共找到 100 个AI工具
点击任意工具查看详细信息
AgentSphere是专为AI代理设计的云基础设施,提供安全的代码执行和文件处理,支持各种AI工作流。其内置功能包括AI数据分析、生成数据可视化、安全虚拟桌面代理等,旨在支持复杂工作流程、DevOps集成和LLM评估与微调。
Seed-Coder 是字节跳动 Seed 团队推出的开源代码大型语言模型系列,包含基础、指令和推理模型,旨在通过最小的人力投入,自主管理代码训练数据,从而显著提升编程能力。该模型在同类开源模型中表现优越,适合于各种编码任务,定位于推动开源 LLM 生态的发展,适用于研究和工业界。
Agent-as-a-Judge 是一种新型的自动化评估系统,旨在通过代理系统的互相评估来提高工作效率和质量。该产品能够显著减少评估时间和成本,同时提供持续的反馈信号,促进代理系统的自我改进。它被广泛应用于 AI 开发任务中,特别是在代码生成领域。该系统具备开源特性,便于开发者进行二次开发和定制。
Search-R1 是一个强化学习框架,旨在训练能够进行推理和调用搜索引擎的语言模型(LLMs)。它基于 veRL 构建,支持多种强化学习方法和不同的 LLM 架构,使得在工具增强的推理研究和开发中具备高效性和可扩展性。
automcp 是一个开源工具,旨在简化将各种现有代理框架(如 CrewAI、LangGraph 等)转换为 MCP 服务器的过程。这使得开发者可以通过标准化接口更容易地访问这些服务器。该工具支持多种代理框架的部署,并且通过易于使用的 CLI 界面进行操作。适合需要快速集成和部署 AI 代理的开发者,价格免费,适合个人和团队使用。
PokemonGym 是一个基于服务器 - 客户端架构的平台,专为 AI 代理设计,能够在 Pokemon Red 游戏中进行评估和训练。它通过 FastAPI 提供游戏状态,支持人类与 AI 代理的互动,帮助研究人员和开发者测试和改进 AI 解决方案。
Pruna 是一个为开发者设计的模型优化框架,通过一系列压缩算法,如量化、修剪和编译等技术,使得机器学习模型在推理时更快、体积更小且计算成本更低。产品适用于多种模型类型,包括 LLMs、视觉转换器等,且支持 Linux、MacOS 和 Windows 等多个平台。Pruna 还提供了企业版 Pruna Pro,解锁更多高级优化功能和优先支持,助力用户在实际应用中提高效率。
Flux 是由字节跳动开发的一个高性能通信重叠库,专为 GPU 上的张量和专家并行设计。它通过高效的内核和对 PyTorch 的兼容性,支持多种并行化策略,适用于大规模模型训练和推理。Flux 的主要优点包括高性能、易于集成和对多种 NVIDIA GPU 架构的支持。它在大规模分布式训练中表现出色,尤其是在 Mixture-of-Experts (MoE) 模型中,能够显著提高计算效率。
Atom of Thoughts (AoT) 是一种新型推理框架,通过将解决方案表示为原子问题的组合,将推理过程转化为马尔可夫过程。该框架通过分解和收缩机制,显著提升了大语言模型在推理任务上的性能,同时减少了计算资源的浪费。AoT 不仅可以作为独立的推理方法,还可以作为现有测试时扩展方法的插件,灵活结合不同方法的优势。该框架开源且基于 Python 实现,适合研究人员和开发者在自然语言处理和大语言模型领域进行实验和应用。
3FS是一个专为AI训练和推理工作负载设计的高性能分布式文件系统。它利用现代SSD和RDMA网络,提供共享存储层,简化分布式应用开发。其核心优势在于高性能、强一致性和对多种工作负载的支持,能够显著提升AI开发和部署的效率。该系统适用于大规模AI项目,尤其在数据准备、训练和推理阶段表现出色。
DeepSeek-V3/R1 推理系统是 DeepSeek 团队开发的高性能推理架构,旨在优化大规模稀疏模型的推理效率。它通过跨节点专家并行(EP)技术,显著提升 GPU 矩阵计算效率,降低延迟。该系统采用双批量重叠策略和多级负载均衡机制,确保在大规模分布式环境中高效运行。其主要优点包括高吞吐量、低延迟和优化的资源利用率,适用于高性能计算和 AI 推理场景。
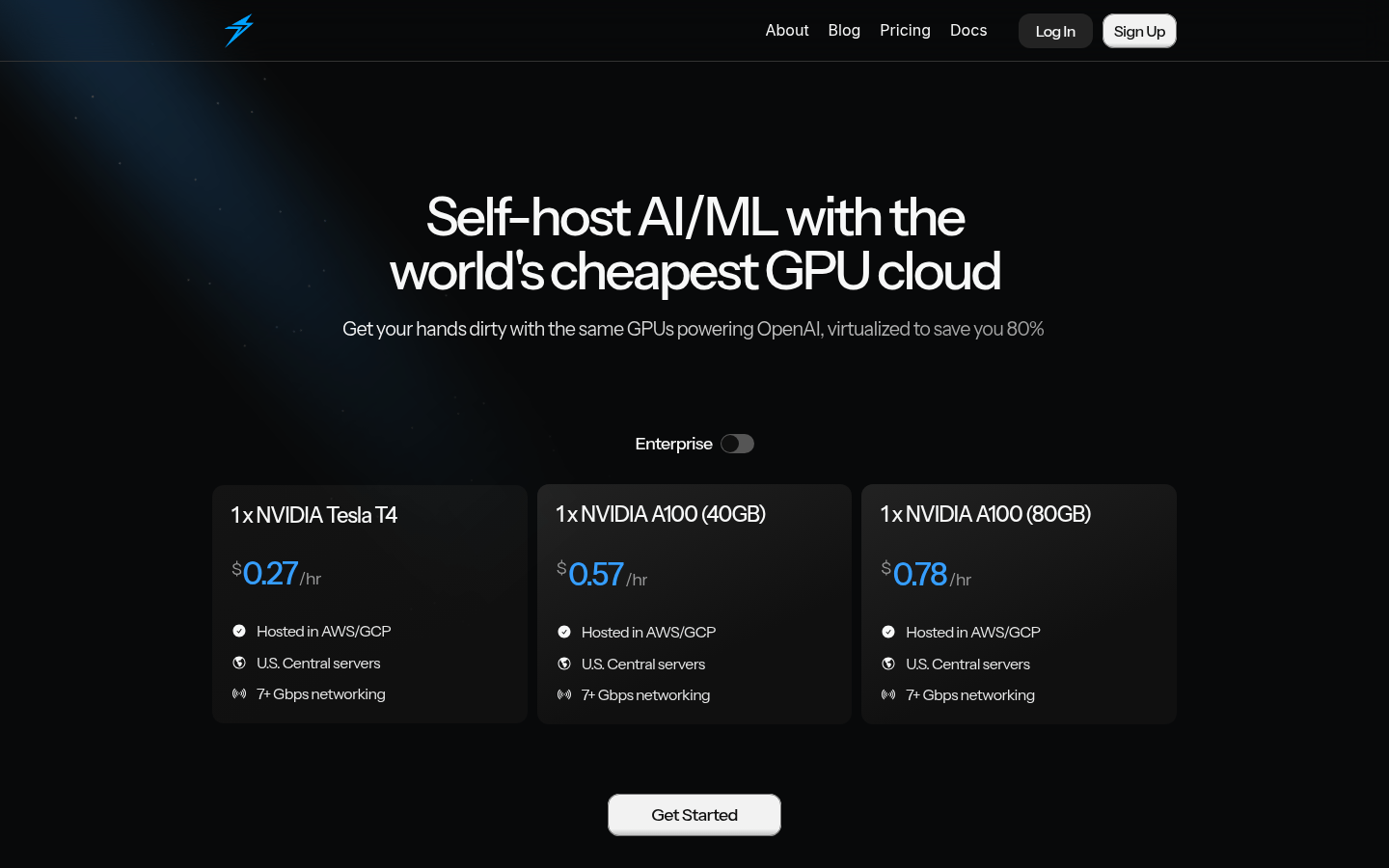
Thunder Compute是一个专注于AI/ML开发的GPU云服务平台,通过虚拟化技术,帮助用户以极低的成本使用高性能GPU资源。其主要优点是价格低廉,相比传统云服务提供商可节省高达80%的成本。该平台支持多种主流GPU型号,如NVIDIA Tesla T4、A100等,并提供7+ Gbps的网络连接,确保数据传输的高效性。Thunder Compute的目标是为AI开发者和企业降低硬件成本,加速模型训练和部署,推动AI技术的普及和应用。
TensorPool 是一个专注于简化机器学习模型训练的云 GPU 平台。它通过提供一个直观的命令行界面(CLI),帮助用户轻松描述任务并自动处理 GPU 的编排和执行。TensorPool 的核心技术包括智能的 Spot 节点恢复技术,能够在抢占式实例被中断时立即恢复作业,从而结合了抢占式实例的成本优势和按需实例的可靠性。此外,TensorPool 还通过实时多云分析选择最便宜的 GPU 选项,用户只需为实际执行时间付费,无需担心闲置机器带来的额外成本。TensorPool 的目标是让开发者无需花费大量时间配置云提供商,从而提高机器学习工程的速度和效率。它提供个人计划和企业计划,个人计划每周提供 $5 的免费信用额度,而企业计划则提供更高级的支持和功能。
MLGym是由Meta的GenAI团队和UCSB NLP团队开发的一个开源框架和基准,用于训练和评估AI研究代理。它通过提供多样化的AI研究任务,推动强化学习算法的发展,帮助研究人员在真实世界的研究场景中训练和评估模型。该框架支持多种任务,包括计算机视觉、自然语言处理和强化学习等领域,旨在为AI研究提供一个标准化的测试平台。
