找到 637 个相关的AI工具
Nano Banana 是一款利用谷歌 Gemini 2.5 Flash Image API 的先进 AI 图像生成与编辑平台。它通过自然语言命令轻松生成高质量图像,支持商业用途,提供专业的工作流程解决方案。定价灵活,适合个人、专业创作者和大型企业。
Nano Banana 是一款革命性的 AI 图像编辑工具,能够通过自然语言提示来快速且精准地编辑照片。其主要优势在于极高的一致性和出色的场景融合能力。与其他编辑工具相比,Nano Banana 能够在保留面部特征的同时,完美处理复杂的图像编辑任务。它非常适合社交媒体内容创造和商业项目,用户可以轻松创建符合要求的 AI 生成内容,且使用门槛低,操作简便。
Veo 4是一款AI视频生成平台,提供完整的视频生成套件,能够将文本和图片转化为高质量视频,具有多种功能,包括文本到视频生成、自然语言处理、高分辨率输出等。Veo 4通过AI技术革新了视频编辑和增强,带来高效的视频生成工作流。
Unshackled AI是一款基于人工智能技术的聊天产品,主要优点是提供准确的自然语言处理,有助于用户快速解决问题。产品定位为帮助用户高效沟通,不收取费用。
AI在线问答是一款基于自然语言处理的智能搜索引擎,可即时提供清晰准确的答案。其主要优点包括快速获得信息、支持多语言、保护用户隐私等。
DeepSeek R1-0528 是知名开源大模型平台 DeepSeek 发布的最新版本,具有高性能的自然语言处理和编程能力。它的发布引起了广泛关注,因其在编程任务中表现出色,能够准确回答复杂问题。该模型支持多种应用场景,是开发者和 AI 研究者的重要工具。预计后续将发布更详细的模型信息和使用指南,增强其功能和应用广度。
WorldPM-72B 是一个通过大规模训练获得的统一偏好建模模型,具有显著的通用性和较强的表现能力。该模型基于 15M 偏好数据,展示了在客观知识的偏好识别方面的巨大潜力。适合用于生成更高质量的文本内容,尤其在写作领域具有重要的应用价值。
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
Describe Anything 模型(DAM)能够处理图像或视频的特定区域,并生成详细描述。它的主要优点在于可以通过简单的标记(点、框、涂鸦或掩码)来生成高质量的本地化描述,极大地提升了计算机视觉领域的图像理解能力。该模型由 NVIDIA 和多所大学联合开发,适合用于研究、开发和实际应用中。
Search-R1 是一个强化学习框架,旨在训练能够进行推理和调用搜索引擎的语言模型(LLMs)。它基于 veRL 构建,支持多种强化学习方法和不同的 LLM 架构,使得在工具增强的推理研究和开发中具备高效性和可扩展性。
该模型通过强化学习和高质量推理轨迹的掩蔽自监督微调,实现了对扩散大语言模型的推理能力的提升。此技术的重要性在于它能够优化模型的推理过程,减少计算成本,同时保证学习动态的稳定性。适合希望在写作和推理任务中提升效率的用户。
GLM-4-32B 是一个高性能的生成语言模型,旨在处理多种自然语言任务。它通过深度学习技术训练而成,能够生成连贯的文本和回答复杂问题。该模型适用于学术研究、商业应用和开发者,价格合理,定位精准,是自然语言处理领域的领先产品。
Amazon Nova Sonic 是一款前沿的基础模型,能够整合语音理解和生成,提升人机对话的自然流畅度。该模型克服了传统语音应用中的复杂性,通过统一的架构实现更深层次的交流理解,适用于多个行业的 AI 应用,具有重要的商业价值。随着人工智能技术的不断发展,Nova Sonic 将为客户提供更好的语音交互体验,提升服务效率。
DeepSeek-V3-0324 是一个先进的文本生成模型,具有 685 亿参数,采用 BF16 和 F32 张量类型,能够支持高效的推理和文本生成。该模型的主要优点在于其强大的生成能力和开放源码的特性,使其可以被广泛应用于多种自然语言处理任务。该模型的定位是为开发者和研究人员提供一个强大的工具,帮助他们在文本生成领域取得突破。
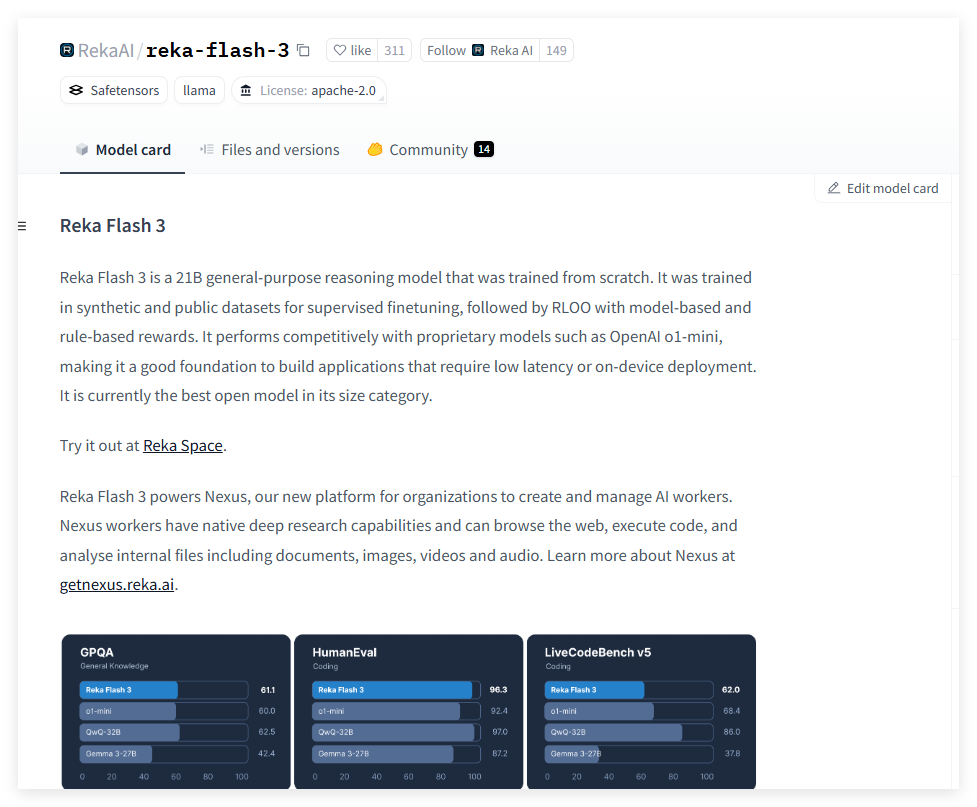
Reka Flash 3 是一款从零开始训练的 21 亿参数的通用推理模型,利用合成和公共数据集进行监督微调,结合基于模型和基于规则的奖励进行强化学习。该模型在低延迟和设备端部署应用中表现优异,具有较强的研究能力。它目前是同类开源模型中的最佳选择,适合于各种自然语言处理任务和应用场景。
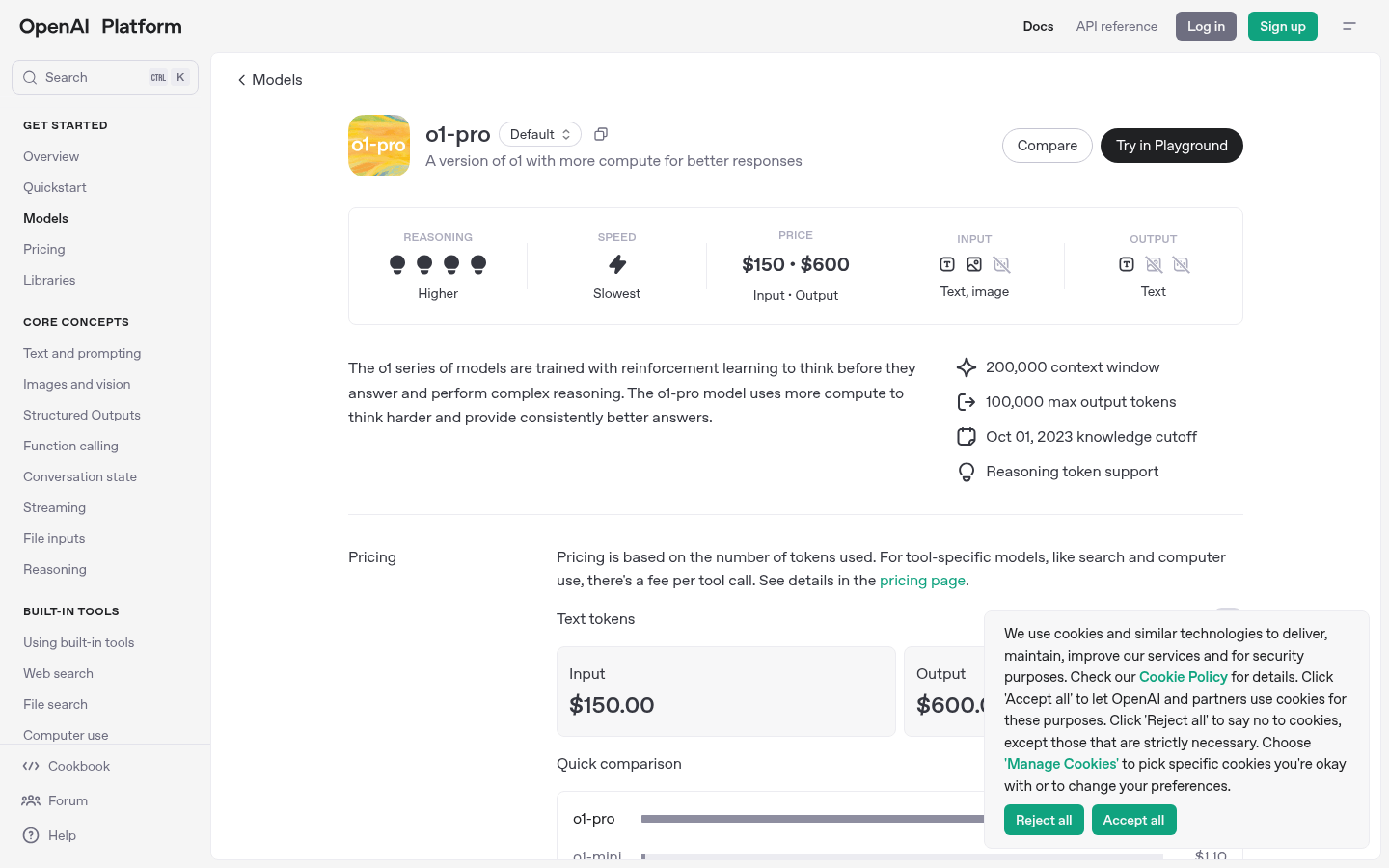
o1-pro 模型是一种先进的人工智能语言模型,专为提供高质量文本生成和复杂推理设计。其在推理和响应准确性上表现优越,适合需要高精度文本处理的应用场景。该模型的定价基于使用的 tokens,输入每百万 tokens 价格为 150 美元,输出每百万 tokens 价格为 600 美元,适合企业和开发者在其应用中集成高效的文本生成能力。
Light-R1-14B-DS 是由北京奇虎科技有限公司开发的开源数学模型。该模型基于 DeepSeek-R1-Distill-Qwen-14B 进行强化学习训练,在 AIME24 和 AIME25 数学竞赛基准测试中分别达到了 74.0 和 60.2 的高分,超越了许多 32B 参数量的模型。它在轻量级预算下成功实现了对已经长链推理微调模型的强化学习尝试,为开源社区提供了一个强大的数学模型工具。该模型的开源有助于推动自然语言处理在教育领域的应用,特别是数学问题解决方面,为研究人员和开发者提供了宝贵的研究基础和实践工具。
理想同学是一款由北京车励行信息技术有限公司开发的智能聊天助手。它通过人工智能技术实现自然语言处理,能够与用户进行流畅的对话交互。该产品的主要优点是操作简单、响应迅速,能够为用户提供个性化的服务。它适用于多种场景,如日常聊天、信息查询等。产品目前没有明确的价格信息,但根据其功能定位,可能主要面向个人用户和企业客户。
