找到 70 个相关的AI工具
OdysseyGPT采用先进的人工智能技术,能够深入理解和利用文档中的信息。它可以快速提取关键信息、生成摘要、提供数据分析等功能,极大提高工作效率。
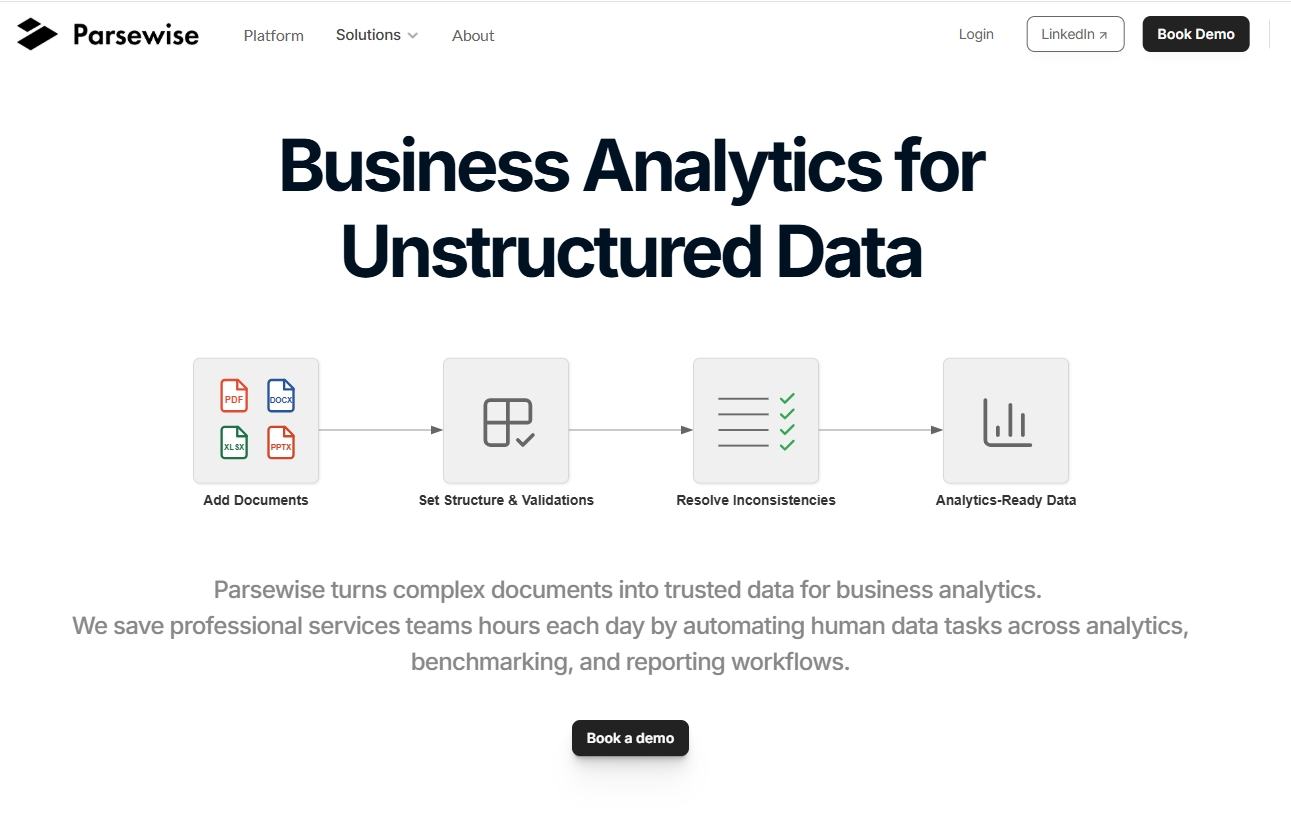
Parsewise 是一款专注于提取和结构化复杂文档数据的平台,帮助专业服务团队节省时间,提升决策效率。通过自动化数据处理,Parsewise 允许用户快速分析和报告信息,使业务决策更加可靠和高效。它的优势在于适应性强、可追溯性高、人工控制 granular 和完整性,确保输出的每一条数据都来源于准确的文档。定价模式上,Parsewise 提供免费试用,方便用户体验其强大的功能。
BrowserAct是一款AI网页爬虫工具,能够即时从任何网站提取数据,无需编码,具有强大的数据提取能力。其主要优点在于自动隐藏广告和非必要元素,支持实时和持久数据访问,同时具有全球住宅IP网络等功能。
Dropflow是一款能够从转发的电子邮件中提取数据并将其发送到Slack、Trello、Google Sheets、Notion或您自己的API的工具。它可以帮助用户自动化邮箱处理过程,提高工作效率。
PulpMiner是一个可以将任何网页数据转换为结构化实时JSON API的工具,它消除了数据提取和API构建的繁琐工作,提供AI驱动的实时API,价格灵活,即时设置。
Firecrawl MCP Server 是一款集成了强大网页抓取功能的插件,支持多种 LLM 客户端如 Cursor 和 Claude。它能高效地抓取、搜索和提取网页内容,并提供自动重试及流量限制等功能,适合开发者和研究人员使用。该产品具有高度的灵活性与可扩展性,可用于批量抓取和深度研究。
Promptrepo是一款集成到Google表单和表格中的工具,可直接从邮件、论坛和聊天中提取客户数据,实现数据的快速分析和见解提取。其主要优点在于节省用户切换工具的时间,提高数据整理和分析的效率。
Reworkd 是一款专注于自动化网页数据提取的产品,通过 AI 技术实现无需代码的网页数据抓取。它能够自动扫描网站、生成代码、运行提取器并验证结果,极大地简化了数据提取的复杂性。该产品的主要优点是节省时间和成本,避免了手动编写和维护数据抓取脚本的繁琐过程。Reworkd 适合需要大量网页数据的企业和开发者,其技术背景基于自研的应用层 LLM 代理技术,能够有效应对网页内容变化和数据一致性问题。产品目前提供付费服务,具体价格需根据官网定价或联系客服了解。
l1m是一个强大的工具,它通过代理的方式利用大型语言模型(LLMs)从非结构化的文本或图像中提取结构化的数据。这种技术的重要性在于它能够将复杂的信息转化为易于处理的格式,从而提高数据处理的效率和准确性。l1m的主要优点包括无需复杂的提示工程、支持多种LLM模型以及内置缓存功能等。它由Inferable公司开发,旨在为用户提供一个简单、高效且灵活的数据提取解决方案。l1m提供免费试用,适合需要从大量非结构化数据中提取有价值信息的企业和开发者。
Deep SerpApi 是一款由 Scrapeless 提供的谷歌搜索引擎数据提取 API 工具。它利用 AI 技术优化数据抓取,能够快速、高效地从谷歌搜索结果中提取结构化数据。该工具支持多种搜索场景,包括谷歌搜索、谷歌Map、谷歌新闻等,并提供高成功率(98.5%)的数据提取能力。其主要优点是快速响应(1-2 秒)、低成本(0.1 美元/千次查询),并且无需用户自行开发或维护爬虫工具。Deep SerpApi 定位为面向企业用户的高效数据提取解决方案,尤其适合需要大规模数据支持的商业分析、市场调研和人工智能应用开发。
