找到 66 个相关的AI工具
Horizon Alpha是一款集成了下一代人工智能的平台,为现代创作者提供快速、可靠的解决方案。其主要优点在于引领人工智能技术发展,提供卓越的推理、编码和自然语言理解能力。该产品定位于企业级AI平台,并具有卓越的性能和灵活性。
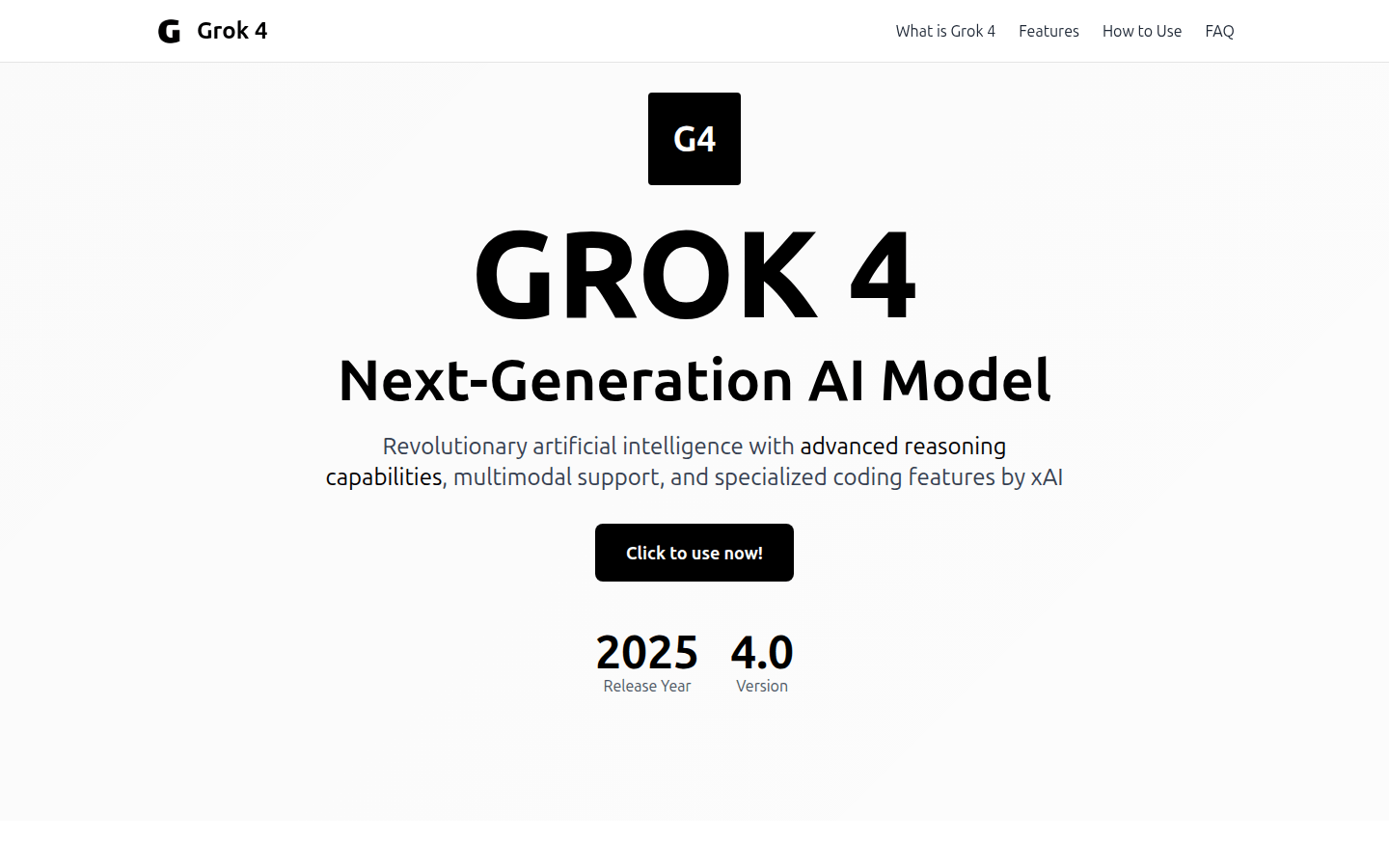
Grok 4是xAI推出的最新版本大型语言模型,于2025年7月正式发布。它具有领先的自然语言、数学和推理能力,是顶级模型AI。Grok 4代表了巨大的进步,跳过了预期的Grok 3.5版本,以在激烈的AI竞争中加快进展。
Claude 4 是 Anthropic 最新推出的 AI 模型系列,具备强大的编程和推理能力,能够高效处理复杂任务。其卓越的性能使其在编程基准测试中名列前茅,成为开发者的重要工具。Claude 4 通过多项新功能的引入,提升了信息处理的效率和准确性,适合需要高效编码和逻辑推理的用户。
DeepSeek-Prover-V2-671B 是一个先进的人工智能模型,旨在提供强大的推理能力。它基于最新的技术,适用于多种应用场景。该模型是开源的,旨在促进人工智能技术的民主化与普及,降低技术壁垒,使更多开发者和研究者能够利用 AI 技术进行创新。通过使用该模型,用户可以提升他们的工作效率,推动各类项目的进展。
该模型通过强化学习和高质量推理轨迹的掩蔽自监督微调,实现了对扩散大语言模型的推理能力的提升。此技术的重要性在于它能够优化模型的推理过程,减少计算成本,同时保证学习动态的稳定性。适合希望在写作和推理任务中提升效率的用户。
Llama-3.1-Nemotron-Ultra-253B-v1 是一个基于 Llama-3.1-405B-Instruct 的大型语言模型,经过多阶段的后训练以提升推理和聊天能力。该模型支持高达 128K 的上下文长度,具备较好的准确性和效率平衡,适用于商业用途,旨在为开发者提供强大的 AI 助手功能。
Gemini 2.5 是谷歌推出的最先进的 AI 模型,具备高效的推理能力和编码性能,能够处理复杂问题,并在多项基准测试中表现出色。该模型引入了新的思维能力,结合增强的基础模型和后期训练,支持更复杂的任务,旨在为开发者和企业提供强大的支持。Gemini 2.5 Pro 可在 Google AI Studio 和 Gemini 应用中使用,适合需要高级推理和编码能力的用户。
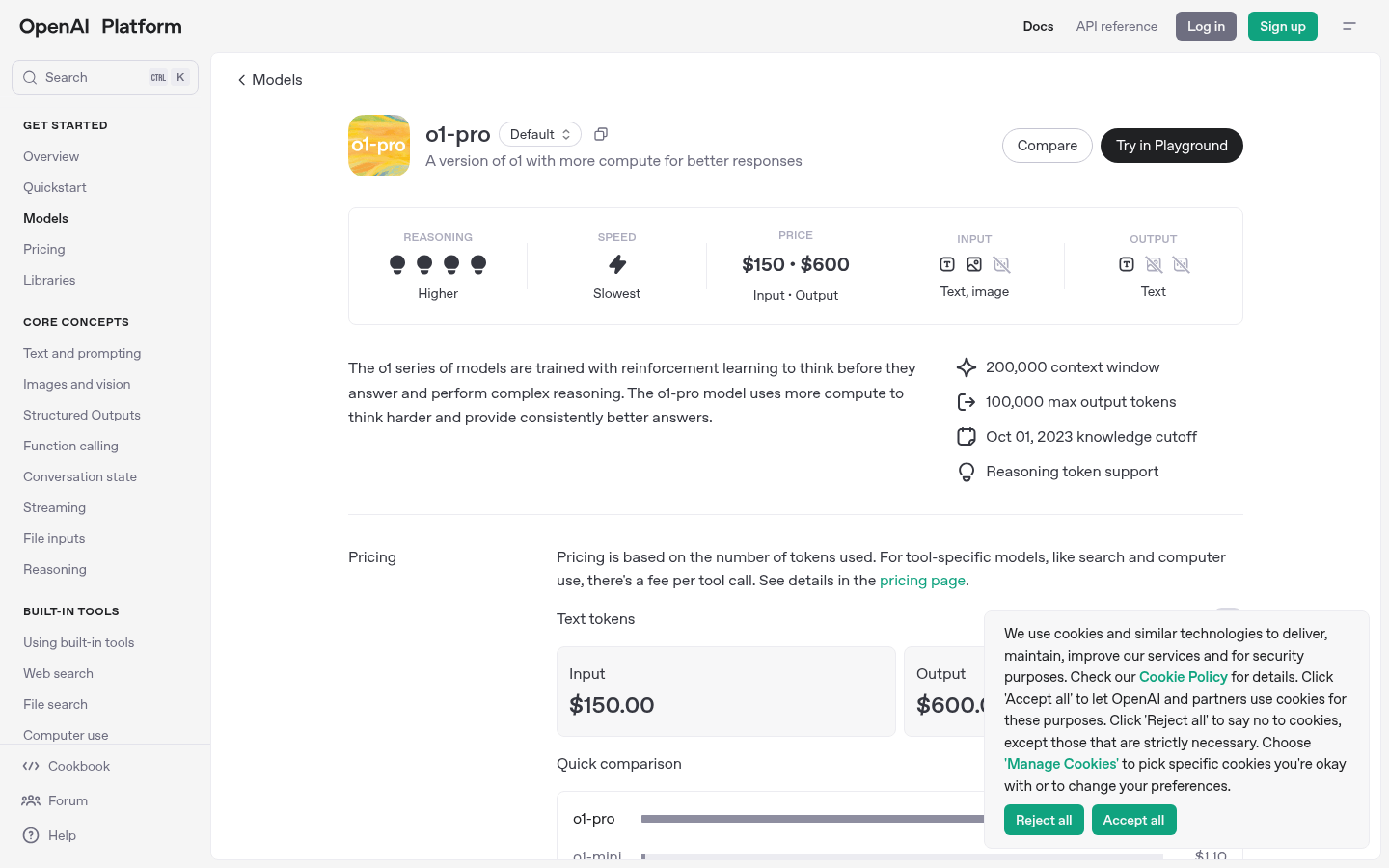
o1-pro 模型是一种先进的人工智能语言模型,专为提供高质量文本生成和复杂推理设计。其在推理和响应准确性上表现优越,适合需要高精度文本处理的应用场景。该模型的定价基于使用的 tokens,输入每百万 tokens 价格为 150 美元,输出每百万 tokens 价格为 600 美元,适合企业和开发者在其应用中集成高效的文本生成能力。
QwQ-32B 是 Qwen 系列的推理模型,专注于复杂问题的思考和推理能力。它在下游任务中表现出色,尤其是在解决难题方面。该模型基于 Qwen2.5 架构,经过预训练和强化学习优化,具有 325 亿参数,支持 131072 个完整上下文长度的处理能力。其主要优点包括强大的推理能力、高效的长文本处理能力和灵活的部署选项。该模型适用于需要深度思考和复杂推理的场景,如学术研究、编程辅助和创意写作等。
QwQ-Max-Preview 是 Qwen 系列的最新成果,基于 Qwen2.5-Max 构建。它在数学、编程以及通用任务中展现了更强的能力,同时在与 Agent 相关的工作流中也有不错的表现。作为即将发布的 QwQ-Max 的预览版,这个版本还在持续优化中。其主要优点包括深度推理、数学、编程和 Agent 任务的强大能力。未来计划以 Apache 2.0 许可协议开源发布 QwQ-Max 以及 Qwen2.5-Max,旨在推动跨领域应用的创新。
