行训练。尽管模型参数较小,但可能在34B以下参数的语言模型中表现最佳。
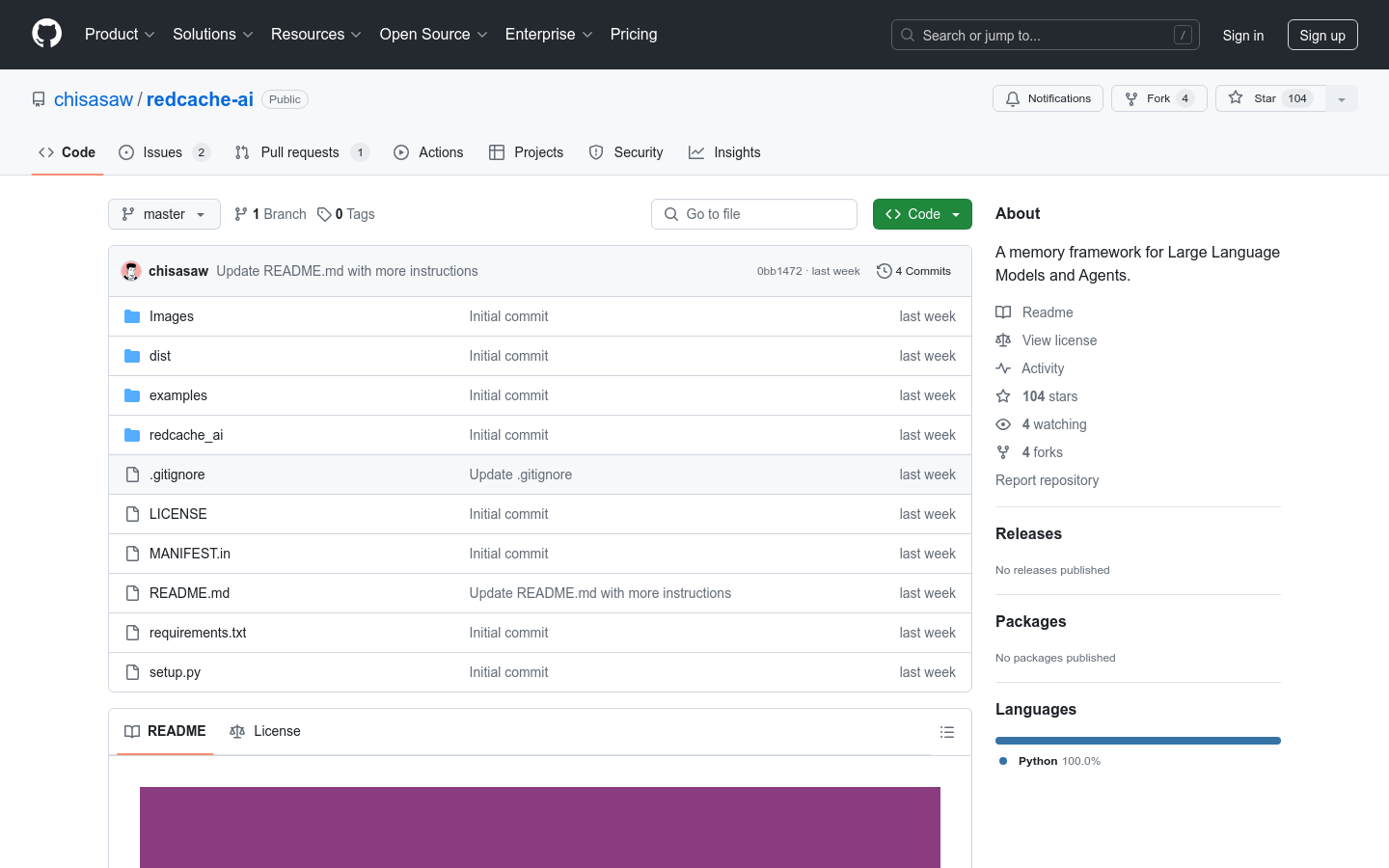
RedCache-AI是一个为大型语言模型和代理设计的动态记忆框架,它允许开发者构建从AI驱动的约会应用到医疗诊断平台等广泛的应用。它解决了现有解决方案昂贵、封闭源代码或缺乏对外部依赖的广泛支持的问题。
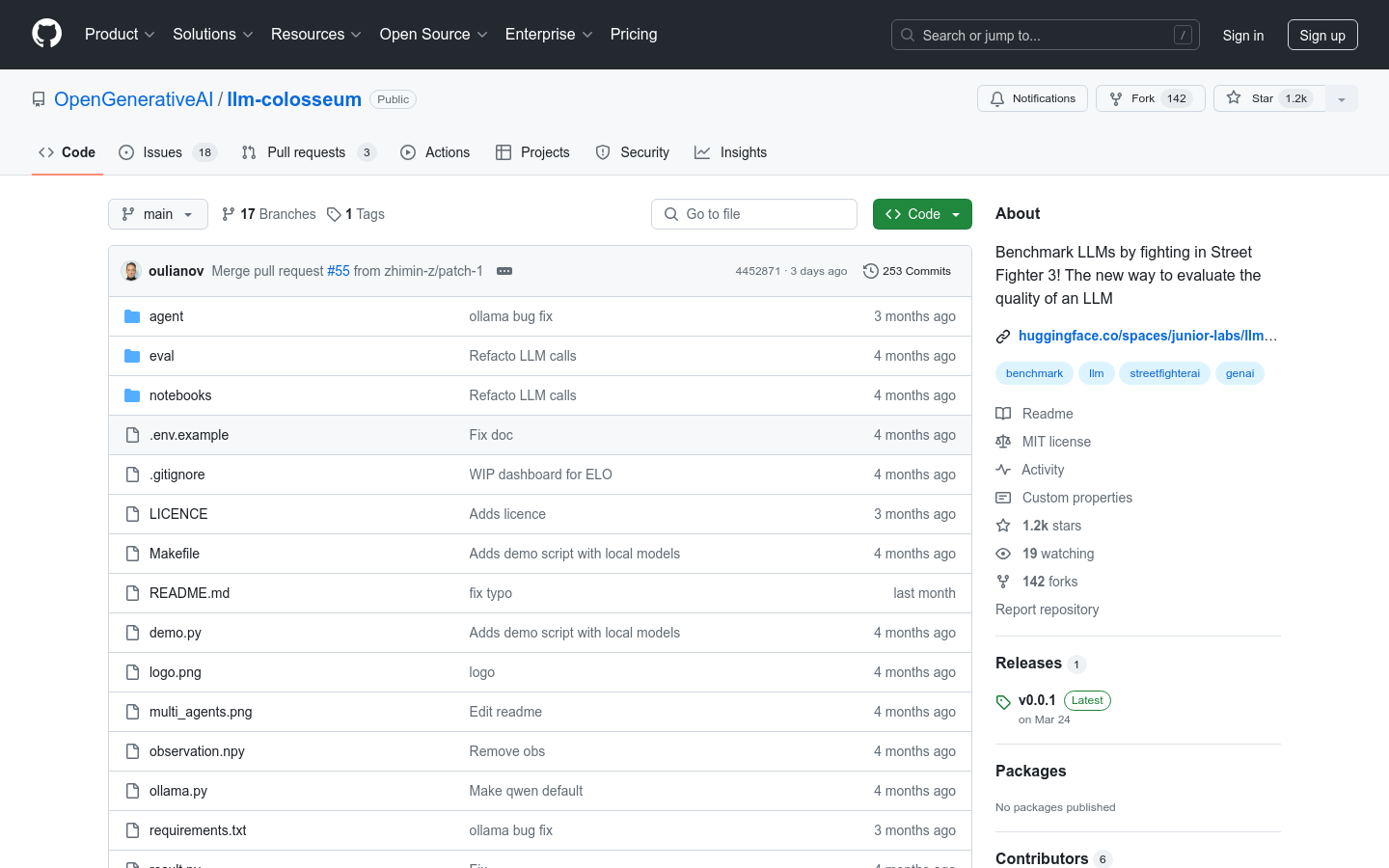
llm-colosseum是一个创新的基准测试工具,它使用街霸3游戏来评估大型语言模型(LLM)的实时决策能力。与传统的基准测试不同,这个工具通过模拟实际游戏场景来测试模型的快速反应、智能策略、创新思维、适应性和恢复力。
Llama3.1-8B-Chinese-Chat是一个基于Meta-Llama-3.1-8B-Instruct模型的指令式调优语言模型,专为中文和英文用户设计,具有角色扮演和工具使用等多种能力。该模型通过ORPO算法进行微调,显著减少了中文问题用英文回答和回答中中英文混合的问题,特别是在角色扮演、功能调用和数学能力方面有显著提升。