PowerAgents 是一款基于 AI 技术的自动化工具,能够帮助用户创建并部署 AI 代理,自动完成网页浏览、数据提取、表单填写等重复性任务。其核心优势在于强大的自动化能力、灵活的任务调度以及实时监控功能,能够显著节省用户的时间和精力,尤其适合需要频繁处理网页任务的专业人士和企业用户。该产品提供多种付费计划,满足不同用户的需求。
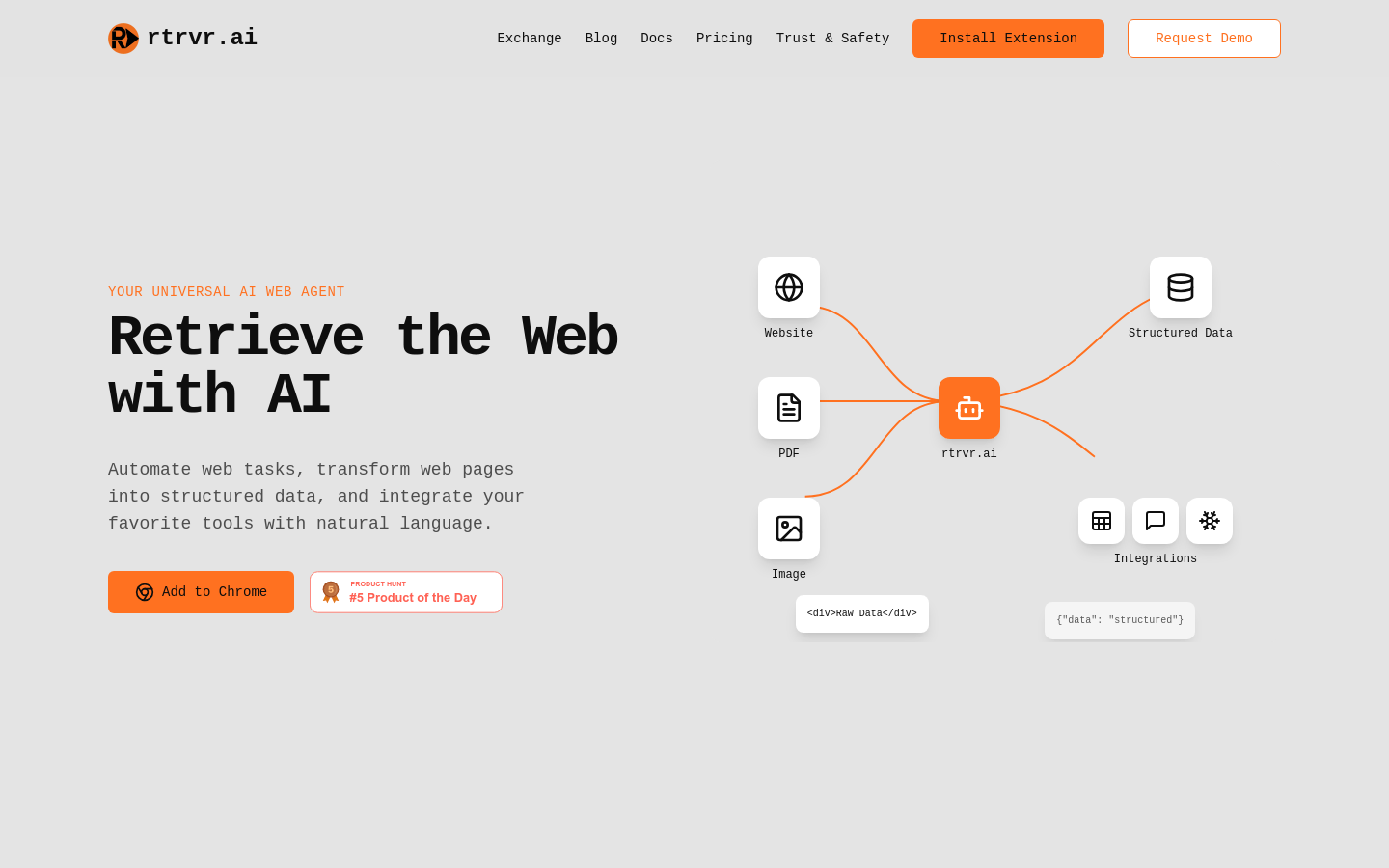
rtrvr.ai 是一款强大的 AI 驱动的网页自动化工具,它能够帮助用户简化复杂的网页浏览和数据提取过程。通过自然语言命令,用户可以轻松地在网页上进行导航,无需手动点击和滚动。此外,它还能将网页内容转化为结构化数据,方便用户构建自定义数据管道。其功能调用特性允许用户直接在浏览器中与各种工具集成,执行任务。该产品在隐私和安全方面表现出色,采用有限权限和沙盒执行等设计,确保用户数据安全。目前,rtrvr.ai 的具体价格未明确,但从其功能和定位来看,它主要面向需要高效处理网页数据和自动化任务的用户。
FreeParser 是一款基于 AI 技术的文档解析工具,旨在通过先进的 OCR 和 LLM 技术帮助用户快速提取文档中的关键信息。它支持多种文件格式,包括 PDF、DOCX、图片等,并提供灵活的自定义提取功能。该产品以简单易用的界面和高性价比的价格定位,满足企业和个人对文档处理的需求。
Stagehand 是一个创新的 AI 驱动的网页自动化框架,它通过自然语言处理技术,扩展了 Playwright 的功能,使开发者能够以更直观的方式自动化浏览器操作。这种技术的重要性在于,它降低了自动化脚本编写的门槛,让非技术用户也能轻松实现复杂的网页交互任务。Stagehand 的主要优点是其强大的自然语言理解能力,能够将简单的指令转化为精确的浏览器操作。它由 Browserbase 团队开发,目标是为开发者提供更高效、更智能的自动化工具。目前,Stagehand 是免费使用的,主要面向开发者和自动化测试人员。
Firecrawl Extract 是一款基于 AI 的数据提取工具,能够将网站数据转换为结构化数据。它通过自然语言提示实现数据提取,解决了传统爬虫脚本易碎、数据质量差等问题。该产品适用于需要大量网络数据的企业和个人,能够显著提高数据获取效率。其定价策略灵活,从免费版到企业定制版,满足不同规模用户的需求。
PDF Dino 是一款基于人工智能的 PDF 数据提取工具,旨在帮助用户从 PDF 文档中快速提取有价值的信息,并将其转换为可操作的结构化数据。该工具利用先进的 AI 技术,能够处理各种类型的 PDF 文件,包括扫描图像、表格和报告。其主要优点是高准确率、快速处理和数据安全性。PDF Dino 提供免费的文本提取功能,并针对高级功能提供灵活的按需付费模式,适合各种规模的企业和个人使用。
NVIDIA-Ingest是一个可扩展、高性能的文档内容和元数据提取微服务。它支持解析PDF、Word和PowerPoint文档,使用NVIDIA NIM微服务来查找、上下文化并提取文本、表格、图表和图像,可用于下游生成式应用。其主要优点包括高性能、可扩展性强、支持多种文档类型和提取方法等。目前处于早期访问阶段,代码库更新频繁。
