找到 171 个相关的AI工具
蛐蛐 (QuQu) 是一款开源免费的桌面端语音输入与文本处理工具,专为中文用户设计。它提供了隐私保护和本地处理功能,与 Wispr Flow 相比,无需支付订阅费用。通过集成 FunASR 本地模型,蛐蛐 能够精准识别中文,优化语音输入体验,适合开发者和普通用户使用。
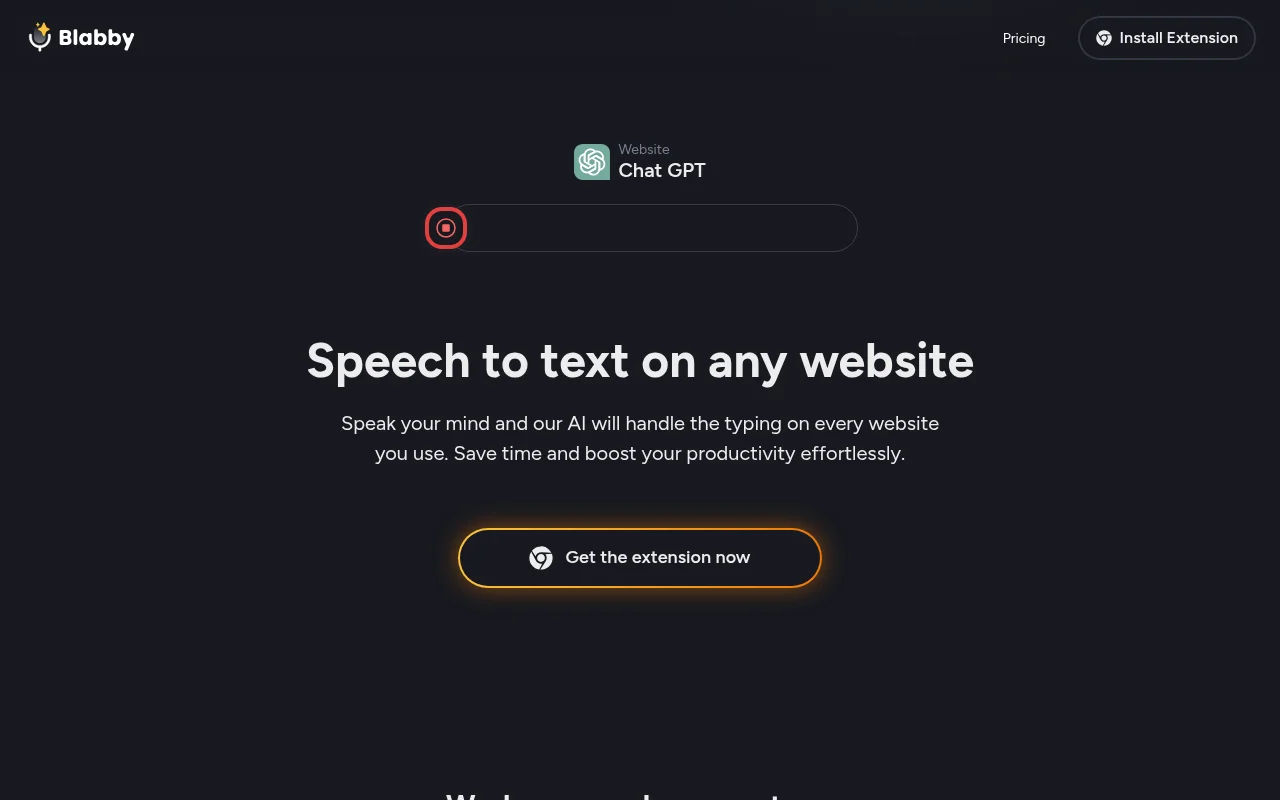
BlabbyAI是一款语音转文本的AI转录工具,以Chrome扩展的形式为用户提供服务。其重要性在于极大地提高了用户输入文本的效率,尤其适用于需要快速记录内容或不方便手动输入的场景。主要优点包括快速、准确的语音识别能力,能够在任意网站上实现无缝的语音打字。产品背景方面,它满足了现代社会人们对高效输入方式的需求。关于价格,文档未提及,推测可能有免费试用或付费模式。其定位是帮助用户提高生产力的语音输入辅助工具。
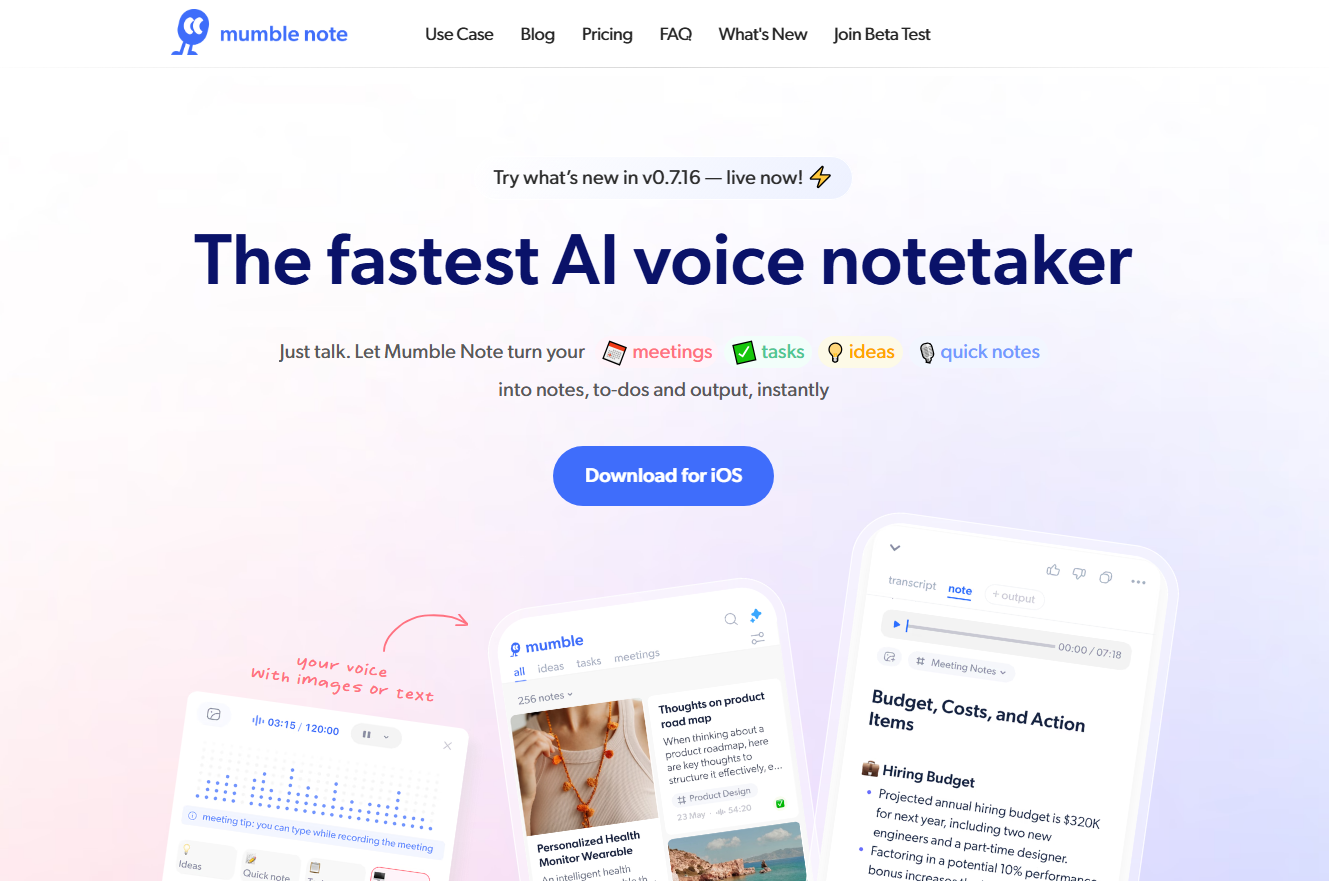
Mumble Note是一款AI语音速记工具,可以将用户的口述内容转换为清晰的笔记、待办事项和输出。该产品具有隐私保护、智能问答等功能,为用户提供高效的语音记录与管理体验。
Speechly是一款旨在将您的语音转化为结构化的电子邮件的工具,无需手动输入,即可轻松获得清晰易读的信息,支持多达100种语言。
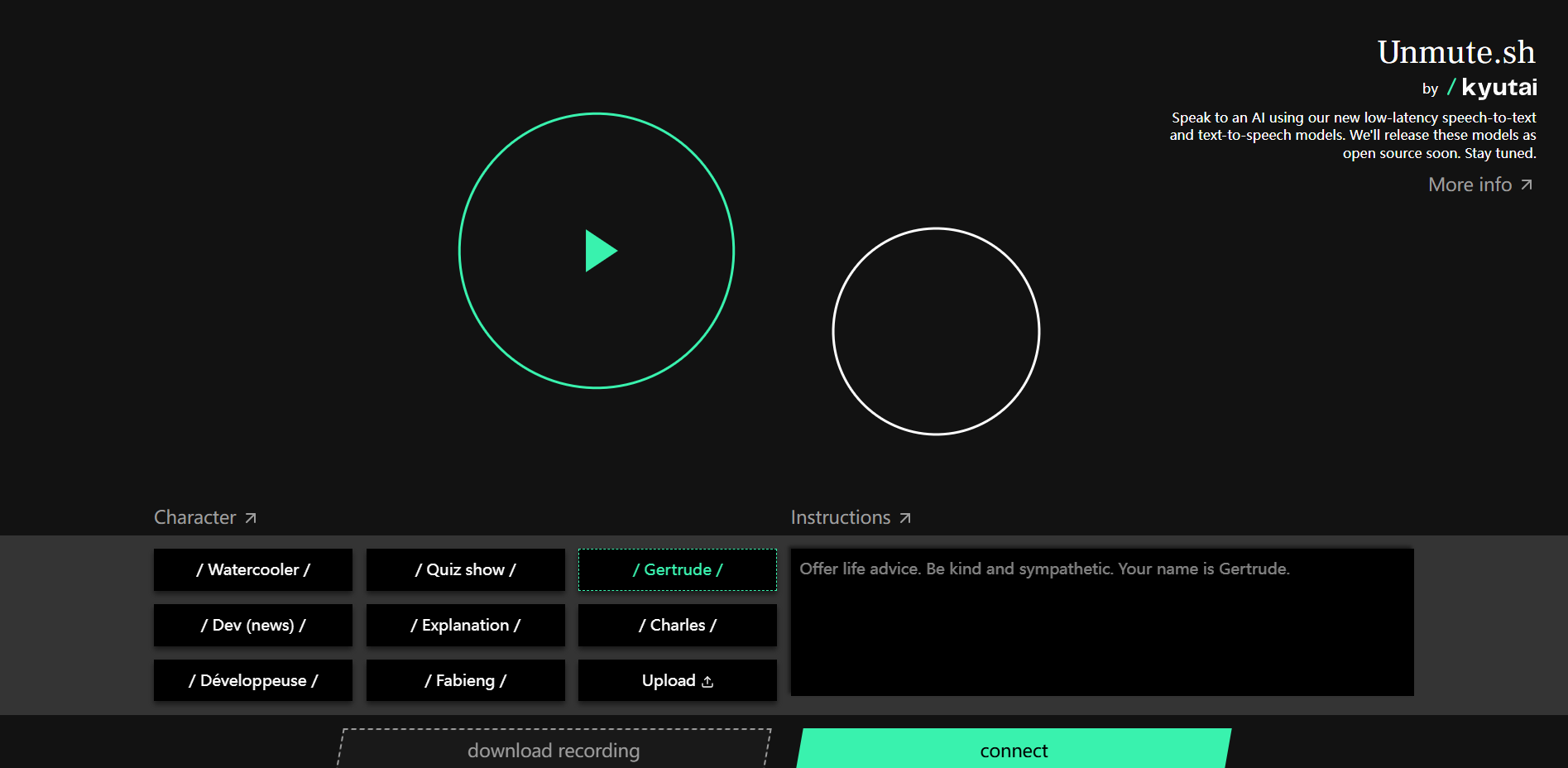
Unmute 是一款创新的语音识别与合成工具,旨在使用户能够通过自然语言与 AI 进行高效的互动。其低延迟技术确保用户体验流畅,适合需要实时反馈的场景。该产品将以开源形式发布,推动更多开发者和用户的参与。当前尚未公布价格,预计将采取免费和付费相结合的模式。
Kimi-Audio 是一个先进的开源音频基础模型,旨在处理多种音频处理任务,如语音识别和音频对话。该模型在超过 1300 万小时的多样化音频数据和文本数据上进行了大规模预训练,具有强大的音频推理和语言理解能力。它的主要优点包括优秀的性能和灵活性,适合研究人员和开发者进行音频相关的研究与开发。
Amazon Nova Sonic 是一款前沿的基础模型,能够整合语音理解和生成,提升人机对话的自然流畅度。该模型克服了传统语音应用中的复杂性,通过统一的架构实现更深层次的交流理解,适用于多个行业的 AI 应用,具有重要的商业价值。随着人工智能技术的不断发展,Nova Sonic 将为客户提供更好的语音交互体验,提升服务效率。
音刻转录是一款专注于音视频转录的在线工具,通过先进的语音识别技术,能够快速将音频或视频文件转换为文本。其主要优点包括转录速度快、准确率高、支持多种语言和文件格式。产品定位为高效办公和学习辅助工具,旨在帮助用户节省时间和精力,提升工作效率。音刻转录提供免费试用版本,用户可以体验其核心功能,付费版本则提供更多高级功能和大文件支持,满足不同用户的需求。
DuRT 是一款专注于 macOS 系统的语音识别和翻译工具。它通过本地 AI 模型和系统服务实现语音的实时识别与翻译,支持多种语音识别方法,提高了识别的准确度和语言支持范围。该产品以悬浮框形式展示结果,方便用户在使用过程中快速获取信息。其主要优点包括高准确度、隐私保护(不收集用户信息)以及便捷的操作体验。DuRT 定位为一款高效生产力工具,旨在帮助用户在多语言环境下更高效地进行沟通和工作。目前产品可在 Mac App Store 下载,具体价格未在页面中明确提及。
Scribe 是由 ElevenLabs 开发的高精度语音转文字模型,旨在处理真实世界音频的不可预测性。它支持99种语言,提供单词级时间戳、说话人分离和音频事件标记等功能。Scribe 在 FLEURS 和 Common Voice 基准测试中表现卓越,超越了 Gemini 2.0 Flash、Whisper Large V3 和 Deepgram Nova-3 等领先模型。它显著降低了传统服务不足语言(如塞尔维亚语、粤语和马拉雅拉姆语)的错误率,这些语言在竞争模型中的错误率通常超过40%。Scribe 提供 API 接口供开发者集成,并将推出低延迟版本以支持实时应用。
Phi-4-multimodal-instruct 是微软开发的多模态基础模型,支持文本、图像和音频输入,生成文本输出。该模型基于Phi-3.5和Phi-4.0的研究和数据集构建,经过监督微调、直接偏好优化和人类反馈强化学习等过程,以提高指令遵循能力和安全性。它支持多种语言的文本、图像和音频输入,具有128K的上下文长度,适用于多种多模态任务,如语音识别、语音翻译、视觉问答等。该模型在多模态能力上取得了显著提升,尤其在语音和视觉任务上表现出色。它为开发者提供了强大的多模态处理能力,可用于构建各种多模态应用。
FireRedASR-AED-L 是一个开源的工业级自动语音识别模型,专为满足高效率和高性能的语音识别需求而设计。该模型采用基于注意力的编码器-解码器架构,支持普通话、中文方言和英语等多种语言。它在公共普通话语音识别基准测试中达到了新的最高水平,并且在歌唱歌词识别方面表现出色。该模型的主要优点包括高性能、低延迟和广泛的适用性,适用于各种语音交互场景。其开源特性使得开发者可以自由地使用和修改代码,进一步推动语音识别技术的发展。
