找到 54 个相关的AI工具
BrainHost VPS是一个可靠的VPS托管平台,提供高性能虚拟服务器和先进管理功能。其基于KVM虚拟化和NVMe存储,性能可靠。全球覆盖,采用多线路BGP和智能路由,确保低延迟访问。使用VirtFusion面板,操作便捷,支持灵活扩展。价格方面,不同套餐价格不同,如Nano套餐8美元/月起,适合企业和个人用户。
12306 MCP Server 是一个基于 Model Context Protocol (MCP) 的高性能火车票查询后端系统,提供实时余票查询、车站信息和换乘方案等功能,适合与 AI / 自动化助手集成。该系统的主要优点在于其快速响应和易于集成,支持的标准化接口使其成为一个强大的数据聚合工具,适用于需要高效查询火车票的场景。该产品免费开源,适合开发者和企业使用。
Skywork-OR1是由昆仑万维天工团队开发的高性能数学代码推理模型。该模型系列在同等参数规模下实现了业界领先的推理性能,突破了大模型在逻辑理解与复杂任务求解方面的能力瓶颈。Skywork-OR1系列包括Skywork-OR1-Math-7B、Skywork-OR1-7B-Preview和Skywork-OR1-32B-Preview三款模型,分别聚焦数学推理、通用推理和高性能推理任务。此次开源不仅涵盖模型权重,还全面开放了训练数据集和完整训练代码,所有资源均已上传至GitHub和Huggingface平台,为AI社区提供了完全可复现的实践参考。这种全方位的开源策略有助于推动整个AI社区在推理能力研究上的共同进步。
Gemma 3 是 Google 推出的最新开源模型,基于 Gemini 2.0 的研究和技术开发。它是一个轻量级、高性能的模型,能够在单个 GPU 或 TPU 上运行,为开发者提供强大的 AI 能力。Gemma 3 提供多种尺寸(1B、4B、12B 和 27B),支持超过 140 种语言,并具备先进的文本和视觉推理能力。其主要优点包括高性能、低计算需求以及广泛的多语言支持,适合在各种设备上快速部署 AI 应用。Gemma 3 的推出旨在推动 AI 技术的普及和创新,帮助开发者在不同硬件平台上实现高效开发。
Instella 是由 AMD GenAI 团队开发的一系列高性能开源语言模型,基于 AMD Instinct™ MI300X GPU 训练而成。该模型在性能上显著优于同尺寸的其他开源语言模型,并且在功能上与 Llama-3.2-3B 和 Qwen2.5-3B 等模型相媲美。Instella 提供模型权重、训练代码和训练数据,旨在推动开源语言模型的发展。其主要优点包括高性能、开源开放以及对 AMD 硬件的优化支持。
Framework Desktop 是一款革命性的迷你型桌面电脑,专为高性能计算、AI 模型运行和游戏设计。它采用 AMD Ryzen™ AI Max 300 系列处理器,具备强大的多任务处理能力和图形性能。产品体积小巧(仅 4.5L),支持标准 PC 零部件,用户可以轻松 DIY 组装和升级。其设计注重可持续性,使用了回收材料,并支持 Linux 等多种操作系统,适合追求高性能和环保的用户。
