找到 551 个相关的AI工具
ColorArt.AI是一款免费的AI着色页生成器,可将照片、图片和图像转换为详细的可打印着色页,为所有年龄段用户提供乐趣和创意空间。产品背景信息包括创始团队和其使命,价格设置灵活,适用于家庭娱乐和商业需求。
MixHub AI集成了各种先进的AI模型,提供AI聊天、图像处理和视频生成功能。其主要优点在于准确性高、功能全面,价格实惠,适合个人和企业用户使用。
Seedream 4.0结合了先进的AI技术与直观的设计理念,通过数百万个创意模式学习,快速将您的想法转化为专业视觉作品。节省设计成本,提高工作效率。
AI Nano Banana是一款创新的AI图像生成和编辑平台,利用先进的人工智能技术从简单的文本描述中创建、编辑和转换图像。它采用最先进的机器学习技术,实现即时智能视觉内容创建。
AI背景去除器利用先进的人工智能技术,能够智能识别图片中的背景并进行去除,节省用户大量时间。该产品背景信息丰富,价格实惠,定位于个人和企业用户。
Nano Banana AI是一款强大的人工智能图像生成器,利用先进的AI技术轻松生成高质量图像。它为用户提供定制化的个性化图像生成服务,可用于各种创意项目和需求。
Nano Banana是一款利用AI技术进行专业照片编辑的平台。其强大的AI图像编辑功能可以帮助用户快速实现精准且创意十足的照片转换,适用于摄影师、设计师、内容创作者等。
AI Vector是一个基于人工智能的在线转换器,能够快速将PNG图片转换为高质量、可编辑的SVG矢量图。其主要优点包括快速高效、高质量转换、免费使用以及无需注册。AI Vector定位于为用户提供简单、快速且高质量的PNG到SVG转换服务。
Facy.ai是一款AI驱动的图像处理平台,提供人脸交换、图像提升、背景去除等功能。其主要优点包括智能算法、简单易用、多功能性,定位于满足用户对图像处理的多样需求。
AI像素艺术转换器利用先进的人工智能技术将图像转换为像素艺术,支持64色调色板,可导出PNG/JSON/CSV格式。该产品提供专业模板,广泛应用于社交媒体营销、产品推广等领域。
ImgEnhancer.ai 是一款使用先进的 AI 技术的图像增强平台,可实现超高分辨率图像放大,提供专业级图像增强工具。该产品的主要优点包括高质量的图像增强效果、方便使用的界面和针对不同用户需求的多种价格定位。
Qwen Image AI是一款革命性的20B MMDiT多模态扩散变换器模型,彻底改变了文本到图像生成,具有出色的文本渲染能力。它是第一个成功处理复杂多行文本布局和段落级内容的模型,无论是英文还是中文。建立在先进的扩散技术上,Qwen Image AI在多个基准测试中表现卓越,特别擅长于文本渲染准确性,在这方面其他模型难以匹敌。
TryScribe是一个提供AI动力工具的平台,旨在简化日常工作、自动化重复任务,并帮助用户专注于重要事项。产品背景信息、价格定位透明,支持用户快速上手。
ToMoviee AI是一款利用人工智能技术快速生成视频、图像、音乐和声音的创意工作室。其主要优点包括高度可控制性、快速生成、真实感强,广泛适用于不同领域的创作者和团队。
ImagePromptGuru是一个免费的AI艺术提示生成器,利用先进的技术将图像或文本转换为高质量的AI艺术提示。其主要优点包括免费、无限制使用、支持多种语言和流行风格,适用于个人项目、商业用途和AI艺术创作。
RoboNeo 是一款专注于影像和设计的 AI 助手,旨在帮助用户轻松修图、设计和制作视频。它使用先进的图像处理技术,使用户能够快速实现创意想法。该产品定位于追求高效创意工作的个人及团队,适用于社交媒体内容创作、市场营销和个人项目。RoboNeo 提供的多种功能和便捷的操作方式,使其成为当今数字创作的理想工具,现阶段提供免费下载使用。
OpenDream AI是一个在线AI艺术生成平台,利用先进的AI模型将文本提示转换为图像。它于2023年推出,旨在让图形设计民主化,并使视觉内容创作对每个人都更易达。无需艺术技能,只需描述想要看到的内容,让OpenDream的AI为您创造出来。
MediaAI的平台利用先进的图像技术,即时将您的自拍照片转换为动漫绘画或时尚视频艺术。该产品的主要优点是其高质量的转换效果和能够保留原始照片的本质。MediaAI定位为一款专注于图像艺术生成的AI工具,提供多种艺术风格转换选项。
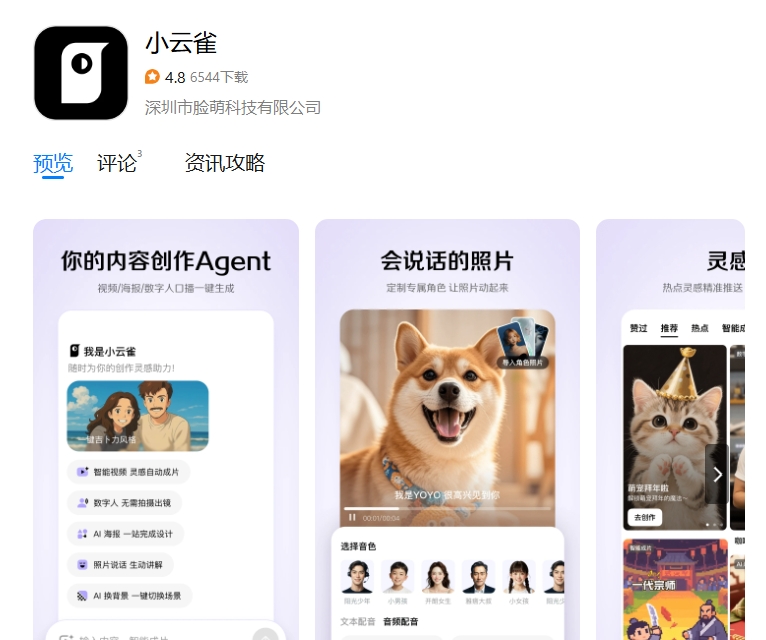
小云雀是由剪映出品的一款 AI 视频和图片创作助手,旨在帮助用户以简单的指令高效创作视频和图像。它为不同场景提供多样化的数字人形象,适合各类内容创作者。该应用的核心功能包括智能生成短视频、数字人讲解和图片设计,极大地降低了内容创作的门槛。小云雀的使用不需要专业的剪辑技能或设计背景,适合新手和专业人士使用,助力他们更好地实现创意表达。
