找到 111 个相关的AI工具
Dream 7B 是由香港大学 NLP 组和华为诺亚方舟实验室联合推出的最新扩散大语言模型。它在文本生成领域展现了优异的性能,特别是在复杂推理、长期规划和上下文连贯性等方面。该模型采用了先进的训练方法,具有强大的计划能力和灵活的推理能力,为各类 AI 应用提供了更为强大的支持。
AccVideo 是一种新颖的高效蒸馏方法,通过合成数据集加速视频扩散模型的推理速度。该模型能够在生成视频时实现 8.5 倍的速度提升,同时保持相似的性能。它使用预训练的视频扩散模型生成多条有效去噪轨迹,从而优化了数据的使用和生成过程。AccVideo 特别适用于需要高效视频生成的场景,如电影制作、游戏开发等,适合研究人员和开发者使用。
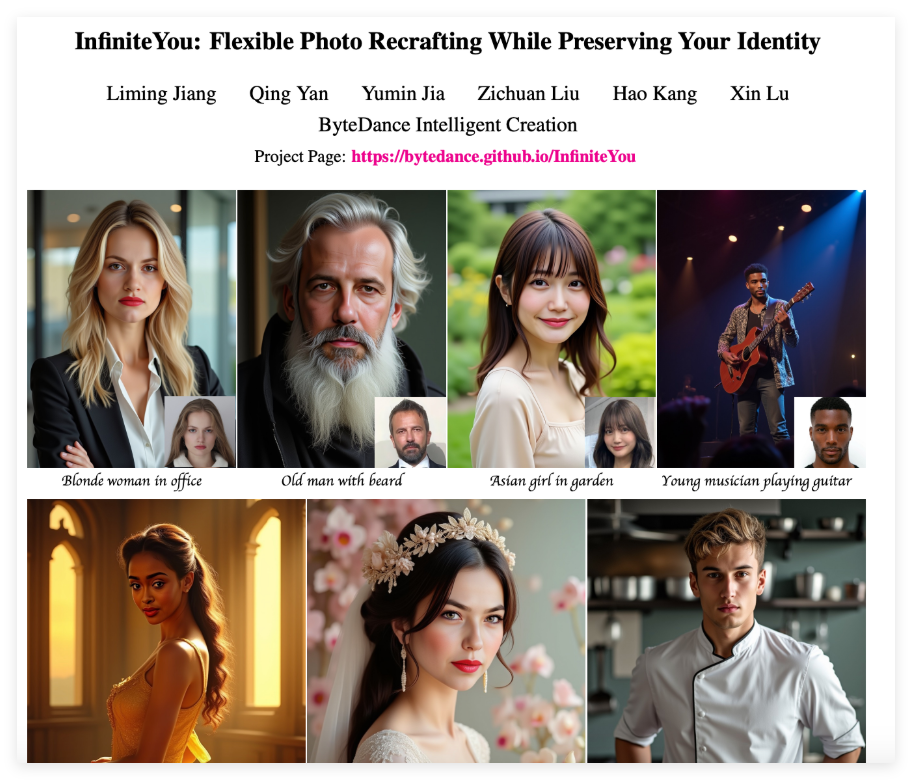
InfiniteYou(InfU)是一个基于扩散变换器的强大框架,旨在实现灵活的图像重构,并保持用户身份。它通过引入身份特征并采用多阶段训练策略,显著提升了图像生成的质量和美学,同时改善了文本与图像的对齐。该技术对提高图像生成的相似性和美观性具有重要意义,适用于各种图像生成任务。
TrajectoryCrafter 是一种先进的相机轨迹重定向工具,利用扩散模型技术,将单目视频中的相机运动重新设计,提升视频的表现力和视觉吸引力。该技术可广泛应用于影视制作和虚拟现实等领域,具备高效、便捷和创新的特点,旨在为用户提供更多创意自由和控制能力。
Inception Labs 是一家专注于开发扩散式大语言模型(dLLMs)的公司。其技术灵感来源于先进的图像和视频生成系统,如 Midjourney 和 Sora。通过扩散模型,Inception Labs 提供了比传统自回归模型快 5-10 倍的速度、更高的效率和更强的生成控制能力。其模型支持并行文本生成,能够纠正错误和幻觉,适合多模态任务,并且在推理和结构化数据生成方面表现出色。公司由斯坦福、UCLA 和康奈尔大学的研究人员和工程师组成,是扩散模型领域的先驱。
Project Starlight 是 Topaz Labs 推出的一款 AI 视频增强模型,专为提升低分辨率和损坏视频的质量而设计。它采用了扩散模型技术,能够实现视频的超分辨率、降噪、去模糊和锐化等功能,同时保持时间一致性,确保视频帧之间的流畅过渡。该技术是视频增强领域的重大突破,为视频修复和提升带来了前所未有的高质量效果。目前,Project Starlight 提供免费试用,并计划在未来支持 4K 导出,主要面向需要高质量视频修复和增强的用户和企业。
Mercury Coder 是 Inception Labs 推出的首款商用级扩散大语言模型(dLLM),专为代码生成优化。该模型采用扩散模型技术,通过‘粗到细’的生成方式,显著提升生成速度和质量。其速度比传统自回归语言模型快 5-10 倍,能够在 NVIDIA H100 硬件上达到每秒 1000 多个 token 的生成速度,同时保持高质量的代码生成能力。该技术的背景是当前自回归语言模型在生成速度和推理成本上的瓶颈,而 Mercury Coder 通过算法优化突破了这一限制,为企业级应用提供了更高效、低成本的解决方案。
VideoGrain 是一种基于扩散模型的视频编辑技术,通过调节时空注意力机制实现多粒度视频编辑。该技术解决了传统方法中语义对齐和特征耦合的问题,能够对视频内容进行精细控制。其主要优点包括零样本编辑能力、高效的文本到区域控制以及特征分离能力。该技术适用于需要对视频进行复杂编辑的场景,如影视后期、广告制作等,能够显著提升编辑效率和质量。
MakeAnything 是一个基于扩散变换器的模型,专注于多领域程序化序列生成。该技术通过结合先进的扩散模型和变换器架构,能够生成高质量的、逐步的创作序列,如绘画、雕塑、图标设计等。其主要优点在于能够处理多种领域的生成任务,并且可以通过少量样本快速适应新领域。该模型由新加坡国立大学 Show Lab 团队开发,目前以开源形式提供,旨在推动多领域生成技术的发展。
Pippo 是由 Meta Reality Labs 和多所高校合作开发的生成模型,能够从单张普通照片生成高分辨率的多人视角视频。该技术的核心优势在于无需额外输入(如参数化模型或相机参数),即可生成高质量的 1K 分辨率视频。它基于多视角扩散变换器架构,具有广泛的应用前景,如虚拟现实、影视制作等。Pippo 的代码已开源,但不包含预训练权重,用户需要自行训练模型。
On-device Sora 是一个开源项目,旨在通过线性比例跳跃(LPL)、时间维度标记合并(TDTM)和动态加载并发推理(CI-DL)等技术,实现在移动设备(如 iPhone 15 Pro)上高效的视频生成。该项目基于 Open-Sora 模型开发,能够根据文本输入生成高质量视频。其主要优点包括高效性、低功耗和对移动设备的优化。该技术适用于需要在移动设备上快速生成视频内容的场景,如短视频创作、广告制作等。项目目前开源,用户可以免费使用。
DiffSplat 是一种创新的 3D 生成技术,能够从文本提示和单视图图像快速生成 3D 高斯点云。该技术通过利用大规模预训练的文本到图像扩散模型,实现了高效的 3D 内容生成。它解决了传统 3D 生成方法中数据集有限和无法有效利用 2D 预训练模型的问题,同时保持了 3D 一致性。DiffSplat 的主要优点包括高效的生成速度(1~2 秒内完成)、高质量的 3D 输出以及对多种输入条件的支持。该模型在学术研究和工业应用中具有广泛前景,尤其是在需要快速生成高质量 3D 模型的场景中。
