找到 113 个相关的AI工具
MemU是一款为AI伴侣设计的智能记忆层,提供更高的准确性、更快的检索速度和更低的成本。它是一个开源的AI记忆框架,适用于机器学习、神经网络、对话AI、聊天机器人记忆、AI代理和自主记忆。
mcp-use 是一个开源的 MCP 客户端库,旨在帮助开发者将任何大型语言模型(LLM)连接到 MCP 工具,构建具有工具访问能力的自定义代理,而无需使用闭源或应用程序客户端。该产品提供了简单易用的 API 和强大的功能,可以应用于多个领域。
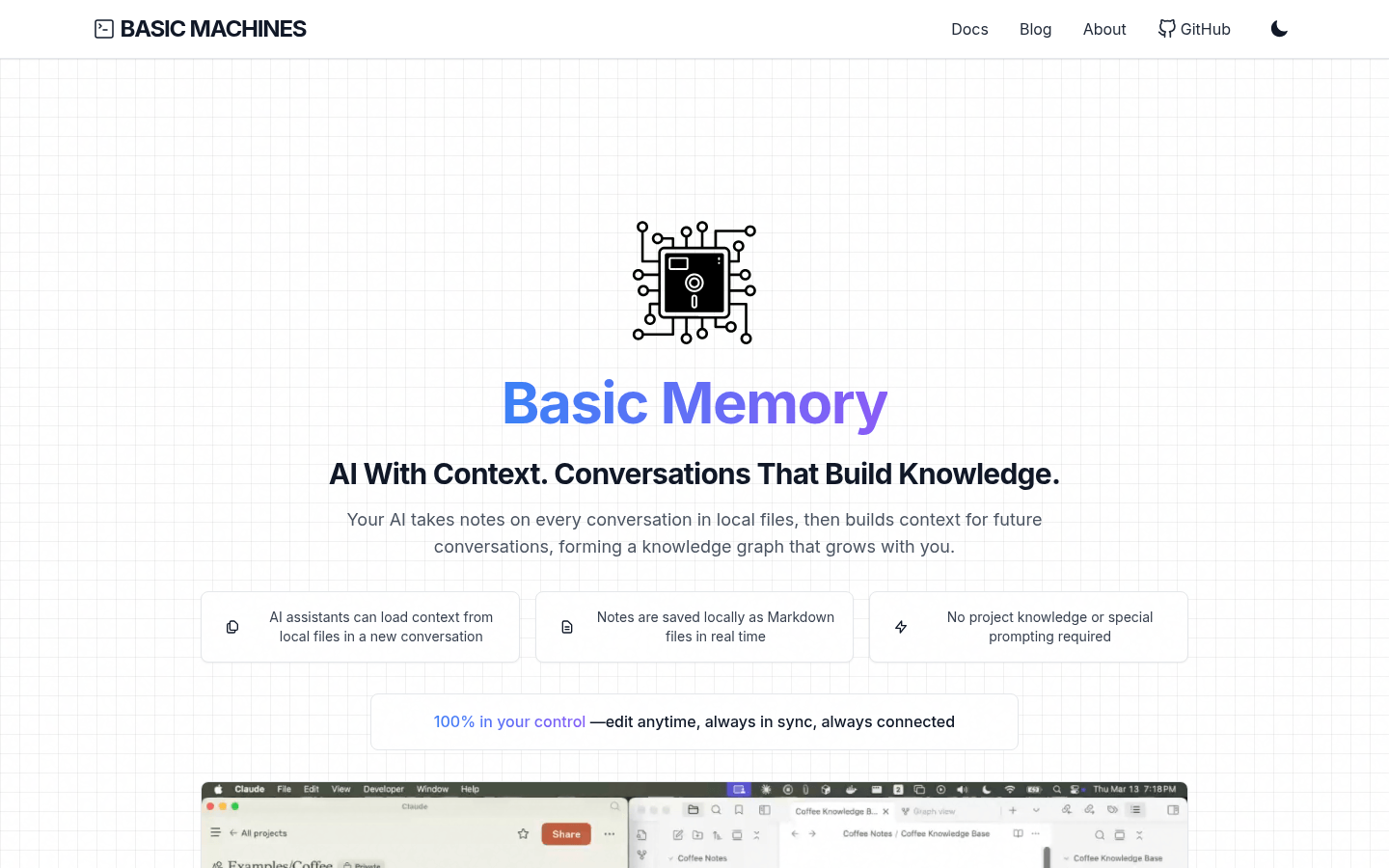
Basic Memory是一款知识管理系统,借助与LLM的自然对话构建持久知识,并保存于本地Markdown文件。它解决了多数LLM互动短暂、知识难留存的问题。其优点包括本地优先、双向读写、结构简单、可形成知识图谱、兼容现有编辑器、基础设施轻量。定位为帮助用户打造个人知识库,采用AGPL - 3.0许可证,无明确价格信息。
OpenAI Agents SDK是一个用于构建多智能体工作流的框架。它允许开发者通过配置指令、工具、安全机制和智能体之间的交接来创建复杂的自动化流程。该框架支持与任何符合OpenAI Chat Completions API格式的模型集成,具有高度的灵活性和可扩展性。它主要用于编程场景中,帮助开发者快速构建和优化智能体驱动的应用程序。
Awesome-LLM-Post-training 是一个专注于大型语言模型(LLM)后训练方法的资源库。它提供了关于 LLM 后训练的深入研究,包括教程、调查和指南。该资源库基于论文《LLM Post-Training: A Deep Dive into Reasoning Large Language Models》,旨在帮助研究人员和开发者更好地理解和应用 LLM 后训练技术。该资源库免费开放,适合学术研究和工业应用。
l1m是一个强大的工具,它通过代理的方式利用大型语言模型(LLMs)从非结构化的文本或图像中提取结构化的数据。这种技术的重要性在于它能够将复杂的信息转化为易于处理的格式,从而提高数据处理的效率和准确性。l1m的主要优点包括无需复杂的提示工程、支持多种LLM模型以及内置缓存功能等。它由Inferable公司开发,旨在为用户提供一个简单、高效且灵活的数据提取解决方案。l1m提供免费试用,适合需要从大量非结构化数据中提取有价值信息的企业和开发者。
LLMs.txt生成器是一个由Firecrawl提供支持的在线工具,旨在帮助用户从网站生成用于LLM训练和推理的整合文本文件。它通过整合网页内容,为训练大型语言模型提供高质量的文本数据,从而提高模型的性能和准确性。该工具的主要优点是操作简单、高效,能够快速生成所需的文本文件。它主要面向需要大量文本数据进行模型训练的开发者和研究人员,为他们提供了一种便捷的解决方案。
hugo-translator是一个基于大型语言模型(LLM)驱动的文章翻译工具。它能够自动将文章从一种语言翻译为另一种语言,并生成新的Markdown文件。该工具支持OpenAI和DeepSeek的模型,用户可以通过简单的配置和命令快速完成翻译任务。它主要面向使用Hugo静态网站生成器的用户,帮助他们快速实现多语言内容的生成和管理。产品目前免费开源,旨在提高内容创作者的效率,降低多语言内容发布的门槛。
Aviator Agents 是一款专注于代码迁移的编程工具。它通过集成LLM技术,能够直接与GitHub连接,支持多种模型,如Open-AI o1、Claude Sonnet 3.5、Llama 3.1和DeepSeek R1。该工具可以自动执行代码迁移任务,包括搜索代码依赖、优化代码、生成PR等,极大提高了代码迁移的效率和准确性。它主要面向开发团队,帮助他们高效完成代码迁移工作,节省时间和精力。
llm-commit 是一个为 LLM(Large Language Model)设计的插件,用于生成 Git 提交信息。该插件通过分析 Git 的暂存区差异,利用 LLM 的语言生成能力,自动生成简洁且有意义的提交信息。它不仅提高了开发者的提交效率,还确保了提交信息的质量和一致性。该插件适用于任何使用 Git 和 LLM 的开发环境,免费开源,易于安装和使用。
Crawl4LLM是一个开源的网络爬虫项目,旨在为大型语言模型(LLM)的预训练提供高效的数据爬取解决方案。它通过智能选择和爬取网页数据,帮助研究人员和开发者获取高质量的训练语料。该工具支持多种文档评分方法,能够根据配置灵活调整爬取策略,以满足不同的预训练需求。项目基于Python开发,具有良好的扩展性和易用性,适合在学术研究和工业应用中使用。
该产品是一个由Vectara开发的开源项目,用于评估大型语言模型(LLM)在总结短文档时的幻觉产生率。它使用了Vectara的Hughes幻觉评估模型(HHEM-2.1),通过检测模型输出中的幻觉来计算排名。该工具对于研究和开发更可靠的LLM具有重要意义,能够帮助开发者了解和改进模型的准确性。
VisionAgent是一个强大的工具,它利用人工智能和大语言模型(LLM)来生成代码,帮助用户快速解决视觉任务。该工具的主要优点是能够自动将复杂的视觉任务转化为可执行的代码,极大地提高了开发效率。VisionAgent支持多种LLM提供商,用户可以根据自己的需求选择不同的模型。它适用于需要快速开发视觉应用的开发者和企业,能够帮助他们在短时间内实现功能强大的视觉解决方案。VisionAgent目前是免费的,旨在为用户提供高效、便捷的视觉任务处理能力。
OmniParser V2 是微软研究团队开发的一种先进的人工智能模型,旨在将大型语言模型(LLM)转化为能够理解和操作图形用户界面(GUI)的智能代理。该技术通过将界面截图从像素空间转换为可解释的结构化元素,使 LLM 能够更准确地识别可交互图标,并在屏幕上执行预定动作。OmniParser V2 在检测小图标和快速推理方面取得了显著进步,其结合 GPT-4o 在 ScreenSpot Pro 基准测试中达到了 39.6% 的平均准确率,远超原始模型的 0.8%。此外,OmniParser V2 还提供了 OmniTool 工具,支持与多种 LLM 结合使用,进一步推动了 GUI 自动化的发展。
Supametas.AI是一款专注于非结构化数据处理的平台,旨在帮助企业快速将音频、视频、图片、文本等多种格式的数据转化为适用于LLM RAG知识库的结构化数据。该平台通过提供多种数据采集方式和强大的预处理功能,极大地简化了数据处理流程,降低了企业构建行业数据集的门槛。其无缝集成到LLM RAG知识库的能力,使得企业能够更高效地利用数据驱动业务发展。Supametas.AI的定位是成为行业领先的LLM数据结构化处理开发平台,满足企业在数据隐私和灵活性方面的需求。