Claude 3.7 Sonnet 是 Anthropic 推出的最新混合推理模型,能够实现快速响应和深度推理的无缝切换。它在编程、前端开发等领域表现出色,并通过 API 提供对推理深度的精细控制。该模型不仅提升了代码生成和调试能力,还优化了对复杂任务的处理,适用于企业级应用。其定价与前代产品一致,输入每百万 token 收费 3 美元,输出每百万 token 收费 15 美元。
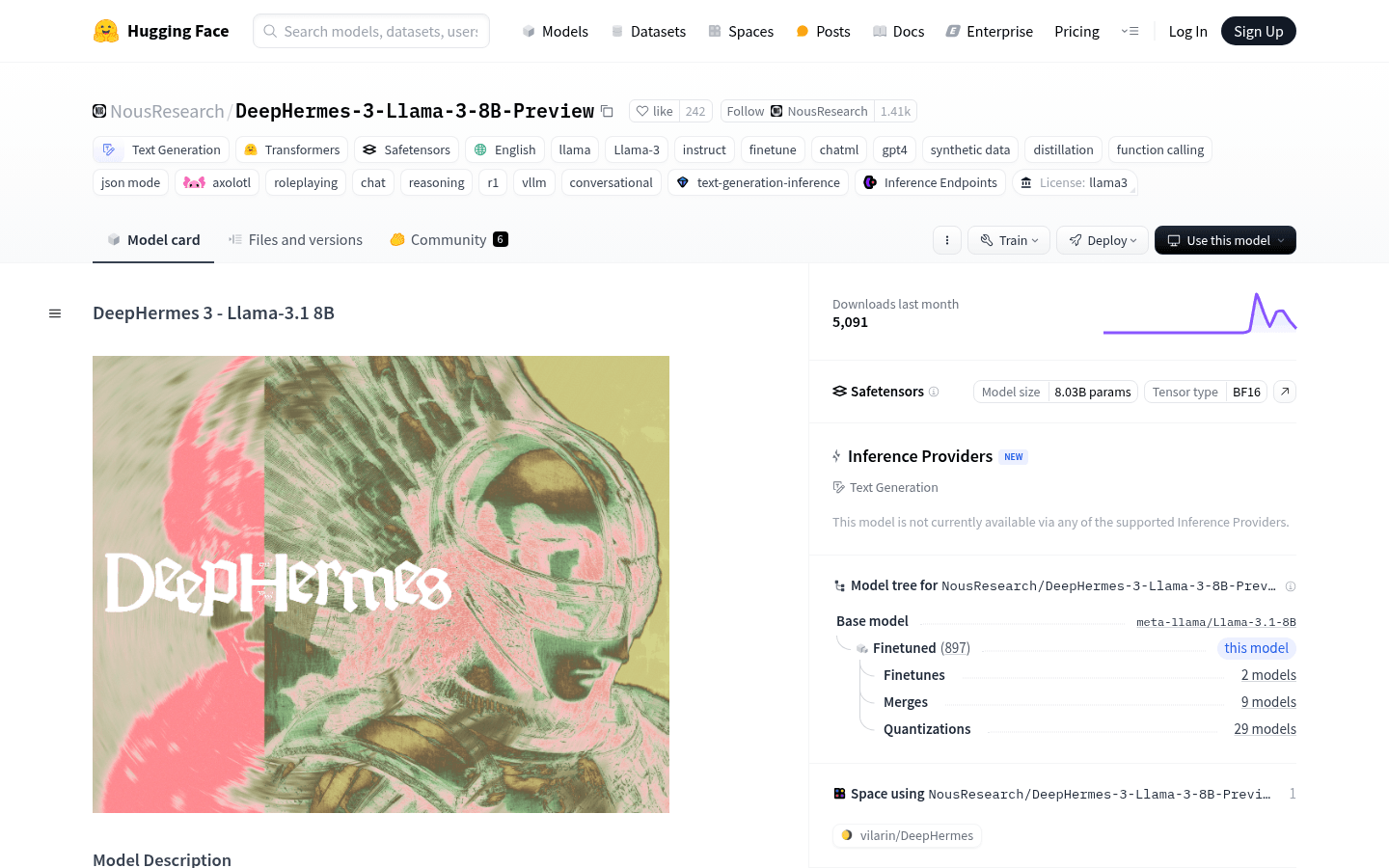
DeepHermes 3 是 NousResearch 开发的先进语言模型,能够通过系统性推理提升回答准确性。它支持推理模式和常规响应模式,用户可以通过系统提示切换。该模型在多轮对话、角色扮演、推理等方面表现出色,旨在为用户提供更强大和灵活的语言生成能力。模型基于 Llama-3.1-8B 微调,参数量达 80.3 亿,支持多种应用场景,如推理、对话、函数调用等。
DeepSeek R1与V3 API是Kie.ai提供的强大AI模型接口。DeepSeek R1是专为数学、编程和逻辑推理等高级推理任务设计的最新推理模型,经过大规模强化学习训练,能够提供精准结果。DeepSeek V3则适用于处理常规AI任务。这些API部署在美国安全服务器上,保障数据安全与隐私。Kie.ai还提供详细的API文档和多种定价方案,满足不同需求,助力开发者快速集成AI能力,提升项目性能。
Grok 3是由Elon Musk的AI公司xAI开发的最新旗舰AI模型。它在计算能力和数据集规模上显著提升,能够处理复杂的数学、科学问题,并支持多模态输入。其主要优点是推理能力强大,能够提供更准确的答案,并且在某些基准测试中超越了现有的顶尖模型。Grok 3的推出标志着xAI在AI领域的进一步发展,旨在为用户提供更智能、更高效的AI服务。该模型目前主要通过Grok APP和X平台提供服务,未来还将推出语音模式和企业API接口。其定位是高端AI解决方案,主要面向需要深度推理和多模态交互的用户。
Huginn-0125是一个由马里兰大学帕克分校Tom Goldstein实验室开发的潜变量循环深度模型。该模型拥有35亿参数,经过8000亿个token的训练,在推理和代码生成方面表现出色。其核心特点是通过循环深度结构在测试时动态调整计算量,能够根据任务需求灵活增加或减少计算步骤,从而在保持性能的同时优化资源利用。该模型基于开源的Hugging Face平台发布,支持社区共享和协作,用户可以自由下载、使用和进一步开发。其开源性和灵活的架构使其成为研究和开发中的重要工具,尤其是在资源受限或需要高性能推理的场景中。
MedRAX是一个创新的AI框架,专门用于胸部X光(CXR)的智能分析。它通过整合最先进的CXR分析工具和多模态大型语言模型,能够动态处理复杂的医疗查询。MedRAX无需额外训练即可运行,支持实时CXR解读,适用于多种临床场景。其主要优点包括高度的灵活性、强大的推理能力以及透明的工作流程。该产品面向医疗专业人员,旨在提高诊断效率和准确性,推动医疗AI的实用化。
DeepClaude是一个强大的AI工具,旨在将DeepSeek R1的推理能力与Claude的创造力和代码生成能力相结合,通过统一的API和聊天界面提供服务。它利用高性能的流式API(用Rust编写)实现即时响应,同时支持端到端加密和本地API密钥管理,确保用户数据的隐私和安全。该产品是完全开源的,用户可以自由贡献、修改和部署。其主要优点包括零延迟响应、高度可配置性以及支持用户自带密钥(BYOK),为开发者提供了极大的灵活性和控制权。DeepClaude主要面向需要高效代码生成和AI推理能力的开发者和企业,目前处于免费试用阶段,未来可能会根据使用量收费。
