找到 690 个相关的AI工具
NanoPhoto.AI是一款由先进AI模型驱动的专业AI照片编辑器。它的背景依托于先进的AI技术,尤其是采用了谷歌GEMINI模型,旨在为用户提供专业级的照片处理体验。该产品定位为满足用户多样化的图像编辑需求,无论是个人用户用于日常照片美化,还是专业人士处理工作相关的图像。产品的主要优点在于其强大的功能,包括多种专业编辑风格、免费的图像转换和压缩功能,能让用户在照片处理过程中发挥无限创意,且操作简单高效。价格方面,文档中未提及收费相关信息,推测部分功能免费使用。
Retro Image Prompt是由Google Nano Banana驱动的复古图像提示生成器。它支持文本到图像(T2I)和图像到图像(I2I)工作流程,能帮助用户快速创建高质量的复古图像提示和复古AI艺术。产品的主要优点在于提供丰富的复古风格供用户选择,生成的图像质量高且风格稳定。价格方面,使用需要消耗积分,用户可获取积分后使用,定位为满足用户对复古图像创作的需求,无论是个人艺术家、设计师还是普通爱好者都能使用。
Midjourney TV基于Midjourney技术,是一个在线图像生成平台。Midjourney是先进的AI图像生成模型,能依据文本描述生成高质量图像。该平台重要性在于为用户提供便捷、高效的图像创作途径。主要优点包括生成速度快、图像质量高、可根据文本灵活定制。其背景是适应市场对AI图像生成的需求而推出。价格方面暂未明确,定位是面向图像创作爱好者、设计师等群体,帮助他们快速获得创意图像。
夸克・造点 AI 是一个利用先进的 AI 技术生成图像和视频的平台,用户可以通过简单的输入生成视觉内容。它的主要优点是快速高效,适用于设计师、艺术家和内容创作者。该产品为用户提供灵活的创作工具,帮助他们在短时间内实现创意构思,定价模式灵活,为用户提供了更多选择。
FluxAPI.ai是面向开发者的平台,提供对Black Forest Labs FLUX 1模型系列的API访问。支持高级的文本转图像和图像转图像生成。主要优点包括价格经济,其Kontext Pro定价仅$0.025,Kontext Max定价仅$0.05,相比其他平台成本更低;提供多种AI模型,能适应不同场景需求;具备灵活的生成模式和实时性能,带来流畅创作体验;还有24/7专家支持。该平台专为开发者、创作者和团队大规模使用而打造,采用基于积分的计费模式,按需购买积分,无订阅、无最低消费、无隐藏费用。
Nano Banana是一款由Google最新Nano Banana模型驱动的人工智能图像生成与编辑平台。其重要性在于为用户提供了便捷、高效且功能强大的图像创作与编辑方式。主要优点包括闪电般的图像生成和预览速度,能实现即时迭代;高保真度,保证图像细节清晰、风格一致且符合提示要求;用户可用自然语言精确控制图像创作和编辑过程。该平台有多种价格套餐,包括按月或按年付费,提供不同的信用额度和功能,可满足从初学者到专业企业的不同需求。定位为满足各类用户对图像生成和编辑的需求,无论是个人创作者还是商业企业都适用。
NanoBanana AI 图片生成器利用Google最新的NanoBanana模型,能在数秒内生成高质量图片。其优势在于极速生成、高质量输出、SEO友好、简单易用。价格灵活,适合各类用户。
Youart是一体化AI创意工作室,提供强大的AI图像和视频生成器,通过文本提示将您的想法转化为令人惊叹的视觉作品。
Nano Banana AI 是一款先进的 AI 图像编辑器,能够快速将您的照片转换为专业级效果。该产品支持多种图片格式,用户可以通过简单的步骤进行编辑,适合个人和商业用途。价格方面,提供免费和付费的订阅选项,以满足不同用户的需求。
NanoBananas使用先进的AI技术,以秒级速度生成高质量图像,无需设计技能。其主要优点包括快速生成、多图像合并编辑、生成迷因等功能。产品定位于为创作者提供快速、简单、高质量的图像生成服务。
Nano Banana API 提供 AI 图像生成与编辑接口,支持自然语言编辑、角色一致性保障、多图合成等功能。其主要优点在于高效稳定的性能、逼真写实效果和多图合成创意构图。
anyimg.ai是一个使用先进AI模型将简单文本描述转换为令人惊叹的视觉艺术品的平台。它能够创建独特的艺术作品、照片和设计。
AI Banana 是一款先进的图像编辑平台,利用 Nano Banana AI 技术,通过自然语言处理实现 1-2 秒内的图像生成与编辑。该产品适合各种创意需求,包括电子商务、市场营销和设计等领域。价格灵活,提供按需购买和订阅服务,满足不同用户的需求。
AI Fiesta提供了多个顶级AI模型,让用户可以比较模型回答,并选择最适合每项任务的AI。该产品的主要优点在于聚合了多个顶尖AI模型,提供便捷的比较功能,价格合理且功能强大。
Nano Banana AI是一款使用先进AI技术的图像生成器和编辑器,能够通过简单的文本提示即时将文字转换为图像。它的AI模型领先于其他传统模型,具有高度准确性和速度。
ImageFX是由Google强大的AI技术驱动的先进AI图像生成器,将简单的文本提示转化为令人惊叹的图像。其主要优点包括生成高品质、详细的图像、快速操作、精准控制、Google AI支持、广泛应用、用户友好界面。价格分为免费、基础和高级三个选项,适用于艺术家、设计师、营销人员等。