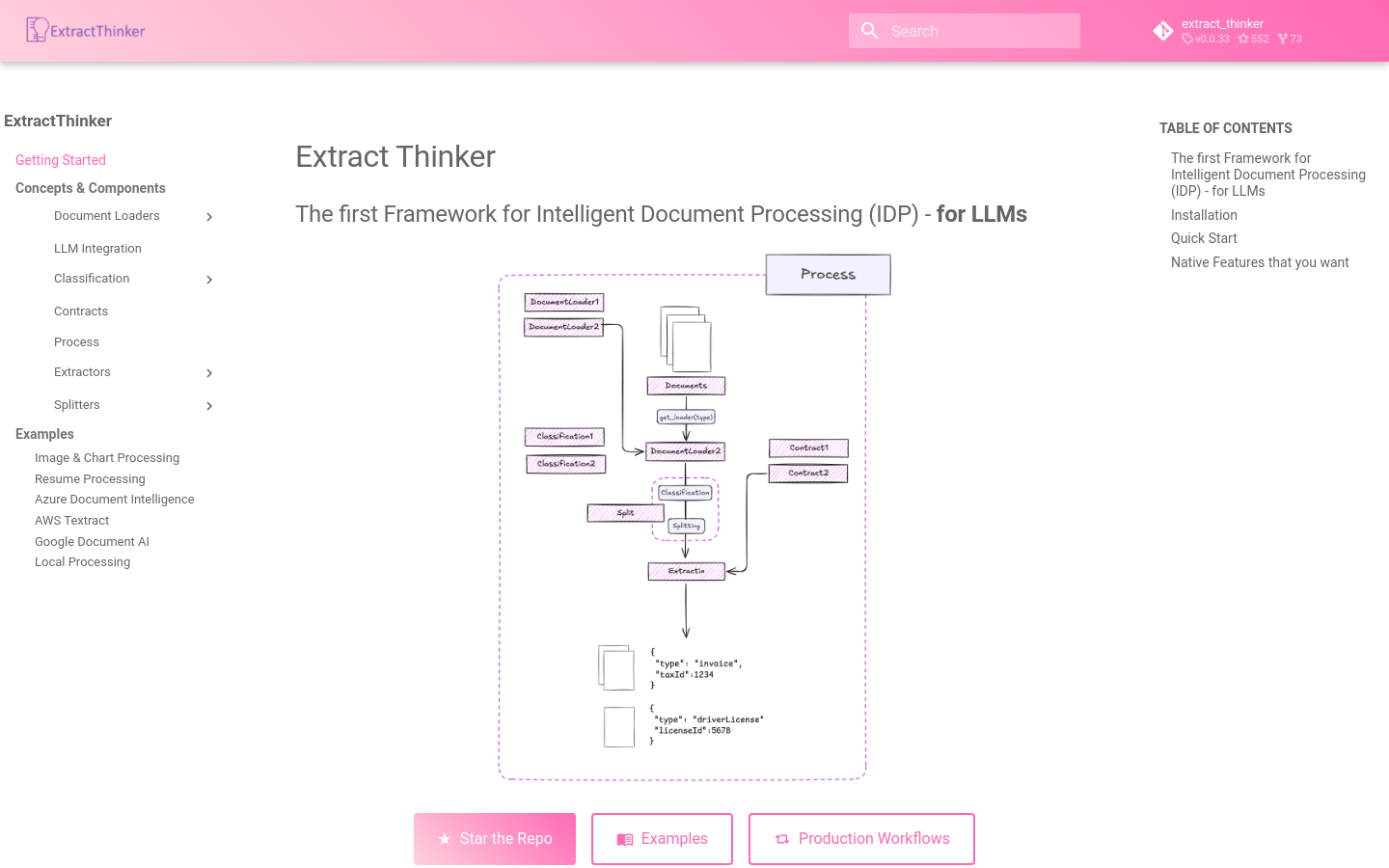
ExtractThinker是一个灵活的文档智能框架,帮助用户从各种文档中提取和分类结构化数据,类似于文档处理工作流的ORM。它被称为“LLMs的文档智能”或“智能文档处理的LangChain”。该框架的动机是为文档处理创建所需的特定功能,如分割大型文档和高级分类。
Midscene.js是一个利用AI技术来简化UI自动化的工具。它通过多模态大语言模型(LLM)直观理解用户界面并执行必要的操作,用户只需描述交互步骤或期望的数据格式,AI即可完成任务。这一技术的重要性在于它极大地降低了UI自动化的维护难度,减少了因界面重构导致的脚本修改工作量,同时提升了自动化测试的效率和准确性。Midscene.js支持多种集成方式,如浏览器插件、Puppeteer和Playwright,并且提供可视化报告和调试工具。作为开源项目,Midscene.js采用MIT许可证,保证了数据的安全性和隐私性。
Claude 3.5 Haiku是Anthropic公司推出的最新最快的模型,它在编程、工具使用和推理任务上表现出色,并且价格亲民。该模型在速度上与Claude 3 Haiku相似,但在各项技能上都有提升,甚至在许多智能基准测试上超越了上一代最大的模型Claude 3 Opus。Anthropic公司致力于AI的安全性,Claude 3.5 Haiku在开发过程中经过了多语言和政策领域的广泛安全评估,增强了处理敏感内容的能力。
Tabled是一个用于检测和提取表格的Python库,它使用surya来识别PDF中的表格,识别行列,并能够将单元格格式化为Markdown、CSV或HTML。这个工具对于数据科学家和研究人员来说非常有用,他们经常需要从PDF文档中提取表格数据以进行进一步的分析。Tabled的主要优点包括高准确性的表格检测和提取能力,支持多种输出格式,以及易于使用的命令行界面。此外,它还提供了一个交互式的APP,允许用户直观地尝试在图像或PDF文件上使用Tabled。
Knowledge Table 是一个开源工具包,旨在简化从非结构化文档中提取和探索结构化数据的过程。它通过自然语言查询界面,使用户能够创建结构化的知识表示,如表格和图表。该工具包具有可定制的提取规则、精细调整的格式化选项,并通过UI显示的数据溯源,适应多种用例。它的目标是为业务用户提供熟悉的电子表格界面,同时为开发者提供灵活且高度可配置的后端,确保与现有RAG工作流程的无缝集成。
Parseflow是一个数据自动化平台,专注于通过先进的OCR和AI技术实现文档数据的自动提取和结构化。它能够显著降低操作成本,提高工作效率,适用于从发票、合同到电子邮件和简历等多种文档类型。该平台易于集成,支持60多种语言,并提供安全的数据存储。Parseflow的主要优点包括快速的数据提取、广泛的文档类型支持、多语言识别能力以及与6000多个应用的集成能力。它的目标是帮助企业释放数据的潜力,提高运营效率。
Handinger是一个提供数据提取服务的网站,它允许用户通过HTTP端点轻松提取网页内容,包括Markdown、截图、元数据和HTML等格式。这种服务对于训练大型语言模型、存储内容或获取网页特定内容非常有用。Handinger的价格非常低廉,每URL的成本仅为0.0005美元,且每月前2000个URL免费,没有前期成本,也无需复杂的API积分。该服务支持所有类型的网站,并且为用户提供了慷慨的速率限制,每分钟可进行1000次请求。
