找到 559 个相关的AI工具
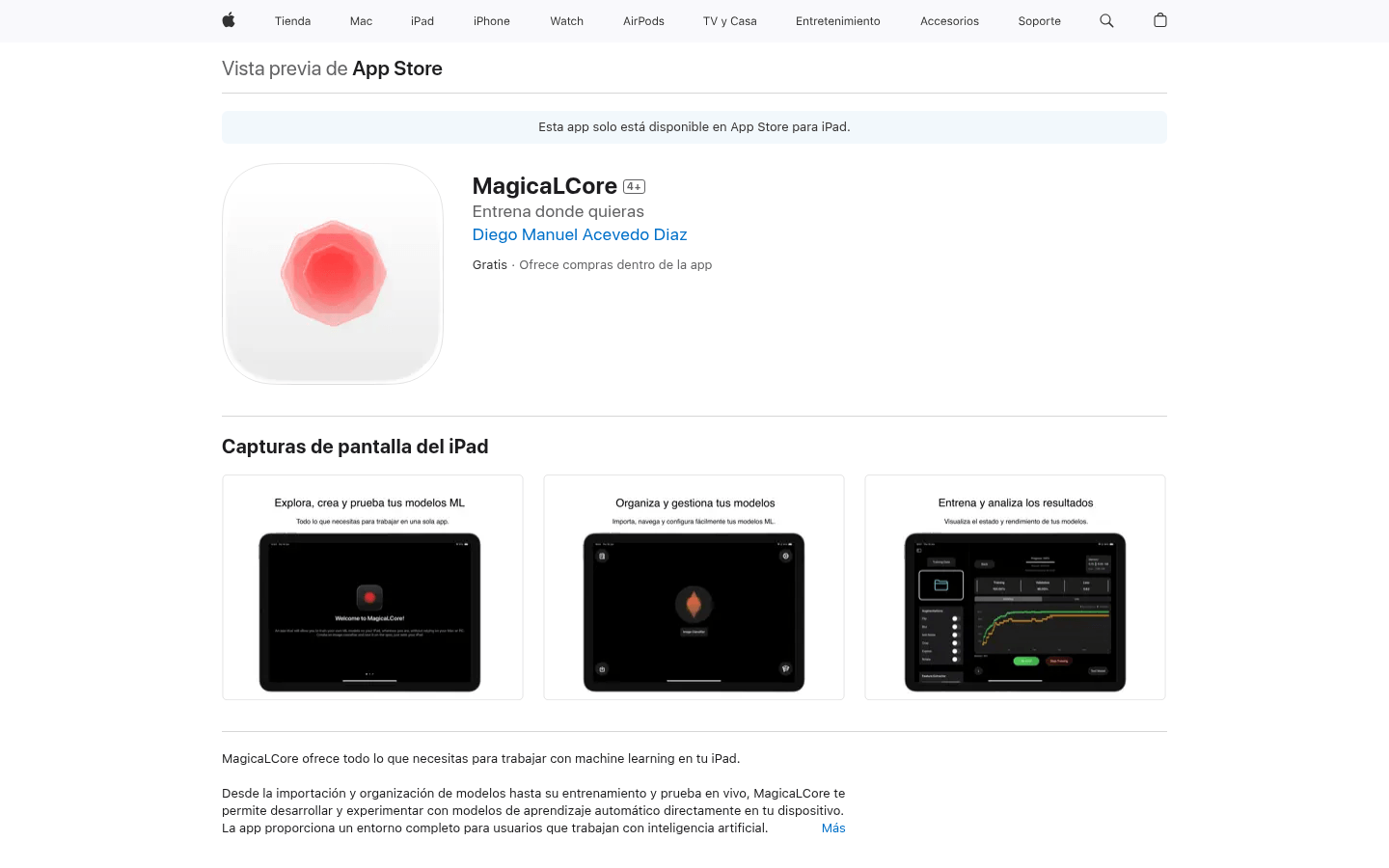
MagicaLCore是一款能够在iPad上进行机器学习工作的应用。用户可以导入、组织、训练和实时测试机器学习模型,直接在设备上开发和实验模型。
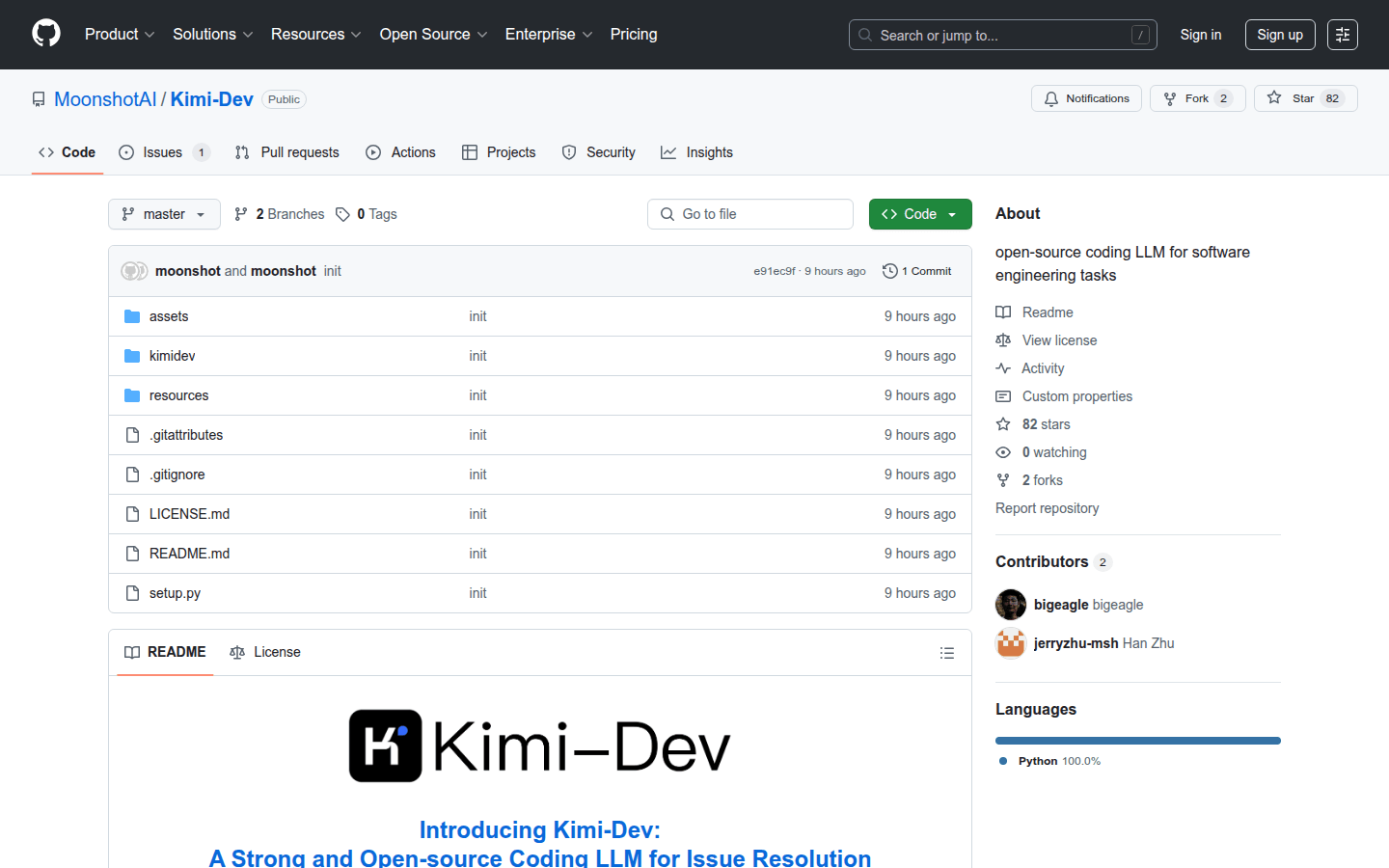
Kimi-Dev 是一款强大的开源编码 LLM,旨在解决软件工程中的问题。它通过大规模强化学习优化,确保在真实开发环境中的正确性和稳健性。Kimi-Dev-72B 在 SWE-bench 验证中实现了 60.4% 的性能,超越其他开源模型,是目前最先进的编码 LLM 之一。该模型可在 Hugging Face 和 GitHub 上下载和部署,适合开发者和研究人员使用。
AlphaOne(α1)是一种调节大型推理模型(LRMs)在测试时思维进度的通用框架。通过引入 α 时刻和动态安排慢速思维转变,α1 实现了慢速到快速推理的灵活调节。这一方法统一并推广了现有的单调缩放方法,优化了推理能力与计算效率。该产品适用于需要处理复杂推理任务的科研人员和开发者。
WorldPM-72B 是一个通过大规模训练获得的统一偏好建模模型,具有显著的通用性和较强的表现能力。该模型基于 15M 偏好数据,展示了在客观知识的偏好识别方面的巨大潜力。适合用于生成更高质量的文本内容,尤其在写作领域具有重要的应用价值。
Audio-SDS 是一个将 Score Distillation Sampling(SDS)概念应用于音频扩散模型的框架。该技术能够在不需要专门数据集的情况下,利用大型预训练模型进行多种音频任务,如物理引导的冲击声合成和基于提示的源分离。其主要优点在于通过一系列迭代优化,使得复杂的音频生成任务变得更为高效。此技术具有广泛的应用前景,能够为未来的音频生成和处理研究提供坚实基础。
docsynecx是一款智能文档处理AI平台,通过AI、机器学习和OCR技术,自动化处理各种文档类型,包括发票处理、收据、提单等。该平台能够快速准确地提取、分类和组织结构化、半结构化和非结构化数据。
parakeet-tdt-0.6b-v2 是一个 600 百万参数的自动语音识别(ASR)模型,旨在实现高质量的英语转录,具有准确的时间戳预测和自动标点符号、大小写支持。该模型基于 FastConformer 架构,能够高效地处理长达 24 分钟的音频片段,适合开发者、研究人员和各行业应用。
Step1X-Edit 是一种实用的通用图像编辑框架,利用 MLLMs 的图像理解能力解析编辑指令,生成编辑令牌,并通过 DiT 网络解码为图像。其重要性在于能够有效满足真实用户的编辑需求,提升了图像编辑的便捷性和灵活性。
Nes2Net 是一个为基础模型驱动的语音反欺诈任务设计的轻量级嵌套架构,具有较低的错误率,适用于音频深度假造检测。该模型在多个数据集上表现优异,预训练模型和代码已在 GitHub 上发布,便于研究人员和开发者使用。适合音频处理和安全领域,主要定位于提高语音识别和反欺诈的效率和准确性。
EaseVoice Trainer 是一个后端项目,旨在简化和增强语音合成与转换训练过程。该项目基于 GPT-SoVITS 进行改进,注重用户体验和系统的可维护性。其设计理念不同于原始项目,旨在提供更模块化和定制化的解决方案,适用于从小规模实验到大规模生产的多种场景。该工具可以帮助开发者和研究人员更高效地进行语音合成和转换的研究与开发。
FramePack 是一个创新的视频生成模型,旨在通过压缩输入帧的上下文来提高视频生成的质量和效率。其主要优点在于解决了视频生成中的漂移问题,通过双向采样方法保持视频质量,适合需要生成长视频的用户。该技术背景来源于对现有模型的深入研究和实验,以改进视频生成的稳定性和连贯性。
GenPRM 是一种新兴的过程奖励模型(PRM),通过生成推理来提高在测试时的计算效率。这项技术能够在处理复杂任务时提供更准确的奖励评估,适用于多种机器学习和人工智能领域的应用。其主要优点是能够在资源有限的情况下优化模型性能,并在实际应用中降低计算成本。
Skywork-OR1是由昆仑万维天工团队开发的高性能数学代码推理模型。该模型系列在同等参数规模下实现了业界领先的推理性能,突破了大模型在逻辑理解与复杂任务求解方面的能力瓶颈。Skywork-OR1系列包括Skywork-OR1-Math-7B、Skywork-OR1-7B-Preview和Skywork-OR1-32B-Preview三款模型,分别聚焦数学推理、通用推理和高性能推理任务。此次开源不仅涵盖模型权重,还全面开放了训练数据集和完整训练代码,所有资源均已上传至GitHub和Huggingface平台,为AI社区提供了完全可复现的实践参考。这种全方位的开源策略有助于推动整个AI社区在推理能力研究上的共同进步。
Pusa 通过帧级噪声控制引入视频扩散建模的创新方法,能够实现高质量的视频生成,适用于多种视频生成任务(文本到视频、图像到视频等)。该模型以其卓越的运动保真度和高效的训练过程,提供了一个开源的解决方案,方便用户进行视频生成任务。
Dream 7B 是由香港大学 NLP 组和华为诺亚方舟实验室联合推出的最新扩散大语言模型。它在文本生成领域展现了优异的性能,特别是在复杂推理、长期规划和上下文连贯性等方面。该模型采用了先进的训练方法,具有强大的计划能力和灵活的推理能力,为各类 AI 应用提供了更为强大的支持。
该产品是一个专门设计的 OCR 系统,旨在从复杂的教育材料中提取结构化数据,支持多语言文本、数学公式、表格和图表,能够生成适用于机器学习训练的高质量数据集。该系统利用多种技术和 API,能够提供高精度的提取结果,适合学术研究和教育工作者使用。