Go with the Flow 是一种创新的视频生成技术,通过使用扭曲噪声代替传统的高斯噪声,实现了对视频扩散模型运动模式的高效控制。该技术无需对原始模型架构进行修改,即可在不增加计算成本的情况下,实现对视频中物体和相机运动的精确控制。其主要优点包括高效性、灵活性和可扩展性,能够广泛应用于图像到视频生成、文本到视频生成等多种场景。该技术由 Netflix Eyeline Studios 等机构的研究人员开发,具有较高的学术价值和商业应用潜力,目前开源免费提供给公众使用。
TokenVerse 是一种创新的多概念个性化方法,它利用预训练的文本到图像扩散模型,能够从单张图像中解耦复杂的视觉元素和属性,并实现无缝的概念组合生成。这种方法突破了现有技术在概念类型或广度上的限制,支持多种概念,包括物体、配饰、材质、姿势和光照等。TokenVerse 的重要性在于其能够为图像生成领域带来更灵活、更个性化的解决方案,满足用户在不同场景下的多样化需求。目前,TokenVerse 的代码尚未公开,但其在个性化图像生成方面的潜力已经引起了广泛关注。
X-Dyna是一种创新的零样本人类图像动画生成技术,通过将驱动视频中的面部表情和身体动作迁移到单张人类图像上,生成逼真且富有表现力的动态效果。该技术基于扩散模型,通过Dynamics-Adapter模块,将参考外观上下文有效整合到扩散模型的空间注意力中,同时保留运动模块合成流畅复杂动态细节的能力。它不仅能够实现身体姿态控制,还能通过本地控制模块捕捉与身份无关的面部表情,实现精确的表情传递。X-Dyna在多种人类和场景视频的混合数据上进行训练,能够学习物理人体运动和自然场景动态,生成高度逼真和富有表现力的动画。
Hunyuan3D 2.0 是腾讯推出的一种先进大规模 3D 合成系统,专注于生成高分辨率纹理化的 3D 资产。该系统包括两个基础组件:大规模形状生成模型 Hunyuan3D-DiT 和大规模纹理合成模型 Hunyuan3D-Paint。它通过解耦形状和纹理生成的难题,为用户提供了灵活的 3D 资产创作平台。该系统在几何细节、条件对齐、纹理质量等方面超越了现有的开源和闭源模型,具有极高的实用性和创新性。目前,该模型的推理代码和预训练模型已开源,用户可以通过官网或 Hugging Face 空间快速体验。
Diffusion as Shader (DaS) 是一种创新的视频生成控制模型,旨在通过3D感知的扩散过程实现对视频生成的多样化控制。该模型利用3D跟踪视频作为控制输入,能够在统一的架构下支持多种视频控制任务,如网格到视频生成、相机控制、运动迁移和对象操作等。DaS的主要优势在于其3D感知能力,能够有效提升生成视频的时间一致性,并在短时间内通过少量数据微调即可展现出强大的控制能力。该模型由香港科技大学等多所高校的研究团队共同开发,旨在推动视频生成技术的发展,为影视制作、虚拟现实等领域提供更为灵活和高效的解决方案。
SeedVR 是一种创新的扩散变换器模型,专门用于处理真实世界中的视频修复任务。该模型通过其独特的移位窗口注意力机制,能够高效地处理任意长度和分辨率的视频序列。SeedVR 的设计使其在生成能力和采样效率方面都取得了显著的提升,相较于传统的扩散模型,它在合成和真实世界的基准测试中均表现出色。此外,SeedVR 还结合了因果视频自编码器、混合图像和视频训练以及渐进式训练等现代实践,进一步提高了其在视频修复领域的竞争力。作为一种前沿的视频修复技术,SeedVR 为视频内容创作者和后期制作人员提供了一种强大的工具,能够显著提升视频质量,尤其是在处理低质量或损坏的视频素材时。
CreatiLayout是一种创新的布局到图像生成技术,利用孪生多模态扩散变换器(Siamese Multimodal Diffusion Transformer)来实现高质量和细粒度可控的图像生成。该技术能够精确渲染复杂的属性,如颜色、纹理、形状、数量和文本,适用于需要精确布局和图像生成的应用场景。其主要优点包括高效的布局引导集成、强大的图像生成能力和大规模数据集的支持。CreatiLayout由复旦大学和字节跳动公司联合开发,旨在推动图像生成技术在创意设计领域的应用。
DiffSensei是一个结合了多模态大型语言模型(LLMs)和扩散模型的定制化漫画生成模型。它能够根据用户提供的文本提示和角色图像,生成可控制的黑白漫画面板,并具有灵活的角色适应性。这项技术的重要性在于它将自然语言处理与图像生成相结合,为漫画创作和个性化内容生成提供了新的可能性。DiffSensei模型以其高质量的图像生成、多样化的应用场景以及对资源的高效利用而受到关注。目前,该模型在GitHub上公开,可以免费下载使用,但具体的使用可能需要一定的计算资源。
DynamicControl是一个用于提升文本到图像扩散模型控制力的框架。它通过动态组合多样的控制信号,支持自适应选择不同数量和类型的条件,以更可靠和详细地合成图像。该框架首先使用双循环控制器,利用预训练的条件生成模型和判别模型,为所有输入条件生成初始真实分数排序。然后,通过多模态大型语言模型(MLLM)构建高效条件评估器,优化条件排序。DynamicControl联合优化MLLM和扩散模型,利用MLLM的推理能力促进多条件文本到图像任务,最终排序的条件输入到并行多控制适配器,学习动态视觉条件的特征图并整合它们以调节ControlNet,增强对生成图像的控制。
InvSR是一种基于扩散反转的图像超分辨率技术,利用大型预训练扩散模型中丰富的图像先验来提高超分辨率性能。该技术通过部分噪声预测策略构建扩散模型的中间状态,作为起始采样点,并使用深度噪声预测器估计最优噪声图,从而在前向扩散过程中初始化采样,生成高分辨率结果。InvSR支持任意数量的采样步骤,从一到五步不等,即使仅使用单步采样,也展现出优于或媲美现有最先进方法的性能。