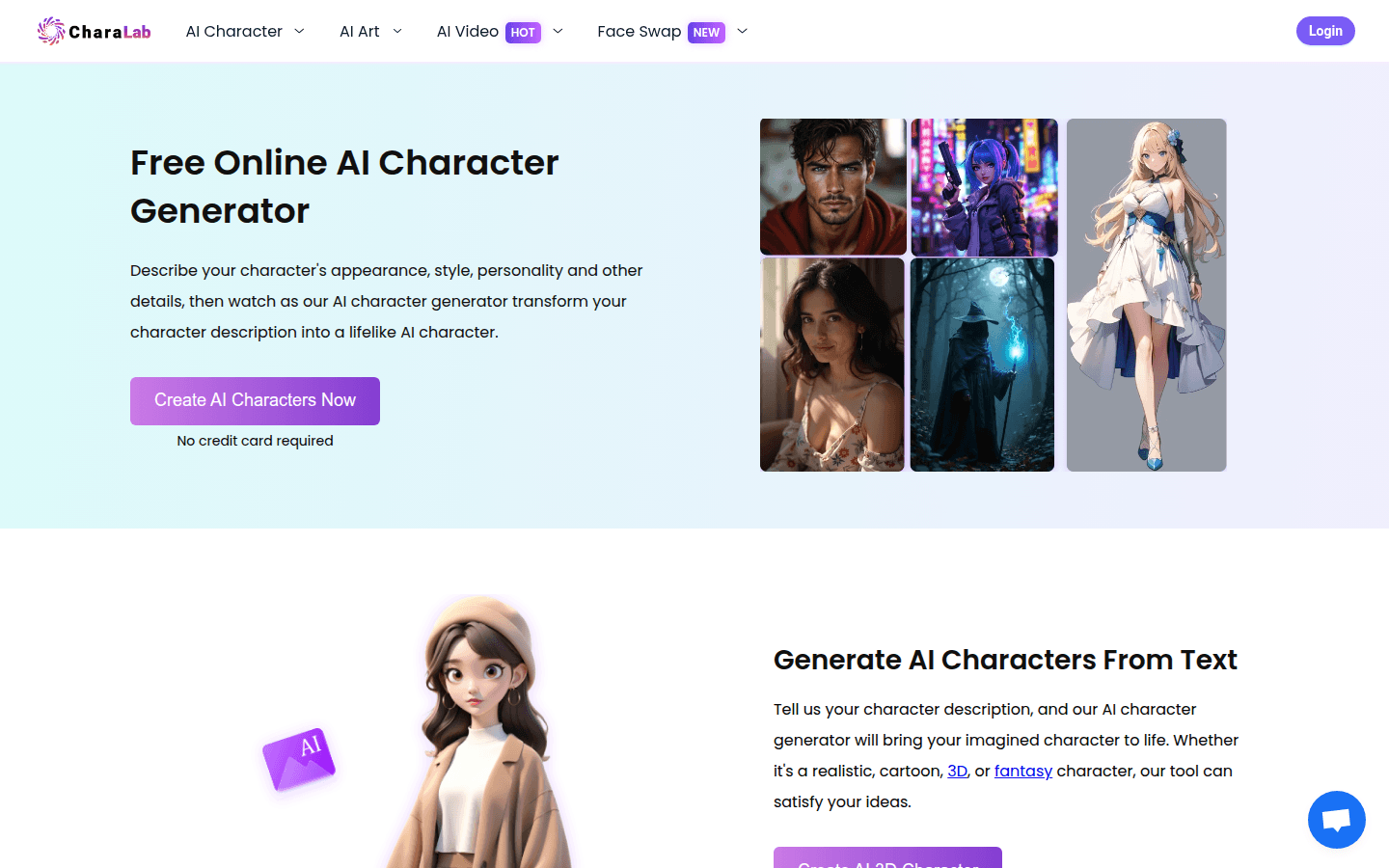
CharaLab是一个AI角色生成器,利用人工智能技术将角色描述转化为逼真的AI角色。它的主要优点在于快速生成高质量角色图像,适用于创作、游戏设计等领域。
Grok Imagine是由Aurora引擎驱动的AI图像和视频生成平台,可生成多领域的逼真图像和动态视频内容。其核心技术基于Aurora引擎的自回归图像模型,为用户提供高质量、多样化的视觉创作体验。
FLUX.1 Krea [dev] 是一个拥有 120 亿参数的修正流转换器,专为从文本描述生成高质量图像而设计。该模型经过指导蒸馏训练,使其更高效,且开放权重推动科学研究和艺术创作。产品强调其美学摄影能力和强大的提示遵循能力,是对封闭源替代品的有力竞争。使用该模型的用户能够进行个人、科学和商业用途,推动创新的工作流程。
Openjourney 是一个高保真的开源项目,旨在模拟 MidJourney 的界面,利用 Google 的 Gemini SDK 进行 AI 图像和视频生成。该项目支持使用 Imagen 4 生成高质量图像,以及使用 Veo 2 和 Veo 3 进行文本到视频和图像到视频的转换。它适合需要进行图像生成和视频制作的开发者和创作者,提供了用户友好的界面和实时生成体验,能够助力创意工作与项目开发。
Holopix AI 是一款专为游戏美术设计提供高效解决方案的在线平台,通过 AI 技术实现角色、场景、三视图等内容的一键生成和快速建模,极大提升创作效率。该产品适合游戏开发团队及独立设计师,提供丰富的风格模型,支持多种创作工具,帮助用户快速实现创意。注册后即可享受多个独家游戏风格模型。其定位在于通过 AI 技术降低游戏美术创作的门槛,为用户提供更高效的设计体验。
FantasyPortrait 是一种高保真、多情感的肖像动画生成框架,使用表达增强学习策略来捕捉细腻的面部动态,适合单角色和多角色场景。该技术的优势在于其独特的掩蔽交叉注意机制,有效防止了特征干扰,提升了动画的质量与表现力。该产品背景源于对现有面部动画方法的不足的反思,尤其是在处理多角色互动时的挑战。未来将以开源形式提供代码与模型,鼓励研究与开发。
ZenCtrl 是一个综合工具包,旨在解决图像生成中的核心挑战。无需微调,可从单个主体图像生成多视角、高分辨率的图像。它能够控制形状、姿势、相机角度和上下文,非常适合进行产品摄影、时尚试穿等场景。该工具包还将发布 API,便于集成与使用。
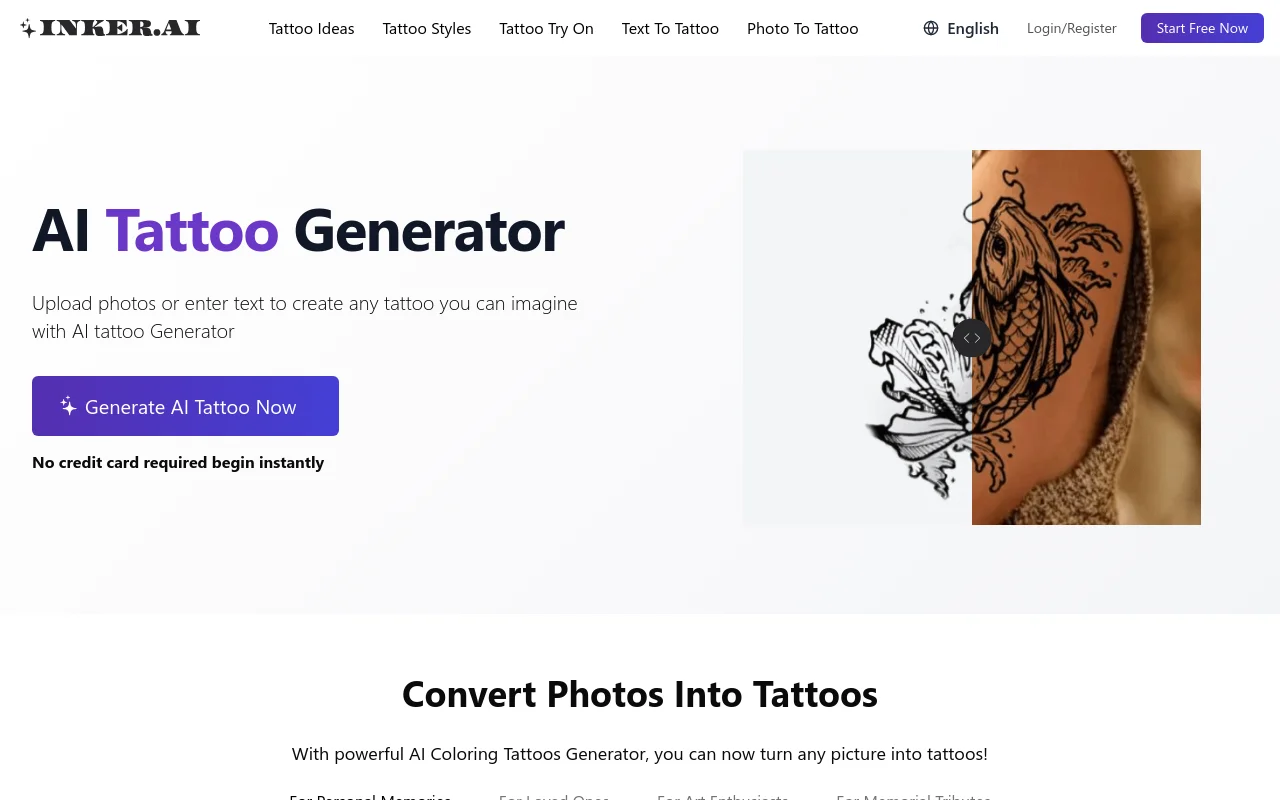
Inker.AI 是一个在线的 AI 纹身生成器,允许用户通过上传照片或输入文字来创建个性化的纹身设计。该平台无需设计技能,用户只需简单操作即可生成专业纹身。适合各类人群,特别是艺术爱好者和纹身爱好者。产品免费使用,易于上手,具有极高的灵活性和创造力。
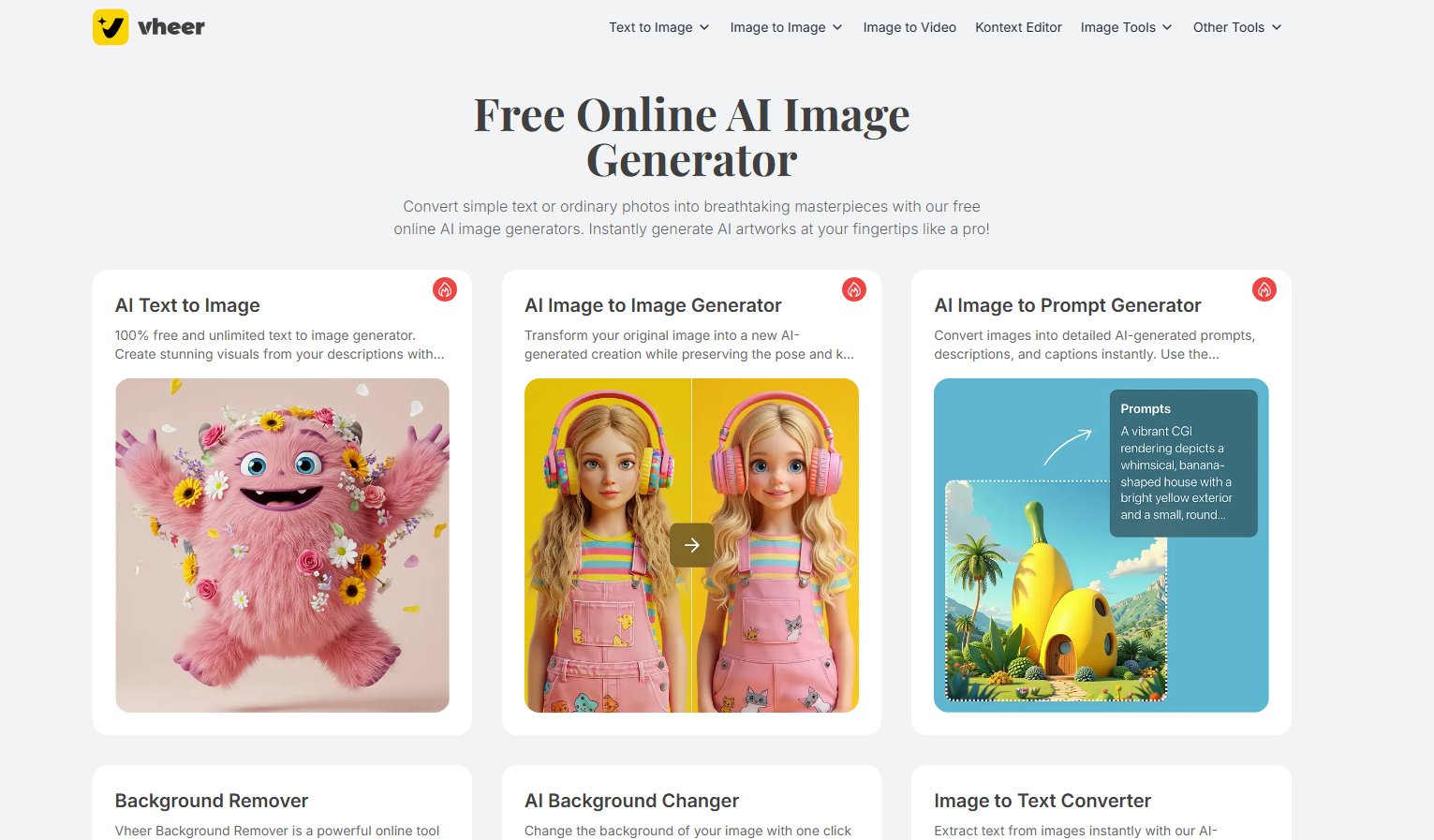
Vheer 是一款强大的在线图像生成器,通过先进的人工智能技术,用户可以轻松创建高质量的图像。无论是艺术作品、头像,还是纹身设计,Vheer 都能够快速满足用户的需求。产品完全免费,无需注册,适合所有创意人士。
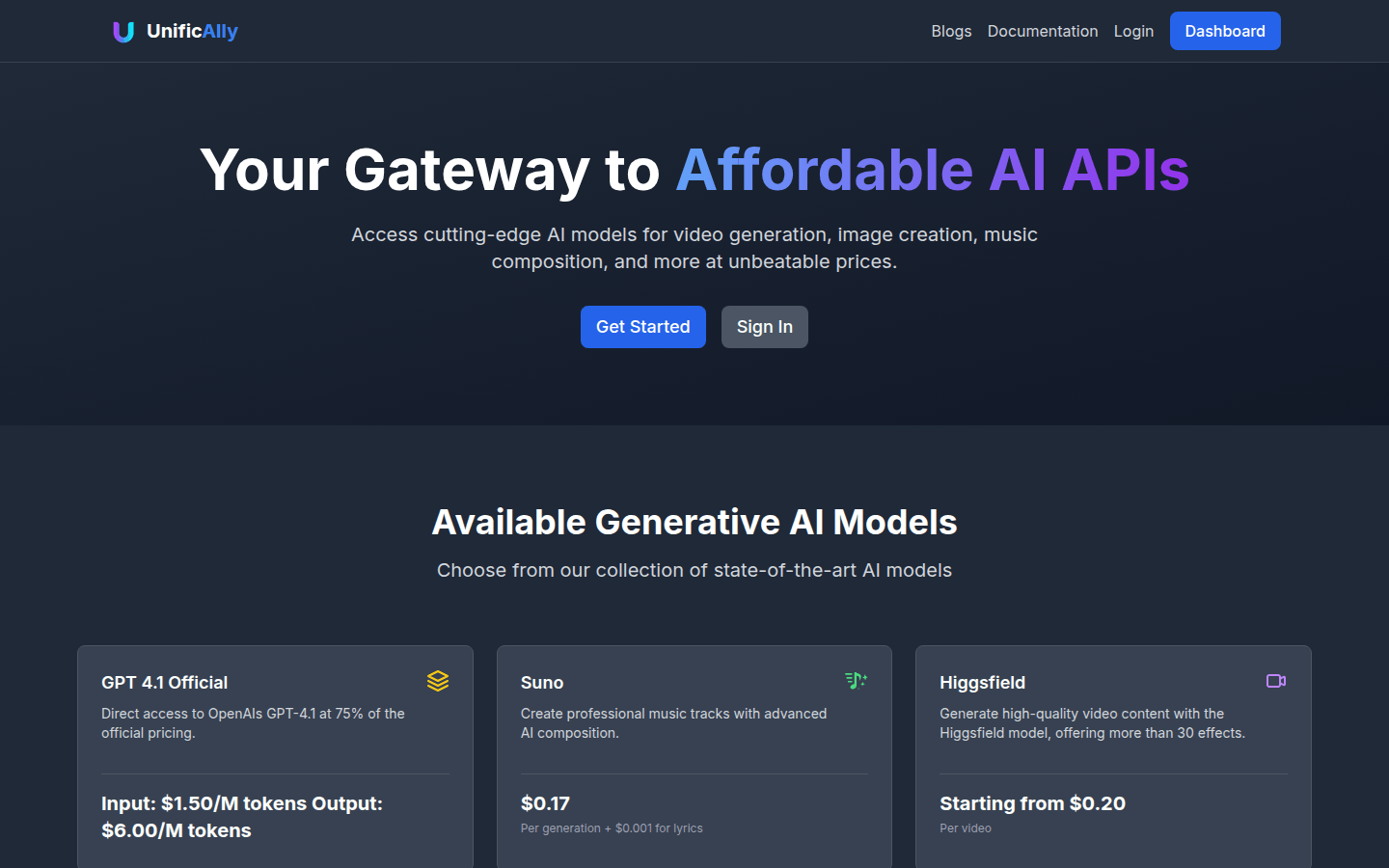
UnificAlly是一家AI API服务平台,提供创新的AI模型和API服务,价格优惠。用户可以访问平台并选择各种先进的AI模型,如GPT 4.1、Suno、Higgsfield等,用于视频生成、图像创作、音乐作曲等。UnificAlly致力于提供高性价比的AI服务,并以快速可靠的API响应、简单易集成的REST API和详尽的文档和示例著称。
Picit AI 是一款强大的在线 AI 图片编辑器,提供多种功能,包括图像生成、背景移除和图像增强。该产品致力于帮助用户轻松创建和编辑高质量图像,适合各类创作者和设计师使用。Picit AI 提供免费服务,使每个人都能享受先进的图像处理技术。
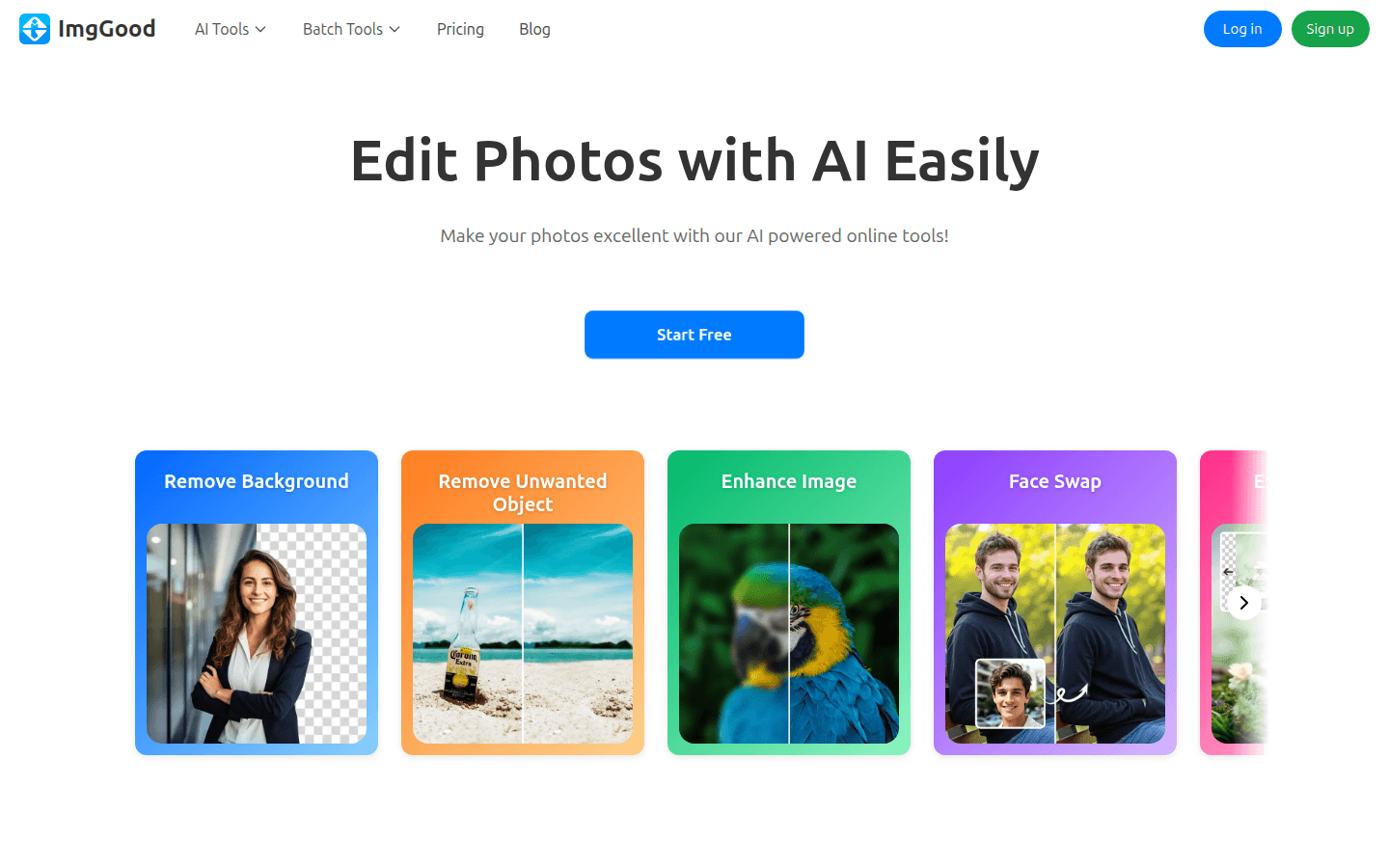
ImgGood 是一款免费的在线照片编辑工具,利用先进的 AI 技术帮助用户快速、高效地编辑照片。它提供背景移除、图像增强、对象移除等多种功能,旨在使照片编辑变得简单而高效。此产品无需下载,适合任何希望提升照片质量的用户,使用过程简便,且完全免费。
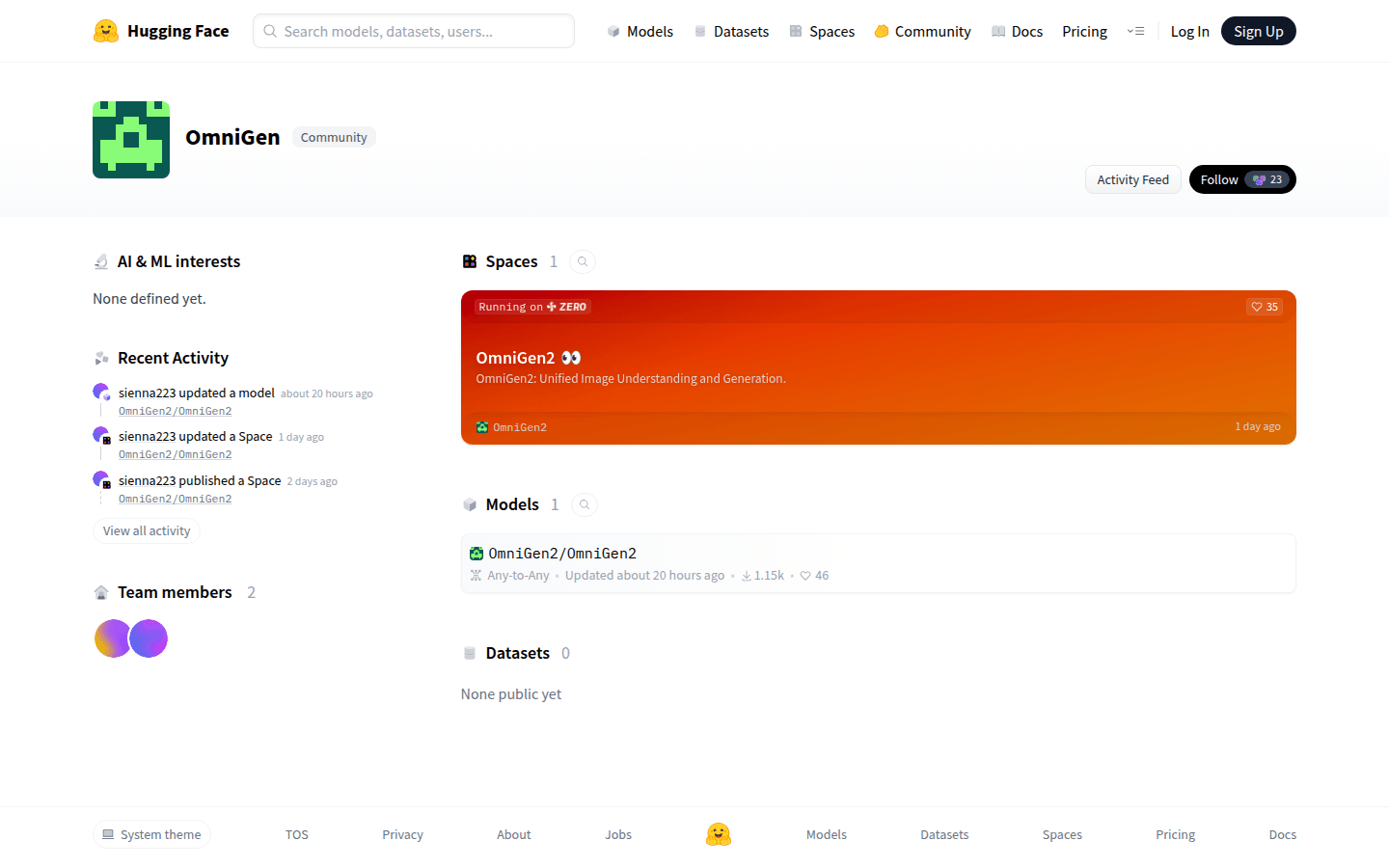
OmniGen2 是一个高效的多模态生成模型,结合了视觉语言模型和扩散模型,能够实现视觉理解、图像生成及编辑等功能。其开源特性为研究人员和开发者提供了强大的基础,助力个性化和可控生成 AI 的探索。
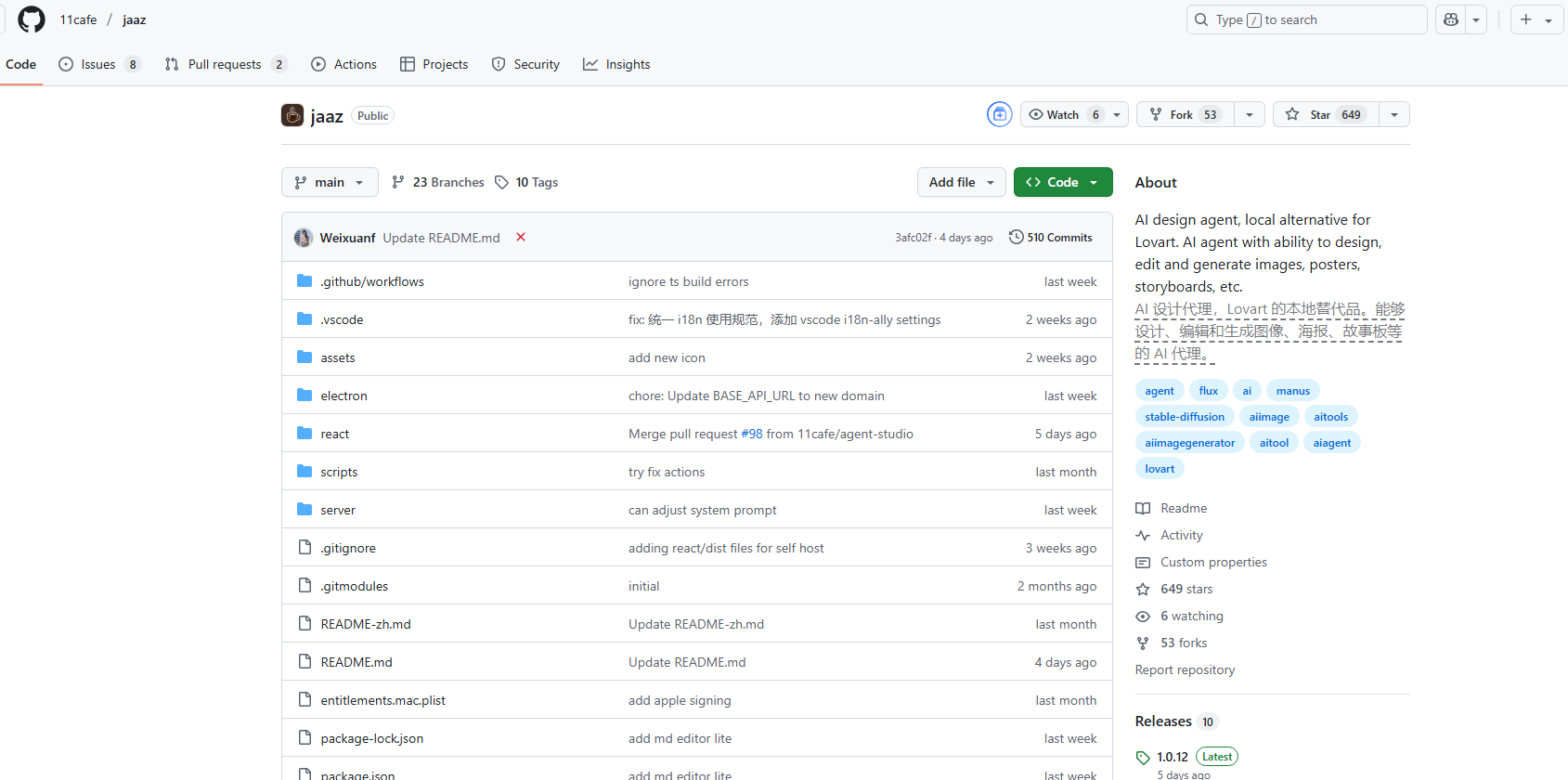
Jaaz 是一款本地免费的 AI 设计代理,旨在为用户提供高效的图像和故事板设计解决方案。它集成了多种 AI 技术,可以快速生成和编辑图像,满足设计师和创作者的需求。Jaaz 支持本地运行,避免了云端服务的限制,用户可以自主使用多种 AI 模型来进行创作。