该产品是一个全栈应用,通过LLM(大型语言模型)和LangChain技术,结合LangGraph实现股票数据和新闻的检索与分析。它利用ChromaDB作为向量数据库,支持语义搜索和数据可视化,为用户提供股票市场的深入洞察。该产品主要面向投资者、金融分析师和数据科学家,帮助他们快速获取和分析股票相关信息,辅助决策。产品目前开源免费,适合需要高效处理金融数据和新闻的用户。
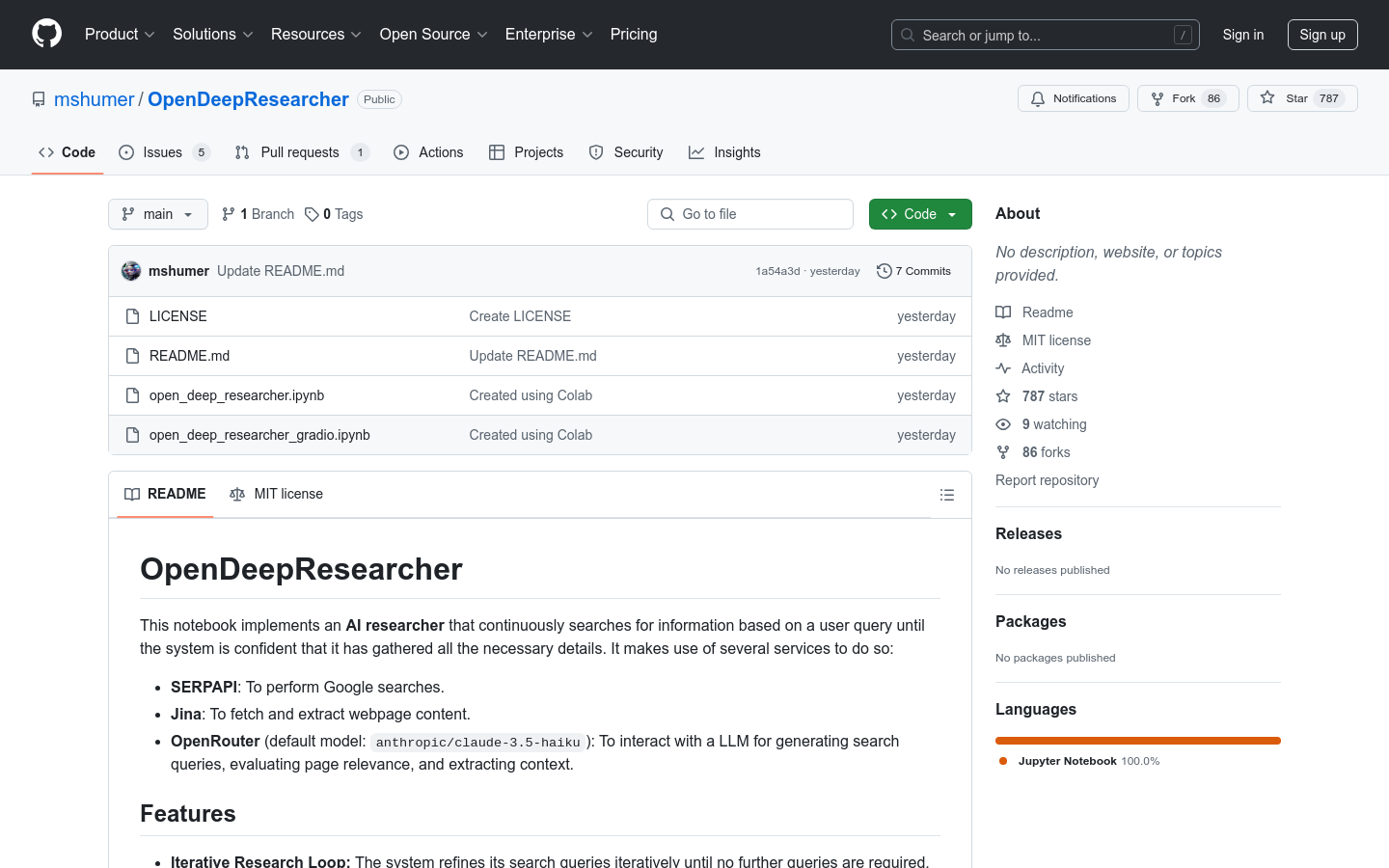
OpenDeepResearcher 是一个基于 AI 的研究工具,通过结合 SERPAPI、Jina 和 OpenRouter 等服务,能够根据用户输入的查询主题,自动进行多轮迭代搜索,直至收集到足够的信息并生成最终报告。该工具的核心优势在于其高效的异步处理能力、去重功能以及强大的 LLM 决策支持,能够显著提升研究效率。它主要面向需要进行大量文献搜索和信息整理的科研人员、学生以及相关领域的专业人士,帮助他们快速获取高质量的研究资料。该工具目前以开源形式提供,用户可以根据需要自行部署和使用。
DocETL是一个强大的系统,用于处理和分析大量文本数据。它通过利用大型语言模型(LLM)的能力,能够自动优化数据处理流程,并将LLM与非LLM操作无缝集成。该系统的主要优点包括其声明式的YAML定义方式,使得用户可以轻松地定义复杂的数据处理流程。此外,DocETL还提供了一个交互式的playground,方便用户进行提示工程的实验。产品背景信息显示,DocETL在2024年12月推出了DocWrangler,这是一个新的交互式playground,旨在简化提示工程。价格方面,虽然没有明确标出,但从提供的使用案例来看,运行和优化数据处理流程的成本相对较低。产品定位主要是为需要处理大量文本数据并从中提取有价值信息的用户提供服务。
DocWrangler是一个开源的交互式开发环境,旨在简化构建和优化基于大型语言模型(LLM)的数据处理管道的过程。它提供即时反馈、可视化探索工具和AI辅助功能,帮助用户更容易地探索数据、实验不同操作并根据发现优化管道。该产品基于DocETL框架构建,适用于处理非结构化数据,如文本分析、信息提取等。它不仅降低了LLM数据处理的门槛,还提高了工作效率,使用户能够更有效地利用LLM的强大功能。
mlabonne/llm-datasets 是一个专注于大型语言模型(LLM)微调的高质量数据集和工具的集合。该产品为研究人员和开发者提供了一系列经过精心筛选和优化的数据集,帮助他们更好地训练和优化自己的语言模型。其主要优点在于数据集的多样性和高质量,能够覆盖多种使用场景,从而提高模型的泛化能力和准确性。此外,该产品还提供了一些工具和概念,帮助用户更好地理解和使用这些数据集。其背景信息包括由 mlabonne 创建和维护,旨在推动 LLM 领域的发展。
FlashInfer是一个专为大型语言模型(LLM)服务而设计的高性能GPU内核库。它通过提供高效的稀疏/密集注意力机制、负载平衡调度、内存效率优化等功能,显著提升了LLM在推理和部署时的性能。FlashInfer支持PyTorch、TVM和C++ API,易于集成到现有项目中。其主要优点包括高效的内核实现、灵活的自定义能力和广泛的兼容性。FlashInfer的开发背景是为了满足日益增长的LLM应用需求,提供更高效、更可靠的推理支持。
llmstxt-generator 是一个用于生成LLM(大型语言模型)训练和推理所需的网站内容整合文本文件的工具。它通过爬取网站内容,将其合并成一个文本文件,支持生成标准的llms.txt和完整的llms-full.txt版本。该工具由firecrawl_dev提供支持进行网页爬取,并使用GPT-4-mini进行文本处理。其主要优点包括无需API密钥即可使用基本功能,同时提供Web界面和API访问,方便用户快速生成所需的文本文件。
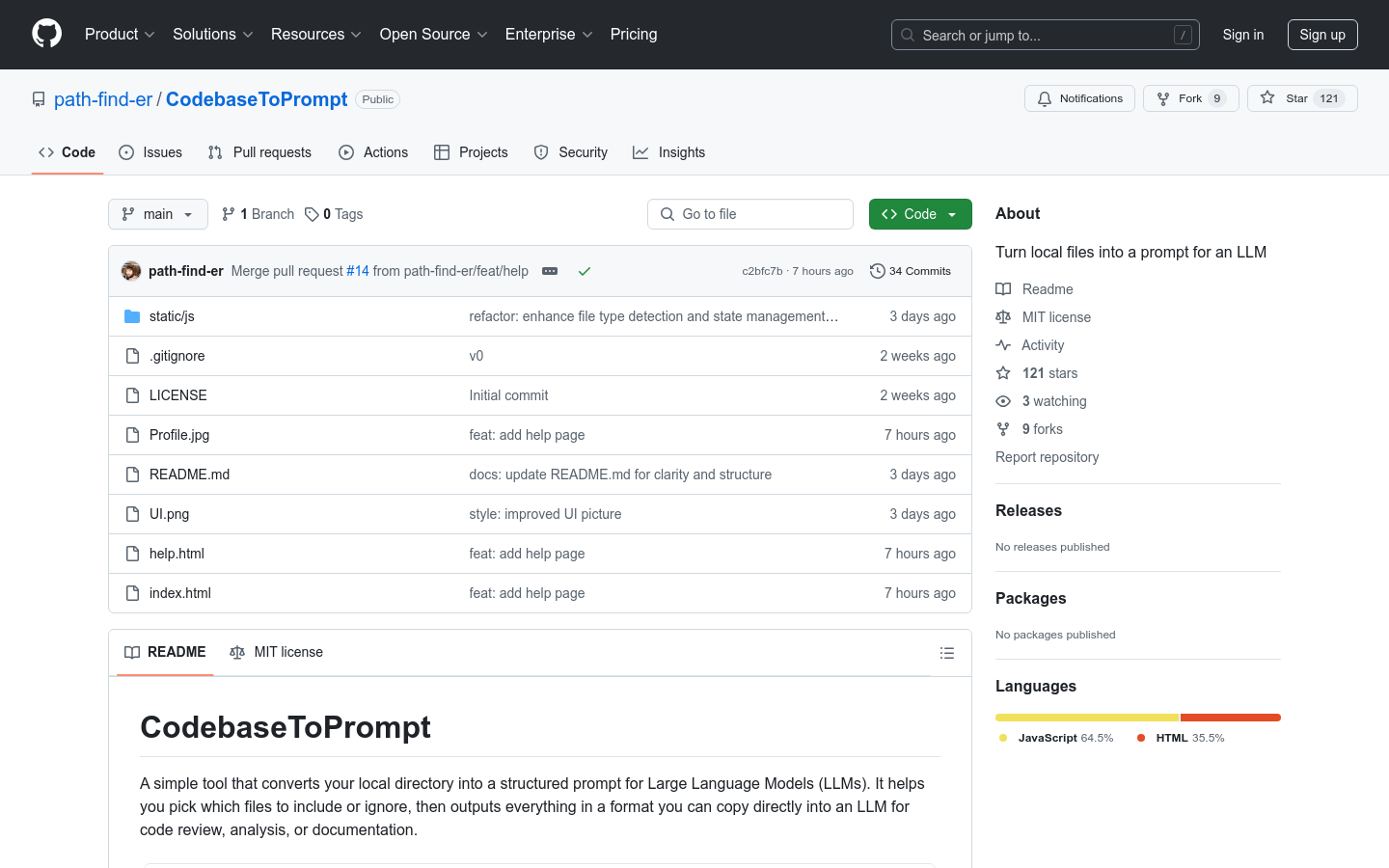
CodebaseToPrompt 是一个简单工具,能够将本地目录转换为大型语言模型(LLM)的结构化提示。它帮助用户选择需要包含或忽略的文件,然后以可以直接复制到 LLM 中的格式输出,适用于代码审查、分析或文档生成。该工具的主要优点在于其交互性强、操作简便,并且能够在浏览器中直接使用,无需上传任何文件,确保了数据的安全性和隐私性。产品背景信息显示,它是由 path-find-er 团队开发,旨在提高开发者在使用 LLM 进行代码相关任务时的效率。
Document Inlining是Fireworks AI推出的一款复合AI系统,它能够将任何大型语言模型(LLM)转化为视觉模型,以处理图像或PDF文档。这项技术通过构建自动化流程,将任何数字资产格式转换为LLM兼容的格式,实现逻辑推理。Document Inlining通过解析图像和PDFs,直接将它们输入到用户选择的LLM中,提供更高的质量、输入灵活性和超简单的使用方式。它解决了传统LLM在处理非文本数据时的局限性,通过专业化的组件分解任务,提高了文本模型推理的质量,并且简化了开发者的使用体验。
IdentityRAG是一个基于客户数据构建LLM聊天机器人的工具,能够从多个内部源系统如数据库和CRM中检索统一的客户数据。该产品通过实时模糊搜索处理拼写错误和不准确信息,提供准确、相关和统一的客户数据响应。它支持快速检索结构化客户数据,构建动态客户档案,并实时更新客户数据,使LLM应用能够访问统一且准确的客户数据。IdentityRAG以其快速响应、数据实时更新和易于扩展的特点,受到快速增长、数据驱动的企业的信任。
PromptWizard是由微软开发的一个任务感知型提示优化框架,它通过自我演化机制,使得大型语言模型(LLM)能够生成、批评和完善自己的提示和示例,通过迭代反馈和综合不断改进。这个自适应方法通过进化指令和上下文学习示例来全面优化,以提高任务性能。该框架的三个关键组件包括:反馈驱动的优化、批评和合成多样化示例、自生成的思考链(Chain of Thought, CoT)步骤。PromptWizard的重要性在于它能够显著提升LLM在特定任务上的表现,通过优化提示和示例来增强模型的性能和解释性。
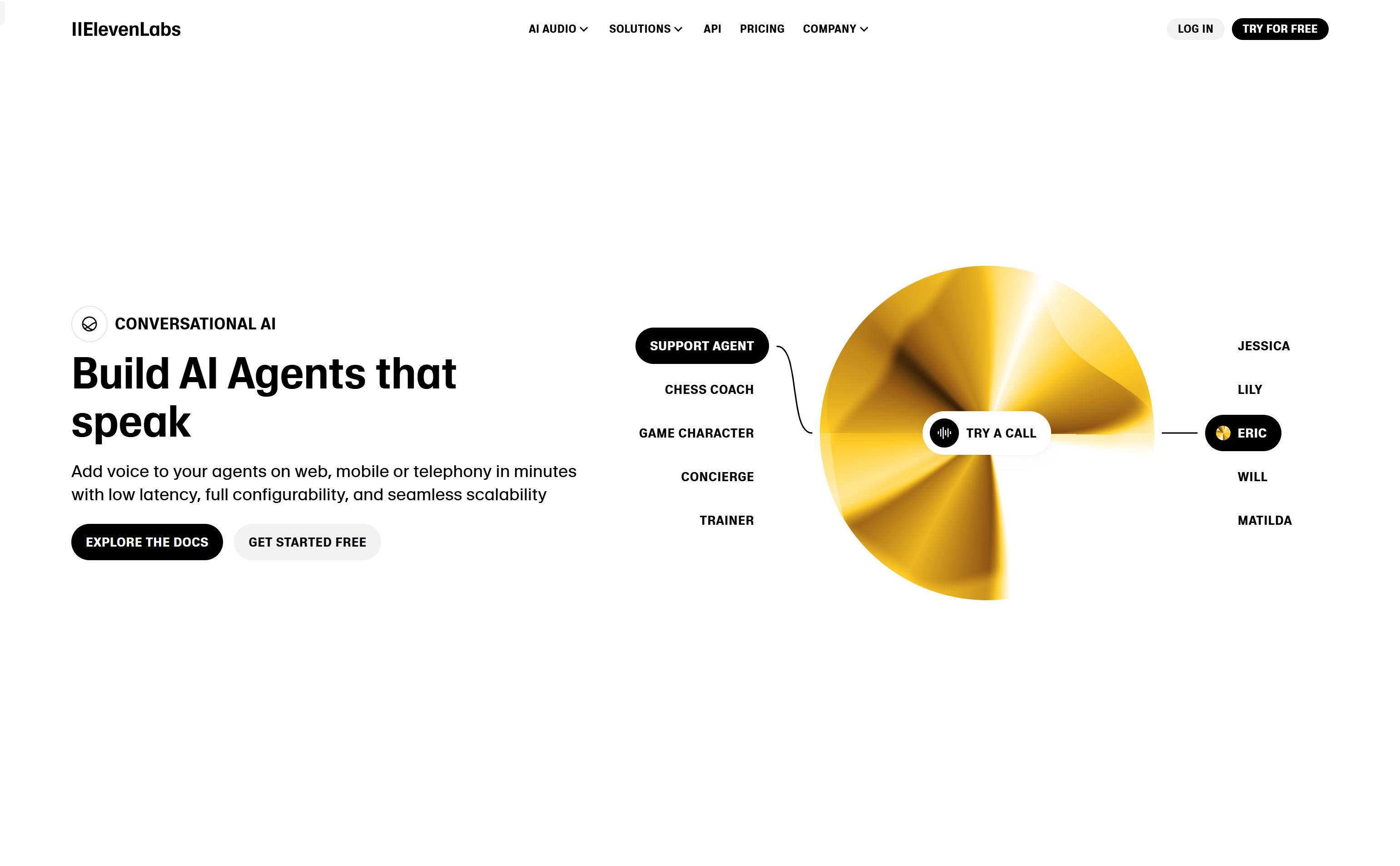
ElevenLabs Conversational AI是一款能够快速部署在网页、移动设备或电话上的语音代理产品。它以低延迟、全配置性和无缝扩展性为特点,支持自然对话中的轮流发言和打断处理,适用于嘈杂环境中的不可预测对话。产品结合了语音转文本、大型语言模型(LLM)和文本转语音技术,支持多语言和自定义声音,适用于客户支持、调度、外呼销售等多种场景。