DeepEP 是一个专为混合专家模型(MoE)和专家并行(EP)设计的通信库。它提供了高吞吐量和低延迟的全连接 GPU 内核,支持低精度操作(如 FP8)。该库针对非对称域带宽转发进行了优化,适合训练和推理预填充任务。此外,它还支持流处理器(SM)数量控制,并引入了一种基于钩子的通信-计算重叠方法,不占用任何 SM 资源。DeepEP 的实现虽然与 DeepSeek-V3 论文略有差异,但其优化的内核和低延迟设计使其在大规模分布式训练和推理任务中表现出色。
FlexHeadFA 是一个基于 FlashAttention 的改进模型,专注于提供快速且内存高效的精确注意力机制。它支持灵活的头维度配置,能够显著提升大语言模型的性能和效率。该模型的主要优点包括高效利用 GPU 资源、支持多种头维度配置以及与 FlashAttention-2 和 FlashAttention-3 兼容。它适用于需要高效计算和内存优化的深度学习场景,尤其在处理长序列数据时表现出色。
FlashMLA 是一个针对 Hopper GPU 优化的高效 MLA 解码内核,专为变长序列服务设计。它基于 CUDA 12.3 及以上版本开发,支持 PyTorch 2.0 及以上版本。FlashMLA 的主要优势在于其高效的内存访问和计算性能,能够在 H800 SXM5 上实现高达 3000 GB/s 的内存带宽和 580 TFLOPS 的计算性能。该技术对于需要大规模并行计算和高效内存管理的深度学习任务具有重要意义,尤其是在自然语言处理和计算机视觉领域。FlashMLA 的开发灵感来源于 FlashAttention 2&3 和 cutlass 项目,旨在为研究人员和开发者提供一个高效的计算工具。
The Ultra-Scale Playbook 是一个基于 Hugging Face Spaces 提供的模型工具,专注于超大规模系统的优化和设计。它利用先进的技术框架,帮助开发者和企业高效地构建和管理大规模系统。该工具的主要优点包括高度的可扩展性、优化的性能和易于集成的特性。它适用于需要处理复杂数据和大规模计算任务的场景,如人工智能、机器学习和大数据处理。产品目前以开源的形式提供,适合各种规模的企业和开发者使用。
Crawl4LLM是一个开源的网络爬虫项目,旨在为大型语言模型(LLM)的预训练提供高效的数据爬取解决方案。它通过智能选择和爬取网页数据,帮助研究人员和开发者获取高质量的训练语料。该工具支持多种文档评分方法,能够根据配置灵活调整爬取策略,以满足不同的预训练需求。项目基于Python开发,具有良好的扩展性和易用性,适合在学术研究和工业应用中使用。
KET-RAG(Knowledge-Enhanced Text Retrieval Augmented Generation)是一个强大的检索增强型生成框架,结合了知识图谱技术。它通过多粒度索引框架(如知识图谱骨架和文本-关键词二分图)实现高效的知识检索和生成。该框架在降低索引成本的同时,显著提升了检索和生成质量,适用于大规模 RAG 应用场景。KET-RAG 基于 Python 开发,支持灵活的配置和扩展,适用于需要高效知识检索和生成的开发人员和研究人员。
Goedel-Prover 是一款专注于自动化定理证明的开源大型语言模型。它通过将自然语言数学问题翻译为形式化语言(如 Lean 4),并生成形式化证明,显著提升了数学问题的自动化证明效率。该模型在 miniF2F 基准测试中达到了 57.6% 的成功率,超越了其他开源模型。其主要优点包括高性能、开源可扩展性以及对数学问题的深度理解能力。Goedel-Prover 旨在推动自动化定理证明技术的发展,并为数学研究和教育提供强大的工具支持。
LangGraph Multi-Agent Supervisor是一个基于LangGraph框架构建的Python库,用于创建分层多智能体系统。它允许开发者通过一个中心化的监督智能体来协调多个专业智能体,实现任务的动态分配和通信管理。该技术的重要性在于其能够高效地组织复杂的多智能体任务,提升系统的灵活性和可扩展性。它适用于需要多智能体协作的场景,如自动化任务处理、复杂问题解决等。该产品定位为高级开发者和企业级应用,目前未明确公开价格,但其开源特性使得用户可以根据自身需求进行定制和扩展。
Huginn-0125是一个由马里兰大学帕克分校Tom Goldstein实验室开发的潜变量循环深度模型。该模型拥有35亿参数,经过8000亿个token的训练,在推理和代码生成方面表现出色。其核心特点是通过循环深度结构在测试时动态调整计算量,能够根据任务需求灵活增加或减少计算步骤,从而在保持性能的同时优化资源利用。该模型基于开源的Hugging Face平台发布,支持社区共享和协作,用户可以自由下载、使用和进一步开发。其开源性和灵活的架构使其成为研究和开发中的重要工具,尤其是在资源受限或需要高性能推理的场景中。
该产品是一个用于大规模深度循环语言模型的预训练代码库,基于Python开发。它在AMD GPU架构上进行了优化,能够在4096个AMD GPU上高效运行。该技术的核心优势在于其深度循环架构,能够有效提升模型的推理能力和效率。它主要用于研究和开发高性能的自然语言处理模型,特别是在需要大规模计算资源的场景中。该代码库开源且基于Apache-2.0许可证,适合学术研究和工业应用。
Steev 是一款专为 AI 模型训练设计的工具,旨在简化训练流程,提升模型性能。它通过自动优化训练参数、实时监控训练过程,并提供代码审查和建议,帮助用户更高效地完成模型训练。Steev 的主要优点是无需配置即可使用,适合希望提高模型训练效率和质量的工程师和研究人员。目前处于免费试用阶段,用户可以免费体验其全部功能。
Kolosal AI 是一款用于本地设备训练和运行大型语言模型(LLMs)的工具。它通过简化模型训练、优化和部署流程,使用户能够在本地设备上高效地使用 AI 技术。该工具支持多种硬件平台,提供快速的推理速度和灵活的定制能力,适合从个人开发者到大型企业的广泛应用场景。其开源特性也使得用户可以根据自身需求进行二次开发。