Arthur Engine 是一个旨在监控和治理 AI/ML 工作负载的工具,利用流行的开源技术和框架。该产品的企业版提供更好的性能和额外功能,如自定义的企业级防护机制和指标,旨在最大化 AI 对组织的潜力。它能够有效评估和优化模型,确保数据安全与合规。
DeepSeek-V3-0324 是一个先进的文本生成模型,具有 685 亿参数,采用 BF16 和 F32 张量类型,能够支持高效的推理和文本生成。该模型的主要优点在于其强大的生成能力和开放源码的特性,使其可以被广泛应用于多种自然语言处理任务。该模型的定位是为开发者和研究人员提供一个强大的工具,帮助他们在文本生成领域取得突破。
RF-DETR 是一个基于变压器的实时目标检测模型,旨在为边缘设备提供高精度和实时性能。它在 Microsoft COCO 基准测试中超过了 60 AP,具有竞争力的性能和快速的推理速度,适合各种实际应用场景。RF-DETR 旨在解决现实世界中的物体检测问题,适用于需要高效且准确检测的行业,如安防、自动驾驶和智能监控等。
Pruna 是一个为开发者设计的模型优化框架,通过一系列压缩算法,如量化、修剪和编译等技术,使得机器学习模型在推理时更快、体积更小且计算成本更低。产品适用于多种模型类型,包括 LLMs、视觉转换器等,且支持 Linux、MacOS 和 Windows 等多个平台。Pruna 还提供了企业版 Pruna Pro,解锁更多高级优化功能和优先支持,助力用户在实际应用中提高效率。
SpatialLM 是一个专为处理 3D 点云数据设计的大型语言模型,能够生成结构化的 3D 场景理解输出,包括建筑元素和对象的语义类别。它能够从单目视频序列、RGBD 图像和 LiDAR 传感器等多种来源处理点云数据,无需专用设备。SpatialLM 在自主导航和复杂 3D 场景分析任务中具有重要应用价值,显著提升空间推理能力。
Orpheus TTS 是一个基于 Llama-3b 模型的开源文本转语音系统,旨在提供更加自然的人类语音合成。它具备较强的语音克隆能力和情感表达能力,适合各种实时应用场景。该产品是免费的,旨在为开发者和研究者提供便捷的语音合成工具。
Firefox Translations Models 是由Mozilla开发的一组CPU优化的神经机器翻译模型,专为Firefox浏览器的翻译功能设计。该模型通过高效的CPU加速技术,提供快速且准确的翻译服务,支持多种语言对。其主要优点包括高性能、低延迟和对多种语言的支持。该模型是Firefox浏览器翻译功能的核心技术,为用户提供无缝的网页翻译体验。
Data Science Agent in Colab 是 Google 推出的一款基于 Gemini 的智能工具,旨在简化数据科学工作流程。它通过自然语言描述自动生成完整的 Colab 笔记本代码,涵盖数据导入、分析和可视化等任务。该工具的主要优点是节省时间、提高效率,并且生成的代码可修改和共享。它面向数据科学家、研究人员和开发者,尤其是那些希望快速从数据中获取洞察的用户。目前该工具免费提供给符合条件的用户。
3FS是一个专为AI训练和推理工作负载设计的高性能分布式文件系统。它利用现代SSD和RDMA网络,提供共享存储层,简化分布式应用开发。其核心优势在于高性能、强一致性和对多种工作负载的支持,能够显著提升AI开发和部署的效率。该系统适用于大规模AI项目,尤其在数据准备、训练和推理阶段表现出色。
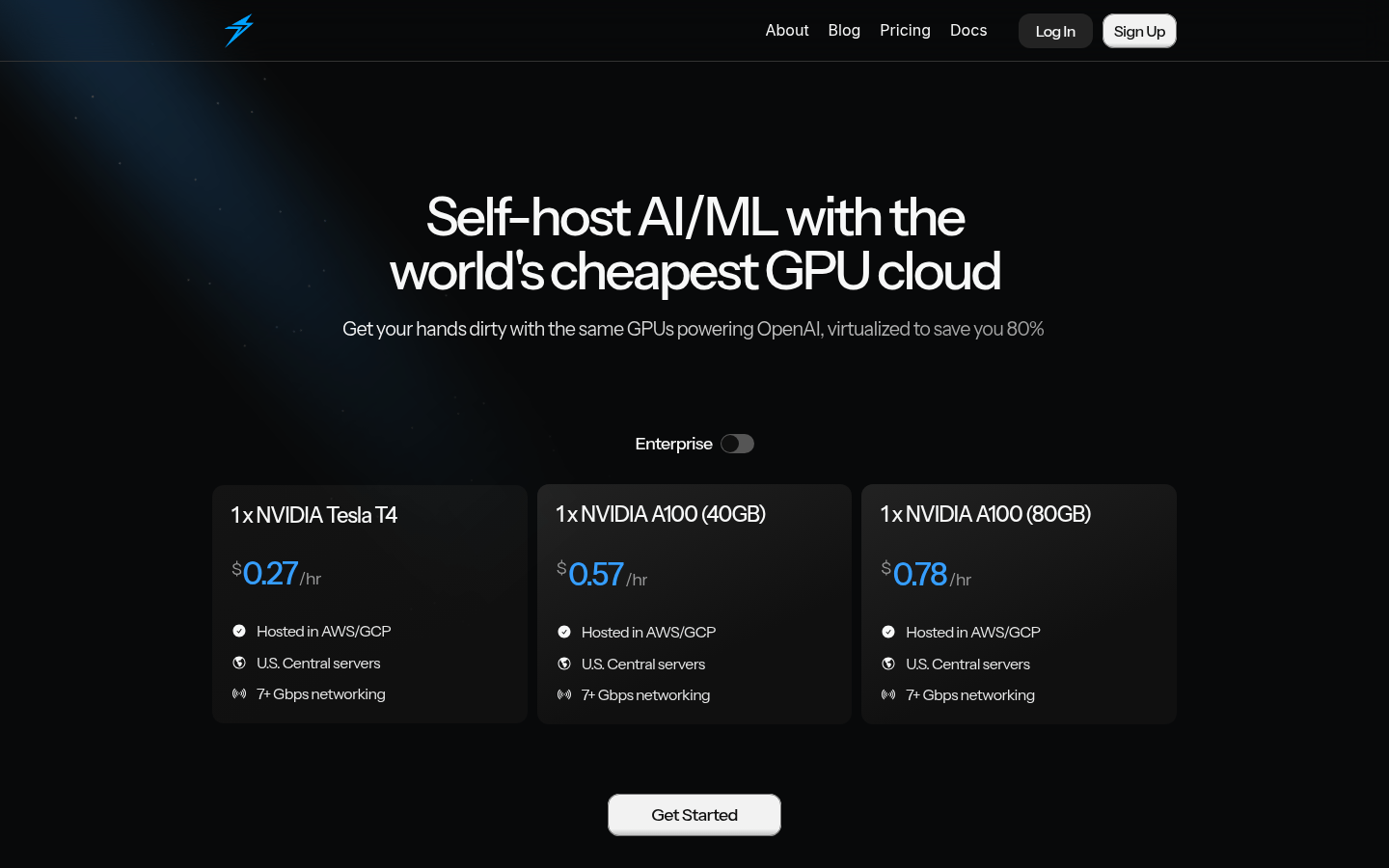
Thunder Compute是一个专注于AI/ML开发的GPU云服务平台,通过虚拟化技术,帮助用户以极低的成本使用高性能GPU资源。其主要优点是价格低廉,相比传统云服务提供商可节省高达80%的成本。该平台支持多种主流GPU型号,如NVIDIA Tesla T4、A100等,并提供7+ Gbps的网络连接,确保数据传输的高效性。Thunder Compute的目标是为AI开发者和企业降低硬件成本,加速模型训练和部署,推动AI技术的普及和应用。
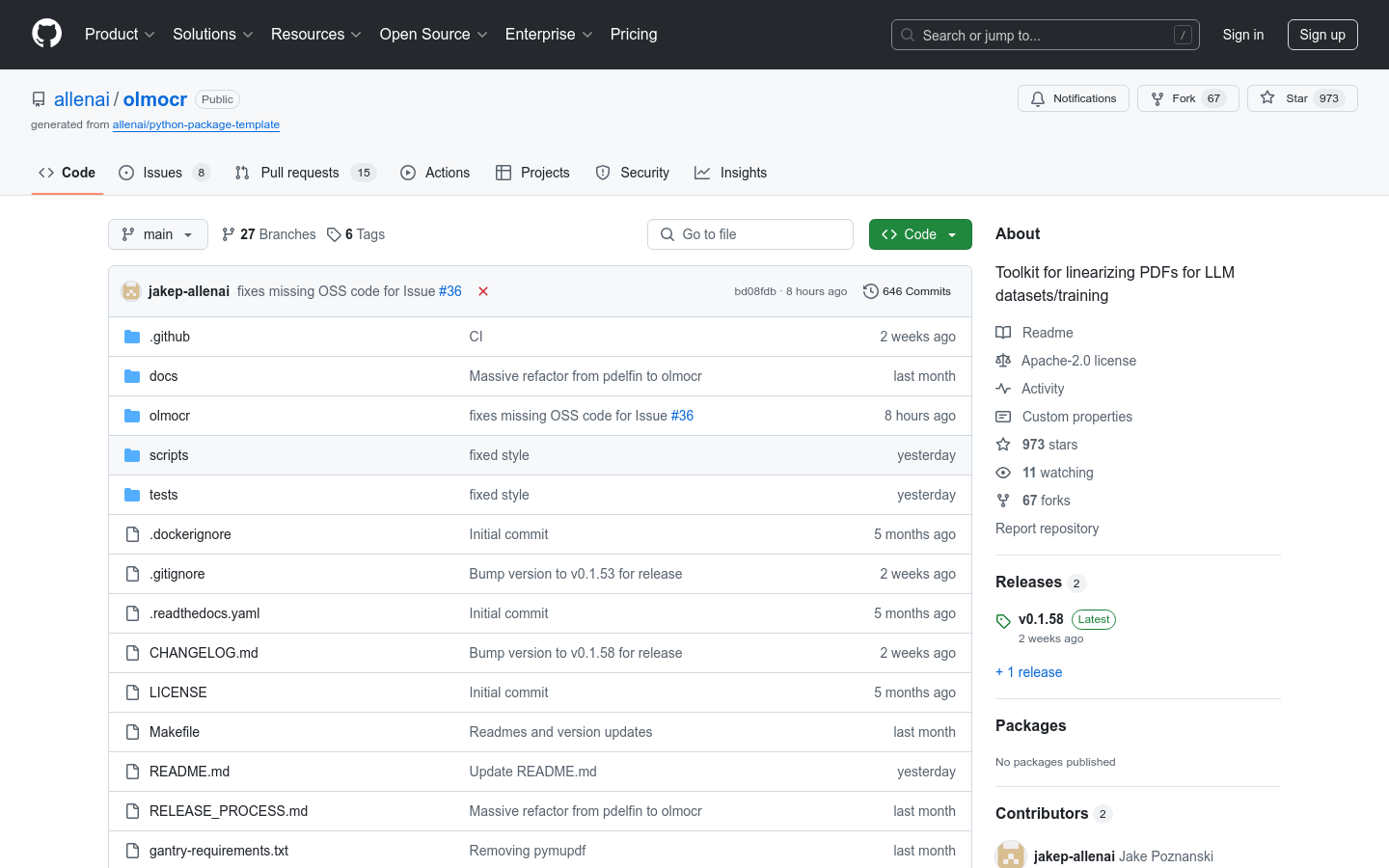
olmOCR是由Allen Institute for Artificial Intelligence (AI2)开发的一个开源工具包,旨在将PDF文档线性化,以便用于大型语言模型(LLM)的训练。该工具包通过将PDF文档转换为适合LLM处理的格式,解决了传统PDF文档结构复杂、难以直接用于模型训练的问题。它支持多种功能,包括自然文本解析、多版本比较、语言过滤和SEO垃圾信息移除等。olmOCR的主要优点是能够高效处理大量PDF文档,并通过优化的提示策略和模型微调,提高文本解析的准确性和效率。该工具包适用于需要处理大量PDF数据的研究人员和开发者,尤其是在自然语言处理和机器学习领域。
TensorPool 是一个专注于简化机器学习模型训练的云 GPU 平台。它通过提供一个直观的命令行界面(CLI),帮助用户轻松描述任务并自动处理 GPU 的编排和执行。TensorPool 的核心技术包括智能的 Spot 节点恢复技术,能够在抢占式实例被中断时立即恢复作业,从而结合了抢占式实例的成本优势和按需实例的可靠性。此外,TensorPool 还通过实时多云分析选择最便宜的 GPU 选项,用户只需为实际执行时间付费,无需担心闲置机器带来的额外成本。TensorPool 的目标是让开发者无需花费大量时间配置云提供商,从而提高机器学习工程的速度和效率。它提供个人计划和企业计划,个人计划每周提供 $5 的免费信用额度,而企业计划则提供更高级的支持和功能。
The Ultra-Scale Playbook 是一个基于 Hugging Face Spaces 提供的模型工具,专注于超大规模系统的优化和设计。它利用先进的技术框架,帮助开发者和企业高效地构建和管理大规模系统。该工具的主要优点包括高度的可扩展性、优化的性能和易于集成的特性。它适用于需要处理复杂数据和大规模计算任务的场景,如人工智能、机器学习和大数据处理。产品目前以开源的形式提供,适合各种规模的企业和开发者使用。
