找到 60 个相关的AI工具
Level-Navi Agent是一个开源的通用网络搜索代理框架,能够将复杂问题分解并逐步搜索互联网上的信息,直至回答用户问题。它通过提供Web24数据集,覆盖金融、游戏、体育、电影和事件等五大领域,为评估模型在搜索任务上的表现提供了基准。该框架支持零样本和少样本学习,为大语言模型在中文网络搜索代理领域的应用提供了重要参考。
Signs 是一个由 NVIDIA 支持的创新平台,旨在通过人工智能技术帮助用户学习美国手语(ASL),并允许用户通过录制手语视频贡献数据,以构建全球最大的开放手语数据集。该平台利用 AI 实时反馈和 3D 动画技术,为初学者提供友好的学习体验,同时为手语社区提供数据支持,推动手语学习的普及和多样性。平台计划在 2025 年下半年公开数据集,以促进更多相关技术和服务的开发。
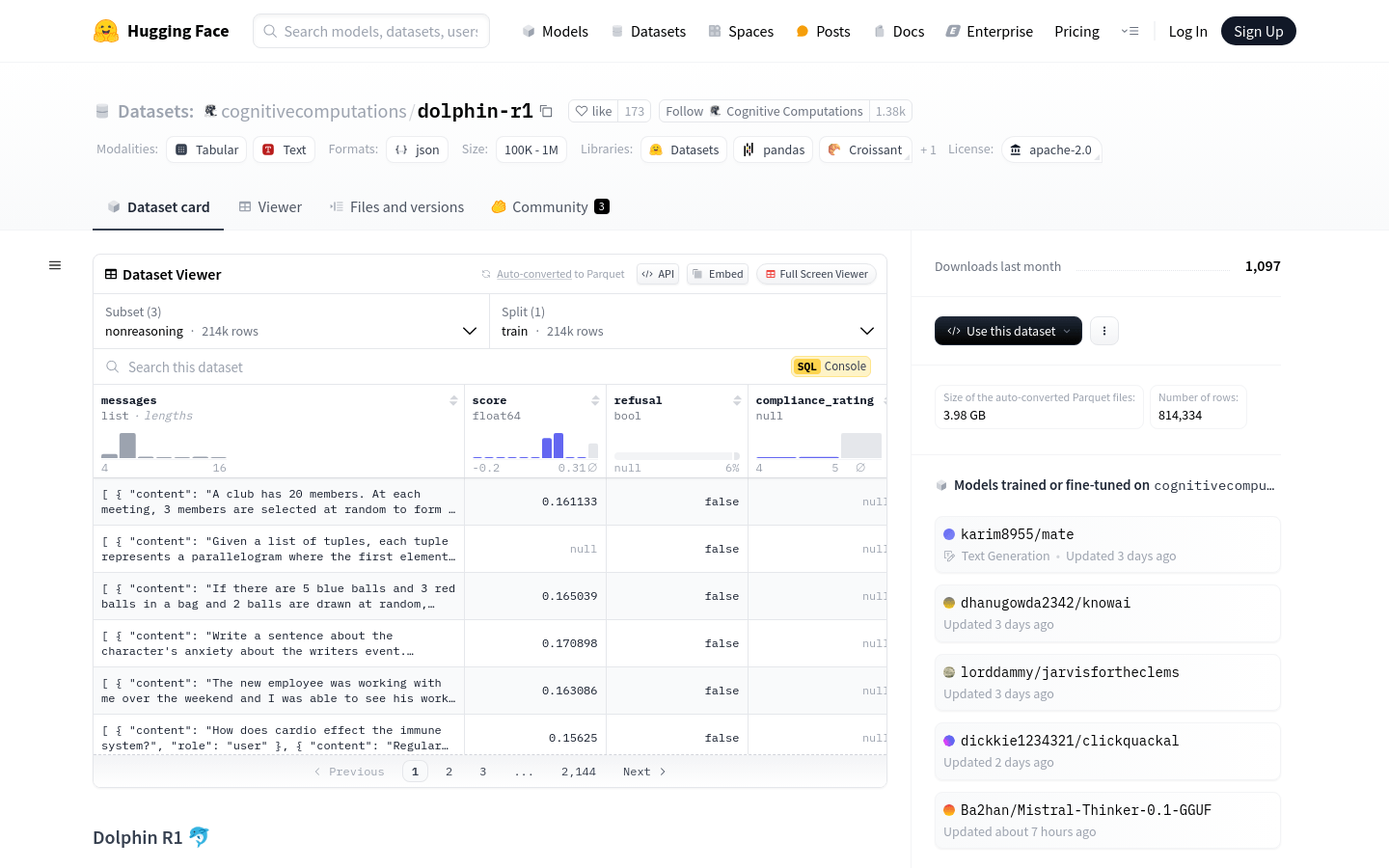
Dolphin R1是一个由Cognitive Computations团队创建的数据集,旨在训练类似DeepSeek-R1 Distill模型的推理模型。该数据集包含30万条来自DeepSeek-R1的推理样本、30万条来自Gemini 2.0 flash thinking的推理样本以及20万条Dolphin聊天样本。这些数据集的组合为研究人员和开发者提供了丰富的训练资源,有助于提升模型的推理能力和对话能力。该数据集的创建得到了Dria、Chutes、Crusoe Cloud等多家公司的赞助支持,这些赞助商为数据集的开发提供了计算资源和资金支持。Dolphin R1数据集的发布,为自然语言处理领域的研究和开发提供了重要的基础,推动了相关技术的发展。
Nemotron-CC是一个基于Common Crawl的6.3万亿token的数据集。它通过分类器集成、合成数据改写和减少启发式过滤器的依赖,将英文Common Crawl转化为一个6.3万亿token的长期预训练数据集,包含4.4万亿全球去重的原始token和1.9万亿合成生成的token。该数据集在准确性和数据量之间取得了更好的平衡,对于训练大型语言模型具有重要意义。
mlabonne/llm-datasets 是一个专注于大型语言模型(LLM)微调的高质量数据集和工具的集合。该产品为研究人员和开发者提供了一系列经过精心筛选和优化的数据集,帮助他们更好地训练和优化自己的语言模型。其主要优点在于数据集的多样性和高质量,能够覆盖多种使用场景,从而提高模型的泛化能力和准确性。此外,该产品还提供了一些工具和概念,帮助用户更好地理解和使用这些数据集。其背景信息包括由 mlabonne 创建和维护,旨在推动 LLM 领域的发展。
RLVR-GSM-MATH-IF-Mixed-Constraints数据集是一个专注于数学问题的数据集,它包含了多种类型的数学问题和相应的解答,用于训练和验证强化学习模型。这个数据集的重要性在于它能够帮助开发更智能的教育辅助工具,提高学生解决数学问题的能力。产品背景信息显示,该数据集由allenai在Hugging Face平台上发布,包含了GSM8k和MATH两个子集,以及带有可验证约束的IF Prompts,适用于MIT License和ODC-BY license。