Smallpond 是一个高性能的数据处理框架,专为大规模数据处理而设计。它基于 DuckDB 和 3FS 构建,能够高效处理 PB 级数据集,无需长时间运行的服务。Smallpond 提供了简单易用的 API,支持 Python 3.8 至 3.12,适合数据科学家和工程师快速开发和部署数据处理任务。其开源特性使得开发者可以自由定制和扩展功能。
Mercury Coder 是 Inception Labs 推出的首款商用级扩散大语言模型(dLLM),专为代码生成优化。该模型采用扩散模型技术,通过‘粗到细’的生成方式,显著提升生成速度和质量。其速度比传统自回归语言模型快 5-10 倍,能够在 NVIDIA H100 硬件上达到每秒 1000 多个 token 的生成速度,同时保持高质量的代码生成能力。该技术的背景是当前自回归语言模型在生成速度和推理成本上的瓶颈,而 Mercury Coder 通过算法优化突破了这一限制,为企业级应用提供了更高效、低成本的解决方案。
DualPipe是一种创新的双向流水线并行算法,由DeepSeek-AI团队开发。该算法通过优化计算与通信的重叠,显著减少了流水线气泡,提高了训练效率。它在大规模分布式训练中表现出色,尤其适用于需要高效并行化的深度学习任务。DualPipe基于PyTorch开发,易于集成和扩展,适合需要高性能计算的开发者和研究人员使用。
GeForce RTX 5070 Ti是NVIDIA推出的高性能显卡,采用最新的Blackwell架构,支持DLSS 4多帧生成技术。该显卡能够为游戏玩家提供极致的图形性能,支持全光追游戏体验,同时在内容创作领域也能显著提升AI生成和视频导出的速度。其强大的性能使其成为追求高帧率和高质量图形体验的用户的理想选择。
iPhone 16e 是苹果公司推出的最新款 iPhone,定位为价格亲民的高性能智能手机。它搭载了最新的 A18 芯片,提供强大的性能支持,同时配备了 48MP 融合相机,能够拍摄高分辨率照片和高质量视频。iPhone 16e 还支持 Apple Intelligence 技术,为用户提供更智能的交互体验。其设计坚固耐用,采用航空级铝材和 Ceramic Shield 陶瓷盾,具备良好的抗摔和防水性能。此外,它还支持 5G 网络和卫星通信功能,确保用户在任何环境下都能保持连接。iPhone 16e 的定位是为用户提供一款性价比极高的智能手机,适合日常使用和多种场景。
PaliGemma 2 mix 是 Google 推出的升级版视觉语言模型,属于 Gemma 家族。它能够处理多种视觉和语言任务,如图像分割、视频字幕生成、科学问题回答等。该模型提供不同大小的预训练检查点(3B、10B 和 28B 参数),可轻松微调以适应各种视觉语言任务。其主要优点是多功能性、高性能和开发者友好性,支持多种框架(如 Hugging Face Transformers、Keras、PyTorch 等)。该模型适用于需要高效处理视觉和语言任务的开发者和研究人员,能够显著提升开发效率。