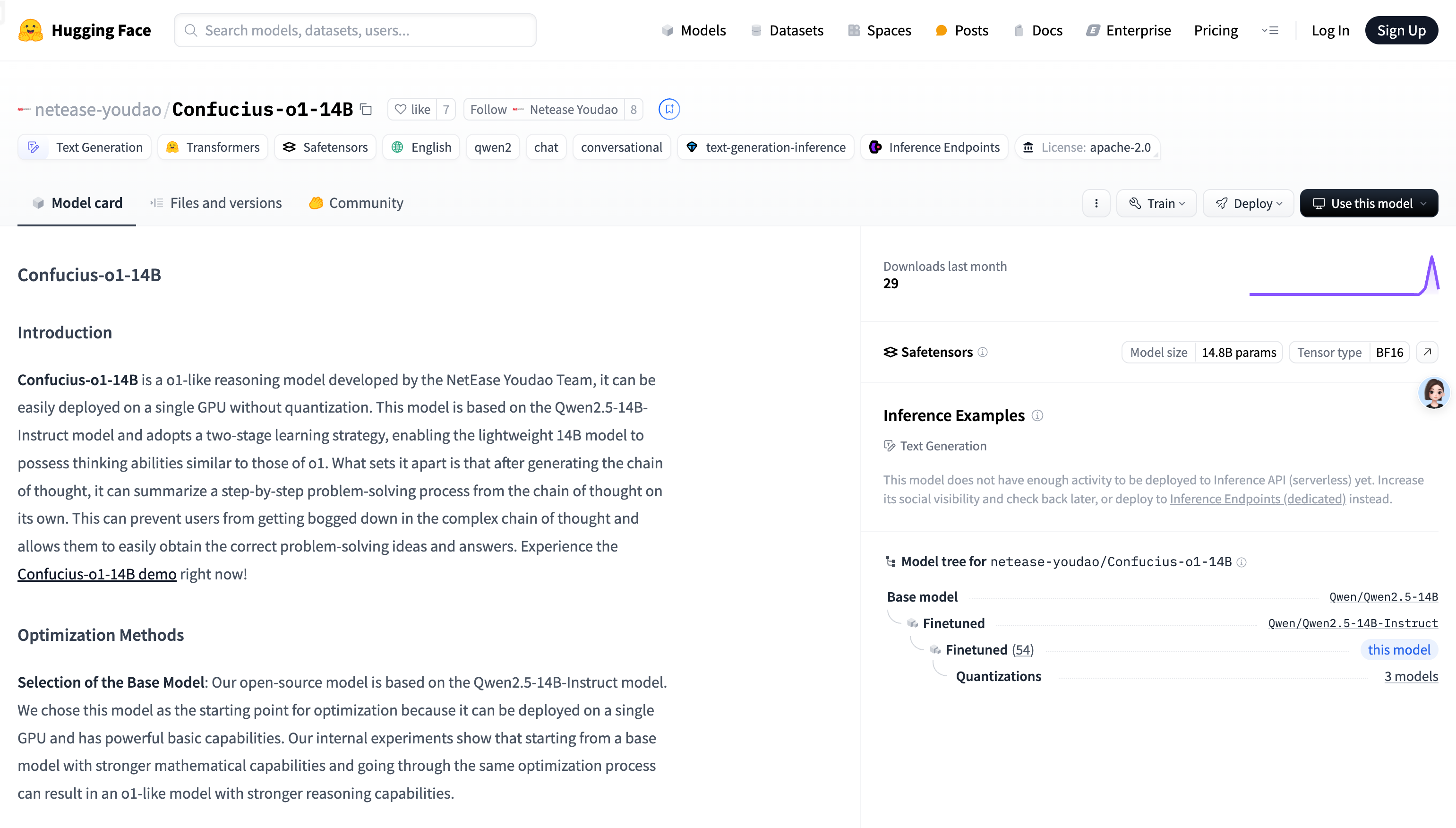
Confucius-o1-14B是由网易有道团队开发的推理模型,基于Qwen2.5-14B-Instruct优化而成。它采用两阶段学习策略,能够自动生成推理链,并总结出逐步的问题解决过程。该模型主要面向教育领域,尤其适合K12数学问题的解答,能够帮助用户快速获取正确解题思路和答案。模型具备轻量化的特点,无需量化即可在单个GPU上部署,降低了使用门槛。其推理能力在内部评估中表现出色,为教育领域的AI应用提供了强大的技术支持。
UI-TARS 是由字节跳动开发的一种新型 GUI 代理模型,专注于通过类似人类的感知、推理和行动能力与图形用户界面进行无缝交互。该模型将感知、推理、定位和记忆等关键组件集成到单一的视觉语言模型中,能够实现无需预定义工作流程或手动规则的端到端任务自动化。其主要优点包括强大的跨平台交互能力、多步任务执行能力以及从合成和真实数据中学习的能力,适用于多种自动化场景,如桌面、移动和网页环境。
Gemini Flash Thinking 是 Google DeepMind 推出的最新 AI 模型,专为复杂任务设计。它能够展示推理过程,帮助用户更好地理解模型的决策逻辑。该模型在数学和科学领域表现出色,支持长文本分析和代码执行功能。它旨在为开发者提供强大的工具,以推动人工智能在复杂任务中的应用。
DeepSeek-R1-Distill-Llama-8B 是 DeepSeek 团队开发的高性能语言模型,基于 Llama 架构并经过强化学习和蒸馏优化。该模型在推理、代码生成和多语言任务中表现出色,是开源社区中首个通过纯强化学习提升推理能力的模型。它支持商业使用,允许修改和衍生作品,适合学术研究和企业应用。
DeepSeek-R1-Distill-Qwen-14B 是 DeepSeek 团队开发的一款基于 Qwen-14B 的蒸馏模型,专注于推理和文本生成任务。该模型通过大规模强化学习和数据蒸馏技术,显著提升了推理能力和生成质量,同时降低了计算资源需求。其主要优点包括高性能、低资源消耗和广泛的适用性,适用于需要高效推理和文本生成的场景。
DeepSeek-R1-Distill-Llama-70B 是由 DeepSeek 团队开发的一款大型语言模型,基于 Llama-70B 架构并通过强化学习进行优化。该模型在推理、对话和多语言任务中表现出色,支持多种应用场景,包括代码生成、数学推理和自然语言处理。其主要优点是高效的推理能力和对复杂问题的解决能力,同时支持开源和商业使用。该模型适用于需要高性能语言生成和推理能力的企业和研究机构。
Kimi k1.5 是由 MoonshotAI 开发的多模态语言模型,通过强化学习和长上下文扩展技术,显著提升了模型在复杂推理任务中的表现。该模型在多个基准测试中达到了行业领先水平,例如在 AIME 和 MATH-500 等数学推理任务中超越了 GPT-4o 和 Claude Sonnet 3.5。其主要优点包括高效的训练框架、强大的多模态推理能力以及对长上下文的支持。Kimi k1.5 主要面向需要复杂推理和逻辑分析的应用场景,如编程辅助、数学解题和代码生成等。
InternVL2.5-MPO是一个基于InternVL2.5和混合偏好优化(MPO)的多模态大型语言模型系列。它在多模态任务中表现出色,通过整合新近增量预训练的InternViT与多种预训练的大型语言模型(LLMs),如InternLM 2.5和Qwen 2.5,使用随机初始化的MLP投影器。该模型系列在多模态推理偏好数据集MMPR上进行了训练,包含约300万个样本,通过有效的数据构建流程和混合偏好优化技术,提升了模型的推理能力和回答质量。