暗壳 AI 是一款专注于设计领域的 AI 工具,致力于提高设计师的工作效率和降低设计成本。通过丰富的功能和专业级的数据支持,暗壳 AI 帮助用户快速生成高质量的设计效果图及营销素材,适合家居行业等多个领域的应用。价格合理,为用户提供了高效的设计解决方案。
FLUX.1 Kontext是一款革命性的多模态AI模型,将文本指令与图像编辑和生成相结合,实现精准本地化编辑,保持角色一致性和风格连贯性。该产品适用于营销内容创作、电影制作和设计等专业工作流程。
BAGEL是一款可扩展的统一多模态模型,它正在革新AI与复杂系统的交互方式。该模型具有对话推理、图像生成、编辑、风格转移、导航、构图、思考等功能,通过深度学习视频和网络数据进行预训练,为生成高保真度、逼真图像提供了基础。
Blip 3o 是一个基于 Hugging Face 平台的应用程序,利用先进的生成模型从文本生成图像,或对现有图像进行分析和回答。该产品为用户提供了强大的图像生成和理解能力,非常适合设计师、艺术家和开发者。此技术的主要优点是其高效的图像生成速度和优质的生成效果,同时还支持多种输入形式,增强了用户体验。该产品是免费的,定位于开放给广大用户使用。
腾讯混元图像 2.0 是腾讯最新发布的 AI 图像生成模型,显著提升了生成速度和画质。通过超高压缩倍率的编解码器和全新扩散架构,使得图像生成速度可达到毫秒级,避免了传统生成的等待时间。同时,模型通过强化学习算法与人类美学知识的结合,提升了图像的真实感和细节表现,适合设计师、创作者等专业用户使用。
ImageGPT是一个全能平台,提供AI图像生成、增强和编辑工具,包括Flux AI、Recraft AI、Ideogram、Stable Diffusion、DALL-E、Imagen等。它的主要优点在于集成了多种先进AI模型,能够实现高效的图像处理和生成。
DreamO 是一种先进的图像定制模型,旨在提高图像生成的保真度和灵活性。该框架结合了 VAE 特征编码,适用于各种输入,特别是在角色身份的保留方面表现出色。支持消费级 GPU,具有 8 位量化和 CPU 卸载功能,适应不同硬件环境。该模型的不断更新使其在解决过度饱和和面部塑料感问题上取得了一定进展,旨在为用户提供更优质的图像生成体验。
魔法 AI 绘画是一款利用最新的人工智能技术,支持多种生成模式的图像生成工具。用户可以通过文字描述生成图像,或对已有图片进行编辑,享受现代化的用户体验。该产品专注于个人用户和设计师,允许用户自定义生成参数,确保生成的图片符合需求。该应用提供本地数据存储,确保用户的隐私安全。
F Lite 是由 Freepik 和 Fal 开发的一个大型扩散模型,具有 100 亿个参数,专门训练于版权安全和适合工作环境 (SFW) 的内容。该模型基于 Freepik 的内部数据集,包含约 8000 万张合法合规的图像,标志着公开可用的模型在这一规模上首次专注于合法和安全的内容。它的技术报告提供了详细的模型信息,并且使用了 CreativeML Open RAIL-M 许可证进行分发。该模型的设计旨在推动人工智能的开放性和可用性。
Flex.2 是当前最灵活的文本到图像扩散模型,具备内置的重绘和通用控制功能。它是一个开源项目,由社区支持,旨在推动人工智能的民主化。Flex.2 具备 8 亿参数,支持 512 个令牌长度输入,并符合 OSI 的 Apache 2.0 许可证。此模型可以在许多创意项目中提供强大的支持。用户可以通过反馈不断改善模型,推动技术进步。
AI Playground 是一个开源项目,旨在为用户提供 AI 图像创建、图像风格化和聊天机器人的功能。它专为使用 Intel® Arc™ GPU 的 PC 设计,支持多种生成 AI 库和模型。此应用程序的主要优点在于其强大的图像生成能力和便捷的使用体验。适合 AI 开发者、设计师和爱好者,帮助他们探索和利用先进的 AI 技术。该软件为用户提供了自由选择和下载模型的灵活性,适合各种应用场景。
Ghiblio 是基于 ChatGPT 4o 模型的吉卜力风格图像生成器。它可以将文字和图片转化为充满魔力的吉卜力风格插画,支持多种动画风格,提供丰富的创作可能性。Ghiblio 的定价灵活,适合不同需求的用户,提供免费体验和多个付费套餐,满足从普通用户到专业创作者的多样化需求。
Awesome GPT-4o Images 是一个展示 OpenAI 最新多模态模型 GPT-4o 生成的图片和提示的集合。该产品充分展示了 GPT-4o 在文本与图像理解方面的能力,支持多种艺术风格的生成。它适合设计师、艺术创作者和任何对 AI 艺术感兴趣的人。该项目是免费开放的,旨在激发创作灵感并推动 AI 艺术的发展。
UNO 是一个基于扩散变换器的多图像条件生成模型,通过引入渐进式跨模态对齐和通用旋转位置嵌入,实现高一致性的图像生成。其主要优点在于增强了对单一或多个主题生成的可控性,适用于各种创意图像生成任务。
VisualCloze 是一个通过视觉上下文学习的通用图像生成框架,旨在解决传统任务特定模型在多样化需求下的低效率问题。该框架不仅支持多种内部任务,还能泛化到未见过的任务,通过可视化示例帮助模型理解任务。这种方法利用了先进的图像填充模型的强生成先验,为图像生成提供了强有力的支持。