FireRedASR-AED-L 是一个开源的工业级自动语音识别模型,专为满足高效率和高性能的语音识别需求而设计。该模型采用基于注意力的编码器-解码器架构,支持普通话、中文方言和英语等多种语言。它在公共普通话语音识别基准测试中达到了新的最高水平,并且在歌唱歌词识别方面表现出色。该模型的主要优点包括高性能、低延迟和广泛的适用性,适用于各种语音交互场景。其开源特性使得开发者可以自由地使用和修改代码,进一步推动语音识别技术的发展。
Webdone是一款基于AI的网站和落地页生成工具,旨在帮助用户快速创建和发布高质量的网页。它通过AI技术自动生成布局和设计,支持Next.js框架,能够快速搭建高性能的网页。其主要优点包括无需编码技能、快速生成页面、高度可定制化以及优化的SEO性能。Webdone适合独立开发者、初创企业和需要快速搭建网页的用户,提供从免费试用到付费高级功能的多种选择。
MNN 是阿里巴巴淘系技术开源的深度学习推理引擎,支持 TensorFlow、Caffe、ONNX 等主流模型格式,兼容 CNN、RNN、GAN 等常用网络。它通过极致优化算子性能,全面支持 CPU、GPU、NPU,充分发挥设备算力,广泛应用于阿里巴巴 70+ 场景下的 AI 应用。MNN 以高性能、易用性和通用性著称,旨在降低 AI 部署门槛,推动端智能的发展。
Gemini 2.0 是谷歌在生成式 AI 领域的重要进展,代表了最新的人工智能技术。它通过强大的语言生成能力,为开发者提供高效、灵活的解决方案,适用于多种复杂场景。Gemini 2.0 的主要优点包括高性能、低延迟和简化的定价策略,旨在降低开发成本并提高生产效率。该模型通过 Google AI Studio 和 Vertex AI 提供,支持多种模态输入,具备广泛的应用前景。
Gemini Pro 是 Google DeepMind 推出的最先进 AI 模型之一,专为复杂任务和编程场景设计。它在代码生成、复杂指令理解和多模态交互方面表现出色,支持文本、图像、视频和音频输入。Gemini Pro 提供强大的工具调用能力,如 Google 搜索和代码执行,能够处理长达 200 万字的上下文信息,适合需要高性能 AI 支持的专业用户和开发者。
DeepClaude是一个强大的AI工具,旨在将DeepSeek R1的推理能力与Claude的创造力和代码生成能力相结合,通过统一的API和聊天界面提供服务。它利用高性能的流式API(用Rust编写)实现即时响应,同时支持端到端加密和本地API密钥管理,确保用户数据的隐私和安全。该产品是完全开源的,用户可以自由贡献、修改和部署。其主要优点包括零延迟响应、高度可配置性以及支持用户自带密钥(BYOK),为开发者提供了极大的灵活性和控制权。DeepClaude主要面向需要高效代码生成和AI推理能力的开发者和企业,目前处于免费试用阶段,未来可能会根据使用量收费。
Galaxy S25 是三星最新推出的智能手机,代表了当前智能手机技术的前沿水平。它搭载了定制的骁龙 8 Elite for Galaxy 处理器,性能强劲,能够满足用户在日常使用、游戏和多任务处理中的各种需求。该设备还配备了先进的 AI 技术,如 Galaxy AI 功能,支持通过自然语言完成多种任务,提升用户体验。Galaxy S25 提供多种颜色选择,设计时尚,坚固耐用,支持 IP68 级别防水防尘,适合追求高性能和智能化体验的用户。