RAG-FiT是一个强大的工具,旨在通过检索增强生成(RAG)技术提升大型语言模型(LLMs)的能力。它通过创建专门的RAG增强数据集,帮助模型更好地利用外部信息。该库支持从数据准备到模型训练、推理和评估的全流程操作。其主要优点包括模块化设计、可定制化工作流以及对多种RAG配置的支持。RAG-FiT基于开源许可,适合研究人员和开发者进行快速原型开发和实验。
MNN 是阿里巴巴淘系技术开源的深度学习推理引擎,支持 TensorFlow、Caffe、ONNX 等主流模型格式,兼容 CNN、RNN、GAN 等常用网络。它通过极致优化算子性能,全面支持 CPU、GPU、NPU,充分发挥设备算力,广泛应用于阿里巴巴 70+ 场景下的 AI 应用。MNN 以高性能、易用性和通用性著称,旨在降低 AI 部署门槛,推动端智能的发展。
LLaSA_training 是一个基于 LLaMA 的语音合成训练项目,旨在通过优化训练时间和推理时间的计算资源,提升语音合成模型的效率和性能。该项目利用开源数据集和内部数据集进行训练,支持多种配置和训练方式,具有较高的灵活性和可扩展性。其主要优点包括高效的数据处理能力、强大的语音合成效果以及对多种语言的支持。该项目适用于需要高性能语音合成解决方案的研究人员和开发者,可用于开发智能语音助手、语音播报系统等应用场景。
Dolphin R1是一个由Cognitive Computations团队创建的数据集,旨在训练类似DeepSeek-R1 Distill模型的推理模型。该数据集包含30万条来自DeepSeek-R1的推理样本、30万条来自Gemini 2.0 flash thinking的推理样本以及20万条Dolphin聊天样本。这些数据集的组合为研究人员和开发者提供了丰富的训练资源,有助于提升模型的推理能力和对话能力。该数据集的创建得到了Dria、Chutes、Crusoe Cloud等多家公司的赞助支持,这些赞助商为数据集的开发提供了计算资源和资金支持。Dolphin R1数据集的发布,为自然语言处理领域的研究和开发提供了重要的基础,推动了相关技术的发展。
DeepSeek-R1-Distill-Qwen-7B 是一个经过强化学习优化的推理模型,基于 Qwen-7B 进行了蒸馏优化。它在数学、代码和推理任务上表现出色,能够生成高质量的推理链和解决方案。该模型通过大规模强化学习和数据蒸馏技术,显著提升了推理能力和效率,适用于需要复杂推理和逻辑分析的场景。
Kimi k1.5 是由 MoonshotAI 开发的多模态语言模型,通过强化学习和长上下文扩展技术,显著提升了模型在复杂推理任务中的表现。该模型在多个基准测试中达到了行业领先水平,例如在 AIME 和 MATH-500 等数学推理任务中超越了 GPT-4o 和 Claude Sonnet 3.5。其主要优点包括高效的训练框架、强大的多模态推理能力以及对长上下文的支持。Kimi k1.5 主要面向需要复杂推理和逻辑分析的应用场景,如编程辅助、数学解题和代码生成等。
RLLoggingBoard 是一个专注于强化学习人类反馈(RLHF)训练过程可视化的工具。它通过细粒度的指标监控,帮助研究人员和开发者直观理解训练过程,快速定位问题,并优化训练效果。该工具支持多种可视化模块,包括奖励曲线、响应排序和 token 级别指标等,旨在辅助现有的训练框架,提升训练效率和效果。它适用于任何支持保存所需指标的训练框架,具有高度的灵活性和可扩展性。
OpenLIT是一个开源的AI工程平台,专注于生成式AI和大型语言模型(LLM)应用的可观察性。它通过提供代码透明度、隐私保护、性能可视化等功能,帮助开发者简化AI开发流程,提高开发效率和应用性能。作为开源项目,用户可以自由查看代码或自行托管,确保数据安全和隐私。其主要优点包括易于集成、支持OpenTelemetry原生集成、提供细粒度的使用洞察等。OpenLIT面向AI开发者、数据科学家和企业,旨在帮助他们更好地构建、优化和管理AI应用。目前未明确具体价格,但从开源特性来看,可能对基础功能提供免费使用。
MiniRAG是一个针对小型语言模型设计的检索增强生成系统,旨在简化RAG流程并提高效率。它通过语义感知的异构图索引机制和轻量级的拓扑增强检索方法,解决了小型模型在传统RAG框架中性能受限的问题。该模型在资源受限的场景下具有显著优势,如在移动设备或边缘计算环境中。MiniRAG的开源特性也使其易于被开发者社区接受和改进。
AutoGen v0.4是微软研究院推出的一款代理型AI模型,旨在通过其异步、事件驱动的架构,改善代码质量、鲁棒性、通用性和可伸缩性。该模型通过社区反馈进行了全面重构,以支持更广泛的代理场景,包括多代理协作、分布式计算和跨语言支持等。AutoGen v0.4的发布为代理型AI应用和研究奠定了坚实基础,推动了AI技术在多个领域的应用和发展。
PocketFlow是一个极简的LLM框架,仅用100行代码实现,旨在让LLM能够自主编程。它强调高级编程范式,去除低级实现细节,使LLM能专注于重要部分。该框架可作为LLM的学习资源,因其简洁性,易于理解和上手。它采用嵌套有向图的核心抽象,将任务分解为多个LLM步骤,支持分支和递归决策。PocketFlow是开源项目,采用MIT许可证,具有高度的灵活性和可扩展性。
Bakery是一个专注于开源AI模型的微调与变现的在线平台,为AI初创企业、机器学习工程师和研究人员提供了一个便捷的工具,使他们能够轻松地对AI模型进行微调,并在市场中进行变现。该平台的主要优点在于其简单易用的界面和强大的功能,用户可以快速创建或上传数据集,微调模型设置,并在市场中进行变现。Bakery的背景信息表明,它旨在推动开源AI技术的发展,并为开发者提供更多的商业机会。虽然具体的定价信息未在页面中明确展示,但其定位是为AI领域的专业人士提供一个高效的工具。