Pixfy AI 是一款革命性的 AI 图像编辑器,采用对话式编辑方式,让照片编辑变得简单易用。其主要优点在于高质量、专业结果,适用于电子商务、社交媒体和个人使用。Pixfy AI 定位于提供简单而强大的照片编辑工具。
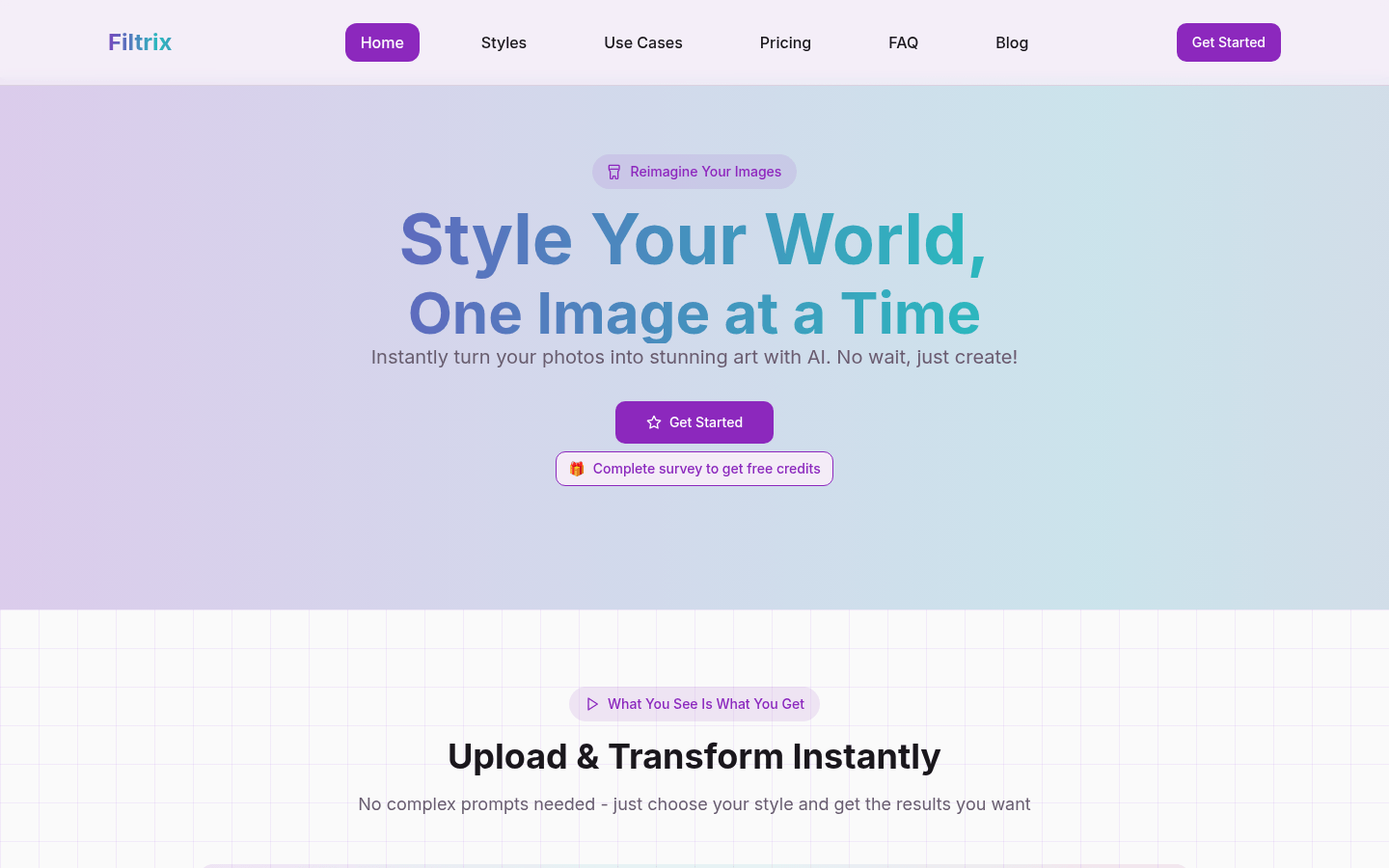
Filtrix AI是一款专注于图像转换的AI工具,提供特殊的风格转换和优化功能,适用于个人项目、产品摄影和营销活动。通过即时转换和专业增强功能,让用户无需复杂操作即可获得惊人的效果。
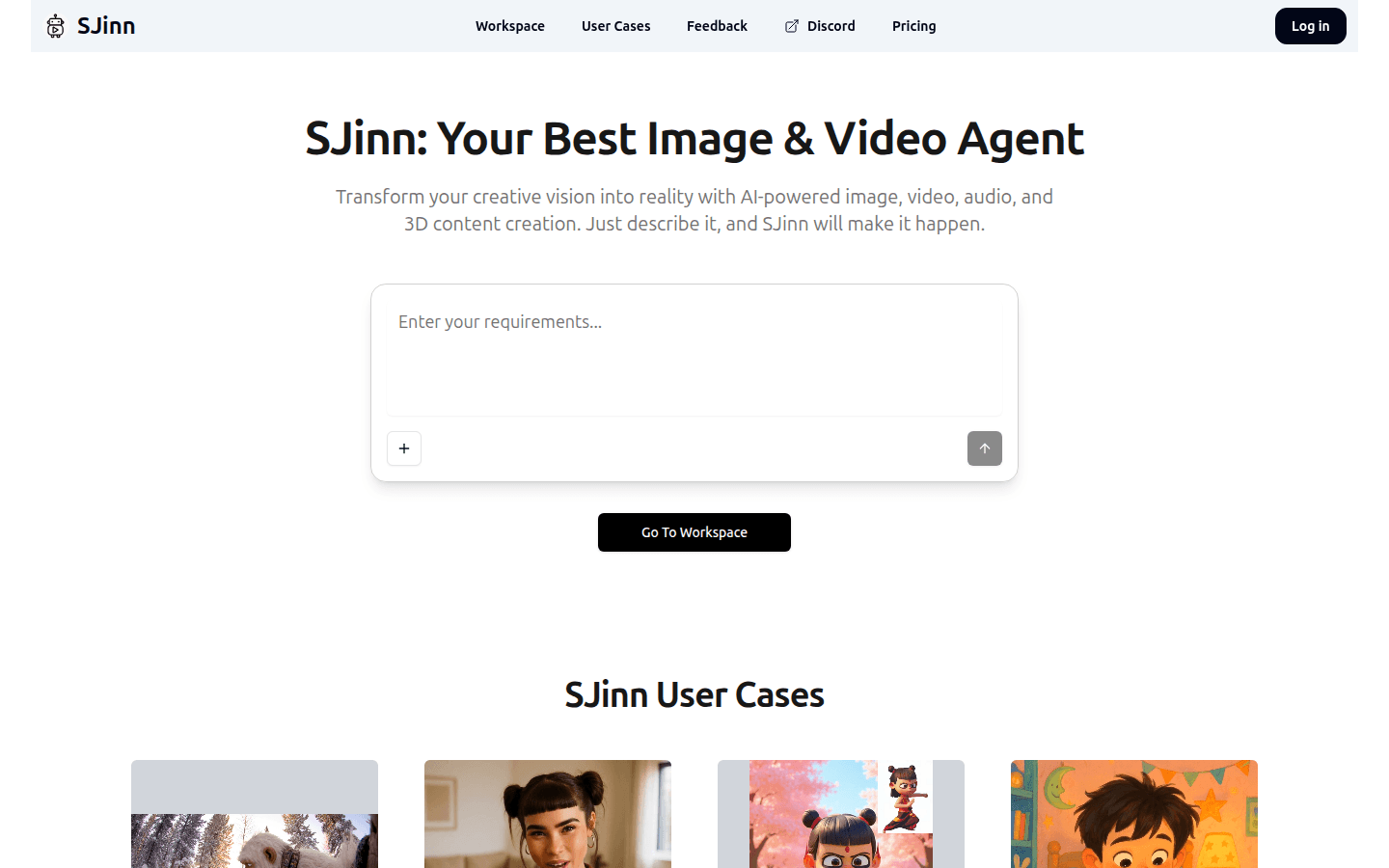
SJinn是一款具有突破性的专业AI智能代理,用于图像、视频、音频和3D内容创作。用户只需描述他们的创意,SJinn就能将复杂的视觉和听觉概念栩栩如生地展现出来。
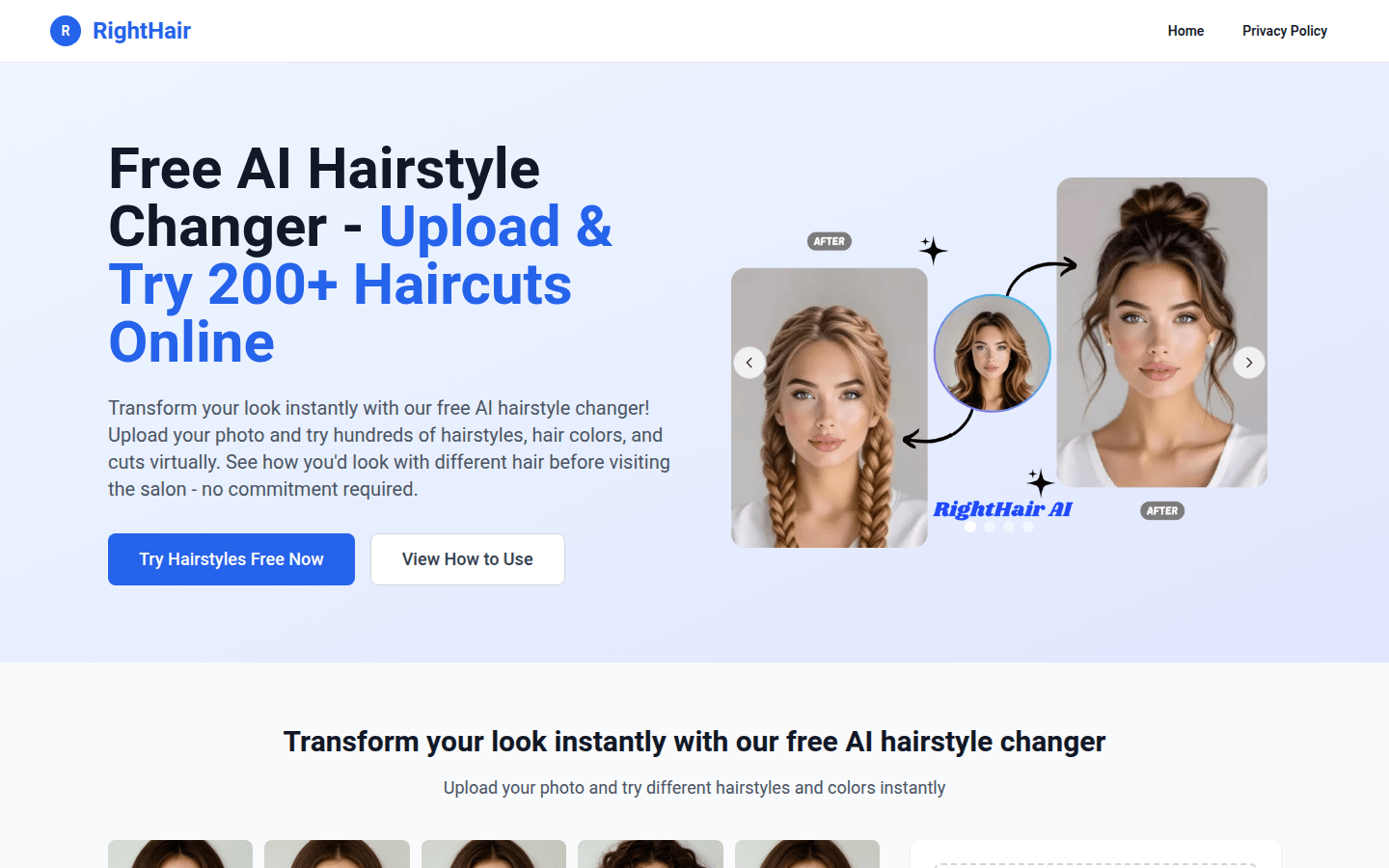
RightHair是一款基于AI技术的发型变化器,用户可以通过上传照片,在线尝试不同发型、颜色和发型剪裁,无需实际剪发。其主要优点包括快速准确的发型变化、隐私保护、方便多平台使用等。RightHair定位为帮助用户在改变发型前做出明智选择的虚拟发型试验工具。
AI图片放大增强器利用人工智能技术,可快速放大和提升照片质量,无需登录账户即可使用。其主要优点在于能够智能分析并提高图像的分辨率,使图像更清晰更生动。
Magic Eraser是一款图像处理工具,可轻松删除照片中的人物、表情符号、文字、标志等不需要的对象。其主要优点包括快速、免费、无需注册,可帮助用户将照片恢复至完美状态。
Unwatermark AI是一款先进的基于AI技术的去水印工具,可快速去除图像和视频中的水印。其主要优点包括自动检测和定位水印、高质量保证、快速速度、支持多终端使用等。产品定位于提供免费的去水印服务。
AI Ease 视频水印移除工具采用AI技术,能够精准快速地擦除视频中的水印、标志和文字,为用户提供清晰高清的视频输出。产品定位于为用户提供便捷、高效的视频水印去除服务。
P20V是一个免费的AI平台,可以在几秒钟内转换图像和视频,无需登录。适用于营销、设计、建筑、时尚、游戏、电子商务等多个行业。用户可以创建专业级视觉内容并与创意社区分享。
Everlyn AI是世界领先的AI视频生成器和免费AI图片生成器,使用先进的AI技术将您的想法转化为令人惊叹的视觉效果。它具有颠覆性的性能指标,包括15秒快速生成速度、25倍降低成本、8倍更高效率。
Imgkits是一款提供AI图像和视频处理工具的在线平台,能够帮助用户快速编辑、修复和定制照片。其主要优点包括强大的AI功能、简单易用的界面、支持多种图片格式、批量处理高效率等。Imgkits定位为免费在线图像编辑工具,适用于个人和专业用户。
PxBee是一款基于AI技术的免费图像处理工具,提供背景移除、背景更换、分辨率增强等功能,帮助用户快速创建专业级图像。
AI 图像融合工具利用先进的 AI 技术,能够快速无缝地合并多张图片,生成高质量的视觉效果。该工具适合数字艺术家、营销人员和摄影师等专业人士使用。定价方面,提供多个套餐,包括免费和付费版本,以满足不同用户的需求。
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
ImagineArt AI工具是一款人工智能艺术生成工具,利用先进的AI技术,可以将文字描述转化为生动的图像作品。其主要优点包括快速生成图像、灵活性高、用户友好,定位于为用户提供创意灵感和图像生成解决方案。
RetextureAI利用AI技术实现图像处理,能够快速为图片增添纹理,实现视觉上的瞬间变换。其主要优点在于提供先进的纹理生成功能,让用户轻松实现图片的艺术化处理。
Photogen by AI是一个通过AI快速生成高质量照片的平台,用户可上传自拍照片并使用AI模型转化为专业级肖像。价格分为Hobby、Pro和Enterprise三个档次。
InstantCharacter 是一个基于扩散变换器的角色个性化框架,旨在克服现有学习基础自定义方法的局限性。该框架的主要优点在于开放域个性化、高保真结果以及有效的角色特征处理能力,适合各种角色外观、姿势和风格的生成。该框架利用一个包含千万级样本的大规模数据集进行训练,以实现角色一致性和文本可编辑性的同时优化。该技术为角色驱动的图像生成设定了新的基准。
InternVL3是由OpenGVLab开源发布的多模态大型语言模型(MLLM),具备卓越的多模态感知和推理能力。该模型系列包含从1B到78B共7个尺寸,能够同时处理文字、图片、视频等多种信息,展现出卓越的整体性能。InternVL3在工业图像分析、3D视觉感知等领域表现出色,其整体文本性能甚至优于Qwen2.5系列。该模型的开源为多模态应用开发提供了强大的支持,有助于推动多模态技术在更多领域的应用。