TxT360 是一个由 LLM360 提供的 Hugging Face 空间产品,专注于从海量文本数据中提取有价值的信息。它利用先进的自然语言处理技术,能够高效地处理大规模文本数据,为用户提供深度分析和洞察。这一技术对于需要处理大量文本信息的企业和研究人员来说至关重要,因为它可以节省大量时间和资源,同时提供更准确的数据分析结果。
Youtube-Whisper是一个基于Gradio的应用程序,它通过提取YouTube视频的音频并使用OpenAI的Whisper模型来转录成文本。这个工具对于需要将视频内容转化为文本以进行分析、存档或翻译的用户来说非常有用。它利用了最新的人工智能技术,提高了视频内容的可访问性和可用性。
pandaETL是一个自动化文档工作流程的平台,它通过提取、转换和查询数据来帮助用户高效地处理文档密集型操作。该平台支持上传多种文档格式,如PDF和电子表格,并提供自动化功能来提取精确数据。它还提供与数据对话的直观聊天界面,帮助用户快速生成详细报告。此外,pandaETL还提供行业特定的自动化模块,以满足不同行业的需求。
SellScale AI 是一款专注于商业领域的智能销售自动化平台,旨在帮助企业通过人工智能技术提高销售效率和效果。该平台通过购买邮箱、扩展注册域名、积极监控收件箱健康,确保邮件正确投递,避免进入垃圾邮件箱。此外,SellScale AI 还提供从网络各个角落提取信息、个性化添加变化、拉取博客、视频等丰富内容的功能,以增强销售信息的吸引力。
AgentQL是一款利用人工智能技术来简化网页数据提取和自动化流程的工具。它通过AgentQL查询语言,使用自然语言描述代替传统的XPath或DOM选择器,使得元素的定位更加可靠,即使在网站发生变化时也能准确找到。它支持Chrome扩展,提供API接口,并且有SDK支持,使得开发者可以轻松地编写查询,自动化地填充表单,以及进行端到端测试。
Scrape It Now! 是一个开源的网页抓取工具,它提供了一整套自动化网页抓取和索引的解决方案。该工具使用Python编写,支持多种功能,包括动态JavaScript内容加载、广告屏蔽、随机用户代理,自动创建AI搜索索引等,以提高抓取效率和数据质量。它适用于需要从网页中提取信息并进行进一步分析或存储的用户。
NinjaRIP是一款AI驱动的文档处理服务,它通过先进的机器学习模型来识别模式和提取有意义的信息,从而简化文档工作流程。它以99%以上的准确率在文档识别和数据提取方面提供无与伦比的精确度,确保了数据的可靠性和可信度。NinjaRIP在beta阶段免费提供,一旦过渡到正式版,将提供不同业务需求的定价计划,价格透明且具有竞争力。
AnyParser Playground 是一个基于网页的解决方案,旨在帮助用户从PDF和图像文件中提取信息。它通过使用机器学习技术,能够处理文件的前10页,为用户提供数据的全面洞察。该平台不存储用户数据,保证了数据的隐私和安全性。
Indexify是一个开源数据框架,具有实时提取引擎和预构建的提取适配器,能够可靠地从各种非结构化数据(文档、演示文稿、视频和音频)中提取数据。它支持多模态数据,提供先进的嵌入和分块技术,并允许用户使用Indexify SDK创建自定义提取器。Indexify支持使用语义搜索和SQL查询图像、视频和PDF,确保LLM应用能够获取最准确、最新的数据。此外,Indexify能够在本地运行时进行原型设计,并在生产环境中利用预配置的Kubernetes部署模板,实现自动扩展和处理大量数据。