HiDream-I1 是一款新型的开源图像生成基础模型,拥有 170 亿个参数,能够在几秒内生成高质量图像。该模型适用于研究和开发,并在多个评测中表现优异,具有高效性和灵活性,适合用于各种创意设计和生成任务。
EasyControl 是一个为 Diffusion Transformer(扩散变换器)提供高效灵活控制的框架,旨在解决当前 DiT 生态系统中存在的效率瓶颈和模型适应性不足等问题。其主要优点包括:支持多种条件组合、提高生成灵活性和推理效率。该产品是基于最新研究成果开发的,适合在图像生成、风格转换等领域使用。
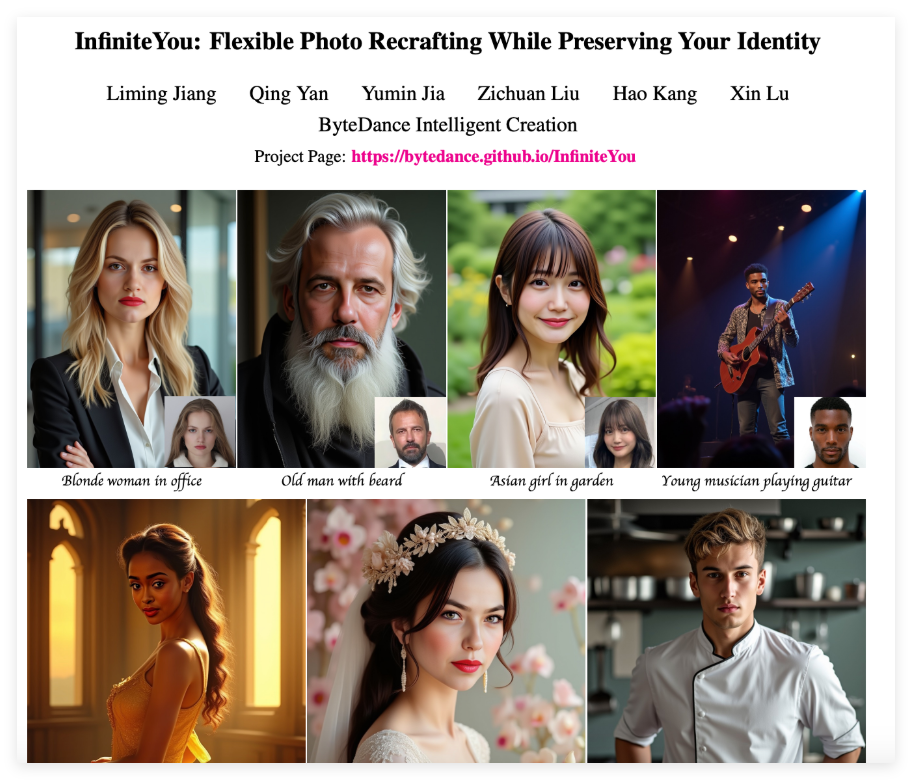
InfiniteYou(InfU)是一个基于扩散变换器的强大框架,旨在实现灵活的图像重构,并保持用户身份。它通过引入身份特征并采用多阶段训练策略,显著提升了图像生成的质量和美学,同时改善了文本与图像的对齐。该技术对提高图像生成的相似性和美观性具有重要意义,适用于各种图像生成任务。
vivago.ai 是一个免费的 AI 生成工具和社区,提供文本转图像、图像转视频等功能,让创作变得更加简单高效。用户可以免费生成高质量的图像和视频,支持多种 AI 编辑工具,方便用户进行创作和分享。该平台的定位是为广大创作者提供易用的 AI 工具,满足他们在视觉创作上的需求。
Midjourney SREF 代码是一项允许用户将特定视觉风格应用于图像生成的功能。使用 SREF 代码可以简化风格描述,使得创作一致的艺术作品变得更加容易。该技术帮助用户探索和分享不同的艺术风格,是 AI 艺术创作的重要工具。
Inductive Moment Matching (IMM) 是一种先进的生成模型技术,主要用于高质量图像生成。该技术通过创新的归纳矩匹配方法,显著提高了生成图像的质量和多样性。其主要优点包括高效性、灵活性以及对复杂数据分布的强大建模能力。IMM 由 Luma AI 和斯坦福大学的研究团队开发,旨在推动生成模型领域的发展,为图像生成、数据增强和创意设计等应用提供强大的技术支持。该项目开源了代码和预训练模型,方便研究人员和开发者快速上手和应用。
Venice 是一个以隐私保护为核心的人工智能平台,提供文本生成、图像生成和代码生成等多种功能。它强调用户数据的私密性,所有数据仅存储在用户设备上,不会上传至服务器。该平台利用领先的开源 AI 技术,提供无审查、无偏见的智能服务,旨在为用户提供一个自由探索创意和知识的环境。Venice 提供免费和付费两种账户选项,付费用户可享受更高分辨率的图像、无水印、无限制的提示次数等高级功能。
Flat Color - Style是一款专为生成扁平色彩风格图像和视频设计的LoRA模型。它基于Wan Video模型训练,具有独特的无线条、低深度效果,适合用于动漫、插画和视频生成。该模型的主要优点是能够减少色彩渗出,增强黑色表现力,同时提供高质量的视觉效果。它适用于需要简洁、扁平化设计的场景,如动漫角色设计、插画创作和视频制作。该模型是免费提供给用户使用的,旨在帮助创作者快速实现具有现代感和简洁风格的视觉作品。
ART 是一种基于深度学习的图像生成技术,专注于生成可变多层透明图像。它通过匿名区域布局和 Transformer 架构,实现了高效的多层图像生成。该技术的主要优点包括高效性、灵活性以及对多层图像生成的支持。它适用于需要精确控制图像层的场景,如图形设计、视觉特效等领域。目前未明确提及价格和具体定位,但其技术特性表明它可能面向专业用户和企业级应用。
CogView4-6B 是由清华大学知识工程组开发的文本到图像生成模型。它基于深度学习技术,能够根据用户输入的文本描述生成高质量的图像。该模型在多个基准测试中表现优异,尤其是在中文文本生成图像方面具有显著优势。其主要优点包括高分辨率图像生成、支持多种语言输入以及高效的推理速度。该模型适用于创意设计、图像生成等领域,能够帮助用户快速将文字描述转化为视觉内容。
CogView4 是由清华大学开发的先进文本到图像生成模型,基于扩散模型技术,能够根据文本描述生成高质量图像。它支持中文和英文输入,并且可以生成高分辨率图像。CogView4 的主要优点是其强大的多语言支持和高质量的图像生成能力,适合需要高效生成图像的用户。该模型在 ECCV 2024 上展示,具有重要的研究和应用价值。
Microsoft Copilot是一款由微软开发的AI助手应用,基于OpenAI和微软的AI技术,旨在为用户提供高效、便捷的智能助手服务。它能够帮助用户快速获取信息、生成文本和图像,提升工作效率和创造力。该应用支持多种语言,界面简洁易用,适合不同用户群体。它不仅适用于个人生活,还能在商业和教育场景中发挥重要作用,是一款免费的生产力工具。
神采AI是一款专注于图像生成与编辑的AI工具,采用先进的AIGC技术,提供多种设计风格和功能,帮助用户快速生成高质量的图像、视频和动画。其主要优点包括操作简单、功能多样、生成效果逼真。该产品面向设计师、市场营销人员、学生等群体,旨在提升设计效率,降低创作门槛。目前提供免费试用服务,适合各类创意工作者。