Meta Llama 3.1是一系列预训练和指令调整的多语言大型语言模型(LLMs),支持8种语言,专为对话使用案例优化,并通过监督式微调(SFT)和人类反馈的强化学习(RLHF)来提高安全性和有用性。
Meta Llama 3.1-405B 是由 Meta 开发的一系列大型多语言预训练语言模型,包含8B、70B和405B三种规模的模型。这些模型经过优化的变压器架构,使用监督式微调(SFT)和强化学习与人类反馈(RLHF)进行调优,以符合人类对帮助性和安全性的偏好。Llama 3.1 模型支持多种语言,包括英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。该模型在多种自然语言生成任务中表现出色,并在行业基准测试中超越了许多现有的开源和封闭聊天模型。
Aphrodite是PygmalionAI的官方后端引擎,旨在为PygmalionAI网站提供推理端点,并允许以极快的速度为大量用户提供Pygmalion模型服务。Aphrodite利用vLLM的分页注意力技术,实现了连续批处理、高效的键值管理、优化的CUDA内核等特性,支持多种量化方案,以提高推理性能。
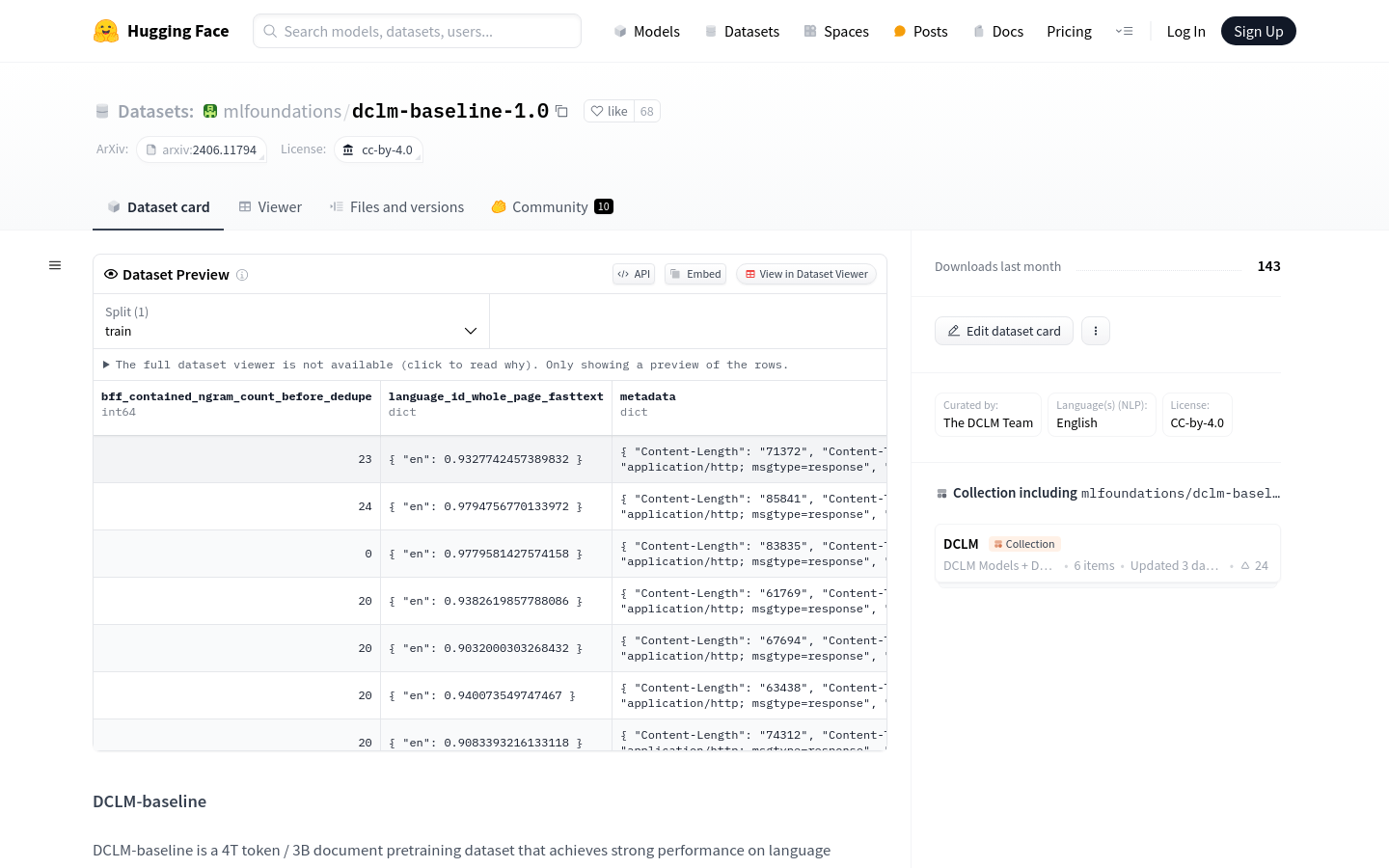
DCLM-baseline是一个用于语言模型基准测试的预训练数据集,包含4T个token和3B个文档。它通过精心策划的数据清洗、过滤和去重步骤,从Common Crawl数据集中提取,旨在展示数据策划在训练高效语言模型中的重要性。该数据集仅供研究使用,不适用于生产环境或特定领域的模型训练,如代码和数学。
DCLM-Baseline-7B是一个7亿参数的语言模型,由DataComp for Language Models (DCLM)团队开发,主要使用英语。该模型旨在通过系统化的数据整理技术来提高语言模型的性能。模型训练使用了PyTorch与OpenLM框架,优化器为AdamW,学习率为2e-3,权重衰减为0.05,批次大小为2048序列,序列长度为2048个token,总训练token数达到了2.5T。模型训练硬件使用了H100 GPU。