Playmaker Document AI是一款旨在通过人工智能技术自动化文档处理流程的产品。它通过智能识别和提取文档中的数据,帮助用户消除手动工作,简化基于文档的流程。产品背景信息显示,Playmaker Document AI由Playmaker Software Ltd.开发,团队来自伦敦、爱丁堡、伊斯坦布尔和新德里。产品的主要优点包括数据的安全性、支持多种文档类型、以及能够与300多个集成无缝对接。
Forloop是一个易于使用的AI工具,专为快速增长的数据团队设计,用于数据准备和管道管理。它支持从各种数据源创建管道,如数据仓库、存储和驱动器。无代码环境允许数据科学家独立于DevOps团队工作,主要针对AI初创公司和拥有机器学习产品的公司。
Crawl4AI是一个强大的、免费的网页爬取服务,旨在从网页中提取有用信息,并使其对大型语言模型(LLMs)和AI应用可用。它支持高效的网页爬取,提供对LLM友好的输出格式,如JSON、清理过的HTML和Markdown,支持同时爬取多个URL,并完全免费且开源。
OneChart是一个专注于图表结构提取的人工智能模型,它通过一个辅助标记来净化和提升提取的准确性。该模型能够识别和解析图表中的关键信息,为用户提供结构化的图表数据。OneChart的优势在于其高精度的识别能力和对复杂图表结构的处理能力,适用于需要图表数据转换和分析的多种场景。
2txt是一个在线OCR工具,能够将图片中的文字内容快速识别并转换成可编辑的文本格式。它支持多种语言的识别,并且操作简单,用户只需上传图片即可获得结果。该工具不存储用户上传的图片,保证了用户数据的隐私安全。
Dataku是一款数据提取工具,可以从文档和非结构化文本中无缝提取有价值的见解。主要功能包括:1.文档见解:将文档转化为结构化、可操作的数据。2.文本智能:轻松从非结构化文本中提取关键信息。3.定制数据提取:提供简历、评论、客户、市场、金融等多种场景的数据提取解决方案。工具优势在于提取精准、流程高效、扩展性强。提供免费入门和付费专业版,以及针对企业的定制化服务。定价透明合理,提供多种服务支持。
Extracta.ai是一款可以从任何非结构化文档中提取数据的工具。它可以自动解析扫描文档,并提取您所需的信息,包括功能、优势、定价、定位等。
DOConvert是一个智能文档处理平台,可自动化提取各类文档的复杂数据,优化文档处理和集成流程,节省高达75%的数据录入成本。它支持主流的ERP系统,包括SAP、Salesforce等,也可自定义API集成到任何ERP或CMS系统。DOConvert最多可在10天内完全实施,从首次演示到定制解决方案、ERP连接、模板定制以及全自动化运行。
TableX是一款能够从PDF或图片中提取表格数据的工具。用户可通过上传文件或拖放文件进行操作,数据处理过程安全可靠。提取完成后,用户可下载提取的数据并以Excel格式保存。产品定位于提高数据提取效率和准确性的生产力工具。
FormToExcel是一款将表单转换为Excel的工具。它可以自动从PDF、图片(如JPG、BMP等)中提取数据,并以高准确度的方式填充到Excel中。它简化了数据录入流程,使用AI技术提取表单数据,支持各种字段类型识别,包括文本字段、复选框和单选按钮。FormToExcel与Microsoft Excel无缝集成,可以直接将提取的数据导出到Excel电子表格中,方便进行数据分析和处理。