InternLM3-8B-Instruct是InternLM团队开发的大型语言模型,具有卓越的推理能力和知识密集型任务处理能力。该模型在仅使用4万亿高质量词元进行训练的情况下,实现了比同级别模型低75%以上的训练成本,同时在多个基准测试中超越了Llama3.1-8B和Qwen2.5-7B等模型。它支持深度思考模式,能够通过长思维链解决复杂的推理任务,同时也具备流畅的用户交互能力。该模型基于Apache-2.0许可证开源,适用于需要高效推理和知识处理的各种应用场景。
Eurus-2-7B-SFT是基于Qwen2.5-Math-7B模型进行微调的大型语言模型,专注于数学推理和问题解决能力的提升。该模型通过模仿学习(监督微调)的方式,学习推理模式,能够有效解决复杂的数学问题和编程任务。其主要优点在于强大的推理能力和对数学问题的准确处理,适用于需要复杂逻辑推理的场景。该模型由PRIME-RL团队开发,旨在通过隐式奖励的方式提升模型的推理能力。
HuatuoGPT-o1-70B是由FreedomIntelligence开发的医疗领域大型语言模型(LLM),专为复杂的医疗推理设计。该模型在提供最终响应之前,会生成一个复杂的思考过程,反映并完善其推理。HuatuoGPT-o1-70B能够处理复杂的医疗问题,提供深思熟虑的答案,这对于提高医疗决策的质量和效率至关重要。该模型基于LLaMA-3.1-70B架构,支持英文,并且可以部署在多种工具上,如vllm或Sglang,或者直接进行推理。
HuatuoGPT-o1-7B是由FreedomIntelligence开发的医疗领域大型语言模型(LLM),专为高级医疗推理设计。该模型在提供最终回答之前,会生成复杂的思考过程,反映并完善其推理。HuatuoGPT-o1-7B支持中英文,能够处理复杂的医疗问题,并以'思考-回答'的格式输出结果,这对于提高医疗决策的透明度和可靠性至关重要。该模型基于Qwen2.5-7B,经过特殊训练以适应医疗领域的需求。
HuatuoGPT-o1-8B 是一个专为高级医疗推理设计的医疗领域大型语言模型(LLM)。它在提供最终响应之前会生成一个复杂的思考过程,反映并完善其推理过程。该模型基于LLaMA-3.1-8B构建,支持英文,并且采用'thinks-before-it-answers'的方法,输出格式包括推理过程和最终响应。此模型在医疗领域具有重要意义,因为它能够处理复杂的医疗问题并提供深思熟虑的答案,这对于提高医疗决策的质量和效率至关重要。
InternVL2-8B-MPO是一个多模态大语言模型(MLLM),通过引入混合偏好优化(MPO)过程,增强了模型的多模态推理能力。该模型在数据方面设计了自动化的偏好数据构建管线,并构建了MMPR这一大规模多模态推理偏好数据集。在模型方面,InternVL2-8B-MPO基于InternVL2-8B初始化,并使用MMPR数据集进行微调,展现出更强的多模态推理能力,且幻觉现象更少。该模型在MathVista上取得了67.0%的准确率,超越InternVL2-8B 8.7个点,且表现接近于大10倍的InternVL2-76B。
Gemini 2.0 Flash Thinking Mode是谷歌推出的一个实验性AI模型,旨在生成模型在响应过程中的“思考过程”。相较于基础的Gemini 2.0 Flash模型,Thinking Mode在响应中展现出更强的推理能力。该模型在Google AI Studio和Gemini API中均可使用,是谷歌在人工智能领域的重要技术成果,对于开发者和研究人员来说,提供了一个强大的工具来探索和实现复杂的AI应用。
Gemini 2.0是Google DeepMind推出的最新AI模型,旨在为“智能助理时代”提供支持。该模型在多模态能力上进行了升级,包括原生图像和音频输出以及工具使用能力,使得构建新的AI智能助理更加接近通用助理的愿景。Gemini 2.0的发布,标志着Google在AI领域的深入探索和持续创新,通过提供更强大的信息处理和输出能力,使得信息更加有用,为用户带来更高效和便捷的体验。
