找到 64 个相关的AI工具
GPT OSS是OpenAI推出的开源语言模型,具有强大的推理能力和Apache 2.0许可。该模型具有高效性、安全性、API兼容性等特点,是未来开源语言模型的先驱。
CameraBench 是一个用于分析视频中相机运动的模型,旨在通过视频理解相机的运动模式。它的主要优点在于利用生成性视觉语言模型进行相机运动的原理分类和视频文本检索。通过与传统的结构从运动 (SfM) 和实时定位与*构建 (SLAM) 方法进行比较,该模型在捕捉场景语义方面显示出了显著的优势。该模型已开源,适合研究人员和开发者使用,且后续将推出更多改进版本。
HiDream-I1 是一款新型的开源图像生成基础模型,拥有 170 亿个参数,能够在几秒内生成高质量图像。该模型适用于研究和开发,并在多个评测中表现优异,具有高效性和灵活性,适合用于各种创意设计和生成任务。
Together Chat 是一个安全的 AI 聊天平台,提供 100 条免费消息每天,适合需要私密对话和高质量交互的用户。它以 North America 为服务器地点,确保用户信息安全。
Wan 2.1 AI 是由阿里巴巴开发的开源大规模视频生成 AI 模型。它支持文本到视频(T2V)和图像到视频(I2V)的生成,能够将简单的输入转化为高质量的视频内容。该模型在视频生成领域具有重要意义,能够极大地简化视频创作流程,降低创作门槛,提高创作效率,为用户提供丰富多样的视频创作可能性。其主要优点包括高质量的视频生成效果、复杂动作的流畅展现、逼真的物理模拟以及丰富的艺术风格等。目前该产品已完全开源,用户可以免费使用其基础功能,对于有视频创作需求但缺乏专业技能或设备的个人和企业来说,具有很高的实用价值。
CSM 1B 是一个基于 Llama 架构的语音生成模型,能够从文本和音频输入中生成 RVQ 音频代码。该模型主要应用于语音合成领域,具有高质量的语音生成能力。其优势在于能够处理多说话人的对话场景,并通过上下文信息生成自然流畅的语音。该模型开源,旨在为研究和教育目的提供支持,但明确禁止用于冒充、欺诈或非法活动。
Gemma 3 是 Google 推出的最新开源模型,基于 Gemini 2.0 的研究和技术开发。它是一个轻量级、高性能的模型,能够在单个 GPU 或 TPU 上运行,为开发者提供强大的 AI 能力。Gemma 3 提供多种尺寸(1B、4B、12B 和 27B),支持超过 140 种语言,并具备先进的文本和视觉推理能力。其主要优点包括高性能、低计算需求以及广泛的多语言支持,适合在各种设备上快速部署 AI 应用。Gemma 3 的推出旨在推动 AI 技术的普及和创新,帮助开发者在不同硬件平台上实现高效开发。
HunyuanVideo-I2V 是腾讯开源的图像到视频生成模型,基于 HunyuanVideo 架构开发。该模型通过图像潜在拼接技术,将参考图像信息有效整合到视频生成过程中,支持高分辨率视频生成,并提供可定制的 LoRA 效果训练功能。该技术在视频创作领域具有重要意义,能够帮助创作者快速生成高质量的视频内容,提升创作效率。
Wan2.1-T2V-14B 是一款先进的文本到视频生成模型,基于扩散变换器架构,结合了创新的时空变分自编码器(VAE)和大规模数据训练。它能够在多种分辨率下生成高质量的视频内容,支持中文和英文文本输入,并在性能和效率上超越现有的开源和商业模型。该模型适用于需要高效视频生成的场景,如内容创作、广告制作和视频编辑等。目前该模型在 Hugging Face 平台上免费提供,旨在推动视频生成技术的发展和应用。