Heron是一款专注于自动化文档处理的生产力工具。它通过先进的AI技术,能够快速接收、分类、解析和同步文档数据,直接将结构化数据同步到用户的CRM系统中。Heron的主要优点包括高效的数据处理能力、强大的机器学习支持以及与现有业务流程的无缝集成。该产品主要面向需要处理大量文档的中小企业融资、法律、保险等行业,旨在帮助用户节省时间、降低成本并提高决策效率。Heron的定价策略灵活,具体价格根据客户需求定制,适合希望通过技术提升工作效率的企业。
DeepResearch123是一个AI研究资源导航平台,旨在为研究人员、开发者和爱好者提供丰富的AI研究资源、文档和实践案例。该平台涵盖了机器学习、深度学习和人工智能等多个领域的最新研究成果,帮助用户快速了解和掌握相关知识。其主要优点是资源丰富、分类清晰,便于用户查找和学习。该平台面向对AI研究感兴趣的各类人群,无论是初学者还是专业人士都能从中受益。目前平台免费开放,用户无需付费即可使用所有功能。
Finbar是一个专注于提供全球基础金融数据的平台。它通过先进的OCR、机器学习和自然语言处理技术,能够快速从海量金融文档中提取结构化数据,并在数据发布后几秒内提供给用户。其主要优点是数据更新速度快、自动化程度高,能够显著减少人工处理数据的时间和成本。该产品主要面向金融机构和分析师,帮助他们快速获取和分析数据,提升工作效率。目前尚不清楚其具体价格和定位,但已获得多家顶级对冲基金的使用。
Mo是一个专注于 AI 技术学习和应用的平台,旨在为用户提供从基础到高级的系统学习资源,帮助各类学习者掌握 AI 技能,并将其应用于实际项目中。无论你是大学生、职场新人,还是想提升自己技能的行业专家,Mo都能为你提供量身定制的课程、实战项目和工具,带你深入理解和应用人工智能。
该产品是一个AI驱动的数据科学团队模型,旨在帮助用户以更快的速度完成数据科学任务。它通过一系列专业的数据科学代理(Agents),如数据清洗、特征工程、建模等,来自动化和加速数据科学工作流程。该产品的主要优点是能够显著提高数据科学工作的效率,减少人工干预,适用于需要快速处理和分析大量数据的企业和研究机构。产品目前处于Beta阶段,正在积极开发中,可能会有突破性变化。它采用MIT许可证,用户可以在GitHub上免费使用和贡献代码。
TimesFM是一个由Google Research开发的预训练时间序列预测模型,用于时间序列预测任务。该模型在多个数据集上进行了预训练,能够处理不同频率和长度的时间序列数据。其主要优点包括高性能、可扩展性强以及易于使用。该模型适用于需要准确预测时间序列数据的各种应用场景,如金融、气象、能源等领域。该模型在Hugging Face平台上免费提供,用户可以方便地下载和使用。
Imitate Before Detect 是一种创新的文本检测技术,旨在提高对机器修订文本的检测能力。该技术通过模仿大型语言模型(LLM)的风格偏好,能够更准确地识别出经过机器修订的文本。其核心优势在于能够有效区分机器生成和人类写作的细微差别,从而在文本检测领域具有重要的应用价值。该技术的背景信息显示,它能够显著提高检测的准确性,并且在处理开源LLM修订文本时,AUC值提升了13%,在检测GPT-3.5和GPT-4o修订文本时分别提升了5%和19%。其定位是为研究人员和开发者提供一种高效的文本检测工具。
Bakery是一个专注于开源AI模型的微调与变现的在线平台,为AI初创企业、机器学习工程师和研究人员提供了一个便捷的工具,使他们能够轻松地对AI模型进行微调,并在市场中进行变现。该平台的主要优点在于其简单易用的界面和强大的功能,用户可以快速创建或上传数据集,微调模型设置,并在市场中进行变现。Bakery的背景信息表明,它旨在推动开源AI技术的发展,并为开发者提供更多的商业机会。虽然具体的定价信息未在页面中明确展示,但其定位是为AI领域的专业人士提供一个高效的工具。
vectrix-graphs 是一个强大的图形库,专注于多模型嵌入的可视化。它支持多种机器学习模型和数据类型,能够将复杂的数据结构以直观的图形形式展现出来。该库的主要优点在于其灵活性和扩展性,可以轻松集成到现有的数据科学工作流程中。vectrix-ai 团队开发了这个库,旨在帮助研究人员和开发者更好地理解和分析模型的嵌入结果。作为一个开源项目,它在 GitHub 上提供免费使用,适合各种规模的项目和团队。
Sonus-1是Sonus AI推出的一系列大型语言模型(LLMs),旨在推动人工智能的边界。这些模型以其高性能和多应用场景的多功能性而设计,包括Sonus-1 Mini、Sonus-1 Air、Sonus-1 Pro和Sonus-1 Pro (w/ Reasoning)等不同版本,以满足不同需求。Sonus-1 Pro (w/ Reasoning)在多个基准测试中表现突出,特别是在推理和数学问题上,展现了其超越其他专有模型的能力。Sonus AI致力于开发高性能、可负担、可靠且注重隐私的大型语言模型。
Text-to-CAD UI是一个利用自然语言提示生成B-Rep CAD文件和网格的平台。它通过ML-ephant API,由Zoo提供支持,能够将用户的自然语言描述直接转化为精确的CAD模型。这项技术的重要性在于它极大地简化了设计过程,使得非专业人士也能轻松创建复杂的CAD模型,从而推动了设计的民主化和创新。产品背景信息显示,它是由Zoo开发的,旨在通过机器学习技术提升设计效率。关于价格和定位,用户需要登录后才能获取更多信息。
Zoo提供了一个现代的硬件设计工具包,包括GPU驱动引擎、按需付费、远程流媒体和开放API兼容等特点,旨在提高硬件设计效率和降低成本。它允许用户创建前所未有的新设计工具,无论是个人爱好者、初创企业还是大型企业,Zoo的安全基础设施都能加速项目和工具的发展。