MAmmoTH-VL是一个大规模多模态推理平台,它通过指令调优技术,显著提升了多模态大型语言模型(MLLMs)在多模态任务中的表现。该平台使用开放模型创建了一个包含1200万指令-响应对的数据集,覆盖了多样化的、推理密集型的任务,并提供了详细且忠实的理由。MAmmoTH-VL在MathVerse、MMMU-Pro和MuirBench等基准测试中取得了最先进的性能,展现了其在教育和研究领域的重要性。
FineWeb2是由Hugging Face提供的一个大规模多语言预训练数据集,覆盖超过1000种语言。该数据集经过精心设计,用于支持自然语言处理(NLP)模型的预训练和微调,特别是在多种语言上。它以其高质量、大规模和多样性而闻名,能够帮助模型学习跨语言的通用特征,提升在特定语言任务上的表现。FineWeb2在多个语言的预训练数据集中表现出色,甚至在某些情况下,比一些专门为单一语言设计的数据库表现更好。
OLMo 2 1124 13B Preference Mixture是一个由Hugging Face提供的大型多语言数据集,包含377.7k个生成对,用于训练和优化语言模型,特别是在偏好学习和指令遵循方面。该数据集的重要性在于它提供了一个多样化和大规模的数据环境,有助于开发更加精准和个性化的语言处理技术。
DOLMino dataset mix for OLMo2 stage 2 annealing training是一个混合了多种高质数据的数据集,用于在OLMo2模型训练的第二阶段。这个数据集包含了网页页面、STEM论文、百科全书等多种类型的数据,旨在提升模型在文本生成任务中的表现。它的重要性在于为开发更智能、更准确的自然语言处理模型提供了丰富的训练资源。
Tülu 3是一系列开源的先进语言模型,它们经过后训练以适应更多的任务和用户。这些模型通过结合专有方法的部分细节、新颖技术和已建立的学术研究,实现了复杂的训练过程。Tülu 3的成功根植于精心的数据管理、严格的实验、创新的方法论和改进的训练基础设施。通过公开分享数据、配方和发现,Tülu 3旨在赋予社区探索新的和创新的后训练方法的能力。
WorkflowLLM是一个以数据为中心的框架,旨在增强大型语言模型(LLMs)在工作流编排方面的能力。核心是WorkflowBench,这是一个大规模的监督式微调数据集,包含来自83个应用、28个类别的1503个API的106763个样本。WorkflowLLM通过微调Llama-3.1-8B模型,创建了专门针对工作流编排任务优化的WorkflowLlama模型。实验结果表明,WorkflowLlama在编排复杂工作流方面表现出色,并且能够很好地泛化到未见过的API。
GenXD是一个专注于3D和4D场景生成的框架,它利用日常生活中常见的相机和物体运动来联合研究一般的3D和4D生成。由于社区缺乏大规模的4D数据,GenXD首先提出了一个数据策划流程,从视频中获取相机姿态和物体运动强度。基于此流程,GenXD引入了一个大规模的现实世界4D场景数据集:CamVid-30K。通过利用所有3D和4D数据,GenXD框架能够生成任何3D或4D场景。它提出了多视图-时间模块,这些模块分离相机和物体运动,无缝地从3D和4D数据中学习。此外,GenXD还采用了掩码潜在条件,以支持多种条件视图。GenXD能够生成遵循相机轨迹的视频以及可以提升到3D表示的一致3D视图。它在各种现实世界和合成数据集上进行了广泛的评估,展示了GenXD在3D和4D生成方面与以前方法相比的有效性和多功能性。