MAmmoTH-VL是一个大规模多模态推理平台,它通过指令调优技术,显著提升了多模态大型语言模型(MLLMs)在多模态任务中的表现。该平台使用开放模型创建了一个包含1200万指令-响应对的数据集,覆盖了多样化的、推理密集型的任务,并提供了详细且忠实的理由。MAmmoTH-VL在MathVerse、MMMU-Pro和MuirBench等基准测试中取得了最先进的性能,展现了其在教育和研究领域的重要性。
Deepthought-8B是一个小型但功能强大的推理模型,它基于LLaMA-3.1 8B构建,旨在使AI推理更加透明和可控。尽管模型相对较小,但它实现了与更大模型相媲美的复杂推理能力。该模型以其独特的问题解决方法而设计,将其思考过程分解为清晰、独特、有记录的步骤,并将推理过程以结构化的JSON格式输出,便于理解和验证其决策过程。
Skywork-o1-Open-Llama-3.1-8B是由昆仑科技Skywork团队开发的一系列模型,这些模型结合了o1风格的慢思考和推理能力。该系列模型不仅在输出中展现出天生的思考、规划和反思能力,而且在标准基准测试中的推理技能有显著提升。这一系列代表了AI能力的战略进步,将原本较弱的基础模型推向了推理任务的最新技术(SOTA)。
QwQ-32B-Preview是一个由Qwen团队开发的实验性研究模型,旨在提高人工智能的推理能力。该模型展示了有前景的分析能力,但也存在一些重要的限制。模型在数学和编程方面表现出色,但在常识推理和细微语言理解方面还有提升空间。该模型使用了transformers架构,具有32.5B个参数,64层,以及40个注意力头(GQA)。产品背景信息显示,QwQ-32B-Preview是基于Qwen2.5-32B模型的进一步开发,具有更深层次的语言理解和生成能力。
DeepSeek-R1-Lite-Preview是一款专注于提升推理能力的AI模型,它在AIME和MATH基准测试中展现了出色的性能。该模型具备实时透明的思考过程,并且计划推出开源模型和API。DeepSeek-R1-Lite-Preview的推理能力随着思考长度的增加而稳步提升,显示出更好的性能。产品背景信息显示,DeepSeek-R1-Lite-Preview是DeepSeek公司推出的最新产品,旨在通过人工智能技术提升用户的工作效率和问题解决能力。目前,产品提供免费试用,具体的定价和定位信息尚未公布。
Mistral-Large-Instruct-2411是由Mistral AI提供的一款具有123B参数的大型语言模型,它在推理、知识、编码等方面具有最先进的能力。该模型支持多种语言,并在80多种编程语言上进行了训练,包括但不限于Python、Java、C、C++等。它以代理为中心,具备原生函数调用和JSON输出能力,是进行科研和开发的理想选择。
Hermes 3是Nous Research公司推出的Hermes系列最新版大型语言模型(LLM),相较于Hermes 2,它在代理能力、角色扮演、推理、多轮对话、长文本连贯性等方面都有显著提升。Hermes系列模型的核心理念是将LLM与用户对齐,赋予终端用户强大的引导能力和控制权。Hermes 3在Hermes 2的基础上,进一步增强了功能调用和结构化输出能力,提升了通用助手能力和代码生成技能。
Llama-3.1-Nemotron-70B-Instruct是NVIDIA定制的大型语言模型,专注于提升大型语言模型(LLM)生成回答的帮助性。该模型在多个自动对齐基准测试中表现优异,例如Arena Hard、AlpacaEval 2 LC和GPT-4-Turbo MT-Bench。它通过使用RLHF(特别是REINFORCE算法)、Llama-3.1-Nemotron-70B-Reward和HelpSteer2-Preference提示在Llama-3.1-70B-Instruct模型上进行训练。此模型不仅展示了NVIDIA在提升通用领域指令遵循帮助性方面的技术,还提供了与HuggingFace Transformers代码库兼容的模型转换格式,并可通过NVIDIA的build平台进行免费托管推理。
