找到 120 个相关的AI工具
Retro Image Prompt是由Google Nano Banana驱动的复古图像提示生成器。它支持文本到图像(T2I)和图像到图像(I2I)工作流程,能帮助用户快速创建高质量的复古图像提示和复古AI艺术。产品的主要优点在于提供丰富的复古风格供用户选择,生成的图像质量高且风格稳定。价格方面,使用需要消耗积分,用户可获取积分后使用,定位为满足用户对复古图像创作的需求,无论是个人艺术家、设计师还是普通爱好者都能使用。
Seedream4是一款拥有革命性多模态AI技术的图像生成器,结合文本到图像生成、精确图像编辑和批量创作于一体。其主要优点包括1.8秒快速生成速度、自然语言控制、完整的创意控制和企业集成可用性。价格信息请访问官方网站。
FLUX.1 Krea [dev] 是一个拥有 120 亿参数的修正流转换器,专为从文本描述生成高质量图像而设计。该模型经过指导蒸馏训练,使其更高效,且开放权重推动科学研究和艺术创作。产品强调其美学摄影能力和强大的提示遵循能力,是对封闭源替代品的有力竞争。使用该模型的用户能够进行个人、科学和商业用途,推动创新的工作流程。
OpenDream AI是一个在线AI艺术生成平台,利用先进的AI模型将文本提示转换为图像。它于2023年推出,旨在让图形设计民主化,并使视觉内容创作对每个人都更易达。无需艺术技能,只需描述想要看到的内容,让OpenDream的AI为您创造出来。
Blip 3o 是一个基于 Hugging Face 平台的应用程序,利用先进的生成模型从文本生成图像,或对现有图像进行分析和回答。该产品为用户提供了强大的图像生成和理解能力,非常适合设计师、艺术家和开发者。此技术的主要优点是其高效的图像生成速度和优质的生成效果,同时还支持多种输入形式,增强了用户体验。该产品是免费的,定位于开放给广大用户使用。
CogView4-6B 是由清华大学知识工程组开发的文本到图像生成模型。它基于深度学习技术,能够根据用户输入的文本描述生成高质量的图像。该模型在多个基准测试中表现优异,尤其是在中文文本生成图像方面具有显著优势。其主要优点包括高分辨率图像生成、支持多种语言输入以及高效的推理速度。该模型适用于创意设计、图像生成等领域,能够帮助用户快速将文字描述转化为视觉内容。
CogView4 是由清华大学开发的先进文本到图像生成模型,基于扩散模型技术,能够根据文本描述生成高质量图像。它支持中文和英文输入,并且可以生成高分辨率图像。CogView4 的主要优点是其强大的多语言支持和高质量的图像生成能力,适合需要高效生成图像的用户。该模型在 ECCV 2024 上展示,具有重要的研究和应用价值。
DiffSplat 是一种创新的 3D 生成技术,能够从文本提示和单视图图像快速生成 3D 高斯点云。该技术通过利用大规模预训练的文本到图像扩散模型,实现了高效的 3D 内容生成。它解决了传统 3D 生成方法中数据集有限和无法有效利用 2D 预训练模型的问题,同时保持了 3D 一致性。DiffSplat 的主要优点包括高效的生成速度(1~2 秒内完成)、高质量的 3D 输出以及对多种输入条件的支持。该模型在学术研究和工业应用中具有广泛前景,尤其是在需要快速生成高质量 3D 模型的场景中。
Fashion-Hut-Modeling-LoRA是一个基于Diffusion技术的文本到图像生成模型,主要用于生成时尚模特的高质量图像。该模型通过特定的训练参数和数据集,能够根据文本提示生成具有特定风格和细节的时尚摄影图像。它在时尚设计、广告制作等领域具有重要应用价值,能够帮助设计师和广告商快速生成创意概念图。模型目前仍在训练阶段,可能存在一些生成效果不佳的情况,但已经展示了强大的潜力。该模型的训练数据集包含14张高分辨率图像,使用了AdamW优化器和constant学习率调度器等参数,训练过程注重图像的细节和质量。
Flux-Midjourney-Mix2-LoRA 是一款基于深度学习的文本到图像生成模型,旨在通过自然语言描述生成高质量的图像。该模型基于Diffusion架构,结合了LoRA技术,能够实现高效的微调和风格化图像生成。其主要优点包括高分辨率输出、多样化的风格支持以及对复杂场景的出色表现能力。该模型适用于需要高质量图像生成的用户,如设计师、艺术家和内容创作者,能够帮助他们快速实现创意构思。
NeuralSVG是一种用于从文本提示生成矢量图形的隐式神经表示方法。它受到神经辐射场(NeRFs)的启发,将整个场景编码到一个小的多层感知器(MLP)网络的权重中,并使用分数蒸馏采样(SDS)进行优化。该方法通过引入基于dropout的正则化技术,鼓励生成的SVG具有分层结构,使每个形状在整体场景中具有独立的意义。此外,其神经表示还提供了推理时控制的优势,允许用户根据提供的输入动态调整生成的SVG,如颜色、宽高比等,且只需一个学习到的表示。通过广泛的定性和定量评估,NeuralSVG在生成结构化和灵活的SVG方面优于现有方法。该模型由特拉维夫大学和MIT CSAIL的研究人员共同开发,目前代码尚未公开。
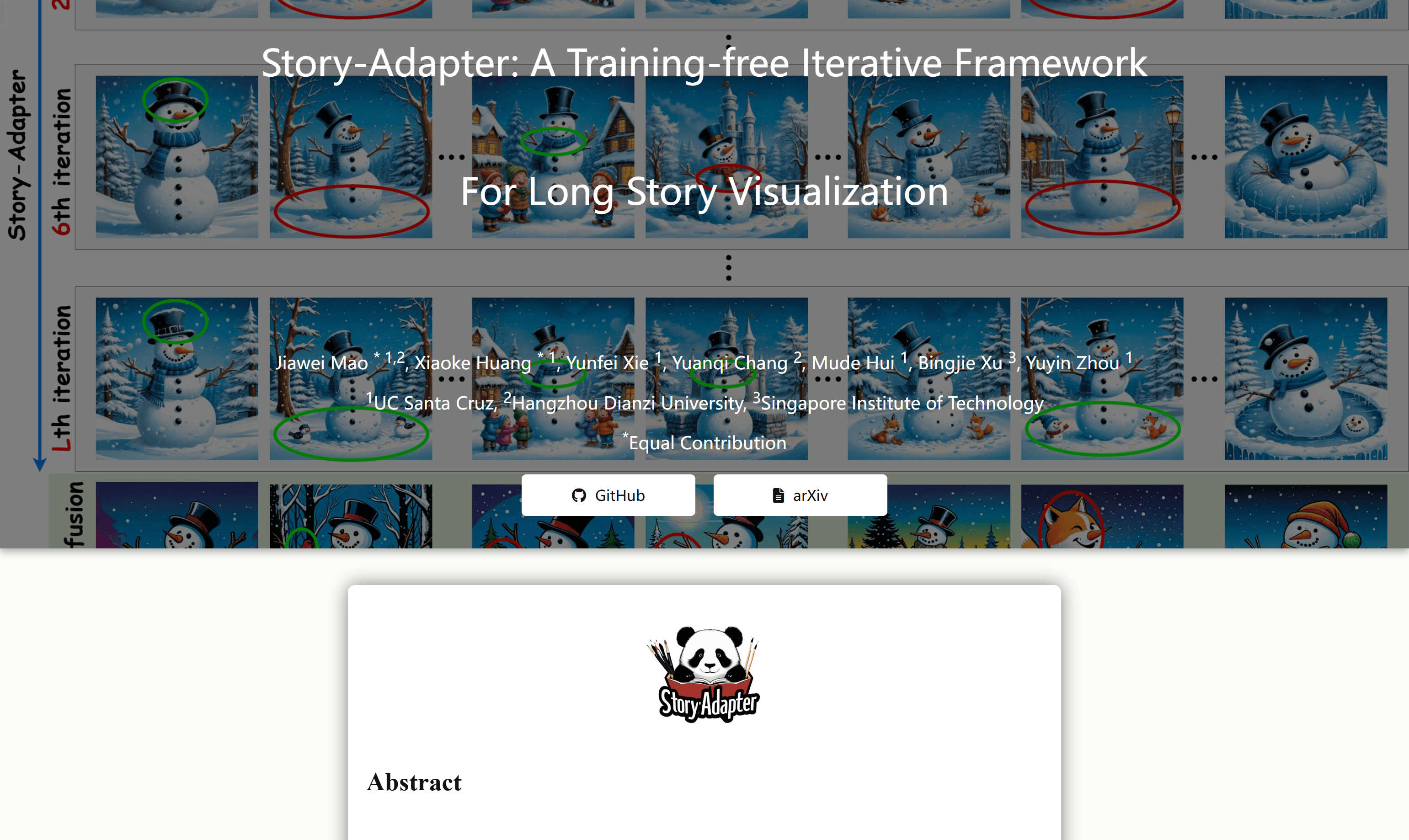
Story-Adapter是一个无需训练的迭代框架,专为长篇故事可视化设计。它通过迭代范式和全局参考交叉注意力模块,优化图像生成过程,保持故事中语义的连贯性,同时减少计算成本。该技术的重要性在于它能够在长篇故事中生成高质量、细节丰富的图像,解决了传统文本到图像模型在长故事可视化中的挑战,如语义一致性和计算可行性。
