找到 266 个相关的AI工具
AI ASMR Generator是一个基于网站的视频生成工具,它利用先进的AI技术,通过分析数百万个病毒性ASMR视频,创建了各类受欢迎格式的模板。其重要性在于为内容创作者和营销人员提供了便捷的视频创作途径。主要优点包括无需编写提示词、可快速定制、有多种模板选择、生成同步的音频和视觉内容、适配社交媒体算法等。产品背景是针对ASMR内容创作需求而开发。价格方面,有不同的订阅计划,包括每月9.9美元的Starter套餐、19.9美元的Creator套餐和49美元的Pro套餐,定位为满足不同层次内容创作者的需求。
夸克・造点 AI 是一个利用先进的 AI 技术生成图像和视频的平台,用户可以通过简单的输入生成视觉内容。它的主要优点是快速高效,适用于设计师、艺术家和内容创作者。该产品为用户提供灵活的创作工具,帮助他们在短时间内实现创意构思,定价模式灵活,为用户提供了更多选择。
Ray3是全球首个具有推理能力的视频模型,由Luma Ray3提供支持。它能够思考、规划并创作专业级内容,具备原生HDR生成和智能草稿模式实现快速迭代。主要优点包括:拥有推理智能,能深入理解提示、规划复杂场景并自我审视;提供原生10、12和16位HDR视频,适用于专业工作室工作流程;草稿模式生成速度快20倍,便于快速完善概念。价格方面,有免费版、29美元的专业版和99美元的工作室版。定位为满足不同用户群体从探索到专业商业应用的视频创作需求。
Aleph AI 是一款基于先进人工智能技术的视频编辑和生成工具,允许用户通过简单的文本提示来快速修改和生成视频。它能够以高效率和准确性进行复杂的视频编辑,适合各类创作者,无论是专业人士还是初学者,能够轻松实现他们的创意想法。Aleph AI 提供每次生成 10 个积分,并且在处理视频时支持商用许可,极大地降低了视频创作的门槛。
图片转视频AI生成器利用先进的AI模型,将静态图片转换为引人注目的视频,适用于社交媒体创作者和任何想要体验AI视频生成的人。产品定位于简化视频制作流程,提高效率。
Kwali 是一款创新的广告视频生成工具,旨在为小商家提供便捷的视频制作解决方案。用户只需简单描述需求,Kwali 就能自动拆分卖点、生成脚本、调用素材,并合成视频。其功能强大且友好,适合没有专业视频制作经验的用户。Kwali 目前正处于内测阶段,适合追求高效和低成本广告解决方案的商家。
KissGen AI是一款利用先进的人工智能技术生成个性化接吻视频的领先工具。其能将照片转化为逼真的接吻视频,为用户创造难忘的浪漫瞬间。
MixHub AI集成了各种先进的AI模型,提供AI聊天、图像处理和视频生成功能。其主要优点在于准确性高、功能全面,价格实惠,适合个人和企业用户使用。
Youart是一体化AI创意工作室,提供强大的AI图像和视频生成器,通过文本提示将您的想法转化为令人惊叹的视觉作品。
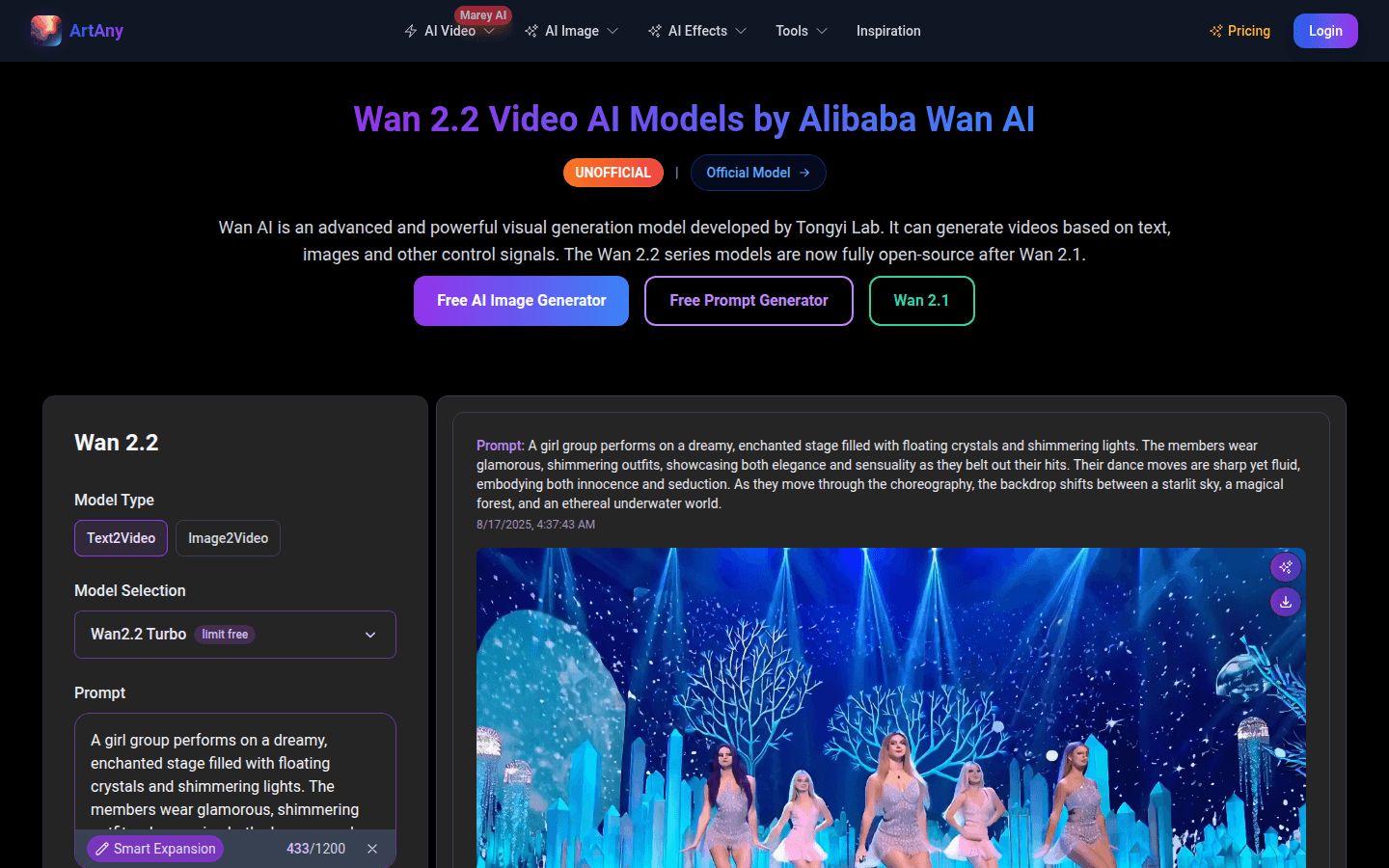
Wan 2.2是一款强大的视频生成模型,支持文本转图像、图像编辑、文本转视频和图像转视频,由Wan AI提供技术支持。它具有出色的视频生成能力和用户友好的界面,为用户提供丰富的创作功能。
Runway Aleph是由Runway AI开发的先进AI视频编辑工具,利用Gen 4技术进行视频转换、编辑和生成,是AI视频编辑和创意叙事的新标准。