ColorFlow是一个为图像序列着色而设计的模型,特别注重在着色过程中保留角色和对象的身份信息。该模型利用上下文信息,能够根据参考图像池为黑白图像序列中的不同元素(如角色的头发和服装)准确生成颜色,并确保与参考图像的颜色一致性。ColorFlow通过三个阶段的扩散模型框架,提出了一种新颖的检索增强着色流程,无需每个身份的微调或显式身份嵌入提取,即可实现具有相关颜色参考的图像着色。ColorFlow的主要优点包括其在保留身份信息的同时,还能提供高质量的着色效果,这对于卡通或漫画系列的着色具有重要的市场价值。
Leffa是一个用于可控人物图像生成的统一框架,它能够精确控制人物的外观(例如虚拟试穿)和姿态(例如姿态转移)。该模型通过在训练期间引导目标查询关注参考图像中的相应区域,减少细节扭曲,同时保持高图像质量。Leffa的主要优点包括模型无关性,可以用于提升其他扩散模型的性能。
HelloMeme是一个集成了空间编织注意力(Spatial Knitting Attentions)的扩散模型,用于嵌入高级别和细节丰富的条件。该模型支持图像和视频的生成,具有改善生成视频与驱动视频之间表情一致性、减少VRAM使用、优化算法等优点。HelloMeme由HelloVision团队开发,属于HelloGroup Inc.,是一个前沿的图像和视频生成技术,具有重要的商业和教育价值。
Color-diffusion是一个基于扩散模型的图像着色项目,它使用LAB颜色空间对黑白图片进行上色。该项目的主要优点在于能够利用已有的灰度信息(L通道),通过训练模型来预测颜色信息(A和B通道)。这种技术在图像处理领域具有重要意义,尤其是在老照片修复和艺术创作中。Color-diffusion作为一个开源项目,其背景信息显示,它是作者为了满足好奇心和体验从头开始训练扩散模型而快速构建的。项目目前是免费的,并且有很大的改进空间。
AnchorCrafter是一个创新的扩散模型系统,旨在生成包含目标人物和定制化对象的2D视频,通过人-物交互(HOI)的集成,实现高视觉保真度和可控交互。该系统通过HOI-外观感知增强从任意多视角识别对象外观的能力,并分离人和物的外观;HOI-运动注入则通过克服对象轨迹条件和相互遮挡管理的挑战,实现复杂的人-物交互。此外,HOI区域重新加权损失作为训练目标,增强了对对象细节的学习。该技术在保持对象外观和形状意识的同时,也维持了人物外观和运动的一致性,对于在线商务、广告和消费者参与等领域具有重要意义。
text-to-pose是一个研究项目,旨在通过文本描述生成人物姿态,并利用这些姿态生成图像。该技术结合了自然语言处理和计算机视觉,通过改进扩散模型的控制和质量,实现了从文本到图像的生成。项目背景基于NeurIPS 2024 Workshop上发表的论文,具有创新性和前沿性。该技术的主要优点包括提高图像生成的准确性和可控性,以及在艺术创作和虚拟现实等领域的应用潜力。
DiffusionDrive是一个用于实时端到端自动驾驶的截断扩散模型,它通过减少扩散去噪步骤来加快计算速度,同时保持高准确性和多样性。该模型直接从人类示范中学习,无需复杂的预处理或后处理步骤,即可实现实时的自动驾驶决策。DiffusionDrive在NAVSIM基准测试中取得了88.1 PDMS的突破性成绩,并且能够在45 FPS的速度下运行。
TryOffDiff是一种基于扩散模型的高保真服装重建技术,用于从穿着个体的单张照片中生成标准化的服装图像。这项技术与传统的虚拟试穿不同,它旨在提取规范的服装图像,这在捕捉服装形状、纹理和复杂图案方面提出了独特的挑战。TryOffDiff通过使用Stable Diffusion和基于SigLIP的视觉条件来确保高保真度和细节保留。该技术在VITON-HD数据集上的实验表明,其方法优于基于姿态转移和虚拟试穿的基线方法,并且需要较少的预处理和后处理步骤。TryOffDiff不仅能够提升电子商务产品图像的质量,还能推进生成模型的评估,并激发未来在高保真重建方面的工作。
Diffusion Self-Distillation是一种基于扩散模型的自蒸馏技术,用于零样本定制图像生成。该技术允许艺术家和用户在没有大量配对数据的情况下,通过预训练的文本到图像的模型生成自己的数据集,进而微调模型以实现文本和图像条件的图像到图像任务。这种方法在保持身份生成任务的性能上超越了现有的零样本方法,并能与每个实例的调优技术相媲美,无需测试时优化。
CAT4D是一个利用多视图视频扩散模型从单目视频中生成4D场景的技术。它能够将输入的单目视频转换成多视角视频,并重建动态的3D场景。这项技术的重要性在于它能够从单一视角的视频资料中提取并重建出三维空间和时间的完整信息,为虚拟现实、增强现实以及三维建模等领域提供了强大的技术支持。产品背景信息显示,CAT4D由Google DeepMind、Columbia University和UC San Diego的研究人员共同开发,是一个前沿的科研成果转化为实际应用的案例。
OneDiffusion是一个多功能、大规模的扩散模型,它能够无缝支持双向图像合成和理解,覆盖多种任务。该模型预计将在12月初发布代码和检查点。OneDiffusion的重要性在于其能够处理图像合成和理解任务,这在人工智能领域是一个重要的进步,尤其是在图像生成和识别方面。产品背景信息显示,这是一个由多位研究人员共同开发的项目,其研究成果已在arXiv上发表。
JoyVASA是一种基于扩散模型的音频驱动人像动画技术,它通过分离动态面部表情和静态3D面部表示来生成面部动态和头部运动。这项技术不仅能够提高视频质量和唇形同步的准确性,还能扩展到动物面部动画,支持多语言,并在训练和推理效率上有所提升。JoyVASA的主要优点包括更长视频生成能力、独立于角色身份的运动序列生成以及高质量的动画渲染。