Sesame AI 代表了下一代语音合成技术,通过结合先进的人工智能技术和自然语言处理,能够生成极其逼真的语音,具备真实的情感表达和自然的对话流程。该平台在生成类似人类的语音模式方面表现出色,同时能够保持一致的性格特征,非常适合内容创作者、开发者和企业,用于为其应用程序增添自然语音功能。目前尚不清楚其具体价格和市场定位,但其强大的功能和广泛的应用场景使其在市场上具有较高的竞争力。
BashBuddy 是一款旨在通过自然语言交互简化命令行操作的工具。它能够理解上下文并生成精确的命令,支持多种操作系统和 Shell 环境。BashBuddy 的主要优点在于其自然语言处理能力、跨平台支持以及对隐私的重视。它适合开发者、系统管理员以及任何需要频繁使用命令行的用户。BashBuddy 提供本地部署和云服务两种模式,本地模式完全免费且数据完全私密,而云服务则提供更快的命令生成速度,每月收费 2 美元。
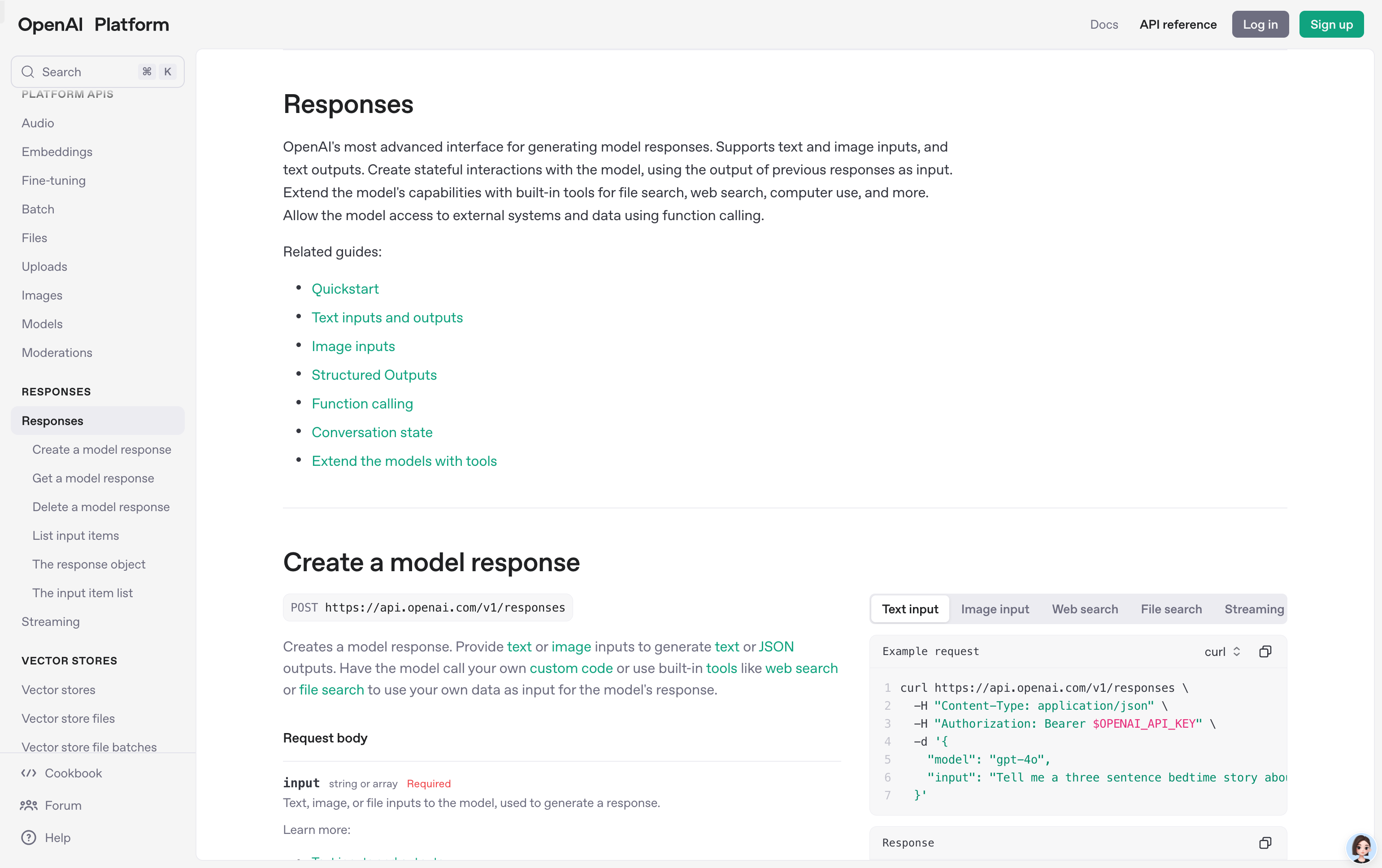
OpenAI API 的 Responses 功能允许用户创建、获取、更新和删除模型的响应。它为开发者提供了强大的工具,用于管理模型的输出和行为。通过 Responses,用户可以更好地控制模型的生成内容,优化模型的性能,并通过存储和检索响应来提高开发效率。该功能支持多种模型,适用于需要高度定制化模型输出的场景,如聊天机器人、内容生成和数据分析等。OpenAI API 提供灵活的定价方案,适合从个人开发者到大型企业的需求。
OpenAI 的内置工具是 OpenAI 平台中用于增强模型能力的功能集合。这些工具允许模型在生成响应时访问网络或文件中的额外上下文和信息。例如,通过启用网络搜索工具,模型可以使用网络上的最新信息来生成响应。这些工具的主要优点是能够扩展模型的能力,使其能够处理更复杂的任务和需求。OpenAI 平台提供了多种工具,如网络搜索、文件搜索、计算机使用和函数调用等。这些工具的使用取决于提供的提示,模型会根据提示自动决定是否使用配置的工具。此外,用户还可以通过设置工具选择参数来明确控制或指导模型的行为。这些工具对于需要实时数据或特定文件内容的场景非常有用,能够提高模型的实用性和灵活性。
Awesome-LLM-Post-training 是一个专注于大型语言模型(LLM)后训练方法的资源库。它提供了关于 LLM 后训练的深入研究,包括教程、调查和指南。该资源库基于论文《LLM Post-Training: A Deep Dive into Reasoning Large Language Models》,旨在帮助研究人员和开发者更好地理解和应用 LLM 后训练技术。该资源库免费开放,适合学术研究和工业应用。
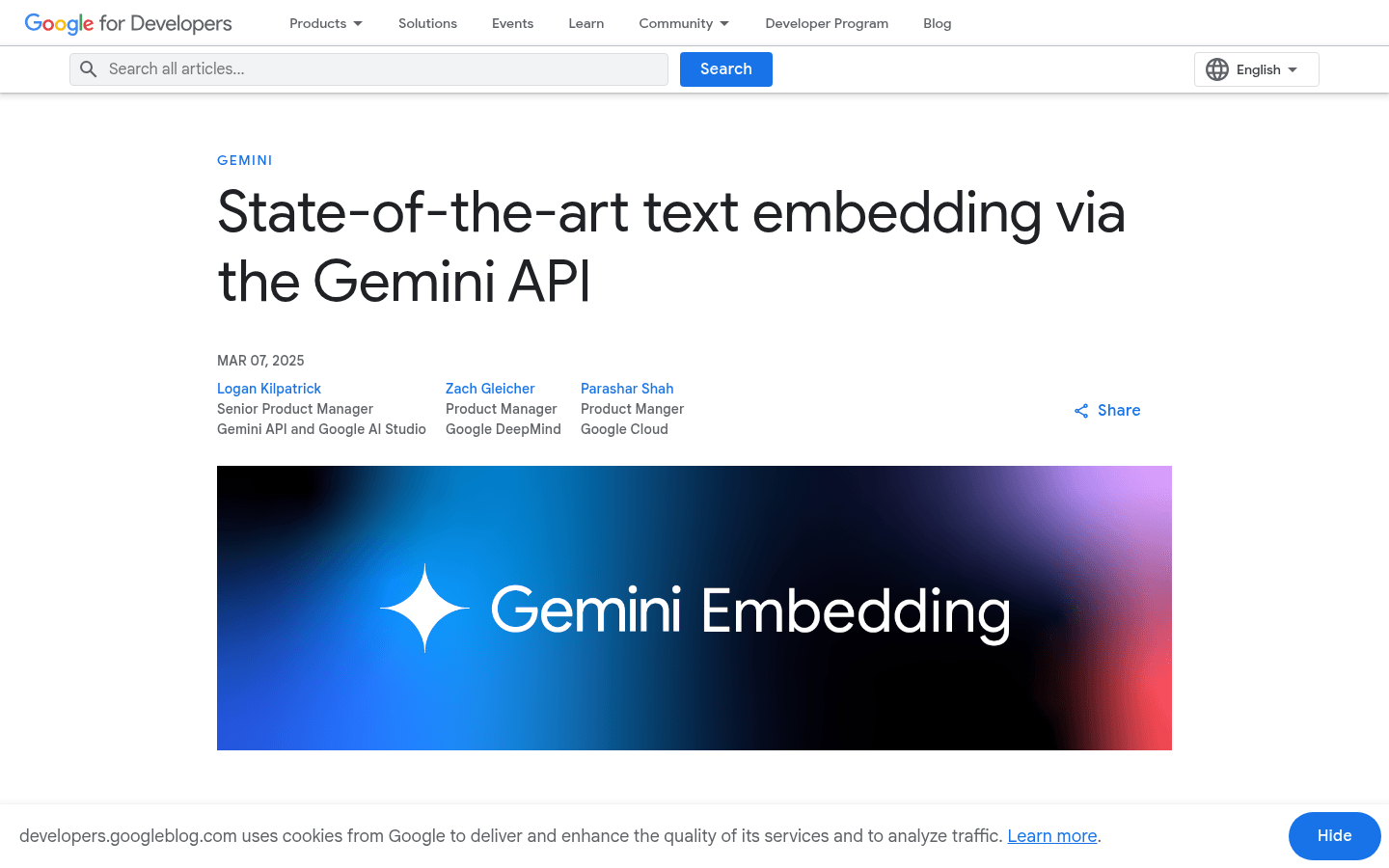
Gemini Embedding 是 Google 推出的一种实验性文本嵌入模型,通过 Gemini API 提供服务。该模型在多语言文本嵌入基准测试(MTEB)中表现卓越,超越了之前的顶尖模型。它能够将文本转换为高维数值向量,捕捉语义和上下文信息,广泛应用于检索、分类、相似性检测等场景。Gemini Embedding 支持超过 100 种语言,具备 8K 输入标记长度和 3K 输出维度,同时引入了嵌套表示学习(MRL)技术,可灵活调整维度以满足存储需求。该模型目前处于实验阶段,未来将推出稳定版本。
NeoBase 是一款创新的 AI 数据库助手,通过自然语言处理技术让用户能够以对话的方式与数据库进行交互。它支持多种主流数据库,如 PostgreSQL、MySQL、MongoDB 等,并且可以与 OpenAI、Google Gemini 等 LLM 客户端集成。其主要优点是简化了数据库管理流程,降低了技术门槛,使非技术用户也能轻松管理和查询数据。NeoBase 采用开源模式,用户可以根据自身需求进行定制和部署,确保数据安全性和隐私性。它主要面向需要高效管理和分析数据的企业和开发者,旨在提高数据库操作的效率和便捷性。
Instella 是由 AMD GenAI 团队开发的一系列高性能开源语言模型,基于 AMD Instinct™ MI300X GPU 训练而成。该模型在性能上显著优于同尺寸的其他开源语言模型,并且在功能上与 Llama-3.2-3B 和 Qwen2.5-3B 等模型相媲美。Instella 提供模型权重、训练代码和训练数据,旨在推动开源语言模型的发展。其主要优点包括高性能、开源开放以及对 AMD 硬件的优化支持。
Clone是一款由Clone Robotics开发的类人机器人,代表了机器人技术的前沿水平。它采用了革命性的人工肌肉技术Myofiber,能够模拟自然动物骨骼的运动。Myofiber技术在重量、功率密度、速度、力量与重量比以及能效方面达到了前所未有的水平,使机器人具备了自然的行走能力、强大的力量和灵活性。Clone不仅在技术上具有重要意义,还为未来机器人在家庭、工业和服务领域的应用提供了新的可能性。其定位为高端科技产品,目标受众是对前沿科技感兴趣的个人、科研机构和企业。
ViDoRAG 是阿里巴巴自然语言处理团队开发的一种新型多模态检索增强生成框架,专为处理视觉丰富文档的复杂推理任务设计。该框架通过动态迭代推理代理和高斯混合模型(GMM)驱动的多模态检索策略,显著提高了生成模型的鲁棒性和准确性。ViDoRAG 的主要优点包括高效处理视觉和文本信息、支持多跳推理以及可扩展性强。该框架适用于需要从大规模文档中检索和生成信息的场景,例如智能问答、文档分析和内容创作。其开源特性和灵活的模块化设计使其成为研究人员和开发者在多模态生成领域的重要工具。