WAN 2.1 LoRA T2V是一款能够根据文本提示生成视频的工具,通过LoRA模块的定制训练,用户可以定制化生成视频,适用于品牌叙事、粉丝内容和风格化动画。产品背景丰富,提供高度定制化的视频生成体验。
Wan 2.2 AI是一款专业的文本转视频和图像转视频生成平台,提供高质量视频生成,具有电影级审美控制和专业运动生成。产品定位为帮助创作者、营销人员和内容制作人轻松生成高质量视频内容。
Openjourney 是一个高保真的开源项目,旨在模拟 MidJourney 的界面,利用 Google 的 Gemini SDK 进行 AI 图像和视频生成。该项目支持使用 Imagen 4 生成高质量图像,以及使用 Veo 2 和 Veo 3 进行文本到视频和图像到视频的转换。它适合需要进行图像生成和视频制作的开发者和创作者,提供了用户友好的界面和实时生成体验,能够助力创意工作与项目开发。
Veo 5 AI视频生成器是一款基于Veo 5技术的下一代AI视频生成器,能够快速创建出令人惊叹的超逼真视频。它采用最新的Veo 5 A模型,实现智能场景理解、自然运动合成和上下文感知渲染,带来前所未有的超逼真和创造力。
LTXV 13B 是 Lightricks 开发的先进 AI 视频生成模型,拥有 130 亿参数,显著提高了视频生成的质量和速度。该模型在 2025 年 5 月发布,是其前身 LTX 视频模型的显著升级,支持实时高质量视频生成,适合各类创意内容制作。该模型采用了多尺度渲染技术,使生成速度比同类模型快 30 倍,并能在消费者硬件上流畅运行。
1703 Media是一家AI视频生成平台,通过AI技术转化旧视频并填充库存,为用户提供未来AI内容创作的无缝体验。该产品定位于帮助内容创作者以更高效、更专业的方式生成视频内容,降低制作成本。
ASMR.so是基于先进的 VEO3 AI 技术的平台,用户可以快速生成专业的 ASMR 视频。该产品支持多种 ASMR 类型,包括耳语、敲击、自然声音等,旨在为用户提供放松和享受的体验。其主要优势在于视频生成速度快(通常在 2 分钟内完成),高清质量以及用户友好的操作流程。适合视频创作者、ASMR 爱好者以及需要放松内容的用户。该平台还提供灵活的信用系统,用户可根据需求选择套餐。产品价格方面,有免费试用和付费套餐可供选择。
FakeYou 是一个使用 AI 技术生成名人声音和视频的在线平台。用户可以通过选择不同的名人声音,生成他们想要的台词,体验独特的互动乐趣。这个平台的主要优点在于其提供了大量的名人声音选择,并且操作简单,适合各类用户进行娱乐和创作。FakeYou 不断更新其声音库,并且支持多个语言,使其适用范围更广泛。
Veo 3是最新的AI视频生成工具,能够添加声音效果、对话和环境噪音,帮助用户生动展现故事情节。该产品背景信息丰富,价格合理,定位于提供高质量视频生成服务。
AI ASMR Generator是一款利用AI技术生成ASMR视频的工具。它可以帮助用户快速创建高质量的ASMR视频,提供更丰富的体验和刺激。
UnificAlly是一家AI API服务平台,提供创新的AI模型和API服务,价格优惠。用户可以访问平台并选择各种先进的AI模型,如GPT 4.1、Suno、Higgsfield等,用于视频生成、图像创作、音乐作曲等。UnificAlly致力于提供高性价比的AI服务,并以快速可靠的API响应、简单易集成的REST API和详尽的文档和示例著称。