FireRedASR 是一个开源的工业级普通话自动语音识别模型,采用 Encoder-Decoder 和 LLM 集成架构。它包含两个变体:FireRedASR-LLM 和 FireRedASR-AED,分别针对高性能和高效能需求设计。该模型在普通话基准测试中表现出色,同时在方言和英文语音识别上也有良好表现。它适用于需要高效语音转文字的工业级应用,如智能助手、视频字幕生成等。模型开源,便于开发者集成和优化。
Bulletpen是一款创新的AI写作应用,旨在帮助用户将口头表达转化为高质量的书面文本。它通过语音识别和自然语言处理技术,将用户的口语内容进行优化和润色,生成结构清晰、语言流畅的书面文本。该产品的主要优点是能够显著提高写作效率,尤其适合那些在写作时感到困难或缺乏灵感的用户。Bulletpen由17岁的高中生Rexan Wong开发,目标是为学生、作家和内容创作者提供一个简单易用的写作辅助工具。它提供免费和付费两种计划,满足不同用户的需求。
Whisper Turbo 是基于 Whisper Large-v3 模型优化的语音识别工具,专为快速语音转录而设计。它利用先进的 AI 技术,能够高效地将不同音频源的语音转换为文本,支持多种语言和口音。该工具免费提供给用户,旨在帮助人们节省时间和精力,提高工作效率。其主要面向需要快速准确转录语音内容的用户,如博主、内容创作者、企业等,为他们提供便捷的语音转文字解决方案。
RealtimeSTT是一个开源的语音识别模型,能够实时将语音转换为文本。它使用了先进的语音活动检测技术,可以自动检测语音的开始和结束,无需手动操作。此外,它还支持唤醒词激活功能,用户可以通过说出特定的唤醒词来启动语音识别。该模型具有低延迟、高效率的特点,适合需要实时语音转录的应用场景,如语音助手、会议记录等。它基于Python开发,易于集成和使用,且在GitHub上开源,社区活跃,不断有新的更新和改进。
xiaozhi-esp32 是一个开源的 AI 聊天机器人项目,基于乐鑫的 ESP-IDF 开发。它将大语言模型与硬件设备相结合,使用户能够打造出个性化的 AI 伴侣。项目支持多种语言的语音识别与对话,具备声纹识别功能,能够识别不同用户的语音特征。其开源特性降低了 AI 硬件开发的门槛,为学生、开发者等群体提供了宝贵的学习资源,有助于推动 AI 技术在硬件领域的应用与创新。项目目前免费开源,适合不同层次的开发者进行学习与二次开发。
通义是一款集成了语音识别、实时字幕翻译、智能总结等功能的浏览器插件,旨在提高用户在网课、追剧追番、线上会议等场景下的效率。它通过AI技术,帮助用户快速记录、转写、翻译和总结网页内容,特别适合需要处理大量信息的用户。产品背景基于当前信息爆炸的时代,用户需要更高效的工具来管理、理解和消化信息。目前产品提供免费试用,具体价格和定位根据用户需求而定。
Robo Blogger是一个专注于将语音转换为博客文章的人工智能助手。它通过捕捉自然语言中的创意,将其结构化为有条理的博客内容,同时可以结合参考资料以确保文章的准确性和深度。这个工具基于之前Report mAIstro项目的概念,专为博客文章创作优化。通过分离创意捕捉和内容结构化,Robo Blogger帮助保持原始想法的真实性,同时确保专业呈现。
Moonshine Web是一个基于React和Vite构建的简单应用,它运行了Moonshine Base,这是一个针对快速准确自动语音识别(ASR)优化的强大语音识别模型,适用于资源受限的设备。该应用在浏览器端本地运行,使用Transformers.js和WebGPU加速(或WASM作为备选)。它的重要性在于能够为用户提供一个无需服务器即可在本地进行语音识别的解决方案,这对于需要快速处理语音数据的应用场景尤为重要。
OmniAudio-2.6B是一个2.6B参数的多模态模型,能够无缝处理文本和音频输入。该模型结合了Gemma-2B、Whisper turbo和一个自定义投影模块,与传统的将ASR和LLM模型串联的方法不同,它将这两种能力统一在一个高效的架构中,以最小的延迟和资源开销实现。这使得它能够安全、快速地在智能手机、笔记本电脑和机器人等边缘设备上直接处理音频文本。
Megrez-3B-Omni是由无问芯穹研发的端侧全模态理解模型,基于大语言模型Megrez-3B-Instruct扩展,具备图片、文本、音频三种模态数据的理解分析能力。该模型在图像理解、语言理解、语音理解方面均取得最优精度,支持中英文语音输入及多轮对话,支持对输入图片的语音提问,根据语音指令直接响应文本,在多项基准任务上取得了领先的结果。
Shortcut by Poised是一个基于语音的AI助手,旨在通过自然对话的方式提升用户的工作效率。它允许用户通过语音输入快速获得答案、整理思路、起草消息、电子邮件和文档,同时保持工作流程的连贯性。产品通过AI技术将自然语言转换为精炼的文本,并提供多种语言风格选项,满足不同场合的需求。Shortcut by Poised的背景信息显示,它在Product Hunt上发布,并即将推出Windows和移动应用版本,目前Mac版本已可下载。