Sparsh是一系列通过自监督算法(如MAE、DINO和JEPA)训练的通用触觉表示。它能够为DIGIT、Gelsight'17和Gelsight Mini生成有用的表示,并在TacBench提出的下游任务中大幅度超越端到端模型,同时能够为新下游任务的数据高效训练提供支持。Sparsh项目包含PyTorch实现、预训练模型和与Sparsh一起发布的数据集。
1X 世界模型是一种机器学习程序,能够模拟世界如何响应机器人的行为。它基于视频生成和自动驾驶汽车世界模型的技术进步,为机器人提供了一个虚拟模拟器,能够预测未来的场景并评估机器人策略。这个模型不仅能够处理复杂的对象交互,如刚体、掉落物体的影响、部分可观察性、可变形物体和铰接物体,还能够在不断变化的环境中进行评估,这对于机器人技术的发展至关重要。
GameGen-O 是首个为生成开放世界视频游戏而定制的扩散变换模型。该模型通过模拟游戏引擎的多种特性,如创新角色、动态环境、复杂动作和多样化事件,实现了高质量、开放领域的生成。此外,它还提供了交互式可控性,允许游戏玩法模拟。GameGen-O 的开发涉及从零开始的全面数据收集和处理工作,包括构建首个开放世界视频游戏数据集(OGameData),通过专有的数据管道进行高效的排序、评分、过滤和解耦标题。这个强大且广泛的 OGameData 构成了模型训练过程的基础。
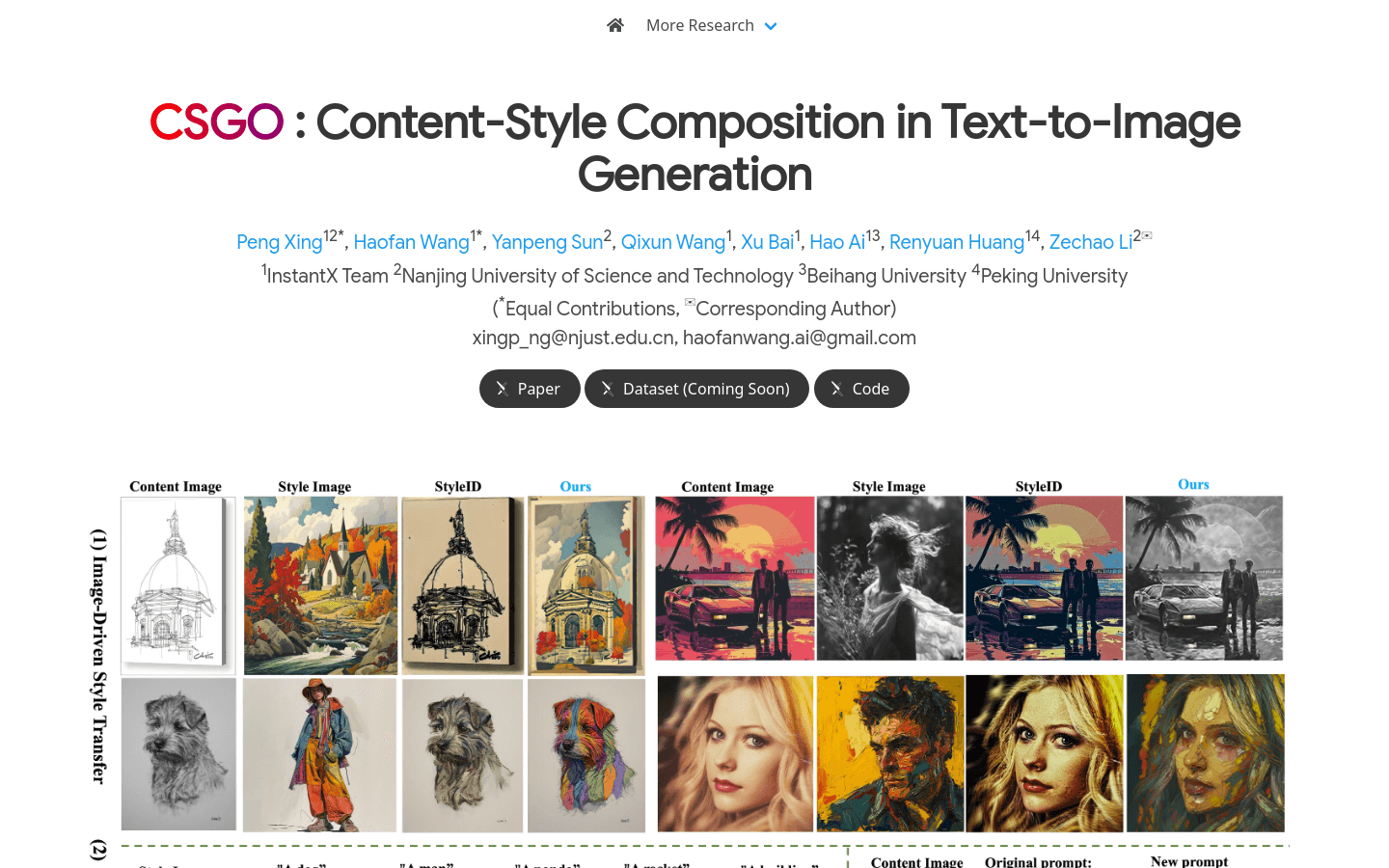
CSGO是一个基于内容风格合成的文本到图像生成模型,它通过一个数据构建管道生成并自动清洗风格化数据三元组,构建了首个大规模的风格迁移数据集IMAGStyle,包含210k图像三元组。CSGO模型采用端到端训练,明确解耦内容和风格特征,通过独立特征注入实现。它实现了图像驱动的风格迁移、文本驱动的风格合成以及文本编辑驱动的风格合成,具有无需微调即可推理、保持原始文本到图像模型的生成能力、统一风格迁移和风格合成等优点。
MedTrinity-25M是一个大规模多模态数据集,包含多粒度的医学注释。它由多位作者共同开发,旨在推动医学图像和文本处理领域的研究。数据集的构建包括数据提取、多粒度文本描述生成等步骤,支持多种医学图像分析任务,如视觉问答(VQA)、病理学图像分析等。
MINT-1T是由Salesforce AI开源的多模态数据集,包含一万亿个文本标记和34亿张图像,规模是现有开源数据集的10倍。它不仅包含HTML文档,还包括PDF文档和ArXiv论文,丰富了数据集的多样性。MINT-1T的数据集构建涉及多种来源的数据收集、处理和过滤步骤,确保了数据的高质量和多样性。
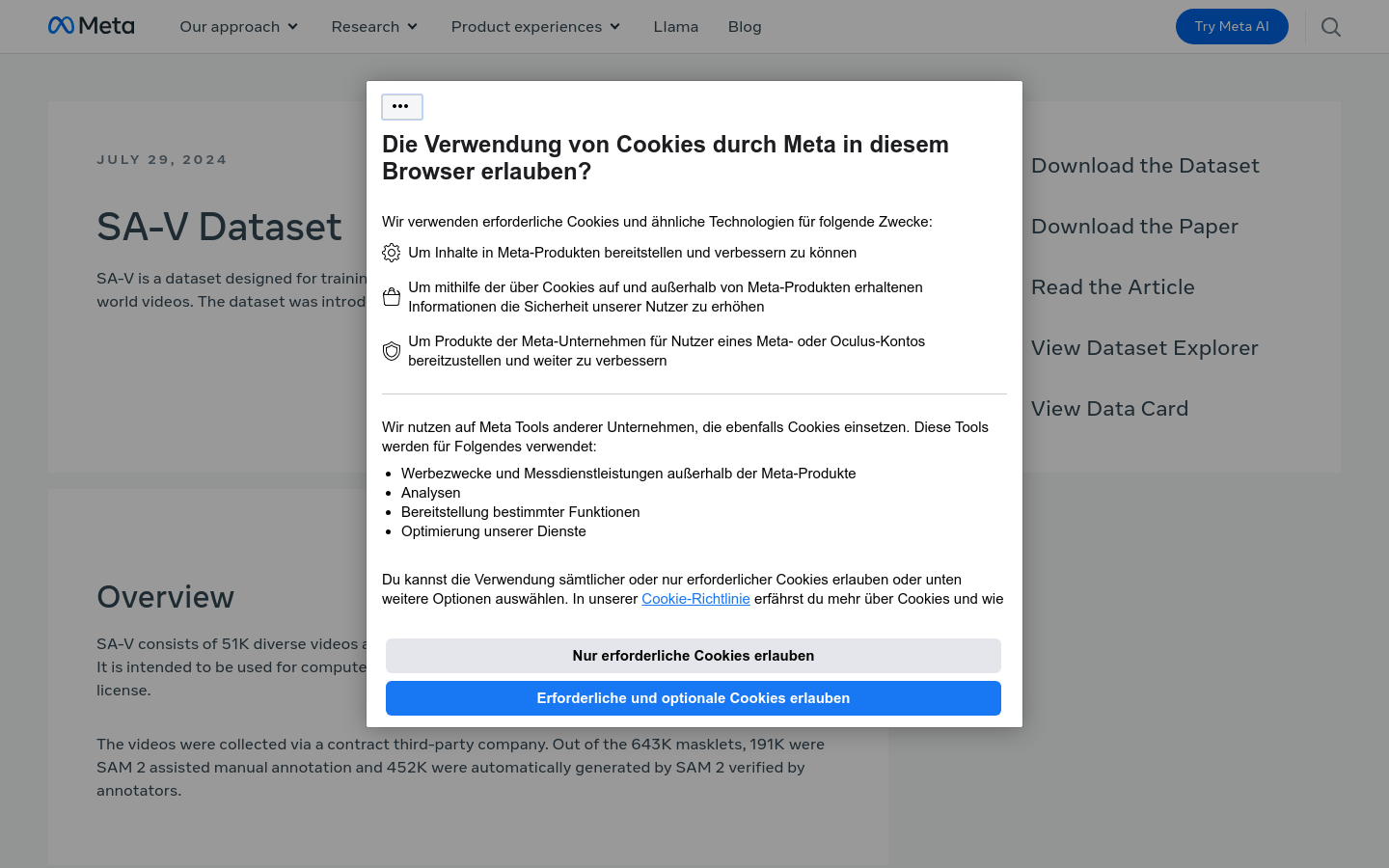