DynamicControl是一个用于提升文本到图像扩散模型控制力的框架。它通过动态组合多样的控制信号,支持自适应选择不同数量和类型的条件,以更可靠和详细地合成图像。该框架首先使用双循环控制器,利用预训练的条件生成模型和判别模型,为所有输入条件生成初始真实分数排序。然后,通过多模态大型语言模型(MLLM)构建高效条件评估器,优化条件排序。DynamicControl联合优化MLLM和扩散模型,利用MLLM的推理能力促进多条件文本到图像任务,最终排序的条件输入到并行多控制适配器,学习动态视觉条件的特征图并整合它们以调节ControlNet,增强对生成图像的控制。
LuminaBrush是一个交互式工具,旨在绘制图像上的照明效果。该工具采用两阶段方法:一阶段将图像转换为“均匀照明”的外观,另一阶段根据用户涂鸦生成照明效果。这种分解方法简化了学习过程,避免了单一阶段可能需要考虑的外部约束(如光传输一致性等)。LuminaBrush利用从高质量野外图像中提取的“均匀照明”外观来构建训练最终交互式照明绘图模型的配对数据。此外,该工具还可以独立使用“均匀照明阶段”来“去照明”图像。
fofr/flux-condensation是一个基于文本生成图像的AI模型,使用Diffusers库和LoRAs技术,能够根据用户提供的文本提示生成相应的图像。该模型在Replicate上训练,具有非商业性质的flux-1-dev许可证。它代表了文本到图像生成技术的最新进展,能够为设计师、艺术家和内容创作者提供强大的视觉表现工具。
Sana是一个由NVIDIA开发的文本到图像的生成框架,能够高效生成高达4096×4096分辨率的图像。Sana以其快速的速度和强大的文本图像对齐能力,可以在笔记本电脑GPU上部署,代表了图像生成技术的一个重要进步。该模型基于线性扩散变换器,使用预训练的文本编码器和空间压缩的潜在特征编码器,能够根据文本提示生成和修改图像。Sana的开源代码可在GitHub上找到,其研究和应用前景广阔,尤其在艺术创作、教育工具和模型研究等方面。
Sana是一个由NVIDIA开发的文本到图像生成框架,能够高效生成高达4096×4096分辨率的图像。Sana以其快速的速度和强大的文本图像对齐能力,使得在笔记本电脑GPU上也能部署。它是一个基于线性扩散变换器(text-to-image generative model)的模型,拥有1648M参数,专门用于生成1024px基础的多尺度高宽图像。Sana模型的主要优点包括高分辨率图像生成、快速的合成速度以及强大的文本图像对齐能力。Sana模型的背景信息显示,它是基于开源代码开发的,可以在GitHub上找到源代码,同时它也遵循特定的许可证(CC BY-NC-SA 4.0 License)。
shou_xin是一个基于文本到图像的生成模型,它能够根据用户提供的文本提示生成具有手訫风格的铅笔素描图像。这个模型使用了diffusers库和lora技术,以实现高质量的图像生成。shou_xin模型以其独特的艺术风格和高效的图像生成能力在图像生成领域占有一席之地,特别适合需要快速生成具有特定艺术风格的图像的用户。
Sana是一个由NVIDIA开发的文本到图像的框架,能够高效生成高达4096×4096分辨率的图像。该模型以惊人的速度合成高分辨率、高质量的图像,并保持强大的文本-图像对齐能力,可部署在笔记本电脑GPU上。Sana模型基于线性扩散变换器,使用预训练的文本编码器和空间压缩的潜在特征编码器,支持Emoji、中文和英文以及混合提示。
Bylo.ai是一款高级的AI图像生成器,能够将文本描述快速转换为高质量的图像。它支持负面提示和多种模型,包括流行的Flux AI图像生成器,让用户可以自定义创作。Bylo.ai以其免费在线访问、快速高效生成、高级自定义选项、灵活的图像设置和高质量图像输出等特点,成为个人和商业用途的理想选择。
AWPortraitCN是一个基于FLUX.1-dev开发的文本到图像生成模型,专门针对中国人的外貌和审美进行训练。它包含多种类型的肖像,如室内外肖像、时尚和摄影棚照片,具有强大的泛化能力。与原始版本相比,AWPortraitCN在皮肤质感上更加细腻和真实。为了追求更真实的原始图像效果,可以与AWPortraitSR工作流程一起使用。
Sana是一个由NVIDIA开发的文本到图像的框架,能够高效生成高达4096×4096分辨率的图像。Sana能够以极快的速度合成高分辨率、高质量的图像,并且具有强烈的文本-图像对齐能力,可以在笔记本电脑GPU上部署。该模型基于线性扩散变换器,使用固定预训练的文本编码器和空间压缩的潜在特征编码器,支持英文、中文和表情符号混合提示。Sana的主要优点包括高效率、高分辨率图像生成能力以及多语言支持。
Sana是一个由NVIDIA开发的文本到图像生成框架,能够高效生成高达4096×4096分辨率的高清晰度、高文本-图像一致性的图像,并且速度极快,可以在笔记本电脑GPU上部署。Sana模型基于线性扩散变换器,使用预训练的文本编码器和空间压缩的潜在特征编码器。该技术的重要性在于其能够快速生成高质量的图像,对于艺术创作、设计和其他创意领域具有革命性的影响。Sana模型遵循CC BY-NC-SA 4.0许可协议,源代码可在GitHub上找到。
Sana是一个由NVIDIA开发的文本到图像的生成框架,能够高效生成高达4096×4096分辨率的图像。Sana以其快速的速度、强大的文本图像对齐能力以及可在笔记本电脑GPU上部署的特性而著称。该模型基于线性扩散变换器,使用预训练的文本编码器和空间压缩的潜在特征编码器,代表了文本到图像生成技术的最新进展。Sana的主要优点包括高分辨率图像生成、快速合成、笔记本电脑GPU上的可部署性,以及开源的代码,使其在研究和实际应用中具有重要价值。