Coval是一个专注于AI代理测试和评估的平台,旨在通过模拟和评估来提高AI代理的可靠性和效率。该平台由自主测试领域的专家构建,支持语音和聊天代理的测试,并提供全面的评估报告,帮助用户优化AI代理的性能。Coval的主要优点包括简化测试流程、提供AI驱动的模拟、兼容语音AI,以及提供详细的性能分析。产品背景信息显示,Coval旨在帮助企业快速、可靠地部署AI代理,提高客户服务的质量和效率。Coval提供三种定价计划,满足不同规模企业的需求。
Whisper-NER是一个创新的模型,它允许同时进行语音转录和实体识别。该模型支持开放类型的命名实体识别(NER),能够识别多样化和不断演变的实体。Whisper-NER旨在作为自动语音识别(ASR)和NER下游任务的强大基础模型,并且可以在特定数据集上进行微调以提高性能。
ultravox-v0_4_1-mistral-nemo是一个基于预训练的Mistral-Nemo-Instruct-2407和whisper-large-v3-turbo的多模态语音大型语言模型(LLM)。该模型能够同时处理语音和文本输入,例如,一个文本系统提示和一个语音用户消息。Ultravox通过特殊的<|audio|>伪标记将输入音频转换为嵌入,并生成输出文本。未来版本计划扩展标记词汇以支持生成语义和声学音频标记,进而可以输入到声码器中产生语音输出。该模型由Fixie.ai开发,采用MIT许可。
fixie-ai/ultravox-v0_4_1-llama-3_1-70b是一个基于预训练的Llama3.1-70B-Instruct和whisper-large-v3-turbo的大型语言模型,能够处理语音和文本输入,生成文本输出。该模型通过特殊伪标记<|audio|>将输入音频转换为嵌入,并与文本提示合并后生成输出文本。Ultravox的开发旨在扩展语音识别和文本生成的应用场景,如语音代理、语音到语音翻译和口语音频分析等。该模型遵循MIT许可,由Fixie.ai开发。
fixie-ai/ultravox-v0_4_1-llama-3_1-8b是一个基于预训练的Llama3.1-8B-Instruct和whisper-large-v3-turbo的大型语言模型,能够处理语音和文本输入,生成文本输出。该模型通过特殊的<|audio|>伪标记将输入音频转换为嵌入,并生成输出文本。未来版本计划扩展标记词汇以支持生成语义和声学音频标记,进而可以用于声码器产生语音输出。该模型在翻译评估中表现出色,且没有偏好调整,适用于语音代理、语音到语音翻译、语音分析等场景。
Ultravox.ai是一个先进的语音语言模型(SLM),直接处理语音,无需转换为文本,实现更自然、流畅的对话。它支持多语言,易于适应新语言或口音,确保与不同受众的顺畅沟通。产品背景信息显示,Ultravox.ai是一个开源模型,用户可以根据自己的需求进行定制和部署,价格为每分钟5美分。
卡卡字幕助手(VideoCaptioner)是一款功能强大的视频字幕配制软件,利用大语言模型进行字幕智能断句、校正、优化、翻译,实现字幕视频全流程一键处理。产品无需高配置,操作简单,内置基础LLM模型,保证开箱即用,且消耗模型Token少,适合视频制作者和内容创作者。
Najva是一款专为Mac设计的AI驱动的语音助手,它结合了先进的本地语音识别技术和强大的AI模型,将您的语音转换成智能文本。这款应用特别适合那些思维速度比打字速度快的用户,如作家、开发者、医疗专业人员等。Najva以其轻量级、原生Swift应用、零追踪和完全免费等特点,为用户提供了一个注重隐私和效率的工作流程解决方案。
hertz-dev是Standard Intelligence开源的全双工、仅音频的变换器基础模型,拥有85亿参数。该模型代表了可扩展的跨模态学习技术,能够将单声道16kHz语音转换为8Hz潜在表示,具有1kbps的比特率,性能优于其他音频编码器。hertz-dev的主要优点包括低延迟、高效率和易于研究人员进行微调和构建。产品背景信息显示,Standard Intelligence致力于构建对全人类有益的通用智能,而hertz-dev是这一旅程的第一步。
Transcribro是一款运行在Android平台上的私有、设备端语音识别键盘和文字服务应用,它使用whisper.cpp来运行OpenAI Whisper系列模型,并结合Silero VAD进行语音活动检测。该应用提供了语音输入键盘,允许用户通过语音进行文字输入,并且可以被其他应用显式使用,或者设置为用户选择的语音转文字应用,部分应用可能会使用它来进行语音转文字。Transcribro的背景是为用户提供一种更安全、更私密的语音转文字解决方案,避免了云端处理可能带来的隐私泄露问题。该应用是开源的,用户可以自由地查看、修改和分发代码。
Universal-2是AssemblyAI推出的最新语音识别模型,它在准确度和精确度上超越了前一代Universal-1,能够更好地捕捉人类语言的复杂性,为用户提供无需二次检查的音频数据。这一技术的重要性在于它能够为产品体验提供更敏锐的洞察力、更快的工作流程和一流的产品体验。Universal-2在专有名词识别、文本格式化和字母数字识别方面都有显著提升,减少了实际应用中的词错误率。
GLM-4-Voice是由清华大学团队开发的端到端语音模型,能够直接理解和生成中英文语音,进行实时语音对话。它通过先进的语音识别和合成技术,实现了语音到文本再到语音的无缝转换,具备低延迟和高智商的对话能力。该模型在语音模态下的智商和合成表现力上进行了优化,适用于需要实时语音交互的场景。