SiteSpeakAI - llms.txt Generator是一个在线工具,用于生成llms.txt文件。这个文件为大型语言模型(LLMs)提供了必要的信息,以便它们能够在推理时更有效地使用您的网站。该工具的重要性在于它能够帮助网站管理员和开发者优化他们的网站,使其更适合与人工智能语言模型的交互,提高网站的功能和用户体验。SiteSpeakAI提供了一个免费的在线生成器,用户可以快速生成所需的llms.txt文件,无需复杂的编程知识。
aisuite是一个提供简单、统一接口以访问多个生成式AI服务的产品。它允许开发者通过标准化的接口使用多个大型语言模型(LLM),并比较结果。作为一个轻量级的Python客户端库包装器,aisuite使得创作者可以在不改变代码的情况下,无缝切换并测试来自不同LLM提供商的响应。目前,该库主要关注聊天完成功能,并计划在未来扩展更多用例。
Model Context Protocol(MCP)是一个开放协议,它允许大型语言模型(LLM)应用与外部数据源和工具之间实现无缝集成。无论是构建AI驱动的集成开发环境(IDE)、增强聊天界面还是创建自定义AI工作流,MCP都提供了一种标准化的方式,将LLM与它们所需的上下文连接起来。MCP的主要优点包括标准化的连接方式、易于集成和扩展、以及强大的社区支持。产品背景信息显示,MCP旨在促进开发者构建更加智能和高效的应用程序,特别是在AI和机器学习领域。MCP目前是免费提供给开发者使用的。
ollama-ebook-summary 是一个利用大型语言模型(LLM)为长文本创建要点笔记摘要的项目。该项目特别适用于epub和pdf格式的书籍,能够自动化提取章节并将其分割成约2000个token的小块,以提高响应的粒度。产品背景是创建者希望快速总结一系列书籍,以整合心理学理论和实践,并基于此信息构建连贯的论点。该工具的主要优点包括提高内容梳理效率、支持自定义问题查询、以及生成每个文本部分的详细摘要。
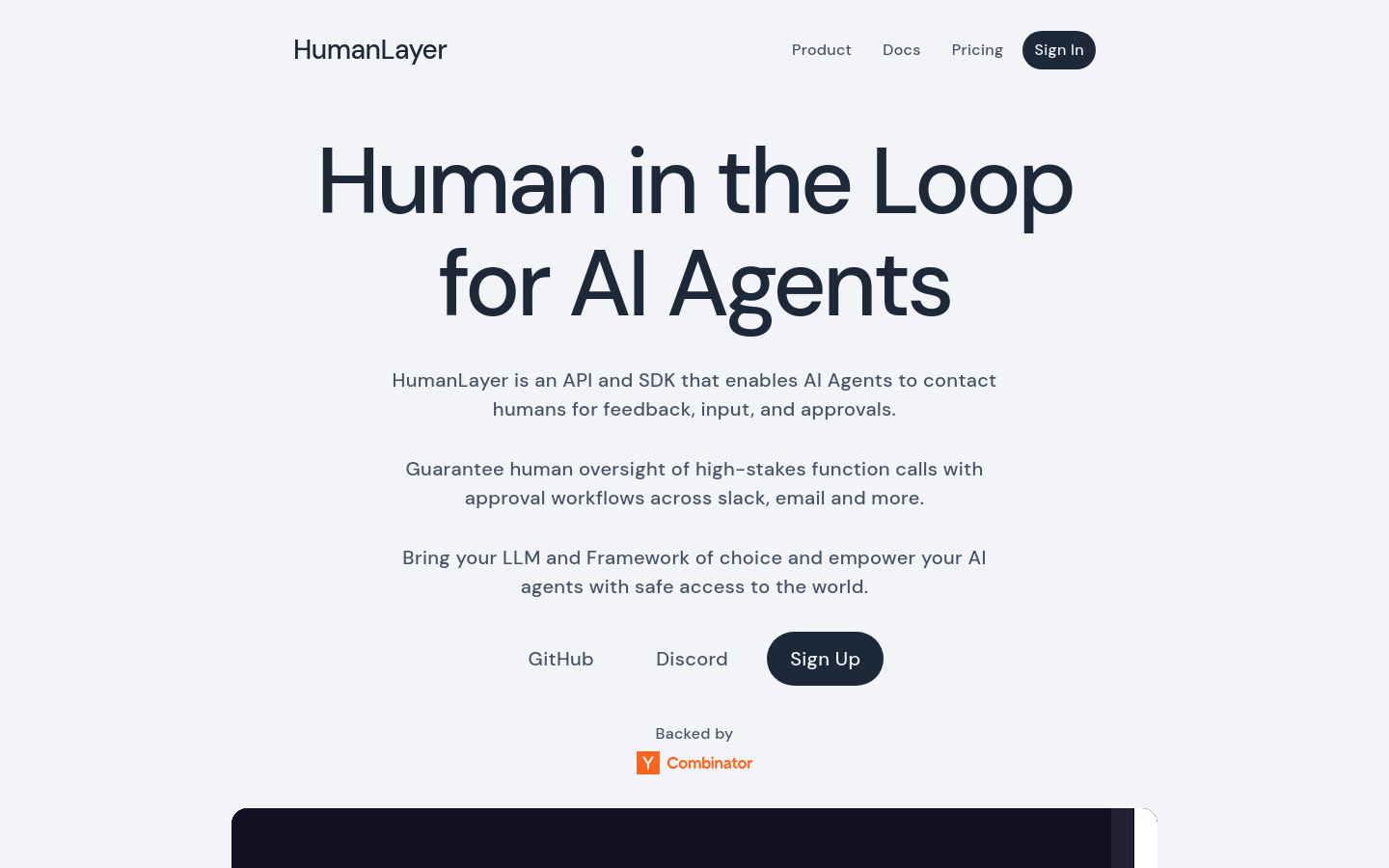
HumanLayer是一个API和SDK,它允许AI代理联系人类以获取反馈、输入和审批。它通过审批工作流程在Slack、电子邮件等渠道上确保对高风险功能调用的人类监督,支持将您选择的LLM和框架与AI代理安全连接到世界。HumanLayer得到了Y Combinator的支持,并且与多种流行的框架和LLM兼容,包括OpenAI、Claude、Llama3.1等。它提供了一个平台,通过人工在环的方式,增强AI代理的能力,提高其可靠性和效率。HumanLayer的价格策略包括免费、付费和定制企业方案,满足不同用户的需求。
Mistral Moderation API是Mistral AI推出的内容审核服务,旨在帮助用户检测和过滤不受欢迎的文本内容。该API是Le Chat中使用的审核服务的同一技术,现在对外开放,以便用户可以根据特定的应用和安全标准定制和使用这一工具。该模型是一个基于LLM(大型语言模型)的分类器,能够将文本输入分类到9个预定义的类别中。Mistral AI的这一API支持原生多语言,特别针对阿拉伯语、中文、英语、法语、德语、意大利语、日语、韩语、葡萄牙语、俄语和西班牙语进行了训练。该API的主要优点包括提高审核的可扩展性和鲁棒性,以及通过技术文档提供的详细政策定义和启动指南,帮助用户有效实施系统级的安全防护。
askrepo是一个基于LLM(大型语言模型)的源代码阅读工具,它能够读取Git管理的文本文件内容,发送至Google Gemini API,并根据指定的提示提供问题的答案。该产品代表了自然语言处理和机器学习技术在代码分析领域的应用,其主要优点包括能够理解和解释代码的功能,帮助开发者快速理解新项目或复杂代码库。产品背景信息显示,askrepo适用于需要深入理解代码的场景,尤其是在代码审查和维护阶段。该产品是开源的,可以免费使用。
Chat Nio是一个国内领先的LLM(Large Language Model)一站式企业解决方案,提供强大的AI集成工具,支持35+主流AI模型,涵盖文本生成、图像创作、音频处理和视频编辑等领域,并支持私有化部署和中转服务。它为开发者、个人用户和企业提供定制化的AI解决方案,包括但不限于多租户令牌分发、计费管理系统、深度集成Midjourney Proxy Plus绘画功能、全方位调用日志记录系统等。Chat Nio以其多功能性、灵活性和易用性,满足企业和团队的多样化需求,帮助他们高效开发和部署AI应用。
Laminar是一个开源的全栈平台,专注于从第一性原理出发进行AI工程。它帮助用户收集、理解和使用数据,以提高大型语言模型(LLM)应用的质量。Laminar支持对文本和图像模型的追踪,并且即将支持音频模型。产品的主要优点包括零开销的可观测性、在线评估、数据集构建和LLM链管理。Laminar完全开源,易于自托管,适合需要构建和管理LLM产品的开发者和团队。
Dabarqus是一个Retrieval Augmented Generation(RAG)框架,它允许用户将私有数据实时提供给大型语言模型(LLM)。这个工具通过提供REST API、SDKs和CLI工具,使得用户能够轻松地将各种数据源(如PDF、电子邮件和原始数据)存储到语义索引中,称为“记忆库”。Dabarqus支持LLM风格的提示,使用户能够以简单的方式与记忆库进行交互,而无需构建特殊的查询或学习新的查询语言。此外,Dabarqus还支持多语义索引(记忆库)的创建和使用,使得数据可以根据主题、类别或其他分组方式进行组织。Dabarqus的产品背景信息显示,它旨在简化私有数据与AI语言模型的集成过程,提高数据检索的效率和准确性。
GitHub to LLM Converter是一个在线工具,旨在帮助用户将GitHub上的项目、文件或文件夹链接转换成适合大型语言模型(LLM)处理的格式。这一工具对于需要处理大量代码或文档数据的开发者和研究人员来说至关重要,因为它简化了数据准备过程,使得这些数据可以被更高效地用于机器学习或自然语言处理任务。该工具由Skirano开发,提供了一个简洁的用户界面,用户只需输入GitHub链接,即可一键转换,极大地提高了工作效率。
Meta Lingua 是一个轻量级、高效的大型语言模型(LLM)训练和推理库,专为研究而设计。它使用了易于修改的PyTorch组件,使得研究人员可以尝试新的架构、损失函数和数据集。该库旨在实现端到端的训练、推理和评估,并提供工具以更好地理解模型的速度和稳定性。尽管Meta Lingua目前仍在开发中,但已经提供了多个示例应用来展示如何使用这个代码库。
Prompt Engineering是人工智能领域的前沿技术,它改变了我们与AI技术的交互方式。这个开源项目旨在为初学者和经验丰富的实践者提供一个学习、构建和分享Prompt Engineering技术的平台。该项目包含了从基础到高级的各种示例,旨在促进Prompt Engineering领域的学习、实验和创新。此外,它还鼓励社区成员分享自己的创新技术,共同推动Prompt Engineering技术的发展。