PIKE-RAG 是微软开发的一种领域知识和推理增强生成模型,旨在通过知识提取、存储和推理逻辑增强大型语言模型(LLM)的能力。该模型通过多模块设计,能够处理复杂的多跳问答任务,并在工业制造、矿业和制药等领域显著提升了问答准确性。PIKE-RAG 的主要优点包括高效的知识提取能力、强大的多源信息整合能力和多步推理能力,使其在需要深度领域知识和复杂逻辑推理的场景中表现出色。
SkyReels V1 是一个基于 HunyuanVideo 微调的人类中心视频生成模型。它通过高质量影视片段训练,能够生成具有电影级质感的视频内容。该模型在开源领域达到了行业领先水平,尤其在面部表情捕捉和场景理解方面表现出色。其主要优点包括开源领先性、先进的面部动画技术和电影级光影美学。该模型适用于需要高质量视频生成的场景,如影视制作、广告创作等,具有广泛的应用前景。
SkyReels-V1 是一个开源的人类中心视频基础模型,基于高质量影视片段微调,专注于生成高质量的视频内容。该模型在开源领域达到了顶尖水平,与商业模型相媲美。其主要优势包括:高质量的面部表情捕捉、电影级的光影效果以及高效的推理框架 SkyReelsInfer,支持多 GPU 并行处理。该模型适用于需要高质量视频生成的场景,如影视制作、广告创作等。
DeepScaleR-1.5B-Preview 是一个经过强化学习优化的大型语言模型,专注于提升数学问题解决能力。该模型通过分布式强化学习算法,显著提高了在长文本推理场景下的准确率。其主要优点包括高效的训练策略、显著的性能提升以及开源的灵活性。该模型由加州大学伯克利分校的 Sky Computing Lab 和 Berkeley AI Research 团队开发,旨在推动人工智能在教育领域的应用,尤其是在数学教育和竞赛数学领域。模型采用 MIT 开源许可,完全免费供研究人员和开发者使用。
Lumina-Video 是 Alpha-VLLM 团队开发的一个视频生成模型,主要用于从文本生成高质量的视频内容。该模型基于深度学习技术,能够根据用户输入的文本提示生成对应的视频,具有高效性和灵活性。它在视频生成领域具有重要意义,为内容创作者提供了强大的工具,能够快速生成视频素材。目前该项目已开源,支持多种分辨率和帧率的视频生成,并提供了详细的安装和使用指南。
Zonos-v0.1 是 Zyphra 团队开发的实时文本转语音(TTS)模型,具备高保真语音克隆功能。该模型包含一个 1.6B 参数的 Transformer 模型和一个 1.6B 参数的混合模型(Hybrid),均在 Apache 2.0 开源许可下发布。它能够根据文本提示生成自然、富有表现力的语音,并支持多种语言。此外,Zonos-v0.1 还可以通过 5 到 30 秒的语音片段实现高质量的语音克隆,并且可以根据说话速度、音调、音质和情绪等条件进行调整。其主要优点是生成质量高、支持实时交互,并且提供了灵活的语音控制功能。该模型的发布旨在推动 TTS 技术的研究和发展。
Hibiki 是一款专注于流式语音翻译的先进模型。它通过实时积累足够的上下文信息来逐块生成正确的翻译,支持语音和文本翻译,并可进行声音转换。该模型基于多流架构,能够同时处理源语音和目标语音,生成连续的音频流和时间戳文本翻译。其主要优点包括高保真语音转换、低延迟实时翻译以及对复杂推理策略的兼容性。Hibiki 目前支持法语到英语的翻译,适合需要高效实时翻译的场景,如国际会议、多语言直播等。模型开源免费,适合开发者和研究人员使用。