Microsoft Dragon Copilot 是微软针对医疗保健领域推出的 AI 驱动的临床工作流解决方案,旨在通过自动化和智能化的文档处理技术,帮助医疗专业人员减少行政负担,专注于患者护理。该产品利用先进的自然语言处理和机器学习技术,能够自动捕捉多语言的医患对话,并将其转化为详细的临床文档。其主要优点包括高效率的文档生成、定制化功能以及与现有电子健康记录(EHR)系统的无缝集成。Dragon Copilot 面向医疗机构和临床医生,旨在通过技术提升医疗服务质量和效率,同时降低运营成本。产品定价和具体价格策略未在页面中明确提及,但通常会根据医疗机构的规模和使用范围进行定制化报价。
Migician 是清华大学自然语言处理实验室开发的一种多模态大语言模型,专注于多图像定位任务。该模型通过引入创新的训练框架和大规模数据集 MGrounding-630k,显著提升了多图像场景下的精确定位能力。它不仅超越了现有的多模态大语言模型,甚至在性能上超过了更大规模的 70B 模型。Migician 的主要优点在于其能够处理复杂的多图像任务,并提供自由形式的定位指令,使其在多图像理解领域具有重要的应用前景。该模型目前在 Hugging Face 上开源,供研究人员和开发者使用。
IndexTTS 是一种基于 GPT 风格的文本到语音(TTS)模型,主要基于 XTTS 和 Tortoise 进行开发。它能够通过拼音纠正汉字发音,并通过标点符号控制停顿。该系统在中文场景中引入了字符-拼音混合建模方法,显著提高了训练稳定性、音色相似性和音质。此外,它还集成了 BigVGAN2 来优化音频质量。该模型在数万小时的数据上进行训练,性能超越了当前流行的 TTS 系统,如 XTTS、CosyVoice2 和 F5-TTS。IndexTTS 适用于需要高质量语音合成的场景,如语音助手、有声读物等,其开源性质也使其适合学术研究和商业应用。
olmOCR是由Allen Institute for Artificial Intelligence (AI2)开发的一个开源工具包,旨在将PDF文档线性化,以便用于大型语言模型(LLM)的训练。该工具包通过将PDF文档转换为适合LLM处理的格式,解决了传统PDF文档结构复杂、难以直接用于模型训练的问题。它支持多种功能,包括自然文本解析、多版本比较、语言过滤和SEO垃圾信息移除等。olmOCR的主要优点是能够高效处理大量PDF文档,并通过优化的提示策略和模型微调,提高文本解析的准确性和效率。该工具包适用于需要处理大量PDF数据的研究人员和开发者,尤其是在自然语言处理和机器学习领域。
Raycast AI Extensions 是一款面向桌面用户的生产力工具,通过自然语言交互技术,用户可以无需打开应用程序即可完成任务。它支持多种 AI 模型,能够与操作系统无缝集成,并提供个性化定制功能。该产品主要面向需要高效完成任务的专业人士,如开发者、项目经理等,目前处于 beta 版,仅面向 Pro 用户开放。
MLGym是由Meta的GenAI团队和UCSB NLP团队开发的一个开源框架和基准,用于训练和评估AI研究代理。它通过提供多样化的AI研究任务,推动强化学习算法的发展,帮助研究人员在真实世界的研究场景中训练和评估模型。该框架支持多种任务,包括计算机视觉、自然语言处理和强化学习等领域,旨在为AI研究提供一个标准化的测试平台。
TableGPT-agent 是一个基于 TableGPT2 的预构建代理模型,专为处理表格数据的问答任务而设计。它基于 Langgraph 库开发,提供用户友好的交互界面,能够高效处理与表格相关的复杂问题。TableGPT2 是一个大型多模态模型,能够将表格数据与自然语言处理相结合,为数据分析和知识提取提供强大的技术支持。该模型适用于需要快速准确处理表格数据的场景,如数据分析、商业智能和学术研究等。
bRAG-langchain是一个开源项目,专注于Retrieval-Augmented Generation (RAG)技术的研究与应用。RAG是一种结合了检索和生成的AI技术,通过检索相关文档并生成回答,为用户提供更准确、更丰富的信息。该项目提供了从基础到高级的RAG实现指南,帮助开发者快速上手并构建自己的RAG应用。其主要优点是开源、灵活且易于扩展,适合各种需要自然语言处理和信息检索的应用场景。
Qwen Chat 是基于 Qwen 语言模型开发的智能聊天工具,能够提供高效、自然的对话体验。它通过先进的自然语言处理技术,理解用户输入并生成高质量的回复。该产品适用于多种场景,包括日常聊天、信息查询、语言学习等。其主要优点是响应速度快、对话质量高,并且能够处理多种语言。产品目前以网页形式提供服务,未来可能会扩展到更多平台。
FlexHeadFA 是一个基于 FlashAttention 的改进模型,专注于提供快速且内存高效的精确注意力机制。它支持灵活的头维度配置,能够显著提升大语言模型的性能和效率。该模型的主要优点包括高效利用 GPU 资源、支持多种头维度配置以及与 FlashAttention-2 和 FlashAttention-3 兼容。它适用于需要高效计算和内存优化的深度学习场景,尤其在处理长序列数据时表现出色。
FlashMLA 是一个针对 Hopper GPU 优化的高效 MLA 解码内核,专为变长序列服务设计。它基于 CUDA 12.3 及以上版本开发,支持 PyTorch 2.0 及以上版本。FlashMLA 的主要优势在于其高效的内存访问和计算性能,能够在 H800 SXM5 上实现高达 3000 GB/s 的内存带宽和 580 TFLOPS 的计算性能。该技术对于需要大规模并行计算和高效内存管理的深度学习任务具有重要意义,尤其是在自然语言处理和计算机视觉领域。FlashMLA 的开发灵感来源于 FlashAttention 2&3 和 cutlass 项目,旨在为研究人员和开发者提供一个高效的计算工具。