WHAM(World and Human Action Model)是由微软研究院开发的一种生成式模型,专门用于生成游戏场景和玩家行为。该模型基于Ninja Theory的《Bleeding Edge》游戏数据训练,能够生成连贯、多样化的游戏视觉和控制器动作。WHAM 的主要优点在于其能够捕捉游戏环境的3D结构和玩家行为的时间序列,为游戏设计和创意探索提供了强大的工具。该模型主要面向学术研究和游戏开发领域,帮助开发者快速迭代游戏设计。
Pippo 是由 Meta Reality Labs 和多所高校合作开发的生成模型,能够从单张普通照片生成高分辨率的多人视角视频。该技术的核心优势在于无需额外输入(如参数化模型或相机参数),即可生成高质量的 1K 分辨率视频。它基于多视角扩散变换器架构,具有广泛的应用前景,如虚拟现实、影视制作等。Pippo 的代码已开源,但不包含预训练权重,用户需要自行训练模型。
Krea Chat 是一款基于 AI 的设计工具,通过聊天界面提供强大的设计功能。它结合了 DeepSeek 的 AI 技术和 Krea 的设计工具套件,用户可以通过自然语言交互生成图像、视频等设计内容。这种创新的交互方式极大地简化了设计流程,降低了设计门槛,使用户能够快速实现创意。Krea Chat 的主要优点包括易于使用、高效生成设计内容以及强大的 AI 驱动功能。它适合需要快速生成设计素材的创作者、设计师和市场营销人员,能够帮助他们节省时间并提升工作效率。
Janus Pro 是由 DeepSeek 技术驱动的先进 AI 图像生成与理解平台。它采用革命性的统一变换器架构,能够高效处理复杂的多模态操作,实现图像生成和理解的卓越性能。该平台训练了超过 9000 万个样本,其中包括 7200 万个合成美学数据点,确保生成的图像在视觉上具有吸引力且上下文准确。Janus Pro 为开发者和研究人员提供强大的视觉 AI 能力,帮助他们实现从创意到视觉叙事的转变。平台提供免费试用,适合需要高质量图像生成和分析的用户。
该产品利用 Gemini 2.0 语言模型和 Google Imagen 图像生成技术,结合语音识别和语音合成,为用户提供一个互动式的故事创作体验。用户可以通过语音输入选择故事走向,系统会实时生成故事内容和相关图像。该产品的主要优点是创新的交互方式和强大的内容生成能力,适合用于教育、娱乐和创意启发。目前该产品处于开源阶段,未明确具体定价,主要面向开发者和教育机构。
SliderSpace 是一项创新技术,旨在提高扩散模型的可控性和可解释性。它通过自动发现模型内部的视觉知识,将其分解为直观的滑块,用户可以通过这些滑块轻松调整图像生成的方向。该技术不仅能够揭示模型对不同概念的理解,还能显著提高图像生成的多样性。SliderSpace 的主要优点包括自动化发现方向、语义正交性和分布一致性,使其成为探索和利用扩散模型视觉能力的强大工具。该技术目前处于研究阶段,尚未明确具体的价格和商业定位。
Google Imagen 3是Google推出的图像生成模型,通过Gemini API向开发者开放。它能够根据用户输入的文本提示生成高质量图像,支持多种艺术风格,如超现实主义、印象派、抽象艺术等。该模型在图像细节和色彩处理上表现出色,适用于艺术创作、广告设计、游戏开发等创意工作。其主要优点包括高效的提示跟踪能力、丰富的自定义选项以及成本效益。此外,为防止误用,所有生成图像均带有不可见水印。定价为每张图像0.03美元,适合需要批量生成图像的开发者和企业。
Animagine XL 4.0 是一款基于Stable Diffusion XL 1.0微调的动漫主题生成模型。它使用了840万张多样化的动漫风格图像进行训练,训练时长达到2650小时。该模型专注于通过文本提示生成和修改动漫主题图像,支持多种特殊标签,可控制图像生成的不同方面。其主要优点包括高质量的图像生成、丰富的动漫风格细节以及对特定角色和风格的精准还原。该模型由Cagliostro Research Lab开发,采用CreativeML Open RAIL++-M许可证,允许商业使用和修改。
Janus-Pro-7B 是一个强大的多模态模型,能够同时处理文本和图像数据。它通过分离视觉编码路径,解决了传统模型在理解和生成任务中的冲突,提高了模型的灵活性和性能。该模型基于 DeepSeek-LLM 架构,使用 SigLIP-L 作为视觉编码器,支持 384x384 的图像输入,并在多模态任务中表现出色。其主要优点包括高效性、灵活性和强大的多模态处理能力。该模型适用于需要多模态交互的场景,例如图像生成和文本理解。
Janus-Pro-1B 是一个创新的多模态模型,专注于统一多模态理解和生成。它通过分离视觉编码路径,解决了传统方法在理解和生成任务中的冲突问题,同时保持了单个统一的 Transformer 架构。这种设计不仅提高了模型的灵活性,还使其在多模态任务中表现出色,甚至超越了特定任务的模型。该模型基于 DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base 构建,使用 SigLIP-L 作为视觉编码器,支持 384x384 的图像输入,并采用特定的图像生成 tokenizer。其开源性和灵活性使其成为下一代多模态模型的有力候选。