Qwen2.5-1M 是一款开源的人工智能语言模型,专为处理长序列任务而设计,支持最多100万Token的上下文长度。该模型通过创新的训练方法和技术优化,显著提升了长序列处理的性能和效率。它在长上下文任务中表现出色,同时保持了短文本任务的性能,是现有长上下文模型的优秀开源替代。该模型适用于需要处理大量文本数据的场景,如文档分析、信息检索等,能够为开发者提供强大的语言处理能力。
BEN2(Background Erase Network)是一个创新的图像分割模型,采用了Confidence Guided Matting(CGM)流程。它通过一个细化网络专门处理模型置信度较低的像素,从而实现更精确的抠图效果。BEN2在头发抠图、4K图像处理、目标分割和边缘细化方面表现出色。其基础模型是开源的,用户可以通过API或Web演示免费试用完整模型。该模型训练数据包括DIS5k数据集和22K专有分割数据集,能够满足多种图像处理需求。
YuE 是由香港科技大学和多模态艺术投影团队开发的开源音乐生成模型。它能够根据给定的歌词生成长达 5 分钟的完整歌曲,包括人声和伴奏部分。该模型通过多种技术创新,如语义增强音频标记器、双标记技术和歌词链式思考等,解决了歌词到歌曲生成的复杂问题。YuE 的主要优点是能够生成高质量的音乐作品,并且支持多种语言和音乐风格,具有很强的可扩展性和可控性。该模型目前免费开源,旨在推动音乐生成技术的发展。
Llasa-1B 是一个由香港科技大学音频实验室开发的文本转语音模型。它基于 LLaMA 架构,通过结合 XCodec2 代码本中的语音标记,能够将文本转换为自然流畅的语音。该模型在 25 万小时的中英文语音数据上进行了训练,支持从纯文本生成语音,也可以利用给定的语音提示进行合成。其主要优点是能够生成高质量的多语言语音,适用于多种语音合成场景,如有声读物、语音助手等。该模型采用 CC BY-NC-ND 4.0 许可证,禁止商业用途。
Llasa-3B 是一个强大的文本到语音(TTS)模型,基于 LLaMA 架构开发,专注于中英文语音合成。该模型通过结合 XCodec2 的语音编码技术,能够将文本高效地转换为自然流畅的语音。其主要优点包括高质量的语音输出、支持多语言合成以及灵活的语音提示功能。该模型适用于需要语音合成的多种场景,如有声读物制作、语音助手开发等。其开源性质也使得开发者可以自由探索和扩展其功能。
MiniRAG是一个针对小型语言模型设计的检索增强生成系统,旨在简化RAG流程并提高效率。它通过语义感知的异构图索引机制和轻量级的拓扑增强检索方法,解决了小型模型在传统RAG框架中性能受限的问题。该模型在资源受限的场景下具有显著优势,如在移动设备或边缘计算环境中。MiniRAG的开源特性也使其易于被开发者社区接受和改进。
MatterGen是微软研究院推出的一种生成式AI工具,用于材料设计。它能够根据应用的设计要求直接生成具有特定化学、机械、电子或磁性属性的新型材料,为材料探索提供了新的范式。该工具的出现有望加速新型材料的研发进程,降低研发成本,并在电池、太阳能电池、CO2吸附剂等领域发挥重要作用。目前,MatterGen的源代码已在GitHub上开源,供公众使用和进一步开发。
Kokoro-82M是一个由hexgrad创建并托管在Hugging Face上的文本到语音(TTS)模型。它具有8200万参数,使用Apache 2.0许可证开源。该模型在2024年12月25日发布了v0.19版本,并提供了10种独特的语音包。Kokoro-82M在TTS Spaces Arena中排名第一,显示出其在参数规模和数据使用上的高效性。它支持美国英语和英国英语,可用于生成高质量的语音输出。