VLM-R1 是一种基于强化学习的视觉语言模型,专注于视觉理解任务,如指代表达理解(Referring Expression Comprehension, REC)。该模型通过结合 R1(Reinforcement Learning)和 SFT(Supervised Fine-Tuning)方法,展示了在领域内和领域外数据上的出色性能。VLM-R1 的主要优点包括其稳定性和泛化能力,使其能够在多种视觉语言任务中表现出色。该模型基于 Qwen2.5-VL 构建,利用了先进的深度学习技术,如闪存注意力机制(Flash Attention 2),以提高计算效率。VLM-R1 旨在为视觉语言任务提供一种高效且可靠的解决方案,适用于需要精确视觉理解的应用场景。
Moonlight-16B-A3B 是由 Moonshot AI 开发的一种大规模语言模型,采用先进的 Muon 优化器进行训练。该模型通过优化训练效率和性能,显著提升了语言生成的能力。其主要优点包括高效的优化器设计、较少的训练 FLOPs 和卓越的性能表现。该模型适用于需要高效语言生成的场景,如自然语言处理、代码生成和多语言对话等。其开源的实现和预训练模型为研究人员和开发者提供了强大的工具。
Moonlight是基于Muon优化器训练的16B参数混合专家模型(MoE),在大规模训练中表现出色。它通过添加权重衰减和调整参数更新比例,显著提高了训练效率和稳定性。该模型在多项基准测试中超越了现有模型,同时大幅减少了训练所需的计算量。Moonlight的开源实现和预训练模型为研究人员和开发者提供了强大的工具,支持多种自然语言处理任务,如文本生成、代码生成等。
kg-gen 是一个基于人工智能的工具,能够从普通文本中提取知识图谱。它支持处理小到单句话、大到长篇文档的文本输入,并且可以处理对话格式的消息。该工具利用先进的语言模型和结构化输出技术,能够帮助用户快速构建知识图谱,适用于自然语言处理、知识管理以及模型训练等领域。kg-gen 提供了灵活的接口和多种功能,旨在简化知识图谱的生成过程,提高效率。
DeepSeek R1与V3 API是Kie.ai提供的强大AI模型接口。DeepSeek R1是专为数学、编程和逻辑推理等高级推理任务设计的最新推理模型,经过大规模强化学习训练,能够提供精准结果。DeepSeek V3则适用于处理常规AI任务。这些API部署在美国安全服务器上,保障数据安全与隐私。Kie.ai还提供详细的API文档和多种定价方案,满足不同需求,助力开发者快速集成AI能力,提升项目性能。
该产品是一个由Vectara开发的开源项目,用于评估大型语言模型(LLM)在总结短文档时的幻觉产生率。它使用了Vectara的Hughes幻觉评估模型(HHEM-2.1),通过检测模型输出中的幻觉来计算排名。该工具对于研究和开发更可靠的LLM具有重要意义,能够帮助开发者了解和改进模型的准确性。
KET-RAG(Knowledge-Enhanced Text Retrieval Augmented Generation)是一个强大的检索增强型生成框架,结合了知识图谱技术。它通过多粒度索引框架(如知识图谱骨架和文本-关键词二分图)实现高效的知识检索和生成。该框架在降低索引成本的同时,显著提升了检索和生成质量,适用于大规模 RAG 应用场景。KET-RAG 基于 Python 开发,支持灵活的配置和扩展,适用于需要高效知识检索和生成的开发人员和研究人员。
Proxy 是 Convergence.ai 推出的 AI 助手,旨在通过自然语言交互帮助用户完成各种日常任务。它利用先进的 AI 技术,能够理解用户的指令并执行任务,如安排日程、总结文章、查找信息等。该产品的主要优点是高效、便捷,能够节省用户的时间和精力。它适合忙碌的专业人士、研究人员、开发者等,帮助他们自动化重复性任务。Proxy 提供免费试用版本,用户可以体验其功能,同时也有付费高级版本供选择。
DeepSeek 模型兼容性检测是一个用于评估设备是否能够运行不同规模 DeepSeek 模型的工具。它通过检测设备的系统内存、显存等配置,结合模型的参数量、精度位数等信息,为用户提供模型运行的预测结果。该工具对于开发者和研究人员在选择合适的硬件资源以部署 DeepSeek 模型时具有重要意义,能够帮助他们提前了解设备的兼容性,避免因硬件不足而导致的运行问题。DeepSeek 模型本身是一种先进的深度学习模型,广泛应用于自然语言处理等领域,具有高效、准确的特点。通过该检测工具,用户可以更好地利用 DeepSeek 模型进行项目开发和研究。
该产品是一个用于大规模深度循环语言模型的预训练代码库,基于Python开发。它在AMD GPU架构上进行了优化,能够在4096个AMD GPU上高效运行。该技术的核心优势在于其深度循环架构,能够有效提升模型的推理能力和效率。它主要用于研究和开发高性能的自然语言处理模型,特别是在需要大规模计算资源的场景中。该代码库开源且基于Apache-2.0许可证,适合学术研究和工业应用。
Concierge AI 是一款通过自然语言与应用程序交互的产品,它利用先进的自然语言处理技术,让用户能够以更直观、更便捷的方式与各种应用程序进行沟通和操作。这种技术的重要性在于它能够打破传统界面操作的限制,让用户以更自然表达的方式需求,从而提高工作效率和用户体验。产品目前处于推广阶段,具体价格和详细定位尚未明确,但其目标是为用户提供一种全新的交互方式,以满足现代工作环境中对效率和便捷性的高要求。
Zyphra通过其开发的人工智能聊天模型Maia,为用户提供高效、智能的聊天体验。该技术基于先进的自然语言处理算法,能够理解并生成自然流畅的对话内容。其主要优点包括高效率的交互、个性化服务以及强大的语言理解能力。Zyphra的目标是通过智能聊天技术改善人机交互体验,推动AI在日常生活中的应用。目前,Zyphra提供免费试用服务,具体定价策略尚未明确。
Basedash是一个AI原生的商业智能平台,它通过自然语言处理技术,帮助用户快速生成数据可视化图表和仪表板。该平台无需用户编写SQL代码,即可从550多个数据源中提取数据,并生成直观的图表。Basedash的主要优点是其强大的AI驱动功能,能够理解用户的自然语言需求,自动调整和优化数据查询。它适用于各种规模的企业,帮助他们快速获取业务洞察。目前,Basedash处于Beta阶段,用户可以免费试用。