Fashion-Hut-Modeling-LoRA是一个基于Diffusion技术的文本到图像生成模型,主要用于生成时尚模特的高质量图像。该模型通过特定的训练参数和数据集,能够根据文本提示生成具有特定风格和细节的时尚摄影图像。它在时尚设计、广告制作等领域具有重要应用价值,能够帮助设计师和广告商快速生成创意概念图。模型目前仍在训练阶段,可能存在一些生成效果不佳的情况,但已经展示了强大的潜力。该模型的训练数据集包含14张高分辨率图像,使用了AdamW优化器和constant学习率调度器等参数,训练过程注重图像的细节和质量。
TokenVerse 是一种创新的多概念个性化方法,它利用预训练的文本到图像扩散模型,能够从单张图像中解耦复杂的视觉元素和属性,并实现无缝的概念组合生成。这种方法突破了现有技术在概念类型或广度上的限制,支持多种概念,包括物体、配饰、材质、姿势和光照等。TokenVerse 的重要性在于其能够为图像生成领域带来更灵活、更个性化的解决方案,满足用户在不同场景下的多样化需求。目前,TokenVerse 的代码尚未公开,但其在个性化图像生成方面的潜力已经引起了广泛关注。
Brat Generator是一个以Charli XCX的专辑封面风格为灵感的在线图像生成工具。它允许用户通过输入文本和选择背景颜色,快速生成具有个性化的专辑封面风格图像。该工具的主要优点是操作简单、快速生成图像,并且可以自定义字体风格和颜色。它适合那些希望在社交媒体上分享个性化图像的用户,尤其是音乐爱好者和创意内容创作者。目前该工具是免费的,旨在为用户提供一种轻松创建独特图像的方式。
AI ContentCraft 是一个强大的内容创作平台,旨在帮助创作者快速生成故事、播客脚本和多媒体内容。它通过集成文本生成、语音合成和图像生成技术,为创作者提供一站式的解决方案。该工具支持中英文内容转换,适合需要高效创作的用户。其技术栈包括 DeepSeek AI、Kokoro TTS 和 Replicate API,确保高质量的内容生成。产品目前开源免费,适合个人和团队使用。
Flex.1-alpha 是一个强大的文本到图像生成模型,基于80亿参数的修正流变换器架构。它继承了FLUX.1-schnell的特性,并通过训练指导嵌入器,使其无需CFG即可生成图像。该模型支持微调,并且具有开放源代码许可(Apache 2.0),适合在多种推理引擎中使用,如Diffusers和ComfyUI。其主要优点包括高效生成高质量图像、灵活的微调能力和开源社区支持。开发背景是为了解决图像生成模型的压缩和优化问题,并通过持续训练提升模型性能。
FLUX Pro Finetuning API 是由 Black Forest Labs 推出的生成式文本到图像模型的定制化工具。它允许用户通过少量示例图像(1-5张)对 FLUX Pro 模型进行微调,从而生成符合特定品牌、风格或视觉需求的高质量图像内容。该技术的主要优点在于其高度的定制化能力、对品牌一致性的保持以及与 FLUX 工具套件的无缝集成。它适用于专业创意人员、设计师和品牌方,帮助他们在营销、品牌建设和故事叙述中实现个性化内容创作。目前尚无明确价格信息,但其定位为高端创意工具,适合对生成内容质量有较高要求的用户。
Frames 是 Runway 的核心产品之一,专注于图像生成领域。它通过深度学习技术,为用户提供高度风格化的图像生成能力。该模型允许用户定义独特的艺术视角,生成具有高度视觉保真度的图像。其主要优点包括强大的风格控制能力、高质量的图像输出以及灵活的创作空间。Frames 面向创意专业人士、艺术家和设计师,旨在帮助他们快速实现创意构思,提升创作效率。Runway 提供了多种使用场景和工具支持,用户可以根据需求选择不同的功能模块。价格方面,Runway 提供了付费和免费试用的选项,以满足不同用户的需求。
Procyon AI Image Generation Benchmark 是一款由 UL Solutions 开发的基准测试工具,旨在为专业用户提供一个一致、准确且易于理解的工作负载,用以测量设备上 AI 加速器的推理性能。该基准测试与多个关键行业成员合作开发,确保在所有支持的硬件上产生公平且可比较的结果。它包括三个测试,可测量从低功耗 NPU 到高端独立显卡的性能。用户可以通过 Procyon 应用程序或命令行进行配置和运行,支持 NVIDIA® TensorRT™、Intel® OpenVINO™ 和 ONNX with DirectML 等多种推理引擎。产品主要面向工程团队,适用于评估推理引擎实现和专用硬件的通用 AI 性能。价格方面,提供免费试用,正式版为年度场地许可,需付费获取报价。
Grok是由xAI开发的AI助手,旨在提供真实、有用且富有好奇心的交互体验。它能够回答各种问题、生成引人注目的图像,并通过上传图片帮助用户更深入地了解世界。Grok强调隐私保护,所有数据交互都以用户隐私为重,确保安全体验。它集成了X平台的数据,专注于实时信息,是寻求AI助手用户的理想选择。该应用免费提供给用户,适合需要高效获取信息和创意灵感的人群。