MV-Adapter是一种基于适配器的多视图图像生成解决方案,它能够在不改变原有网络结构或特征空间的前提下,增强预训练的文本到图像(T2I)模型及其衍生模型。通过更新更少的参数,MV-Adapter实现了高效的训练并保留了预训练模型中嵌入的先验知识,降低了过拟合风险。该技术通过创新的设计,如复制的自注意力层和并行注意力架构,使得适配器能够继承预训练模型的强大先验,以建模新的3D知识。此外,MV-Adapter还提供了统一的条件编码器,无缝整合相机参数和几何信息,支持基于文本和图像的3D生成以及纹理映射等应用。MV-Adapter在Stable Diffusion XL(SDXL)上实现了768分辨率的多视图生成,并展示了其适应性和多功能性,能够扩展到任意视图生成,开启更广泛的应用可能性。
text-to-pose是一个研究项目,旨在通过文本描述生成人物姿态,并利用这些姿态生成图像。该技术结合了自然语言处理和计算机视觉,通过改进扩散模型的控制和质量,实现了从文本到图像的生成。项目背景基于NeurIPS 2024 Workshop上发表的论文,具有创新性和前沿性。该技术的主要优点包括提高图像生成的准确性和可控性,以及在艺术创作和虚拟现实等领域的应用潜力。
Sana是一个文本到图像的框架,能够高效生成高达4096×4096分辨率的图像。它以极快的速度合成高分辨率、高质量的图像,并保持强大的文本-图像对齐,可以部署在笔记本电脑GPU上。Sana的核心设计包括深度压缩自编码器、线性扩散变换器(DiT)、仅解码器的小型语言模型作为文本编码器,以及高效的训练和采样策略。Sana-0.6B与现代大型扩散模型相比,体积小20倍,测量吞吐量快100倍以上。此外,Sana-0.6B可以部署在16GB笔记本电脑GPU上,生成1024×1024分辨率图像的时间少于1秒。Sana使得低成本的内容创作成为可能。
Stable Diffusion 3.5 ControlNets是由Stability AI提供的文本到图像的AI模型,支持多种控制网络(ControlNets),如Canny边缘检测、深度图和高保真上采样等。该模型能够根据文本提示生成高质量的图像,特别适用于插画、建筑渲染和3D资产纹理等场景。它的重要性在于能够提供更精细的图像控制能力,提升生成图像的质量和细节。产品背景信息包括其在学术界的引用(arxiv:2302.05543),以及遵循的Stability Community License。价格方面,对于非商业用途、年收入不超过100万美元的商业用途免费,超过则需联系企业许可。
FLUX.1-dev-IP-Adapter是一个基于FLUX.1-dev模型的IP-Adapter,由InstantX Team研发。该模型能够将图像工作处理得像文本一样灵活,使得图像生成和编辑更加高效和直观。它支持图像参考,但不适用于细粒度的风格转换或角色一致性。模型在10M开源数据集上训练,使用128的批量大小和80K的训练步骤。该模型在图像生成领域具有创新性,能够提供多样化的图像生成解决方案,但可能存在风格或概念覆盖不足的问题。
FLUX.1 Tools是Black Forest Labs推出的一套模型工具,旨在为基于文本的图像生成模型FLUX.1增加控制和可操作性,使得对真实和生成的图像进行修改和再创造成为可能。该工具套件包含四个不同的特性,以开放访问模型的形式在FLUX.1 [dev]模型系列中提供,并作为BFL API的补充,支持FLUX.1 [pro]。FLUX.1 Tools的主要优点包括先进的图像修复和扩展能力、结构化引导、图像变化和重构等,这些功能对于图像编辑和创作领域具有重要意义。
Edify Image是NVIDIA推出的一款图像生成模型,它能够生成具有像素级精确度的逼真图像内容。该模型采用级联像素空间扩散模型,并通过新颖的拉普拉斯扩散过程进行训练,该过程能够在不同频率带以不同的速率衰减图像信号。Edify Image支持多种应用,包括文本到图像合成、4K上采样、ControlNets、360° HDR全景图生成和图像定制微调。它代表了图像生成技术的最新进展,具有广泛的应用前景和重要的商业价值。
FLUX.1-dev LoRA Outfit Generator是一个文本到图像的AI模型,能够根据用户详细描述的颜色、图案、合身度、风格、材质和类型来生成服装。该模型使用了H&M Fashion Captions Dataset数据集进行训练,并基于Ostris的AI Toolkit进行开发。它的重要性在于能够辅助设计师快速实现设计想法,加速服装行业的创新和生产流程。
Regional-Prompting-FLUX是一种训练无关的区域提示扩散变换器模型,它能够在无需训练的情况下,为扩散变换器(如FLUX)提供细粒度的组合文本到图像生成能力。该模型不仅效果显著,而且与LoRA和ControlNet高度兼容,能够在保持高速度的同时减少GPU内存的使用。
Stable Diffusion 3.5 Medium 是由 Stability AI 提供的一款基于人工智能的图像生成模型,它能够根据文本描述生成高质量的图像。这项技术的重要性在于它能够极大地推动创意产业的发展,如游戏设计、广告、艺术创作等领域。Stable Diffusion 3.5 Medium 以其高效的图像生成能力、易用性和较低的资源消耗而受到用户的青睐。目前,该模型在 Hugging Face 平台上以免费试用的形式提供给用户。
Stable Diffusion 3.5 Medium是一个基于文本到图像的生成模型,由Stability AI开发,具有改进的图像质量、排版、复杂提示理解和资源效率。该模型使用了三个固定的预训练文本编码器,通过QK-规范化提高训练稳定性,并在前12个变换层中引入双注意力块。它在多分辨率图像生成、一致性和各种文本到图像任务的适应性方面表现出色。