SA-V Dataset是一个专为训练通用目标分割模型设计的开放世界视频数据集,包含51K个多样化视频和643K个时空分割掩模(masklets)。该数据集用于计算机视觉研究,允许在CC BY 4.0许可下使用。视频内容多样,包括地点、对象和场景等主题,掩模从建筑物等大规模对象到室内装饰等细节不等。
Segment Anything Model 2 (SAM 2)是Meta公司AI研究部门FAIR推出的一个视觉分割模型,它通过简单的变换器架构和流式内存设计,实现实时视频处理。该模型通过用户交互构建了一个模型循环数据引擎,收集了迄今为止最大的视频分割数据集SA-V。SAM 2在该数据集上训练,提供了在广泛任务和视觉领域中的强大性能。
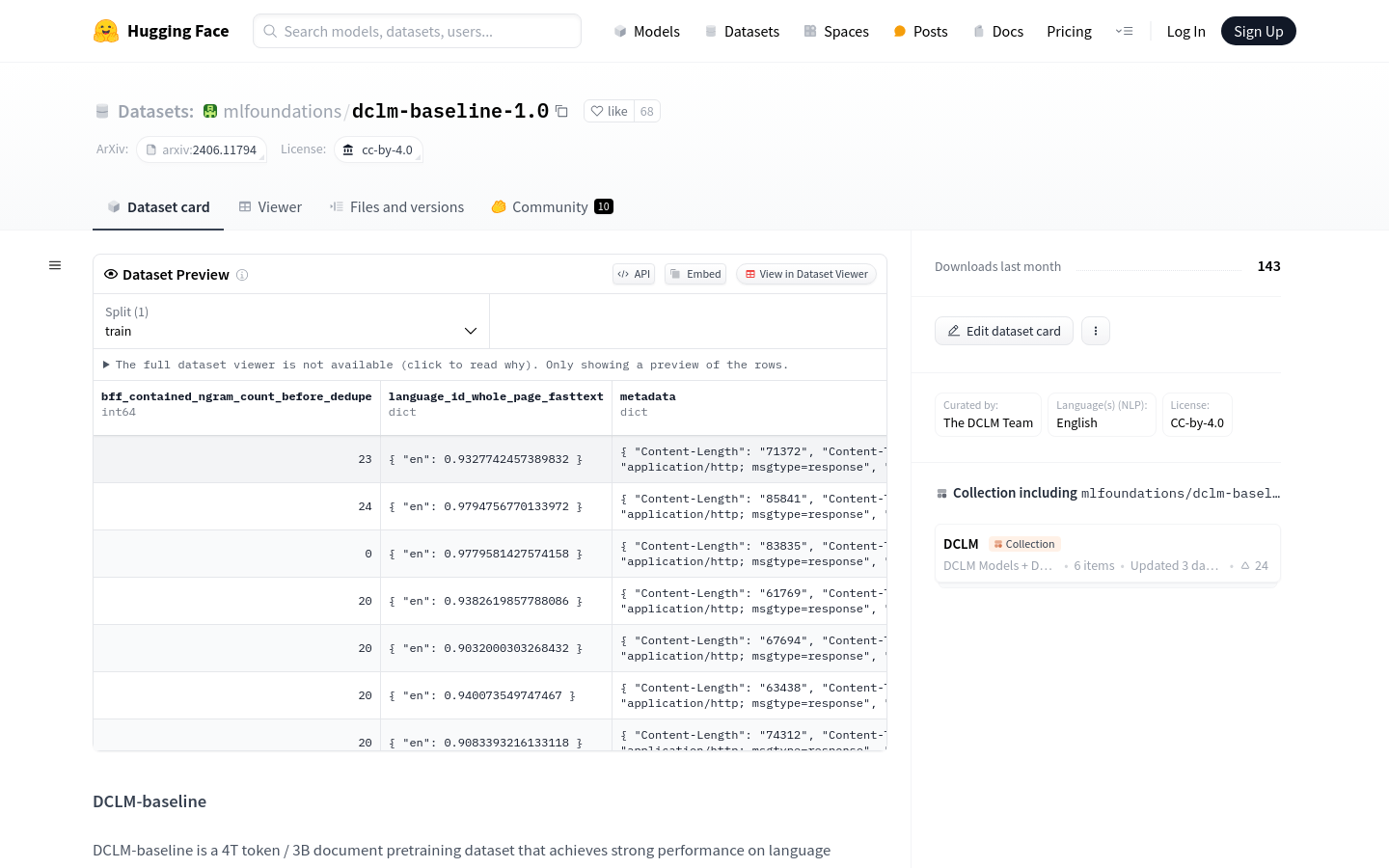
DCLM-baseline是一个用于语言模型基准测试的预训练数据集,包含4T个token和3B个文档。它通过精心策划的数据清洗、过滤和去重步骤,从Common Crawl数据集中提取,旨在展示数据策划在训练高效语言模型中的重要性。该数据集仅供研究使用,不适用于生产环境或特定领域的模型训练,如代码和数学。
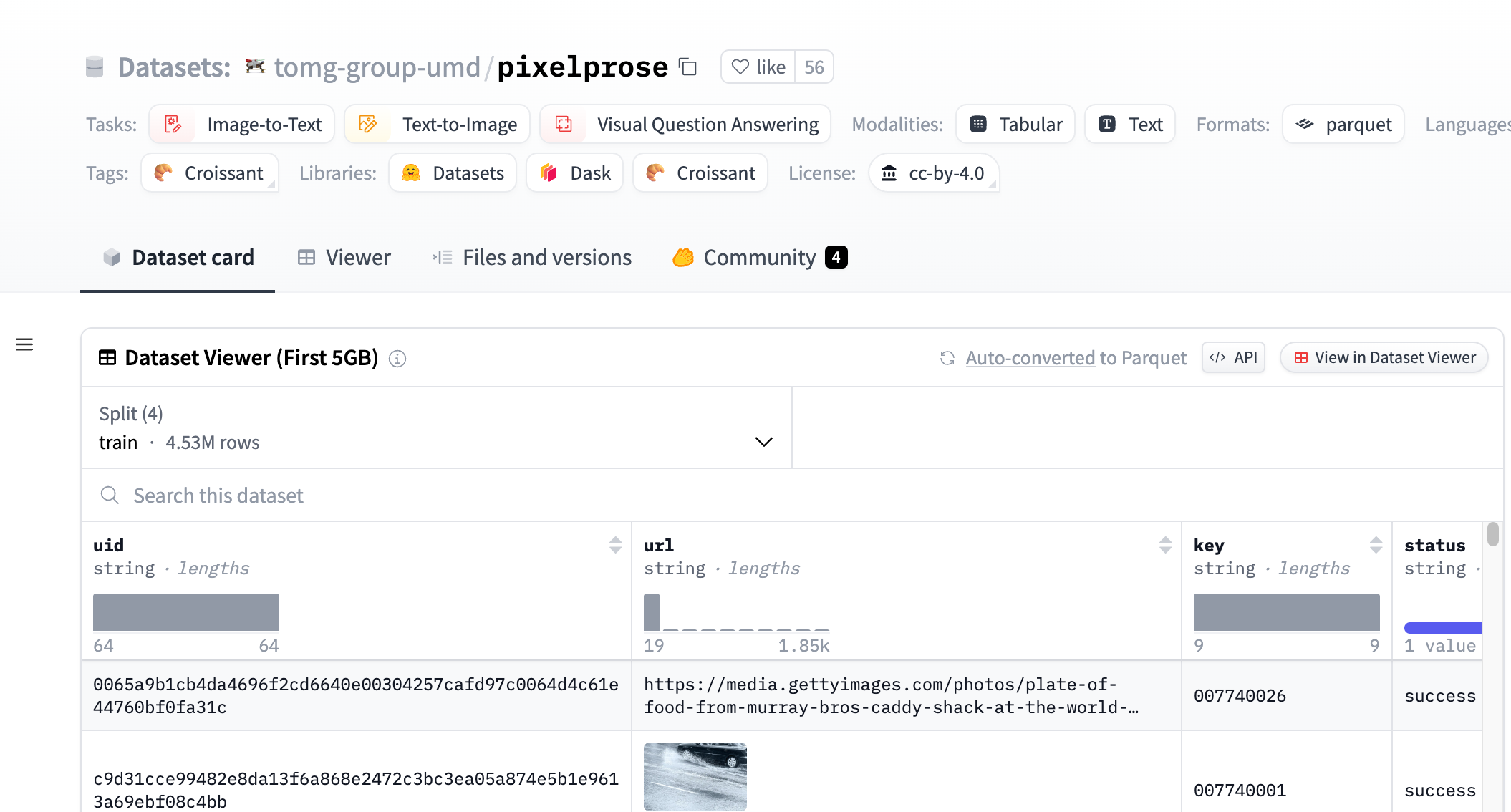
PixelProse是一个由tomg-group-umd创建的大规模数据集,它利用先进的视觉-语言模型Gemini 1.0 Pro Vision生成了超过1600万个详细的图像描述。这个数据集对于开发和改进图像到文本的转换技术具有重要意义,可以用于图像描述生成、视觉问答等任务。
emo-visual-data 是一个公开的表情包视觉标注数据集,它通过使用 glm-4v 和 step-free-api 项目完成的视觉标注,收集了5329个表情包。这个数据集可以用于训练和测试多模态大模型,对于理解图像内容和文本描述之间的关系具有重要意义。
UltraMedical项目旨在开发生物医学领域的专业通用模型,这些模型旨在回答与考试、临床场景和研究问题相关的问题,同时保持广泛的通用知识基础,以有效处理跨领域问题。通过使用先进的对齐技术,包括监督微调(SFT)、直接偏好优化(DPO)和赔率比偏好优化(ORPO),训练大型语言模型在UltraMedical数据集上,以创建强大且多功能的模型,有效服务于生物医学社区的需求。
FlashRAG是一个Python工具包,用于检索增强生成(RAG)研究的复现和开发。它包括32个预处理的基准RAG数据集和12种最先进的RAG算法。FlashRAG提供了一个广泛且可定制的框架,包括检索器、重排器、生成器和压缩器等RAG场景所需的基本组件,允许灵活组装复杂流程。此外,FlashRAG还提供了高效的预处理阶段和优化的执行,支持vLLM、FastChat等工具加速LLM推理和向量索引管理。
ImageInWords (IIW) 是一个由人类参与的循环注释框架,用于策划超详细的图像描述,并生成一个新的数据集。该数据集通过评估自动化和人类并行(SxS)指标来实现最先进的结果。IIW 数据集在生成描述时,比以往的数据集和GPT-4V输出在多个维度上有了显著提升,包括可读性、全面性、特异性、幻觉和人类相似度。此外,使用IIW数据微调的模型在文本到图像生成和视觉语言推理方面表现出色,能够生成更接近原始图像的描述。