Llama-3-Patronus-Lynx-8B-Instruct是由Patronus AI开发的一个基于meta-llama/Meta-Llama-3-8B-Instruct模型的微调版本,主要用于检测在RAG设置中的幻觉。该模型训练于包含CovidQA、PubmedQA、DROP、RAGTruth等多个数据集,包含人工标注和合成数据。它能够评估给定文档、问题和答案是否忠实于文档内容,不提供文档之外的新信息,也不与文档信息相矛盾。
Meta Video Seal是一个先进的开源视频水印模型,能够在视频编辑后仍嵌入持久、不可见的水印。随着AI生成内容的增加,验证视频来源变得至关重要。Video Seal通过嵌入隐形水印,即使在视频被编辑后,也能保持水印的完整性,这对于版权保护和内容验证具有重要意义。
OLMo-2-1124-13B-Instruct是由Allen AI研究所开发的一款大型语言模型,专注于文本生成和对话任务。该模型在多个任务上表现出色,包括数学问题解答、科学问题解答等。它是基于13B参数的版本,经过在特定数据集上的监督微调和强化学习训练,以提高其性能和安全性。作为一个开源模型,它允许研究人员和开发者探索和改进语言模型的科学。
OLMo-2-1124-7B-Instruct是由Allen人工智能研究所开发的一个大型语言模型,专注于对话生成任务。该模型在多种任务上进行了优化,包括数学问题解答、GSM8K、IFEval等,并在Tülu 3数据集上进行了监督微调。它是基于Transformers库构建的,可以用于研究和教育目的。该模型的主要优点包括高性能、多任务适应性和开源性,使其成为自然语言处理领域的一个重要工具。
Allegro-TI2V是一个文本图像到视频生成模型,它能够根据用户提供的提示和图像生成视频内容。该模型以其开源性、多样化的内容创作能力、高质量的输出、小巧高效的模型参数以及支持多种精度和GPU内存优化而受到关注。它代表了当前人工智能技术在视频生成领域的前沿进展,具有重要的技术价值和商业应用潜力。Allegro-TI2V模型在Hugging Face平台上提供,遵循Apache 2.0开源协议,用户可以免费下载和使用。
Llama-3.1-Tulu-3-70B-DPO是Tülu3模型家族的一部分,专为现代后训练技术提供全面指南。该模型家族旨在除了聊天之外的多种任务上实现最先进的性能,如MATH、GSM8K和IFEval。它是基于公开可用的、合成的和人为创建的数据集训练的模型,主要使用英语,并遵循Llama 3.1社区许可协议。
Llama-3.1-Tulu-3-70B是Tülu3模型家族中的一员,专为现代后训练技术提供全面的指南。该模型不仅在聊天任务上表现出色,还在MATH、GSM8K和IFEval等多种任务上展现出了卓越的性能。作为一个开源模型,它允许研究人员和开发者访问和使用其数据和代码,以推动自然语言处理技术的发展。
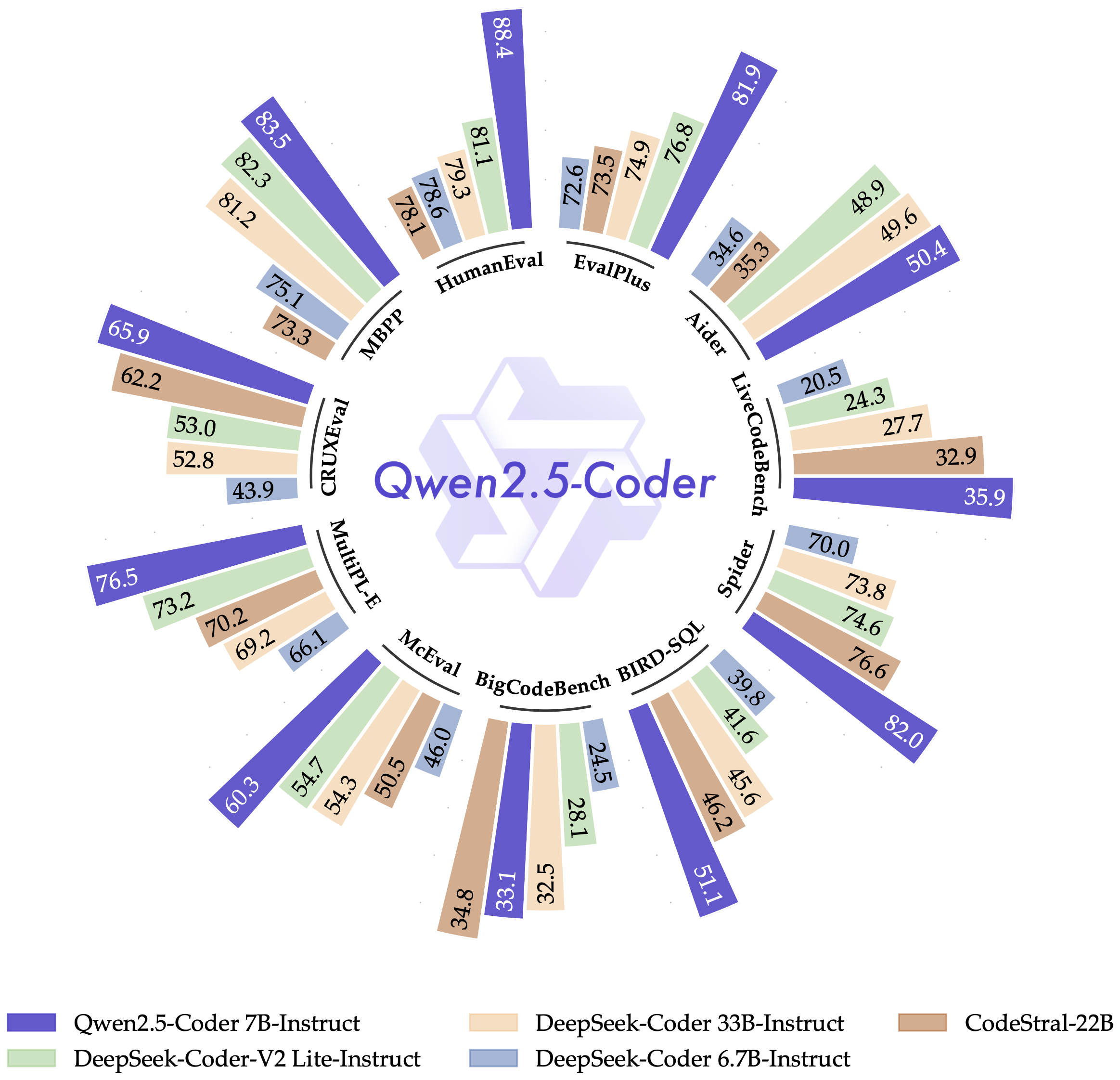
Qwen2.5-Coder是Qwen大型语言模型的最新系列,专注于代码生成、代码推理和代码修复。基于强大的Qwen2.5,该模型在训练中包含了5.5万亿的源代码、文本代码关联、合成数据等,是目前开源代码语言模型中的佼佼者,其编码能力可与GPT-4相媲美。此外,Qwen2.5-Coder还具备更全面的现实世界应用基础,如代码代理等,不仅增强了编码能力,还保持了在数学和通用能力方面的优势。