Open O1是一个开源项目,旨在通过开源创新,匹配专有的强大O1模型能力。该项目通过策划一组O1风格的思考数据,用于训练LLaMA和Qwen模型,赋予了这些较小模型更强大的长期推理和解决问题的能力。随着Open O1项目的推进,我们将继续推动大型语言模型的可能性,我们的愿景是创建一个不仅能够实现类似O1的性能,而且在测试时扩展性方面也处于领先地位的模型,使高级AI能力为所有人所用。通过社区驱动的开发和对道德实践的承诺,Open O1将成为AI进步的基石,确保技术的未来发展是开放的,并对所有人有益。
Show-Me是一个开源应用程序,旨在提供传统大型语言模型(如ChatGPT)交互的可视化和透明替代方案。它通过将复杂问题分解成一系列推理子任务,使用户能够理解语言模型的逐步思考过程。该应用程序使用LangChain与语言模型交互,并通过动态图形界面可视化推理过程。
Phi-3.5-MoE-instruct是由微软开发的轻量级、多语言的AI模型,基于高质量、推理密集型数据构建,支持128K的上下文长度。该模型经过严格的增强过程,包括监督式微调、近端策略优化和直接偏好优化,以确保精确的指令遵循和强大的安全措施。它旨在加速语言和多模态模型的研究,作为生成性AI功能的构建模块。
Phi-3.5-mini-instruct 是微软基于高质量数据构建的轻量级、多语言的先进文本生成模型。它专注于提供高质量的推理密集型数据,支持128K的token上下文长度,经过严格的增强过程,包括监督式微调、近端策略优化和直接偏好优化,确保精确的指令遵循和强大的安全措施。
Grok-2是xAI的前沿语言模型,具有最先进的推理能力。此次发布包括Grok家族的两个成员:Grok-2和Grok-2 mini。这两个模型现在都在𝕏平台上发布给Grok用户。Grok-2是Grok-1.5的重要进步,具有聊天、编程和推理方面的前沿能力。同时,xAI引入了Grok-2 mini,一个小巧但功能强大的Grok-2的兄弟模型。Grok-2的早期版本已经在LMSYS排行榜上以“sus-column-r”的名字进行了测试。它在整体Elo得分方面超过了Claude 3.5 Sonnet和GPT-4-Turbo。
Tost AI是一个免费、非盈利、开源的服务,它为最新的AI论文提供推理服务,使用非盈利GPU集群。Tost AI不存储任何推理数据,所有数据在12小时内过期。此外,Tost AI提供将数据发送到Discord频道的选项。每个账户每天提供100个免费钱包余额,如果希望每天获得1100个钱包余额,可以订阅GitHub赞助者或Patreon。Tost AI将演示的所有利润都发送给论文的第一作者,其预算由公司和个人赞助者支持。
Mistral-Large-Instruct-2407是一个拥有123B参数的先进大型语言模型(LLM),具备最新的推理、知识和编程能力。它支持多语言,包括中文、英语、法语等十种语言,并且在80多种编程语言上受过训练,如Python、Java等。此外,它还具备代理中心能力和先进的数学及推理能力。
Mathstral 7B 是一个专注于数学和科学任务的模型,基于 Mistral 7B。该模型在数学和科学领域的文本生成和推理方面表现出色,适用于需要高度精确和复杂计算的应用场景。模型的开发团队包括多位专家,确保了其在行业内的领先地位和可靠性。