Llama-3.1-Nemotron-70B-Instruct是NVIDIA定制的大型语言模型,专注于提升大型语言模型(LLM)生成回答的帮助性。该模型在多个自动对齐基准测试中表现优异,例如Arena Hard、AlpacaEval 2 LC和GPT-4-Turbo MT-Bench。它通过使用RLHF(特别是REINFORCE算法)、Llama-3.1-Nemotron-70B-Reward和HelpSteer2-Preference提示在Llama-3.1-70B-Instruct模型上进行训练。此模型不仅展示了NVIDIA在提升通用领域指令遵循帮助性方面的技术,还提供了与HuggingFace Transformers代码库兼容的模型转换格式,并可通过NVIDIA的build平台进行免费托管推理。
LlamaIndex.TS是一个为构建基于大型语言模型(LLM)的应用而设计的框架。它专注于帮助用户摄取、结构化和访问私有或特定领域的数据。这个框架提供了一个自然语言界面,用于连接人类和推断出的数据,使得开发者无需成为机器学习或自然语言处理的专家,也能通过LLM增强其软件功能。LlamaIndex.TS支持Node.js、Vercel Edge Functions和Deno等流行运行时环境。
ComfyUI LLM Party旨在基于ComfyUI前端开发一套完整的LLM工作流节点集合,使用户能够快速便捷地构建自己的LLM工作流,并轻松地将它们集成到现有的图像工作流中。
promptic是一个轻量级、基于装饰器的Python库,它通过litellm简化了与大型语言模型(LLMs)交互的过程。使用promptic,你可以轻松创建提示,处理输入参数,并从LLMs接收结构化输出,仅需几行代码。
Epsilla是一个无需编码的RAG即服务(RAG-as-a-Service)平台,它允许用户基于私有或公共数据构建生产就绪的大型语言模型(Large Language Model, LLM)应用程序。该平台提供了一站式服务,包括数据管理、RAG工具、CI/CD风格的评估以及企业级安全措施,旨在降低总拥有成本(TCO),提高查询速度和吞吐量,同时确保信息的时效性和安全性。
MemoryScope是一个为大型语言模型(LLM)聊天机器人提供长期记忆能力的框架。它通过记忆数据库和工作库,使得聊天机器人能够存储和检索记忆片段,从而实现个性化的用户交互体验。该产品通过记忆检索和记忆整合等操作,使得机器人能够理解并记住用户的习惯和偏好,为用户提供更加个性化和连贯的对话体验。MemoryScope支持多种模型API,包括openai和dashscope,并且可以与现有的代理框架如AutoGen和AgentScope结合使用,提供了丰富的定制化和扩展性。
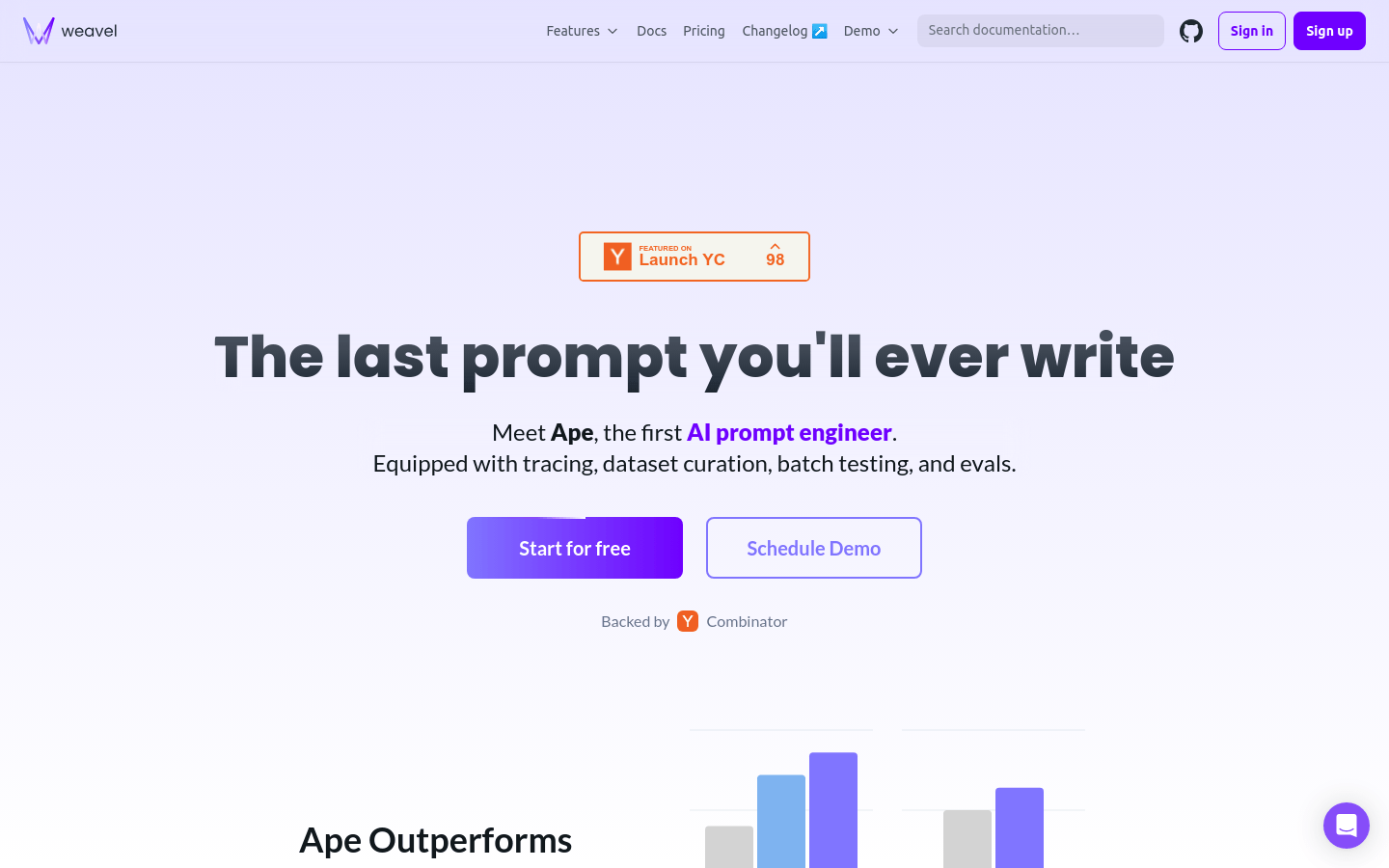
Weavel是一个AI提示工程师,它通过追踪、数据集管理、批量测试和评估等功能,帮助用户优化大型语言模型(LLM)的应用。Weavel与Weavel SDK结合使用,能够自动记录并添加LLM生成的数据到您的数据集中,实现无缝集成和针对特定用例的持续改进。此外,Weavel能够自动生成评估代码,并使用LLM作为复杂任务的公正裁判,简化评估流程,确保准确、细致的性能指标。
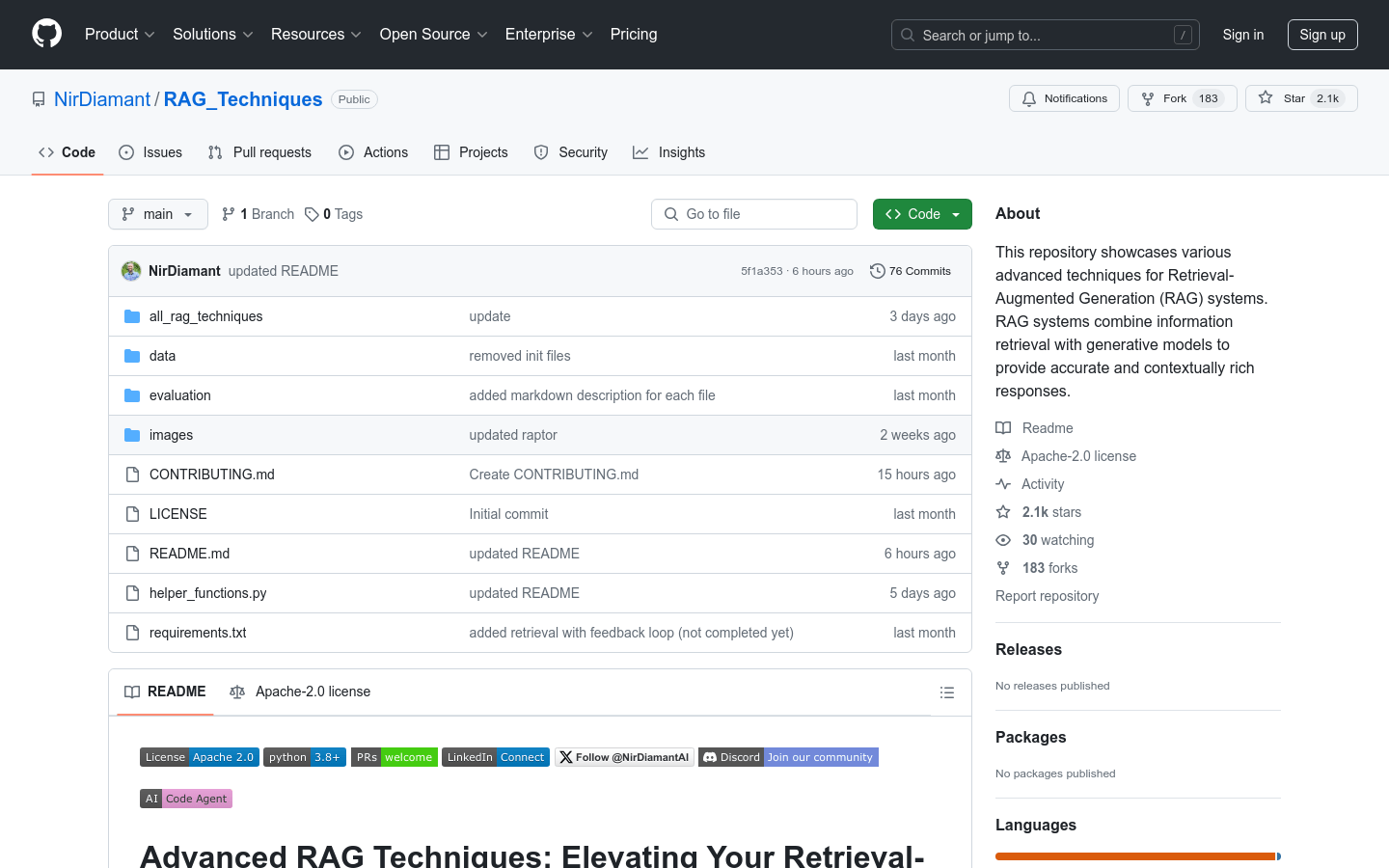
RAG_Techniques 是一个专注于检索增强生成(Retrieval-Augmented Generation, RAG)系统的技术集合,旨在提升系统的准确性、效率和上下文丰富性。它提供了一个前沿技术的中心,通过社区贡献和协作环境,推动RAG技术的发展和创新。
GitHub Models是GitHub推出的新一代AI模型服务,旨在帮助开发者成为AI工程师。它将行业领先的大型和小型语言模型直接集成到GitHub平台,让超过1亿用户能够直接在GitHub上访问和使用这些模型。GitHub Models提供了一个交互式的模型游乐场,用户可以在这里测试不同的提示和模型参数,无需支付费用。此外,GitHub Models与Codespaces和VS Code集成,允许开发者在开发环境中无缝使用这些模型,并通过Azure AI实现生产部署,提供企业级安全和数据隐私保护。
RouteLLM是一个用于服务和评估大型语言模型(LLM)路由器的框架。它通过智能路由查询到不同成本和性能的模型,以节省成本同时保持响应质量。它提供了开箱即用的路由器,并在广泛使用的基准测试中显示出高达85%的成本降低和95%的GPT-4性能。
vLLM是一个为大型语言模型(LLM)推理和提供服务的快速、易用且高效的库。它通过使用最新的服务吞吐量技术、高效的内存管理、连续批处理请求、CUDA/HIP图快速模型执行、量化技术、优化的CUDA内核等,提供了高性能的推理服务。vLLM支持与流行的HuggingFace模型无缝集成,支持多种解码算法,包括并行采样、束搜索等,支持张量并行性,适用于分布式推理,支持流式输出,并兼容OpenAI API服务器。此外,vLLM还支持NVIDIA和AMD GPU,以及实验性的前缀缓存和多lora支持。
RAGElo是一个工具集,使用Elo评分系统帮助选择最佳的基于检索增强生成(RAG)的大型语言模型(LLM)代理。随着生成性LLM在生产中的原型设计和整合变得更加容易,评估仍然是解决方案中最具有挑战性的部分。RAGElo通过比较不同RAG管道和提示对多个问题的答案,计算不同设置的排名,提供了一个良好的概览,了解哪些设置有效,哪些无效。
Nerve是一个可以创建具有状态的代理的LLM工具,用户无需编写代码即可定义和执行复杂任务。它通过动态更新系统提示和在多个推理过程中保持状态,使代理能够规划和逐步执行完成任务所需的操作。Nerve支持任何通过ollama、groq或OpenAI API可访问的模型,具有高度的灵活性和效率,同时注重内存安全。
Unify AI是一个为开发者设计的平台,它允许用户通过一个统一的API访问和比较来自不同提供商的大型语言模型(LLMs)。该平台提供了实时性能基准测试,帮助用户根据质量、速度和成本效率来选择和优化最合适的模型。Unify AI还提供了定制路由功能,允许用户根据自己的需求设置成本、延迟和输出速度的约束,并定义自定义质量指标。此外,Unify AI的系统会根据最新的基准数据,每10分钟更新一次,将查询发送到最快提供商,确保持续达到峰值性能。
Siri-Ultra是一个基于云的智能助手,可以在Cloudflare Workers上运行,并且可以与任何大型语言模型(LLM)配合使用。它利用了LLaMA 3模型,并且通过自定义函数调用来获取天气数据和在线搜索。这个项目允许用户通过Apple Shortcuts来使用Siri,从而消除了对专用硬件设备的需求。