Fashion-VDM是一个视频扩散模型(VDM),用于生成虚拟试穿视频。该模型接受一件衣物图片和人物视频作为输入,旨在生成人物穿着给定衣物的高质量试穿视频,同时保留人物的身份和动作。与传统的基于图像的虚拟试穿相比,Fashion-VDM在衣物细节和时间一致性方面表现出色。该技术的主要优点包括:扩散式架构、分类器自由引导增强控制、单次64帧512px视频生成的渐进式时间训练策略,以及联合图像-视频训练的有效性。Fashion-VDM在视频虚拟试穿领域树立了新的行业标准。
InstantIR是一种基于扩散模型的盲图像恢复方法,能够在测试时处理未知退化问题,提高模型的泛化能力。该技术通过动态调整生成条件,在推理过程中生成参考图像,从而提供稳健的生成条件。InstantIR的主要优点包括:能够恢复极端退化的图像细节,提供逼真的纹理,并且通过文本描述调节生成参考,实现创造性的图像恢复。该技术由北京大学、InstantX团队和香港中文大学的研究人员共同开发,得到了HuggingFace和fal.ai的赞助支持。
PromptFix是一个综合框架,能够使扩散模型遵循人类指令执行各种图像处理任务。该框架通过构建大规模的指令遵循数据集,提出了高频引导采样方法来控制去噪过程,并设计了辅助提示适配器,利用视觉语言模型增强文本提示,提高模型的任务泛化能力。PromptFix在多种图像处理任务中表现优于先前的方法,并在盲恢复和组合任务中展现出优越的零样本能力。
MarDini是Meta AI Research推出的一款视频扩散模型,它将掩码自回归(MAR)的优势整合到统一的扩散模型(DM)框架中。该模型能够根据任意数量的掩码帧在任意帧位置进行视频生成,支持视频插值、图像到视频生成以及视频扩展等多种视频生成任务。MarDini的设计高效,将大部分计算资源分配给低分辨率规划模型,使得在大规模上进行空间-时间注意力成为可能。MarDini在视频插值方面树立了新的标杆,并且在几次推理步骤内,就能高效生成与更昂贵的高级图像到视频模型相媲美的视频。
FasterCache是一种创新的无需训练的策略,旨在加速视频扩散模型的推理过程,并生成高质量的视频内容。这一技术的重要性在于它能够显著提高视频生成的效率,同时保持或提升内容的质量,这对于需要快速生成视频内容的行业来说是非常有价值的。FasterCache由来自香港大学、南洋理工大学和上海人工智能实验室的研究人员共同开发,项目页面提供了更多的视觉结果和详细信息。产品目前免费提供,主要面向视频内容生成、AI研究和开发等领域。
genmoai/models 是一个开源的视频生成模型,代表了视频生成技术的最新进展。该模型名为 Mochi 1,是一个基于 Asymmetric Diffusion Transformer (AsymmDiT) 架构的10亿参数扩散模型,从零开始训练,是迄今为止公开发布的最大的视频生成模型。它具有高保真运动和强提示遵循性,显著缩小了封闭和开放视频生成系统之间的差距。该模型在 Apache 2.0 许可下发布,用户可以在 Genmo 的 playground 上免费试用此模型。
Stable Diffusion 3.5 Large Turbo 是一个基于文本生成图像的多模态扩散变换器(MMDiT)模型,采用了对抗性扩散蒸馏(ADD)技术,提高了图像质量、排版、复杂提示理解和资源效率,特别注重减少推理步骤。该模型在生成图像方面表现出色,能够理解和生成复杂的文本提示,适用于多种图像生成场景。它在Hugging Face平台上发布,遵循Stability Community License,适合研究、非商业用途以及年收入少于100万美元的组织或个人免费使用。
Stable Diffusion 3.5 Large 是一个基于文本生成图像的多模态扩散变换器(MMDiT)模型,由 Stability AI 开发。该模型在图像质量、排版、复杂提示理解和资源效率方面都有显著提升。它使用三个固定的预训练文本编码器,并通过 QK 归一化技术提高训练稳定性。此外,该模型在训练数据和策略上使用了包括合成数据和过滤后的公开可用数据。Stable Diffusion 3.5 Large 模型在遵守社区许可协议的前提下,可以免费用于研究、非商业用途,以及年收入少于100万美元的组织或个人的商业用途。
ACE是一个基于扩散变换的全能创造者和编辑器,它能够通过统一的条件格式Long-context Condition Unit (LCU)输入,实现多种视觉生成任务的联合训练。ACE通过高效的数据收集方法解决了训练数据缺乏的问题,并通过多模态大型语言模型生成准确的文本指令。ACE在视觉生成领域具有显著的性能优势,可以轻松构建响应任何图像创建请求的聊天系统,避免了视觉代理通常采用的繁琐流程。
Inverse Painting 是一种基于扩散模型的方法,能够从一幅目标画作生成绘画过程的时间流逝视频。该技术通过训练学习真实艺术家的绘画过程,能够处理多种艺术风格,并生成类似人类艺术家的绘画过程视频。它结合了文本和区域理解,定义了一组绘画指令,并使用新颖的扩散基础渲染器更新画布。该技术不仅能够处理训练中有限的丙烯画风格,还能为广泛的艺术风格和流派提供合理的结果。
HelloMeme是一个集成了空间编织注意力的扩散模型,旨在将高保真和丰富的条件嵌入到图像生成过程中。该技术通过提取驱动视频中的每一帧特征,并将其作为输入到HMControlModule,从而生成视频。通过进一步优化Animatediff模块,提高了生成视频的连续性和保真度。此外,HelloMeme还支持通过ARKit面部混合形状控制生成的面部表情,以及基于SD1.5的Lora或Checkpoint,实现了框架的热插拔适配器,不会影响T2I模型的泛化能力。
