找到 124 个相关的AI工具
CameraBench 是一个用于分析视频中相机运动的模型,旨在通过视频理解相机的运动模式。它的主要优点在于利用生成性视觉语言模型进行相机运动的原理分类和视频文本检索。通过与传统的结构从运动 (SfM) 和实时定位与*构建 (SLAM) 方法进行比较,该模型在捕捉场景语义方面显示出了显著的优势。该模型已开源,适合研究人员和开发者使用,且后续将推出更多改进版本。
Describe Anything 模型(DAM)能够处理图像或视频的特定区域,并生成详细描述。它的主要优点在于可以通过简单的标记(点、框、涂鸦或掩码)来生成高质量的本地化描述,极大地提升了计算机视觉领域的图像理解能力。该模型由 NVIDIA 和多所大学联合开发,适合用于研究、开发和实际应用中。
EasyControl 是一个为 Diffusion Transformer(扩散变换器)提供高效灵活控制的框架,旨在解决当前 DiT 生态系统中存在的效率瓶颈和模型适应性不足等问题。其主要优点包括:支持多种条件组合、提高生成灵活性和推理效率。该产品是基于最新研究成果开发的,适合在图像生成、风格转换等领域使用。
Thera 是一种先进的超分辨率技术,能够在不同尺度下生成高质量图像。其主要优点在于内置物理观察模型,有效避免了混叠现象。该技术由 ETH Zurich 的研究团队开发,适用于图像增强和计算机视觉领域,尤其在遥感和摄影测量中具有广泛应用。
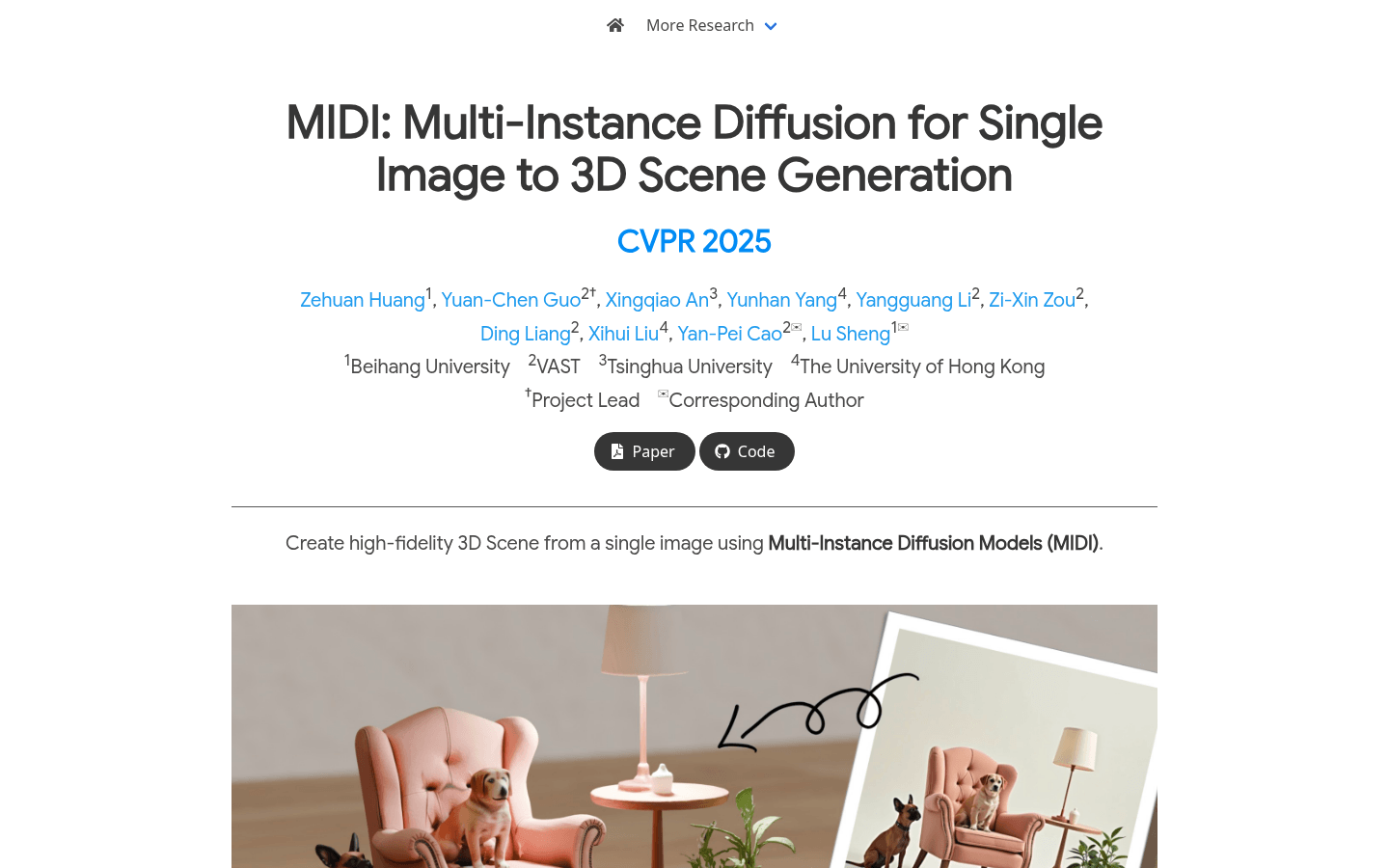
MIDI是一种创新的图像到3D场景生成技术,它利用多实例扩散模型,能够从单张图像中直接生成具有准确空间关系的多个3D实例。该技术的核心在于其多实例注意力机制,能够有效捕捉物体间的交互和空间一致性,无需复杂的多步骤处理。MIDI在图像到场景生成领域表现出色,适用于合成数据、真实场景数据以及由文本到图像扩散模型生成的风格化场景图像。其主要优点包括高效性、高保真度和强大的泛化能力。
GaussianCity是一个专注于高效生成无边界3D城市的框架,基于3D高斯绘制技术。该技术通过紧凑的3D场景表示和空间感知的高斯属性解码器,解决了传统方法在生成大规模城市场景时面临的内存和计算瓶颈。其主要优点是能够在单次前向传递中快速生成大规模3D城市,显著优于现有技术。该产品由南洋理工大学S-Lab团队开发,相关论文发表于CVPR 2025,代码和模型已开源,适用于需要高效生成3D城市环境的研究人员和开发者。
MLGym是由Meta的GenAI团队和UCSB NLP团队开发的一个开源框架和基准,用于训练和评估AI研究代理。它通过提供多样化的AI研究任务,推动强化学习算法的发展,帮助研究人员在真实世界的研究场景中训练和评估模型。该框架支持多种任务,包括计算机视觉、自然语言处理和强化学习等领域,旨在为AI研究提供一个标准化的测试平台。
Pippo 是由 Meta Reality Labs 和多所高校合作开发的生成模型,能够从单张普通照片生成高分辨率的多人视角视频。该技术的核心优势在于无需额外输入(如参数化模型或相机参数),即可生成高质量的 1K 分辨率视频。它基于多视角扩散变换器架构,具有广泛的应用前景,如虚拟现实、影视制作等。Pippo 的代码已开源,但不包含预训练权重,用户需要自行训练模型。
VideoWorld是一个专注于从纯视觉输入(无标签视频)中学习复杂知识的深度生成模型。它通过自回归视频生成技术,探索如何仅通过视觉信息学习任务规则、推理和规划能力。该模型的核心优势在于其创新的潜在动态模型(LDM),能够高效地表示多步视觉变化,从而显著提升学习效率和知识获取能力。VideoWorld在视频围棋和机器人控制任务中表现出色,展示了其强大的泛化能力和对复杂任务的学习能力。该模型的研究背景源于对生物体通过视觉而非语言学习知识的模仿,旨在为人工智能的知识获取开辟新的途径。
Video Depth Anything 是一个基于深度学习的视频深度估计模型,能够为超长视频提供高质量、时间一致的深度估计。该技术基于 Depth Anything V2 开发,具有强大的泛化能力和稳定性。其主要优点包括对任意长度视频的深度估计能力、时间一致性以及对开放世界视频的良好适应性。该模型由字节跳动的研究团队开发,旨在解决长视频深度估计中的挑战,如时间一致性问题和复杂场景的适应性问题。目前,该模型的代码和演示已公开,供研究人员和开发者使用。
ViTPose是一系列基于Transformer架构的人体姿态估计模型。它利用Transformer的强大特征提取能力,为人体姿态估计任务提供了简单而有效的基线。ViTPose模型在多个数据集上表现出色,具有较高的准确性和效率。该模型由悉尼大学社区维护和更新,提供了多种不同规模的版本,以满足不同应用场景的需求。在Hugging Face平台上,ViTPose模型以开源的形式供用户使用,用户可以方便地下载和部署这些模型,进行人体姿态估计相关的研究和应用开发。
TryOffAnyone是一个用于从穿着人身上生成平铺布料的深度学习模型。该模型能够将穿着衣物的人的图片转换成布料平铺图,这对于服装设计、虚拟试衣等领域具有重要意义。它通过深度学习技术,实现了高度逼真的布料模拟,使得用户可以更直观地预览衣物的穿着效果。该模型的主要优点包括逼真的布料模拟效果和较高的自动化程度,可以减少实际试衣过程中的时间和成本。