DeepSeek-R1-Distill-Qwen-32B 是由 DeepSeek 团队开发的高性能语言模型,基于 Qwen-2.5 系列进行蒸馏优化。该模型在多项基准测试中表现出色,尤其是在数学、代码和推理任务上。其主要优点包括高效的推理能力、强大的多语言支持以及开源特性,便于研究人员和开发者进行二次开发和应用。该模型适用于需要高性能文本生成的场景,如智能客服、内容创作和代码辅助等,具有广泛的应用前景。
NVIDIA® GeForce RTX™ 5090由NVIDIA Blackwell架构驱动,配备32 GB超快GDDR7内存,为游戏玩家和创作者提供前所未有的AI性能。它支持全射线追踪和最低延迟的游戏体验,能够应对最先进的模型和最具挑战性的创意工作负载。
FlexRAG是一个用于检索增强生成(RAG)任务的灵活且高性能的框架。它支持多模态数据、无缝配置管理和开箱即用的性能,适用于研究和原型开发。该框架使用Python编写,具有轻量级和高性能的特点,能够显著提高RAG工作流的速度和减少延迟。其主要优点包括支持多种数据类型、统一的配置管理以及易于集成和扩展。
YuLan-Mini是由中国人民大学AI Box团队开发的一款轻量级语言模型,具有2.4亿参数,尽管仅使用1.08T的预训练数据,但其性能可与使用更多数据训练的行业领先模型相媲美。该模型特别擅长数学和代码领域,为了促进可复现性,团队将开源相关的预训练资源。
ASUS NUC 14 Pro是一款AI赋能的迷你PC,专为满足日常计算需求而设计。它搭载了Intel® Core™ Ultra处理器、Arc™ GPU、Intel AI Boost (NPU)、vPro® Enterprise等功能,以及无需工具即可访问的机箱设计。这款迷你PC以其卓越的性能、全面的管理能力、AI能力、Wi-Fi感知技术、无线连接能力和定制化设计,成为现代商业、边缘计算和IoT应用的理想选择。
ASUS NUC 14 Pro AI是全球首款搭载英特尔®酷睿™Ultra处理器(系列2,原名'Lunar Lake')的迷你电脑,具备先进的AI能力,性能强大,设计紧凑(小于0.6L)。它拥有Copilot+按钮、Wi-Fi 7、蓝牙5.4、语音命令和指纹识别功能,结合安全启动技术,提供增强的安全性。这款革命性设备为迷你电脑创新树立了新的基准,为企业、娱乐和工业应用提供无与伦比的性能。
RWKV-6 Finch 7B World 3是一个开源的人工智能模型,拥有7B个参数,并且经过3.1万亿个多语言令牌的训练。该模型以其环保的设计理念和高性能而著称,旨在为全球用户提供高质量的开源AI模型,无论国籍、语言或经济状况如何。RWKV架构旨在减少对环境的影响,每令牌消耗的功率固定,与上下文长度无关。