vLLM是一个为大型语言模型(LLM)推理和提供服务的快速、易用且高效的库。它通过使用最新的服务吞吐量技术、高效的内存管理、连续批处理请求、CUDA/HIP图快速模型执行、量化技术、优化的CUDA内核等,提供了高性能的推理服务。vLLM支持与流行的HuggingFace模型无缝集成,支持多种解码算法,包括并行采样、束搜索等,支持张量并行性,适用于分布式推理,支持流式输出,并兼容OpenAI API服务器。此外,vLLM还支持NVIDIA和AMD GPU,以及实验性的前缀缓存和多lora支持。
“汤很热” 是一个以 AI 驱动的海龟汤游戏平台,旨在为用户提供一个充满悬疑和推理乐趣的游戏体验。用户可以通过提出问题来推理故事的背后真相,挑战自己的逻辑思维和想象力。部分故事包含恐怖和血腥元素,增加了游戏的刺激感。
Higgs-Llama-3-70B是一个基于Meta-Llama-3-70B的后训练模型,特别针对角色扮演进行了优化,同时在通用领域指令执行和推理方面保持竞争力。该模型通过监督式微调,结合人工标注者和私有大型语言模型构建偏好对,进行迭代偏好优化以对齐模型行为,使其更贴近系统消息。与其它指令型模型相比,Higgs模型更紧密地遵循其角色。
Phi-3 Vision是一个轻量级、最先进的开放多模态模型,基于包括合成数据和经过筛选的公开可用网站在内的数据集构建,专注于文本和视觉的非常高质量的推理密集数据。该模型属于Phi-3模型家族,多模态版本支持128K上下文长度(以token计),经过严格的增强过程,结合了监督微调和直接偏好优化,以确保精确的指令遵循和强大的安全措施。
Fireworks 与世界领先的生成式 AI 研究人员合作,以最快的速度提供最佳模型。拥有经 Fireworks 精心筛选和优化的模型,以及企业级吞吐量和专业的技术支持。定位为最快速且最可靠的 AI 平台。
Grok-1.5是一种先进的大型语言模型,具有出色的长文本理解和推理能力。它可以处理高达128,000个标记的长上下文,远超以前模型的能力。在数学和编码等任务中,Grok-1.5表现出色,在多个公认的基准测试中获得了极高的分数。该模型建立在强大的分布式训练框架之上,确保高效和可靠的训练过程。Grok-1.5旨在为用户提供强大的语言理解和生成能力,助力各种复杂的语言任务。
OpenDiT是一个开源项目,提供了一个基于Colossal-AI的Diffusion Transformer(DiT)的高性能实现,专为增强DiT应用(包括文本到视频生成和文本到图像生成)的训练和推理效率而设计。OpenDiT通过以下技术提升性能:在GPU上高达80%的加速和50%的内存减少;包括FlashAttention、Fused AdaLN和Fused layernorm核心优化;包括ZeRO、Gemini和DDP的混合并行方法,还有对ema模型进行分片进一步降低内存成本;FastSeq:一种新颖的序列并行方法,特别适用于DiT等工作负载,其中激活大小较大但参数大小较小;单节点序列并行可以节省高达48%的通信成本;突破单个GPU的内存限制,减少整体训练和推理时间;通过少量代码修改获得巨大性能改进;用户无需了解分布式训练的实现细节;完整的文本到图像和文本到视频生成流程;研究人员和工程师可以轻松使用和调整我们的流程到实际应用中,无需修改并行部分;在ImageNet上进行文本到图像训练并发布检查点。
ReadAgent是一个简单的提示系统,它利用大型语言模型(LLM)的先进语言能力来决定将哪些内容存储在记忆集中,将这些记忆集压缩成称为要点记忆的短篇回忆,并在ReadAgent需要提醒自己相关细节以完成任务时,采取行动查阅原始文本。ReadAgent可以通过使用要点记忆来捕获全局上下文,并关注局部细节,从而有效地推理非常长的上下文,在需要一次处理的信息量方面具有高效性,这对理解也很重要。