video-analyzer是一个视频分析工具,它结合了Llama的11B视觉模型和OpenAI的Whisper模型,通过提取关键帧、将它们输入视觉模型以获取细节,并结合每个帧的细节和可用的转录内容来描述视频中发生的事情。这个工具代表了计算机视觉、音频转录和自然语言处理的结合,能够生成视频内容的详细描述。它的主要优点包括完全本地运行无需云服务或API密钥、智能提取视频关键帧、使用OpenAI的Whisper进行高质量音频转录、使用Ollama和Llama3.2 11B视觉模型进行帧分析,以及生成自然语言描述的视频内容。
MegaSaM是一个系统,它允许从动态场景的单目视频中准确、快速、稳健地估计相机参数和深度图。该系统突破了传统结构从运动和单目SLAM技术的局限,这些技术通常假设输入视频主要包含静态场景和大量视差。MegaSaM通过深度视觉SLAM框架的精心修改,能够扩展到真实世界中复杂动态场景的视频,包括具有未知视场和不受限制相机路径的视频。该技术在合成和真实视频上的广泛实验表明,与先前和并行工作相比,MegaSaM在相机姿态和深度估计方面更为准确和稳健,运行时间更快或相当。
NVIDIA Jetson Orin Nano Super Developer Kit是一款紧凑型生成型AI超级计算机,提供了更高的性能和更低的价格。它支持从商业AI开发者到业余爱好者和学生的广泛用户群体,提供了1.7倍的生成型AI推理性能提升,67 INT8 TOPS的性能提升,以及102GB/s的内存带宽提升。这款产品是开发基于检索增强生成的LLM聊天机器人、构建视觉AI代理或部署基于AI的机器人的理想选择。
这是一个由卡内基梅隆大学提出的视频非可见物体分割和内容补全的模型。该模型通过条件生成任务的方式,利用视频生成模型的基础知识,对视频中的可见物体序列进行处理,以生成包括可见和不可见部分的物体掩码和RGB内容。该技术的主要优点包括能够处理高度遮挡的情况,并且能够对变形物体进行有效的处理。此外,该模型在多个数据集上的表现均优于现有的先进方法,特别是在物体被遮挡区域的非可见分割上,性能提升高达13%。
StableAnimator是首个端到端身份保留的视频扩散框架,能够在不进行后处理的情况下合成高质量视频。该技术通过参考图像和一系列姿势进行条件合成,确保了身份一致性。其主要优点在于无需依赖第三方工具,适合需要高质量人像动画的用户。
Controllable Human-Object Interaction Synthesis (CHOIS) 是一种先进的技术,它能够根据语言描述、初始物体和人类状态以及稀疏物体路径点来同时生成物体运动和人类运动。这项技术对于模拟真实的人类行为至关重要,尤其在需要精确手-物体接触和由地面支撑的适当接触的场景中。CHOIS通过引入物体几何损失作为额外的监督信息,以及在训练扩散模型的采样过程中设计指导项来强制执行接触约束,从而提高了生成物体运动与输入物体路径点之间的匹配度,并确保了交互的真实性。
PSHuman是一个创新的框架,它利用多视图扩散模型和显式重构技术,从单张图片中重建出逼真的3D人体模型。这项技术的重要性在于它能够处理复杂的自遮挡问题,并且在生成的面部细节上避免了几何失真。PSHuman通过跨尺度扩散模型联合建模全局全身形状和局部面部特征,实现了细节丰富且保持身份特征的新视角生成。此外,PSHuman还通过SMPL-X等参数化模型提供的身体先验,增强了不同人体姿态下的跨视图身体形状一致性。PSHuman的主要优点包括几何细节丰富、纹理保真度高以及泛化能力强。
text-to-pose是一个研究项目,旨在通过文本描述生成人物姿态,并利用这些姿态生成图像。该技术结合了自然语言处理和计算机视觉,通过改进扩散模型的控制和质量,实现了从文本到图像的生成。项目背景基于NeurIPS 2024 Workshop上发表的论文,具有创新性和前沿性。该技术的主要优点包括提高图像生成的准确性和可控性,以及在艺术创作和虚拟现实等领域的应用潜力。
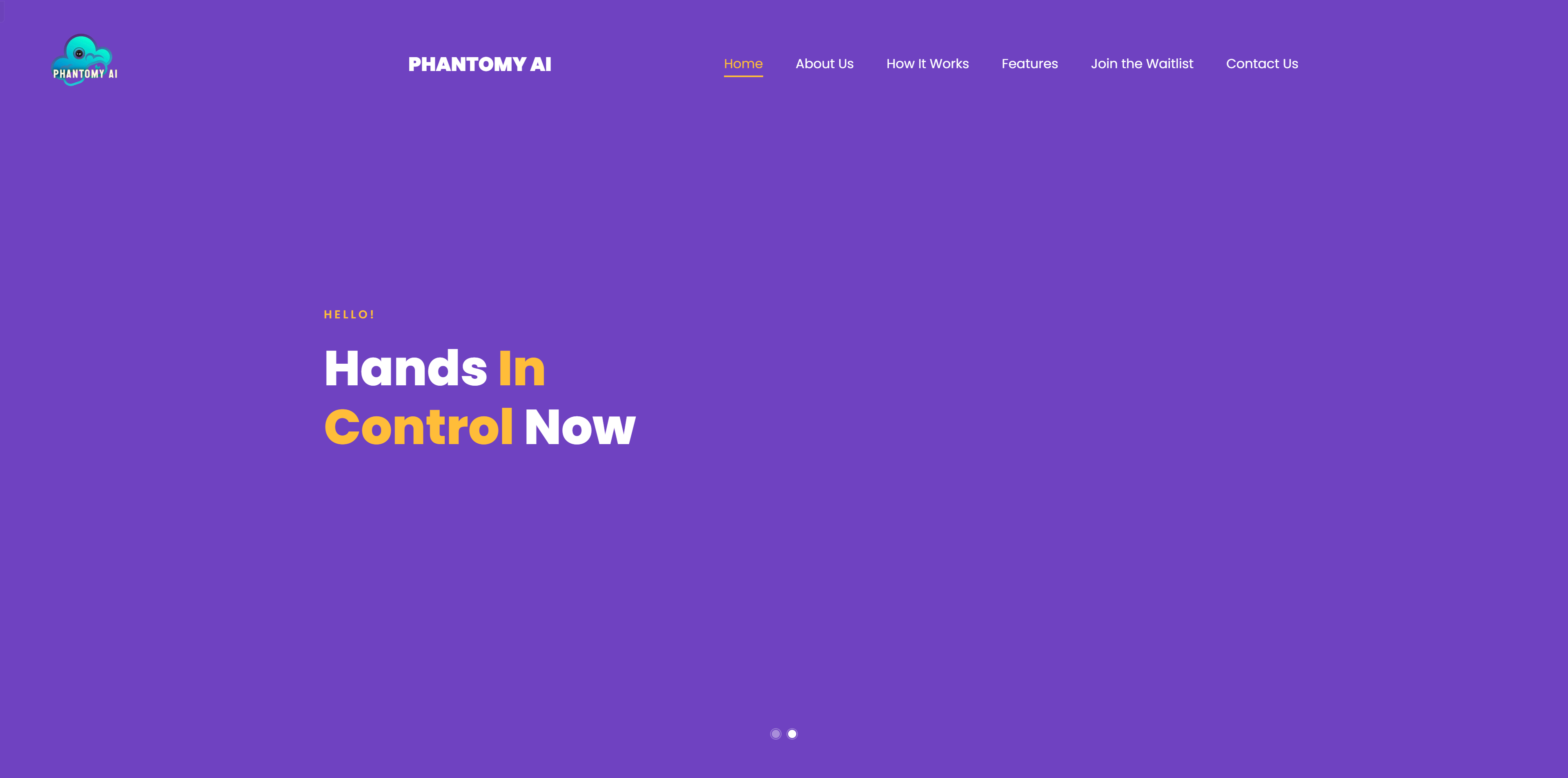
Phantomy AI是一款利用计算机视觉软件,通过屏幕对象检测和手势识别技术,增强用户交互和演示的先进工具。它无需额外硬件,即可通过直观的手势控制屏幕,为用户提供了一种无需接触的交互方式。Phantomy AI的主要优点包括高精准的屏幕对象检测、基于手势的控制、流畅的幻灯片导航、增强的用户体验和广泛的应用场景。产品背景信息显示,Phantomy AI由AI工程师Almajd Ismail开发,他拥有软件开发和全栈开发的背景。关于价格和定位,页面上没有提供具体信息。
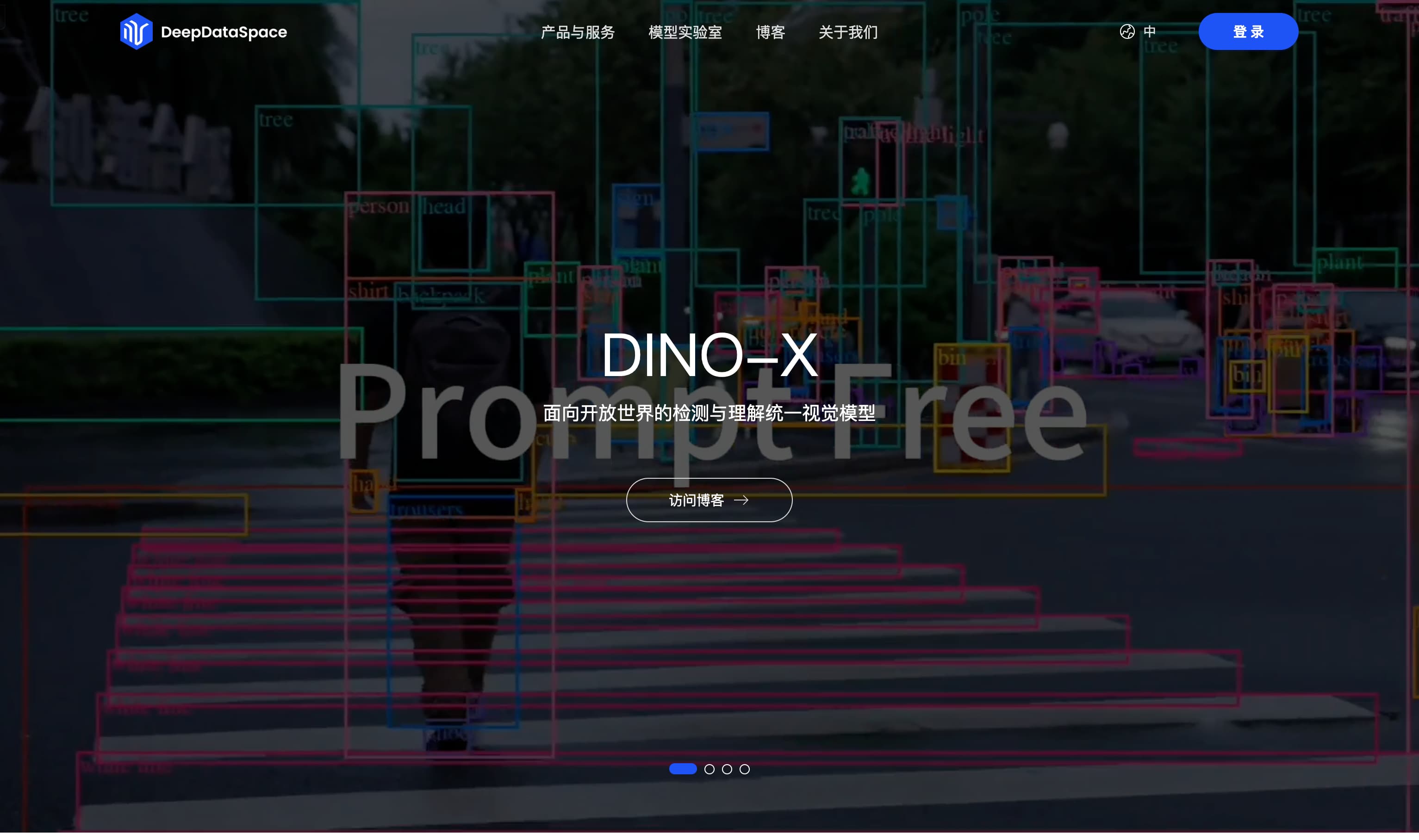
DINO-X是一个以物体感知为核心的视觉大模型,具备开集检测、智能问答、人体姿态、物体计数、服装换色等核心能力。它不仅能识别已知目标,还能灵活应对未知类别,凭借先进算法,模型具备出色的适应性和鲁棒性,能够精准应对各种不可预见的挑战,提供针对复杂视觉数据的全方位解决方案。DINO-X的应用场景广泛,包括机器人、农业、零售行业、安防监控、交通管理、制造业、智能家居、物流与仓储、娱乐媒体等,是DeepDataSpace公司在计算机视觉技术领域的旗舰产品。