Diffusers Image Outpaint 是一个基于扩散模型的图像外延技术,它能够根据已有的图像内容,生成图像的额外部分。这项技术在图像编辑、游戏开发、虚拟现实等领域具有广泛的应用前景。它通过先进的机器学习算法,使得图像生成更加自然和逼真,为用户提供了一种创新的图像处理方式。
InstantDrag是一个优化自由的流程,它通过仅使用图像和拖拽指令作为输入,增强了交互性和速度。该技术由两个精心设计的网络组成:拖拽条件的光流生成器(FlowGen)和光流条件的扩散模型(FlowDiffusion)。InstantDrag通过将任务分解为运动生成和运动条件图像生成,学习了基于真实世界视频数据集的拖拽图像编辑的运动动态。它能够在不需要掩码或文本提示的情况下,快速执行逼真的编辑,这使得它成为交互式、实时应用的有前景的解决方案。
OmniGen是一个创新的扩散框架,它将多种图像生成任务统一到单一模型中,无需特定任务的网络或微调。这一技术简化了图像生成流程,提高了效率,降低了开发和维护成本。
Concept Sliders 是一种用于精确控制扩散模型中概念的技术,它通过低秩适配器(LoRA)在预训练模型之上进行应用,允许艺术家和用户通过简单的文本描述或图像对来训练控制特定属性的方向。这种技术的主要优点是能够在不改变图像整体结构的情况下,对生成的图像进行细微调整,如眼睛大小、光线等,从而实现更精细的控制。它为艺术家提供了一种新的创作表达方式,同时解决了生成模糊或扭曲图像的问题。
该产品是一个图像到视频的扩散模型,通过轻量级的微调技术,能够从一对关键帧生成具有连贯运动的连续视频序列。这种方法特别适用于需要在两个静态图像之间生成平滑过渡动画的场景,如动画制作、视频编辑等。它利用了大规模图像到视频扩散模型的强大能力,通过微调使其能够预测两个关键帧之间的视频,从而实现前向和后向的一致性。
Follow-Your-Canvas 是一种基于扩散模型的视频外延技术,它能够生成高分辨率的视频内容。该技术通过分布式处理和空间窗口合并,解决了GPU内存限制问题,同时保持了视频的空间和时间一致性。它在大规模视频外延方面表现出色,能够将视频分辨率显著提升,如从512 X 512扩展到1152 X 2048,同时生成高质量和视觉上令人愉悦的结果。
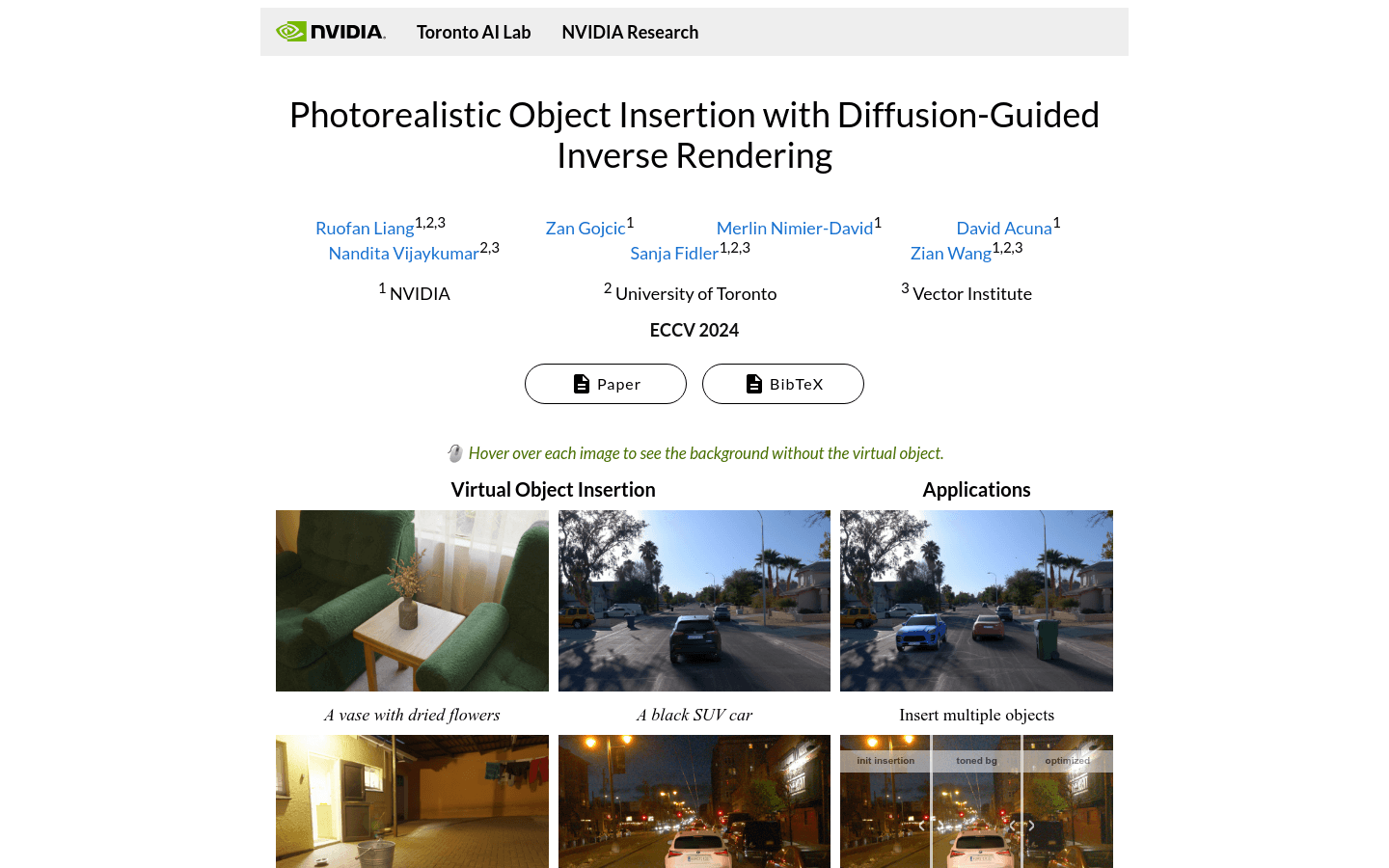
DiPIR是多伦多AI实验室与NVIDIA Research共同研发的一种基于物理的方法,它通过从单张图片中恢复场景照明,使得虚拟物体能够逼真地插入到室内外场景中。该技术不仅能够优化材质和色调映射,还能自动调整以适应不同的环境,提高图像的真实感。
GameNGen是一个完全由神经模型驱动的游戏引擎,能够实现与复杂环境的实时互动,并在长时间轨迹上保持高质量。它能够以每秒超过20帧的速度交互式模拟经典游戏《DOOM》,并且其下一帧预测的PSNR达到29.4,与有损JPEG压缩相当。人类评估者在区分游戏片段和模拟片段方面仅略优于随机机会。GameNGen通过两个阶段的训练:(1)一个RL-agent学习玩游戏并记录训练会话的动作和观察结果,成为生成模型的训练数据;(2)一个扩散模型被训练来预测下一帧,条件是过去的动作和观察序列。条件增强允许在长时间轨迹上稳定自回归生成。
ml-mdm是一个Python包,用于高效训练高质量的文本到图像扩散模型。该模型利用Matryoshka扩散模型技术,能够在1024x1024像素的分辨率上训练单一像素空间模型,展现出强大的零样本泛化能力。
TexGen是一个创新的多视角采样和重采样框架,用于根据任意文本描述合成3D纹理。它利用预训练的文本到图像的扩散模型,通过一致性视图采样和注意力引导的多视角采样策略,以及噪声重采样技术,显著提高了3D对象的纹理质量,具有高度的视角一致性和丰富的外观细节。
CatVTON是一款基于扩散模型的虚拟试穿技术,具有轻量级网络(总共899.06M参数)、参数高效训练(49.57M可训练参数)和简化推理(1024X768分辨率下<8G VRAM)。它通过简化的网络结构和推理过程,实现了快速且高效的虚拟试穿效果,特别适合时尚行业和个性化推荐场景。
DiT-MoE是一个使用PyTorch实现的扩散变换器模型,能够扩展到160亿参数,与密集网络竞争的同时展现出高度优化的推理能力。它代表了深度学习领域在处理大规模数据集时的前沿技术,具有重要的研究和应用价值。
TCAN是一种基于扩散模型的新型人像动画框架,它能够保持时间一致性并很好地泛化到未见过的领域。该框架通过特有的模块,如外观-姿态自适应层(APPA层)、时间控制网络和姿态驱动的温度图,来确保生成的视频既保持源图像的外观,又遵循驱动视频的姿态,同时保持背景的一致性。
RodinHD是一个基于扩散模型的高保真3D头像生成技术,由Bowen Zhang、Yiji Cheng等研究者开发,旨在从单一肖像图像生成细节丰富的3D头像。该技术解决了现有方法在捕捉发型等复杂细节时的不足,通过新颖的数据调度策略和权重整合正则化项,提高了解码器渲染锐利细节的能力。此外,通过多尺度特征表示和交叉注意力机制,优化了肖像图像的引导效果,生成的3D头像在细节上显著优于以往方法,并且能够泛化到野外肖像输入。
AsyncDiff 是一种用于并行化扩散模型的异步去噪加速方案,它通过将噪声预测模型分割成多个组件并分配到不同的设备上,实现了模型的并行处理。这种方法显著减少了推理延迟,同时对生成质量的影响很小。AsyncDiff 支持多种扩散模型,包括 Stable Diffusion 2.1、Stable Diffusion 1.5、Stable Diffusion x4 Upscaler、Stable Diffusion XL 1.0、ControlNet、Stable Video Diffusion 和 AnimateDiff。