Pusa 通过帧级噪声控制引入视频扩散建模的创新方法,能够实现高质量的视频生成,适用于多种视频生成任务(文本到视频、图像到视频等)。该模型以其卓越的运动保真度和高效的训练过程,提供了一个开源的解决方案,方便用户进行视频生成任务。
HiPixel 是一款原生 macOS 应用程序,专为图像超分辨率处理而设计。它利用 Upscayl 的 AI 模型,提供高质量图像放大功能,且通过 GPU 加速实现快速处理,适合需要图像处理的设计师和摄影师。该产品在 macOS 平台上运行流畅,支持多种图像格式,并提供便捷的文件夹监控功能。HiPixel 的定位为高效的图像处理工具,旨在提高用户的工作效率。
MagicColor 是一个创新的多实例草图上色框架,旨在自动化传统的手动上色流程。传统的上色方法费时且容易出错,而 MagicColor 通过引入自我训练策略、实例引导器和边缘损失等技术设计,显著提升了上色效率和准确性。该产品能够在保持多个对象一致性的同时,自动将草图转化为生动的彩色图像。此技术不仅简化了艺术创作的流程,也为需要一致性和精确度的多实例图像生成提供了有效的解决方案,适用于动漫、游戏等多个领域。
StarVector 是一个先进的生成模型,旨在将图像和文本指令转化为高质量的可缩放矢量图形(SVG)代码。其主要优点在于能够处理复杂的 SVG 元素,并在各种图形风格和复杂性上表现出色。作为开放源代码资源,StarVector 推动了图形设计的创新和效率,适用于设计、插图和技术文档等多种应用场景。
Thera 是一种先进的超分辨率技术,能够在不同尺度下生成高质量图像。其主要优点在于内置物理观察模型,有效避免了混叠现象。该技术由 ETH Zurich 的研究团队开发,适用于图像增强和计算机视觉领域,尤其在遥感和摄影测量中具有广泛应用。
AI Watermark Remover 是一款基于人工智能技术的在线工具,专注于快速去除照片和视频中的水印。它利用先进的AI算法,能够精准识别并去除水印,无需复杂的编辑技能。该工具的主要优点是免费、高效且易于使用,适合需要快速清理图片和视频的用户。产品定位为简单易用的在线工具,旨在帮助用户快速恢复图片和视频的原始质量,同时保护用户隐私,不存储任何数据。
Picture AI 是一个基于人工智能的在线图像生成和编辑平台,它利用先进的AI技术帮助用户轻松创建和优化图像。该平台的主要优点是操作简单、功能多样且完全在线,无需下载或安装任何软件。它适用于各种用户,包括设计师、摄影师、普通用户等,能够满足从创意设计到日常图像处理的多种需求。目前该平台提供免费试用,用户可以根据自己的需求选择不同的功能和服务。
MIDI是一种创新的图像到3D场景生成技术,它利用多实例扩散模型,能够从单张图像中直接生成具有准确空间关系的多个3D实例。该技术的核心在于其多实例注意力机制,能够有效捕捉物体间的交互和空间一致性,无需复杂的多步骤处理。MIDI在图像到场景生成领域表现出色,适用于合成数据、真实场景数据以及由文本到图像扩散模型生成的风格化场景图像。其主要优点包括高效性、高保真度和强大的泛化能力。
HunyuanVideo-I2V 是腾讯开源的图像到视频生成模型,基于 HunyuanVideo 架构开发。该模型通过图像潜在拼接技术,将参考图像信息有效整合到视频生成过程中,支持高分辨率视频生成,并提供可定制的 LoRA 效果训练功能。该技术在视频创作领域具有重要意义,能够帮助创作者快速生成高质量的视频内容,提升创作效率。
UniTok是一种创新的视觉分词技术,旨在弥合视觉生成和理解之间的差距。它通过多码本量化技术,显著提升了离散分词器的表示能力,使其能够捕捉到更丰富的视觉细节和语义信息。这一技术突破了传统分词器在训练过程中的瓶颈,为视觉生成和理解任务提供了一种高效且统一的解决方案。UniTok在图像生成和理解任务中表现出色,例如在ImageNet上实现了显著的零样本准确率提升。该技术的主要优点包括高效性、灵活性以及对多模态任务的强大支持,为视觉生成和理解领域带来了新的可能性。
olmOCR-7B-0225-preview 是由 Allen Institute for AI 开发的先进文档识别模型,旨在通过高效的图像处理和文本生成技术,将文档图像快速转换为可编辑的纯文本。该模型基于 Qwen2-VL-7B-Instruct 微调,结合了强大的视觉和语言处理能力,适用于大规模文档处理任务。其主要优点包括高效处理能力、高精度文本识别以及灵活的提示生成方式。该模型适用于研究和教育用途,遵循 Apache 2.0 许可证,强调负责任的使用。
VisionAgent是一个强大的工具,它利用人工智能和大语言模型(LLM)来生成代码,帮助用户快速解决视觉任务。该工具的主要优点是能够自动将复杂的视觉任务转化为可执行的代码,极大地提高了开发效率。VisionAgent支持多种LLM提供商,用户可以根据自己的需求选择不同的模型。它适用于需要快速开发视觉应用的开发者和企业,能够帮助他们在短时间内实现功能强大的视觉解决方案。VisionAgent目前是免费的,旨在为用户提供高效、便捷的视觉任务处理能力。