Data Annotation Platform是一个端到端的数据标注平台,允许用户上传计算机视觉数据,选择标注类型,并下载结果,无需任何最低承诺。该平台支持多种数据标注类型,包括矩形、多边形、3D立方体、关键点、语义分割、实例分割和泛视觉分割等,服务于AI项目经理、机器学习工程师、AI初创公司和研究团队,解决他们在数据标注过程中遇到的挑战。平台以其无缝执行、成本计算器、指令生成器、免费任务、API接入和团队访问等特点,为用户提供了一个简单、高效、成本效益高的数据标注解决方案。
AutoSeg-SAM2是一个基于Segment-Anything-2(SAM2)和Segment-Anything-1(SAM1)的自动全视频分割工具,它能够对视频中的每个对象进行追踪,并检测可能的新对象。该工具的重要性在于它能够提供静态分割结果,并利用SAM2对这些结果进行追踪,这对于视频内容分析、对象识别和视频编辑等领域具有重要意义。产品背景信息显示,它是由zrporz开发的,并且是基于Facebook Research的SAM2和zrporz自己的SAM1。价格方面,由于这是一个开源项目,因此它是免费的。
TurboLens是一个集OCR、计算机视觉和生成式AI于一体的全功能平台,它能够自动化地从非结构化图像中快速生成洞见,简化工作流程。产品背景信息显示,TurboLens旨在通过其创新的OCR技术和AI驱动的翻译及分析套件,从印刷和手写文档中提取定制化的洞见。此外,TurboLens还提供了数学公式和表格识别功能,将图像转换为可操作的数据,并将数学公式翻译成LaTeX格式,表格转换为Excel格式。产品价格方面,TurboLens提供免费和付费两种计划,满足不同用户的需求。
LLaMA-Mesh是一项将大型语言模型(LLMs)预训练在文本上扩展到生成3D网格的能力的技术。这项技术利用了LLMs中已经嵌入的空间知识,并实现了对话式3D生成和网格理解。LLaMA-Mesh的主要优势在于它能够将3D网格的顶点坐标和面定义表示为纯文本,允许与LLMs直接集成而无需扩展词汇表。该技术的主要优点包括能够从文本提示生成3D网格、按需产生交错的文本和3D网格输出,以及理解和解释3D网格。LLaMA-Mesh在保持强大的文本生成性能的同时,实现了与从头开始训练的模型相当的网格生成质量。
CountAnything是一个前沿应用,利用先进的计算机视觉算法实现自动、准确的物体计数。它适用于多种场景,包括工业、养殖业、建筑、医药和零售等。该产品的主要优点在于其高精度和高效率,能够显著提升计数工作的准确性和速度。产品背景信息显示,CountAnything目前已开放给非中国大陆地区用户使用,并且提供免费试用。
NVIDIA AI Blueprint for Video Search and Summarization是一个基于NVIDIA NIM微服务和生成式AI模型的参考工作流程,用于构建能够理解自然语言提示并执行视觉问题回答的视觉AI代理。这些代理可以部署在工厂、仓库、零售店、机场、交通路口等多种场景中,帮助运营团队从自然交互中生成的丰富洞察中做出更好的决策。
GenXD是一个专注于3D和4D场景生成的框架,它利用日常生活中常见的相机和物体运动来联合研究一般的3D和4D生成。由于社区缺乏大规模的4D数据,GenXD首先提出了一个数据策划流程,从视频中获取相机姿态和物体运动强度。基于此流程,GenXD引入了一个大规模的现实世界4D场景数据集:CamVid-30K。通过利用所有3D和4D数据,GenXD框架能够生成任何3D或4D场景。它提出了多视图-时间模块,这些模块分离相机和物体运动,无缝地从3D和4D数据中学习。此外,GenXD还采用了掩码潜在条件,以支持多种条件视图。GenXD能够生成遵循相机轨迹的视频以及可以提升到3D表示的一致3D视图。它在各种现实世界和合成数据集上进行了广泛的评估,展示了GenXD在3D和4D生成方面与以前方法相比的有效性和多功能性。
Tencent-Hunyuan-Large(混元大模型)是由腾讯推出的业界领先的开源大型混合专家(MoE)模型,拥有3890亿总参数和520亿激活参数。该模型在自然语言处理、计算机视觉和科学任务等领域取得了显著进展,特别是在处理长上下文输入和提升长上下文任务处理能力方面表现出色。混元大模型的开源,旨在激发更多研究者的创新灵感,共同推动AI技术的进步和应用。
Flex3D是一个两阶段流程,能够从单张图片或文本提示生成高质量的3D资产。该技术代表了3D重建领域的最新进展,可以显著提高3D内容的生成效率和质量。Flex3D的开发得到了Meta的支持,并且团队成员在3D重建和计算机视觉领域有着深厚的背景。
StableDelight是一个先进的模型,专注于从纹理表面去除镜面反射。它基于StableNormal的成功,后者专注于提高单目法线估计的稳定性。StableDelight通过应用这一概念来解决去除反射的挑战性任务。训练数据包括Hypersim、Lumos以及来自TSHRNet的各种镜面高光去除数据集。此外,我们在扩散训练过程中整合了多尺度SSIM损失和随机条件尺度技术,以提高一步扩散预测的清晰度。