a2e.ai是一款AI工具,提供AI头像、唇形同步、语音克隆、文字生成视频等功能。该产品具有高清晰度、高一致性、高效生成速度等优点,适用于各种场景,提供完整的头像AI工具集。
FlyAgt是一个AI图像和视频生成平台,提供先进的AI工具,从创建到编辑再到增强图像。它的主要优点在于价格实惠,提供多种专业工具,并保护用户隐私。
AI视频生成器采用领先行业的图像到视频AI技术,智能选择最佳模型,生成1080p视频,支持多镜头拍摄,样式多样,运动流畅。主要优点包括快速生成高质量视频,支持复杂场景和镜头运动控制,适用于设计师、内容创作者等用户。
DreamASMR利用Veo3 ASMR技术创造令人放松的视频内容,提供先进的AI视频生成、双耳声音和巨细靡遗的视觉体验,是终极ASMR体验。
Veo3 Video是一款利用Google Veo3模型生成高质量视频的平台。它采用先进的技术和算法,确保视频生成过程中音频与唇语同步,提供一致的视频质量。
Veo 3是最新的AI视频生成工具,可添加音效、对话和环境噪音,将您的故事栩栩如生。
HunyuanCustom 是一个多模态定制视频生成框架,旨在根据用户定义的条件生成特定主题的视频。该技术在身份一致性和多种输入模式的支持上表现出色,能够处理文本、图像、音频和视频输入,适合虚拟人广告、视频编辑等多种应用场景。
PixVerse-MCP 是一个工具,允许用户通过支持模型上下文协议(MCP)的应用程序访问 PixVerse 最新的视频生成模型。该产品提供了文本转视频等功能,适用于创作者和开发者,能够在任何地方生成高质量的视频。PixVerse 平台需要 API 积分,用户需自行购买。
AvatarFX 是一个尖端的 AI 平台,专注于互动故事讲述。用户可以通过上传图片和选择声音,快速生成生动、真实的角色视频。其核心技术是基于 DiT 的扩散视频生成模型,能够高效生成高保真、时序一致的视频,特别适合需要多个角色和对话场景的创作。产品定位在为创作者提供工具,帮助他们实现想象力的无限可能。
Vidu Q1 是由生数科技推出的国产视频生成大模型,专为视频创作者设计,支持高清 1080p 视频生成,具备电影级运镜效果和首尾帧功能。该产品在 VBench-1.0 和 VBench-2.0 评测中位居榜首,性价比极高,价格仅为同行的十分之一。它适用于电影、广告、动漫等多个领域,能够大幅降低创作成本,提升创作效率。
SkyReels-V2 是昆仑万维 SkyReels 团队发布的全球首个使用扩散强迫框架的无限时长电影生成模型。该模型通过结合多模态大语言模型、多阶段预训练、强化学习和扩散强迫框架来实现协同优化,突破了传统视频生成技术在提示词遵循、视觉质量、运动动态和视频时长协调上的重大挑战。它不仅为内容创作者提供了强大的工具,还开启了利用 AI 进行视频叙事和创意表达的无限可能。
Wan2.1-FLF2V-14B 是一个开源的大规模视频生成模型,旨在推动视频生成领域的进步。该模型在多项基准测试中表现优异,支持消费者级 GPU,能够高效生成 480P 和 720P 的视频。它在文本到视频、图像到视频等多个任务中表现出色,具有强大的视觉文本生成能力,适用于各种实际应用场景。
FramePack 是一个创新的视频生成模型,旨在通过压缩输入帧的上下文来提高视频生成的质量和效率。其主要优点在于解决了视频生成中的漂移问题,通过双向采样方法保持视频质量,适合需要生成长视频的用户。该技术背景来源于对现有模型的深入研究和实验,以改进视频生成的稳定性和连贯性。