Flash Diffusion 是一种高效的图像生成模型,通过少步骤生成高质量的图像,适用于多种图像处理任务,如文本到图像、修复、超分辨率等。该模型在 COCO2014 和 COCO2017 数据集上达到了最先进的性能,同时训练时间少,参数数量少。
UniAnimate是一个用于人物图像动画的统一视频扩散模型框架。它通过将参考图像、姿势指导和噪声视频映射到一个共同的特征空间,以减少优化难度并确保时间上的连贯性。UniAnimate能够处理长序列,支持随机噪声输入和首帧条件输入,显著提高了生成长期视频的能力。此外,它还探索了基于状态空间模型的替代时间建模架构,以替代原始的计算密集型时间Transformer。UniAnimate在定量和定性评估中都取得了优于现有最先进技术的合成结果,并且能够通过迭代使用首帧条件策略生成高度一致的一分钟视频。
HOI-Swap是一个基于扩散模型的视频编辑框架,专注于处理视频编辑中手与物体交互的复杂性。该模型通过自监督训练,能够在单帧中实现物体交换,并学习根据物体属性变化调整手的交互模式,如手的抓握方式。第二阶段将单帧编辑扩展到整个视频序列,通过运动对齐和视频生成,实现高质量的视频编辑。
Hallo是一个由复旦大学开发的肖像图像动画技术,它利用扩散模型生成逼真且动态的肖像动画。与传统依赖参数模型的中间面部表示不同,Hallo采用端到端的扩散范式,并引入了一个分层的音频驱动视觉合成模块,以增强音频输入和视觉输出之间的对齐精度,包括嘴唇、表情和姿态运动。该技术提供了对表情和姿态多样性的自适应控制,能够更有效地实现个性化定制,适用于不同身份的人。
Bootstrap3D是一个用于改善3D内容创造的框架,通过合成数据生成技术,解决了高质量3D资产稀缺的问题。它利用2D和视频扩散模型,基于文本提示生成多视角图像,并使用3D感知的MV-LLaVA模型筛选高质量数据,重写不准确的标题。该框架已生成了100万张高质量合成多视角图像,具有密集的描述性标题,以解决高质量3D数据的短缺问题。此外,它还提出了一种训练时间步重排(TTR)策略,利用去噪过程学习多视角一致性,同时保持原始的2D扩散先验。
Era3D是一个开源的高分辨率多视角扩散模型,它通过高效的行注意力机制来生成高质量的图像。该模型能够生成多视角的颜色和法线图像,支持自定义参数以获得最佳结果。Era3D在图像生成领域具有重要性,因为它提供了一种新的方法来生成逼真的三维图像。
ViViD是一个利用扩散模型进行视频虚拟试穿的新框架。它通过设计服装编码器提取精细的服装语义特征,并引入轻量级姿态编码器以确保时空一致性,生成逼真的视频试穿效果。ViViD收集了迄今为止规模最大、服装类型最多样化、分辨率最高的视频虚拟试穿数据集。
I2VEdit是一种创新的视频编辑技术,通过预训练的图像到视频模型,将单一帧的编辑扩展到整个视频。这项技术能够适应性地保持源视频的视觉和运动完整性,并有效处理全局编辑、局部编辑以及适度的形状变化,这是现有方法所不能实现的。I2VEdit的核心包括两个主要过程:粗略运动提取和外观细化,通过粗粒度注意力匹配进行精确调整。此外,还引入了跳过间隔策略,以减轻多个视频片段自动回归生成过程中的质量下降。实验结果表明,I2VEdit在细粒度视频编辑方面的优越性能,证明了其能够产生高质量、时间一致的输出。
StreamV2V是一个扩散模型,它通过用户提示实现了实时的视频到视频(V2V)翻译。与传统的批处理方法不同,StreamV2V采用流式处理方式,能够处理无限帧的视频。它的核心是维护一个特征库,该库存储了过去帧的信息。对于新进来的帧,StreamV2V通过扩展自注意力和直接特征融合技术,将相似的过去特征直接融合到输出中。特征库通过合并存储的和新的特征不断更新,保持紧凑且信息丰富。StreamV2V以其适应性和效率脱颖而出,无需微调即可与图像扩散模型无缝集成。
Make-An-Audio 2是一种基于扩散模型的文本到音频生成技术,由浙江大学、字节跳动和香港中文大学的研究人员共同开发。该技术通过使用预训练的大型语言模型(LLMs)解析文本,优化了语义对齐和时间一致性,提高了生成音频的质量。它还设计了基于前馈Transformer的扩散去噪器,以改善变长音频生成的性能,并增强时间信息的提取。此外,通过使用LLMs将大量音频标签数据转换为音频文本数据集,解决了时间数据稀缺的问题。
TryOnDiffusion是一种创新的图像合成技术,它通过两个UNets(Parallel-UNet)的结合,实现了在单一网络中同时保持服装细节和适应显著的身体姿势及形状变化。这项技术在保持服装细节的同时,能够适应不同的身体姿势和形状,解决了以往方法在细节保持和姿势适应上的不足,达到了业界领先的性能。
DIAMOND(DIffusion As a Model Of eNvironment Dreams)是一个在扩散世界模型中训练的强化学习代理,用于雅达利游戏中的视觉细节至关重要的世界建模。它通过自回归想象在Atari游戏子集上进行训练,可以快速安装并尝试预先训练的世界模型。
Slicedit是一种零样本视频编辑技术,它利用文本到图像的扩散模型,并结合时空切片来增强视频编辑中的时序一致性。该技术能够保留原始视频的结构和运动,同时符合目标文本描述。通过广泛的实验,证明了Slicedit在编辑真实世界视频方面具有明显优势。
CAT3D是一个利用多视角扩散模型从任意数量的输入图像生成新视角的3D场景的网站。它通过一个强大的3D重建管道,将生成的视图转化为可交互渲染的3D表示。整个处理时间(包括视图生成和3D重建)仅需一分钟。
MuLan是一个开源的多语言扩散模型,旨在为超过110种语言提供无需额外训练即可使用的扩散模型支持。该模型通过适配技术,使得原本需要大量训练数据和计算资源的扩散模型能够快速适应新的语言环境,极大地扩展了扩散模型的应用范围和语言多样性。MuLan的主要优点包括对多种语言的支持、优化的内存使用、以及通过技术报告和代码模型的发布,为研究人员和开发者提供了丰富的资源。