Light-A-Video 是一种创新的视频重光照技术,旨在解决传统视频重光照中存在的光照不一致和闪烁问题。该技术通过 Consistent Light Attention(CLA)模块和 Progressive Light Fusion(PLF)策略,增强了视频帧之间的光照一致性,同时保持了高质量的图像效果。该技术无需额外训练,可以直接应用于现有的视频内容,具有高效性和实用性。它适用于视频编辑、影视制作等领域,能够显著提升视频的视觉效果。
该产品利用人工智能技术,能够快速将用户上传的普通照片转化为专业风格的头像。其主要优点在于操作简便、生成速度快且效果出色。用户无需专业摄影设备或设计技能,即可获得适用于商务、社交媒体等场景的高质量头像。产品定位为免费在线工具,旨在满足用户快速获取专业头像的需求。
Animate Anyone 2 是一种基于扩散模型的角色图像动画技术,能够生成与环境高度适配的动画。它通过提取环境表示作为条件输入,解决了传统方法中角色与环境缺乏合理关联的问题。该技术的主要优点包括高保真度、环境适配性强以及动态动作处理能力出色。它适用于需要高质量动画生成的场景,如影视制作、游戏开发等领域,能够帮助创作者快速生成具有环境交互的角色动画,节省时间和成本。
VisoMaster是一款专注于视频替换和编辑的桌面客户端软件。它利用先进的AI技术,能够在图像和视频中实现高质量的替换,效果自然逼真。该软件操作简单,支持多种输入输出格式,并通过GPU加速提高处理效率。VisoMaster的主要优点是易于使用、高效处理以及高度定制化,适合视频创作者、影视后期制作人员以及对视频编辑有需求的普通用户。软件目前免费提供给用户,旨在帮助用户快速生成高质量的视频内容。
Genime AI 是一个面向动画创作者的工具平台,通过先进的 AI 技术,为用户提供图像到 3D 模型转换、补间动画生成等功能。其主要优点是能够帮助用户快速生成高质量的动画内容,降低动画制作门槛,提高创作效率。该产品适合动画设计师、视频创作者以及相关领域的专业人士,尤其适合那些希望借助 AI 技术提升创作能力的用户。目前产品处于发展阶段,具体价格和定位尚未明确。
MatAnyone 是一种先进的视频抠像技术,专注于通过一致的记忆传播实现稳定的视频抠像。它通过区域自适应记忆融合模块,结合目标指定的分割图,能够在复杂背景中保持语义稳定性和细节完整性。该技术的重要性在于它能够为视频编辑、特效制作和内容创作提供高质量的抠像解决方案,尤其适用于需要精确抠像的场景。MatAnyone 的主要优点是其在核心区域的语义稳定性和边界细节的精细处理能力。它由南洋理工大学和商汤科技的研究团队开发,旨在解决传统抠像方法在复杂背景下的不足。
leapfusion-hunyuan-image2video 是一种基于 Hunyuan 模型的图像到视频生成技术。它通过先进的深度学习算法,将静态图像转换为动态视频,为内容创作者提供了一种全新的创作方式。该技术的主要优点包括高效的内容生成、灵活的定制化能力以及对高质量视频输出的支持。它适用于需要快速生成视频内容的场景,如广告制作、视频特效等领域。该模型目前以开源形式发布,供开发者和研究人员免费使用,未来有望通过社区贡献进一步提升其性能。
SmolVLM-256M 是由 Hugging Face 开发的多模态模型,基于 Idefics3 架构,专为高效处理图像和文本输入而设计。它能够回答关于图像的问题、描述视觉内容或转录文本,且仅需不到 1GB 的 GPU 内存即可运行推理。该模型在多模态任务上表现出色,同时保持轻量化架构,适合在设备端应用。其训练数据来自 The Cauldron 和 Docmatix 数据集,涵盖文档理解、图像描述等多领域内容,使其具备广泛的应用潜力。目前该模型在 Hugging Face 平台上免费提供,旨在为开发者和研究人员提供强大的多模态处理能力。
美间AI无损放大是美间美盒推出的一项图像处理技术,利用先进的人工智能算法,能够将低分辨率图片无损放大至高分辨率,同时保持图像的清晰度和细节。该技术对于需要对图片进行放大处理的用户来说非常实用,能够满足在不降低图像质量的前提下,实现图片的尺寸放大需求。美间美盒作为一家专业的创意设计平台,致力于为用户提供高效、便捷的图像处理工具,帮助用户提升设计效率和作品质量。AI无损放大功能在图像处理领域具有重要意义,它弥补了传统放大方式容易导致图像模糊、失真的不足,为用户提供了更加优质、高效的图像放大解决方案。目前,该功能以网页形式提供服务,用户无需下载安装任何软件,只需通过浏览器访问即可使用,操作简单便捷。具体价格和定位等详细信息暂未明确,但其在图像处理领域的应用前景广阔,有望成为设计师、摄影师等专业人士以及普通用户提升图像质量的得力助手。