ScrapeGraphAI是一个使用LLM(大型语言模型)和直接图逻辑来为网站、文档和XML文件创建抓取管道的Python网络爬虫库。用户只需指定想要提取的信息,库就会自动完成这项工作。该库的主要优点在于简化了网络数据抓取的过程,提高了数据提取的效率和准确性。它适用于数据探索和研究目的,但不应被滥用。
Reka Core是一个GPT-4级别的多模态大型语言模型(LLM),具备图像、视频和音频的强大上下文理解能力。它是目前市场上仅有的两个商用综合多模态解决方案之一。Core在多模态理解、推理能力、编码和Agent工作流程、多语言支持以及部署灵活性方面表现出色。
Tools4AI是100%用Java实现的大型行动模型(LAM),可作为企业Java应用程序的LLM代理。该项目演示了如何将AI与企业工具或外部工具集成,将自然语言提示转换为可执行行为。这些提示可以被称为"行动提示"或"可执行提示"。通过利用AI能力,它简化了用户与复杂系统的交互,提高了生产力和创新能力。
Langtail 是一个旨在简化大型语言模型(LLM)提示管理的平台。通过Langtail,您可以增强团队协作、提高效率,并更深入地了解您的AI工作原理。尝试Langtail,以更具协作和洞察力的方式构建LLM应用。
karpathy/llm.c 是一个使用简单的 C/CUDA 实现 LLM 训练的项目。它旨在提供一个干净、简单的参考实现,同时也包含了更优化的版本,可以接近 PyTorch 的性能,但代码和依赖大大减少。目前正在开发直接的 CUDA 实现、使用 SIMD 指令优化 CPU 版本以及支持更多现代架构如 Llama2、Gemma 等。
Tara是一款插件,可以将大型语言模型(LLM)接入到Comfy UI中,支持简单的API设置,并集成LLaVa模型。其中包含TaraPrompter节点用于生成精确结果、TaraApiKeyLoader节点管理API密钥、TaraApiKeySaver节点安全保存密钥、TaraDaisyChainNode节点串联输出实现复杂工作流。
构建UI组件通常是一项乏味的工作。OpenUI旨在使这一过程变得有趣、快捷和灵活。这也是我们在W&B用于测试和原型化下一代工具的工具,用于在LLM的基础上构建强大的应用程序。您可以使用想象力描述UI,然后实时查看渲染效果。您可以要求进行更改,并将HTML转换为React、Svelte、Web组件等。就像是V0的开源和不太精致的版本。
OPT2I是一个T2I优化框架,利用大型语言模型(LLM)提高提示-图像一致性。通过迭代生成修订后的提示,优化生成过程。能显著提高一致性得分,同时保持FID并增加生成数据与真实数据召回率。
苹果发布了自己的大语言模型MM1,这是一个最高有30B规模的多模态LLM。通过预训练和SFT,MM1模型在多个基准测试中取得了SOTA性能,展现了上下文内预测、多图像推理和少样本学习能力等吸引人的特性。
ELLA(Efficient Large Language Model Adapter)是一种轻量级方法,可将现有的基于CLIP的扩散模型配备强大的LLM。ELLA提高了模型的提示跟随能力,使文本到图像模型能够理解长文本。我们设计了一个时间感知语义连接器,从预训练的LLM中提取各种去噪阶段的时间步骤相关条件。我们的TSC动态地适应了不同采样时间步的语义特征,有助于在不同的语义层次上对U-Net进行冻结。ELLA在DPG-Bench等基准测试中表现优越,尤其在涉及多个对象组合、不同属性和关系的密集提示方面表现出色。
LongRoPE是微软推出的技术,可以将预训练大型语言模型(LLM)的上下文窗口扩展到2048k(200万)令牌,实现从短上下文到长上下文的扩展,降低训练成本和时间,同时保持原有短上下文窗口性能。适用于提高语言模型在长文本上的理解和生成能力,提升机器阅读理解、文本摘要和长篇文章生成等任务。
LangSmith是一个统一的DevOps平台,用于开发、协作、测试、部署和监控LLM应用程序。它支持LLM应用程序开发生命周期的所有阶段,为构建LLM应用提供端到端的解决方案。主要功能包括:链路追踪、提示工具、数据集、自动评估、线上部署等。适用于构建基于LLM的AI助手、 ChatGPT应用的开发者。
茴香豆是一个基于LLM的领域特定知识助手,能够处理群聊中的复杂场景,回答用户问题而不引起消息泛滥。它提供算法管道来回答技术问题,并且部署成本低,只需LLM模型满足4个特点就能回答大部分用户问题。茴香豆在运行的场景中能够处理各种问题,并且欢迎加入他们的微信群体验最新版本。
React Flow是一个开源的可视化编辑器,允许用户通过拖放的方式创建agent工作群,用于自定义业务逻辑。用户可以从图库中拖放agent到工作区,连接它们,定义初始任务,导出Python脚本在本地机器上运行。我们通过定制的操作系统为企业提供云端支持,让他们可以运行LLM。欢迎联系我们的企业支持团队了解更多信息。
Athina AI是一个用于监控和调试LLM(大型语言模型)模型的工具。它可以帮助你发现和修复LLM模型在生产环境中的幻觉和错误,并提供详细的分析和改进建议。Athina AI支持多种LLM模型,可以配置定制化的评估来满足不同的使用场景。你可以通过Athina AI来检测错误的输出、分析成本和准确性、调试模型输出、探索对话内容以及比较不同模型的性能表现等。
LLM Context Extender是一款旨在扩展大型语言模型(LLMs)上下文窗口的工具。它通过调整RoPE的基础频率和缩放注意力logits的方式,帮助LLMs有效适应更大的上下文窗口。该工具在精细调整性能和稳健性方面验证了其方法的优越性,并展示了在仅有100个样本和6个训练步骤的情况下,将LLaMA-2-7B-Chat的上下文窗口扩展到16,384的非凡效率。此外,还探讨了数据组成和训练课程如何影响特定下游任务的上下文窗口扩展,建议以长对话进行LLMs的精细调整作为良好的起点。
Portkey的AI网关是应用程序和托管LLM之间的接口。它使用统一的API对OpenAI、Anthropic、Mistral、LLama2、Anyscale、Google Gemini等的API请求进行了优化,从而实现了流畅的路由。该网关快速、轻量,内置重试机制,支持多模型负载均衡,确保应用程序的可靠性和性能。
Kindllm是一款专为Kindle优化的无干扰LLM聊天Web应用,是您阅读的完美伴侣。由Mistral AI的Mixtral提供技术支持。主要在Kindle Paperwhite上进行了测试。为什么?作者之前尝试制作这款应用,但在旧版Kindle浏览器上无法很好地运行。令人惊讶的是,亚马逊最近更新了一些Kindle的网络浏览器,现在似乎已经足够好以运行这样的简单交互应用!