Airdoc.Pro是一款基于人工智能的数据提取与管理工具。它能够自动从交付文档中提取和整理数据,帮助用户创建站点清单、站点登记和工程量清单,并提供供应商详细信息。通过AI扫描,可以处理照片、PDF等多种格式的文档。Airdoc.Pro可以帮助企业提高文档处理效率,降低成本,并为决策提供数据支持。
GPTOCR是一款自动化文档处理工具,通过几次点击,将您的文档转换为结构化的JSON文件,节省时间,减少错误,提高工作效率,增强团队协作。定价根据使用情况而定,定位于提高工作效率和数据准确性的生产力工具。
Hexofy Scraper是一款免费的网页抓取工具,通过结合人工智能,实现1点击数据捕获和网页抓取。它提供直观的点选界面,无需编写代码即可轻松从网页中提取数据。无论是从市场上的热门网站如亚马逊和eBay,还是从特定领域的网站上提取信息,Hexofy都能高效地完成任务。它是基于浏览器的工具,无需下载和安装。无论是一次性任务还是大规模数据提取项目,Hexofy都能为您提供无缝的抓取体验。
Parseur 是一款强大的 AI 文件解析器,可轻松自动从 PDF、电子邮件和其他文档中提取文本。使用 Parseur,您可以将提取的数据即时发送到所有应用程序。Parseur 不需要技术技能,无需创建复杂的数据提取规则或训练 AI 模型。
DataExtraction是一款AI自动化手动数据任务的产品,可以快速从图像中提取数据,减少人工工作量和时间。它支持多渠道集成,包括语音、文本、文档、视频通话和聊天等。使用先进的技术,如LLMs,自动提取相关信息。它还提供了直观易用的用户界面,可以根据业务需求定义自定义提取规则。用户可以轻松地提取所需的数据,节省时间和资源。
From Chaos是一个Chrome插件,可以将网页内容转化为有组织的数据。通过ChatGPT的能力,您可以输入您的OpenAI API密钥,在所需页面上点击插件,描述您想要的数据类型,并选择数据类型(如JSON、YAML、CSV等)来下载数据。
WAVELINE EXTRACT是一款强大的API,可从文档、图像和PDF中提取数据。它使用AI技术,无需训练数据即可从任何格式的文档中提取数据。它支持各种格式,包括PDF、图像和电子表格文件。WAVELINE EXTRACT有三种不同的定价计划,包括免费的STARTER计划、POPULAR PRO计划和ENTERPRISE计划。它适用于各种场景,包括运输文件、简历和护照等。WAVELINE EXTRACT的主要功能包括从PDF中提取所有数据、从各种格式中提取数据、自定义定价和本地解决方案等。
GetOData是一款AI驱动的Chrome插件,能够轻松从任何网站中提取数据,支持多种格式导出,并提供数据分析功能。通过自定义数据点和支持分页功能,用户可以快速提取所需数据。支持的导出格式包括CSV、Excel、JSON等。快来购买永久使用权吧!
Airparser是一款基于GPT技术的自动化数据提取工具,可以从电子邮件、PDF和文档中提取结构化数据,并实时导出到任何应用程序。它具有OCR引擎,可以轻松从扫描的文档、图像和手写笔记中提取数据。用户可以通过API或自动化平台导入文档,然后使用Airparser的AI和GPT技术进行高效的数据提取。Airparser可以将解析的数据发送到Webhooks,并支持Excel、CSV或JSON格式的导出,可以与Zapier和Make等6000多个应用程序进行无缝集成。