NVIDIA Project DIGITS 是一款基于 NVIDIA GB10 Grace Blackwell 超级芯片的桌面超级计算机,旨在为 AI 开发者提供强大的 AI 性能。它能够在功耗高效、紧凑的形态中提供每秒一千万亿次的 AI 性能。该产品预装了 NVIDIA AI 软件栈,并配备了 128GB 的内存,使开发者能够在本地原型设计、微调和推理高达 2000 亿参数的大型 AI 模型,并无缝部署到数据中心或云中。Project DIGITS 的推出标志着 NVIDIA 在推动 AI 开发和创新方面的又一重要里程碑,为开发者提供了一个强大的工具,以加速 AI 模型的开发和部署。
NVIDIA Cosmos是一个先进的世界基础模型平台,旨在加速物理AI系统的开发,如自动驾驶车辆和机器人。它提供了一系列预训练的生成模型、高级分词器和加速数据处理管道,使开发者能够更容易地构建和优化物理AI应用。Cosmos通过其开放的模型许可,降低了开发成本,提高了开发效率,适用于各种规模的企业和研究机构。
FlashInfer是一个专为大型语言模型(LLM)服务而设计的高性能GPU内核库。它通过提供高效的稀疏/密集注意力机制、负载平衡调度、内存效率优化等功能,显著提升了LLM在推理和部署时的性能。FlashInfer支持PyTorch、TVM和C++ API,易于集成到现有项目中。其主要优点包括高效的内核实现、灵活的自定义能力和广泛的兼容性。FlashInfer的开发背景是为了满足日益增长的LLM应用需求,提供更高效、更可靠的推理支持。
PRIME-RL/Eurus-2-7B-PRIME是一个基于PRIME方法训练的7B参数的语言模型,旨在通过在线强化学习提升语言模型的推理能力。该模型从Eurus-2-7B-SFT开始训练,利用Eurus-2-RL-Data数据集进行强化学习。PRIME方法通过隐式奖励机制,使模型在生成过程中更加注重推理过程,而不仅仅是结果。该模型在多项推理基准测试中表现出色,相较于其SFT版本平均提升了16.7%。其主要优点包括高效的推理能力提升、较低的数据和模型资源需求,以及在数学和编程任务中的优异表现。该模型适用于需要复杂推理能力的场景,如编程问题解答和数学问题求解。
Eurus-2-7B-SFT是基于Qwen2.5-Math-7B模型进行微调的大型语言模型,专注于数学推理和问题解决能力的提升。该模型通过模仿学习(监督微调)的方式,学习推理模式,能够有效解决复杂的数学问题和编程任务。其主要优点在于强大的推理能力和对数学问题的准确处理,适用于需要复杂逻辑推理的场景。该模型由PRIME-RL团队开发,旨在通过隐式奖励的方式提升模型的推理能力。
llmstxt-generator 是一个用于生成LLM(大型语言模型)训练和推理所需的网站内容整合文本文件的工具。它通过爬取网站内容,将其合并成一个文本文件,支持生成标准的llms.txt和完整的llms-full.txt版本。该工具由firecrawl_dev提供支持进行网页爬取,并使用GPT-4-mini进行文本处理。其主要优点包括无需API密钥即可使用基本功能,同时提供Web界面和API访问,方便用户快速生成所需的文本文件。
EurusPRM-Stage2是一个先进的强化学习模型,通过隐式过程奖励来优化生成模型的推理过程。该模型利用因果语言模型的对数似然比来计算过程奖励,从而在不增加额外标注成本的情况下提升模型的推理能力。其主要优点在于能够在仅使用响应级标签的情况下,隐式地学习到过程奖励,从而提高生成模型的准确性和可靠性。该模型在数学问题解答等任务中表现出色,适用于需要复杂推理和决策的场景。
EurusPRM-Stage1是PRIME-RL项目的一部分,旨在通过隐式过程奖励来增强生成模型的推理能力。该模型利用隐式过程奖励机制,无需额外标注过程标签,即可在推理过程中获得过程奖励。其主要优点是能够有效地提升生成模型在复杂任务中的表现,同时降低了标注成本。该模型适用于需要复杂推理和生成能力的场景,如数学问题解答、自然语言生成等。
PRIME是一个开源的在线强化学习解决方案,通过隐式过程奖励来增强语言模型的推理能力。该技术的主要优点在于能够在不依赖显式过程标签的情况下,有效地提供密集的奖励信号,从而加速模型的训练和推理能力的提升。PRIME在数学竞赛基准测试中表现出色,超越了现有的大型语言模型。其背景信息包括由多个研究者共同开发,并在GitHub上发布了相关代码和数据集。PRIME的定位是为需要复杂推理任务的用户提供强大的模型支持。
Llama-3-Patronus-Lynx-8B-Instruct是由Patronus AI开发的一个基于meta-llama/Meta-Llama-3-8B-Instruct模型的微调版本,主要用于检测在RAG设置中的幻觉。该模型训练于包含CovidQA、PubmedQA、DROP、RAGTruth等多个数据集,包含人工标注和合成数据。它能够评估给定文档、问题和答案是否忠实于文档内容,不提供文档之外的新信息,也不与文档信息相矛盾。
Patronus-Lynx-8B-Instruct-v1.1是基于meta-llama/Meta-Llama-3.1-8B-Instruct模型的微调版本,主要用于检测RAG设置中的幻觉。该模型经过CovidQA、PubmedQA、DROP、RAGTruth等多个数据集的训练,包含人工标注和合成数据。它能够评估给定文档、问题和答案是否忠实于文档内容,不提供超出文档范围的新信息,也不与文档信息相矛盾。
Orchestra是一个用于创建AI驱动的任务管道和多代理团队的框架。它允许开发者和企业构建复杂的工作流程,通过集成不同的AI模型和工具来自动化任务处理。Orchestra的背景信息显示,它由Mainframe开发,旨在提供一个强大的平台,以支持AI技术的集成和应用。产品的主要优点包括其灵活性和可扩展性,能够适应不同的业务需求和场景。目前,Orchestra提供免费试用,具体的价格和定位信息需要进一步查询。