Whispo是一款利用人工智能技术的语音听写工具,它能够将用户的语音实时转换成文字。这款工具使用了OpenAI Whisper技术进行语音识别,并支持使用自定义API进行语音转写,还允许通过大型语言模型进行转录后处理。Whispo支持多种操作系统,包括macOS(Apple Silicon)和Windows x64,并且所有数据都存储在本地,保障了用户隐私。它的设计背景是为了提高那些需要大量文字输入的用户的工作效率,无论是编程、写作还是日常记录。Whispo目前是免费试用的,但具体的定价策略尚未在页面上明确。
Spirit LM是一个基础多模态语言模型,能够自由混合文本和语音。该模型基于一个7B预训练的文本语言模型,通过持续在文本和语音单元上训练来扩展到语音模式。语音和文本序列被串联为单个令牌流,并使用一个小的自动策划的语音-文本平行语料库,采用词级交错方法进行训练。Spirit LM有两个版本:基础版使用语音音素单元(HuBERT),而表达版除了音素单元外,还使用音高和风格单元来模拟表达性。对于两个版本,文本都使用子词BPE令牌进行编码。该模型不仅展现了文本模型的语义能力,还展现了语音模型的表达能力。此外,我们展示了Spirit LM能够在少量样本的情况下跨模态学习新任务(例如ASR、TTS、语音分类)。
FunASR是一款语音离线文件转写服务软件包,集成了语音端点检测、语音识别、标点等模型,能够将长音频与视频转换成带标点的文字,并支持多路请求同时转写。它支持ITN与用户自定义热词,服务端集成有ffmpeg,支持多种音视频格式输入,并提供多种编程语言客户端,适用于需要高效、准确语音转写服务的企业和开发者。
AsrTools是一款基于人工智能技术的语音转文字工具,它通过调用大厂的ASR服务接口,实现了无需GPU和复杂配置的高效语音识别功能。该工具支持批量处理和多线程并发,能够快速将音频文件转换成SRT或TXT格式的字幕文件。AsrTools的用户界面基于PyQt5和qfluentwidgets,提供高颜值且易于操作的交互体验。它的主要优点包括调用大厂接口的稳定性、无需复杂配置的便捷性、以及多格式输出的灵活性。AsrTools适合需要快速将语音内容转换成文字的用户,特别是在视频制作、音频编辑和字幕生成等领域。目前,AsrTools提供免费使用大厂ASR服务的模式,对于个人和小团队来说,可以显著降低成本并提高工作效率。
NotesGPT是一款利用人工智能技术将用户的语音笔记转换成有组织的摘要和清晰的行动项的在线服务。它通过先进的语音识别和自然语言处理技术,帮助用户更高效地记录和管理笔记,特别适合需要快速记录信息并整理成结构化内容的用户。产品背景信息显示,NotesGPT由Together.ai和Convex提供技术支持,这表明其背后有着强大的AI技术支撑。目前,该产品似乎处于推广阶段,具体价格和定位信息未在页面中明确展示。
Reverb 是一个开源的语音识别和说话人分割模型推理代码,使用 WeNet 框架进行语音识别 (ASR) 和 Pyannote 框架进行说话人分割。它提供了详细的模型描述,并允许用户从 Hugging Face 下载模型。Reverb 旨在为开发者和研究人员提供高质量的语音识别和说话人分割工具,以支持各种语音处理任务。
Rev AI提供高精度的语音转录服务,支持58种以上语言,能够将视频和语音应用中的语音转换为文本。它通过使用世界上最多样化的声音集合进行训练,为视频和语音应用设定了准确性标准。Rev AI还提供实时流媒体转录、人类转录、语言识别、情感分析、主题提取、总结和翻译等服务。Rev AI的技术优势在于低词错误率、对性别和种族口音的最小偏见、支持更多语言以及提供最易读的转录文本。此外,它还符合世界顶级的安全标准,包括SOC II、HIPAA、GDPR和PCI合规性。
AI-Powered Meeting Summarizer是一个基于Gradio的网站应用,能够将会议录音转换为文本,并使用whisper.cpp进行音频到文本的转换,以及Ollama服务器进行文本摘要。该工具非常适合快速提取会议中的关键点、决策和行动项目。
EMOVA(EMotionally Omni-present Voice Assistant)是一个多模态语言模型,它能够进行端到端的语音处理,同时保持领先的视觉-语言性能。该模型通过语义-声学解耦的语音分词器,实现了情感丰富的多模态对话,并在视觉-语言和语音基准测试中达到了最先进的性能。
OmniSenseVoice是基于SenseVoice优化的语音识别模型,专为快速推理和精确时间戳设计,提供更智能、更快速的音频转录方式。
Deepgram Voice Agent API 是一个统一的语音到语音API,它允许人类和机器之间进行自然听起来的对话。该API由行业领先的语音识别和语音合成模型提供支持,能够自然且实时地听、思考和说话。Deepgram致力于通过其语音代理API推动语音优先AI的未来,通过集成先进的生成AI技术,打造能够进行流畅、类似人类语音代理的业务世界。
讯飞星火是科大讯飞推出的一款全面对标GPT-4 Turbo的AI大语言模型,它通过集成多种AI技术,如语音识别、自然语言处理、机器学习等,为用户提供高效、智能的办公效率工具。该产品不仅能够处理文本信息,还能进行语音识别和生成,支持多语种,适用于企业服务、智能硬件、智慧政务、智慧金融、智慧医疗等多个领域。