Qwen2.5-Coder是Qwen大型语言模型的最新系列,专为代码生成、推理和修复而设计。基于强大的Qwen2.5,该模型在训练时包含了5.5万亿的源代码、文本代码基础、合成数据等,使其在代码能力上达到了开源代码LLM的最新水平。它不仅增强了编码能力,还保持了在数学和通用能力方面的优势。
Qwen2.5-Coder-3B-Instruct-GPTQ-Int8是Qwen2.5-Coder系列中的一种大型语言模型,专门针对代码生成、代码推理和代码修复进行了优化。该模型基于Qwen2.5,训练数据包括源代码、文本代码关联、合成数据等,达到5.5万亿个训练令牌。Qwen2.5-Coder-32B已成为当前最先进的开源代码大型语言模型,其编码能力与GPT-4o相匹配。该模型还为现实世界中的应用提供了更全面的基础,如代码代理,不仅增强了编码能力,还保持了在数学和通用能力方面的优势。
Qwen2.5-Coder是Qwen大型语言模型的最新系列,专注于代码生成、代码推理和代码修复。基于强大的Qwen2.5,训练令牌扩展到5.5万亿,包括源代码、文本代码接地、合成数据等。Qwen2.5-Coder-32B已成为当前最先进的开源代码大型语言模型,其编码能力与GPT-4o相匹配。该模型在实际应用中提供了更全面的基础,如代码代理,不仅增强了编码能力,还保持了在数学和通用能力方面的优势。
Qwen2.5-Coder-32B-Instruct-GPTQ-Int8是Qwen系列中针对代码生成优化的大型语言模型,拥有32亿参数,支持长文本处理,是当前开源代码生成领域最先进的模型之一。该模型基于Qwen2.5进行了进一步的训练和优化,不仅在代码生成、推理和修复方面有显著提升,而且在数学和通用能力上也保持了优势。模型采用GPTQ 8-bit量化技术,以减少模型大小并提高运行效率。
Qwen2.5-Coder-1.5B是Qwen2.5-Coder系列中的一款大型语言模型,专注于代码生成、代码推理和代码修复。基于强大的Qwen2.5,该模型通过扩展训练令牌至5.5万亿,包括源代码、文本代码基础、合成数据等,成为当前开源代码LLM中的佼佼者,编码能力媲美GPT-4o。此外,Qwen2.5-Coder-1.5B还强化了数学和通用能力,为实际应用如代码代理提供了更全面的基础。
Qwen2.5-Coder是Qwen大型语言模型的最新系列,专注于代码生成、代码推理和代码修复。基于Qwen2.5的强大能力,该模型在训练时使用了5.5万亿的源代码、文本代码基础、合成数据等,是目前开源代码生成语言模型中的佼佼者,编码能力与GPT-4o相媲美。它不仅增强了编码能力,还保持了在数学和通用能力方面的优势,为实际应用如代码代理提供了更全面的基础。
Qwen2.5-Coder是Qwen大型语言模型的最新系列,专注于代码生成、代码推理和代码修复。基于强大的Qwen2.5,该系列模型通过增加训练令牌至5.5万亿,包括源代码、文本代码接地、合成数据等,显著提升了代码生成、推理和修复能力。Qwen2.5-Coder-3B是该系列中的一个模型,拥有3.09B参数,36层,16个注意力头(Q)和2个注意力头(KV),全32,768令牌上下文长度。该模型是目前开源代码LLM中的佼佼者,编码能力与GPT-4o相匹配,为开发者提供了一个强大的代码辅助工具。
CogVideoX1.5-5B-SAT是由清华大学知识工程与数据挖掘团队开发的开源视频生成模型,是CogVideoX模型的升级版。该模型支持生成10秒视频,并支持更高分辨率的视频生成。模型包含Transformer、VAE和Text Encoder等模块,能够根据文本描述生成视频内容。CogVideoX1.5-5B-SAT模型以其强大的视频生成能力和高分辨率支持,为视频内容创作者提供了一个强大的工具,尤其在教育、娱乐和商业领域有着广泛的应用前景。