RAG-FiT是一个强大的工具,旨在通过检索增强生成(RAG)技术提升大型语言模型(LLMs)的能力。它通过创建专门的RAG增强数据集,帮助模型更好地利用外部信息。该库支持从数据准备到模型训练、推理和评估的全流程操作。其主要优点包括模块化设计、可定制化工作流以及对多种RAG配置的支持。RAG-FiT基于开源许可,适合研究人员和开发者进行快速原型开发和实验。
s1是一个推理模型,专注于通过少量样本实现高效的文本生成能力。它通过预算强制技术在测试时进行扩展,能够匹配o1-preview的性能。该模型由Niklas Muennighoff等人开发,相关研究发表在arXiv上。模型使用Safetensors技术,具有328亿参数,支持文本生成任务。其主要优点是能够通过少量样本实现高质量的推理,适合需要高效文本生成的场景。
Site RAG 是一款 Chrome 扩展程序,旨在通过自然语言处理技术帮助用户在浏览网页时快速获取问题答案。它支持将当前页面内容作为上下文进行查询,还能将整个网站内容索引到向量数据库中,以便后续进行检索增强生成(RAG)。该产品完全在本地浏览器运行,确保用户数据安全,同时支持连接本地运行的 Ollama 实例进行推理。它主要面向需要快速从网页内容中提取信息的用户,如开发者、研究人员和学生。目前该产品免费提供,适合希望在浏览网页时获得即时帮助的用户。
Qwen2.5-1M 是一款开源的人工智能语言模型,专为处理长序列任务而设计,支持最多100万Token的上下文长度。该模型通过创新的训练方法和技术优化,显著提升了长序列处理的性能和效率。它在长上下文任务中表现出色,同时保持了短文本任务的性能,是现有长上下文模型的优秀开源替代。该模型适用于需要处理大量文本数据的场景,如文档分析、信息检索等,能够为开发者提供强大的语言处理能力。
Qwen2.5-Max是一个大规模的Mixture-of-Expert (MoE)模型,经过超过20万亿tokens的预训练和监督微调与人类反馈强化学习的后训练。它在多个基准测试中表现优异,展示了强大的知识和编码能力。该模型通过阿里巴巴云提供API接口,支持开发者在各种应用场景中使用。其主要优点包括强大的性能、灵活的部署方式和高效的训练技术,旨在为人工智能领域提供更智能的解决方案。
DeepSeek是一个基于人工智能技术的智能聊天助手,旨在通过自然语言处理技术为用户提供高效、智能的对话体验。它能够理解用户的问题并提供准确的回答,适用于多种场景,包括日常对话、信息查询和问题解答。DeepSeek的核心优势在于其强大的语言理解和生成能力,能够为用户提供流畅的交互体验。该产品目前以网站形式提供服务,适合需要快速获取信息和进行智能对话的用户。
Xwen-Chat由xwen-team开发,为满足高质量中文对话模型需求而生,填补领域空白。其有多个版本,具备强大语言理解与生成能力,可处理复杂语言任务,生成自然对话内容,适用于智能客服等场景,在Hugging Face平台免费提供。
node-DeepResearch 是一个基于 Jina AI 技术的深度研究模型,专注于通过持续搜索和阅读网页来寻找问题的答案。它利用 Gemini 提供的 LLM 能力和 Jina Reader 的网页搜索功能,能够处理复杂的查询任务,并通过多步骤的推理和信息整合来生成答案。该模型的主要优点在于其强大的信息检索能力和推理能力,能够处理复杂的、需要多步骤解答的问题。它适用于需要深入研究和信息挖掘的场景,如学术研究、市场分析等。目前该模型是开源的,用户可以通过 GitHub 获取代码并自行部署使用。
Dolphin R1是一个由Cognitive Computations团队创建的数据集,旨在训练类似DeepSeek-R1 Distill模型的推理模型。该数据集包含30万条来自DeepSeek-R1的推理样本、30万条来自Gemini 2.0 flash thinking的推理样本以及20万条Dolphin聊天样本。这些数据集的组合为研究人员和开发者提供了丰富的训练资源,有助于提升模型的推理能力和对话能力。该数据集的创建得到了Dria、Chutes、Crusoe Cloud等多家公司的赞助支持,这些赞助商为数据集的开发提供了计算资源和资金支持。Dolphin R1数据集的发布,为自然语言处理领域的研究和开发提供了重要的基础,推动了相关技术的发展。
Tülu 3 405B 是由 Allen Institute for AI 开发的开源语言模型,具有 4050 亿参数。该模型通过创新的强化学习框架(RLVR)提升性能,尤其在数学和指令跟随任务中表现出色。它基于 Llama-405B 模型进行优化,采用监督微调、偏好优化等技术。Tülu 3 405B 的开源性质使其成为研究和开发领域的强大工具,适用于需要高性能语言模型的各种应用场景。
huggingface/open-r1 是一个开源项目,致力于复现 DeepSeek-R1 模型。该项目提供了一系列脚本和工具,用于训练、评估和生成合成数据,支持多种训练方法和硬件配置。其主要优点是完全开放,允许开发者自由使用和改进,对于希望在深度学习和自然语言处理领域进行研究和开发的用户来说,是一个非常有价值的资源。该项目目前没有明确的定价,适合学术研究和商业用途。
Janus-Pro-1B 是一个创新的多模态模型,专注于统一多模态理解和生成。它通过分离视觉编码路径,解决了传统方法在理解和生成任务中的冲突问题,同时保持了单个统一的 Transformer 架构。这种设计不仅提高了模型的灵活性,还使其在多模态任务中表现出色,甚至超越了特定任务的模型。该模型基于 DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base 构建,使用 SigLIP-L 作为视觉编码器,支持 384x384 的图像输入,并采用特定的图像生成 tokenizer。其开源性和灵活性使其成为下一代多模态模型的有力候选。