WildChat数据集是一个由100万真实世界用户与ChatGPT交互组成的语料库,特点是语言多样和用户提示的多样性。该数据集用于微调Meta的Llama-2,创建了WildLlama-7b-user-assistant聊天机器人,能够预测用户提示和助手回应。
HuggingFace镜像站是一个非盈利性项目,旨在为国内的AI开发者提供一个快速且稳定的模型和数据集下载平台。通过优化下载过程,减少因网络问题导致的中断,它极大地提高了开发者的工作效率。该镜像站支持多种下载方式,包括网页直接下载、使用官方命令行工具huggingface-cli、本站开发的hfd下载工具以及通过设置环境变量来实现非侵入式下载。
FineWeb数据集包含超过15万亿个经过清洗和去重的英文网页数据,来源于CommonCrawl。该数据集专为大型语言模型预训练设计,旨在推动开源模型的发展。数据集经过精心处理和筛选,以确保高质量,适用于各种自然语言处理任务。
StableDesign项目旨在为生成式室内设计提供数据集和训练方法。用户上传空房间图片和文字提示,生成装修效果图。通过爱彼迎数据下载、特征提取和ControlNet模型训练,结合图像处理和自然语言处理技术,提供新思路和方法。
LMSYS Org 是一个组织,旨在使大型模型及其系统基础设施的技术民主化。他们开发了 Vicuna 聊天机器人,其在 7B/13B/33B 规模下可以印象 GPT-4,实现了 90% ChatGPT 质量。同时,还提供 Chatbot Arena 以众包和 Elo 评级系统进行大规模、游戏化评估 LLMs。SGLang 提供了复杂 LLM 程序的高效接口和运行时环境。LMSYS-Chat-1M 是一个大规模真实世界 LLM 对话数据集。FastChat 是一个用于训练、提供服务和评估基于 LLM 的聊天机器人的开放平台。MT-Bench 是一个用于评估聊天机器人的一组具有挑战性、多回合、开放式问题。
Apollo项目由FreedomIntelligence组织维护,旨在通过提供多语言医学领域的大型语言模型(LLMs)来民主化医疗AI,覆盖6亿人。该项目包括模型、数据集、基准测试和相关代码。
MNBVC(Massive Never-ending BT Vast Chinese corpus)是一个旨在为AI提供丰富中文语料的项目。它不仅包括主流文化内容,还涵盖了小众文化和网络用语。数据集包括新闻、作文、小说、书籍、杂志、论文、台词、帖子、wiki、古诗、歌词、商品介绍、笑话、糗事、聊天记录等多种形式的纯文本中文数据。
Refined-Anime-Text是一个针对动漫文本的精炼数据集,由CausalLM提供。该数据集包含了大量的动漫相关文本,适用于训练和优化文本生成模型,特别是在动漫领域的应用。
Aria每日活动数据集是Aria项目发布的首个试点数据集的重新发布版本,该数据集利用新的工具和位置数据进行了更新,以加速机器感知和人工智能技术的发展。数据集包含日常生活场景下的第一人称视频序列,并配有丰富的传感器数据、注释数据以及由Aria机器感知服务生成的3D点云数据等。研究人员可以使用Aria提供的专用工具快速上手使用该数据集开展研究。