MangaNinja 是一种参考引导的线稿上色方法,它通过独特的设计确保精确的人物细节转录,包括用于促进参考彩色图像和目标线稿之间对应学习的块洗牌模块,以及用于实现细粒度颜色匹配的点驱动控制方案。该模型在自收集的基准测试中表现出色,超越了当前解决方案的精确上色能力。此外,其交互式点控制在处理复杂情况(如极端姿势和阴影)、跨角色上色、多参考协调等方面展现出巨大潜力,这些是现有算法难以实现的。MangaNinja 由来自香港大学、香港科技大学、通义实验室和蚂蚁集团的研究人员共同开发,相关论文已发表在 arXiv 上,代码也已开源。
该产品利用Google Gemini 2.0技术,实现高精度的文字识别,支持多国语言和手写字体识别。其主要优点包括高精度识别、多语言支持、优雅的渐变动画效果以及响应式设计。产品适用于需要进行文字识别的各类用户,如学生、研究人员、办公人员等。目前该产品是免费的,旨在为用户提供高效的文字识别解决方案。
Shapen是一款创新的在线工具,它利用先进的图像处理和3D建模技术,将2D图像转化为详细的3D模型。这一技术对于设计师、艺术家和创意工作者来说是一个巨大的突破,因为它极大地简化了3D模型的创建过程,降低了3D建模的门槛。用户无需深厚的3D建模知识,只需上传图片,即可快速生成可用于渲染、动画制作或3D打印的模型。Shapen的出现,为创意表达和产品设计带来了全新的可能性,其定价策略和市场定位也使其成为个人创作者和小型工作室的理想选择。
美图云修是美图公司推出的专业级AI人像精修软件。它基于美图自研AI算法大模型,为商业摄影行业提供真实、自然、干净、通透的人像精修效果。该产品历经数亿用户验证,兼具稳定性与实用性,能够帮助用户快速打造大师级质感人像,提升修图效率。美图云修不仅适用于专业摄影师和修图师,也适合摄影爱好者和普通用户。它提供多种套餐价格,满足不同用户的需求。
StructLDM是一个结构化潜在扩散模型,用于从2D图像学习3D人体生成。它能够生成多样化的视角一致的人体,并支持不同级别的可控生成和编辑,如组合生成和局部服装编辑等。该模型在无需服装类型或掩码条件的情况下,实现了服装无关的生成和编辑。项目由南洋理工大学S-Lab的Tao Hu、Fangzhou Hong和Ziwei Liu提出,相关论文发表于ECCV 2024。
FitDiT 旨在解决图像基础虚拟试衣中高保真度和鲁棒性不足的问题,通过引入服装纹理提取器和频域学习,以及采用扩张松弛掩码策略,显著提升了虚拟试衣的贴合度和细节表现,其主要优点是能够生成逼真且细节丰富的服装图像,适用于多种场景,具有较高的实用价值和竞争力,目前尚未明确具体价格和市场定位。
Hallo3是一种用于肖像图像动画的技术,它利用预训练的基于变换器的视频生成模型,能够生成高度动态和逼真的视频,有效解决了非正面视角、动态对象渲染和沉浸式背景生成等挑战。该技术由复旦大学和百度公司的研究人员共同开发,具有强大的泛化能力,为肖像动画领域带来了新的突破。
InternVL2.5-MPO是一个先进的多模态大型语言模型系列,基于InternVL2.5和混合偏好优化(MPO)构建。该系列模型在多模态任务中表现出色,能够处理图像、文本和视频数据,并生成高质量的文本响应。模型采用'ViT-MLP-LLM'范式,通过像素unshuffle操作和动态分辨率策略优化视觉处理能力。此外,模型还引入了多图像和视频数据的支持,进一步扩展了其应用场景。InternVL2.5-MPO在多模态能力评估中超越了多个基准模型,证明了其在多模态领域的领先地位。
STAR是一种创新的视频超分辨率技术,通过将文本到视频扩散模型与视频超分辨率相结合,解决了传统GAN方法中存在的过度平滑问题。该技术不仅能够恢复视频的细节,还能保持视频的时空一致性,适用于各种真实世界的视频场景。STAR由南京大学、字节跳动等机构联合开发,具有较高的学术价值和应用前景。
InternVL2_5-26B-MPO-AWQ 是由 OpenGVLab 开发的多模态大型语言模型,旨在通过混合偏好优化提升模型的推理能力。该模型在多模态任务中表现出色,能够处理图像和文本之间的复杂关系。它采用了先进的模型架构和优化技术,使其在多模态数据处理方面具有显著优势。该模型适用于需要高效处理和理解多模态数据的场景,如图像描述生成、多模态问答等。其主要优点包括强大的推理能力和高效的模型架构。
SHMT是一种自监督的层次化化妆迁移技术,通过潜在扩散模型实现。该技术能够在不需要显式标注的情况下,将一种面部妆容自然地迁移到另一种面部上。其主要优点在于能够处理复杂的面部特征和表情变化,提供高质量的迁移效果。该技术在NeurIPS 2024上被接受,展示了其在图像处理领域的创新性和实用性。