这是一种在 Intel GPU 上实现的高效的 LLM 推理解决方案。通过简化 LLM 解码器层、使用分段 KV 缓存策略和自定义的 Scaled-Dot-Product-Attention 内核,该解决方案在 Intel GPU 上相比标准的 HuggingFace 实现可实现高达 7 倍的令牌延迟降低和 27 倍的吞吐量提升。详细功能、优势、定价和定位等信息请参考官方网站。
Confident AI 是一个开源的评估基础设施,为 LLM(Language Model)提供信心。用户可以通过编写和执行测试用例来评估自己的 LLM 应用,并使用丰富的开源指标来衡量其性能。通过定义预期输出并与实际输出进行比较,用户可以确定 LLM 的表现是否符合预期,并找出改进的方向。Confident AI 还提供了高级的差异跟踪功能,帮助用户优化 LLM 配置。此外,用户还可以利用全面的分析功能,识别重点关注的用例,实现 LLM 的有信心地投产。Confident AI 还提供了强大的功能,帮助用户自信地将 LLM 投入生产,包括 A/B 测试、评估、输出分类、报告仪表盘、数据集生成和详细监控。
LobeChat是一个开源的可扩展高性能聊天机器人框架,支持一键免费部署私有ChatGPT/LLM网络应用。具有自定义模型、多语言支持、Plugins系统、知识抽取等功能,可以帮助用户快速构建私有、安全可控的AI助理和知识管理工具。
Essential AI开发了全栈AI产品,通过自动化枯燥乏味的工作流程,显著提高企业工作效率。例如,他们的技术可以使数据分析师的工作效率提高10倍,并为商业用户提供工具,使他们自己成为独立的数据驱动决策者。它还可以识别组织供应链中的最大风险并提出改进建议。随着人工反馈和技术突破,Essential AI的LLM将赋能用户解决越来越困难的任务,解锁关键技能,扩大组织对社会的影响。
Algomax简化LLM和RAG模型的评估,优化提示开发,并通过直观的仪表板提供对定性指标的独特洞察。我们的评估引擎精确评估LLM,并通过广泛测试确保可靠性。平台提供了全面的定性和定量指标,帮助您更好地理解模型的行为,并提供具体的改进建议。Algomax的用途广泛,适用于各个行业和领域。
Agent M是一个强大的大型语言模型或ChatGPT驱动的主代理开发框架,可让您创建多个基于LLM的代理。Agent Mbetween多个执行各种任务的代理之间进行编排,例如基于自然语言的API调用,连接到您的数据并帮助自动化复杂的对话。
Teammate Lang是一个全能的LLM App开发和运营解决方案。提供无代码编辑器、语义缓存、Prompt版本管理、LLM数据平台、A/B测试、QA、Playground等20多个模型,包括GPT、PaLM、Llama、Cohere等。
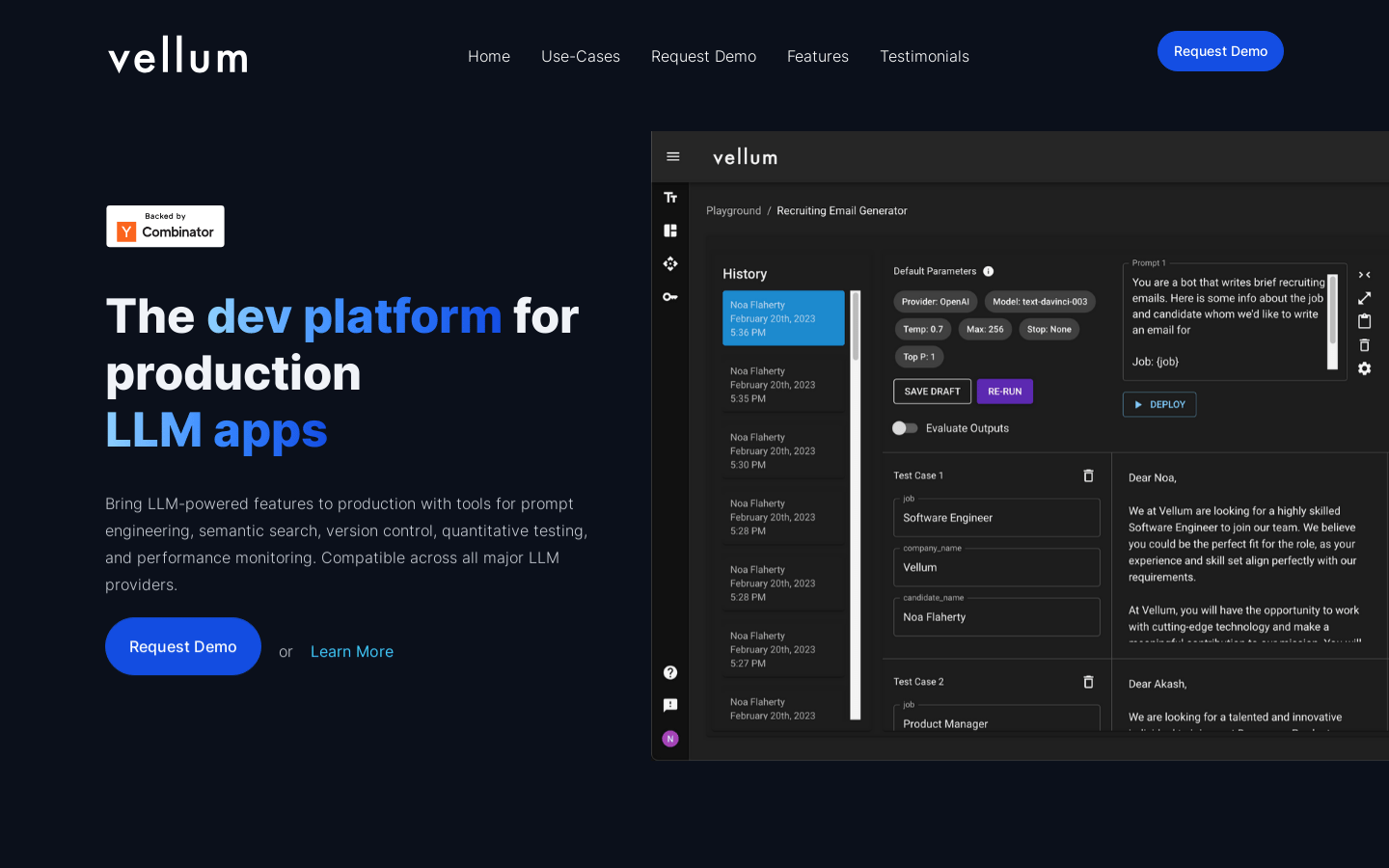
Vellum是一个用于构建LLM驱动应用的开发平台。它具有提示工程、语义搜索、版本控制、测试和监控等工具,可以帮助开发者将LLM的功能引入生产环境。它与所有主要的LLM提供商兼容,开发者可以选择最适合的模型,也可以随时切换,避免业务过于依赖单一的LLM提供商。
llamafile是一个将LLM(大型语言模型)模型及其权重打包成一个自包含可执行文件的工具。它结合了llama.cpp和Cosmopolitan Libc,可以让复杂的LLM模型被压缩成一个llamafile,无需进行任何安装和配置就可以在大多数计算机上本地运行。主要优点是使开源的LLM模型更易于开发者和终端用户访问。
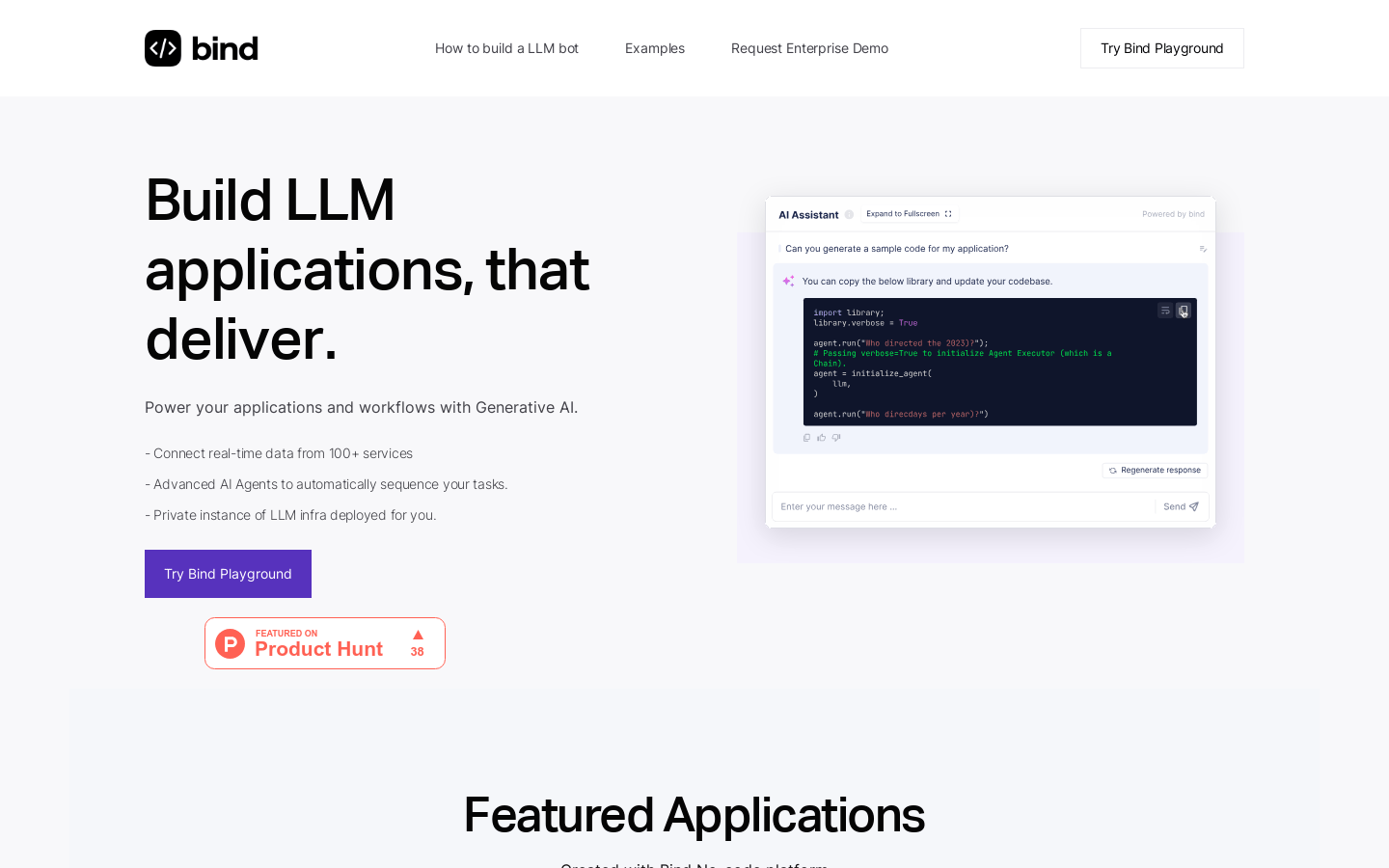