SpeechGPT 2.0-preview 是一款由复旦大学自然语言处理实验室开发的先进语音交互模型。它通过海量语音数据训练,实现了低延迟、高自然度的语音交互能力。该模型能够模拟多种情感、风格和角色的语音表达,同时支持工具调用、在线搜索和外部知识库访问等功能。其主要优点包括强大的语音风格泛化能力、多角色模拟以及低延迟交互体验。目前该模型仅支持中文语音交互,未来计划扩展到更多语言。
Tarsier 是由字节跳动研究团队开发的一系列大规模视频语言模型,旨在生成高质量的视频描述,并具备强大的视频理解能力。该模型通过两阶段训练策略(多任务预训练和多粒度指令微调)显著提升了视频描述的精度和细节。其主要优点包括高精度的视频描述能力、对复杂视频内容的理解能力以及在多个视频理解基准测试中取得的 SOTA(State-of-the-Art)结果。Tarsier 的背景基于对现有视频语言模型在描述细节和准确性上的不足进行改进,通过大规模高质量数据训练和创新的训练方法,使其在视频描述领域达到了新的高度。该模型目前未明确定价,主要面向学术研究和商业应用,适合需要高质量视频内容理解和生成的场景。
Baichuan-M1-14B 是由百川智能开发的开源大语言模型,专为医疗场景优化。它基于20万亿token的高质量医疗与通用数据训练,覆盖20多个医疗科室,具备强大的上下文理解和长序列任务表现能力。该模型在医疗领域表现出色,同时在通用任务中也达到了同尺寸模型的效果。其创新的模型结构和训练方法使其在医疗推理、病症判断等复杂任务中表现出色,为医疗领域的人工智能应用提供了强大的支持。
VideoLLaMA3是由DAMO-NLP-SG团队开发的前沿多模态基础模型,专注于图像和视频理解。该模型基于Qwen2.5架构,结合了先进的视觉编码器(如SigLip)和强大的语言生成能力,能够处理复杂的视觉和语言任务。其主要优点包括高效的时空建模能力、强大的多模态融合能力以及对大规模数据的优化训练。该模型适用于需要深度视频理解的应用场景,如视频内容分析、视觉问答等,具有广泛的研究和商业应用潜力。
Anthropic API 的 Citations 功能是一种强大的技术,它允许 Claude 模型在生成回答时引用源文件中的确切句子和段落。这种功能不仅提高了回答的可验证性和可信度,还减少了模型可能出现的幻觉问题。Citations 功能基于 Anthropic API 提供,适用于需要验证 AI 生成内容来源的各种场景,如文档总结、复杂问答和客户支持等。其定价采用标准的基于 token 的定价模型,用户无需为返回引用文本的输出 token 付费。
Eko 是一个面向开发者的生产级智能代理框架。它允许开发者通过自然语言和代码逻辑轻松构建基于代理的工作流。Eko 的主要优点包括高效的任务分解能力、强大的工具支持以及灵活的定制化选项。它旨在帮助开发者快速实现复杂的自动化任务,提高开发效率。Eko 由 FellouAI 团队开发,目前处于开源状态,支持多种平台,包括浏览器和桌面环境。具体价格未明确公开,但从其开源特性来看,可能对开发者免费开放,但部分高级功能或定制化服务可能需要付费。
UPDF AI 是一款基于人工智能技术的 PDF 智能处理工具。它通过与 PDF 文档的交互,帮助用户快速提取和分析文档中的关键信息,从而提高阅读和学习效率。该产品利用先进的自然语言处理技术,能够精准地对文档内容进行总结、翻译、解释等操作。其主要优点包括高效的信息提取能力、精准的语言处理能力以及便捷的用户交互体验。UPDF AI 面向需要处理大量 PDF 文档的用户,无论是学生、研究人员还是专业人士,都能从中受益。目前,该产品的具体价格和定位尚未明确,但其强大的功能和高效的表现使其在市场上具有较高的竞争力。
Finbar是一个专注于提供全球基础金融数据的平台。它通过先进的OCR、机器学习和自然语言处理技术,能够快速从海量金融文档中提取结构化数据,并在数据发布后几秒内提供给用户。其主要优点是数据更新速度快、自动化程度高,能够显著减少人工处理数据的时间和成本。该产品主要面向金融机构和分析师,帮助他们快速获取和分析数据,提升工作效率。目前尚不清楚其具体价格和定位,但已获得多家顶级对冲基金的使用。
UI-TARS-desktop 是由字节跳动开发的一款桌面客户端应用,它基于 UI-TARS 视觉语言模型,允许用户通过自然语言与计算机进行交互,完成各种任务。该产品利用先进的视觉语言模型技术,能够理解用户的自然语言指令,并通过屏幕截图和视觉识别功能实现精准的鼠标和键盘操作。它支持跨平台使用(Windows 和 macOS),并提供实时反馈和状态显示,极大地提高了用户的工作效率和交互体验。目前该产品在 GitHub 上开源,用户可以免费下载和使用。
DeepSeek-R1-Distill-Qwen-1.5B 是由 DeepSeek 团队开发的开源语言模型,基于 Qwen2.5 系列进行蒸馏优化。该模型通过大规模强化学习和数据蒸馏技术,显著提升了推理能力和性能,同时保持了较小的模型体积。它在多项基准测试中表现出色,尤其在数学、代码生成和推理任务中具有显著优势。该模型支持商业使用,并允许用户进行修改和衍生作品开发,适合研究机构和企业用于开发高性能的自然语言处理应用。
DeepSeek-R1-Distill-Qwen-14B 是 DeepSeek 团队开发的一款基于 Qwen-14B 的蒸馏模型,专注于推理和文本生成任务。该模型通过大规模强化学习和数据蒸馏技术,显著提升了推理能力和生成质量,同时降低了计算资源需求。其主要优点包括高性能、低资源消耗和广泛的适用性,适用于需要高效推理和文本生成的场景。