百度AI搜是一个基于人工智能技术的智能搜索平台,它集成了搜索、智能创作、图像处理等多种功能,旨在提升用户的工作效率和创造力。该平台利用百度的AI技术,为用户提供便捷的服务,适用于办公、学习、设计等多种场景。产品背景依托于百度强大的搜索引擎和AI技术,定位于为用户提供全面的智能搜索解决方案,部分功能提供免费试用,其他功能可能需要付费。
InternVL2.5-MPO是一个先进的多模态大型语言模型系列,它基于InternVL2.5和混合偏好优化构建。该模型整合了新增量预训练的InternViT与各种预训练的大型语言模型,包括InternLM 2.5和Qwen 2.5,使用随机初始化的MLP投影器。InternVL2.5-MPO在新版本中保留了与InternVL 2.5及其前身相同的模型架构,遵循“ViT-MLP-LLM”范式。该模型支持多图像和视频数据,通过混合偏好优化(MPO)进一步提升模型性能,使其在多模态任务中表现更优。
TRELLIS 3D AI是一款利用人工智能技术将图片转换成3D资产的专业工具。它通过结合先进的神经网络和结构化潜在技术(Structured LATents, SLAT),能够保持输入图片的结构完整性和视觉细节,生成高质量的3D资产。产品背景信息显示,TRELLIS 3D AI被全球专业人士信赖,用于可靠的图像到3D资产的转换。与传统的3D建模工具不同,TRELLIS 3D AI提供了一个无需复杂操作的图像到3D资产的转换过程。产品价格为免费,适合需要快速、高效生成3D资产的用户。
Transmonkey的Comic Translator是一款利用人工智能技术进行漫画翻译的在线工具。它结合了强大的大型语言模型和尖端设计,提供准确、自然的翻译,同时保持原作的艺术美感。这款工具的主要优点包括精确的语言模型翻译、视觉真实性的保持、批量翻译的便捷性、浏览器的无缝集成、长漫画页面的优化处理以及即时翻译结果。产品背景信息显示,Transmonkey致力于通过AI技术打破全球沟通障碍,支持超过130种语言的翻译服务。价格方面,提供免费试用信用额度,用户可以在网页上翻译10张图片,更多信用需订阅高级服务。
EdgeOne Pages Functions:AI OCR是一款基于人工智能技术的图像文字识别服务,它能够将图片中的文字内容转换为可编辑的文本格式。这项技术的重要性在于它极大地提高了文字录入的效率,减少了人工输入的错误率,并且能够处理多种语言的文字识别。产品背景信息显示,EdgeOne提供了一个免费的部署平台,拥有即时全球CDN覆盖,这使得AI OCR服务可以快速、稳定地服务于全球用户。价格方面,用户可以免费部署体验,具体定价策略未在页面中明确说明。
PNGFree.ai是一个提供数百万免费PNG图片的网站,同时提供高质量的免费PNG转换器和AI PNG工具。该网站为设计师、创意工作者和普通用户提供了一个丰富的资源库,帮助他们快速找到所需的透明背景图片,支持创意和设计工作。PNGFree.ai以其免费、高质量和便捷的服务在图像领域占有一席之地,用户无需担心版权问题,可以安心使用这些图片。
InternVL2.5-MPO是一个先进的多模态大型语言模型系列,基于InternVL2.5和混合偏好优化构建。该模型集成了新增量预训练的InternViT和各种预训练的大型语言模型,如InternLM 2.5和Qwen 2.5,使用随机初始化的MLP投影器。它支持多图像和视频数据,并且在多模态任务中表现出色,能够理解和生成与图像相关的文本内容。
Valley是由字节跳动开发的尖端多模态大型模型,能够处理涉及文本、图像和视频数据的多种任务。该模型在内部电子商务和短视频基准测试中取得了最佳结果,比其他开源模型表现更优。在OpenCompass测试中,与同规模模型相比,平均得分大于等于67.40,在小于10B模型中排名第二。Valley-Eagle版本参考了Eagle,引入了一个可以灵活调整令牌数量并与原始视觉令牌并行的视觉编码器,增强了模型在极端场景下的性能。
InternVL2_5-2B-MPO是一个多模态大型语言模型系列,展示了卓越的整体性能。该系列基于InternVL2.5和混合偏好优化构建。它集成了新增量预训练的InternViT与各种预训练的大型语言模型,包括InternLM 2.5和Qwen 2.5,使用随机初始化的MLP投影器。该模型在多模态任务中表现出色,能够处理包括图像和文本在内的多种数据类型,适用于需要理解和生成多模态内容的场景。
LuminaBrush是一个交互式工具,旨在绘制图像上的照明效果。该工具采用两阶段方法:一阶段将图像转换为“均匀照明”的外观,另一阶段根据用户涂鸦生成照明效果。这种分解方法简化了学习过程,避免了单一阶段可能需要考虑的外部约束(如光传输一致性等)。LuminaBrush利用从高质量野外图像中提取的“均匀照明”外观来构建训练最终交互式照明绘图模型的配对数据。此外,该工具还可以独立使用“均匀照明阶段”来“去照明”图像。