Bind是一个协作式的Generative AI应用开发平台,可帮助开发者快速构建和部署强大的语言模型应用。提供丰富的工具和功能,包括实时测试和调试LLM响应的提示场景,简易的部署LLM助手等应用到生产环境的平台。
Hippocratic AI是医疗保健行业的首个安全导向的LLM。它采用最先进的技术,在105项医疗考试和认证中超越了GPT 4的表现。它具有强大的功能和优势,并提供定价和定位等详细信息。
Vellum 是一个开发平台,用于构建 LLM 应用。它提供了快速工程、语义搜索、版本控制、测试和监控等工具,兼容所有主要的 LLM 提供商。Vellum 可以帮助您将 LLM 功能带入生产环境,支持迅速开发和部署 LLM 模型,同时提供质量测试和性能监控等功能。定价和定位请参考官方网站。
PlugBear可以在几秒钟内将您的LLM应用程序连接到Slack等工具,无需编写任何代码。它支持主流的LLM框架,让您只需开发一次LLM应用,就可以连接到各种流行的协作和交流工具。
LLM Spark是一个开发平台,可用于构建基于LLM的应用程序。它提供多个LLM的快速测试、版本控制、可观察性、协作、多个LLM支持等功能。LLM Spark可轻松构建AI聊天机器人、虚拟助手等智能应用程序,并通过与提供商密钥集成,实现卓越性能。它还提供了GPT驱动的模板,加速了各种AI应用程序的创建,同时支持从零开始定制项目。LLM Spark还支持无缝上传数据集,以增强AI应用程序的功能。通过LLM Spark的全面日志和分析,可以比较GPT结果、迭代和部署智能AI应用程序。它还支持多个模型同时测试,保存提示版本和历史记录,轻松协作,以及基于意义而不仅仅是关键字的强大搜索功能。此外,LLM Spark还支持将外部数据集集成到LLM中,并符合GDPR合规要求,确保数据安全和隐私保护。
Lookahead Decoding是一种新的推理方法,用于打破LLM推理的顺序依赖性,提高推理效率。用户可以通过导入Lookahead Decoding库,使用Lookahead Decoding改进自己的代码。Lookahead Decoding目前只支持LLaMA和Greedy Search两种模型。
Klu是一款全能的LLM应用平台,可以在Klu上快速构建、评估和优化基于LLM技术的应用。它提供了多种最先进的LLM模型选择,让用户可以根据自己的需求进行选择和调整。Klu还支持团队协作、版本管理、数据评估等功能,为AI团队提供了一个全面而便捷的开发平台。
Pulze.ai是一站式LLM开发自动化平台,提供单一API,将所有最佳LLM插入您的产品,并在几分钟内简化您的LLM功能开发。Pulze.ai的API遵循LLMOps最佳实践,并使您的团队轻松使用。Pulze.ai允许您一次测试所有最佳模型,以加速开发。您可以在Pulze.ai内动态控制预算和成本目标,并在扩展时保护您的利润。Pulze.ai还提供企业级安全性,以管理所有用户数据的数据隐私和安全性。Pulze.ai提供了多个功能点,如上传数据源、优化结果、一键部署、实时跟踪和版本控制等。
ArguflowChat是一款检索增强型LLM聊天机器人,可以与Garry Tan进行对话。它具有以下功能和优势:提供定制化解决方案、与Garry Tan进行对话、通过电子邮件联系。
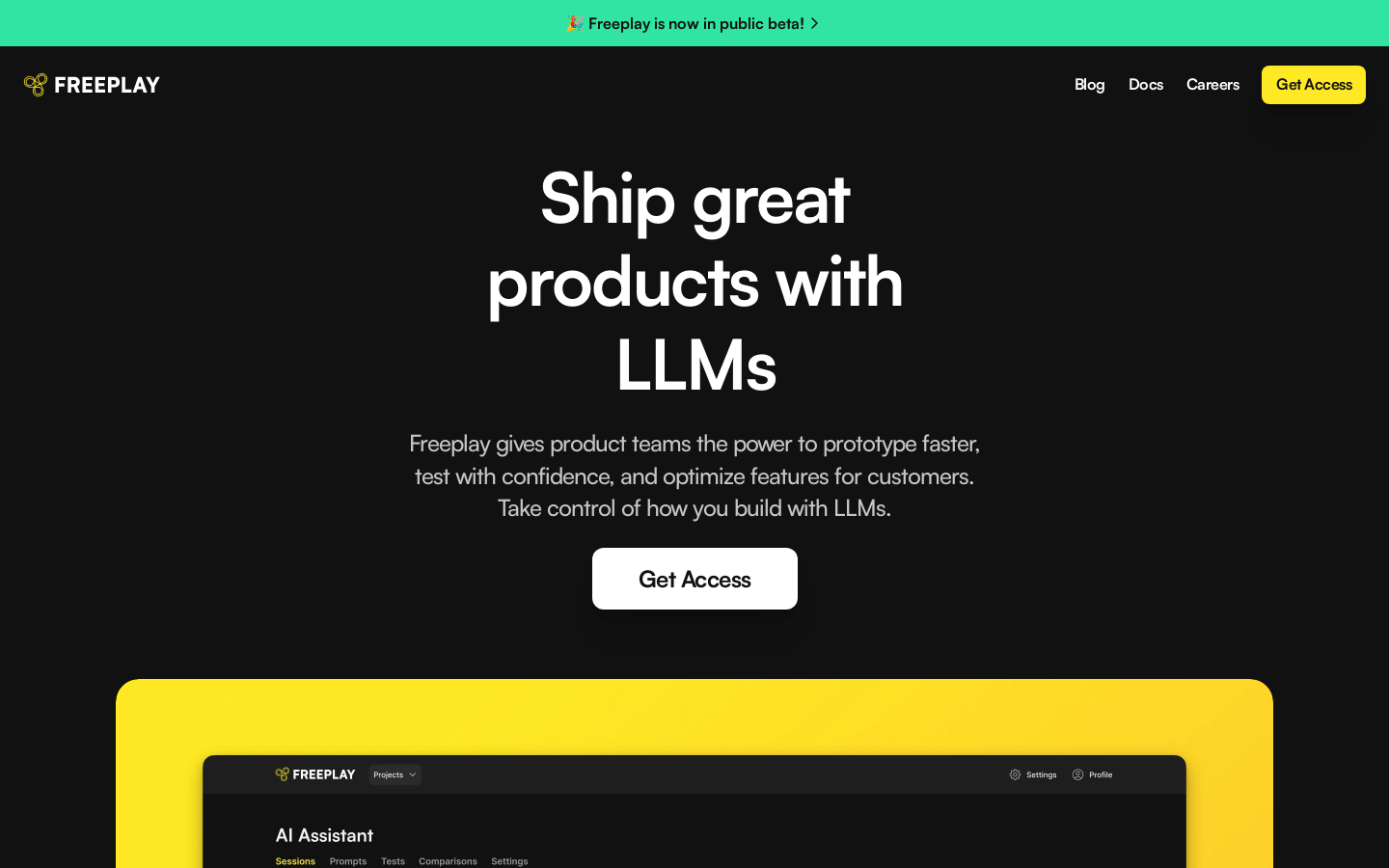
Freeplay是一个LLM原型构建工具,可以帮助产品团队更快地原型化、测试及优化功能。它赋能团队利用LLM加快构建速度。
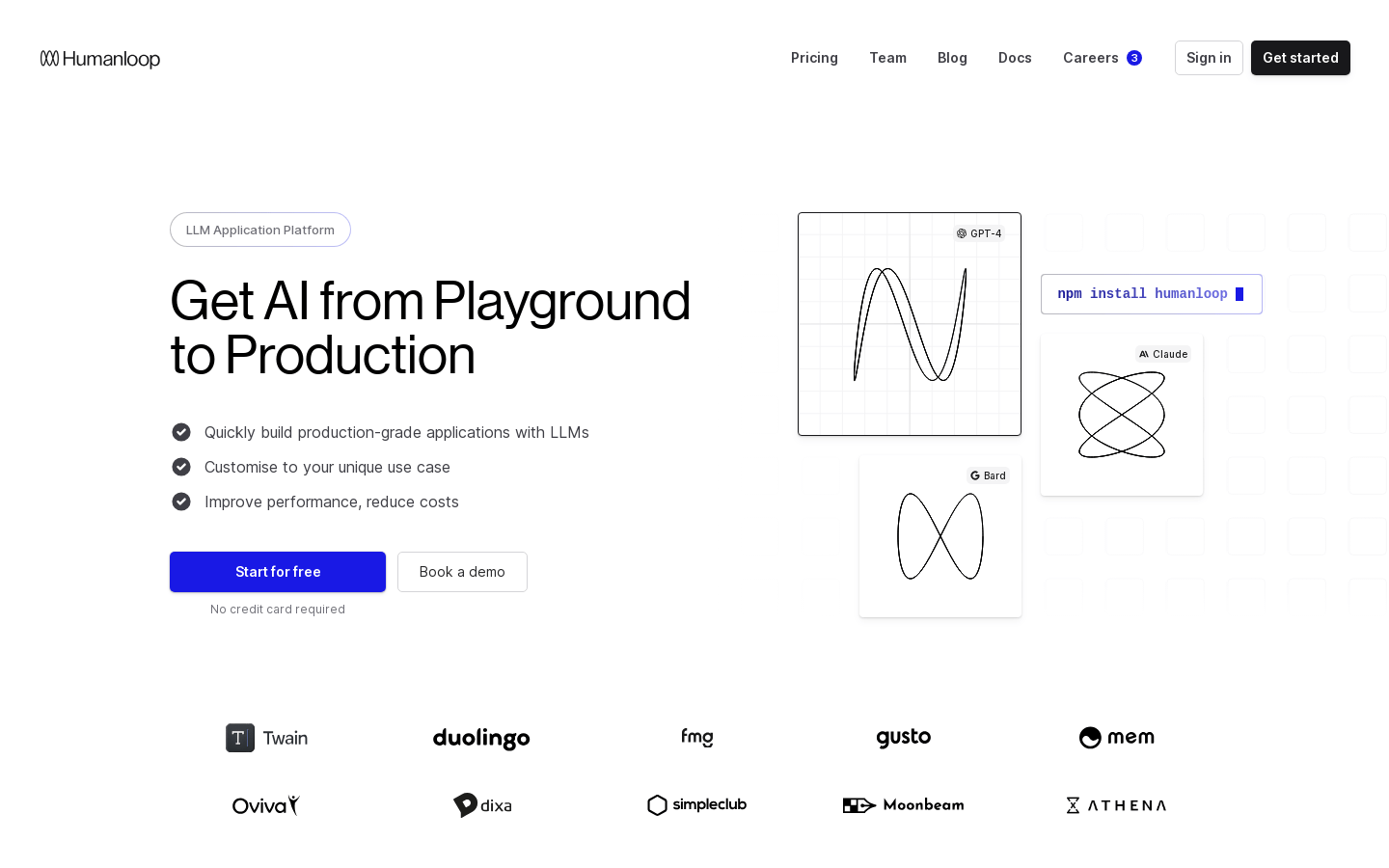