Flux.1 Lite是一个由Freepik发布的8B参数的文本到图像生成模型,它是从FLUX.1-dev模型中提取出来的。这个版本相较于原始模型减少了7GB的RAM使用,并提高了23%的运行速度,同时保持了与原始模型相同的精度(bfloat16)。该模型的发布旨在使高质量的AI模型更加易于获取,特别是对于消费级GPU用户。
Stable Diffusion 3.5 Large Turbo 是一个基于文本生成图像的多模态扩散变换器(MMDiT)模型,采用了对抗性扩散蒸馏(ADD)技术,提高了图像质量、排版、复杂提示理解和资源效率,特别注重减少推理步骤。该模型在生成图像方面表现出色,能够理解和生成复杂的文本提示,适用于多种图像生成场景。它在Hugging Face平台上发布,遵循Stability Community License,适合研究、非商业用途以及年收入少于100万美元的组织或个人免费使用。
Stable Diffusion 3.5 Large 是一个基于文本生成图像的多模态扩散变换器(MMDiT)模型,由 Stability AI 开发。该模型在图像质量、排版、复杂提示理解和资源效率方面都有显著提升。它使用三个固定的预训练文本编码器,并通过 QK 归一化技术提高训练稳定性。此外,该模型在训练数据和策略上使用了包括合成数据和过滤后的公开可用数据。Stable Diffusion 3.5 Large 模型在遵守社区许可协议的前提下,可以免费用于研究、非商业用途,以及年收入少于100万美元的组织或个人的商业用途。
Stable Diffusion 3.5是一个用于简单推理的轻量级模型,它包含了文本编码器、VAE解码器和核心MM-DiT技术。该模型旨在帮助合作伙伴组织实现SD3.5,并且可以用于生成高质量的图像。它的重要性在于其高效的推理能力和对资源的低要求,使得广泛的用户群体能够使用和享受生成图像的乐趣。该模型遵循Stability AI Community License Agreement,并且可以免费使用。
SD3.5-LoRA-Linear-Red-Light是一个基于文本到图像生成的AI模型,通过使用LoRA(Low-Rank Adaptation)技术,该模型能够根据用户提供的文本提示生成高质量的图像。这种技术的重要性在于它能够以较低的计算成本实现模型的微调,同时保持生成图像的多样性和质量。该模型基于Stable Diffusion 3.5 Large模型,并在此基础上进行了优化和调整,以适应特定的图像生成需求。
FLUX.1-dev-LoRA-Text-Poster是由Shakker-Labs开发的文本到图像生成模型,专门用于艺术文本海报的生成。该模型利用LoRA技术,通过文本提示来生成图像,为用户提供了一种创新的方式来创作艺术作品。模型的训练由版权用户cooooool完成,并在Hugging Face平台上共享,以促进社区的交流和发展。模型遵循非商业用途的flux-1-dev许可协议。
ComfyGen 是一个专注于文本到图像生成的自适应工作流系统,它通过学习用户提示来自动化并定制有效的工作流。这项技术的出现,标志着从使用单一模型到结合多个专业组件的复杂工作流的转变,旨在提高图像生成的质量。ComfyGen 背后的主要优点是能够根据用户的文本提示自动调整工作流,以生成更高质量的图像,这对于需要生成特定风格或主题图像的用户来说非常重要。
由清华大学团队开发的文本到图像生成模型,开源,在图像生成领域有广泛应用前景,有高分辨率输出等优点。
Flux Ghibsky Illustration 是一个基于文本生成图像的模型,它结合了宫崎骏动画工作室的奇幻细节和新海诚作品中的宁静天空,创造出迷人的场景。该模型特别适合创造梦幻般的视觉效果,用户可以通过特定的触发词来生成具有独特审美的图像。它是基于Hugging Face平台的开源项目,允许用户下载模型并在Replicate上运行。
Easy Anime Maker是一个基于人工智能的动漫生成器,它使用深度学习技术,如生成对抗网络,将用户输入的文本描述或上传的照片转换成动漫风格的艺术作品。这项技术的重要性在于它降低了创作动漫艺术的门槛,使得没有专业绘画技能的用户也能创造出个性化的动漫图像。产品背景信息显示,它是一个在线平台,用户可以通过简单的文本提示或上传照片来生成动漫艺术,非常适合动漫爱好者和需要快速生成动漫风格图像的专业人士。产品提供免费试用,用户注册后可以获得5个免费积分,如果需要更多生成需求,可以选择购买积分,无需订阅。
FLUX.1-Turbo-Alpha是一个基于FLUX.1-dev模型的8步蒸馏Lora,由AlimamaCreative Team发布。该模型使用多头鉴别器来提高蒸馏质量,可以用于文本到图像(T2I)、修复控制网络等FLUX相关模型。推荐使用指导比例为3.5,Lora比例为1。该模型在1M开源和内部源图像上进行训练,采用对抗性训练提高质量,固定原始FLUX.1-dev变换器作为鉴别器主干,并在每层变换器上添加多头。
FLUX.1-dev-LoRA-One-Click-Creative-Template 是一个基于 LoRA 训练的图像生成模型,由 Shakker-Labs 提供。该模型专注于创意照片生成,能够将用户的文本提示转化为具有创意性的图像。模型使用了先进的文本到图像的生成技术,特别适合需要快速生成高质量图像的用户。它是基于 Hugging Face 平台,可以方便地进行部署和使用。模型的非商业使用是免费的,但商业使用需要遵守相应的许可协议。