Pusa 通过帧级噪声控制引入视频扩散建模的创新方法,能够实现高质量的视频生成,适用于多种视频生成任务(文本到视频、图像到视频等)。该模型以其卓越的运动保真度和高效的训练过程,提供了一个开源的解决方案,方便用户进行视频生成任务。
SkyReels-A2 是一个基于视频扩散变换器的框架,允许用户合成和生成视频内容。该模型通过利用深度学习技术,提供了灵活的创作能力,适合多种视频生成应用,尤其是在动画和特效制作方面。该产品的优点在于其开源特性和高效的模型性能,适合研究人员和开发者使用,且目前不收取费用。
DreamActor-M1 是一个基于扩散变换器 (DiT) 的人类动画框架,旨在实现细粒度的整体可控性、多尺度适应性和长期时间一致性。该模型通过混合引导,能够生成高表现力和真实感的人类视频,适用于从肖像到全身动画的多种场景。其主要优势在于高保真度和身份保留,为人类行为动画带来了新的可能性。
GAIA-2 是 Wayve 开发的先进视频生成模型,旨在为自动驾驶系统提供多样化和复杂的驾驶场景,以提高安全性和可靠性。该模型通过生成合成数据来解决依赖现实世界数据收集的限制,能够创建各种驾驶情境,包括常规和边缘案例。GAIA-2 支持多种地理和环境条件的模拟,帮助开发者在没有高昂成本的情况下快速测试和验证自动驾驶算法。
AccVideo 是一种新颖的高效蒸馏方法,通过合成数据集加速视频扩散模型的推理速度。该模型能够在生成视频时实现 8.5 倍的速度提升,同时保持相似的性能。它使用预训练的视频扩散模型生成多条有效去噪轨迹,从而优化了数据的使用和生成过程。AccVideo 特别适用于需要高效视频生成的场景,如电影制作、游戏开发等,适合研究人员和开发者使用。
Video-T1 是一个视频生成模型,通过测试时间缩放技术(TTS)显著提升生成视频的质量和一致性。该技术允许在推理过程中使用更多的计算资源,从而优化生成结果。相较于传统的视频生成方法,TTS 能够提供更高的生成质量和更丰富的内容表达,适用于数字创作领域。该产品的定位主要面向研究人员和开发者,价格信息未明确。
vivago.ai 是一个免费的 AI 生成工具和社区,提供文本转图像、图像转视频等功能,让创作变得更加简单高效。用户可以免费生成高质量的图像和视频,支持多种 AI 编辑工具,方便用户进行创作和分享。该平台的定位是为广大创作者提供易用的 AI 工具,满足他们在视觉创作上的需求。
长上下文调优(LCT)旨在解决当前单次生成能力与现实叙事视频制作之间的差距。该技术通过数据驱动的方法直接学习场景级一致性,支持交互式多镜头开发和合成生成,适用于视频制作的各个方面。
MM_StoryAgent 是一个基于多智能体范式的故事视频生成框架,它结合了文本、图像和音频等多种模态,通过多阶段流程生成高质量的故事视频。该框架的核心优势在于其可定制性,用户可以自定义专家工具以提升每个组件的生成质量。此外,它还提供了故事主题列表和评估标准,便于进一步的故事创作和评估。MM_StoryAgent 主要面向需要高效生成故事视频的创作者和企业,其开源特性使得用户可以根据自身需求进行扩展和优化。
Flat Color - Style是一款专为生成扁平色彩风格图像和视频设计的LoRA模型。它基于Wan Video模型训练,具有独特的无线条、低深度效果,适合用于动漫、插画和视频生成。该模型的主要优点是能够减少色彩渗出,增强黑色表现力,同时提供高质量的视觉效果。它适用于需要简洁、扁平化设计的场景,如动漫角色设计、插画创作和视频制作。该模型是免费提供给用户使用的,旨在帮助创作者快速实现具有现代感和简洁风格的视觉作品。