Mochi是Genmo最新推出的开源视频生成模型,它在ComfyUI中经过优化,即使使用消费级GPU也能实现。Mochi以其高保真度动作和卓越的提示遵循性而著称,为ComfyUI社区带来了最先进的视频生成能力。Mochi模型在Apache 2.0许可下发布,这意味着开发者和创作者可以自由使用、修改和集成Mochi,而不受限制性许可的阻碍。Mochi能够在消费级GPU上运行,如4090,且在ComfyUI中支持多种注意力后端,使其能够适应小于24GB的VRAM。
腾讯混元3D是一个开源的3D生成模型,旨在解决现有3D生成模型在生成速度和泛化能力上的不足。该模型采用两阶段生成方法,第一阶段使用多视角扩散模型快速生成多视角图像,第二阶段通过前馈重建模型快速重建3D资产。混元3D-1.0模型能够帮助3D创作者和艺术家自动化生产3D资产,支持快速单图生3D,10秒内完成端到端生成,包括mesh和texture提取。
hertz-dev是Standard Intelligence开源的全双工、仅音频的变换器基础模型,拥有85亿参数。该模型代表了可扩展的跨模态学习技术,能够将单声道16kHz语音转换为8Hz潜在表示,具有1kbps的比特率,性能优于其他音频编码器。hertz-dev的主要优点包括低延迟、高效率和易于研究人员进行微调和构建。产品背景信息显示,Standard Intelligence致力于构建对全人类有益的通用智能,而hertz-dev是这一旅程的第一步。
Mochi 1 是 Genmo 公司推出的一款研究预览版本的开源视频生成模型,它致力于解决当前AI视频领域的基本问题。该模型以其无与伦比的运动质量、卓越的提示遵循能力和跨越恐怖谷的能力而著称,能够生成连贯、流畅的人类动作和表情。Mochi 1 的开发背景是响应对高质量视频内容生成的需求,特别是在游戏、电影和娱乐行业中。产品目前提供免费试用,具体定价信息未在页面中提供。
Allegro是由Rhymes AI开发的高级文本到视频模型,它能够将简单的文本提示转换成高质量的短视频片段。Allegro的开源特性使其成为创作者、开发者和AI视频生成领域研究人员的强大工具。Allegro的主要优点包括开源、内容创作多样化、高质量输出以及模型体积小且高效。它支持多种精度(FP32、BF16、FP16),在BF16模式下,GPU内存使用量为9.3 GB,上下文长度为79.2k,相当于88帧。Allegro的技术核心包括大规模视频数据处理、视频压缩成视觉令牌以及扩展视频扩散变换器。
Janus是一个创新的自回归框架,通过将视觉编码分离成不同的路径,同时利用单一的、统一的变换器架构进行处理,解决了以往方法的局限性。这种解耦不仅减轻了视觉编码器在理解和生成中的角色冲突,还增强了框架的灵活性。Janus的性能超越了以往的统一模型,并且达到了或超过了特定任务模型的性能。Janus的简单性、高灵活性和有效性使其成为下一代统一多模态模型的强有力候选。
LightRAG是一个基于检索增强型生成模型,旨在通过结合检索和生成的优势来提升文本生成任务的性能。该模型在保持生成速度的同时,能够提供更准确和相关的信息,这对于需要快速且准确信息检索的应用场景尤为重要。LightRAG的开发背景是基于对现有文本生成模型的改进需求,特别是在需要处理大量数据和复杂查询时。该模型目前是开源的,可以免费使用,对于研究人员和开发者来说,它提供了一个强大的工具来探索和实现基于检索的文本生成任务。