Lumina-T2X是一个先进的文本到任意模态生成框架,它能够将文本描述转换为生动的图像、动态视频、详细的多视图3D图像和合成语音。该框架采用基于流的大型扩散变换器(Flag-DiT),支持高达7亿参数,并能扩展序列长度至128,000个标记。Lumina-T2X集成了图像、视频、3D对象的多视图和语音频谱图到一个时空潜在标记空间中,可以生成任何分辨率、宽高比和时长的输出。
IDM-VTON是一种新型的扩散模型,用于基于图像的虚拟试穿任务,它通过结合视觉编码器和UNet网络的高级语义以及低级特征,生成具有高度真实感和细节的虚拟试穿图像。该技术通过提供详细的文本提示,增强了生成图像的真实性,并通过定制方法进一步提升了真实世界场景下的保真度和真实感。
Imagine Flash 是一种新型的扩散模型,它通过后向蒸馏框架,使用仅一到三个步骤就能实现高保真、多样化的样本生成。该模型包含三个关键组件:后向蒸馏、动态适应的知识转移以及噪声校正技术,显著提升了在极低步骤情况下的图像质量和样本多样性。
Diffusion-RWKV是一种基于RWKV架构的扩散模型,旨在提高扩散模型的可扩展性。它针对图像生成任务进行了相应的优化和改进,可以生成高质量的图像。该模型支持无条件和类条件训练,具有较好的性能和可扩展性。
DreamWalk是一种基于扩散指引的文本感知图像生成方法,可对图像的风格和内容进行细粒度控制,无需对扩散模型进行微调或修改内部层。支持多种风格插值和空间变化的引导函数,可广泛应用于各种扩散模型。
VAR是一种新的视觉自回归建模方法,能够超越扩散模型,实现更高效的图像生成。它建立了视觉生成的幂律scaling laws,并具备零shots的泛化能力。VAR提供了一系列不同规模的预训练模型,供用户探索和使用。
MuseV是一个基于扩散模型的虚拟人视频生成框架,支持无限长度视频生成,采用了新颖的视觉条件并行去噪方案。它提供了预训练的虚拟人视频生成模型,支持Image2Video、Text2Image2Video、Video2Video等功能,兼容Stable Diffusion生态系统,包括基础模型、LoRA、ControlNet等。它支持多参考图像技术,如IPAdapter、ReferenceOnly、ReferenceNet、IPAdapterFaceID等。MuseV的优势在于可生成高保真无限长度视频,定位于视频生成领域。
Make-Your-Anchor是一个基于扩散模型的2D虚拟形象生成框架。它只需一段1分钟左右的视频素材就可以自动生成具有精确上身和手部动作的主播风格视频。该系统采用了一种结构引导的扩散模型来将3D网格状态渲染成人物外观。通过两阶段训练策略,有效地将运动与特定外观相绑定。为了生成任意长度的时序视频,将frame-wise扩散模型的2D U-Net扩展到3D形式,并提出简单有效的批重叠时序去噪模块,从而突破推理时的视频长度限制。最后,引入了一种基于特定身份的面部增强模块,提高输出视频中面部区域的视觉质量。实验表明,该系统在视觉质量、时序一致性和身份保真度方面均优于现有技术。
ObjectDrop是一种监督方法,旨在实现照片级真实的物体删除和插入。它利用了一个计数事实数据集和自助监督技术。主要功能是可以从图像中移除物体及其对场景产生的影响(如遮挡、阴影和反射),也能够将物体以极其逼真的方式插入图像。它通过在一个小型的专门捕获的数据集上微调扩散模型来实现物体删除,而对于物体插入,它采用自助监督方式利用删除模型合成大规模的计数事实数据集,在此数据集上训练后再微调到真实数据集,从而获得高质量的插入模型。相比之前的方法,ObjectDrop在物体删除和插入的真实性上有了显著提升。
MOTIA是一个基于测试时适应的扩散方法,利用源视频内的内在内容和运动模式来有效进行视频外延画。该方法包括内在适应和外在渲染两个主要阶段,旨在提升视频外延画的质量和灵活性。
ELLA(Efficient Large Language Model Adapter)是一种轻量级方法,可将现有的基于CLIP的扩散模型配备强大的LLM。ELLA提高了模型的提示跟随能力,使文本到图像模型能够理解长文本。我们设计了一个时间感知语义连接器,从预训练的LLM中提取各种去噪阶段的时间步骤相关条件。我们的TSC动态地适应了不同采样时间步的语义特征,有助于在不同的语义层次上对U-Net进行冻结。ELLA在DPG-Bench等基准测试中表现优越,尤其在涉及多个对象组合、不同属性和关系的密集提示方面表现出色。
SLD是一个自纠正的LLM控制的扩散模型框架,它通过集成检测器增强生成模型,以实现精确的文本到图像对齐。SLD框架支持图像生成和精细编辑,并且与任何图像生成器兼容,如DALL-E 3,无需额外训练或数据。
ResAdapter是一个为扩散模型(如Stable Diffusion)设计的分辨率适配器,它能够在保持风格域一致性的同时,生成任意分辨率和宽高比的图像。与处理静态分辨率图像的多分辨率生成方法不同,ResAdapter直接生成动态分辨率的图像,提高了推理效率并减少了额外的推理时间。
DistriFusion是一个训练不需要的算法,可以利用多个GPU来加速扩散模型推理,而不会牺牲图像质量。DistriFusion可以根据使用的设备数量减少延迟,同时保持视觉保真度。
Neural Network Diffusion是由新加坡国立大学高性能计算与人工智能实验室开发的神经网络扩散模型。该模型利用扩散过程生成高质量的图像,适用于图像生成和修复等任务。