Glean AI是一款智能AP软件,帮助财务和FP&A团队更快、更轻松、更智能地处理账款。它提供了无与伦比的智能和可视性,自动化数据提取、GL编码、账单审批和付款等任务,以及专有的基准数据,帮助用户更好地与供应商谈判,提高公司的支出效率。Glean AI还提供了集中的协作和规划,使用户可以在一个集中的位置查看所有供应商数据,并与团队对预算进行对齐,无缝协作进行支出决策。Glean AI的客户包括Orum、Alloy和Thimble等高增长财务团队。
Bitskout是一款基于AI技术的数据提取工具,可以从文档、电子邮件、发票、名片等中提取数据,提高工作效率和准确性。Bitskout的功能包括自动提取文本、识别结构化数据、自定义数据模板等。它的优势在于可以节省大量的时间和人力,提高数据提取的准确性,同时还提供灵活的定价和定位策略。
Docucontext是一个基于云原生的AI驱动的文档处理解决方案,可以自动提取和分析各种类型文档中的非结构化数据。它采用了生成式AI模型ChatGPT进行驱动。Docucontext的主要功能包括消除手动数据录入和转录错误、处理不同格式和布局的文档、提供强大的搜索和检索功能、与其他软件应用和系统集成、个性化客户体验、高效的客户获取和留存、以及基于Azure Cloud的强大计算能力。
AlgoDocs是一款基于人工智能技术的数据提取工具。它可以从PDF和扫描文件中快速、安全、准确地提取数据,并将其导出到Excel或发送到会计软件等其他集成系统中。AlgoDocs的功能强大,使用简单,可以帮助用户自动化文档处理流程,提高工作效率。
super.AI是一款智能文档处理产品,通过使用最新的人工智能模型,可以自动化处理复杂文档。它可以快速提取文档中的数据,并实现端到端的业务流程自动化。super.AI提供保证结果的智能文档处理服务,可以处理各种复杂文档,包括合同、发票、报告等。它的功能强大,优势在于高准确率和高效率的数据提取,以及可靠的业务流程自动化。super.AI的定价根据使用量和服务等级进行计费,具体详情可联系销售团队。它适用于各种场景,包括金融、法律、医疗等行业。
Base64.ai是一款智能文档处理API,可以从各种类型的文档中提取OCR文本、数据、手写内容、照片和签名。它适用于各种文档类型,包括身份证、驾驶证、护照、签证、收据、发票、表格等。它提供高准确性和安全性,并可通过API、RPA系统、扫描仪、网页和移动应用等多种方式使用。
Intics是一款处理文档的强大工具,能够处理各种形状和形式的文档。它具有提取和验证可靠准确的数据、自动化流程、与工作流应用和RPAs的无缝集成等功能。Intics的定价模型确保您不需要为存储、提取和管道基础设施额外支付费用,使AI变得更加贴近实际。
Kadoa是一款利用生成式AI自动生成网页抓取器并自动提取所需数据的工具。它能够帮助用户在几秒钟内从各种来源中获取所需数据,无需编写代码。
Pixl OCR Solution API是一款高效的OCR解决方案API,可以简化文档OCR文本识别流程。轻松从图像和文档中提取文本,实现快速信息检索。通过集成我们强大的API,不仅可以降低劳动成本,还能实现更快速和更明智的决策。