讯飞虚拟人利用最新的AI虚拟形象技术,结合语音识别、语义理解、语音合成、NLP、星火大模型等AI核心技术,提供虚拟人形象资产构建、AI驱动、多模态交互的多场景虚拟人产品服务。一站式虚拟人音视频内容生产,AIGC助力创作灵活高效;在虚拟'AI演播室'中输入文本或录音,一键完成音、视频作品的输出,3分钟内渲染出稿。
EVI 2是Hume AI推出的新型基础语音对语音模型,能够以接近人类的自然方式与用户进行流畅对话。它具备快速响应、理解用户语调、生成不同语调、以及执行特定请求的能力。EVI 2通过特殊训练增强了情感智能,能够预测并适应用户的偏好,维持有趣且引人入胜的性格和个性。此外,EVI 2还具有多语言能力,能够适应不同应用场景和用户需求。
心辰Lingo语音大模型是一款先进的人工智能语音模型,专注于提供高效、准确的语音识别和处理服务。它能够理解并处理自然语言,使得人机交互更加流畅和自然。该模型背后依托西湖心辰强大的AI技术,致力于在各种场景下提供高质量的语音交互体验。
聆龙是一款AI笔记助手,它通过语音AI笔记功能,支持用户随时记录信息,并以富文本形式保存。它还具备AI智能标签功能,能够自动生成标题,帮助用户与自己的知识库进行对话。此外,聆龙采用了独创的AI卡片盒笔记法,让用户能够不断记录,实现知识的自然呈现。产品支持多平台同步,包括安卓、苹果和Web版,满足不同用户的需求。
Aixploria是一个专注于人工智能的网站,提供在线AI工具目录,帮助用户发现和选择满足其需求的最佳AI工具。该平台以简化的设计和直观的搜索引擎,让用户能够轻松地通过关键词搜索,找到各种AI应用。Aixploria不仅提供工具列表,还发布关于每个AI如何工作的文章,帮助用户理解最新趋势和最受欢迎的应用。此外,Aixploria还设有实时更新的'top 10 AI'专区,方便用户快速了解每个类别中的顶级AI工具。Aixploria适合所有对AI感兴趣的人,无论是初学者还是专家,都能在这里找到有价值的信息。
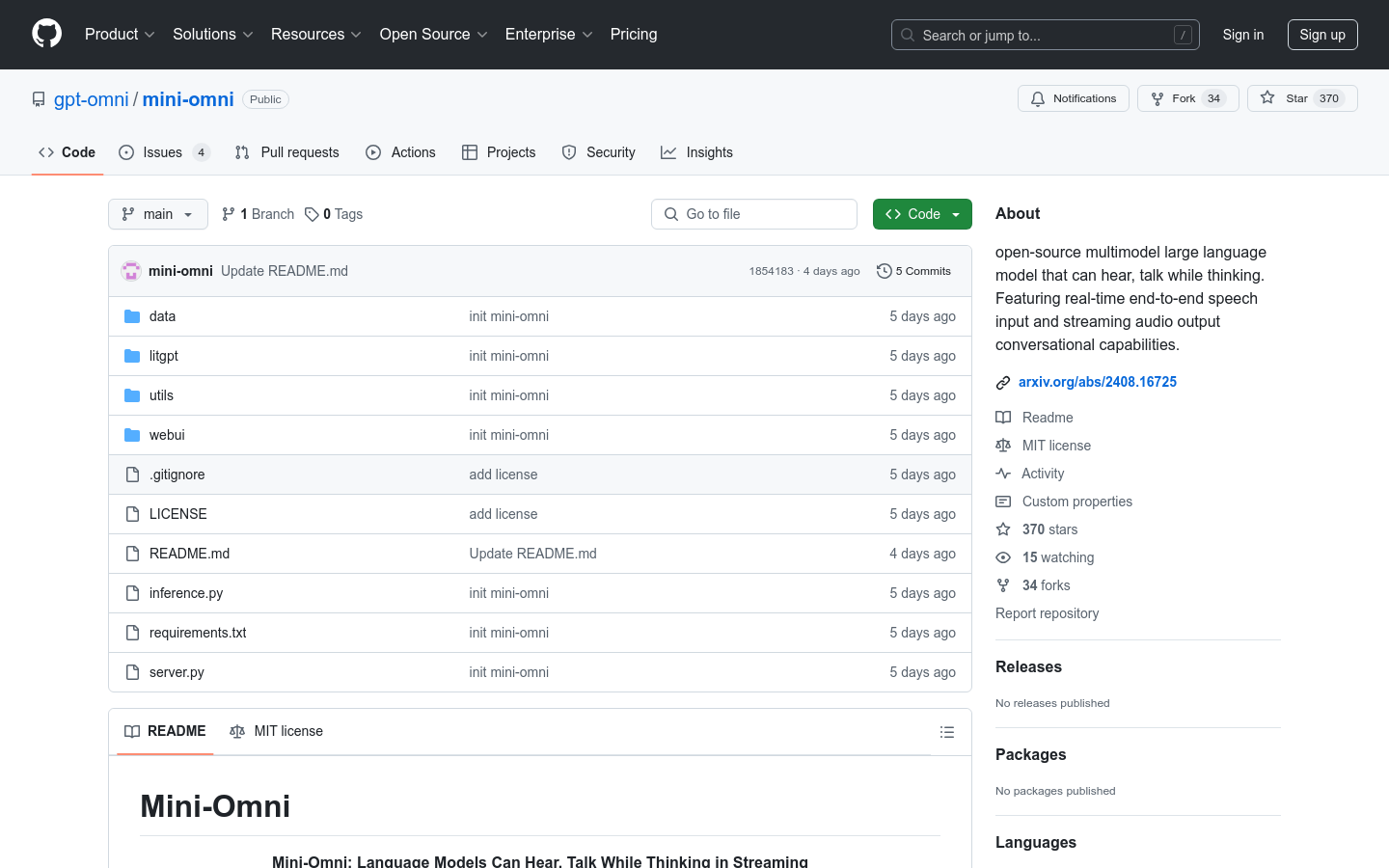
Mini-Omni是一个开源的多模态大型语言模型,能够实现实时的语音输入和流式音频输出的对话能力。它具备实时语音到语音的对话功能,无需额外的ASR或TTS模型。此外,它还可以在思考的同时进行语音输出,支持文本和音频的同时生成。Mini-Omni通过'Audio-to-Text'和'Audio-to-Audio'的批量推理进一步增强性能。
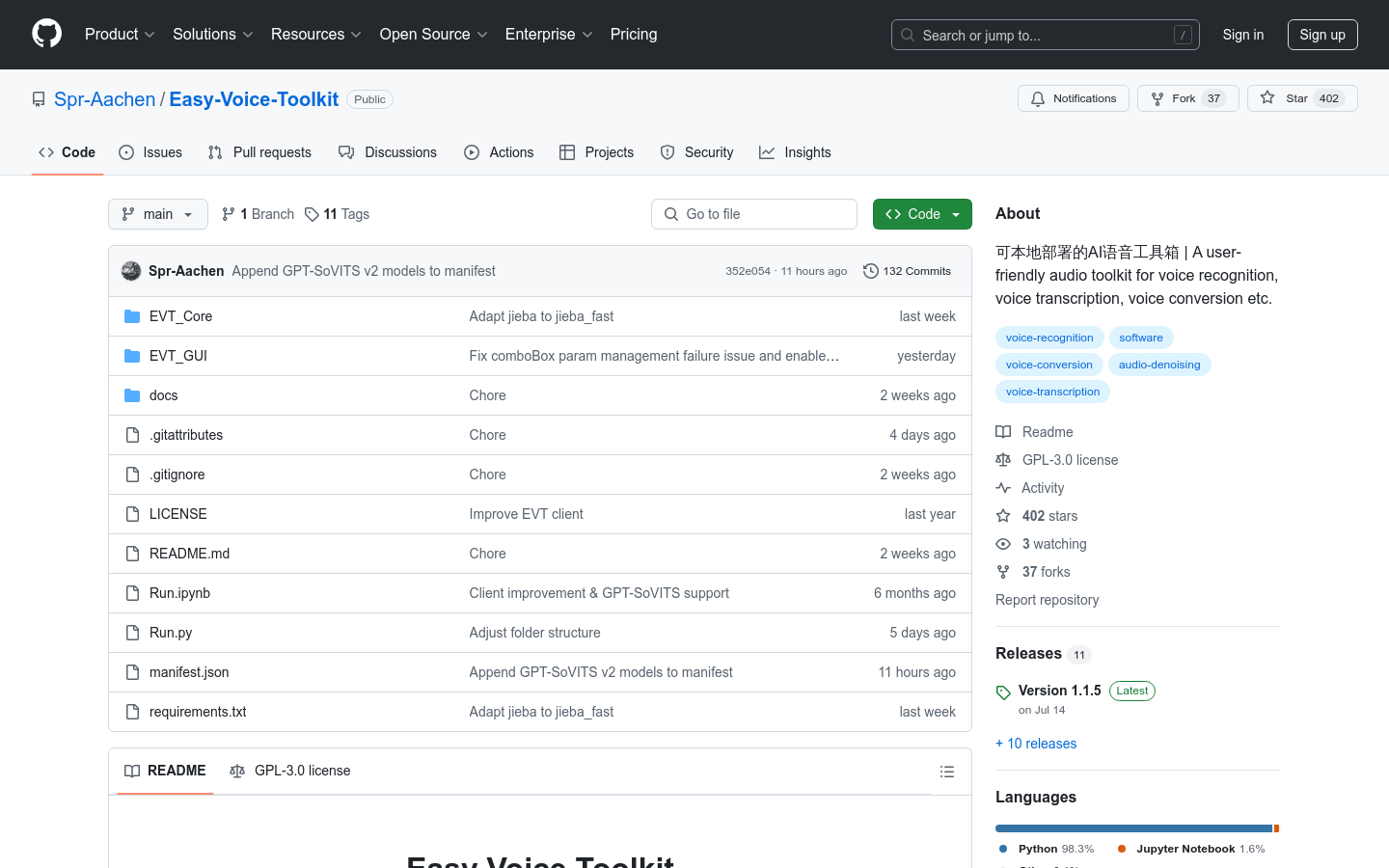
Easy Voice Toolkit是一个基于开源语音项目的AI语音工具箱,提供包括语音模型训练在内的多种自动化音频工具。该工具箱能够无缝集成,形成完整的工作流程,用户可以根据需要选择性使用这些工具,或按顺序使用,逐步将原始音频文件转换为理想的语音模型。
OpenVoiceChat是一个开源项目,旨在提供一个与大型语言模型(LLM)进行自然语音对话的平台。它支持多种语音识别(STT)、文本到语音(TTS)和LLM模型,允许用户通过语音与AI进行交互。项目采用Apache-2.0许可,强调开放性和易用性,目标是成为封闭商业实现的开源替代品。
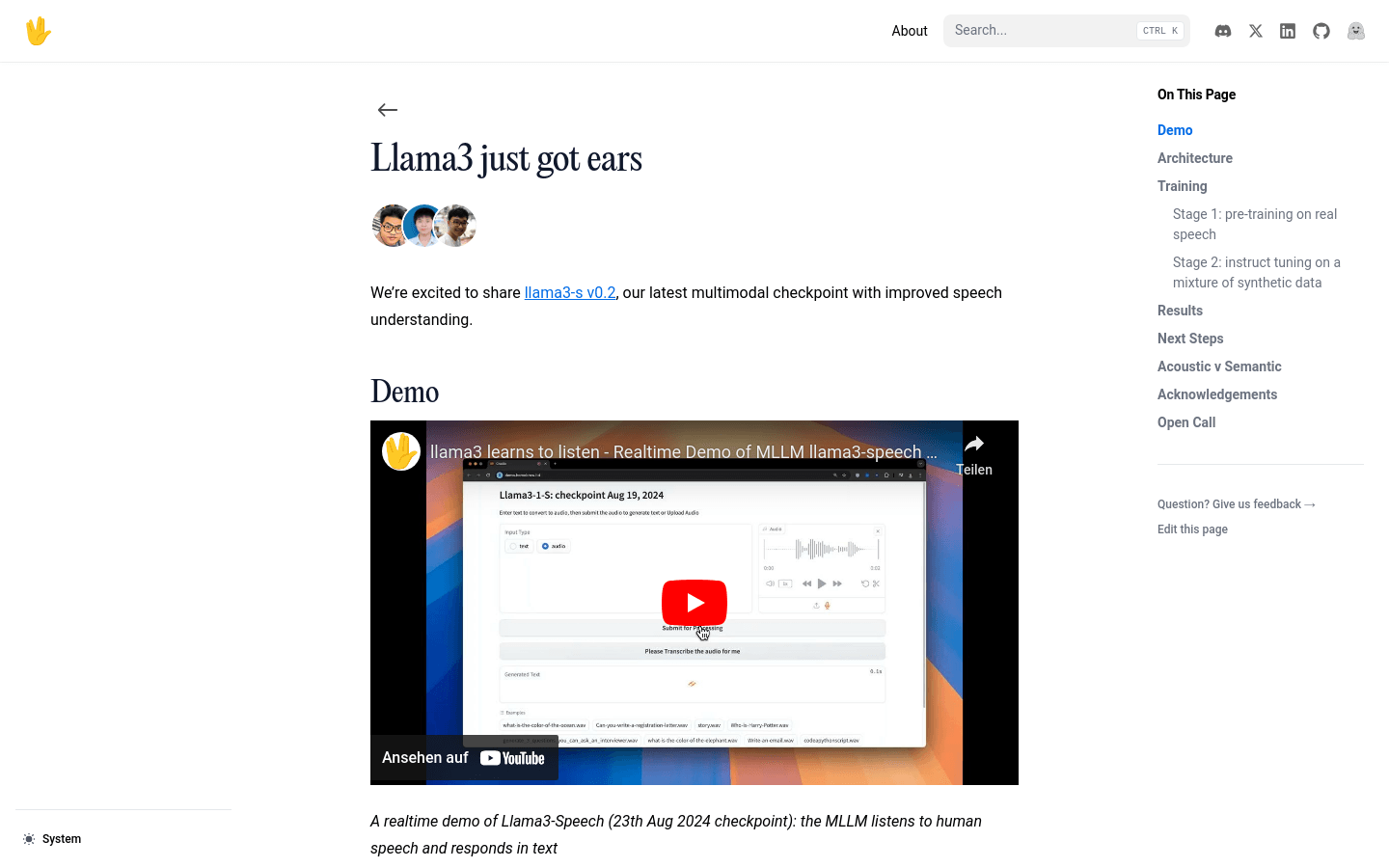
Llama3-s v0.2 是 Homebrew Computer Company 开发的多模态检查点,专注于提升语音理解能力。该模型通过早期融合语义标记的方式,利用社区反馈进行改进,以简化模型结构,提高压缩效率,并实现一致的语音特征提取。Llama3-s v0.2 在多个语音理解基准测试中表现稳定,并提供了实时演示,允许用户亲自体验其功能。尽管模型仍在早期开发阶段,存在一些限制,如对音频压缩敏感、无法处理超过10秒的音频等,但团队计划在未来更新中解决这些问题。
Encounter AI - Advisor是一款利用SRI的隐马尔可夫模型(HMM)基础的语音识别技术,为多单位餐厅运营商提供实时的音频监控服务。它通过先进的技术,精准跟踪和分析餐厅层面的每一段对话,消除了常见的“他说/她说”的主观性问题,为零售领导者提供实时对话分析,帮助他们实现目标,增加收入。
Seed-ASR是由字节跳动公司开发的基于大型语言模型(Large Language Model, LLM)的语音识别模型。它通过将连续的语音表示和上下文信息输入到LLM中,利用LLM的能力,在大规模训练和上下文感知能力的引导下,显著提高了在包括多个领域、口音/方言和语言的综合评估集上的表现。与最近发布的大型ASR模型相比,Seed-ASR在中英文公共测试集上实现了10%-40%的词错误率降低,进一步证明了其强大的性能。
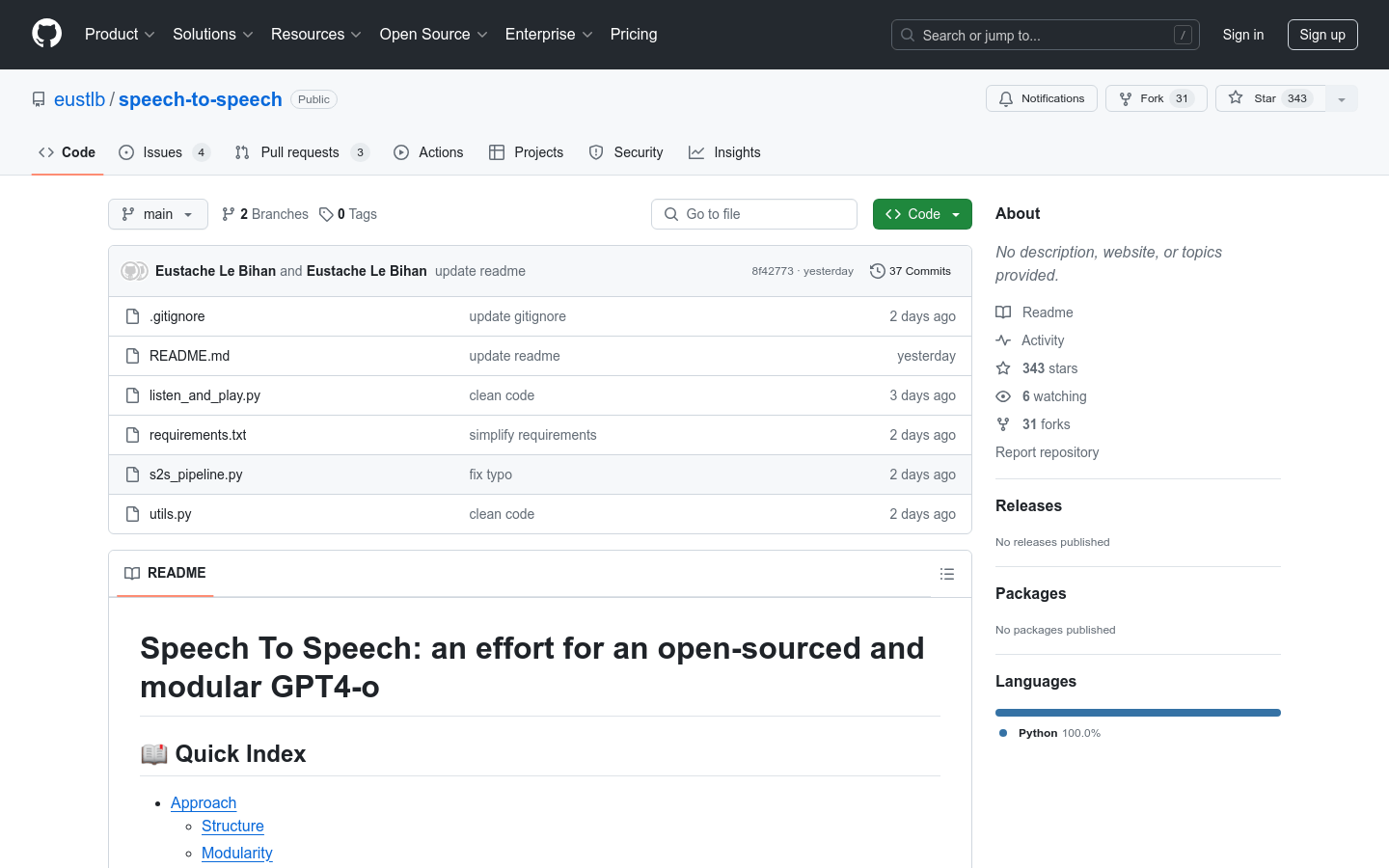
speech-to-speech 是一个开源的模块化GPT4-o项目,通过语音活动检测、语音转文本、语言模型和文本转语音等连续部分实现语音到语音的转换。它利用了Transformers库和Hugging Face hub上可用的模型,提供了高度的模块化和灵活性。