TangoFlux是一个高效的文本到音频(TTA)生成模型,拥有515M参数,能够在单个A40 GPU上仅用3.7秒生成长达30秒的44.1kHz音频。该模型通过提出CLAP-Ranked Preference Optimization (CRPO)框架,解决了TTA模型对齐的挑战,通过迭代生成和优化偏好数据来增强TTA对齐。TangoFlux在客观和主观基准测试中均实现了最先进的性能,并且所有代码和模型均开源,以支持TTA生成的进一步研究。
InternVL2.5-MPO是一个先进的多模态大型语言模型系列,它基于InternVL2.5和混合偏好优化构建。该模型整合了新增量预训练的InternViT与各种预训练的大型语言模型,包括InternLM 2.5和Qwen 2.5,使用随机初始化的MLP投影器。InternVL2.5-MPO在新版本中保留了与InternVL 2.5及其前身相同的模型架构,遵循“ViT-MLP-LLM”范式。该模型支持多图像和视频数据,通过混合偏好优化(MPO)进一步提升模型性能,使其在多模态任务中表现更优。
Llama-3.1-70B-Instruct-AWQ-INT4是一个由Hugging Face托管的大型语言模型,专注于文本生成任务。该模型拥有70B个参数,能够理解和生成自然语言文本,适用于多种文本相关的应用场景,如内容创作、自动回复等。它基于深度学习技术,通过大量的数据训练,能够捕捉语言的复杂性和多样性。模型的主要优点包括高参数量带来的强大表达能力,以及针对特定任务的优化,使其在文本生成领域具有较高的效率和准确性。
Bespoke Curator是一个开源项目,提供了一个基于Python的丰富库,用于生成和策展合成数据。它具备高性能优化、智能缓存和故障恢复功能,并且可以与HuggingFace Dataset对象直接协作。Bespoke Curator的主要优点包括其程序性和结构化输出能力,能够设计复杂的数据生成管道,以及通过内置的Curator Viewer实时检查和优化数据生成策略。
ModernBERT是由Answer.AI和LightOn共同发布的新一代编码器模型,它是BERT模型的全面升级版,提供了更长的序列长度、更好的下游性能和更快的处理速度。ModernBERT采用了最新的Transformer架构改进,特别关注效率,并使用了现代数据规模和来源进行训练。作为编码器模型,ModernBERT在各种自然语言处理任务中表现出色,尤其是在代码搜索和理解方面。它提供了基础版(139M参数)和大型版(395M参数)两种模型尺寸,适合各种规模的应用需求。
InternVL2_5-4B-MPO-AWQ是一个多模态大型语言模型(MLLM),专注于提升模型在图像和文本交互任务中的表现。该模型基于InternVL2.5系列,并通过混合偏好优化(MPO)进一步提升性能。它能够处理包括单图像和多图像、视频数据在内的多种输入,适用于需要图像和文本交互理解的复杂任务。InternVL2_5-4B-MPO-AWQ以其卓越的多模态能力,为图像-文本到文本的任务提供了一个强大的解决方案。
VidTok是微软开源的一系列先进的视频分词器,它在连续和离散分词方面表现出色。VidTok在架构效率、量化技术和训练策略上都有显著的创新,提供了高效的视频处理能力,并且在多个视频质量评估指标上超越了以往的模型。VidTok的开发旨在推动视频处理和压缩技术的发展,对于视频内容的高效传输和存储具有重要意义。
DynamicControl是一个用于提升文本到图像扩散模型控制力的框架。它通过动态组合多样的控制信号,支持自适应选择不同数量和类型的条件,以更可靠和详细地合成图像。该框架首先使用双循环控制器,利用预训练的条件生成模型和判别模型,为所有输入条件生成初始真实分数排序。然后,通过多模态大型语言模型(MLLM)构建高效条件评估器,优化条件排序。DynamicControl联合优化MLLM和扩散模型,利用MLLM的推理能力促进多条件文本到图像任务,最终排序的条件输入到并行多控制适配器,学习动态视觉条件的特征图并整合它们以调节ControlNet,增强对生成图像的控制。
Valley是由字节跳动开发的多模态大型模型(MLLM),旨在处理涉及文本、图像和视频数据的多种任务。该模型在内部电子商务和短视频基准测试中取得了最佳结果,远超过其他开源模型,并在OpenCompass多模态模型评估排行榜上展现了出色的性能,平均得分67.40,位列已知开源MLLMs(<10B)中的前两名。
shoonya是一个专注于现代商业领域的基础模型与代理,提供多语言支持、本地化服务和针对特定商业垂直领域的优化。它通过为电子商务用例特别调整的基础模型,支持多种语言和本地上下文,以推动下一代零售业务的发展。shoonya的技术背景是基于人工智能和机器学习,旨在理解和优化区域商业模式、术语和偏好,为用户提供更加个性化和高效的购物体验。
Smolagents是一个轻量级的库,允许用户以几行代码运行强大的智能代理。它以简洁性为特点,支持任何语言模型(LLM),包括Hugging Face Hub上的模型以及通过LiteLLM集成的OpenAI、Anthropic等模型。特别支持代码代理,即代理通过编写代码来执行动作,而不是让代理来编写代码。Smolagents还提供了代码执行的安全选项,包括安全的Python解释器和使用E2B的沙箱环境。
Llama-lynx-70b-4bitAWQ是一个由Hugging Face托管的70亿参数的文本生成模型,使用了4-bit精度和AWQ技术。该模型在自然语言处理领域具有重要性,特别是在需要处理大量数据和复杂任务时。它的优势在于能够生成高质量的文本,同时保持较低的计算成本。产品背景信息显示,该模型与'transformers'和'safetensors'库兼容,适用于文本生成任务。