AutoMathText是一个广泛且精心策划的数据集,包含约200GB的数学文本。数据集中的每条内容都被最先进的开源语言模型Qwen进行自主选择和评分,确保高标准的相关性和质量。该数据集特别适合促进数学和人工智能交叉领域的高级研究,作为学习和教授复杂数学概念的教育工具,以及为开发和训练专门处理和理解数学内容的AI模型提供基础。
LiveFood是一个包含超过5100个美食视频的数据集,视频包括食材、烹饪、呈现和食用四个领域,所有视频均由专业工人精细注释,并采用严格的双重检查机制进一步保证注释质量。我们还提出了全局原型编码(GPE)模型来处理这个增量学习问题,与传统技术相比获得了竞争性的性能。
MAGNeT是一个提供各种人工智能模型和数据集的社区平台。用户可以在平台上找到各种先进的自然语言处理和机器学习模型,以及相关的数据集。该平台还提供了一系列解决方案,包括文本到语音转换、图像处理等。MAGNeT定位于为开发人员、研究人员和企业提供高质量的人工智能模型和数据集。
ANIM-400K是一个包含超过425,000个对齐的日语和英语动画视频片段的综合数据集,支持自动配音、同声翻译、视频摘要、流派/主题/风格分类等各种视频相关任务。该数据集公开用于研究目的。
DL3DV-10K是一个包含超过10000个高质量视频的大规模实景数据集,每个视频都经过人工标注场景关键点和复杂程度,并提供相机姿态、NeRF估计深度、点云和3D网格等。该数据集可用于通用NeRF研究、场景一致性跟踪、视觉语言模型等计算机视觉研究。
En3D是一个提供先进自然语言处理模型的平台。他们提供了各种各样的模型和数据集,以帮助开发者构建和部署自然语言处理应用。En3D平台的优势在于提供了大量预训练模型和方便的部署工具,使得开发者能够快速、高效地构建自然语言处理应用。
ml-ferret是一个端到端的机器学习语言模型(MLLM),能够接受各种形式的引用并响应性地在多模态环境中进行精准定位。它结合了混合区域表示和空间感知的视觉采样器,支持细粒度和开放词汇的引用和定位。此外,ml-ferret还包括GRIT数据集(约110万个样本)和Ferret-Bench评估基准。
LLM Spark是一个开发平台,可用于构建基于LLM的应用程序。它提供多个LLM的快速测试、版本控制、可观察性、协作、多个LLM支持等功能。LLM Spark可轻松构建AI聊天机器人、虚拟助手等智能应用程序,并通过与提供商密钥集成,实现卓越性能。它还提供了GPT驱动的模板,加速了各种AI应用程序的创建,同时支持从零开始定制项目。LLM Spark还支持无缝上传数据集,以增强AI应用程序的功能。通过LLM Spark的全面日志和分析,可以比较GPT结果、迭代和部署智能AI应用程序。它还支持多个模型同时测试,保存提示版本和历史记录,轻松协作,以及基于意义而不仅仅是关键字的强大搜索功能。此外,LLM Spark还支持将外部数据集集成到LLM中,并符合GDPR合规要求,确保数据安全和隐私保护。
Distil-Whisper是一个提供模型和数据集的平台,用户可以在该平台上访问各种预训练模型和数据集,并进行相关的应用和研究。该平台提供了丰富的模型和数据集资源,帮助用户快速开展自然语言处理和机器学习相关工作。