Llama-3.1-Tulu-3-8B-RM是Tülu3模型家族的一部分,该家族以开源数据、代码和配方为特色,旨在为现代后训练技术提供全面指南。该模型专为聊天以外的多样化任务(如MATH、GSM8K和IFEval)提供最先进的性能。
OuteTTS-0.2-500M是基于Qwen-2.5-0.5B构建的文本到语音合成模型,它在更大的数据集上进行了训练,实现了在准确性、自然度、词汇量、声音克隆能力以及多语言支持方面的显著提升。该模型特别感谢Hugging Face提供的GPU资助,支持了模型的训练。
Qwen2.5-Turbo是阿里巴巴开发团队推出的一款能够处理超长文本的语言模型,它在Qwen2.5的基础上进行了优化,支持长达1M个token的上下文,相当于约100万英文单词或150万中文字符。该模型在1M-token Passkey Retrieval任务中实现了100%的准确率,并在RULER长文本评估基准测试中得分93.1,超越了GPT-4和GLM4-9B-1M。Qwen2.5-Turbo不仅在长文本处理上表现出色,还保持了短文本处理的高性能,且成本效益高,每1M个token的处理成本仅为0.3元。
全新MacBook Pro是苹果公司推出的高性能笔记本电脑,它搭载了苹果自家设计的M4系列芯片,包括M4、M4 Pro和M4 Max,提供了更快的处理速度和增强的功能。这款笔记本电脑专为Apple Intelligence设计,这是一个个人智能系统,它改变了用户在Mac上工作、沟通和表达自己的方式,同时保护了用户的隐私。MacBook Pro以其卓越的性能、长达24小时的电池寿命以及先进的12MP Center Stage摄像头等特性,成为了专业人士的首选工具。
Snapdragon 8 Elite Mobile Platform是高通公司推出的顶级移动平台,代表了骁龙创新的巅峰。该平台首次在移动路线图中引入了高通Oryon™ CPU,提供了前所未有的性能。它通过强大的处理能力、突破性的AI增强功能和一系列前所未有的移动创新,彻底改变了设备上的体验。高通Oryon CPU提供了惊人的速度和效率,增强并扩展了每一次交互。此外,该平台还通过设备上的AI,包括多模态Gen AI和个性化功能,能够支持语音、文本和图像提示,进一步提升了用户的非凡体验。
BabyAlpha Chat 是一款具有未来感的机器人模型,全身搭载12个高性能执行器,配合蔚蓝自研五层运动控制算法,使得其运动性能极其出众。最大前进速度可达每小时3.2公里,最大旋转速度可达每秒180度。BabyAlpha Chat 不仅是一个高科技玩具,也是教育和娱乐的完美结合,适合各个年龄段的用户。其价格亲民,起售价为4999元,并有特惠活动直降2000元,截止日期为11月16日。
Ministral-8B-Instruct-2410是由Mistral AI团队开发的一款大型语言模型,专为本地智能、设备端计算和边缘使用场景设计。该模型在类似的大小模型中表现优异,支持128k上下文窗口和交错滑动窗口注意力机制,能够在多语言和代码数据上进行训练,支持函数调用,词汇量达到131k。Ministral-8B-Instruct-2410模型在各种基准测试中表现出色,包括知识与常识、代码与数学以及多语言支持等方面。该模型在聊天/竞技场(gpt-4o判断)中的性能尤为突出,能够处理复杂的对话和任务。