Humanloop是一个用于构建和监控以大语言模型为基础的生产级应用的协作平台。它提供了一套完整的工具集,可以帮助开发者更快速地将AI从原型开发到生产环境,同时保证系统的可靠性。主要功能包括:提示工程,可以迭代和版本化提示,提高命中率;模型管理,支持各种模型并进行跟踪;内容评估,收集反馈并进行定量分析;以及合作平台,让非技术人员也可以参与到AI应用开发中。典型应用场景有构建聊天机器人、自动化客户支持以及生成营销内容等。Humanloop已经受到了成千上万开发者的青睐,被多家知名企业所使用。
Langroid是一个轻量级、可扩展和原则性的Python框架,可以轻松地构建基于LLM的应用程序。您可以设置代理,为它们配备可选组件(LLM、向量存储和方法),分配它们任务,并让他们通过交换消息协作解决问题。这个多代理范例的灵感来自Actor框架(但您不需要了解任何关于这个的知识!)。Langroid提供了一个全新的LLM应用程序开发方式,在简化开发人员体验方面进行了深思熟虑;它不使用Langchain。我们欢迎贡献--请参阅贡献文档以获取贡献想法。
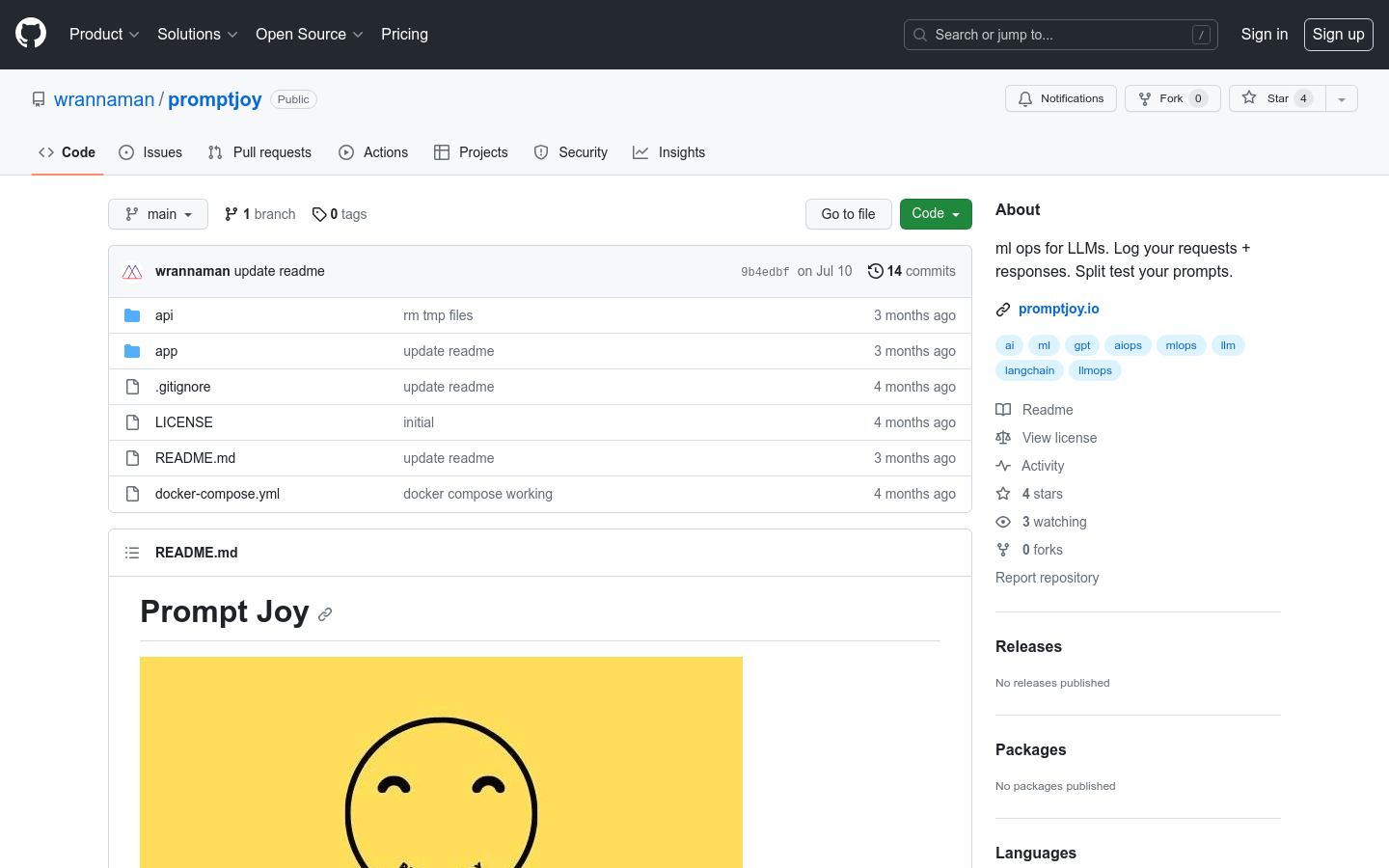
Prompt Joy是一个用于帮助理解和调试LLM(大语言模型)提示的工具。主要功能包括日志记录和分割测试。日志记录可以记录LLM的请求与响应,便于检查输出结果。分割测试可以轻松进行A/B测试,找出效果最佳的提示。它与具体的LLM解耦,可以配合OpenAI、Anthropic等LLM使用。它提供了日志和分割测试的API。采用Node.js+PostgreSQL构建。
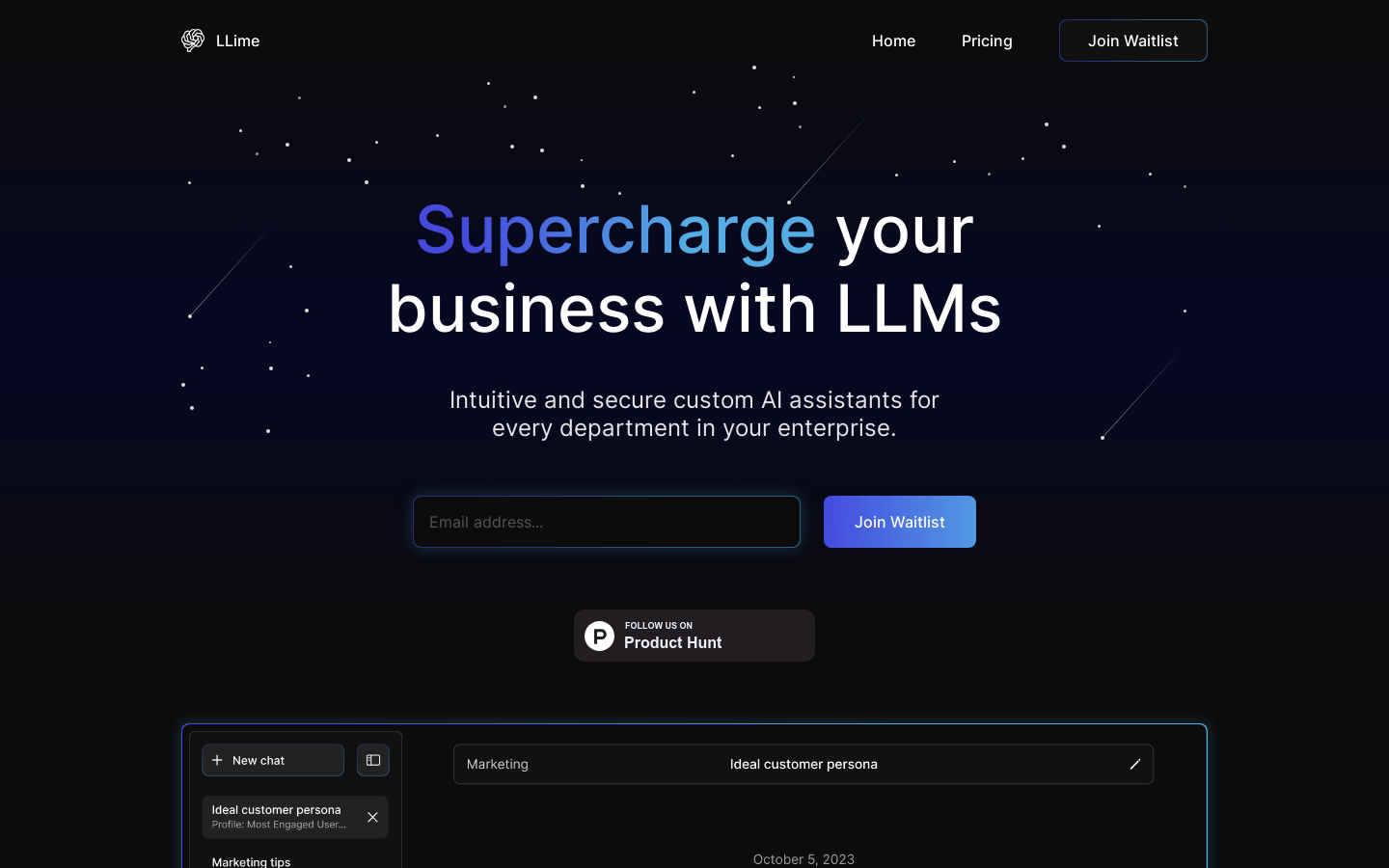
LLime是一个基于大型语言模型的企业智能工作助手,可以为企业的各个部门提供定制化的AI助手,提升工作效率。它提供简单易用的界面,支持根据企业数据进行模型微调,确保模型精准适配企业需求。主要功能包括代码探索、数据分析、内容策略等,可以帮助开发者、管理者和市场人员的工作决策。该产品采用订阅制,根据部门和员工人数定价。
LangChain是一个帮助开发人员构建应用程序的库,通过组合性将大型语言模型(LLMs)与其他计算或知识源结合起来。它提供了各种应用场景的端到端示例,包括问题回答、聊天机器人和代理等。LangChain还提供了对LLMs的通用接口、链式调用、数据增强生成、记忆和评估等功能。定价信息请访问官方网站。
GPT4All是一个一站式AI工具,提供300多个AI专家条件和500多个精细调整模型,可以用于写作、编码、数据组织、图像生成、音乐生成等多种任务。它具有易于使用的用户界面,支持浅色和深色模式,集成了GitHub仓库,支持不同的预定义欢迎消息的个性化,支持生成答案的点赞和点踩评级,支持复制、编辑和删除消息,支持本地数据库存储讨论,支持搜索、导出和删除多个讨论,支持基于稳定扩散的图像/视频生成,支持基于musicgen的音乐生成,支持通过Lollms节点和花瓣进行多代对等网络生成,支持Docker、conda和手动虚拟环境设置。
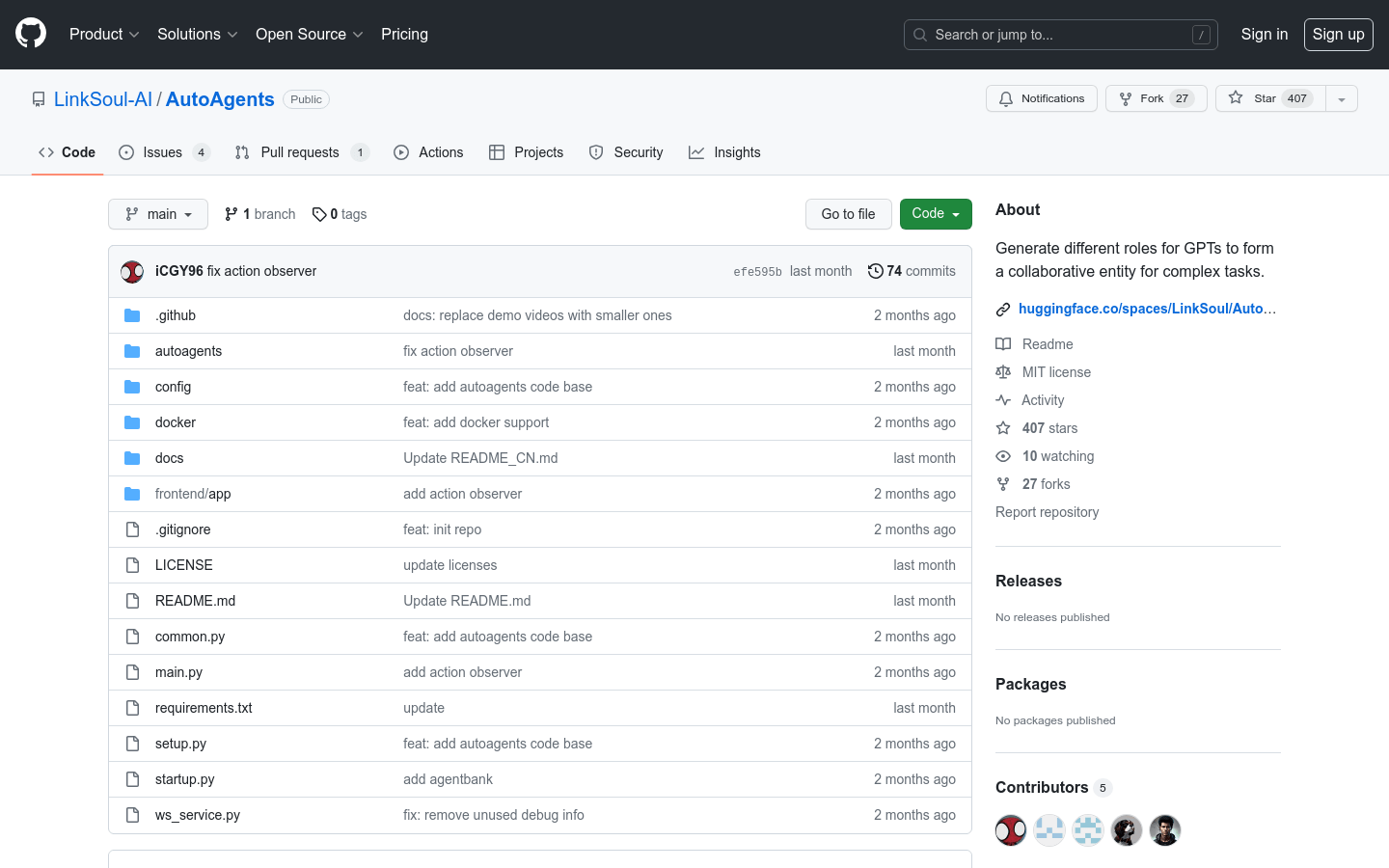
AutoAgents是一个开源的基于LLM的自动智能体生成实验应用程序。该程序由LLM驱动,可以根据你设定的目标自动生成多角色智能体。它可以根据问题确定需要添加的专家角色和具体的执行计划。包含智能体生成器、执行计划生成器、结果反思模块等。使LLM像人一样,可以根据问题自主地分配不同的角色,制定解决问题的计划并执行。
LM Studio是一个易于使用的桌面应用程序,用于在本地实验和运行本地和开源的Large Language Models (LLMs)。LM Studio跨平台桌面应用程序允许您从Hugging Face下载和运行任何ggml兼容的模型,并提供了一个简单而强大的模型配置和推理界面。该应用程序在有GPU的情况下利用您的GPU。