Ruyi-Mini-7B是由CreateAI团队开发的开源图像到视频生成模型,具有约71亿参数,能够从输入图像生成360p到720p分辨率的视频帧,最长5秒。模型支持不同宽高比,并增强了运动和相机控制功能,提供更大的灵活性和创造力。该模型在Apache 2.0许可下发布,意味着用户可以自由使用和修改。
PromptWizard是由微软开发的一个任务感知型提示优化框架,它通过自我演化机制,使得大型语言模型(LLM)能够生成、批评和完善自己的提示和示例,通过迭代反馈和综合不断改进。这个自适应方法通过进化指令和上下文学习示例来全面优化,以提高任务性能。该框架的三个关键组件包括:反馈驱动的优化、批评和合成多样化示例、自生成的思考链(Chain of Thought, CoT)步骤。PromptWizard的重要性在于它能够显著提升LLM在特定任务上的表现,通过优化提示和示例来增强模型的性能和解释性。
Gemini 2.0 Flash Thinking Mode是谷歌推出的一个实验性AI模型,旨在生成模型在响应过程中的“思考过程”。相较于基础的Gemini 2.0 Flash模型,Thinking Mode在响应中展现出更强的推理能力。该模型在Google AI Studio和Gemini API中均可使用,是谷歌在人工智能领域的重要技术成果,对于开发者和研究人员来说,提供了一个强大的工具来探索和实现复杂的AI应用。
Gemini 2.0 Flash Experimental是Google DeepMind开发的最新AI模型,旨在提供低延迟和增强性能的智能代理体验。该模型支持原生工具使用,并首次能够原生创建图像和生成语音,代表了AI技术在理解和生成多媒体内容方面的重要进步。Gemini Flash模型家族以其高效的处理能力和广泛的应用场景,成为推动AI领域发展的关键技术之一。
Astris AI是洛克希德·马丁公司成立的子公司,旨在推动美国国防工业基地和商业行业领域中对高保证要求的人工智能解决方案的采用。Astris AI通过提供洛克希德·马丁公司在人工智能和机器学习领域的领先技术和专业团队,帮助客户开发和部署安全、弹性和可扩展的AI解决方案。Astris AI的成立体现了洛克希德·马丁公司在推进21世纪安全、加强国防工业基础和国家安全方面的承诺,同时也展示了其在整合商业技术以帮助客户应对日益增长的威胁环境方面的领导力。
Phi Open Models是微软Azure提供的一款小型语言模型(SLMs),以其卓越的性能、低成本和低延迟重新定义了小语言模型的可能性。Phi模型在保持较小体积的同时,提供了强大的AI能力,降低了资源消耗,并确保了成本效益的生成型AI部署。Phi模型的开发遵循了微软的AI原则,包括责任、透明度、公平性、可靠性和安全性、隐私和安全性以及包容性。
Recursal AI致力于使人工智能技术对所有人开放,无论语言或国家。他们的产品包括featherless.ai、RWKV和recursal cloud。featherless.ai提供即时且无需服务器的Hugging Face模型推理服务;RWKV是一个下一代基础模型,支持100多种语言,推理成本降低100倍;recursal cloud则让用户能够轻松地微调和部署RWKV模型。这些产品和技术的主要优点在于它们能够降低AI技术的门槛,提高效率,并支持多语言,这对于全球化背景下的企业和开发者来说至关重要。
Apollo是一个专注于视频理解的先进大型多模态模型家族。它通过系统性地探索视频-LMMs的设计空间,揭示了驱动性能的关键因素,提供了优化模型性能的实用见解。Apollo通过发现'Scaling Consistency',使得在较小模型和数据集上的设计决策能够可靠地转移到更大的模型上,大幅降低计算成本。Apollo的主要优点包括高效的设计决策、优化的训练计划和数据混合,以及一个新型的基准测试ApolloBench,用于高效评估。
Flock of Finches 37B-A11B v0.1是RWKV家族的最新成员,这是一个实验性模型,拥有11亿个活跃参数,尽管仅训练了1090亿个token,但在常见基准测试中的得分与最近发布的Finch 14B模型大致相当。该模型采用了高效的稀疏混合专家(MoE)方法,在任何给定token上仅激活一部分参数,从而在训练和推理过程中节省时间和减少计算资源的使用。尽管这种架构选择以更高的VRAM使用为代价,但从我们的角度看,能够低成本训练和运行具有更大能力模型是非常值得的。
Q-RWKV-6 32B Instruct Preview是由Recursal AI开发的最新RWKV模型变体,它在多项英语基准测试中超越了之前所有的RWKV、State Space和Liquid AI模型。这个模型通过将Qwen 32B Instruct模型的权重转换到定制的QRWKV6架构中,成功地用RWKV-V6注意力头替换了现有的Transformer注意力头,这一过程是由Recursal AI团队与RWKV和EleutherAI开源社区联合开发的。该模型的主要优点包括在大规模计算成本上的显著降低,以及对环境友好的开源AI技术。
CosyVoice语音生成大模型2.0-0.5B是一个高性能的语音合成模型,支持零样本、跨语言的语音合成,能够根据文本内容直接生成相应的语音输出。该模型由通义实验室提供,具有强大的语音合成能力和广泛的应用场景,包括但不限于智能助手、有声读物、虚拟主播等。模型的重要性在于其能够提供自然、流畅的语音输出,极大地丰富了人机交互的体验。
Command R7B是Cohere公司推出的一款高性能、可扩展的大型语言模型(LLM),专为企业级应用设计。它在保持较小模型体积的同时,提供了一流的速度、效率和质量,能够在普通的GPU、边缘设备甚至CPU上部署,大幅降低了AI应用的生产部署成本。Command R7B在多语言支持、引用验证检索增强生成(RAG)、推理、工具使用和代理行为等方面表现出色,特别适合需要优化速度、成本性能和计算资源的企业使用案例。