汉王语音王App是汉王科技基于自研多模态天地大模型,自主研发的智能语音旗舰应用。它集AI语音记录、智能翻译与同声传译于一体,支持AI精准转写、拍录同步、话稿整理、智能总结及不间断实时翻译等功能。依托全栈AI技术,汉王语音王致力于帮助用户跨越语言障碍,提高办公、学习、会议、旅游等场景的效率和便捷性。
whisper-diarization是一个结合了Whisper自动语音识别(ASR)能力、声音活动检测(VAD)和说话人嵌入技术的开源项目。它通过提取音频中的声音部分来提高说话人嵌入的准确性,然后使用Whisper生成转录文本,并通过WhisperX校正时间戳和对齐,以减少由于时间偏移导致的分割错误。接着,使用MarbleNet进行VAD和分割以排除静音,TitaNet用于提取说话人嵌入以识别每个段落的说话人,最后将结果与WhisperX生成的时间戳关联,基于时间戳检测每个单词的说话人,并使用标点模型重新对齐以补偿小的时间偏移。
Qwen2 Audio Instruct Demo 是一个基于音频指令的交互式演示网站,它利用最新的人工智能技术,让用户通过语音指令与网页进行互动。这种技术不仅增强了用户体验,还为残障人士提供了更便捷的访问方式。产品背景信息包括其开发团队和技术支持,价格定位为免费试用,主要面向对人工智能交互感兴趣的用户群体。
WeST是一个开源的语音识别转录模型,以300行代码的简洁形式,基于大型语言模型(LLM)实现语音到文本的转换。它由一个大型语言模型、一个语音编码器和一个投影器组成,其中仅投影器部分可训练。WeST的开发灵感来源于SLAM-ASR和LLaMA 3.1,旨在通过简化的代码实现高效的语音识别功能。
Listening-while-Speaking Language Model (LSLM)是一款旨在提升人机交互自然度的人工智能对话模型。它通过全双工建模(FDM)技术,实现了在说话时同时监听的能力,增强了实时交互性,尤其是在生成内容不满意时能够被打断和实时响应。LSLM采用了基于token的解码器仅TTS进行语音生成,以及流式自监督学习(SSL)编码器进行实时音频输入,通过三种融合策略(早期融合、中期融合和晚期融合)探索最佳交互平衡。
Voice Assistant Plugin for GPT 是一款专为GPT设计的语音助手插件,旨在通过语音交互提升用户体验。该插件结合了先进的语音识别技术,允许用户通过语音命令与GPT进行交流,实现更加自然和便捷的对话体验。产品背景信息显示,该插件由Air Tech Studio开发,支持多语言,并且注重用户数据安全,不与第三方分享任何数据。
Say My Name! 是一款以趣味和个性化为核心的语音识别应用。它利用先进的语音识别技术,让用户的设备能够识别和响应用户的声音,尤其是用户的名字。这款应用不仅增加了用户与设备互动的乐趣,还提升了操作的便捷性。Say My Name! 的主要优点包括高准确率的语音识别、个性化的口令设置以及用户友好的操作界面。
PC Agent是一款利用人工智能技术,通过屏幕内容和音频转录来理解用户的电脑环境,从而提供更加精准的辅助服务。它旨在解决当前聊天机器人的局限性,通过更深层次的交互提升用户体验。产品背景信息显示,PC Agent注重于提升个人电脑的使用效率,其主要优点包括智能理解环境、提供个性化帮助和持续的功能更新。
AIAvatarKit是一个用于快速构建基于AI的会话头像的工具。它支持在VRChat、集群和其他元宇宙平台以及现实世界的设备上运行。该工具易于启动,具有无限的扩展能力,可以根据用户的需求进行定制。主要优点包括:1. 多平台支持:可以在多种平台上运行,包括VRChat、集群和元宇宙平台。2. 易于启动:用户可以立即开始对话,无需复杂的设置。3. 扩展性:用户可以根据需要添加无限功能。4. 技术支持:需要VOICEVOX API、Google或Azure的语音服务API密钥以及OpenAI API密钥。
SenseVoiceSmall是一款具备多种语音理解能力的语音基础模型,包括自动语音识别(ASR)、口语语言识别(LID)、语音情感识别(SER)和音频事件检测(AED)。该模型经过超过40万小时的数据训练,支持超过50种语言,识别性能超越Whisper模型。其小型模型SenseVoice-Small采用非自回归端到端框架,推理延迟极低,处理10秒音频仅需70毫秒,比Whisper-Large快15倍。此外,SenseVoice还提供便捷的微调脚本和策略,支持多并发请求的服务部署管道,客户端语言包括Python、C++、HTML、Java和C#等。
Onyxium是一个综合性的AI工具平台,提供包括图像识别、文本分析、语音识别等在内的多种AI技术。它旨在帮助用户轻松访问最新AI技术,以低成本使用这些工具,提升项目和工作流程的效率。
FunAudioLLM是一个旨在增强人类与大型语言模型(Large Language Models, LLMs)之间自然语音交互的框架。它包含两个创新模型:SenseVoice负责高精度多语种语音识别、情绪识别和音频事件检测;CosyVoice负责自然语音生成,支持多语种、音色和情绪控制。SenseVoice支持超过50种语言,具有极低的延迟;CosyVoice擅长多语种语音生成、零样本上下文生成、跨语言语音克隆和指令跟随能力。相关模型已在Modelscope和Huggingface上开源,并在GitHub上发布了相应的训练、推理和微调代码。