Colorful Diffuse Intrinsic Image Decomposition 是一种图像处理技术,它能够将野外拍摄的照片分解为反照率、漫反射阴影和非漫反射残留部分。这项技术通过逐步移除单色照明和Lambertian世界假设,实现了对图像中多彩漫反射阴影的估计,包括多个照明和场景中的二次反射,同时模型了镜面反射和可见光源。这项技术对于图像编辑应用,如去除镜面反射和像素级白平衡,具有重要意义。
diffusion-e2e-ft是一个开源的图像条件扩散模型微调工具,它通过微调预训练的扩散模型来提高特定任务的性能。该工具支持多种模型和任务,如深度估计和法线估计,并提供了详细的使用说明和模型检查点。它在图像处理和计算机视觉领域具有重要应用,能够显著提升模型在特定任务上的准确性和效率。
opencv_contrib是OpenCV的额外模块库,用于开发和测试新的图像处理功能。这些模块通常在API稳定、经过充分测试并被广泛接受后,才会被整合到OpenCV的核心库中。该库允许开发者使用最新的图像处理技术,推动计算机视觉领域的创新。
OpenCV是一个跨平台的开源计算机视觉和机器学习软件库,它提供了一系列编程功能,包括但不限于图像处理、视频分析、特征检测、机器学习等。该库广泛应用于学术研究和商业项目中,因其强大的功能和灵活性而受到开发者的青睐。
GVHMR是一种创新的人体运动恢复技术,它通过重力视角坐标系统来解决从单目视频中恢复世界定位的人体运动的问题。该技术能够减少学习图像-姿态映射的歧义,并且避免了自回归方法中连续图像的累积误差。GVHMR在野外基准测试中表现出色,不仅在准确性和速度上超越了现有的最先进技术,而且其训练过程和模型权重对公众开放,具有很高的科研和实用价值。
Shangchen Zhou 是一位在计算机视觉和机器学习领域有着深厚研究背景的博士生,他的工作主要集中在视觉内容增强、编辑和生成AI(2D和3D)上。他的研究成果广泛应用于图像和视频的超分辨率、去模糊、低光照增强等领域,为提升视觉内容的质量和用户体验做出了重要贡献。
Segment Anything 2 for Surgical Video Segmentation 是一个基于Segment Anything Model 2的手术视频分割模型。它利用先进的计算机视觉技术,对手术视频进行自动分割,以识别和定位手术工具,提高手术视频分析的效率和准确性。该模型适用于内窥镜手术、耳蜗植入手术等多种手术场景,具有高精度和高鲁棒性的特点。
AvatarPose是一种用于从稀疏多视角视频中估计多个紧密互动人的3D姿态和形状的方法。该技术通过重建每个人的个性化隐式神经化身,并将其作为先验,通过颜色和轮廓渲染损失来细化姿态,显著提高了在紧密互动中估计3D姿态的鲁棒性和精确度。
SA-V Dataset是一个专为训练通用目标分割模型设计的开放世界视频数据集,包含51K个多样化视频和643K个时空分割掩模(masklets)。该数据集用于计算机视觉研究,允许在CC BY 4.0许可下使用。视频内容多样,包括地点、对象和场景等主题,掩模从建筑物等大规模对象到室内装饰等细节不等。
Meta Segment Anything Model 2 (SAM 2)是Meta公司开发的下一代模型,用于视频和图像中的实时、可提示的对象分割。它实现了最先进的性能,并且支持零样本泛化,即无需定制适配即可应用于之前未见过的视觉内容。SAM 2的发布遵循开放科学的方法,代码和模型权重在Apache 2.0许可下共享,SA-V数据集也在CC BY 4.0许可下共享。
roboflow/sports 是一个开源的计算机视觉工具集,专注于体育领域的应用。它利用先进的图像处理技术,如目标检测、图像分割、关键点检测等,来解决体育分析中的挑战。这个工具集由Roboflow开发,旨在推动计算机视觉技术在体育领域的应用,并通过社区贡献不断优化。
VGGSfM是一种基于深度学习的三维重建技术,旨在从一组不受限制的2D图像中重建场景的相机姿态和3D结构。该技术通过完全可微分的深度学习框架,实现端到端的训练。它利用深度2D点跟踪技术提取可靠的像素级轨迹,同时基于图像和轨迹特征恢复所有相机,并通过可微分的捆绑调整层优化相机和三角化3D点。VGGSfM在CO3D、IMC Phototourism和ETH3D三个流行数据集上取得了最先进的性能。
MASt3R是由Naver Corporation开发的一种用于3D图像匹配的先进模型,它专注于提升计算机视觉领域中的几何3D视觉任务。该模型利用了最新的深度学习技术,通过训练能够实现对图像之间精确的3D匹配,对于增强现实、自动驾驶以及机器人导航等领域具有重要意义。
GaussianCube是一种创新的3D辐射表示方法,它通过结构化和显式的表示方式,极大地促进了三维生成建模的发展。该技术通过使用一种新颖的密度约束高斯拟合算法和最优传输方法,将高斯函数重新排列到预定义的体素网格中,从而实现了高精度的拟合。与传统的隐式特征解码器或空间无结构的辐射表示相比,GaussianCube具有更少的参数和更高的质量,使得3D生成建模变得更加容易。
L4GM是一个4D大型重建模型,能够从单视图视频输入中快速生成动画对象。它采用了一种新颖的数据集,包含多视图视频,这些视频展示了Objaverse中渲染的动画对象。该数据集包含44K种不同的对象和110K个动画,从48个视角渲染,生成了12M个视频,总共包含300M帧。L4GM基于预训练的3D大型重建模型LGM构建,该模型能够从多视图图像输入中输出3D高斯椭球。L4GM输出每帧的3D高斯Splatting表示,然后将其上采样到更高的帧率以实现时间平滑。此外,L4GM还添加了时间自注意力层,以帮助学习时间上的一致性,并使用每个时间步的多视图渲染损失来训练模型。