Sora是一个基于大规模训练的文本控制视频生成扩散模型。它能够生成长达1分钟的高清视频,涵盖广泛的视觉数据类型和分辨率。Sora通过在视频和图像的压缩潜在空间中训练,将其分解为时空位置补丁,实现了可扩展的视频生成。Sora还展现出一些模拟物理世界和数字世界的能力,如三维一致性和交互,揭示了继续扩大视频生成模型规模来发展高能力模拟器的前景。
Diffuse to Choose 是一种基于扩散的图像修复模型,主要用于虚拟试穿场景。它能够在修复图像时保留参考物品的细节,并且能够进行准确的语义操作。通过将参考图像的细节特征直接融入主要扩散模型的潜在特征图中,并结合感知损失来进一步保留参考物品的细节,该模型在快速推理和高保真细节方面取得了良好的平衡。
AnyDoor AI是一款突破性的图像生成工具,其设计理念基于扩散模型。它可以无缝地将目标物体嵌入到用户指定的新场景位置。AnyDoor先使用分割器去除目标物体的背景,然后使用ID提取器捕捉身份信息(ID令牌)。这些信息以及目标物体的细节被输入到一个预训练的文本到图像扩散模型中。在提取的信息和细节的指导下,该模型生成所需的图像。这个模型的独特之处在于,它不需要为每个物体调整参数。此外,它强大的自定义功能允许用户轻松地在场景图像中定位和调整物体,实现高保真和多样化的零次射物体-场景合成。除了照片编辑之外,该工具在电子商务领域也具有广阔的应用前景。借助AnyDoor,“一键更换服装”等概念得以实现,使用真人模型进行衣着互换,为用户提供更加个性化的购物体验。从更广泛的意义上说,AnyDoor也可以被理解为“一键Photoshop合成”或Photoshop中的“上下文感知移动工具”。它具有无缝图像集成和交换场景物体以及将图像对象放置到目标位置的功能。通过利用先进技术的力量,AnyDoor从本质上重新定义了图像操作,承诺在日常交互中提供多种更人性化的应用。
Make-A-Shape是一个新的3D生成模型,旨在以高效的方式训练大规模数据,能够利用1000万个公开可用的形状。我们创新性地引入了小波树表示法,通过制定子带系数滤波方案来紧凑地编码形状,然后通过设计子带系数打包方案将表示布置在低分辨率网格中,使其可生成扩散模型。此外,我们还提出了子带自适应训练策略,使我们的模型能够有效地学习生成粗细小波系数。最后,我们将我们的框架扩展为受额外输入条件控制,以使其能够从各种模态生成形状,例如单/多视图图像、点云和低分辨率体素。在大量实验中,我们展示了无条件生成、形状完成和条件生成等各种应用。我们的方法不仅在提供高质量结果方面超越了现有技术水平,而且在几秒内高效生成形状,通常在大多数条件下仅需2秒钟。
本文提出了一种简单有效的个性化图像复原方法,名为双枢纽调谐。该方法包含两个步骤:1) 通过微调条件性生成模型来利用编码器中的条件信息进行个性化;2) 固定生成模型,调节编码器的参数以适应强化的个性化先验。这可以生成保留个性化面部特征以及图像退化属性的自然图像。实验证明,与非个性化方法相比,该方法可以生成更高保真度的面部图像。
该论文介绍了一种基于感知损失的扩散模型,通过将感知损失直接纳入扩散训练中来提高样本质量。对于有条件生成,该方法仅改善样本质量而不会影响条件输入,因此不会牺牲样本多样性。对于无条件生成,这种方法也能提高样本质量。论文详细介绍了方法的原理和实验结果。
InstructVideo 是一种通过人类反馈用奖励微调来指导文本到视频的扩散模型的方法。它通过编辑的方式进行奖励微调,减少了微调成本,同时提高了微调效率。它使用已建立的图像奖励模型,通过分段稀疏采样和时间衰减奖励的方式提供奖励信号,显著提高了生成视频的视觉质量。InstructVideo 不仅能够提高生成视频的视觉质量,还能保持较强的泛化能力。欲了解更多信息,请访问官方网站。
X-Adapter是一个通用升级工具,可以使预训练的插件模块(例如ControlNet、LoRA)直接与升级的文本到图像扩散模型(例如SD-XL)配合使用,无需进一步重新训练。通过训练额外的网络来控制冻结的升级模型,X-Adapter保留旧模型的连接器,并添加可训练的映射层以连接不同版本模型的解码器进行特征重映射。重映射的特征将作为升级模型的引导。为了增强X-Adapter的引导能力,我们采用空文本训练策略。在训练后,我们还引入了两阶段去噪策略,以调整X-Adapter和升级模型的初始潜变量。X-Adapter展示了与各种插件的通用兼容性,并使不同版本的插件能够共同工作,从而扩展了扩散社区的功能。我们进行了大量实验证明,X-Adapter可能在升级的基础扩散模型中有更广泛的应用。
Upscale-A-Video是一个基于扩散的模型,通过将低分辨率视频和文本提示作为输入来提高视频的分辨率。该模型通过两个关键机制确保时间上的一致性:在局部,它将时间层集成到U-Net和VAE-Decoder中,保持短序列的一致性;在全局,引入了一个流引导的循环潜在传播模块,通过在整个序列中传播和融合潜在信息来增强整体视频的稳定性。由于扩散范式,我们的模型还通过允许文本提示指导纹理创建和可调噪声水平来平衡恢复和生成,实现了保真度和质量之间的权衡。大量实验证明,Upscale-A-Video在合成和真实世界基准以及AI生成的视频中均超越了现有方法,展现出令人印象深刻的视觉逼真和时间一致性。
MagicAnimate是一款基于扩散模型的先进框架,用于人体图像动画。它能够从单张图像和动态视频生成动画视频,具有时域一致性,能够保持参考图像的特征,并显著提升动画的保真度。MagicAnimate支持使用来自各种来源的动作序列进行图像动画,包括跨身份的动画和未见过的领域,如油画和电影角色。它还与DALLE3等T2I扩散模型无缝集成,可以根据文本生成的图像赋予动态动作。MagicAnimate由新加坡国立大学Show Lab和Bytedance字节跳动共同开发。