CausVid是一个先进的视频生成模型,它通过将预训练的双向扩散变换器适配为因果变换器,实现了即时视频帧的生成。这一技术的重要性在于它能够显著减少视频生成的延迟,使得视频生成能够以交互式帧率(9.4FPS)在单个GPU上进行流式生成。CausVid模型支持从文本到视频的生成,以及零样本图像到视频的生成,展现了视频生成技术的新高度。
Phi-4是微软Phi系列小型语言模型的最新成员,拥有14B参数,擅长数学等复杂推理领域。Phi-4通过使用高质量的合成数据集、精选有机数据和后训练创新,在大小与质量之间取得了平衡。Phi-4体现了微软在小型语言模型(SLM)领域的技术进步,推动了AI技术的边界。Phi-4目前已在Azure AI Foundry上提供,并将在未来几周登陆Hugging Face平台。
allenai/tulu-3-sft-olmo-2-mixture是一个大规模的多语言数据集,包含了用于训练和微调语言模型的多样化文本样本。该数据集的重要性在于它为研究人员和开发者提供了丰富的语言资源,以改进和优化多语言AI模型的性能。产品背景信息包括其由多个来源的数据混合而成,适用于教育和研究领域,且遵循特定的许可协议。
InternVL 2.5是基于InternVL 2.0的高级多模态大型语言模型系列,它在保持核心模型架构的同时,在训练和测试策略以及数据质量方面引入了显著的增强。该模型深入探讨了模型扩展与性能之间的关系,系统地探索了视觉编码器、语言模型、数据集大小和测试时配置的性能趋势。通过在包括多学科推理、文档理解、多图像/视频理解、现实世界理解、多模态幻觉检测、视觉定位、多语言能力和纯语言处理在内的广泛基准测试中进行的广泛评估,InternVL 2.5展现出了与GPT-4o和Claude-3.5-Sonnet等领先商业模型相媲美的竞争力。特别是,该模型是第一个在MMMU基准测试中超过70%的开源MLLM,通过链式思考(CoT)推理实现了3.7个百分点的提升,并展示了测试时扩展的强大潜力。
Procyon AI Inference Benchmark for Android是一款基于NNAPI的基准测试工具,用于衡量Android设备上的AI性能和质量。它通过一系列流行的、最先进的神经网络模型来执行常见的机器视觉任务,帮助工程团队独立、标准化地评估NNAPI实现和专用移动硬件的AI性能。该工具不仅能够测量Android设备上专用AI处理硬件的性能,还能够验证NNAPI实现的质量,对于优化硬件加速器的驱动程序、比较浮点和整数优化模型的性能具有重要意义。
Trillium TPU是Google Cloud的第六代Tensor Processing Unit(TPU),专为AI工作负载设计,提供增强的性能和成本效益。它作为Google Cloud AI Hypercomputer的关键组件,通过集成的硬件系统、开放软件、领先的机器学习框架和灵活的消费模型,支持大规模AI模型的训练、微调和推理。Trillium TPU在性能、成本效率和可持续性方面都有显著提升,是AI领域的重要进步。
OLMo-2-1124-7B-RM是由Hugging Face和Allen AI共同开发的一个大型语言模型,专注于文本生成和分类任务。该模型基于7B参数的规模构建,旨在处理多样化的语言任务,包括聊天、数学问题解答、文本分类等。它是基于Tülu 3数据集和偏好数据集训练的奖励模型,用于初始化RLVR训练中的价值模型。OLMo系列模型的发布,旨在推动语言模型的科学研究,通过开放代码、检查点、日志和相关的训练细节,促进了模型的透明度和可访问性。
InternVL 2.5是一系列先进的多模态大型语言模型(MLLM),它在InternVL 2.0的基础上,通过引入显著的训练和测试策略增强以及数据质量提升,保持了其核心模型架构。该模型集成了新增量预训练的InternViT与各种预训练的大型语言模型(LLMs),如InternLM 2.5和Qwen 2.5,使用随机初始化的MLP投影器。InternVL 2.5支持多图像和视频数据,通过动态高分辨率训练方法,增强了模型处理多模态数据的能力。
SPDL(Scalable and Performant Data Loading)是由Meta Reality Labs开发的一种新的数据加载解决方案,旨在提高AI模型训练的效率。它采用基于线程的并行处理,相比传统的基于进程的解决方案,SPDL在普通Python解释器中实现了高吞吐量,并且消耗的计算资源更少。SPDL与Free-Threaded Python兼容,在禁用GIL的情况下,比启用GIL的FT Python实现更高的吞吐量。SPDL的主要优点包括高吞吐量、易于理解的性能、不封装预处理操作、不引入领域特定语言(DSL)、无缝集成异步工具、灵活性、简单直观以及容错性。SPDL的背景信息显示,随着模型规模的增长,对数据的计算需求也随之增加,而SPDL通过最大化GPU的利用,加快了模型训练的速度。
Countless.dev是一个提供AI模型比较的平台,用户可以轻松查看和比较不同的AI模型。这个工具对于开发者和研究人员来说非常重要,因为它可以帮助他们根据模型的特性和价格来选择最合适的AI模型。平台提供了详细的模型参数,如输入长度、输出长度、价格等,以及是否支持视觉功能。
Agentless是一种无需代理的自动解决软件开发问题的方法。它通过定位、修复和补丁验证三个阶段来解决每个问题。Agentless利用分层过程定位故障到特定文件、相关类或函数,以及细粒度的编辑位置。然后,Agentless根据编辑位置采样多个候选补丁,并选择回归测试来运行,生成额外的复现测试以复现原始错误,并使用测试结果重新排名所有剩余补丁,以选择一个提交。Agentless是目前在SWE-bench lite上表现最佳的开源方法,具有82个修复(27.3%的解决率),平均每问题成本0.34美元。