DocumentPro使用AI从文档和电子邮件中提取信息和表格,快速准确地完成数据录入。它可以处理各种标准的商业文档,无需任何设置,节省时间和精力。支持各类文档类型,包括发票、采购订单、收据、提货单、身份证等。通过智能OCR和GPT技术,DocumentPro能够自动提取数据字段和表格,并支持导出为Excel或JSON格式。无需培训即可使用,还可以处理自定义文档(即将推出)。
Procys是一款利用先进的机器学习技术进行文件处理的产品。它可以自动提取发票、护照、身份证等文档中的数据,实现账务应付自动化。同时,Procys还提供了OCR API和UBL等功能,可以与您的企业资源计划(ERP)系统同步。Procys的自学习引擎和丰富的集成能力使其成为您节省时间和金钱的理想选择。
Regex.ai是一款使用人工智能技术驱动的正则表达式生成器与求解器。它能帮助用户自动化数据提取任务,优化工作流程。通过Regex.ai,您可以轻松地生成和解决各种复杂的正则表达式,从而提高数据处理的效率。
Alphamoon是一款基于人工智能的智能文档处理平台。它能处理各种类型的文档,优化业务流程,并将文档安全存储在云端。Alphamoon提供AI OCR、数据提取、分类、表格等功能。它适用于各个行业,如金融、债务回收等。您可以根据需要选择合适的功能点,并根据不同的使用场景来使用。
FormX.ai是一个基于人工智能技术的服务,可以将纸质文件转换为结构化的数字化数据。通过使用OCR、正则表达式和AI技术,FormX.ai可以提取收据、身份证、商业证书等各种类型的文档中的信息,并将其转换为可读的JSON格式数据。FormX.ai提供易于使用的API和用户友好的Web门户,可以轻松集成到任何软件中。无论您是需要自动化数据提取,还是需要进行数据分析和处理,FormX.ai都是一个强大而可靠的解决方案。
Iris.ai是一款基于人工智能的科研助手,能够帮助研究人员进行文献综述、研究数据提取、市场监测等繁琐任务。它能够理解科学文本,提供高效的文献搜索和分析工具,并能够自动抽取关键信息。Iris.ai的智能功能使得科研工作更加高效和准确。
Hexomatic是一个提供网络爬虫和工作流自动化功能的平台。通过Hexomatic,您可以将互联网作为自己的数据源,自动化执行100多种销售、营销或研究任务。Hexomatic的主要功能包括网页抓取、数据提取、数据清洗和自动化工作流程等。它可以帮助您节省大量时间和人力资源,并提高工作效率。Hexomatic的定价根据用户需求和使用频率进行灵活调整。
Browse AI是一款无需编码即可提取和监控任何网站数据的产品。它可以将特定数据从网站提取为自动填充的电子表格,并在数据发生变化时发送通知。它还提供了预构建的机器人,可以快速解决一些常见的数据提取和监控需求。Browse AI还可以将任何网站转化为API,方便用户进行数据集成和自定义工作流。它的灵活定价和易用性使其受到了101,000多个个人和团队的信赖。
Extend 是为现代企业打造的智能数据提取和自动化工具。它能智能处理文档、电子邮件、图像和各种非结构化数据,提供强大的提取、分类和分析工具。用户可以结合强大的 AI 工具、业务逻辑、验证和集成功能,构建端到端解决方案。Extend 支持各种数据类型,包括 PDF、CSV、XLSX、IMG 和 HTML 等。它还提供内置的置信度评分和人工参与流程,确保用户能够自信地将其部署到生产环境中。Extend 还具备企业级准备性,支持本地部署,与 SOC 2 政策兼容,并且数据安全、加密,并且不会用于训练目的。