UniAnimate是一个用于人物图像动画的统一视频扩散模型框架。它通过将参考图像、姿势指导和噪声视频映射到一个共同的特征空间,以减少优化难度并确保时间上的连贯性。UniAnimate能够处理长序列,支持随机噪声输入和首帧条件输入,显著提高了生成长期视频的能力。此外,它还探索了基于状态空间模型的替代时间建模架构,以替代原始的计算密集型时间Transformer。UniAnimate在定量和定性评估中都取得了优于现有最先进技术的合成结果,并且能够通过迭代使用首帧条件策略生成高度一致的一分钟视频。
MASA是一个用于视频帧中对象匹配的先进模型,它能够处理复杂场景中的多目标跟踪(MOT)。MASA不依赖于特定领域的标注视频数据集,而是通过Segment Anything Model(SAM)丰富的对象分割,学习实例级别的对应关系。MASA设计了一个通用适配器,可以与基础的分割或检测模型配合使用,实现零样本跟踪能力,即使在复杂领域中也能表现出色。
VastGaussian是一个3D场景重建的开源项目,它通过使用3D高斯来模拟大型场景的几何和外观信息。这个项目是作者从零开始实现的,可能存在一些错误,但为3D场景重建领域提供了一种新的尝试。项目的主要优点包括对大型数据集的处理能力,以及对原始3DGS项目的改进,使其更易于理解和使用。
AI Online Course是一个互动学习平台,提供清晰简明的人工智能介绍,使复杂的概念易于理解。它涵盖机器学习、深度学习、计算机视觉、自动驾驶、聊天机器人等方面的知识,并强调实际应用和技术优势。
SadCaptcha是一个解决TikTok验证码的插件,它可以快速、准确地解决TikTok的旋转、拼图和3D形状验证码。它使用先进的计算机视觉算法,能够高效解决验证码,并且适用于任何设备和屏幕分辨率。
JavaVision是一个基于Java开发的全能视觉智能识别项目,它不仅实现了PaddleOCR-V4、YoloV8物体识别、人脸识别、以图搜图等核心功能,还可以轻松扩展到其他领域,如语音识别、动物识别、安防检查等。项目特点包括使用SpringBoot框架、多功能性、高性能、可靠稳定、易于集成和灵活可拓展。JavaVision旨在为Java开发者提供一个全面的视觉智能识别解决方案,让他们能够以熟悉且喜爱的编程语言构建出先进、可靠且易于集成的AI应用。
CoreNet 是一个深度神经网络工具包,使研究人员和工程师能够训练标准和新颖的小型和大型规模模型,用于各种任务,包括基础模型(例如 CLIP 和 LLM)、对象分类、对象检测和语义分割。
SAM是一个先进的视频对象分割模型,它结合了光学流动和RGB信息,能够发现并分割视频中的移动对象。该模型在单对象和多对象基准测试中均取得了显著的性能提升,同时保持了对象的身份一致性。
ZeST是由牛津大学、Stability AI 和 MIT CSAIL 研究团队共同开发的图像材质迁移技术,它能够在无需任何先前训练的情况下,实现从一张图像到另一张图像中对象的材质迁移。ZeST支持单一材质的迁移,并能处理单一图像中的多重材质编辑,用户可以轻松地将一种材质应用到图像中的多个对象上。此外,ZeST还支持在设备上快速处理图像,摆脱了对云计算或服务器端处理的依赖,大大提高了效率。
PhysAvatar是一个结合逆向渲染和逆向物理的创新框架,可以从多视角视频数据中自动估计人体形状、外表以及服装的物理参数。它采用网格对齐的4D高斯时空网格跟踪技术和基于物理的逆向渲染器来估计内在的材料属性。PhysAvatar集成了物理模拟器,使用基于梯度的优化方法以原理性的方式估计服装的物理参数。这些创新能力使PhysAvatar能够在训练数据之外的运动和照明条件下,渲染出高质量的穿着宽松衣服的新视角头像。
Open-Sora-Plan是一个开源项目,旨在为开源社区提供高质量的视频数据集。该项目已经爬取并处理了40258个来自开源网站的高质量视频,涵盖了60%的横屏视频。同时还提供了自动生成的密集字幕,供机器学习等应用使用。该项目免费开源,欢迎大家共同参与和支持。
Scenic 是一个专注于基于注意力模型的计算机视觉研究的代码库,提供优化训练和评估循环、基线模型等功能,适用于图像、视频、音频等多模态数据。提供 SOTA 模型和基线,支持快速原型设计,价格免费。
华为开源自研AI框架MindSpore。自动微分、并行加持,一次训练,可多场景部署。支持端边云全场景的深度学习训练推理框架,主要应用于计算机视觉、自然语言处理等AI领域,面向数据科学家、算法工程师等人群。主要具备基于源码转换的通用自动微分、自动实现分布式并行训练、数据处理、以及图执行引擎等功能特性。借助自动微分,轻松训练神经网络。框架开源,华为培育AI开发生态。
ObjectDrop是一种监督方法,旨在实现照片级真实的物体删除和插入。它利用了一个计数事实数据集和自助监督技术。主要功能是可以从图像中移除物体及其对场景产生的影响(如遮挡、阴影和反射),也能够将物体以极其逼真的方式插入图像。它通过在一个小型的专门捕获的数据集上微调扩散模型来实现物体删除,而对于物体插入,它采用自助监督方式利用删除模型合成大规模的计数事实数据集,在此数据集上训练后再微调到真实数据集,从而获得高质量的插入模型。相比之前的方法,ObjectDrop在物体删除和插入的真实性上有了显著提升。