由清华大学团队开发的文本到图像生成模型,开源,在图像生成领域有广泛应用前景,有高分辨率输出等优点。
Aria是一个多模态原生混合专家模型,具有强大的多模态、语言和编码任务性能。它在视频和文档理解方面表现出色,支持长达64K的多模态输入,能够在10秒内描述一个256帧的视频。Aria模型的参数量为25.3B,能够在单个A100(80GB)GPU上使用bfloat16精度进行加载。Aria的开发背景是满足对多模态数据理解的需求,特别是在视频和文档处理方面。它是一个开源模型,旨在推动多模态人工智能的发展。
CursorCore是一系列开源模型,旨在通过编程指令对齐来协助编程,支持自动化编辑和内联聊天等功能。这些功能模仿了如Cursor这样的闭源AI辅助编程工具的核心能力。该项目通过开源社区的力量,推动了AI在编程领域的应用,使得开发者能够更加高效地编写和编辑代码。目前该项目处于早期阶段,但已经展示了其在提高编程效率和辅助代码生成方面的潜力。
Qwen2.5系列语言模型是一系列开源的decoder-only稠密模型,参数规模从0.5B到72B不等,旨在满足不同产品对模型规模的需求。这些模型在自然语言理解、代码生成、数学推理等多个领域表现出色,特别适合需要高性能语言处理能力的应用场景。Qwen2.5系列模型的发布,标志着在大型语言模型领域的一次重要进步,为开发者和研究者提供了强大的工具。
Qwen2.5-Coder是Qwen2.5开源家族的一员,专注于代码生成、推理、修复等任务。它通过扩增大规模代码训练数据,提升了代码能力,同时保持了数学和通用能力。该模型支持92种编程语言,并在代码相关任务中取得了显著提升。Qwen2.5-Coder采用Apache 2.0许可,旨在加速代码智能的应用。
Qwen2.5是一系列基于Qwen2语言模型构建的新型语言模型,包括通用语言模型Qwen2.5,以及专门针对编程的Qwen2.5-Coder和数学的Qwen2.5-Math。这些模型在大规模数据集上进行了预训练,具备强大的知识理解能力和多语言支持,适用于各种复杂的自然语言处理任务。它们的主要优点包括更高的知识密度、增强的编程和数学能力、以及对长文本和结构化数据的更好理解。Qwen2.5的发布是开源社区的一大进步,为开发者和研究人员提供了强大的工具,以推动人工智能领域的研究和发展。
g1是一个实验性的项目,旨在通过使用Llama-3.1 70b模型在Groq硬件上创建类似于OpenAI的o1模型的推理链。这个项目展示了仅通过提示技术,就可以显著提高现有开源模型在逻辑问题解决上的能力,而无需进行复杂的训练。g1通过可视化的推理步骤,帮助模型在逻辑问题上实现更准确的推理,这对于提高人工智能的逻辑推理能力具有重要意义。
AuraFlow v0.3是一个完全开源的基于流的文本到图像生成模型。与之前的版本AuraFlow-v0.2相比,该模型经过了更多的计算训练,并在美学数据集上进行了微调,支持各种宽高比,宽度和高度可达1536像素。该模型在GenEval上取得了最先进的结果,目前处于beta测试阶段,正在不断改进中,社区反馈非常重要。
LongWriter是由清华大学团队开发的长文本生成模型,它基于大规模语言模型(LLMs),能够生成超过10,000字的文本内容。该模型特别适用于需要生成长篇连贯文本的场景,如写作辅助、内容创作等。LongWriter通过精细调整和优化,提高了生成文本的质量和一致性,同时保持了模型的高效性和可扩展性。