CreatiLayout是一种创新的布局到图像生成技术,利用孪生多模态扩散变换器(Siamese Multimodal Diffusion Transformer)来实现高质量和细粒度可控的图像生成。该技术能够精确渲染复杂的属性,如颜色、纹理、形状、数量和文本,适用于需要精确布局和图像生成的应用场景。其主要优点包括高效的布局引导集成、强大的图像生成能力和大规模数据集的支持。CreatiLayout由复旦大学和字节跳动公司联合开发,旨在推动图像生成技术在创意设计领域的应用。
Dreamina是一个AI影像生成平台,通过先进的AI技术,用户可以将简单的文字提示转化为精美的图像和艺术作品。该产品的主要优点在于其强大的语义理解和创造力,能够准确把握用户的创意需求,生成高质量的视觉内容。Dreamina适合各种创意需求,如角色设计、时尚美容、游戏素材等,帮助用户节省时间和成本,提升创作效率。产品目前免费提供给用户,旨在激发用户的创造力和灵感。
Free OG Image Generator 是一个在线工具,旨在帮助用户快速生成用于社交媒体的高质量预览图像,如 Open Graph 图像、Twitter/X 头图等。该工具的主要优点在于其简单易用且完全免费,用户无需注册即可访问所有功能。它提供了多种专业设计的模板,支持自定义背景、渐变色、网格叠加等高级功能,能够满足不同用户的设计需求。该工具的背景信息显示其由开发者 Jude Wei 创建,旨在为用户提供一个无需复杂软件即可快速制作专业图像的平台。
TryOffAnyone是一个用于从穿着人身上生成平铺布料的深度学习模型。该模型能够将穿着衣物的人的图片转换成布料平铺图,这对于服装设计、虚拟试衣等领域具有重要意义。它通过深度学习技术,实现了高度逼真的布料模拟,使得用户可以更直观地预览衣物的穿着效果。该模型的主要优点包括逼真的布料模拟效果和较高的自动化程度,可以减少实际试衣过程中的时间和成本。
1.58-bit FLUX是一种先进的文本到图像生成模型,通过使用1.58位权重(即{-1, 0, +1}中的值)来量化FLUX.1-dev模型,同时保持生成1024x1024图像的可比性能。该方法无需访问图像数据,完全依赖于FLUX.1-dev模型的自监督。此外,开发了一种定制的内核,优化了1.58位操作,实现了模型存储减少7.7倍,推理内存减少5.1倍,并改善了推理延迟。在GenEval和T2I Compbench基准测试中的广泛评估表明,1.58-bit FLUX在保持生成质量的同时显著提高了计算效率。
Story-Adapter是一个无需训练的迭代框架,专为长篇故事可视化设计。它通过迭代范式和全局参考交叉注意力模块,优化图像生成过程,保持故事中语义的连贯性,同时减少计算成本。该技术的重要性在于它能够在长篇故事中生成高质量、细节丰富的图像,解决了传统文本到图像模型在长故事可视化中的挑战,如语义一致性和计算可行性。
DiffSensei是一个结合了多模态大型语言模型(LLMs)和扩散模型的定制化漫画生成模型。它能够根据用户提供的文本提示和角色图像,生成可控制的黑白漫画面板,并具有灵活的角色适应性。这项技术的重要性在于它将自然语言处理与图像生成相结合,为漫画创作和个性化内容生成提供了新的可能性。DiffSensei模型以其高质量的图像生成、多样化的应用场景以及对资源的高效利用而受到关注。目前,该模型在GitHub上公开,可以免费下载使用,但具体的使用可能需要一定的计算资源。
FaceMimic AI是一款利用先进AI技术将自拍照片转换成专业头像的服务。无需专业摄影师或昂贵设备,用户只需上传自拍,即可在60秒内获得高质量的头像,适用于LinkedIn、社交媒体、个人使用等多种场景。产品背景信息显示,该技术能显著提升个人在职业网络中的可见度,增加面试机会,适用于职业发展、商业形象构建、社交分享和约会应用等多个领域。价格方面,提供免费试用,并根据不同的使用需求提供不同的套餐。
API.box是一个提供先进AI接口的平台,旨在帮助开发者快速集成AI功能到他们的项目中。它提供全面的API文档和详细的调用日志,确保高效开发和系统性能稳定。API.box具备企业级安全性和强大可扩展性,支持高并发需求,同时提供免费试用和商业用途的输出许可,是开发者和企业的理想选择。
Pokecut AI Background Remover是一款利用人工智能技术实现一键去除图片背景的工具。它能够处理各种复杂背景和细节丰富的图像,无论是肖像、产品、动物、标志还是签名,都能精确抠图。该工具的主要优点包括高精度、高精确度、适应性强、支持多主体图像以及快速处理。产品背景信息显示,它不仅提供了背景移除功能,还提供了背景更换功能,并且有多种专业背景模板可供选择,以提升产品照片的专业度并增加销售额。
头像定制是一个提供个性化手绘头像服务的网站。它允许用户上传自己的照片,由专业的绘画师根据照片绘制出风格独特的头像。这种服务不仅满足了用户在社交平台上展示个性化形象的需求,也因其艺术性和独特性而受到欢迎。产品背景信息显示,该服务由经验丰富的绘画师提供,包括首席绘画师jissacos和新秀kiki等,他们擅长捕捉面部表情和个人特色。价格方面,根据绘画师的不同,提供不同价位的服务,用户可以根据自己的预算和喜好选择合适的服务。