Wan_AI Creative Drawing 是一个基于人工智能技术的创意绘画和视频创作平台。它通过先进的AI模型,能够根据用户输入的文字描述生成独特的艺术作品和视频内容。这种技术不仅降低了艺术创作的门槛,还为创意工作者提供了强大的工具。产品主要面向创意专业人士、艺术家和普通用户,帮助他们快速实现创意想法。目前,该平台可能提供免费试用或付费使用,具体价格和定位需进一步确认。
HunyuanVideo-I2V 是腾讯开源的图像到视频生成模型,基于 HunyuanVideo 架构开发。该模型通过图像潜在拼接技术,将参考图像信息有效整合到视频生成过程中,支持高分辨率视频生成,并提供可定制的 LoRA 效果训练功能。该技术在视频创作领域具有重要意义,能够帮助创作者快速生成高质量的视频内容,提升创作效率。
Wan2GP 是基于 Wan2.1 的改进版本,旨在为低配置 GPU 用户提供高效、低内存占用的视频生成解决方案。该模型通过优化内存管理和加速算法,使得普通用户也能在消费级 GPU 上快速生成高质量的视频内容。它支持多种任务,包括文本到视频、图像到视频、视频编辑等,同时具备强大的视频 VAE 架构,能够高效处理 1080P 视频。Wan2GP 的出现降低了视频生成技术的门槛,使得更多用户能够轻松上手并应用于实际场景。
HunyuanVideo Keyframe Control Lora 是一个针对HunyuanVideo T2V模型的适配器,专注于关键帧视频生成。它通过修改输入嵌入层以有效整合关键帧信息,并应用低秩适配(LoRA)技术优化线性层和卷积输入层,从而实现高效微调。该模型允许用户通过定义关键帧精确控制生成视频的起始和结束帧,确保生成内容与指定关键帧无缝衔接,增强视频连贯性和叙事性。它在视频生成领域具有重要应用价值,尤其在需要精确控制视频内容的场景中表现出色。
TheoremExplainAgent 是一款基于人工智能的模型,专注于为数学和科学定理生成详细的多模态解释视频。它通过结合文本和视觉动画,帮助用户更深入地理解复杂概念。该产品利用 Manim 动画技术生成超过 5 分钟的长视频,填补了传统文本解释的不足,尤其在揭示推理错误方面表现出色。它主要面向教育领域,旨在提升学习者对 STEM 领域定理的理解能力,目前尚未明确其价格和商业化定位。
ComfyUI-WanVideoWrapper 是一个为 WanVideo 提供 ComfyUI 节点的工具。它允许用户在 ComfyUI 环境中使用 WanVideo 的功能,实现视频生成和处理。该工具基于 Python 开发,支持高效的内容创作和视频生成,适合需要快速生成视频内容的用户。
Wan2.1 是一款开源的先进大规模视频生成模型,旨在推动视频生成技术的边界。它通过创新的时空变分自编码器(VAE)、可扩展的训练策略、大规模数据构建和自动化评估指标,显著提升了模型的性能和通用性。Wan2.1 支持多种任务,包括文本到视频、图像到视频、视频编辑等,能够生成高质量的视频内容。该模型在多个基准测试中表现优异,甚至超越了一些闭源模型。其开源特性使得研究人员和开发者可以自由使用和扩展该模型,适用于多种应用场景。