DRT-o1是一个神经机器翻译模型,它通过长思考链的方式优化翻译过程。该模型通过挖掘含有比喻或隐喻的英文句子,并采用多代理框架(包括翻译者、顾问和评估者)来合成长思考的机器翻译样本。DRT-o1-7B和DRT-o1-14B是基于Qwen2.5-7B-Instruct和Qwen2.5-14B-Instruct训练的大型语言模型。DRT-o1的主要优点在于其能够处理复杂的语言结构和深层次的语义理解,这对于提高机器翻译的准确性和自然性至关重要。
PromptWizard是由微软开发的一个任务感知型提示优化框架,它通过自我演化机制,使得大型语言模型(LLM)能够生成、批评和完善自己的提示和示例,通过迭代反馈和综合不断改进。这个自适应方法通过进化指令和上下文学习示例来全面优化,以提高任务性能。该框架的三个关键组件包括:反馈驱动的优化、批评和合成多样化示例、自生成的思考链(Chain of Thought, CoT)步骤。PromptWizard的重要性在于它能够显著提升LLM在特定任务上的表现,通过优化提示和示例来增强模型的性能和解释性。
LiteMCP是一个TypeScript框架,用于优雅地构建MCP(Model Context Protocol)服务器。它支持简单的工具、资源、提示定义,提供完整的TypeScript支持,并内置了错误处理和CLI工具,方便测试和调试。LiteMCP的出现为开发者提供了一个高效、易用的平台,用于开发和部署MCP服务器,从而推动了人工智能和机器学习模型的交互和协作。LiteMCP是开源的,遵循MIT许可证,适合希望快速构建和部署MCP服务器的开发者和企业使用。
Unitree RL GYM是一个基于Unitree机器人的强化学习平台,支持Unitree Go2、H1、H1_2、G1等型号。该平台提供了一个集成环境,允许研究人员和开发者训练和测试强化学习算法在真实或模拟的机器人上的表现。它的重要性在于推动机器人自主性和智能技术的发展,特别是在需要复杂决策和运动控制的应用中。Unitree RL GYM是开源的,可以免费使用,主要面向科研人员和机器人爱好者。
CohereForAI/c4ai-command-r7b-12-2024是一个7B参数的多语言模型,专注于推理、总结、问答和代码生成等高级任务。该模型支持检索增强生成(RAG)和工具使用,能够使用和组合多个工具来完成更复杂的任务。它在企业相关的代码用例上表现优异,支持23种语言。
ReFT是一个开源的研究项目,旨在通过深度强化学习技术对大型语言模型进行微调,以提高其在特定任务上的表现。该项目提供了详细的代码和数据,以便研究人员和开发者能够复现论文中的结果。ReFT的主要优点包括能够利用强化学习自动调整模型参数,以及通过微调提高模型在特定任务上的性能。产品背景信息显示,ReFT基于Codellama和Galactica模型,遵循Apache2.0许可证。
O1-CODER是一个旨在复现OpenAI的O1模型的项目,专注于编程任务。该项目结合了强化学习(RL)和蒙特卡洛树搜索(MCTS)技术,以增强模型的系统二型思考能力,目标是生成更高效、逻辑性更强的代码。这个项目对于提升编程效率和代码质量具有重要意义,尤其是在需要大量自动化测试和代码优化的场景中。
PrimeIntellect-ai/prime是一个用于在互联网上高效、全球分布式训练AI模型的框架。它通过技术创新,实现了跨地域的AI模型训练,提高了计算资源的利用率,降低了训练成本,对于需要大规模计算资源的AI研究和应用开发具有重要意义。
OLMo-2-1124-13B-DPO是经过监督微调和DPO训练的13B参数大型语言模型,主要针对英文,旨在提供在聊天、数学、GSM8K和IFEval等多种任务上的卓越性能。该模型是OLMo系列的一部分,旨在推动语言模型的科学研究。模型训练基于Dolma数据集,并公开代码、检查点、日志和训练细节。
DOLMino dataset mix for OLMo2 stage 2 annealing training是一个混合了多种高质数据的数据集,用于在OLMo2模型训练的第二阶段。这个数据集包含了网页页面、STEM论文、百科全书等多种类型的数据,旨在提升模型在文本生成任务中的表现。它的重要性在于为开发更智能、更准确的自然语言处理模型提供了丰富的训练资源。
Learning to Fly (L2F) 是一个开源项目,旨在通过深度强化学习训练端到端控制策略,并能够在消费级笔记本电脑上快速完成训练。该项目的主要优点是训练速度快,能够在几秒钟内完成,并且训练出的策略具有良好的泛化能力,可以直接部署到真实的四旋翼飞行器上。L2F项目依赖于RLtools深度强化学习库,并且提供了详细的安装和部署指南,使得研究人员和开发者能够快速上手并进行实验。
Star-Attention是NVIDIA提出的一种新型块稀疏注意力机制,旨在提高基于Transformer的大型语言模型(LLM)在长序列上的推理效率。该技术通过两个阶段的操作显著提高了推理速度,同时保持了95-100%的准确率。它与大多数基于Transformer的LLM兼容,无需额外训练或微调即可直接使用,并且可以与其他优化方法如Flash Attention和KV缓存压缩技术结合使用,进一步提升性能。
Qwen2.5-Coder是Qwen大型语言模型的最新系列,专注于代码生成、代码推理和代码修复。基于强大的Qwen2.5,该系列模型通过增加训练令牌至5.5万亿,包括源代码、文本代码基础、合成数据等,显著提升了编码能力。Qwen2.5-Coder-32B已成为当前最先进的开源代码大型语言模型,编码能力与GPT-4o相当。此外,Qwen2.5-Coder还为实际应用如代码代理提供了更全面的基础,不仅增强了编码能力,还保持了在数学和通用能力方面的优势。
Qwen2.5-Coder-3B是Qwen2.5-Coder系列中的一个大型语言模型,专注于代码生成、推理和修复。基于强大的Qwen2.5,该模型通过增加训练令牌至5.5万亿,包括源代码、文本代码基础、合成数据等,实现了在代码生成、推理和修复方面的显著改进。Qwen2.5-Coder-32B已成为当前最先进的开源代码大型语言模型,其编码能力与GPT-4o相匹配。此外,Qwen2.5-Coder-3B还为现实世界的应用提供了更全面的基础,如代码代理,不仅增强了编码能力,还保持了在数学和通用能力方面的优势。