Procyon是由UL Solutions开发的一套性能测试基准工具,专为工业、企业、政府、零售和媒体的专业用户设计。Procyon套件中的每个基准测试都提供了一致且熟悉的体验,并共享一套共同的设计和功能。灵活的许可模式意味着用户可以根据自己的需求选择适合的单个基准测试。Procyon基准测试套件很快将提供一系列针对专业用户的基准测试和性能测试,每个基准测试都针对特定用例设计,并尽可能使用真实应用。UL Solutions与行业合作伙伴紧密合作,确保每个Procyon基准测试准确、相关且公正。
Whisk是Google实验室推出的一款图像创作工具,它利用先进的图像处理技术,让用户能够轻松地创作和编辑图像。Whisk的主要优点在于其强大的图像处理能力和用户友好的界面,它能够快速地将用户的想法转化为视觉作品。Whisk的背景信息显示,它是由Google的创新团队开发的,旨在推动图像创作技术的边界,为用户提供一个全新的创作平台。Whisk的价格定位尚未明确,但考虑到Google实验室的性质,它可能会提供免费试用或部分免费功能。
Speed AI Art Photo Editor是一款利用人工智能技术的照片编辑应用,它能够将普通照片转换成艺术风格的照片或者卡通化的头像。这款应用拥有丰富的人像细节设置,用户可以自由选择从发型到表情、身材、皮肤、光线等多种细节,快速创造出新的艺术照片或个性化卡通形象。产品背景信息显示,Speed AI拥有庞大的AI图像模型库和数千种照片素材模板,用户可以根据自己的需求输出不同版本的自己,或者创造一个全新的形象。产品的主要优点包括快速编辑、丰富的细节设置选项、艺术风格多样化以及高保真度的输出控制。
Poify是一个利用生成式AI技术,为用户提供独特工具套件的网站,帮助用户将创意传达给世界。它通过上传照片,让用户与AI共同创作,体验圣诞节的奇幻旅程,如与北极熊共舞、成为自己的圣诞老人等。Poify强调创意与技术的结合,为用户提供一个展示和分享创意的平台。
IC-Light V2-Vary是一款基于扩散模型的光照编辑工具,主要针对复杂光照场景中的图像生成和编辑问题,提供了光照一致性约束、大规模数据支持、精确光照编辑等功能。它通过物理光传输理论确保物体在不同光照条件下的表现可以线性组合,减少图像伪影,保持输出结果与实际物理光照条件一致。适用于摄影师、设计师及3D建模专业人士,同时为艺术创作者提供了更多可能性。
ComfyUI Watermark Removal Workflow是一个专门设计用于去除图像水印的插件,它通过高效的算法帮助用户快速清除图片中的水印,恢复图片的原始美观。该插件由Exaflop Labs开发,结合了商业洞察和技术专长,旨在帮助企业实现具体的业务目标。产品背景信息显示,该团队由来自Google和Microsoft的软件工程师以及Intuit Credit Karma的产品经理组成,他们在机器学习系统方面拥有丰富的经验。产品的主要优点包括高效的水印去除能力、易用性以及对企业业务流程的优化。目前,该产品的具体价格和定位信息未在页面中提供。
TryOffDiff是一种基于扩散模型的高保真服装重建技术,用于从穿着个体的单张照片中生成标准化的服装图像。这项技术与传统的虚拟试穿不同,它旨在提取规范的服装图像,这在捕捉服装形状、纹理和复杂图案方面提出了独特的挑战。TryOffDiff通过使用Stable Diffusion和基于SigLIP的视觉条件来确保高保真度和细节保留。该技术在VITON-HD数据集上的实验表明,其方法优于基于姿态转移和虚拟试穿的基线方法,并且需要较少的预处理和后处理步骤。TryOffDiff不仅能够提升电子商务产品图像的质量,还能推进生成模型的评估,并激发未来在高保真重建方面的工作。
Aiarty Image Matting是一款适用于AI PC的先进图像抠图软件,采用高级alpha抠图技术处理头发、毛发及透明物体,并实现前景与背景的无缝融合。该产品利用深度学习技术,通过320K HQ 4K图像训练数据集,提供4个AI模型用于智能抠图,3种算法用于边缘优化,以及4个手动调节工具和5种内置效果。它适用于电商和设计领域,能够批量替换产品图像背景,智能识别物体,一次性替换背景,处理最多3000张产品照片。产品背景信息显示,首发限免活动将于2024年12月2日结束,之后将转为付费软件。
该产品是一个用于Stable Diffusion的扩展,允许用户在WebUI中创建简单的漫画。它支持多种语言,提供直观的界面和丰富的功能,适合漫画创作者和设计师使用。该工具的主要优点包括易于使用的拖放界面、丰富的面板布局选择和图像处理功能,适合各种水平的用户。该产品是免费的,定位于为漫画创作者提供高效的工具。
ComfyUI_AdvancedRefluxControl是一个自定义节点工具,用于控制Redux模型中条件图像对最终图像的影响强度。Redux模型通常用于生成图像的多个变体,但不支持根据提示改变图像。此工具通过添加自定义节点,允许用户调整Redux效果的强度,支持非方形图像和带遮罩的条件图像,从而增强图像生成的灵活性和控制力。