Flux 1.1 Pro AI是一个基于人工智能的高级图像生成平台,它利用尖端的AI技术将用户的文本提示转化为高质量的视觉效果。该平台在图像生成速度上提高了6倍,图像质量显著改善,并增强了对提示的遵从性。Flux 1.1 Pro AI不仅适用于艺术家和设计师,还适用于内容创作者、营销人员等专业人士,帮助他们在各自的领域中实现视觉想法,提升创作效率和质量。
FLUX1.1 [pro] 是 Black Forest Labs 发布的最新图像生成模型,它在速度和图像质量上都有显著提升。该模型提供六倍于前代的速度,同时改善了图像质量、提示遵循度和多样性。FLUX1.1 [pro] 还提供了更高级的定制化选项,以及更优的性价比,适合需要高效、高质量图像生成的开发者和企业。
OpenFLUX.1是一个基于FLUX.1-schnell模型的微调版本,移除了蒸馏过程,使其可以进行微调,并且拥有开源、宽松的许可证Apache 2.0。该模型能够生成令人惊叹的图像,并且只需1-4步即可完成。它是一个尝试去除蒸馏过程,创建一个可以微调的开源许可模型。
Stable Video Portraits是一种创新的混合2D/3D生成方法,利用预训练的文本到图像模型(2D)和3D形态模型(3D)生成逼真的动态人脸视频。该技术通过人特定的微调,将一般2D稳定扩散模型提升到视频模型,通过提供时间序列的3D形态模型作为条件,并引入时间去噪过程,生成具有时间平滑性的人脸影像,可以编辑和变形为文本定义的名人形象,无需额外的测试时微调。该方法在定量和定性分析中均优于现有的单目头部化身方法。
CogView3是一个基于级联扩散的文本到图像生成系统,使用中继扩散框架。该系统通过将高分辨率图像生成过程分解为多个阶段,并通过中继超分辨率过程,在低分辨率生成结果上添加高斯噪声,从而开始从这些带噪声的图像进行扩散过程。CogView3在生成图像方面超越了SDXL,具有更快的生成速度和更高的图像质量。
Prompt Llama是一个专注于文本到图像生成的AI模型测试平台,它允许用户收集高质量的文本提示,并测试不同模型在同一提示下的表现。该平台支持多种AI模型,包括但不限于midjourney、DALL·E 3、Firefly等,是AI图像生成领域研究者和爱好者的宝贵资源。
FLUX AI图像生成器是一个创新的图像生成模型,它能够根据文本提示生成高质量的图像。FLUX.1的重要性在于它能够使高质量内容创作工具民主化,为专业人士和业余爱好者提供了一个简化的解决方案,允许用户在不需要广泛的技术知识或资源的情况下生成专业级的视觉效果。
StoryMaker是一个专注于文本到图像生成的AI模型,能够根据文本描述生成具有连贯性的角色和场景图像。它通过结合先进的图像生成技术和人脸编码技术,为用户提供了一个强大的工具,用于创作故事性强的视觉内容。该模型的主要优点包括高效的图像生成能力、对细节的精确控制以及对用户输入的高度响应。它在创意产业、广告和娱乐领域有着广泛的应用前景。
Concept Sliders 是一种用于精确控制扩散模型中概念的技术,它通过低秩适配器(LoRA)在预训练模型之上进行应用,允许艺术家和用户通过简单的文本描述或图像对来训练控制特定属性的方向。这种技术的主要优点是能够在不改变图像整体结构的情况下,对生成的图像进行细微调整,如眼睛大小、光线等,从而实现更精细的控制。它为艺术家提供了一种新的创作表达方式,同时解决了生成模糊或扭曲图像的问题。
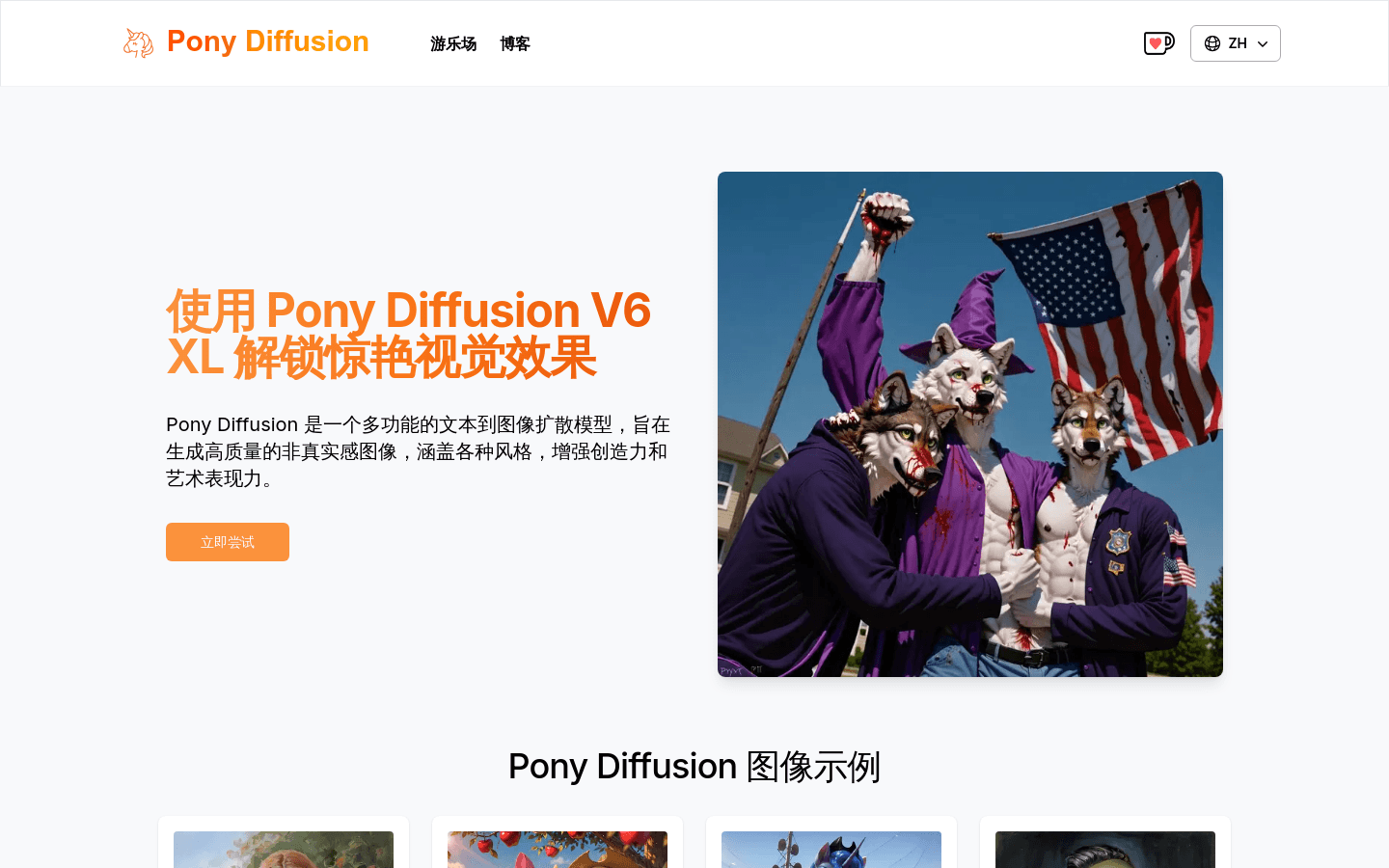
Pony Diffusion V6 XL是一个文本到图像的扩散模型,专门设计用于生成以小马为主题的高质量艺术作品。它在大约80,000张小马图像的数据集上进行了微调,确保生成的图像既相关又美观。该模型采用用户友好的界面,易于使用,并通过CLIP进行美学排名,以提升图像质量。Pony Diffusion在CreativeML OpenRAIL许可证下提供,允许用户自由使用、再分发和修改模型。
Flux Image Generator是一个利用先进AI模型技术,将用户的想法迅速转化为高质量图像的工具。它提供三种不同的模型变体,包括快速的本地开发和个人使用模型FLUX.1 [schnell],非商业应用的指导蒸馏模型FLUX.1 [dev],以及提供最先进性能图像生成的FLUX.1 [pro]。该工具不仅适用于个人项目,也适用于商业用途,能够满足不同用户的需求。
RECE是一种文本到图像扩散模型的概念擦除技术,它通过在模型训练过程中引入正则化项来实现对特定概念的可靠和高效擦除。这项技术对于提高图像生成模型的安全性和控制性具有重要意义,特别是在需要避免生成不适当内容的场景中。RECE技术的主要优点包括高效率、高可靠性和易于集成到现有模型中。
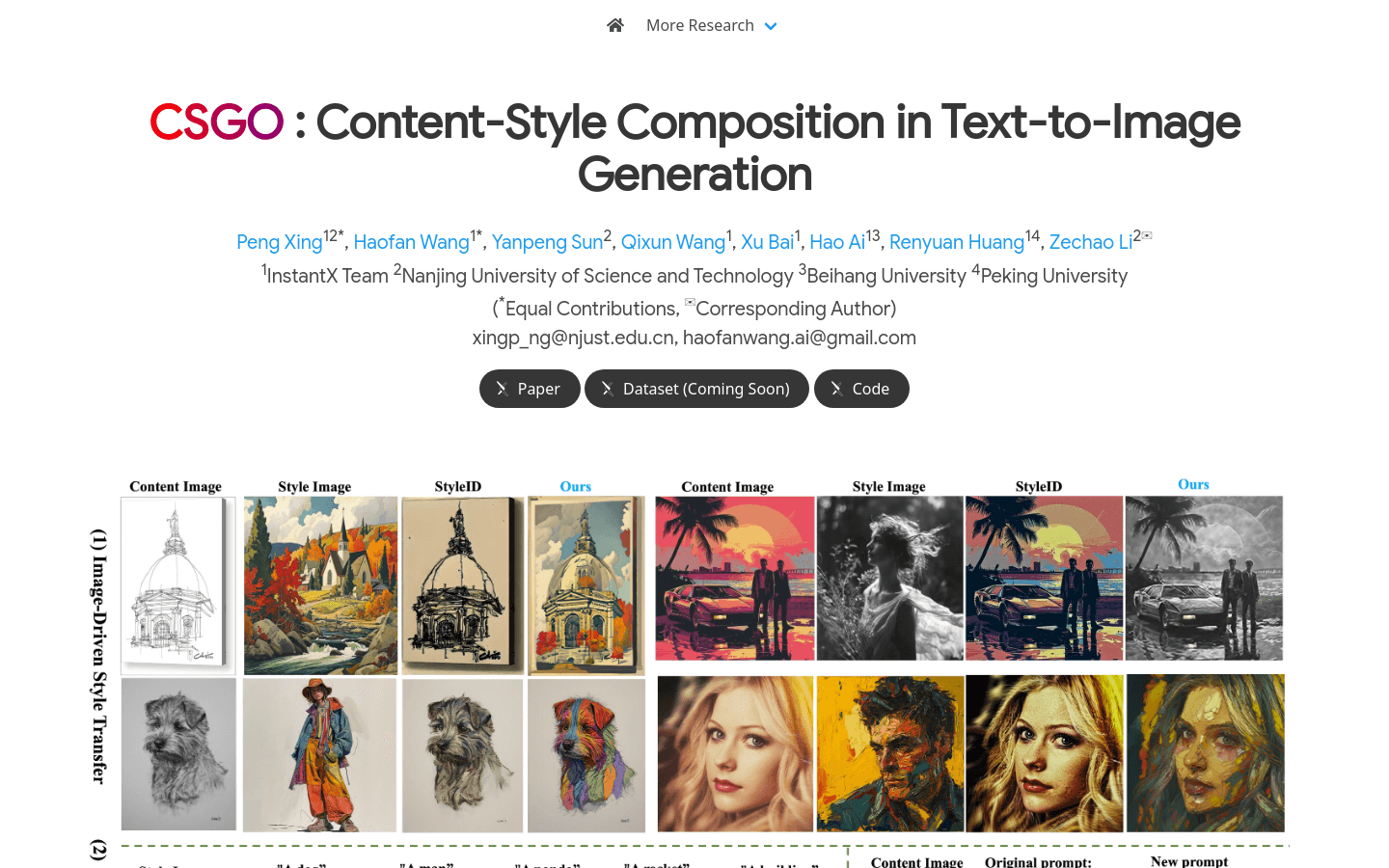
CSGO是一个基于内容风格合成的文本到图像生成模型,它通过一个数据构建管道生成并自动清洗风格化数据三元组,构建了首个大规模的风格迁移数据集IMAGStyle,包含210k图像三元组。CSGO模型采用端到端训练,明确解耦内容和风格特征,通过独立特征注入实现。它实现了图像驱动的风格迁移、文本驱动的风格合成以及文本编辑驱动的风格合成,具有无需微调即可推理、保持原始文本到图像模型的生成能力、统一风格迁移和风格合成等优点。
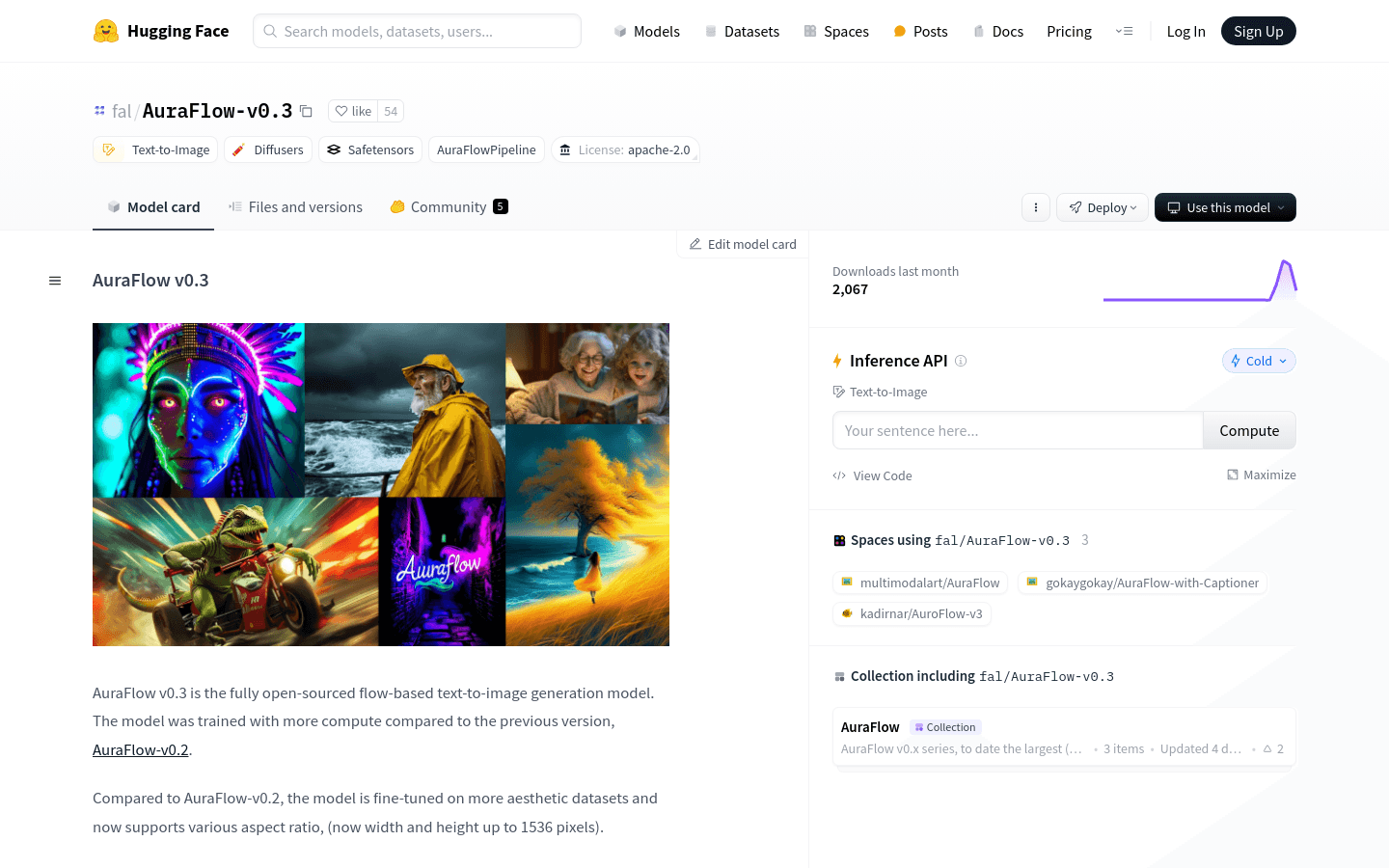
AuraFlow v0.3是一个完全开源的基于流的文本到图像生成模型。与之前的版本AuraFlow-v0.2相比,该模型经过了更多的计算训练,并在美学数据集上进行了微调,支持各种宽高比,宽度和高度可达1536像素。该模型在GenEval上取得了最先进的结果,目前处于beta测试阶段,正在不断改进中,社区反馈非常重要。