ReFT是一种增强大型语言模型(LLMs)推理能力的简单而有效的方法。它首先通过监督微调(SFT)对模型进行预热,然后使用在线强化学习,具体来说是本文中的PPO算法,进一步微调模型。ReFT通过自动对给定问题进行大量推理路径的采样,并从真实答案中自然地得出奖励,从而显著优于SFT。ReFT的性能可能通过结合推理时策略(如多数投票和重新排名)进一步提升。需要注意的是,ReFT通过学习与SFT相同的训练问题而获得改进,而无需依赖额外或增强的训练问题。这表明ReFT具有更强的泛化能力。
AlphaGeometry是一个超越了现有技术水平的几何问题AI系统,它通过结合神经语言模型的预测能力和规则驱动的推理引擎,能够解决复杂的几何问题。该系统采用神经符号学方法,由神经语言模型和符号推理引擎组成,共同寻找复杂几何定理的证明。通过生成10亿个随机几何对象图形,并从中推导出所有的关系,最终得到了1亿个独特的训练样本,其中900万个包含了额外的构造。AlphaGeometry的语言模型能够在面对国际数学奥林匹克竞赛的几何问题时做出良好的建议。该系统已经成为世界上第一个能够达到国际数学奥林匹克竞赛铜牌水平的AI模型。
这是一种在 Intel GPU 上实现的高效的 LLM 推理解决方案。通过简化 LLM 解码器层、使用分段 KV 缓存策略和自定义的 Scaled-Dot-Product-Attention 内核,该解决方案在 Intel GPU 上相比标准的 HuggingFace 实现可实现高达 7 倍的令牌延迟降低和 27 倍的吞吐量提升。详细功能、优势、定价和定位等信息请参考官方网站。
Phi-2是一个2.7亿参数的语言模型,通过优质的数据和创新技术,实现了超越模型规模的表现,在复杂的语言理解和推理测试中,匹敌或超过大25倍规模的模型。
Google Gemini 是一款基于多模态的 AI 模型,能够无缝进行图像、视频、音频和代码的推理。Gemini 是 DeepMind 推出的最先进的 AI 模型,能够在 MMLU(大规模多任务语言理解)等各项测试中超越人类专家。Gemini 具有出色的推理能力,在各种多模态任务中取得了最先进的性能。
Orca 2 是一个用于研究目的的助手,通过提供单轮响应来帮助推理和理解任务,如数据推理、阅读理解、数学问题解决和文本摘要。该模型特别擅长推理。我们公开发布 Orca 2,以促进在开发、评估和对齐更小的语言模型方面的进一步研究。
Flash-Decoding是一种针对长上下文推理的技术,可以显著加速推理中的注意力机制,从而使生成速度提高8倍。该技术通过并行加载键和值,然后分别重新缩放和组合结果来维护正确的注意力输出,从而实现了更快的推理速度。Flash-Decoding适用于大型语言模型,可以处理长文档、长对话或整个代码库等长上下文。Flash-Decoding已经在FlashAttention包和xFormers中提供,可以自动选择Flash-Decoding或FlashAttention方法,也可以使用高效的Triton内核。
MathCoder是一款基于开源语言模型的数学推理工具,通过fine-tune模型和生成高质量的数据集,实现了自然语言、代码和执行结果的交替,提高了数学推理能力。MathCoder模型在MATH和GSM8K数据集上取得了最新的最高分数,远远超过其他开源替代品。MathCoder模型不仅在GSM8K和MATH上超过了ChatGPT-3.5和PaLM-2,还在竞赛级别的MATH数据集上超过了GPT-4。
Stability AI 生成模型是一个开源的生成模型库,提供了各种生成模型的训练、推理和应用功能。该库支持各种生成模型的训练,包括基于 PyTorch Lightning 的训练,提供了丰富的配置选项和模块化的设计。用户可以使用该库进行生成模型的训练,并通过提供的模型进行推理和应用。该库还提供了示例训练配置和数据处理的功能,方便用户进行快速上手和定制。