新款 iPad mini 是一款超便携的设备,搭载了强大的 A17 Pro 芯片和支持 Apple Pencil Pro,提供了出色的性能和多功能性。它配备了8.3英寸Liquid Retina显示屏,拥有全天的电池续航能力,并预装了全新的iPadOS 18系统。这款新设备不仅性能出色,而且设计精美,提供了蓝色、紫色、星光色和深空灰四种颜色选择。iPad mini的起售价为499美元,提供了128GB的存储空间,是上一代产品的两倍,为用户带来了极高的性价比。
英特尔®酷睿™至尊200系列台式机处理器是首款面向台式机平台的AI PC处理器,为发烧友带来卓越的游戏体验和行业领先的计算性能,同时显著降低功耗。这些处理器拥有多达8个下一代性能核心(P-cores)和多达16个下一代能效核心(E-cores),与上一代相比,在多线程工作负载中性能提升高达14%。这些处理器是首款为发烧友配备神经处理单元(NPU)的台式机处理器,内置Xe GPU,支持最先进的媒体功能。
AMD Ryzen™ AI PRO 300系列处理器是专为企业用户设计的第三代商用AI移动处理器。它们通过集成的NPU提供高达50+ TOPS的AI处理能力,是市场上同类产品中性能最强的。这些处理器不仅能够处理日常的工作任务,还特别为满足商务环境中对AI计算能力的需求而设计,如实时字幕、语言翻译和高级AI图像生成等。它们基于4nm工艺制造,并采用创新的电源管理技术,能够提供理想的电池续航能力,非常适合需要在移动状态下保持高性能和生产力的商务人士。
MediaTek Dimensity 9400是联发科推出的新一代旗舰智能手机芯片,采用最新的Armv9.2架构和3nm工艺制程,提供卓越的性能和能效比。该芯片支持LPDDR5X内存和UFS 4.0存储,具备强大的AI处理能力,支持先进的摄影和显示技术,以及高速的5G和Wi-Fi 7连接。它代表了移动计算和通信技术的最新进展,为高端智能手机市场提供了强大的动力。
Inflection AI for Enterprise是一个围绕多亿级终端大型语言模型(LLM)构建的企业AI系统,允许企业完全拥有自己的智能。该系统的基础模型经过针对业务的微调,提供以人为中心、富有同理心的企业AI方法。Inflection 3.0使团队能够构建定制的、安全的、员工友好的AI应用程序,消除了开发障碍,加速了硬件测试和模型构建。此外,Inflection AI与Intel AI硬件和软件结合,使企业能够根据品牌、文化和业务需求定制AI解决方案,降低总体拥有成本(TCO)。
SiFive Intelligence XM系列是SiFive推出的高效能AI计算引擎,通过集成标量、向量和矩阵引擎,为计算密集型应用提供极高的性能功耗比。该系列继续SiFive的传统,提供高效的内存带宽,并通过开源SiFive Kernel Library来加速开发时间。