SenseVoice是一个包含自动语音识别(ASR)、语音语言识别(LID)、语音情感识别(SER)和音频事件检测(AED)等多语音理解能力的语音基础模型。它专注于高精度多语种语音识别、语音情感识别和音频事件检测,支持超过50种语言,识别性能超越Whisper模型。模型采用非自回归端到端框架,推理延迟极低,是实时语音处理的理想选择。
Azure 认知服务语音是微软推出的一款语音识别与合成服务,支持超过100种语言和方言的语音转文本和文本转语音功能。它通过创建可处理特定术语、背景噪音和重音的自定义语音模型,提高听录的准确度。此外,该服务还支持实时语音转文本、语音翻译、文本转语音等功能,适用于多种商业场景,如字幕生成、通话后听录分析、视频翻译等。
GPT-4o是OpenAI的最新创新,代表了人工智能技术的前沿。它通过真正的多模态方法扩展了GPT-4的功能,包括文本、视觉和音频。GPT-4o以其快速、成本效益和普遍可访问性,革命性地改变了我们与AI技术的互动。它在文本理解、图像分析和语音识别方面表现出色,提供流畅直观的AI互动,适合从学术研究到特定行业需求的多种应用。
sherpa-onnx 是一个基于下一代 Kaldi 的语音识别和语音合成项目,使用onnxruntime进行推理,支持多种语音相关功能,包括语音转文字(ASR)、文字转语音(TTS)、说话人识别、说话人验证、语言识别、关键词检测等。它支持多种平台和操作系统,包括嵌入式系统、Android、iOS、Raspberry Pi、RISC-V、服务器等。
StreamSpeech是一款基于多任务学习的实时语音到语音翻译模型。它通过统一框架同时学习翻译和同步策略,有效识别流式语音输入中的翻译时机,实现高质量的实时通信体验。该模型在CVSS基准测试中取得了领先的性能,并能提供低延迟的中间结果,如ASR或翻译结果。
LookOnceToHear 是一种创新的智能耳机交互系统,允许用户通过简单的视觉识别来选择想要听到的目标说话者。这项技术在 CHI 2024 上获得了最佳论文荣誉提名。它通过合成音频混合、头相关传输函数(HRTFs)和双耳房间脉冲响应(BRIRs)来实现实时语音提取,为用户提供了一种新颖的交互方式。
BeMyEars 是一款实时字幕生成工具,利用本地设备完成语音识别,为听障人士和需要字幕的用户提供极致体验。其主要优点包括多语言支持、多源输入、隐私保护等。
Transkriptor是一款将音频转换为文本的浏览器插件。它使用先进的人工智能技术,可以自动记录和转录会议、访谈和讲座等不同类型的语音内容。Transkriptor具有简单直观的界面,支持多种文件格式,提供安全的转录服务,并具备生成字幕、支持多语言转录和远程协作编辑等功能。
Chartnote是一款能够快速完成医学文档的插件。它通过使用生成式人工智能、语音识别和智能模板等技术,将医疗记录的撰写变得轻松快捷。它的主要优点是提高工作效率、减少文档撰写时间、提供准确的临床记录。Chartnote适用于医生、护士和其他医疗从业者。
Gemini 1.5 Flash是Google DeepMind团队推出的最新AI模型,它通过'蒸馏'过程从更大的1.5 Pro模型中提炼出核心知识和技能,以更小、更高效的模型形式提供服务。该模型在多模态推理、长文本处理、聊天应用、图像和视频字幕生成、长文档和表格数据提取等方面表现出色。它的重要性在于为需要低延迟和低成本服务的应用提供了解决方案,同时保持了高质量的输出。
FunClip是一款完全开源、本地部署的自动化视频剪辑工具,通过调用阿里巴巴通义实验室开源的FunASR Paraformer系列模型进行视频的语音识别,随后用户可以自由选择识别结果中的文本片段或说话人,点击裁剪按钮即可获取对应片段的视频。FunClip集成了阿里巴巴开源的工业级模型Paraformer-Large,是当前识别效果最优的开源中文ASR模型之一,并且能够一体化的准确预测时间戳。
TransLinguist是一款远程口译产品,通过语音识别和自动翻译技术,在各种语言之间进行实时口译。它提供高质量的远程口译服务,帮助用户在会议、培训、演讲和其他活动中消除语言障碍。TransLinguist的主要优点是节省成本、增加观众参与度,并且提供安全可靠的语言服务。
Retell AI是一个强大的AI代理构建平台,允许用户快速构建和测试复杂的工作流程,并通过电话呼叫、网络呼叫或任何其他地方部署它们。该平台支持使用任何大型语言模型(LLM),并提供了实时的交互体验,包括人类般的声音和语音克隆支持。Retell AI的主要优点包括低延迟、高稳定性和符合HIPAA标准的安全性。
boff.ai是一款基于人工智能的语音识别和自然语言处理技术的网站。它的主要优点是快速准确地识别用户的语音输入并能够理解其意图,从而提供相应的回答和建议。boff.ai的定位是提供智能的语音助手服务,帮助用户更高效地处理信息和完成任务。
A.I.智能客服解决方案是科大讯飞基于其先进的语音技术,为企业提供的一套完整的客户服务系统。该系统通过电话、Web、APP、小程序、自助终端等多种渠道,实现智能外呼、智能接听、语音导航、在线文字客服、质检分析、坐席辅助等功能。它通过高识别率的语音识别引擎、自然流畅的语音合成技术、智能打断能力、IVR导航以及客服平台中间件等技术,帮助企业提高客服效率,降低人力成本,同时提升客户服务体验。