Qwen2.5-Coder-7B-Instruct是Qwen2.5-Coder系列中的一款代码特定大型语言模型,覆盖了0.5、1.5、3、7、14、32亿参数的六种主流模型尺寸,以满足不同开发者的需求。该模型在代码生成、代码推理和代码修复方面有显著提升,基于强大的Qwen2.5,训练令牌扩展到5.5万亿,包括源代码、文本代码基础、合成数据等。Qwen2.5-Coder-32B已成为当前最先进的开源代码LLM,其编码能力与GPT-4o相匹配。此外,该模型还支持长达128K令牌的长上下文,并为实际应用如代码代理提供了更全面的基础。
Qwen2.5-Coder系列是基于Qwen2.5架构的代码特定模型,包括Qwen2.5-Coder-1.5B和Qwen2.5-Coder-7B两个模型。这些模型在超过5.5万亿个token的大规模语料库上继续预训练,并通过精细的数据清洗、可扩展的合成数据生成和平衡的数据混合,展现出令人印象深刻的代码生成能力,同时保持了通用性。Qwen2.5-Coder在包括代码生成、补全、推理和修复在内的多种代码相关任务上取得了超过10个基准测试的最新性能,并且一致性地超越了同等大小的更大模型。该系列的发布不仅推动了代码智能研究的边界,而且通过其许可授权,鼓励开发者在现实世界的应用中更广泛地采用。
Qwen2.5-Coder-14B是Qwen系列中专注于代码的大型语言模型,覆盖了0.5到32亿参数的不同模型尺寸,以满足不同开发者的需求。该模型在代码生成、代码推理和代码修复方面有显著提升,基于强大的Qwen2.5,训练令牌扩展到5.5万亿,包括源代码、文本代码接地、合成数据等。Qwen2.5-Coder-32B已成为当前最先进的开源代码LLM,其编码能力与GPT-4o相匹配。此外,它还为现实世界应用如代码代理提供了更全面的基础,不仅增强了编码能力,还保持了在数学和通用能力方面的优势。支持长达128K令牌的长上下文。
Qwen2.5-Coder-14B-Instruct是Qwen2.5-Coder系列中的一个大型语言模型,专注于代码生成、代码推理和代码修复。基于强大的Qwen2.5,该模型通过扩展训练令牌到5.5万亿,包括源代码、文本代码接地、合成数据等,成为当前开源代码LLM的最新技术。它不仅增强了编码能力,还保持了在数学和通用能力方面的优势,并支持长达128K令牌的长上下文。
Qwen2.5-Coder-32B是基于Qwen2.5的代码生成模型,拥有32亿参数,是目前开源代码语言模型中参数最多的模型之一。它在代码生成、代码推理和代码修复方面有显著提升,能够处理长达128K tokens的长文本,适用于代码代理等实际应用场景。该模型在数学和通用能力上也保持了优势,支持长文本处理,是开发者在进行代码开发时的强大助手。
Qwen2.5-Coder是一系列专为代码生成设计的Qwen大型语言模型,包含0.5、1.5、3、7、14、32亿参数的六种主流模型尺寸,以满足不同开发者的需求。该模型在代码生成、代码推理和代码修复方面有显著提升,基于强大的Qwen2.5,训练令牌扩展到5.5万亿,包括源代码、文本代码基础、合成数据等。Qwen2.5-Coder-32B是目前最先进的开源代码生成大型语言模型,其编码能力与GPT-4o相匹配。它不仅增强了编码能力,还保持了在数学和通用能力方面的优势,并支持长达128K令牌的长上下文。
Lamatic.ai是一个为构建、测试和部署高性能GenAI应用在边缘而设计的管理型PaaS平台,提供低代码可视化构建器、VectorDB和集成应用及模型。它通过集成多种工具和技术,帮助AI创始人和构建者快速实现复杂的AI工作流程。平台的主要优点包括减少团队间的来回沟通、自动化工作流程、提高部署速度和降低延迟。Lamatic.ai的背景信息显示,它是由一群对GenAI应用开发有着深刻理解和丰富经验的工程师和社区成员共同打造的。平台的价格定位是包含所有可用的管理集成、向量数据库、托管、边缘部署和SDK的月度订阅服务,同时提供按小时计费的专业服务。
O1-Journey是由上海交通大学GAIR研究组发起的一个项目,旨在复制和重新想象OpenAI的O1模型的能力。该项目提出了“旅程学习”的新训练范式,并构建了首个成功整合搜索和学习在数学推理中的模型。这个模型通过试错、纠正、回溯和反思等过程,成为处理复杂推理任务的有效方法。
hertz-dev是Standard Intelligence开源的全双工、仅音频的变换器基础模型,拥有85亿参数。该模型代表了可扩展的跨模态学习技术,能够将单声道16kHz语音转换为8Hz潜在表示,具有1kbps的比特率,性能优于其他音频编码器。hertz-dev的主要优点包括低延迟、高效率和易于研究人员进行微调和构建。产品背景信息显示,Standard Intelligence致力于构建对全人类有益的通用智能,而hertz-dev是这一旅程的第一步。
ManiSkill是一个领先的开源平台,专注于机器人模拟、无限机器人数据生成和泛化机器人AI。由HillBot.ai领导,该平台支持通过状态和/或视觉输入快速训练机器人,与其它平台相比,ManiSkill/SAPIEN实现了10-100倍的视觉数据收集速度。它支持在GPU上并行模拟和渲染RGB-D,速度高达30,000+FPS。ManiSkill提供了40多种技能/任务和2000多个对象的预构建任务,拥有数百万帧的演示和密集的奖励函数,用户无需自己收集资产或设计任务,可以专注于算法开发。此外,它还支持在每个并行环境中同时模拟不同的对象和关节,训练泛化机器人策略/AI的时间从天缩短到分钟。ManiSkill易于使用,可以通过pip安装,并提供简单灵活的GUI以及所有功能的广泛文档。