AI Tattoo Removal是一个利用人工智能技术展示纹身去除效果的先进工具。它提供了多种可视化选项和用户友好的界面,适用于考虑纹身去除的个人和专业纹身去除专家。该平台使用尖端的机器学习算法分析并展示纹身去除进度,用户可以查看不同的去除阶段、结果和治疗方案,以更好地理解去除过程。产品的主要优点包括即时可视化、个性化体验和免费的基础功能,同时提供高级功能订阅服务。
face_anon_simple是一个人脸匿名化技术,旨在通过先进的算法在保护个人隐私的同时保留原始照片中的面部表情、头部姿势、眼神方向和背景元素。这项技术对于需要发布包含人脸的图片但又希望保护个人隐私的场合非常有用,比如在新闻报道、社交媒体和安全监控等领域。产品基于开源代码,允许用户自行部署和使用,具有很高的灵活性和应用价值。
Watermark Anything是一个由Facebook Research开发的图像水印技术,它允许在图片中嵌入一个或多个局部化水印信息。这项技术的重要性在于它能够在保证图像质量的同时,实现对图像内容的版权保护和追踪。该技术背景是基于深度学习和图像处理的研究,主要优点包括高鲁棒性、隐蔽性和灵活性。产品定位为研究和开发用途,目前是免费提供给学术界和开发者使用。
Fashion-VDM是一个视频扩散模型(VDM),用于生成虚拟试穿视频。该模型接受一件衣物图片和人物视频作为输入,旨在生成人物穿着给定衣物的高质量试穿视频,同时保留人物的身份和动作。与传统的基于图像的虚拟试穿相比,Fashion-VDM在衣物细节和时间一致性方面表现出色。该技术的主要优点包括:扩散式架构、分类器自由引导增强控制、单次64帧512px视频生成的渐进式时间训练策略,以及联合图像-视频训练的有效性。Fashion-VDM在视频虚拟试穿领域树立了新的行业标准。
ComfyUI-GIMM-VFI是一个基于GIMM-VFI算法的帧插值工具,使用户能够在图像和视频处理中实现高质量的帧插值效果。该技术通过在连续帧之间插入新的帧来提高视频的帧率,从而使得动作看起来更加流畅。这对于视频游戏、电影后期制作和其他需要高帧率视频的应用场景尤为重要。产品背景信息显示,它是基于Python开发的,并且依赖于CuPy库,特别适用于需要进行高性能计算的场景。
Face Sticker AI是一个AI驱动的面部贴纸工具,它通过添加文本提示将用户的面部图像转换成奇妙的面部贴纸图像。该产品利用先进的面部识别技术和自然语言处理技术,确保生成的贴纸与原始图像高度相似,同时保持高清图像质量。Face Sticker AI不仅支持真人照片,还支持动画角色照片,满足用户个性化表达和创造的需求。产品背景信息显示,Face Sticker AI旨在提供一个简单易用的平台,让用户能够以前所未有的方式探索和创造面部贴纸,释放创造力。产品定价分为Base、Standard和Pro三个等级,用户可以根据自己的需求选择合适的计划购买积分。
Claude Vision Object Detection是一个基于Python的工具,它利用Claude 3.5 Sonnet Vision API来检测图像中的物体并进行可视化。该工具能够自动在检测到的物体周围绘制边界框,对它们进行标记,并显示置信度分数。它支持处理单张图片或整个目录中的图片,并且具有高精度的置信度分数,为每个检测到的物体使用鲜艳且不同的颜色。此外,它还能保存带有检测结果的注释图片。
PromptFix是一个综合框架,能够使扩散模型遵循人类指令执行各种图像处理任务。该框架通过构建大规模的指令遵循数据集,提出了高频引导采样方法来控制去噪过程,并设计了辅助提示适配器,利用视觉语言模型增强文本提示,提高模型的任务泛化能力。PromptFix在多种图像处理任务中表现优于先前的方法,并在盲恢复和组合任务中展现出优越的零样本能力。
Excerptor是一个专门设计来从实体书籍中提取划线或手写标记文本的工具。它通过图像处理和光学字符识别技术,将书籍中的标记文本转换为数字格式,方便用户编辑和保存。这项技术的重要性在于它能够帮助用户快速从大量书籍中提取关键信息,提高研究和学习的效率。Excerptor以其高效、准确的文本识别能力和用户友好的操作界面,满足了学术研究、教育和个人学习等不同领域的需求。目前,Excerptor是免费提供给用户的,它的开发和维护由开源社区负责。
Flux.1 Lite是一个由Freepik发布的8B参数的文本到图像生成模型,它是从FLUX.1-dev模型中提取出来的。这个版本相较于原始模型减少了7GB的RAM使用,并提高了23%的运行速度,同时保持了与原始模型相同的精度(bfloat16)。该模型的发布旨在使高质量的AI模型更加易于获取,特别是对于消费级GPU用户。