InternVL 2.5是一系列先进的多模态大型语言模型(MLLM),在InternVL 2.0的基础上,通过引入显著的训练和测试策略增强以及数据质量提升,进一步发展而来。该模型系列在视觉感知和多模态能力方面进行了优化,支持包括图像、文本到文本的转换在内的多种功能,适用于需要处理视觉和语言信息的复杂任务。
TRELLIS是一个基于统一结构化潜在表示和修正流变换器的原生3D生成模型,能够实现多样化和高质量的3D资产创建。该模型通过整合稀疏的3D网格和从强大的视觉基础模型提取的密集多视图视觉特征,全面捕获结构(几何)和纹理(外观)信息,同时在解码过程中保持灵活性。TRELLIS模型能够处理高达20亿参数,并在包含50万个多样化对象的大型3D资产数据集上进行训练。该模型在文本或图像条件下生成高质量结果,显著超越现有方法,包括规模相似的最近方法。TRELLIS还展示了灵活的输出格式选择和局部3D编辑能力,这些是以前模型所没有提供的。代码、模型和数据将被发布。
ChatGPT Pro是OpenAI推出的一款月费200美元的产品,它提供了对OpenAI最先进模型和工具的规模化访问权限。该计划包括对OpenAI o1模型的无限访问,以及o1-mini、GPT-4o和高级语音功能。o1 pro模式是o1的一个版本,它使用更多的计算资源来更深入地思考并提供更好的答案,尤其是在解决最困难的问题时。ChatGPT Pro旨在帮助研究人员、工程师和其他日常使用研究级智能的个体提高生产力,并保持在人工智能进步的前沿。
GitHub Copilot是一个由GitHub提供的AI驱动的代码补全工具,它通过机器学习技术帮助开发者在编写代码时提供智能的代码建议。该工具集成在Visual Studio Code等IDE中,能够理解代码上下文并提供整行甚至整个函数的代码补全。现在GitHub Copilot也上线了Web版。GitHub Copilot的开发背景基于大量开源代码的训练,使其能够提供高质量的代码建议,提高开发效率和代码质量。它支持多种编程语言,并且可以根据开发者的编码习惯进行个性化调整。GitHub Copilot的价格定位是为专业开发者提供付费服务,同时也提供了免费试用的机会。
PaliGemma 2是Gemma家族中的第二代视觉语言模型,它在性能上进行了扩展,增加了视觉能力,使得模型能够看到、理解和与视觉输入交互,开启了新的可能性。PaliGemma 2基于高性能的Gemma 2模型构建,提供了多种模型尺寸(3B、10B、28B参数)和分辨率(224px、448px、896px)以优化任何任务的性能。此外,PaliGemma 2在化学公式识别、乐谱识别、空间推理和胸部X光报告生成等方面展现出领先的性能。PaliGemma 2旨在为现有PaliGemma用户提供便捷的升级路径,作为即插即用的替代品,大多数任务无需大幅修改代码即可获得性能提升。
GraphCast是由Google DeepMind开发的深度学习模型,专注于全球中期天气预报。该模型通过先进的机器学习技术,能够预测天气变化,提高预报的准确性和速度。GraphCast模型在科学研究中发挥重要作用,有助于更好地理解和预测天气模式,对气象学、农业、航空等多个领域具有重要价值。
OLMo 2 1124 7B Preference Mixture 是一个大规模的文本数据集,由 Hugging Face 提供,包含366.7k个生成对。该数据集用于训练和微调自然语言处理模型,特别是在偏好学习和用户意图理解方面。它结合了多个来源的数据,包括SFT混合数据、WildChat数据以及DaringAnteater数据,覆盖了广泛的语言使用场景和用户交互模式。
Amazon Nova是亚马逊推出的新一代基础模型,能够处理文本、图像和视频提示,使客户能够使用Amazon Nova驱动的生成性AI应用程序理解视频、图表和文档,或生成视频和其他多媒体内容。Amazon Nova模型在亚马逊内部约有1000个生成性AI应用正在运行,旨在帮助内部和外部构建者应对挑战,并在延迟、成本效益、定制化、信息接地和代理能力方面取得有意义的进展。
OLMo-2-1124-7B-SFT是由艾伦人工智能研究所(AI2)发布的一个英文文本生成模型,它是OLMo 2 7B模型的监督微调版本,专门针对Tülu 3数据集进行了优化。Tülu 3数据集旨在提供多样化任务的顶尖性能,包括聊天、数学问题解答、GSM8K、IFEval等。该模型的主要优点包括强大的文本生成能力、多样性任务处理能力以及开源的代码和训练细节,使其成为研究和教育领域的有力工具。
HunyuanVideo是腾讯开源的一个系统性框架,用于训练大型视频生成模型。该框架通过采用数据策划、图像-视频联合模型训练和高效的基础设施等关键技术,成功训练了一个超过130亿参数的视频生成模型,是所有开源模型中最大的。HunyuanVideo在视觉质量、运动多样性、文本-视频对齐和生成稳定性方面表现出色,超越了包括Runway Gen-3、Luma 1.6在内的多个行业领先模型。通过开源代码和模型权重,HunyuanVideo旨在缩小闭源和开源视频生成模型之间的差距,推动视频生成生态系统的活跃发展。
OLMo-2-1124-7B-DPO是由Allen人工智能研究所开发的一个大型语言模型,经过特定的数据集进行监督式微调,并进一步进行了DPO训练。该模型旨在提供在多种任务上,包括聊天、数学问题解答、文本生成等的高性能表现。它是基于Transformers库构建的,支持PyTorch,并以Apache 2.0许可发布。