xAI API提供了对Grok系列基础模型的程序化访问,支持文本和图像输入,具有128,000个token的上下文长度,并支持函数调用和系统提示。该API与OpenAI和Anthropic的API完全兼容,简化了迁移过程。产品背景信息显示,xAI正在进行公共Beta测试,直至2024年底,期间每位用户每月可获得25美元的免费API积分。
SELA是一个创新系统,它通过将蒙特卡洛树搜索(MCTS)与基于大型语言模型(LLM)的代理结合起来,增强了自动化机器学习(AutoML)。传统的AutoML方法经常产生低多样性和次优的代码,限制了它们在模型选择和集成方面的有效性。SELA通过将管道配置表示为树,使代理能够智能地探索解决方案空间,并根据实验反馈迭代改进其策略。
Laminar是一个开源的全栈平台,专注于从第一性原理出发进行AI工程。它帮助用户收集、理解和使用数据,以提高大型语言模型(LLM)应用的质量。Laminar支持对文本和图像模型的追踪,并且即将支持音频模型。产品的主要优点包括零开销的可观测性、在线评估、数据集构建和LLM链管理。Laminar完全开源,易于自托管,适合需要构建和管理LLM产品的开发者和团队。
HOVER是一个针对人形机器人的多功能神经全身控制器,它通过模仿全身运动来提供通用的运动技能,学习多种全身控制模式。HOVER通过多模式策略蒸馏框架将不同的控制模式整合到一个统一的策略中,实现了在不同控制模式之间的无缝切换,同时保留了每种模式的独特优势。这种控制器提高了人形机器人在多种模式下的控制效率和灵活性,为未来的机器人应用提供了一个健壮且可扩展的解决方案。
Dabarqus是一个Retrieval Augmented Generation(RAG)框架,它允许用户将私有数据实时提供给大型语言模型(LLM)。这个工具通过提供REST API、SDKs和CLI工具,使得用户能够轻松地将各种数据源(如PDF、电子邮件和原始数据)存储到语义索引中,称为“记忆库”。Dabarqus支持LLM风格的提示,使用户能够以简单的方式与记忆库进行交互,而无需构建特殊的查询或学习新的查询语言。此外,Dabarqus还支持多语义索引(记忆库)的创建和使用,使得数据可以根据主题、类别或其他分组方式进行组织。Dabarqus的产品背景信息显示,它旨在简化私有数据与AI语言模型的集成过程,提高数据检索的效率和准确性。
ROCKET-1是一个视觉-语言模型(VLMs),专门针对开放世界环境中的具身决策制定而设计。该模型通过视觉-时间上下文提示协议,将VLMs与策略模型之间的通信连接起来,利用来自过去和当前观察的对象分割来指导策略-环境交互。ROCKET-1通过这种方式,能够解锁VLMs的视觉-语言推理能力,使其能够解决复杂的创造性任务,尤其是在空间理解方面。ROCKET-1在Minecraft中的实验表明,该方法使代理能够完成以前无法实现的任务,突出了视觉-时间上下文提示在具身决策制定中的有效性。
Aya Expanse是一个由CohereForAI开发的Hugging Face Space,它可能涉及到机器学习模型的开发和应用。Hugging Face是一个专注于自然语言处理的人工智能平台,提供各种模型和工具,以帮助开发者构建、训练和部署NLP应用。Aya Expanse作为该平台上的一个Space,可能具有特定的功能或技术,用于支持开发者在NLP领域的工作。
Agibot X1是由Agibot开发的模块化仿人机器人,具有高自由度,基于Agibot开源框架AimRT作为中间件,并使用强化学习进行运动控制。该项目包括模型推理、平台驱动和软件仿真等多个功能模块。AimRT框架是一个用于机器人应用开发的开源框架,它提供了一套完整的工具和库,以支持机器人的感知、决策和行动。Agibot X1项目的重要性在于它为机器人研究和教育提供了一个高度可定制和可扩展的平台。
GitHub to LLM Converter是一个在线工具,旨在帮助用户将GitHub上的项目、文件或文件夹链接转换成适合大型语言模型(LLM)处理的格式。这一工具对于需要处理大量代码或文档数据的开发者和研究人员来说至关重要,因为它简化了数据准备过程,使得这些数据可以被更高效地用于机器学习或自然语言处理任务。该工具由Skirano开发,提供了一个简洁的用户界面,用户只需输入GitHub链接,即可一键转换,极大地提高了工作效率。
AgileCoder是一个创新的多智能体软件开发框架,灵感来源于专业软件工程中广泛使用的敏捷方法论。该框架的关键在于其任务导向的方法,而不是给智能体分配固定角色,AgileCoder通过创建任务积压和将开发过程划分为冲刺,模仿现实世界的软件开发,每个冲刺都会动态更新积压。AgileCoder支持多种模型,包括OpenAI、Azure OpenAI、Anthropic以及自托管的Ollama模型。
Playnode是一个基于网页的AI工作流构建平台,它允许用户通过拖拽的方式创建和部署AI模型,支持多种AI模型和数据流的组合,以实现复杂的数据处理和分析任务。该平台的主要优点是其可视化操作界面,使得即使是非技术用户也能轻松上手,快速构建和部署AI工作流。Playnode的背景信息显示,它旨在降低AI技术的门槛,让更多人能够利用AI技术解决实际问题。目前,Playnode提供免费试用,用户可以开始免费使用并获得每周20个积分,无需信用卡信息。
Janus是一个创新的自回归框架,通过将视觉编码分离成不同的路径,同时利用单一的、统一的变换器架构进行处理,解决了以往方法的局限性。这种解耦不仅减轻了视觉编码器在理解和生成中的角色冲突,还增强了框架的灵活性。Janus的性能超越了以往的统一模型,并且达到了或超过了特定任务模型的性能。Janus的简单性、高灵活性和有效性使其成为下一代统一多模态模型的强有力候选。