OpenXLab浦源面向人工智能领域开发者和使用者,提供一站式 AI 开发平台。包括应用开发,模型免费托管,数据集下载等服务。应用中心提供应用构建平台,模型中心提供社区化模型托管平台,数据集中心提供海量优质人工智能数据集。
V7是一个AI数据引擎,提供企业级训练数据的完整基础设施,涵盖标注、工作流、数据集和人工在循环中。它能够帮助用户快速高效地标注、处理和管理训练数据,提高AI模型的准确性和性能。V7支持自动化标注、视频标注、文档处理等功能,适用于各种行业和应用场景。
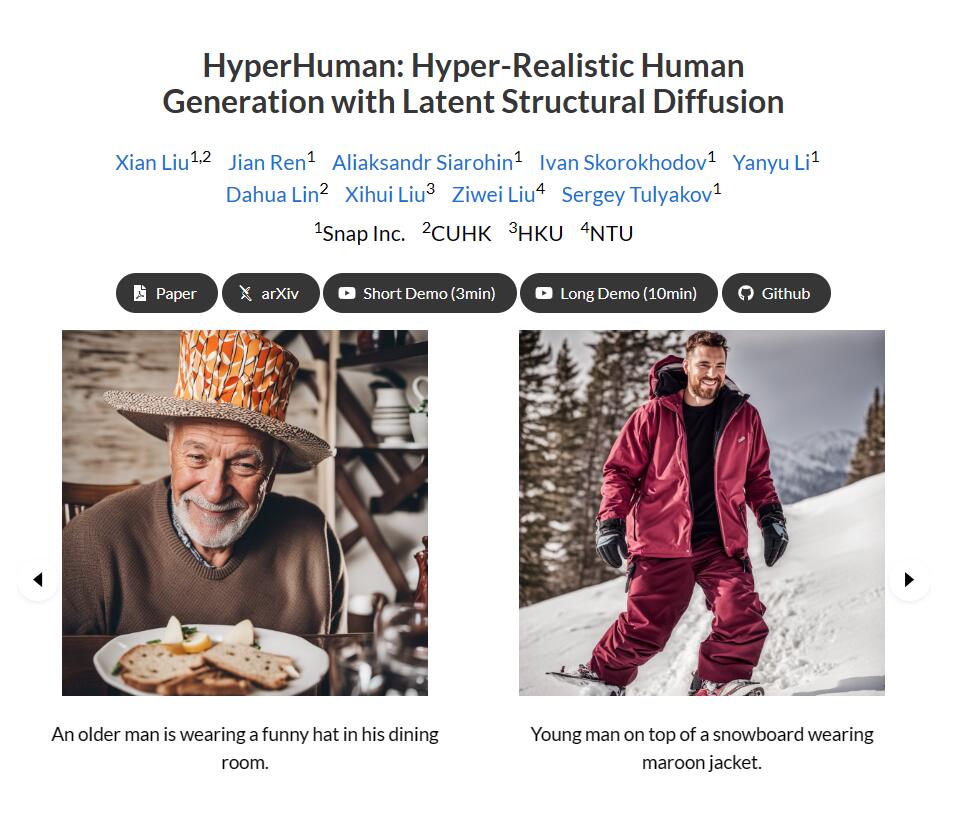
HyperHuman是一个生成逼真的人类图像的模型。该模型通过捕捉人类图像的结构性特征,从粗略的身体骨架到细粒度的空间几何形状,生成具有连贯性和自然性的人类图像。HyperHuman包括三个部分:1)构建一个大规模的人类数据集HumanVerse,其中包含340M张图像和全面的注释,如人体姿势、深度和表面法线;2)提出一个潜在结构扩散模型,该模型同时去噪深度、表面法线和合成的RGB图像。我们的模型在一个统一的网络中强制学习图像外观、空间关系和几何形状,模型中的每个分支都具有结构感知性和纹理丰富性;3)最后,为了进一步提高视觉质量,我们提出了一个结构引导的细化器,用于更详细的高分辨率生成。大量实验证明,我们的模型在各种场景下生成了具有高真实感和多样性的人类图像,达到了最先进的性能。
RoleLLM是一个角色扮演框架,用于构建和评估大型语言模型的角色扮演能力。它包括四个阶段:角色概要构建、基于上下文的指令生成、使用GPT进行角色提示和基于角色的指令调整。通过Context-Instruct和RoleGPT,我们创建了RoleBench,这是一个系统化和细粒度的角色级别基准数据集,包含168,093个样本。此外,RoCIT在RoleBench上产生了RoleLLaMA(英语)和RoleGLM(中文),显著提高了角色扮演能力,甚至与使用GPT-4的RoleGPT取得了可比较的结果。
Awesome-Domain-LLM是一个收集和梳理垂直领域的开源模型、数据集及评测基准的项目。该项目收录了包括医疗、法律、金融、教育等多个领域的开源模型、数据集和评测基准,旨在推动大模型赋能各行各业。用户可以在该项目中找到适合自己领域的模型和数据集,以提高工作效率和质量。
始智AI是一家提供AI模型和数据集的平台,致力于为科研单位、企事业单位和个人提供高质量的AI模型和数据集。始智AI的优势在于提供多种类型的AI模型和数据集,包括图像、视频、自然语言处理等,用户可以根据自己的需求选择合适的模型和数据集。始智AI的定价合理,用户可以根据自己的需求选择不同的套餐,满足不同的需求。始智AI的定位是成为AI模型和数据集领域的领先平台。
I2VGen-XL是一款AI模型库与数据集平台,提供丰富的AI模型和数据集,帮助用户快速构建AI应用。平台支持多种AI任务,包括图像识别、自然语言处理、语音识别等。用户可以通过平台上传、下载和分享模型和数据集,也可以使用平台提供的API接口进行调用。平台提供免费和付费两种服务,用户可以根据需求选择适合自己的服务。