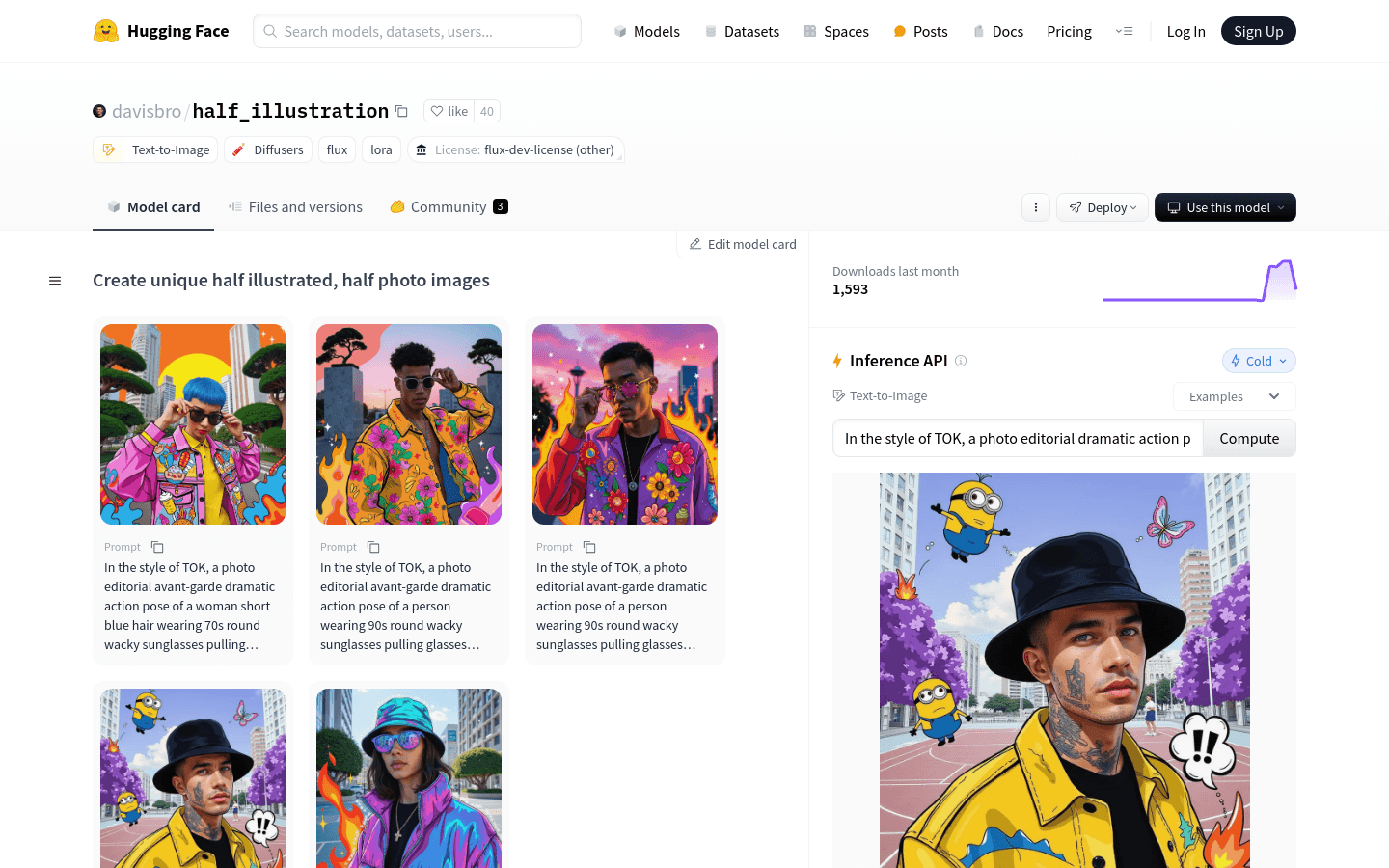
half_illustration是一个基于Flux Dev 1模型的文本到图像生成模型,能够结合摄影和插图元素,创造出具有艺术感的图像。该模型使用了LoRA技术,可以通过特定的触发词来保持风格一致性,适合用于艺术创作和设计领域。
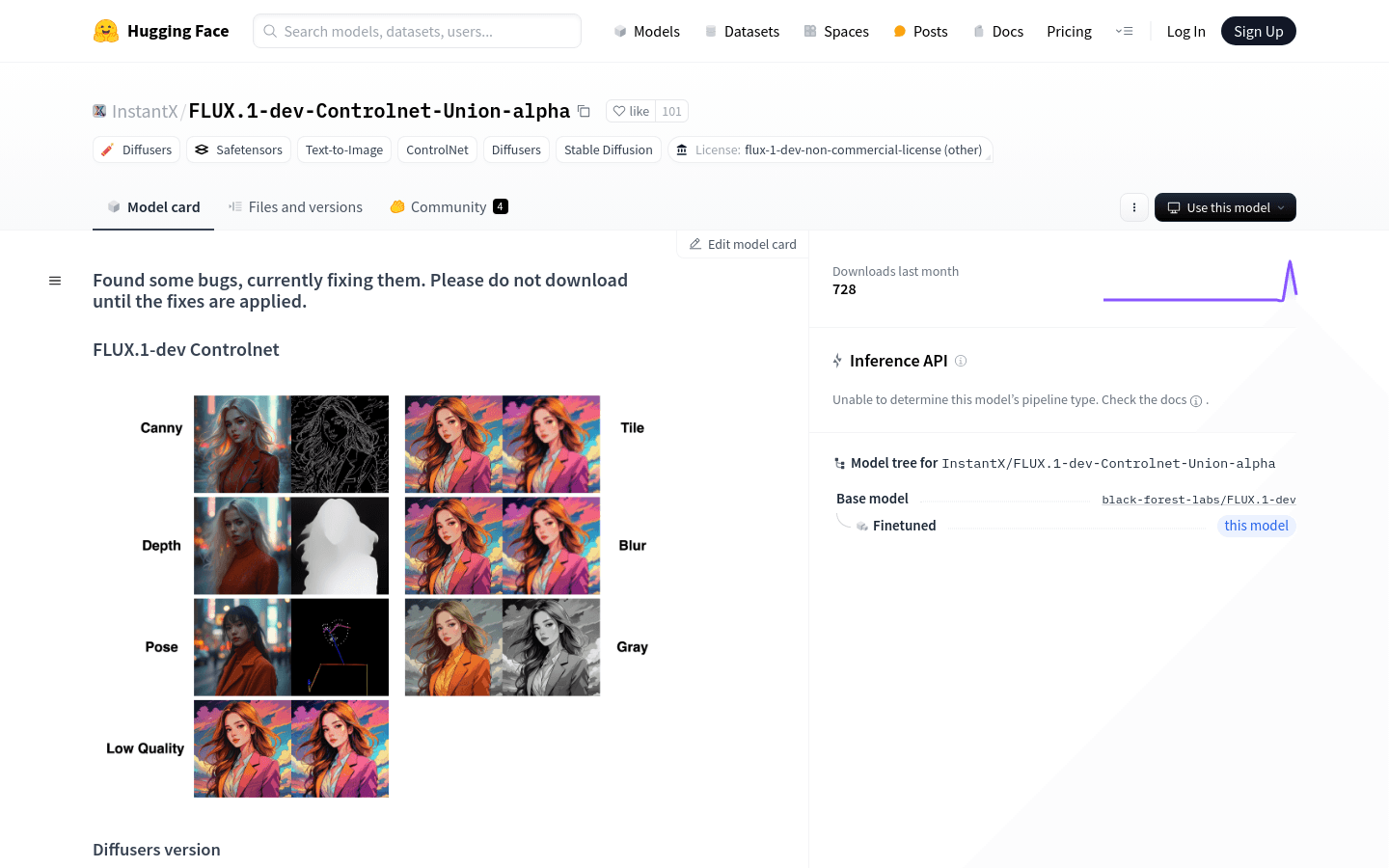
FLUX.1-dev-Controlnet-Union-alpha是一个文本到图像的生成模型,属于Diffusers系列,使用ControlNet技术进行控制。目前发布的是alpha版本,尚未完全训练完成,但已经展示了其代码的有效性。该模型旨在通过开源社区的快速成长,推动Flux生态系统的发展。尽管完全训练的Union模型可能在特定领域如姿势控制上不如专业模型,但随着训练的进展,其性能将不断提升。
flux-RealismLora是由XLabs AI团队发布的基于FLUX.1-dev模型的LoRA技术,用于生成逼真的图像。该技术通过文本提示生成图像,支持多种风格,如动画风格、幻想风格和自然电影风格。XLabs AI提供了训练脚本和配置文件,以方便用户进行模型训练和使用。
flux-controlnet-canny是由XLabs AI团队开发的基于FLUX.1-dev模型的ControlNet Canny模型,用于文本到图像的生成。该模型通过训练,能够根据文本提示生成高质量的图像,广泛应用于创意设计和视觉艺术领域。
TexGen是一个创新的多视角采样和重采样框架,用于根据任意文本描述合成3D纹理。它利用预训练的文本到图像的扩散模型,通过一致性视图采样和注意力引导的多视角采样策略,以及噪声重采样技术,显著提高了3D对象的纹理质量,具有高度的视角一致性和丰富的外观细节。
Flux AI是由Black Forest Labs开发的一款先进的文本到图像的AI模型,它利用基于变换器的流模型生成高质量的图像。该技术的主要优点包括卓越的视觉质量、对提示的严格遵循、尺寸/比例的多样性、排版和输出多样性。Flux AI提供三种变体:FLUX.1 [pro]、FLUX.1 [dev]和FLUX.1 [schnell],分别针对不同的使用场景和性能水平。Flux AI致力于让尖端AI技术对每个人都可及,通过提供FLUX.1 [schnell]作为免费开源模型,确保个人、研究人员和小开发者能够无财务障碍地受益于先进的AI技术。
Phantasma Anime模型是一个专注于幻想主题的动漫风格插画生成工具,它通过文本到图像的转换技术,为用户提供具有特定效果细节的动漫插画。该模型在灵活性和幻想元素的表现上具有优势,适合需要快速生成动漫风格图像的用户。
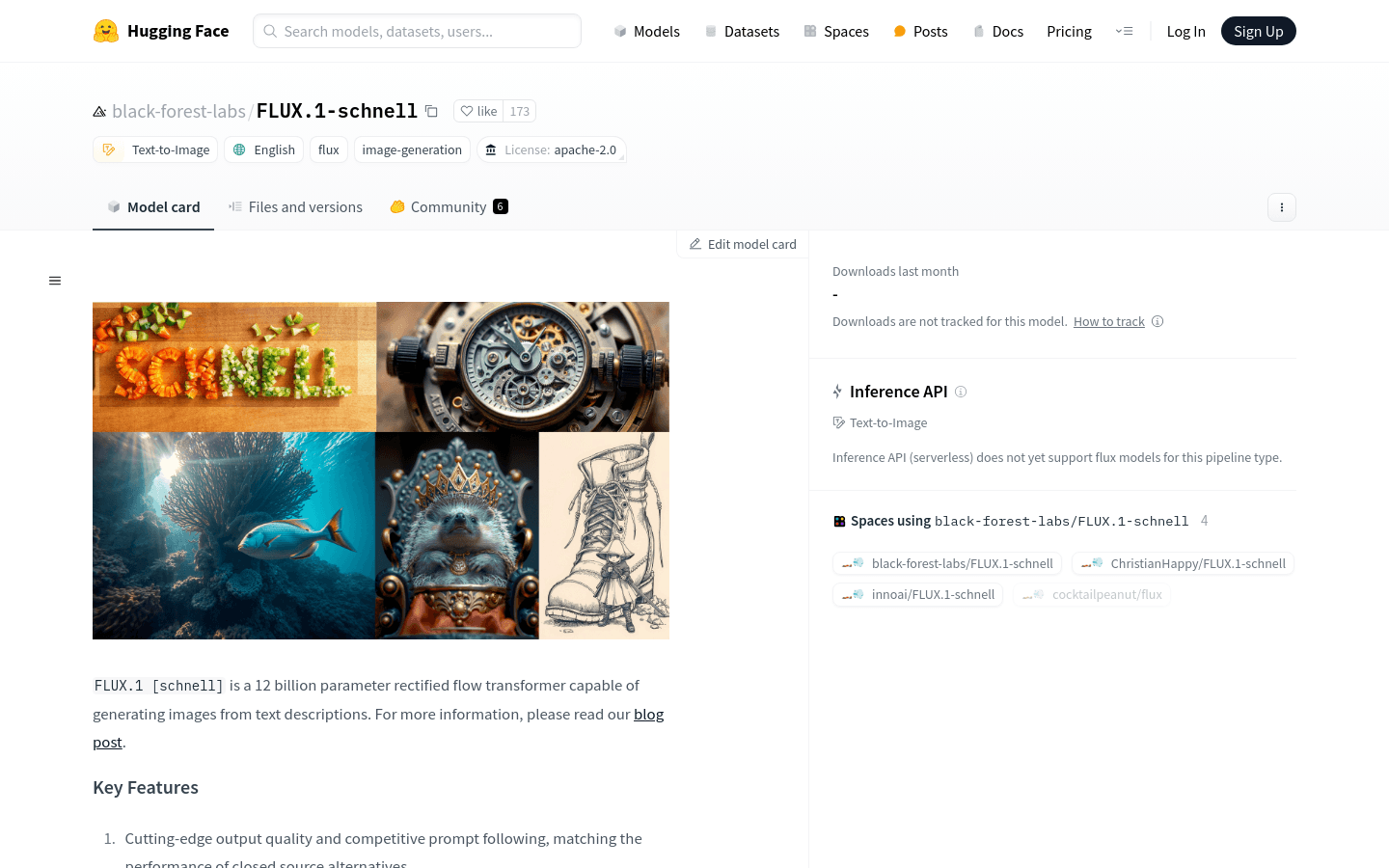
FLUX.1 [schnell] 是一个具有12亿参数的修正流变换器,能够从文本描述生成图像。它以其尖端的输出质量和竞争性的提示跟随能力而著称,与闭源替代品的性能相匹配。该模型使用潜在对抗性扩散蒸馏进行训练,能够在1到4步内生成高质量的图像。FLUX.1 [schnell] 在apache-2.0许可证下发布,可以用于个人、科学和商业目的。
FLUX.1-dev是一个拥有12亿参数的修正流变换器,能够根据文本描述生成图像。它代表了文本到图像生成技术的最新发展,具有先进的输出质量,仅次于其专业版模型FLUX.1 [pro]。该模型通过指导蒸馏训练,提高了效率,并且开放权重以推动新的科学研究,并赋予艺术家开发创新工作流程的能力。生成的输出可以用于个人、科学和商业目的,具体如flux-1-dev-non-commercial-license所述。
Adobe Firefly Vector AI是Adobe推出的一系列创意生成AI模型,旨在通过生成AI功能增强创意工作。Firefly模型和服务于Photoshop、Illustrator、Lightroom等Adobe创意应用中。它通过文本到图像、生成填充、生成扩展等功能,帮助用户以前所未有的控制力和创造力生成丰富、逼真的图像和艺术作品。Firefly的训练数据包括Adobe Stock的授权内容、公开许可内容和公共领域内容,确保其商业使用安全。Adobe致力于负责任地开发生成AI,并通过与创意社区的紧密合作,不断改进技术,支持和提升创意过程。
AuraFlow v0.1是一个完全开源的、基于流的文本到图像生成模型,它在GenEval上达到了最先进的结果。目前模型处于beta阶段,正在不断改进中,社区反馈至关重要。感谢两位工程师@cloneofsimo和@isidentical将此项目变为现实,以及为该项目奠定基础的研究人员。
Kolors是由快手Kolors团队开发的大规模文本到图像生成模型,基于潜在扩散模型,训练于数十亿文本-图像对。它在视觉质量、复杂语义准确性以及中英文文本渲染方面,均优于开源和闭源模型。Kolors支持中英文输入,尤其在理解及生成中文特定内容方面表现突出。
这是一款基于stabilityai/stable-diffusion-xl-base-1.0的LoRA适应性权重模型,专为生成具有水彩插画风格图像而设计。它通过LoRA技术增强了原有模型的特定风格生成能力,使得用户可以更精确地控制生成图像的风格。
Midsommar Cartoon是一款将复古风格与动漫元素结合的图像生成模型。它基于stable-diffusion技术,通过文本到图像的转换,能够生成具有北欧卡通特色的插画。该模型支持在Inference API上加载,使用户能够轻松地将文本描述转化为视觉图像。