BitNet是由微软开发的官方推理框架,专为1位大型语言模型(LLMs)设计。它提供了一套优化的核心,支持在CPU上进行快速且无损的1.58位模型推理(NPU和GPU支持即将推出)。BitNet在ARM CPU上实现了1.37倍到5.07倍的速度提升,能效比提高了55.4%到70.0%。在x86 CPU上,速度提升范围从2.37倍到6.17倍,能效比提高了71.9%到82.2%。此外,BitNet能够在单个CPU上运行100B参数的BitNet b1.58模型,实现接近人类阅读速度的推理速度,拓宽了在本地设备上运行大型语言模型的可能性。
MetaGPT是一个多智能体框架,它通过自然语言编程技术,能够模拟一个完整的软件公司团队,从而实现快速开发和自动化工作流程。它代表了人工智能在软件开发领域的最新进展,能够显著提高开发效率,降低成本。MetaGPT的主要优点包括高度自动化、多智能体协作、以及能够处理复杂的软件开发任务。产品背景信息显示,MetaGPT旨在通过AI技术,为用户提供一个能够快速响应开发需求的平台。目前,产品似乎处于测试阶段,用户可以通过加入等待列表来体验产品。
Meta Lingua 是一个轻量级、高效的大型语言模型(LLM)训练和推理库,专为研究而设计。它使用了易于修改的PyTorch组件,使得研究人员可以尝试新的架构、损失函数和数据集。该库旨在实现端到端的训练、推理和评估,并提供工具以更好地理解模型的速度和稳定性。尽管Meta Lingua目前仍在开发中,但已经提供了多个示例应用来展示如何使用这个代码库。
TEN-framework是一个创新的AI代理框架,旨在提供实时多模态交互的高性能支持。它支持多种语言和平台,实现了边缘-云集成,并能够灵活地超越单一模型的限制。TEN-framework通过实时管理代理状态,使得AI代理能够动态响应并实时调整行为。该框架的背景是满足日益增长的复杂AI应用需求,特别是在音频-视觉场景中。它不仅提供了高效的开发支持,还通过模块化和可重用扩展的方式,促进了AI技术的创新和应用。
FastAgency是一个面向开发者和企业用户的AI模型构建和部署平台,它通过提供易用的界面和强大的后端支持,使得用户能够快速地开发和部署AI模型,从而加速产品从概念到市场的转化过程。该平台的主要优点包括快速迭代、高效率和易于集成,适合需要快速响应市场变化的企业和开发者。
Velvet AI gateway是一个为工程师设计的AI请求仓库解决方案,它允许用户将OpenAI和Anthropic的请求存储到PostgreSQL数据库中,并通过日志分析、评估和生成数据集来优化AI功能。产品的主要优点包括易用性、成本优化、数据透明性和支持自定义查询。Velvet AI gateway的背景是帮助创新团队更有效地管理和利用AI技术,通过减少成本和提高效率来增强产品的竞争力。
Llama3-s v0.2 是 Homebrew Computer Company 开发的多模态检查点,专注于提升语音理解能力。该模型通过早期融合语义标记的方式,利用社区反馈进行改进,以简化模型结构,提高压缩效率,并实现一致的语音特征提取。Llama3-s v0.2 在多个语音理解基准测试中表现稳定,并提供了实时演示,允许用户亲自体验其功能。尽管模型仍在早期开发阶段,存在一些限制,如对音频压缩敏感、无法处理超过10秒的音频等,但团队计划在未来更新中解决这些问题。
Helicone AI是一个为开发者设计的开源平台,专注于日志记录、监控和调试。它具备毫秒级延迟影响、100%日志覆盖率和行业领先的查询时间,是为生产级工作负载设计的。平台通过Cloudflare Workers实现低延迟和高可靠性,并支持风险无忧的实验,无需安装SDK,仅需添加头部信息即可访问所有功能。
Evidently AI是一个开源的Python库,用于监控机器学习模型,支持从RAGs到AI助手的LLM驱动产品的评估。它提供了数据漂移、数据质量和生产ML模型性能的监控,拥有超过2000万的下载量和5000+的GitHub星标,是机器学习领域中一个值得信赖的监控工具。
Moonglow是一个允许用户在远程GPU上运行本地Jupyter笔记本的服务,无需管理SSH密钥、软件包安装等DevOps问题。该服务由Leila和Trevor创立,Leila曾在Jane Street构建高性能基础设施,而Trevor在斯坦福的Hazy Research Lab进行机器学习研究。
Not Diamond 是一款强大的AI模型路由器,专为开发者设计,能够根据任务需求智能选择最合适的AI模型,以实现成本和延迟的显著降低。它支持开箱即用,也可以通过训练自定义路由器来优化模型路由,以适应特定用例。产品具备快速选择模型的能力,支持联合提示优化,无需手动调整和实验即可为每个大型语言模型(LM)编程最佳提示。
MInference 1.0 是一种稀疏计算方法,旨在加速长序列处理的预填充阶段。它通过识别长上下文注意力矩阵中的三种独特模式,实现了对长上下文大型语言模型(LLMs)的动态稀疏注意力方法,加速了1M token提示的预填充阶段,同时保持了LLMs的能力,尤其是检索能力。
prompteasy.ai是一个在线平台,允许用户通过简单的聊天方式对GPT模型进行微调,无需具备任何技术技能。平台的目标是让AI更加智能,易于任何人访问和使用。目前,该服务在v1版本发布期间对所有用户免费。
vLLM是一个为大型语言模型(LLM)推理和提供服务的快速、易用且高效的库。它通过使用最新的服务吞吐量技术、高效的内存管理、连续批处理请求、CUDA/HIP图快速模型执行、量化技术、优化的CUDA内核等,提供了高性能的推理服务。vLLM支持与流行的HuggingFace模型无缝集成,支持多种解码算法,包括并行采样、束搜索等,支持张量并行性,适用于分布式推理,支持流式输出,并兼容OpenAI API服务器。此外,vLLM还支持NVIDIA和AMD GPU,以及实验性的前缀缓存和多lora支持。
探索 编程 分类下的其他子分类
768 个工具
465 个工具
368 个工具
294 个工具
85 个工具
66 个工具
61 个工具
模型训练与部署 是 编程 分类下的热门子分类,包含 140 个优质AI工具