Process Street是一款简单易用的无代码流程平台,可帮助企业创建、跟踪、自动化和完成任务,以优化流程并提高效率。其主要功能包括任务分配、审批、条件逻辑、自动化、调度和分组等。通过AI技术,Process Street还提供了AI驱动的工作流设计,可根据企业的独特运营需求进行自适应,推动生产力和增长。此外,Process Street还提供了表单、数据集和页面等功能,以及与Salesforce、Slack、Microsoft Teams、Google Sheets等工具的集成。
Inst-Inpaint是一种图像修复算法,可以根据自然语言输入估计要删除的对象并同时删除它。该产品提供了一个名为GQA-Inpaint的数据集,以及一种名为Inst-Inpaint的新型修复框架,可以根据文本提示从图像中删除对象。该产品提供了各种GAN和扩散基线,并在合成和真实图像数据集上运行实验。该产品提供了不同的评估指标,以衡量模型的质量和准确性,并显示出显著的定量和定性改进。
CelebV-Text是一个大规模、高质量、多样化的人脸文本-视频数据集,旨在促进人脸文本-视频生成任务的研究。数据集包含70,000个野外人脸视频剪辑,每个视频剪辑都配有20个文本,涵盖40种一般外观、5种详细外观、6种光照条件、37种动作、8种情绪和6种光线方向。CelebV-Text通过全面的统计分析验证了其在视频、文本和文本-视频相关性方面的优越性,并构建了一个基准来标准化人脸文本-视频生成任务的评估。
Botdocs是一系列高质量的数据集,用于训练人工智能处理常见的客服互动。它可用于训练大型语言模型、意图分类器和自然语言理解引擎,以帮助企业自动化常见的客服互动,并提供对客户意图的理解和提供卓越的客户体验。Botdocs以CSV、JSONL和Dialogflow(ES)格式提供,以满足AI开发人员和系统对大型语言模型、意图分类器和自然语言理解引擎的不同需求。
Objaverse是一个包含800K+个标注3D物体的大规模数据集,每个物体都有名称、描述、标签和其他元数据。它包含了各种类型的物体,包括静态物体、动画物体、有部位注释的角色、可分解的模型、室内外环境等,并具有多样的视觉风格。Objaverse可用于生成3D模型、作为2D实例分割的增强、开放词汇体现的AI以及研究CLIP的鲁棒性。
ClearCypherAI是一家总部位于美国的AI初创公司,致力于构建前沿的解决方案。我们的产品包括文本转语音(T2A)、语音转文本(A2T)和语音转语音(A2A),支持多语言、多模态、实时语音智能。我们还提供自然语言数据集、威胁评估、AI定制平台等服务。我们的产品具有高度定制性、先进的技术和优质的客户支持。
Riku.AI是一款无代码AI构建工具,可用于创建AI模型和数据集。通过与现有工具的集成,API或公共共享链接,轻松使用AI。为每个人提供可访问的AI。
LAION是一个非营利组织,致力于提供机器学习资源给公众使用,包括数据集、工具和模型。我们鼓励开放公共教育,并通过重复使用现有数据集和模型来更环保地使用资源。我们提供多个数据集、模型和项目,以支持广泛的人工智能研究。