OLMo-2-1124-13B-DPO是经过监督微调和DPO训练的13B参数大型语言模型,主要针对英文,旨在提供在聊天、数学、GSM8K和IFEval等多种任务上的卓越性能。该模型是OLMo系列的一部分,旨在推动语言模型的科学研究。模型训练基于Dolma数据集,并公开代码、检查点、日志和训练细节。
ProactiveAgent是一个基于大型语言模型(LLM)的主动式代理项目,旨在构建一个能够预测用户需求并主动提供帮助的智能代理。该项目通过数据收集和生成管道、自动评估器和训练代理来实现这一目标。ProactiveAgent的主要优点包括环境感知、协助标注、动态数据生成和构建管道,其奖励模型在测试集上达到了0.918的F1分数,显示出良好的性能。该产品背景信息显示,它适用于编程、写作和日常生活场景,并且遵循Apache License 2.0协议。
OpenScholar是一个检索增强型语言模型(LM),旨在通过首先搜索文献中的相关论文,然后基于这些来源生成回答,来帮助科学家有效地导航和综合科学文献。该模型对于处理每年发表的数百万篇科学论文,以及帮助科学家找到他们需要的信息或跟上单一子领域最新发现具有重要意义。
ComfyUI Watermark Removal Workflow是一个专门设计用于去除图像水印的插件,它通过高效的算法帮助用户快速清除图片中的水印,恢复图片的原始美观。该插件由Exaflop Labs开发,结合了商业洞察和技术专长,旨在帮助企业实现具体的业务目标。产品背景信息显示,该团队由来自Google和Microsoft的软件工程师以及Intuit Credit Karma的产品经理组成,他们在机器学习系统方面拥有丰富的经验。产品的主要优点包括高效的水印去除能力、易用性以及对企业业务流程的优化。目前,该产品的具体价格和定位信息未在页面中提供。
DOLMino dataset mix for OLMo2 stage 2 annealing training是一个混合了多种高质数据的数据集,用于在OLMo2模型训练的第二阶段。这个数据集包含了网页页面、STEM论文、百科全书等多种类型的数据,旨在提升模型在文本生成任务中的表现。它的重要性在于为开发更智能、更准确的自然语言处理模型提供了丰富的训练资源。
OLMo-2-1124-13B-Instruct是由Allen AI研究所开发的一款大型语言模型,专注于文本生成和对话任务。该模型在多个任务上表现出色,包括数学问题解答、科学问题解答等。它是基于13B参数的版本,经过在特定数据集上的监督微调和强化学习训练,以提高其性能和安全性。作为一个开源模型,它允许研究人员和开发者探索和改进语言模型的科学。
OLMo-2-1124-7B-Instruct是由Allen人工智能研究所开发的一个大型语言模型,专注于对话生成任务。该模型在多种任务上进行了优化,包括数学问题解答、GSM8K、IFEval等,并在Tülu 3数据集上进行了监督微调。它是基于Transformers库构建的,可以用于研究和教育目的。该模型的主要优点包括高性能、多任务适应性和开源性,使其成为自然语言处理领域的一个重要工具。
Skywork-o1-Open-PRM-Qwen-2.5-7B是由昆仑科技Skywork团队开发的一系列模型,这些模型结合了o1风格的慢思考和推理能力。这个模型系列不仅在输出中展现出天生的思考、规划和反思能力,而且在标准基准测试中显示出推理技能的显著提升。它代表了AI能力的战略进步,将一个原本较弱的基础模型推向了推理任务的最新技术(SOTA)。
OLMo 2是由Ai2推出的最新全开放语言模型,包括7B和13B两种规模的模型,训练数据高达5T tokens。这些模型在性能上与同等规模的全开放模型相当或更优,并且在英语学术基准测试中与开放权重模型如Llama 3.1竞争。OLMo 2的开发注重模型训练的稳定性、阶段性训练干预、最先进的后训练方法和可操作的评估框架。这些技术的应用使得OLMo 2在多个任务上表现出色,特别是在知识回忆、常识、一般和数学推理方面。
SoraVids是一个基于Hugging Face平台的视频生成模型Sora的存档库。它包含了87个视频和83个对应的提示,这些视频和提示在OpenAI撤销API密钥前被公开展示。这些视频均为MIME类型video/mp4,帧率为30 FPS。SoraVids的背景是OpenAI的视频生成技术,它允许用户通过文本提示生成视频内容。这个存档库的重要性在于它保存了在API密钥被撤销前生成的视频,为研究和教育提供了宝贵的资源。
ZipPy是一个研究性质的快速AI检测工具,它使用压缩比来间接测量文本的困惑度。ZipPy通过比较AI生成的语料库与提供的样本之间的相似性来进行分类。该工具的主要优点是速度快、可扩展性强,并且可以嵌入到其他系统中。ZipPy的背景信息显示,它是作为对现有大型语言模型检测系统的补充,这些系统通常使用大型模型来计算每个词的概率,而ZipPy提供了一种更快的近似方法。
ControlNets for Stable Diffusion 3.5 Large是Stability AI推出的三款图像控制模型,包括Blur、Canny和Depth。这些模型能够提供精确和便捷的图像生成控制,适用于从室内设计到角色创建等多种应用场景。它们在用户偏好的ELO比较研究中排名第一,显示出其在同类模型中的优越性。这些模型在Stability AI社区许可下免费提供给商业和非商业用途,对于年收入不超过100万美元的组织和个人,使用完全免费,并且产出的媒体所有权归用户所有。
Random Animal Generator是一个利用先进人工智能技术的网站,用户可以在短时间内生成高质量、独特的动物图像。这项技术的重要性在于它能够快速满足用户对动物图像的需求,无论是用于娱乐、教育还是设计灵感。产品背景信息显示,该网站由专业的机器学习算法支持,能够提供即时的结果和多样化的动物种类及风格选择。价格方面,网站提供了不同层次的服务选项,以满足不同用户的需求。