T-Rex2是一种范式突破的物体检测技术,能够识别从日常到深奥的各种物体,无需任务特定调优或大量训练数据集。它将视觉和文本提示相结合,赋予其强大的零射能力,可广泛应用于各种场景的物体检测任务。T-Rex2综合了四个组件:图像编码器、视觉提示编码器、文本提示编码器和框解码器。它遵循DETR的端到端设计原理,涵盖多种应用场景。T-Rex2在COCO、LVIS、ODinW和Roboflow100等四个学术基准测试中取得了最优秀的表现。
StyleSketch是一种从面部图像中提取高分辨率风格化素描的方法。该方法利用预训练StyleGAN的深层特征的丰富语义,能够仅使用16对人脸和相应素描图像对来训练素描生成器。通过分阶段学习中的部分损失,StyleSketch能够快速收敛并提取高质量的素描。与现有的最先进素描提取方法和少量样本图像适应方法相比,StyleSketch在提取高分辨率抽象面部素描的任务上表现更优。
Skyvern是一个自动化工具,它结合了大型语言模型(LLMs)和计算机视觉技术,用于自动化基于浏览器的工作流程。它提供了一个简单的API端点,可以完全自动化手动工作流程,替代易碎或不可靠的自动化解决方案。
Glyph-ByT5是一种定制的文本编码器,旨在提高文本到图像生成模型中的视觉文本渲染准确性。它通过微调字符感知的ByT5编码器并使用精心策划的成对字形文本数据集来实现。将Glyph-ByT5与SDXL集成后,形成了Glyph-SDXL模型,使设计图像生成中的文本渲染准确性从低于20%提高到接近90%。该模型还能够实现段落文本的自动多行布局渲染,字符数量从几十到几百字符都能保持较高的拼写准确性。此外,通过使用少量高质量的包含视觉文本的真实图像进行微调,Glyph-SDXL在开放域真实图像中的场景文本渲染能力也有了大幅提升。这些令人鼓舞的成果旨在鼓励进一步探索为不同具有挑战性的任务设计定制的文本编码器。
LensAI是一个基于人工智能的上下文广告平台,通过视频和图像分析将广告直接放置在对象中,实现有效的流量变现。LensAI识别对象、标志、动作和上下文,并将其与相关广告进行匹配,精细调整定向,提供显著的广告效果和高回报率。LensAI提供了先进的图片和视频广告解决方案,为数字广告生态系统的所有关键利益相关者带来了利益。
FineControlNet是一个基于Pytorch的官方实现,用于生成可通过空间对齐的文本控制输入(如2D人体姿势)和实例特定的文本描述来控制图像实例的形状和纹理的图像。它可以使用从简单的线条画作为空间输入,到复杂的人体姿势。FineControlNet确保了实例和环境之间自然的交互和视觉协调,同时获得了Stable Diffusion的质量和泛化能力,但具有更多的控制能力。
DUSt3R是一种新颖的密集和无约束立体3D重建方法,适用于任意图像集合。它不需要事先了解相机校准或视点姿态信息,通过将成对重建问题视为点图的回归,放宽了传统投影相机模型的严格约束。DUSt3R提供了一种统一的单目和双目重建方法,并在多图像情况下提出了一种简单有效的全局对齐策略。基于标准的Transformer编码器和解码器构建网络架构,利用强大的预训练模型。DUSt3R直接提供场景的3D模型和深度信息,并且可以从中恢复像素匹配、相对和绝对相机信息。
U-xer是一款基于计算机视觉的测试自动化和RPA工具,旨在自动化屏幕上看到的任何内容,包括Web和桌面应用程序。它具有易用和高级两种模式,可以满足非技术用户和高级用户的不同需求。U-xer能够识别屏幕,像人类一样解释屏幕内容,实现更自然、准确的自动化。它适用于各种应用场景,包括Web应用程序、桌面软件、移动设备等,并提供定制化解决方案。U-xer的定价和定位请查看官方网站。
YOLOv8是YOLO系列目标检测模型的最新版本,能够在图像或视频中准确快速地识别和定位多个对象,并实时跟踪它们的移动。相比之前版本,YOLOv8在检测速度和精确度上都有很大提升,同时支持多种额外的计算机视觉任务,如实例分割、姿态估计等。YOLOv8可通过多种格式部署在不同硬件平台上,提供一站式的端到端目标检测解决方案。
VisFusion是一个利用视频数据进行在线3D场景重建的技术,它能够实时地从视频中提取和重建出三维环境。这项技术结合了计算机视觉和深度学习,为用户提供了一个强大的工具,用于创建精确的三维模型。
Sora 是 OpenAI 开发的文本到视频生成模型,能够根据文本描述生成长达1分钟的逼真图像序列。它具有理解和模拟物理世界运动的能力,目标是训练出帮助人们解决需要实物交互的问题的模型。Sora 可以解释长篇提示,根据文本输入生成各种人物、动物、景观和城市景象。它的缺点是难以准确描绘复杂场景的物理学以及理解因果关系。
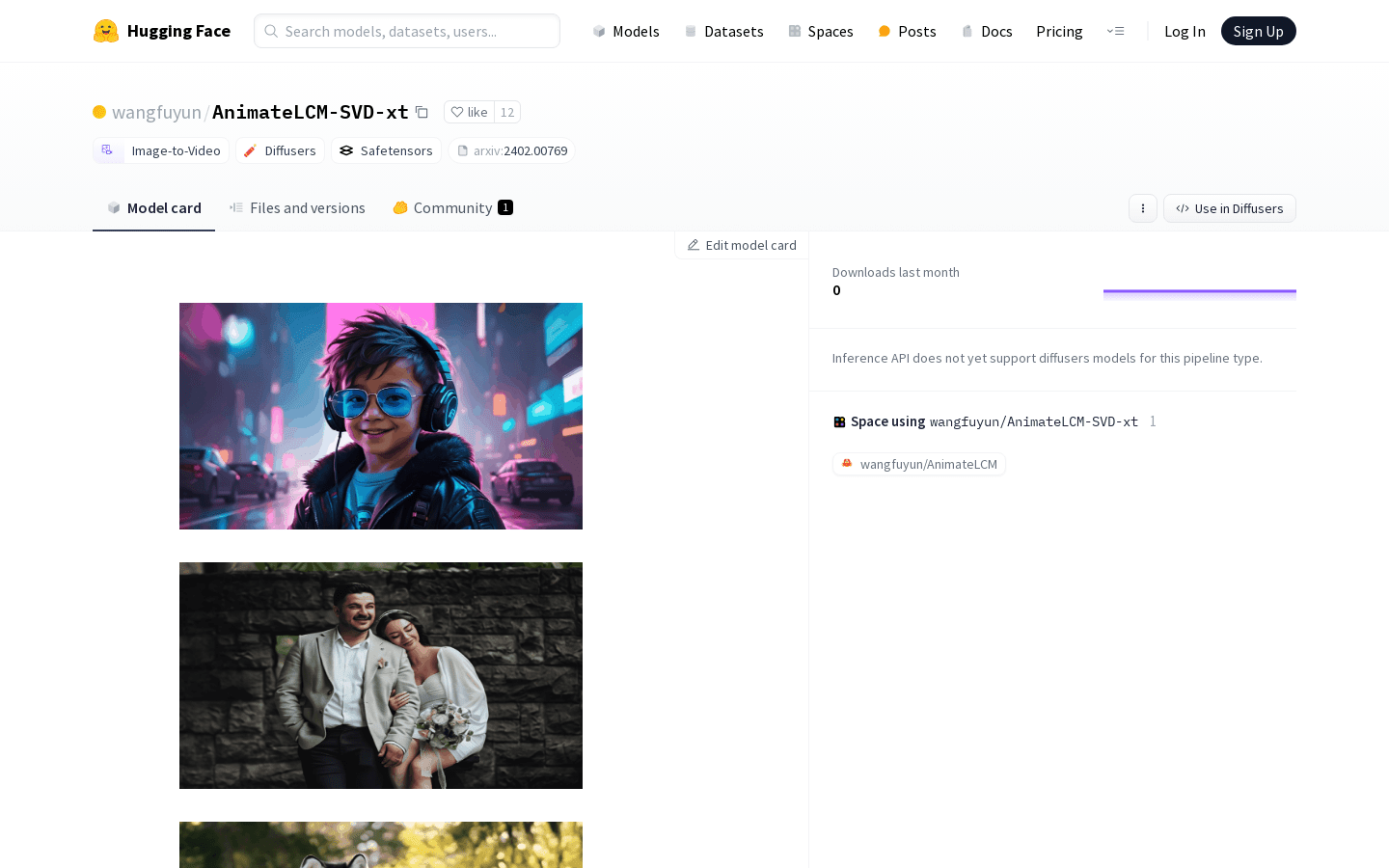
AnimateLCM-SVD-xt是一种新的图像到视频生成模型,可以在很少的步骤内生成高质量、连贯性好的视频。该模型通过一致性知识蒸馏和立体匹配学习技术,使生成视频更加平稳连贯,同时大大减少了计算量。关键特点包括:1) 4-8步内生成25帧576x1024分辨率视频;2) 比普通视频diffusion模型降低12.5倍计算量;3) 生成视频质量好,无需额外分类器引导。