Grok是一个由X.AI Corp开发的AI助手应用,旨在提供最真实、有用和好奇的答案。用户可以通过Grok获取任何问题的答案、生成引人注目的图像,并上传图片以更深入地了解世界。Grok以其高质量的图像生成、实时更新的数据、对话式的幽默语气和注重隐私的特性,为用户提供了一个安全、高效的AI体验平台。
CAP4D是一种利用可变形多视图扩散模型(Morphable Multi-View Diffusion Models)来创建4D人像化身的技术。它能够从任意数量的参考图像生成不同视角和表情的图像,并将其适配到一个4D化身上,该化身可以通过3DMM控制并实时渲染。这项技术的主要优点包括高度逼真的图像生成、多视角的适应性以及实时渲染的能力。CAP4D的技术背景是基于深度学习和图像生成领域的最新进展,尤其是在扩散模型和3D面部建模方面。由于其高质量的图像生成和实时渲染能力,CAP4D在娱乐、游戏开发、虚拟现实等领域具有广泛的应用前景。目前,该技术是免费提供代码的,但具体的商业化应用可能需要进一步的授权和定价。
Artedge AI是一个提供前沿AI工具的平台,旨在提升用户的创意过程。平台提供AI艺术生成器和AI亲吻生成器等工具,以快速生成高分辨率、高质量的艺术作品。这些工具不仅能够加速创意实现,还能提供独特的艺术体验,适合设计师、艺术家和创意爱好者。平台还提供定价计划,用户可以根据自己的需求选择合适的服务。
Gemini 2.0 Flash Experimental是Google DeepMind开发的最新AI模型,旨在提供低延迟和增强性能的智能代理体验。该模型支持原生工具使用,并首次能够原生创建图像和生成语音,代表了AI技术在理解和生成多媒体内容方面的重要进步。Gemini Flash模型家族以其高效的处理能力和广泛的应用场景,成为推动AI领域发展的关键技术之一。
ComfyUI-IF_MemoAvatar是一个基于记忆引导扩散的模型,用于生成表达性的视频。该技术允许用户从单一图像和音频输入创建富有表现力的说话头像视频。这项技术的重要性在于其能够将静态图像转化为动态视频,同时保留图像中人物的面部特征和情感表达,为视频内容创作提供了新的可能性。该模型由Longtao Zheng等人开发,并在arXiv上发布相关论文。
GenEx是一个AI模型,它能够从单张图片创建一个完全可探索的360°3D世界。用户可以互动地探索这个生成的世界。GenEx在想象空间中推进具身AI,并有潜力将这些能力扩展到现实世界的探索。
Leffa是一个用于可控人物图像生成的统一框架,它能够精确控制人物的外观(例如虚拟试穿)和姿态(例如姿态转移)。该模型通过在训练期间引导目标查询关注参考图像中的相应区域,减少细节扭曲,同时保持高图像质量。Leffa的主要优点包括模型无关性,可以用于提升其他扩散模型的性能。
fofr/flux-condensation是一个基于文本生成图像的AI模型,使用Diffusers库和LoRAs技术,能够根据用户提供的文本提示生成相应的图像。该模型在Replicate上训练,具有非商业性质的flux-1-dev许可证。它代表了文本到图像生成技术的最新进展,能够为设计师、艺术家和内容创作者提供强大的视觉表现工具。
HelloMeme是一个集成了空间编织注意力(Spatial Knitting Attentions)的扩散模型,用于嵌入高级别和细节丰富的条件。该模型支持图像和视频的生成,具有改善生成视频与驱动视频之间表情一致性、减少VRAM使用、优化算法等优点。HelloMeme由HelloVision团队开发,属于HelloGroup Inc.,是一个前沿的图像和视频生成技术,具有重要的商业和教育价值。
Sana是一个由NVIDIA开发的文本到图像的生成框架,能够高效生成高达4096×4096分辨率的图像。Sana以其快速的速度和强大的文本图像对齐能力,可以在笔记本电脑GPU上部署,代表了图像生成技术的一个重要进步。该模型基于线性扩散变换器,使用预训练的文本编码器和空间压缩的潜在特征编码器,能够根据文本提示生成和修改图像。Sana的开源代码可在GitHub上找到,其研究和应用前景广阔,尤其在艺术创作、教育工具和模型研究等方面。
Interstice是一个开源的Krita插件,专为专业绘画应用Krita设计,旨在提供精确控制和高效的工作流程。它允许用户通过选择特定区域来编辑照片和艺术作品,生成的结果能够无缝融合。此外,Interstice.cloud是一个在线图像生成服务,旨在让AI辅助绘画立即对每个人开放。该产品背景信息显示,它是一个100%免费的本地硬件产品,不需要GPU,易于下载和使用。
shou_xin是一个基于文本到图像的生成模型,它能够根据用户提供的文本提示生成具有手訫风格的铅笔素描图像。这个模型使用了diffusers库和lora技术,以实现高质量的图像生成。shou_xin模型以其独特的艺术风格和高效的图像生成能力在图像生成领域占有一席之地,特别适合需要快速生成具有特定艺术风格的图像的用户。














![FLUX.1 Krea [dev]](https://pic.chinaz.com/ai/2025/08/01/25080110475283667344.jpg)