Fey 是一款专注于投资领域的工具,具有实时市场数据、智能观察列表、人工智能驱动的见解和高级筛选功能。它结合了直观的界面和强大的数据分析能力,无论是新手投资者还是经验丰富的专业人士,都能从中受益。Fey 的主要优点是能够简化复杂信息,减少干扰,让用户专注于重要的投资决策。其背景信息显示,该产品由 Fey Labs Inc. 开发,旨在为用户提供高效、便捷的投资体验。目前,Fey 提供免费试用服务,具体价格尚未明确。
WebWalker是一个由阿里巴巴集团通义实验室开发的多智能体框架,用于评估大型语言模型(LLMs)在网页遍历任务中的表现。该框架通过模拟人类浏览网页的方式,通过探索和评估范式来系统地提取高质量数据。WebWalker的主要优点在于其创新的网页遍历能力,能够深入挖掘多层级信息,弥补了传统搜索引擎在处理复杂问题时的不足。该技术对于提升语言模型在开放域问答中的表现具有重要意义,尤其是在需要多步骤信息检索的场景中。WebWalker的开发旨在推动语言模型在信息检索领域的应用和发展。
InternLM3 是由 InternLM 团队开发的一系列高性能语言模型,专注于文本生成任务。该模型通过多种量化技术优化,能够在不同硬件环境下高效运行,同时保持出色的生成质量。其主要优点包括高效的推理性能、多样化的应用场景以及对多种文本生成任务的优化支持。InternLM3 适用于需要高质量文本生成的开发者和研究人员,能够帮助他们在自然语言处理领域快速实现应用。
MiniRAG是一个针对小型语言模型设计的检索增强生成系统,旨在简化RAG流程并提高效率。它通过语义感知的异构图索引机制和轻量级的拓扑增强检索方法,解决了小型模型在传统RAG框架中性能受限的问题。该模型在资源受限的场景下具有显著优势,如在移动设备或边缘计算环境中。MiniRAG的开源特性也使其易于被开发者社区接受和改进。
MiniMax-01是一个具有4560亿总参数的强大语言模型,其中每个token激活459亿参数。它采用混合架构,结合了闪电注意力、softmax注意力和专家混合(MoE),通过先进的并行策略和创新的计算-通信重叠方法,如线性注意力序列并行主义加(LASP+)、varlen环形注意力、专家张量并行(ETP)等,将训练上下文长度扩展到100万tokens,在推理时可处理长达400万tokens的上下文。在多个学术基准测试中,MiniMax-01展现了顶级模型的性能。
Nemotron-CC是一个基于Common Crawl的6.3万亿token的数据集。它通过分类器集成、合成数据改写和减少启发式过滤器的依赖,将英文Common Crawl转化为一个6.3万亿token的长期预训练数据集,包含4.4万亿全球去重的原始token和1.9万亿合成生成的token。该数据集在准确性和数据量之间取得了更好的平衡,对于训练大型语言模型具有重要意义。
Wren AI Cloud 是一款强大的生产力工具,旨在通过自然语言处理技术,帮助非技术团队轻松访问和分析数据库中的数据。它利用先进的SQL生成算法和多智能体工作流程,减少AI幻觉,提供可靠、准确的数据查询结果。产品主要面向企业数据团队、销售和市场团队,以及开源社区,支持多种数据库和SaaS工具的集成。其价格策略灵活,提供免费试用选项,旨在推动数据驱动的文化,加速决策过程。
该模型是量化版大型语言模型,采用4位量化技术,降低存储与计算需求,适用于自然语言处理,参数量8.03B,免费且可用于非商业用途,适合资源受限环境下高性能语言应用需求者。
Your Interviewer 是一款创新的内容创作工具,通过AI采访技术,帮助用户挖掘个人故事并将其转化为高度个性化的内容。该产品利用先进的自然语言处理技术,通过一系列启发性问题引导用户分享自己的经历和见解,然后将这些内容优化为适合不同媒介的高参与度内容。其主要优点在于无需用户进行繁琐的提示或指导,即可生成高质量的内容。该产品适合需要快速创作内容的企业和个人,如营销人员、内容创作者等,能够帮助他们节省时间并提高内容的吸引力。产品目前处于等待名单阶段,尚未公开定价,但预计将提供免费试用选项。
GitHub Assistant 是一款创新的编程辅助工具,它利用自然语言处理技术,使用户能够通过简单的语言问题来探索和理解GitHub上的各种代码仓库。该工具的主要优点在于其易用性和高效性,用户无需具备复杂的编程知识即可快速获取所需信息。产品由 assistant-ui 和 relta 共同开发,旨在为开发者提供一个更加便捷和直观的代码探索方式。GitHub Assistant 的定位是为编程人员提供一个强大的辅助工具,帮助他们更好地理解和利用开源代码资源。
Imitate Before Detect 是一种创新的文本检测技术,旨在提高对机器修订文本的检测能力。该技术通过模仿大型语言模型(LLM)的风格偏好,能够更准确地识别出经过机器修订的文本。其核心优势在于能够有效区分机器生成和人类写作的细微差别,从而在文本检测领域具有重要的应用价值。该技术的背景信息显示,它能够显著提高检测的准确性,并且在处理开源LLM修订文本时,AUC值提升了13%,在检测GPT-3.5和GPT-4o修订文本时分别提升了5%和19%。其定位是为研究人员和开发者提供一种高效的文本检测工具。
Project G-Assist是NVIDIA推出的一款AI助手,专为GeForce RTX AI PC用户设计。它通过本地运行在RTX GPU上,能够简化用户对PC的配置和优化过程。G-Assist利用先进的自然语言处理技术,帮助用户通过语音或文本命令控制PC的各种设置,从而提升游戏体验和系统性能。其主要优点包括快速响应、无需在线连接和免费使用。该产品旨在为游戏玩家和创作者提供更加智能和便捷的PC使用体验。
Cure AI 是一款专为医学研究人员设计的工具,旨在通过访问超过2600万篇PubMed文章,提供高效、高质量的科研支持。其主要优点包括强大的证据排名功能、自然语言查询处理能力以及无缝的文献导航体验。Cure AI 的背景信息显示,它致力于简化科研流程,帮助研究人员快速找到相关且可靠的文献资源。产品目前提供免费试用,并有多种付费计划可供选择,适合不同规模和需求的研究团队。