CogVideoX-2B是一个开源的视频生成模型,由清华大学团队开发。它支持使用英语提示语言生成视频,具有36GB的推理GPU内存需求,并且可以生成6秒长、每秒8帧、分辨率为720*480的视频。该模型使用正弦位置嵌入,目前不支持量化推理和多卡推理。它基于Hugging Face的diffusers库进行部署,能够根据文本提示生成视频,具有高度的创造性和应用潜力。
CogVideoX是一个开源的视频生成模型,与商业模型同源,支持通过文本描述生成视频内容。它代表了文本到视频生成技术的最新进展,具有生成高质量视频的能力,能够广泛应用于娱乐、教育、商业宣传等领域。
DeepSeek-Coder-V2是一个开源的Mixture-of-Experts代码语言模型,性能可与GPT4-Turbo相媲美,在代码特定任务上表现突出。它通过额外的6万亿个token进一步预训练,增强了编码和数学推理能力,同时保持了在一般语言任务上的相似性能。与DeepSeek-Coder-33B相比,在代码相关任务、推理和一般能力方面都有显著进步。此外,它支持的编程语言从86种扩展到338种,上下文长度从16K扩展到128K。
DeepSeek-Coder-V2是一个开源的Mixture-of-Experts (MoE) 代码语言模型,性能与GPT4-Turbo相当,在代码特定任务上表现卓越。它在DeepSeek-Coder-V2-Base的基础上,通过6万亿token的高质量多源语料库进一步预训练,显著增强了编码和数学推理能力,同时保持了在通用语言任务上的性能。支持的编程语言从86种扩展到338种,上下文长度从16K扩展到128K。
Stable Audio Open是一个开源的文本到音频模型,专为生成短音频样本、音效和制作元素而优化。它允许用户通过简单的文本提示生成高达47秒的高质量音频数据,特别适用于创造鼓点、乐器即兴演奏、环境声音、拟音录音等音乐制作和声音设计。开源发布的关键好处是用户可以根据自己的自定义音频数据微调模型。
360Zhinao是由奇虎360开源的一系列7B规模的智能语言模型,包括基础模型和三个不同长度上下文的对话模型。这些模型经过大规模中英文语料预训练,在自然语言理解、知识、数学、代码生成等多种任务上表现出色,并具有强大的长文本对话能力。模型可用于各种对话式应用的开发和部署。
HuggingChat Assistants是HuggingFace发布的聊天机器人定制平台。用户可以选择HuggingFace托管的多个开源模型,创建自定义的聊天机器人,适用于多个领域。
PIXART LCM是一个文本到图像合成框架,将潜在一致性模型(LCM)和ControlNet集成到先进的PIXART-α模型中。PIXART LCM以其能够通过高效的训练过程生成1024px分辨率的高质量图像而闻名。在PIXART-δ中集成LCM显著加快了推理速度,使得仅需2-4步即可生成高质量图像。特别值得注意的是,PIXART-δ实现了在0.5秒内生成1024x1024像素图像的突破,比PIXART-α改进了7倍。此外,PIXART-δ经过精心设计,可在单日内在32GB V100GPU上进行高效训练。具有8位推理能力的PIXART-δ可以在8GB GPU内存约束下合成1024px图像,极大地增强了其可用性和可访问性。此外,引入类似于ControlNet的模块可以对文本到图像扩散模型进行精细控制。我们引入了一种新颖的ControlNet-Transformer架构,专门为Transformers量身定制,实现了显式可控性和高质量图像生成。作为一种最先进的开源图像生成模型,PIXART-δ为稳定扩散模型家族提供了一个有前途的选择,为文本到图像合成做出了重大贡献。