GLIGEN是一个开放式的基于文本提示的图像生成模型,它可以基于文本描述和边界框等限定条件生成图像。该模型通过冻结预训练好的文本到图像Diffusion模型的参数,并在其中插入新的数据来实现。这种模块化设计可以高效地进行训练,并具有很强的推理灵活性。GLIGEN可以支持开放世界的有条件图像生成,对新出现的概念和布局也具有很强的泛化能力。
Ollama是一个开源项目,能够在Windows本地运行各类大型AI模型,支持GPU加速,内置OpenAI模型兼容层,提供永久在线的API。用户可以无缝访问Ollama的完整模型库,进行图片和语音交互。Ollama免配置就能获得强大的AI能力,帮助开发者和创作者在Windows上构建AI应用。
Vision Arena是一个由Hugging Face创建的开源平台,用于测试和比较不同的计算机视觉模型效果。它提供了一个友好的界面,允许用户上传图片并通过不同模型处理,从而直观地对比结果质量。平台预装了主流的图像分类、对象检测、语义分割等模型,也支持自定义模型。关键优势是开源免费,使用简单,支持多模型并行测试,有利于模型效果评估和选择。适用于计算机视觉研发人员、算法工程师等角色,可以加速计算机视觉模型的实验和调优。
ImageTools是一款通用抠图工具,通过先进的计算机视觉算法,精确自动地从照片中移除背景,突显主体。适用于图像编辑、广告设计、电商等场景,提供用户在各种情境中展示图像主体的灵活性和创造空间。
LiveFood是一个包含超过5100个美食视频的数据集,视频包括食材、烹饪、呈现和食用四个领域,所有视频均由专业工人精细注释,并采用严格的双重检查机制进一步保证注释质量。我们还提出了全局原型编码(GPE)模型来处理这个增量学习问题,与传统技术相比获得了竞争性的性能。
VMamba是一种视觉状态空间模型,结合了卷积神经网络(CNNs)和视觉Transformer(ViTs)的优势,实现了线性复杂度而不牺牲全局感知。引入了Cross-Scan模块(CSM)来解决方向敏感问题,能够在各种视觉感知任务中展现出优异的性能,并且随着图像分辨率的增加,相对已有基准模型表现出更为显著的优势。
Vision Mamba是一个高效的视觉表示学习框架,使用双向Mamba模块构建,可以克服计算和内存限制,进行高分辨率图像的Transformer风格理解。它不依赖自注意力机制,通过位置嵌入和双向状态空间模型压缩视觉表示,实现更高性能,计算和内存效率也更好。该框架在 ImageNet分类、COCO目标检测和ADE20k语义分割任务上,性能优于经典的视觉Transformers,如DeiT,但计算和内存效率提高2.8倍和86.8%。
SIFU是一个利用侧视图像重建高质量3D服装虚拟人物模型的方法。它的核心创新点是提出了一种新的基于侧视图像的隐式函数,可以增强特征提取和提高几何精度。此外,SIFU还引入了一种3D一致的纹理优化过程,可大大提升纹理质量,借助文本到图像的diffusion模型实现纹理编辑。SIFU擅长处理复杂姿势和宽松衣物,是实际应用中理想的解决方案。
FMA-Net是一个用于视频超分辨率和去模糊的深度学习模型。它可以将低分辨率和模糊的视频恢复成高分辨率和清晰的视频。该模型通过流引导的动态过滤和多注意力的迭代特征精炼技术,可以有效处理视频中的大动作,实现视频的联合超分辨率和去模糊。该模型结构简单、效果显著,可以广泛应用于视频增强、编辑等领域。
Repaint123可以在2分钟内从一张图片生成高质量、多视角一致的3D内容。它结合2D散射模型强大的图像生成能力和渐进重绘策略的纹理对齐能力,生成高质量、视角一致的多视角图像,并通过可视性感知的自适应重绘强度提升重绘过程中的图像质量。生成的高质量、多视角一致图像使得简单的均方误差损失函数就能实现快速的3D内容生成。
该代码仓库包含从合成图像数据(主要是图片)进行学习的研究,包括StableRep、Scaling和SynCLR三个项目。这些项目研究了如何利用文本到图像模型生成的合成图像数据进行视觉表示模型的训练,并取得了非常好的效果。
ODIN(Omni-Dimensional INstance segmentation)是一个模型,可以使用转换器架构在2D RGB图像和3D点云上进行分割和标记。它通过在2D视图内和3D视图之间交替融合信息来区分2D和3D特征操作。ODIN在ScanNet200、Matterport3D和AI2THOR 3D实例分割基准上实现了最先进的性能,并在ScanNet、S3DIS和COCO上实现了竞争性能。当使用来自3D网格的采样点云代替感知的3D点云时,它超过了以往所有的作品。作为可指导的具体化代理架构中的3D感知引擎时,它在TEACh对话动作基准上树立了新的最先进水平。我们的代码和检查点可以在项目网站找到。
3D Fauna是一个通过学习 2D 网络图片来构建三维动物模的方法。它通过引入语义相关的模型集合来解决模型泛化的挑战,并提供了一个新的大规模数据集。在推理过程中,给定一张任意四足动物的图片,我们的模型可以在几秒内通过前馈方式重建出一个有关联的三维网格模型。