飞书妙记是智能会议纪要工具,可将会议内容转录成易搜索、可翻译的逐字稿,自动总结会议纪要与待办事项,提升回顾和协作效率。
WhisperKit由Argmax公司推出,是一个基于Whisper项目的推理工具包,它允许在iOS和macOS应用程序中进行语音识别和转录。该项目的目标是收集开发者反馈,并在几周内发布一个稳定的候选版本,以加速设备上推理的生产化。
Luzia是一款智能助手,通过WhatsApp轻松访问人工智能的力量,无需注册,完全免费。Luzia可以帮助你处理工作、学校、社交和追求激情的日常任务。
AnyGPT是一个统一的多模态大型语言模型,利用离散表示进行各种模态的统一处理,包括语音、文本、图像和音乐。AnyGPT可以在不改变当前大型语言模型架构或训练范式的情况下稳定训练。它完全依赖于数据级预处理,促进了新模态无缝集成到语言模型中,类似于新的语言的加入。我们构建了一个用于多模态对齐预训练的以文本为中心的多模态数据集。利用生成模型,我们合成了第一个大规模的任意到任意的多模态指令数据集。它由10.8万个多轮对话样例组成,多种模态交织在一起,因此使模型能够处理任意组合的多模态输入和输出。实验结果表明,AnyGPT能够促进任意到任意的多模态对话,同时在所有模态上达到与专用模型相当的性能,证明了离散表示可以有效且方便地在语言模型中统一多个模态。
VocBot Turbo 是一个高效的语音转文字工具,可以快速将语音内容转换为文字,支持多种语言和音频格式,提供准确的识别结果。VocBot Turbo具有高度的准确性和灵活性,适用于各种场景,包括会议记录、语音转写、语音搜索等。它还具有用户友好的界面和简单易用的操作,使您可以轻松地进行语音转文字。
WhisperFusion是一款基于WhisperLive和WhisperSpeech功能的产品,通过在实时语音转文字流程中集成Mistral大型语言模型(LLM)来实现与AI的无缝对话。Whisper和LLM均经过TensorRT引擎优化,以最大程度提升性能和实时处理能力。WhisperSpeech则使用torch.compile来优化。产品定位于提供超低延迟的AI实时对话体验。
Voxos 是一款多功能且用户友好的桌面语音助手,可将LLM集成到日常工作流程中,相比于使用Web UI访问LLM,它更加简化。它非常适合任何使用桌面计算机且希望节省时间和精力的人。此外,您还可以在Voxos的模块化设计基础上构建自己的定制功能。Voxos旨在易于扩展和定制。因此,我们鼓励您以符合当前设计模式的方式定制您的修改,并希望您通过提交MR来为Voxos的所有用户带来益处。
AI Audio Kit是一款使用OpenAI官方Whisper API在macOS上进行音频转录的工具。它使用先进的AI技术来实现精确转录,无需繁琐的上传步骤,同时支持长文本摘要功能。AI Audio Kit以9美元的价格提供,旨在节省用户的时间和精力。
MacGaiver是一款AI助手软件,可以帮助用户在任何应用程序中快速获得帮助。用户只需使用一个键盘快捷键激活MacGaiver,然后在不离开应用的情况下通过语音或文本提问,MacGaiver将会以文字和语音的形式提供相应的答案。它使用OpenAI GPT V模型和OpenAI Vision API,能够在几秒内回答用户的问题。
HoneyDo是一款语音识别AI购物清单助手,通过语音输入购物清单,AI将其转化为整洁有序的列表。另外,还支持拍照识别食材并列出清单,以及与家人实时同步共享购物清单等功能。HoneyDo分为免费版和PRO版,PRO版提供无限语音录制和图像捕捉功能。
腾讯云语音识别(ASR)为开发者提供语音转文字服务的最佳体验。语音识别服务具备识别准确率高、接入便捷、性能稳定等特点。腾讯云语音识别服务开放实时语音识别、一句话识别和录音文件识别三种服务形式,满足不同类型开发者需求。技术先进,性价比高,多语种支持,适用于客服、会议、法庭等多场景。
Hintscribe是一个创新的语音转文字桌面应用程序。它可以实时转录系统音频,并通过集成ChatGPT,支持用户与转录后的文本进行交互,从而实现诸如回答问题、翻译文本或为社交平台创作机智评论等多种任务。该应用程序的实时转录功能,可显著提高会议效率;与各种会议平台的无缝集成,实现了简单方便的转录;实时面试录音转录功能,可减少面试者的笔记负担,让面试者更专注于与应聘者的互动。该应用还可通过ChatGPT提供面试应对建议,帮助应聘者改进表现。
elsAi 是一款功能强大的 AI 助手工具,可以帮助用户提高工作效率和生产力。它具有智能翻译、语音识别、智能推荐等多项功能,支持多种语言和场景应用。elsAi 定位于为用户提供便捷的 AI 辅助工具。
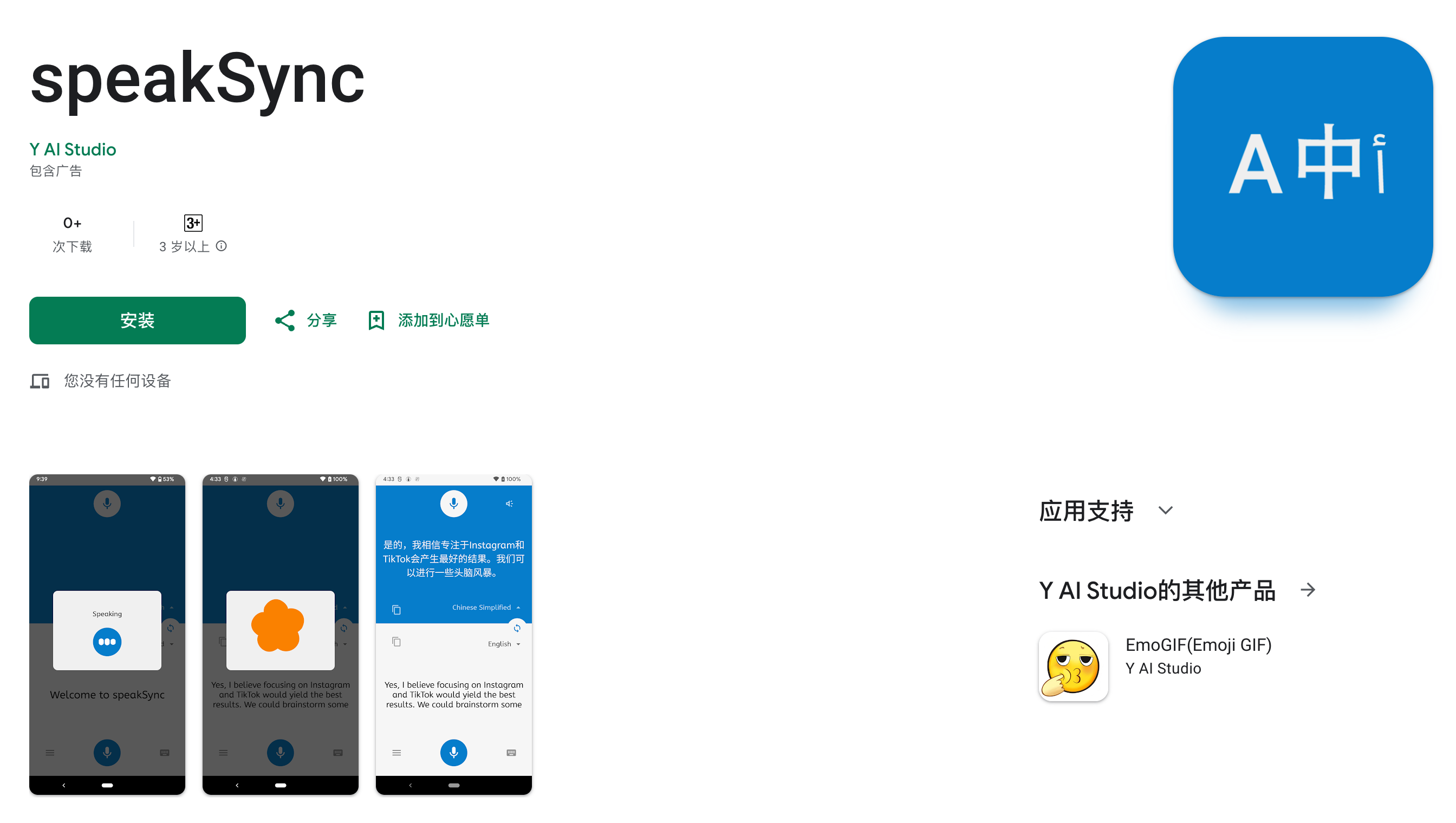
speakSync是一个基于人工智能的实时语音翻译APP。它能够实现多种语言之间的即时翻译,支持语音转文本和文本转语音,采用了OpenAI的Whisper和GPT模型,实现了流畅准确的翻译效果。该APP专为旅行者、商务人士和语言学习者设计,简化了翻译流程,创建无障碍的跨语言交流环境。