AsyncDiff 是一种用于并行化扩散模型的异步去噪加速方案,它通过将噪声预测模型分割成多个组件并分配到不同的设备上,实现了模型的并行处理。这种方法显著减少了推理延迟,同时对生成质量的影响很小。AsyncDiff 支持多种扩散模型,包括 Stable Diffusion 2.1、Stable Diffusion 1.5、Stable Diffusion x4 Upscaler、Stable Diffusion XL 1.0、ControlNet、Stable Video Diffusion 和 AnimateDiff。
Stable Diffusion 3是由Stability AI开发的最新文本生成图像模型,具有显著进步的图像保真度、多主体处理和文本匹配能力。利用多模态扩散变换器(MMDiT)架构,提供单独的图像和语言表示,支持API、下载和在线平台访问,适用于各种应用场景。
InstantX是一个专注于AI内容生成的独立研究组织,致力于文本到图像的生成技术。其研究项目包括风格保持的文本到图像生成(InstantStyle)和零样本身份保持生成(InstantID)。该组织通过GitHub社区进行项目更新和交流,推动AI在图像生成领域的应用和发展。
Stable Diffusion 3 Medium是Stability AI迄今为止发布的最先进文本到图像生成模型。它具有2亿参数,提供出色的细节、色彩和光照效果,支持多种风格。模型对长文本和复杂提示的理解能力强,能够生成具有空间推理、构图元素、动作和风格的图像。此外,它还实现了前所未有的文本质量,减少了拼写、字距、字母形成和间距的错误。模型资源效率高,适合在标准消费级GPU上运行,且具备微调能力,可以吸收小数据集中的细微细节,非常适合定制化。
HyperDreamBooth是由Google Research开发的一种超网络,用于快速个性化文本到图像模型。它通过从单张人脸图像生成一组小型的个性化权重,结合快速微调,能够在多种上下文和风格中生成具有高主题细节的人脸图像,同时保持模型对多样化风格和语义修改的关键知识。
SDXL Flash是由SD社区与Project Fluently合作推出的文本到图像生成模型。它在保持生成图像质量的同时,提供了比LCM、Turbo、Lightning和Hyper更快的处理速度。该模型基于Stable Diffusion XL技术,通过优化步骤和CFG(Guidance)参数,实现了图像生成的高效率和高质量。
Slicedit是一种零样本视频编辑技术,它利用文本到图像的扩散模型,并结合时空切片来增强视频编辑中的时序一致性。该技术能够保留原始视频的结构和运动,同时符合目标文本描述。通过广泛的实验,证明了Slicedit在编辑真实世界视频方面具有明显优势。
Imagen 3 是谷歌一个先进的文本到图像的生成模型,它能够生成具有极高细节水平和逼真效果的图像,并且相较于之前的模型,其视觉干扰元素显著减少。该模型对自然语言的理解更为深入,能够更好地把握提示背后的意图,并从更长的提示中提取细节。此外,Imagen 3 在渲染文本方面表现出色,为个性化生日信息、演示文稿标题幻灯片等提供了新的可能性。
Lumina-T2X是一个先进的文本到任意模态生成框架,它能够将文本描述转换为生动的图像、动态视频、详细的多视图3D图像和合成语音。该框架采用基于流的大型扩散变换器(Flag-DiT),支持高达7亿参数,并能扩展序列长度至128,000个标记。Lumina-T2X集成了图像、视频、3D对象的多视图和语音频谱图到一个时空潜在标记空间中,可以生成任何分辨率、宽高比和时长的输出。
ID-Aligner 是一种用于增强身份保留文本到图像生成的反馈学习框架,它通过奖励反馈学习来解决身份特征保持、生成图像的审美吸引力以及与LoRA和Adapter方法的兼容性问题。该方法利用面部检测和识别模型的反馈来提高生成的身份保留,并通过人类标注偏好数据和自动构建的反馈来提供审美调整信号。ID-Aligner 适用于LoRA和Adapter模型,通过广泛的实验验证了其有效性。
PixArt-Sigma是一个基于PyTorch的模型定义、预训练权重和推理/采样代码的集合,用于探索4K文本到图像生成的弱到强训练扩散变换器。它支持从低分辨率到高分辨率的图像生成,提供了多种功能和优势,如快速体验、用户友好的代码库和多种模型选择。
Stable Diffusion 3是一款先进的文本到图像生成系统,它在排版和提示遵循方面与DALL-E 3和Midjourney v6等顶尖系统相匹敌或更优。该系统采用新的多模态扩散变换器(MMDiT)架构,使用不同的权重集来改善图像和语言的表示,从而提高文本理解和拼写能力。Stable Diffusion 3 API现已在Stability AI开发者平台上线,与Fireworks AI合作提供快速可靠的API服务,并承诺在不久的将来通过Stability AI会员资格开放模型权重以供自托管。
ViewDiff 是一种利用预训练的文本到图像模型作为先验知识,从真实世界数据中学习生成多视角一致的图像的方法。它在U-Net网络中加入了3D体积渲染和跨帧注意力层,能够在单个去噪过程中生成3D一致的图像。与现有方法相比,ViewDiff生成的结果具有更好的视觉质量和3D一致性。
InstantStyle 是一个通用框架,利用两种简单但强大的技术,实现对参考图像中风格和内容的有效分离。其原则包括将内容从图像中分离出来、仅注入到风格块中,并提供样式风格的合成和图像生成等功能。InstantStyle 可以帮助用户在文本到图像生成过程中保持风格,为用户提供更好的生成体验。