CAG(Cache-Augmented Generation)是一种创新的语言模型增强技术,旨在解决传统RAG(Retrieval-Augmented Generation)方法中存在的检索延迟、检索错误和系统复杂性等问题。通过在模型上下文中预加载所有相关资源并缓存其运行时参数,CAG能够在推理过程中直接生成响应,无需进行实时检索。这种方法不仅显著降低了延迟,提高了可靠性,还简化了系统设计,使其成为一种实用且可扩展的替代方案。随着大型语言模型(LLMs)上下文窗口的不断扩展,CAG有望在更复杂的应用场景中发挥作用。
Sonus-1是Sonus AI推出的一系列大型语言模型(LLMs),旨在推动人工智能的边界。这些模型以其高性能和多应用场景的多功能性而设计,包括Sonus-1 Mini、Sonus-1 Air、Sonus-1 Pro和Sonus-1 Pro (w/ Reasoning)等不同版本,以满足不同需求。Sonus-1 Pro (w/ Reasoning)在多个基准测试中表现突出,特别是在推理和数学问题上,展现了其超越其他专有模型的能力。Sonus AI致力于开发高性能、可负担、可靠且注重隐私的大型语言模型。
Text-to-CAD UI是一个利用自然语言提示生成B-Rep CAD文件和网格的平台。它通过ML-ephant API,由Zoo提供支持,能够将用户的自然语言描述直接转化为精确的CAD模型。这项技术的重要性在于它极大地简化了设计过程,使得非专业人士也能轻松创建复杂的CAD模型,从而推动了设计的民主化和创新。产品背景信息显示,它是由Zoo开发的,旨在通过机器学习技术提升设计效率。关于价格和定位,用户需要登录后才能获取更多信息。
Patronus-Lynx-8B-Instruct-v1.1是基于meta-llama/Meta-Llama-3.1-8B-Instruct模型的微调版本,主要用于检测RAG设置中的幻觉。该模型经过CovidQA、PubmedQA、DROP、RAGTruth等多个数据集的训练,包含人工标注和合成数据。它能够评估给定文档、问题和答案是否忠实于文档内容,不提供超出文档范围的新信息,也不与文档信息相矛盾。
InternVL2.5-MPO是一个先进的多模态大型语言模型系列,它基于InternVL2.5和混合偏好优化构建。该模型整合了新增量预训练的InternViT与各种预训练的大型语言模型,包括InternLM 2.5和Qwen 2.5,使用随机初始化的MLP投影器。InternVL2.5-MPO在新版本中保留了与InternVL 2.5及其前身相同的模型架构,遵循“ViT-MLP-LLM”范式。该模型支持多图像和视频数据,通过混合偏好优化(MPO)进一步提升模型性能,使其在多模态任务中表现更优。
Llama-3.1-70B-Instruct-AWQ-INT4是一个由Hugging Face托管的大型语言模型,专注于文本生成任务。该模型拥有70B个参数,能够理解和生成自然语言文本,适用于多种文本相关的应用场景,如内容创作、自动回复等。它基于深度学习技术,通过大量的数据训练,能够捕捉语言的复杂性和多样性。模型的主要优点包括高参数量带来的强大表达能力,以及针对特定任务的优化,使其在文本生成领域具有较高的效率和准确性。
StoryWeaver是一个为知识增强型故事角色定制而设计的统一世界模型,旨在实现单一和多角色故事可视化。该模型基于AAAI 2025论文,能够通过统一的框架处理故事中角色的定制和可视化,这对于自然语言处理和人工智能领域具有重要意义。StoryWeaver的主要优点包括其能够处理复杂故事情境的能力,以及能够持续更新和扩展其功能。产品背景信息显示,该模型将不断更新arXiv论文,并添加更多实验结果。
ModernBERT是由Answer.AI和LightOn共同发布的新一代编码器模型,它是BERT模型的全面升级版,提供了更长的序列长度、更好的下游性能和更快的处理速度。ModernBERT采用了最新的Transformer架构改进,特别关注效率,并使用了现代数据规模和来源进行训练。作为编码器模型,ModernBERT在各种自然语言处理任务中表现出色,尤其是在代码搜索和理解方面。它提供了基础版(139M参数)和大型版(395M参数)两种模型尺寸,适合各种规模的应用需求。
PatronusAI/Llama-3-Patronus-Lynx-70B-Instruct-Q4_K_M-GGUF是一个基于70B参数的大型量化语言模型,使用了4-bit量化技术,以减少模型大小并提高推理效率。该模型属于PatronusAI系列,是基于Transformers库构建的,适用于需要高性能自然语言处理的应用场景。模型遵循cc-by-nc-4.0许可协议,意味着可以非商业性地使用和分享。
YuLan-Mini是由中国人民大学AI Box团队开发的一款轻量级语言模型,具有2.4亿参数,尽管仅使用1.08T的预训练数据,但其性能可与使用更多数据训练的行业领先模型相媲美。该模型特别擅长数学和代码领域,为了促进可复现性,团队将开源相关的预训练资源。
SCENIC是一个文本条件的场景交互模型,能够适应具有不同地形的复杂场景,并支持使用自然语言进行用户指定的语义控制。该模型通过用户指定的轨迹作为子目标和文本提示,来导航3D场景。SCENIC利用层次化推理场景的方法,结合运动与文本之间的帧对齐,实现不同运动风格之间的无缝过渡。该技术的重要性在于其能够生成符合真实物理规则和用户指令的角色导航动作,对于虚拟现实、增强现实以及游戏开发等领域具有重要意义。
InternVL2.5-MPO是一个先进的多模态大型语言模型系列,基于InternVL2.5和混合偏好优化构建。该模型集成了新增量预训练的InternViT和各种预训练的大型语言模型,如InternLM 2.5和Qwen 2.5,使用随机初始化的MLP投影器。它支持多图像和视频数据,并且在多模态任务中表现出色,能够理解和生成与图像相关的文本内容。