Wild2Avatar是一个用于渲染被遮挡的野外单目视频中的人类外观的神经渲染方法。它可以在真实场景下渲染人类,即使障碍物可能会阻挡相机视野并导致部分遮挡。该方法通过将场景分解为三部分(遮挡物、人类和背景)来实现,并使用特定的目标函数强制分离人类与遮挡物和背景,以确保人类模型的完整性。
Human101是一个快速从单视图重建人体的框架。它能够在100秒内训练3D高斯模型,并以60FPS以上渲染1024分辨率的图像,而无需预先存储每帧的高斯属性。Human101管道如下:首先,从单视图视频中提取2D人体姿态。然后,利用姿态驱动3D模拟器生成匹配的3D骨架动画。最后,基于动画构建时间相关的3D高斯模型,进行实时渲染。
为什么选择 Innovatiana 进行数据标注外包?Innovatiana 是一家致力于为您的人工智能需求提供有意义和有影响力的外包服务的公司。我们在马达加斯加招聘并培训我们自己的数据标注团队,为他们提供公平的薪水、良好的工作条件和职业发展机会。我们拒绝使用众包实践,为您提供有意义和有影响力的外包服务,并透明地提供用于人工智能的数据来源。我们的任务由一位英语或法语经理负责,以实现紧密的管理和沟通。我们提供灵活的价格,根据您的需求和预算定价。我们重视数据的安全性和机密性,并采取最佳的信息安全实践来保护数据。我们的数据标注专家经过专业培训,为您提供高质量的标注数据,用于培训您的人工智能模型。
UniRef是一个统一的用于图像和视频参考对象分割的模型。它支持语义参考图像分割(RIS)、少样本分割(FSS)、语义参考视频对象分割(RVOS)和视频对象分割(VOS)等多种任务。UniRef的核心是UniFusion模块,它可以高效地将各种参考信息注入到基础网络中。 UniRef可以作为SAM等基础模型的插件组件使用。UniRef提供了在多个基准数据集上训练好的模型,同时也开源了代码以供研究使用。
ALFI是一款由人工智能驱动的企业SaaS平台,采用计算机视觉、机器学习、深度学习和边缘计算技术。它提供了广告定向、实时观众分析和个性化内容交付等功能。ALFI的独特网络将人工智能屏幕安装在Uber和Lyft等共乘服务中,实现数字户外广告的精准定向和个性化交付。它通过计算机视觉技术实时匹配受众与相关广告,并在符合隐私规范的过程中进行内容投放。ALFI的目标是为品牌提供更精准的广告投放,为企业提供实时观众分析和定制化内容交付。
Wrestling Endurance Challenge是一个结合了人工智能和计算机视觉的摔跤耐力挑战应用。该应用通过AI分配任务,利用计算机视觉检测用户的持续时间。用户可通过扬声器或耳机接收指令,以参与耐力挑战。应用使用持续的机器学习在云端进行计算,并保证隐私安全,不会发送视频,仅导出关节坐标和轨迹数据。
Vision AI 提供了三种计算机视觉产品,包括 Vertex AI Vision、自定义机器学习模型和 Vision API。您可以使用这些产品从图像中提取有价值的信息,进行图像分类和搜索,并创建各种计算机视觉应用。Vision AI 提供简单易用的界面和功能强大的预训练模型,满足不同用户需求。
Manot洞察管理平台通过准确定位改进计算机视觉模型的表现。它为产品经理和工程师提供了可操作的见解,以便他们能够确定计算机视觉模型失败的原因。
Adversarial Diffusion Distillation是一个实时图像编辑平台,可以通过手机、平板电脑或计算机将任何物理媒介转换为数字媒介,并在任何地方进行编辑。它使用先进的计算机视觉技术,可以快速、轻松地将物理媒介转换为数字媒介,包括纸张、墙壁、白板、书籍等。Adversarial Diffusion Distillation可以帮助用户提高工作效率,减少时间和成本。
该产品是一种新型去噪扩散概率模型,学习从未直接观察到的信号分布中采样,而是通过已知的可微分前向模型测量。该产品可直接从部分观测的未知信号分布中采样,适用于计算机视觉任务。在逆图形学中,它能够生成与单个2D输入图像一致的3D场景分布。产品定价灵活,定位于图像处理和计算机视觉领域。
AttentionKart是一个利用人工智能提供参与度洞察的平台。它使用计算机视觉技术如面部识别、表情识别、眼球追踪等,帮助用户分析参与度和互动,获得用户行为深入洞察。平台可以离线分析录像,也可以在线整合第三方应用。主要功能包括参与度分析、精准用户画像、互动优化等。适用于教育机构的在线课程、企业的会议演示、销售电话等场景。
YOLO-NAS Pose是一款免费的、开源的库,用于训练基于PyTorch的计算机视觉模型。它提供了训练脚本和快速简单复制模型结果的示例。内置SOTA模型,可以轻松加载和微调生产就绪的预训练模型,包括最佳实践和验证的超参数,以实现最佳的准确性。可以缩短训练生命周期,消除不确定性。提供分类、检测、分割等不同任务的模型,可以轻松集成到代码库中。
OpenCV是一个实时优化的计算机视觉库,提供了一套功能强大的工具和硬件支持。它还支持机器学习(ML)和人工智能(AI)模型的执行。OpenCV是开源的,免费商用。
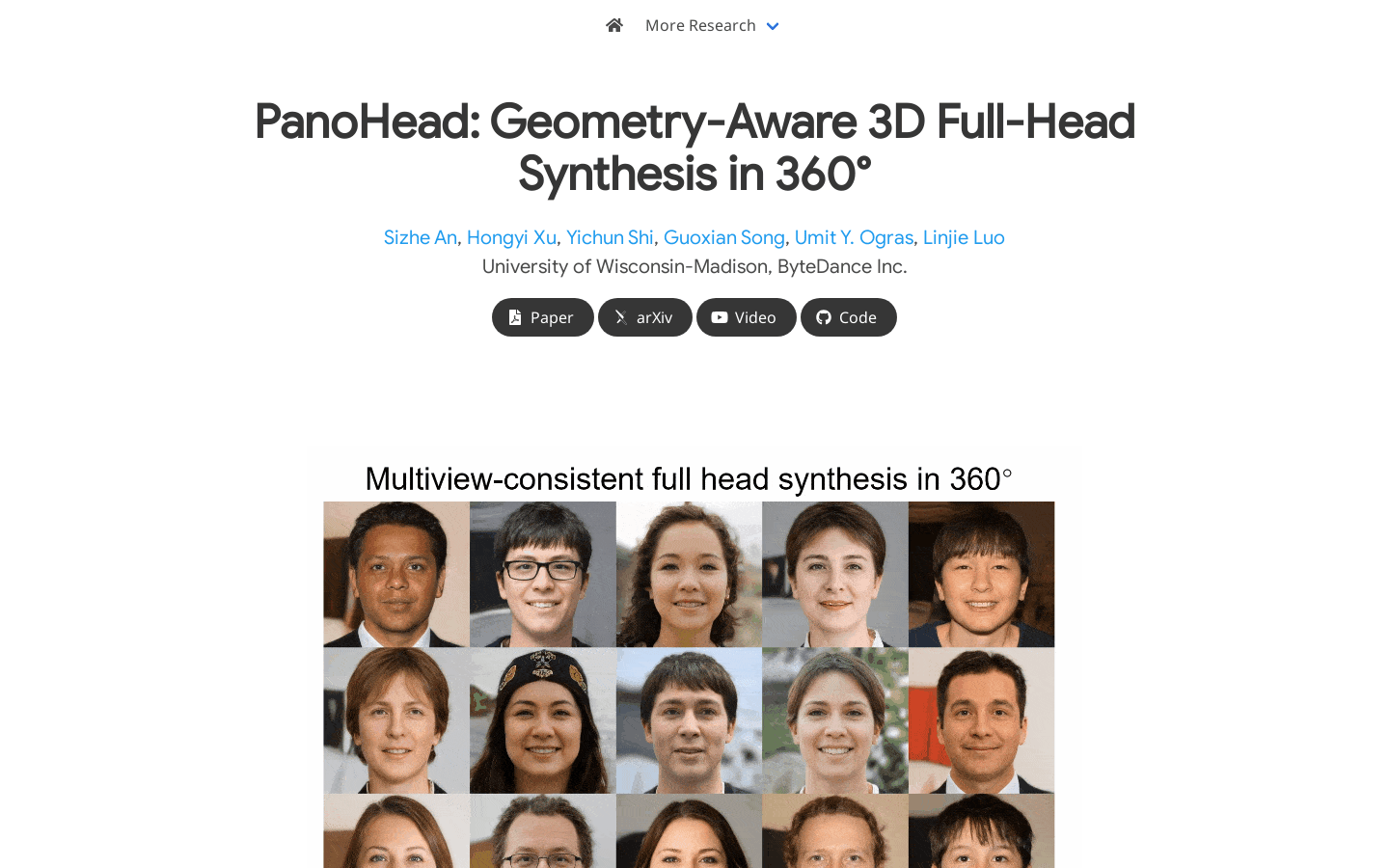
PanoHead是一个360°几何感知3D全头合成方法,能够仅依靠野外非结构化图像进行训练,实现高质量视图一致的360°全头部图像合成,具有不同的外观和详细的几何形状。