SPRIGHT是一个专注于空间关系的大规模视觉语言数据集和模型。它通过重新描述600万张图像构建了SPRIGHT数据集,显著增加了描述中的空间短语。该模型在444张包含大量物体的图像上进行微调训练,从而优化生成具有空间关系的图像。SPRIGHT在多个基准测试中实现了空间一致性的最新水平,同时提高了图像质量评分。
Canva 的 AI 图像生成器应用程序让你随时拥有完美的图像——即使它还不存在。使用"文本到图像"功能,您只需输入文字,就能生成用于创意项目(如演示文稿或社交媒体帖子)的图像。选择不同的图像风格,如水彩、电影、霓虹灯等。您还可以使用 Canva 的其他 AI 生成器应用程序,如 DALL·E 和 Imagen。无论您是内容创作者、企业家还是艺术家,都可以使用这些工具高效创建独特的图像和品牌素材。Canva 提供免费和付费订阅,付费版可以每月生成更多图像。
Animagine XL 3.1 是一款能够基于文本提示生成高质量动漫风格图像的文本到图像生成模型。它建立在稳定扩散 XL 的基础之上,专门针对动漫风格进行了优化。该模型具有更广泛的动漫角色知识、优化过的数据集和新的美学标签,从而提高了生成图像的质量和准确性。它旨在为动漫爱好者、艺术家和内容创作者提供有价值的资源。
FineControlNet是一个基于Pytorch的官方实现,用于生成可通过空间对齐的文本控制输入(如2D人体姿势)和实例特定的文本描述来控制图像实例的形状和纹理的图像。它可以使用从简单的线条画作为空间输入,到复杂的人体姿势。FineControlNet确保了实例和环境之间自然的交互和视觉协调,同时获得了Stable Diffusion的质量和泛化能力,但具有更多的控制能力。
ELLA(Efficient Large Language Model Adapter)是一种轻量级方法,可将现有的基于CLIP的扩散模型配备强大的LLM。ELLA提高了模型的提示跟随能力,使文本到图像模型能够理解长文本。我们设计了一个时间感知语义连接器,从预训练的LLM中提取各种去噪阶段的时间步骤相关条件。我们的TSC动态地适应了不同采样时间步的语义特征,有助于在不同的语义层次上对U-Net进行冻结。ELLA在DPG-Bench等基准测试中表现优越,尤其在涉及多个对象组合、不同属性和关系的密集提示方面表现出色。
Muse Pro通过GPT-4 Vision技术提供无与伦比的速度和质量,支持实时AI引导,让艺术家可以使用熟悉的工具和创新的AI释放创造力。它具备文本到图像的功能、随机化创作、细节增强、视觉描述、直观的AI控制滑块、暂停功能以及图层和画笔库等多样化工具。
SLD是一个自纠正的LLM控制的扩散模型框架,它通过集成检测器增强生成模型,以实现精确的文本到图像对齐。SLD框架支持图像生成和精细编辑,并且与任何图像生成器兼容,如DALL-E 3,无需额外训练或数据。
PIXART-Σ是一个直接生成4K分辨率图像的扩散变换器模型,相较于前身PixArt-α,它提供了更高的图像保真度和与文本提示更好的对齐。PIXART-Σ的关键特性包括高效的训练过程,它通过结合更高质量的数据,从“较弱”的基线模型进化到“更强”的模型,这一过程被称为“弱到强训练”。PIXART-Σ的改进包括使用更高质量的训练数据和高效的标记压缩。
TCD是一种用于文本到图像合成的一致性蒸馏技术,它通过轨迹一致性函数(TCF)和策略性随机采样(SSS)来减少合成过程中的错误。TCD在低NFE(噪声自由能量)时显著提高图像质量,并在高NFE时保持比教师模型更详细的结果。TCD不需要额外的判别器或LPIPS监督,即可在低NFE和高NFE时均保持优越的生成质量。
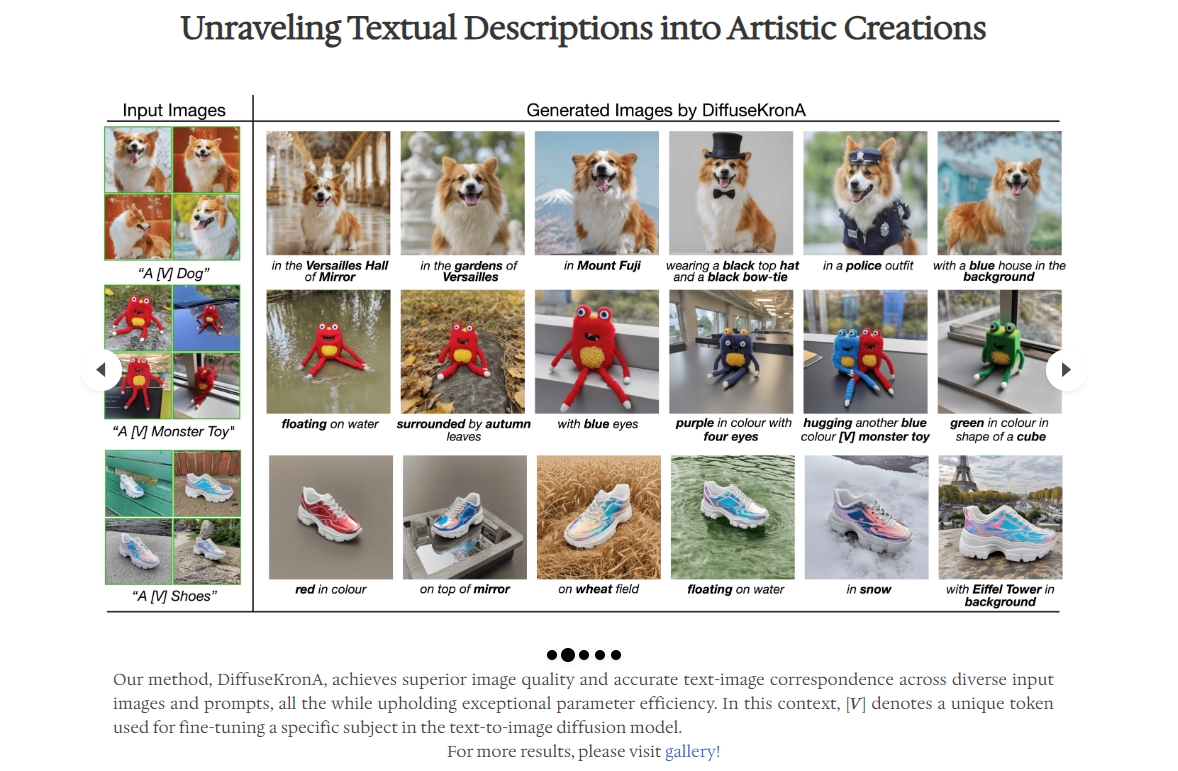
DiffuseKronA 是一种参数高效的微调方法,用于个性化扩散模型。它通过引入基于 Kronecker 乘积的适配模块,显著降低参数数量,提升图像合成质量。该方法减少了对超参数的敏感性,在不同超参数下生成高质量图像,为文本到图像生成模型领域带来重大进展。
OpenDiT是一个开源项目,提供了一个基于Colossal-AI的Diffusion Transformer(DiT)的高性能实现,专为增强DiT应用(包括文本到视频生成和文本到图像生成)的训练和推理效率而设计。OpenDiT通过以下技术提升性能:在GPU上高达80%的加速和50%的内存减少;包括FlashAttention、Fused AdaLN和Fused layernorm核心优化;包括ZeRO、Gemini和DDP的混合并行方法,还有对ema模型进行分片进一步降低内存成本;FastSeq:一种新颖的序列并行方法,特别适用于DiT等工作负载,其中激活大小较大但参数大小较小;单节点序列并行可以节省高达48%的通信成本;突破单个GPU的内存限制,减少整体训练和推理时间;通过少量代码修改获得巨大性能改进;用户无需了解分布式训练的实现细节;完整的文本到图像和文本到视频生成流程;研究人员和工程师可以轻松使用和调整我们的流程到实际应用中,无需修改并行部分;在ImageNet上进行文本到图像训练并发布检查点。

![FLUX.1 Krea [dev]](https://pic.chinaz.com/ai/2025/08/01/25080110475283667344.jpg)











































![FLUX1.1 [pro]](https://pic.chinaz.com/ai/2024/10/08/202410081033531725.jpg)