Falcon Mamba是由阿布扎比技术创新研究所(TII)发布的首个无需注意力机制的7B大规模模型。该模型在处理大型序列时,不受序列长度增加导致的计算和存储成本增加的限制,同时保持了与现有最先进模型相当的性能。
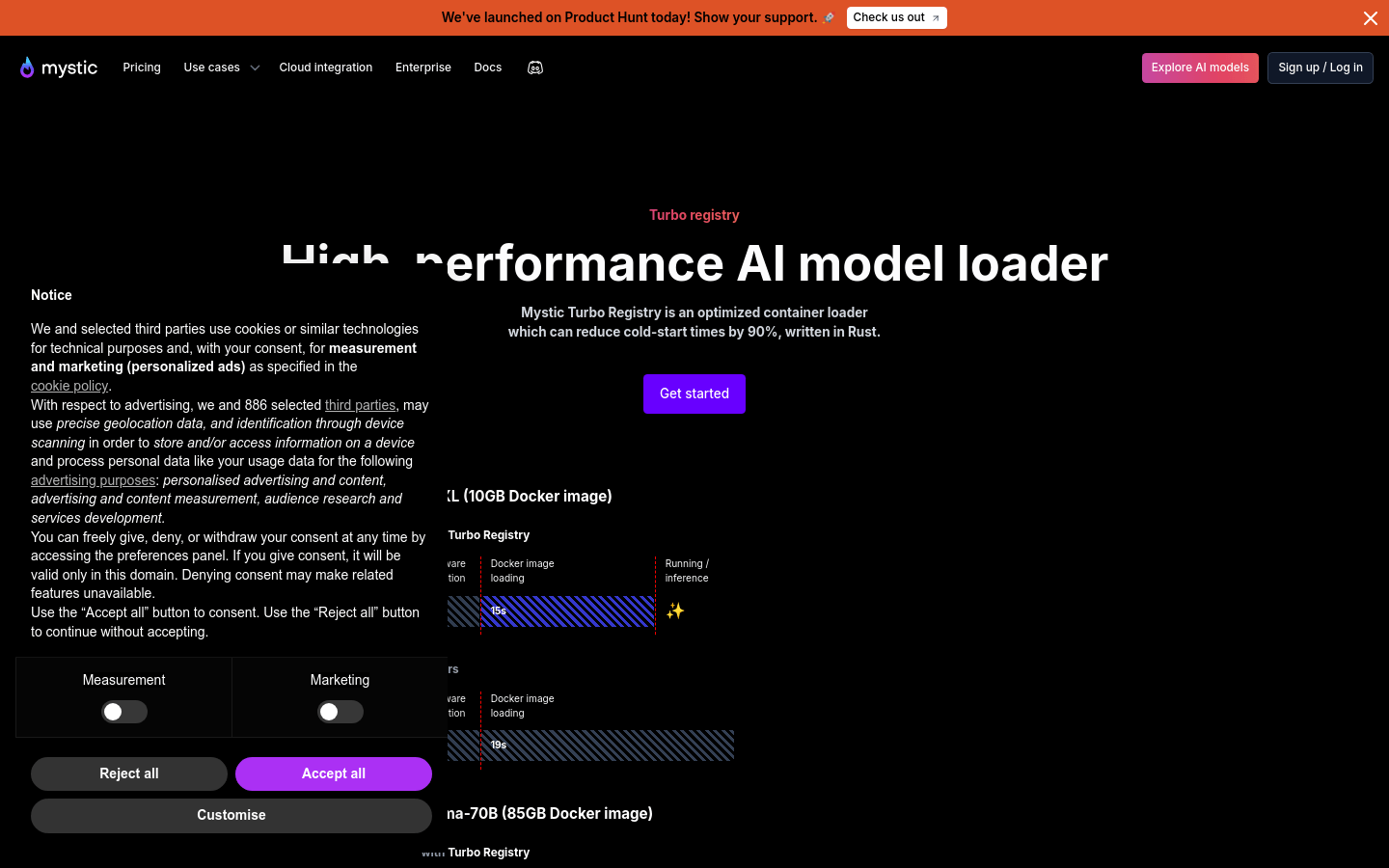
Mystic Turbo Registry是一款由Mystic.ai开发的高性能AI模型加载器,采用Rust语言编写,专门针对减少AI模型的冷启动时间进行了优化。它通过提高容器加载效率,显著减少了模型从启动到运行所需的时间,为用户提供了更快的模型响应速度和更高的运行效率。
RDFox 是由牛津大学计算机科学系的三位教授基于数十年知识表示与推理(KRR)研究开发的规则驱动人工智能技术。其独特之处在于:1. 强大的AI推理能力:RDFox 能够像人类一样从数据中创建知识,基于事实进行推理,确保结果的准确性和可解释性。2. 高性能:作为唯一在内存中运行的知识图谱,RDFox 在基准测试中的表现远超其他图技术,能够处理数十亿三元组的复杂数据存储。3. 可扩展部署:RDFox 具有极高的效率和优化的占用空间,可以嵌入边缘和移动设备,作为 AI 应用的大脑独立运行。4. 企业级特性:包括高性能、高可用性、访问控制、可解释性、人类般的推理能力、数据导入和 API 支持等。5. 增量推理:RDFox 的推理功能在数据添加或删除时即时更新,不影响性能,无需重新加载。
Mooncake是Kimi的服务平台,由Moonshot AI提供,是一个领先的大型语言模型(LLM)服务。它采用了以KVCache为中心的解耦架构,通过分离预填充(prefill)和解码(decoding)集群,以及利用GPU集群中未充分利用的CPU、DRAM和SSD资源来实现KVCache的解耦缓存。Mooncake的核心是其KVCache中心调度器,它在确保满足延迟相关的服务级别目标(SLOs)要求的同时,平衡最大化整体有效吞吐量。与传统研究不同,Mooncake面对的是高度过载的场景,为此开发了基于预测的早期拒绝策略。实验表明,Mooncake在长上下文场景中表现出色,与基线方法相比,在某些模拟场景中吞吐量可提高525%,同时遵守SLOs。在实际工作负载下,Mooncake的创新架构使Kimi能够处理75%以上的请求。
Gemma 2是谷歌DeepMind推出的下一代开源AI模型,提供9亿和27亿参数版本,具有卓越的性能和推理效率,支持在不同硬件上以全精度高效运行,大幅降低部署成本。Gemma 2在27亿参数版本中,提供了两倍于其大小模型的竞争力,并且可以在单个NVIDIA H100 Tensor Core GPU或TPU主机上实现,显著降低部署成本。
AQChatServer是一个接入AI的极速、便捷的匿名在线即时聊天室,基于Netty和protobuf协议实现高性能,对标游戏后端开发,全程无需HTTP协议,支持文本、图片、文件、音频、视频的发送和接收。
MiniCPM-Llama3-V 2.5 是 OpenBMB 项目中最新发布的端侧多模态大模型,具备8B参数量,支持超过30种语言的多模态交互,并在多模态综合性能上超越了多个商用闭源模型。该模型通过模型量化、CPU、NPU、编译优化等技术实现了高效的终端设备部署,具有优秀的OCR能力、可信行为以及多语言支持等特点。
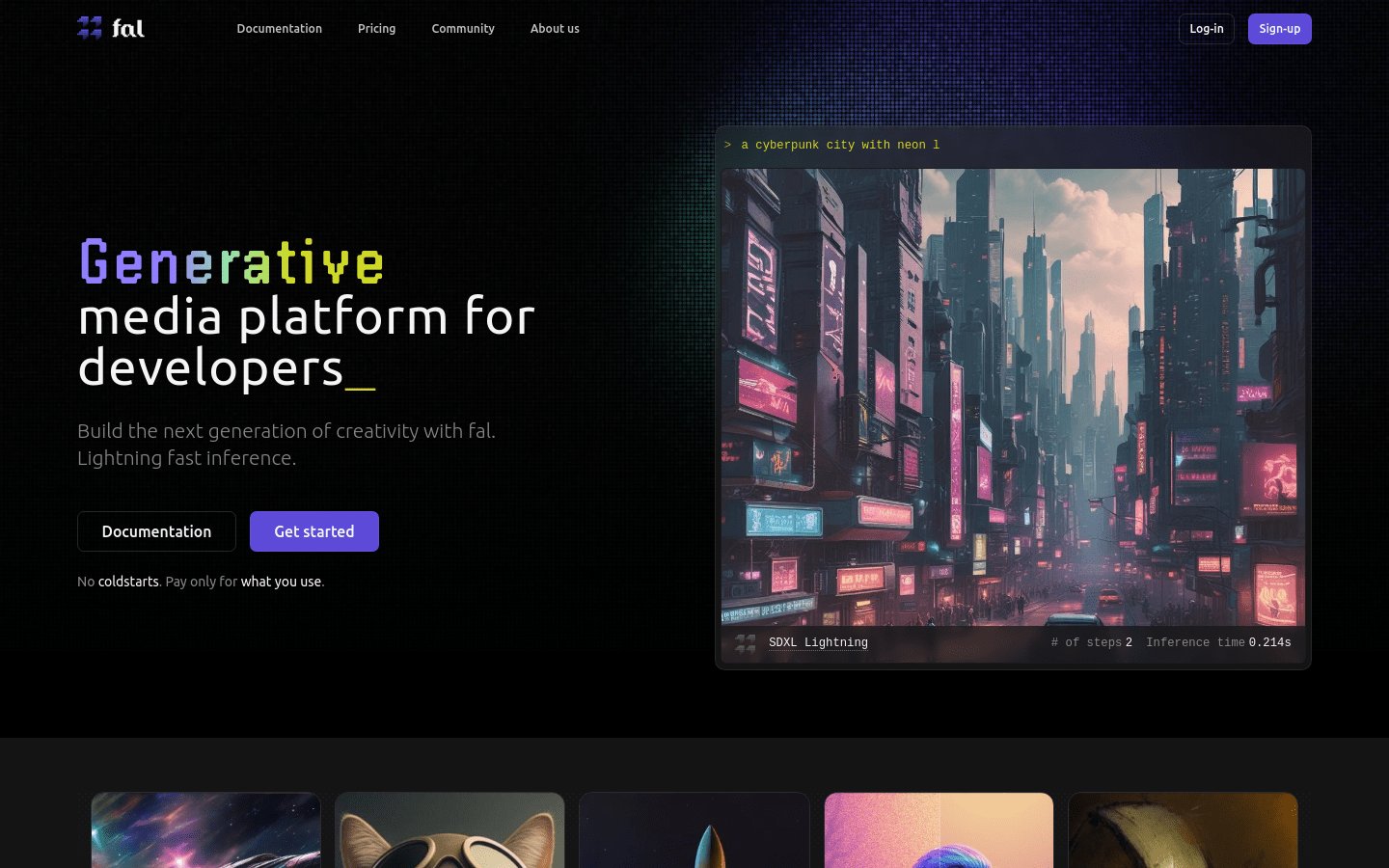
fal.ai 是一款面向开发者的生成媒体平台,提供了业界最快的推理引擎,可以让您以更低的成本运行扩散模型,创造出全新的用户体验。它拥有实时、无缝的 WebSocket 推理基础设施,为开发者带来了卓越的使用体验。fal.ai 的定价方案根据实际使用情况灵活调整,确保您只为消耗的计算资源付费,实现了最佳的可扩展性和经济性。
JetMoE-8B是一个开源的大型语言模型,通过使用公共数据集和优化的训练方法,以低于10万美元的成本实现了超越Meta AI LLaMA2-7B的性能。该模型在推理时仅激活22亿参数,大幅降低了计算成本,同时保持了优异的性能。
Jamba是一款基于SSM-Transformer混合架构的开放语言模型,提供顶级的质量和性能表现。它融合了Transformer和SSM架构的优势,在推理基准测试中表现出色,同时在长上下文场景下提供3倍的吞吐量提升。Jamba是目前该规模下唯一可在单GPU上支持14万字符上下文的模型,成本效益极高。作为基础模型,Jamba旨在供开发者微调、训练并构建定制化解决方案。
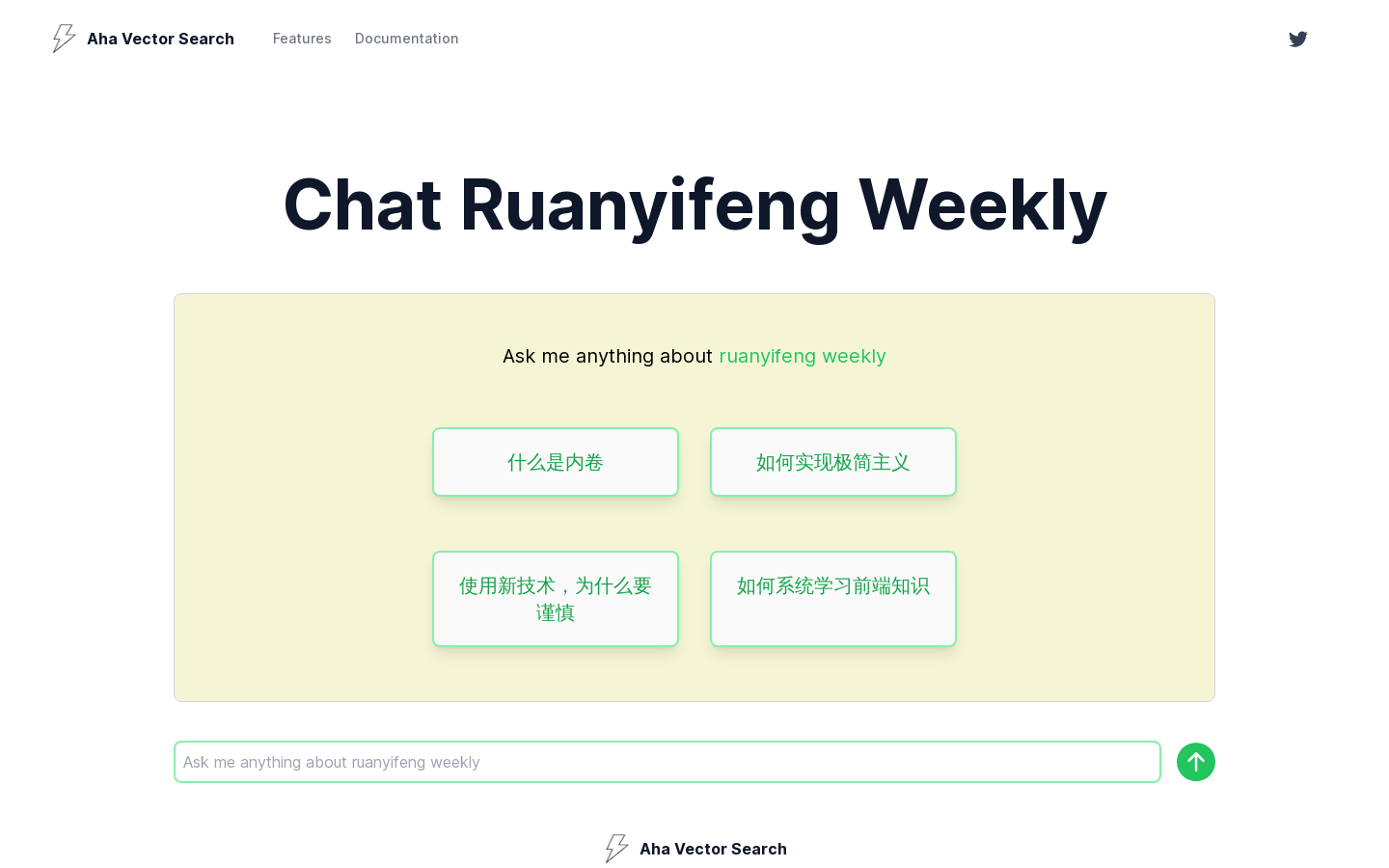
Aha Vector Search是一个高性能、低成本的端到端向量搜索服务。它提供了一种快速构建端到端向量搜索的方法,帮助用户以更低的成本实现高效的搜索体验。
CentML 是一个高效、节约成本的 AI 模型训练和部署平台。通过使用 CentML,您可以提升 GPU 效率、降低延迟、提高吞吐量,实现计算的高性价比和强大性能。
Apache HTTP Server是一个稳定可靠的开源Web服务器,具有高度可配置性和可扩展性。它支持多种操作系统和编程语言,提供了强大的功能和性能。Apache HTTP Server被广泛用于构建和托管网站,是Web开发的首选工具。它采用了模块化的架构,可以轻松地进行功能扩展和定制。Apache HTTP Server是免费的,适用于个人和商业用途。
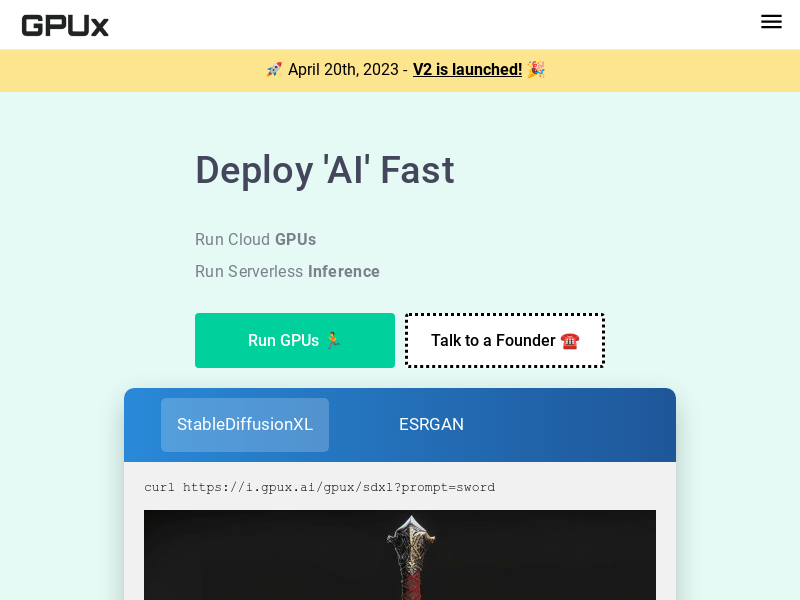
GPUX是一个快速运行云GPU的平台。它提供了高性能的GPU实例,用于运行机器学习工作负载。GPUX支持各种常见的机器学习任务,包括稳定扩散、Blender、Jupyter Notebook等。它还提供了稳定扩散SDXL0.9、Alpaca、LLM和Whisper等功能。GPUX还具有1秒冷启动时间、Shared Instance Storage和ReBar+P2P支持等优势。定价合理,定位于提供高性能GPU实例的云平台。
云服务器提供高性能的网站托管服务,具备灵活的配置选项和可靠的稳定性。优势包括强大的计算能力、高速的网络连接、可扩展的存储空间和灵活的安全性配置。价格根据配置选项和使用时长而定,适合个人用户和中小型企业使用。定位为提供可靠稳定的网站托管解决方案。