Wan2.1-T2V-14B 是一款先进的文本到视频生成模型,基于扩散变换器架构,结合了创新的时空变分自编码器(VAE)和大规模数据训练。它能够在多种分辨率下生成高质量的视频内容,支持中文和英文文本输入,并在性能和效率上超越现有的开源和商业模型。该模型适用于需要高效视频生成的场景,如内容创作、广告制作和视频编辑等。目前该模型在 Hugging Face 平台上免费提供,旨在推动视频生成技术的发展和应用。
JoyGen 是一种创新的音频驱动 3D 深度感知说话人脸视频生成技术。它通过音频驱动唇部动作生成和视觉外观合成,解决了传统技术中唇部与音频不同步和视觉质量差的问题。该技术在多语言环境下表现出色,尤其针对中文语境进行了优化。其主要优点包括高精度的唇音同步、高质量的视觉效果以及对多语言的支持。该技术适用于视频编辑、虚拟主播、动画制作等领域,具有广泛的应用前景。
Freepik AI 视频生成器是一款基于人工智能技术的在线工具,能够根据用户输入的初始图像或描述快速生成视频。该技术利用先进的 AI 算法,实现视频内容的自动化生成,极大地提高了视频创作的效率。产品定位为创意设计人员和视频制作者提供快速、高效的视频生成解决方案,帮助用户节省时间和精力。目前该工具处于 Beta 测试阶段,用户可以免费试用其功能。
AI Kungfu Video Generator是一个基于Hailuo AI模型的在线平台,能够让用户通过上传照片并选择相关提示,快速生成高质量的功夫视频。该技术利用人工智能的强大能力,将静态图片转化为充满动感的武术场景,为用户带来极具视觉冲击力的体验。其主要优点包括操作简单、生成速度快以及高度的定制化选项。产品定位为满足用户对功夫视频创作的需求,无论是个人娱乐还是商业用途,都能提供相应的解决方案。此外,平台还提供免费试用,用户在注册后可以免费生成第一个视频,之后则需要升级到付费计划以获得更多功能。
Phantom 是一种先进的视频生成技术,通过跨模态对齐实现主体一致性视频生成。它能够根据单张或多张参考图像生成生动的视频内容,同时严格保留主体的身份特征。该技术在内容创作、虚拟现实和广告等领域具有重要应用价值,能够为创作者提供高效且富有创意的视频生成解决方案。Phantom 的主要优点包括高度的主体一致性、丰富的视频细节以及强大的多模态交互能力。
SkyReels V1 是一个基于 HunyuanVideo 微调的人类中心视频生成模型。它通过高质量影视片段训练,能够生成具有电影级质感的视频内容。该模型在开源领域达到了行业领先水平,尤其在面部表情捕捉和场景理解方面表现出色。其主要优点包括开源领先性、先进的面部动画技术和电影级光影美学。该模型适用于需要高质量视频生成的场景,如影视制作、广告创作等,具有广泛的应用前景。
SkyReels-V1 是一个开源的人类中心视频基础模型,基于高质量影视片段微调,专注于生成高质量的视频内容。该模型在开源领域达到了顶尖水平,与商业模型相媲美。其主要优势包括:高质量的面部表情捕捉、电影级的光影效果以及高效的推理框架 SkyReelsInfer,支持多 GPU 并行处理。该模型适用于需要高质量视频生成的场景,如影视制作、广告创作等。
FlashVideo 是一款专注于高效高分辨率视频生成的深度学习模型。它通过分阶段的生成策略,首先生成低分辨率视频,再通过增强模型提升至高分辨率,从而在保证细节的同时显著降低计算成本。该技术在视频生成领域具有重要意义,尤其是在需要高质量视觉内容的场景中。FlashVideo 适用于多种应用场景,包括内容创作、广告制作和视频编辑等。其开源性质使得研究人员和开发者可以灵活地进行定制和扩展。
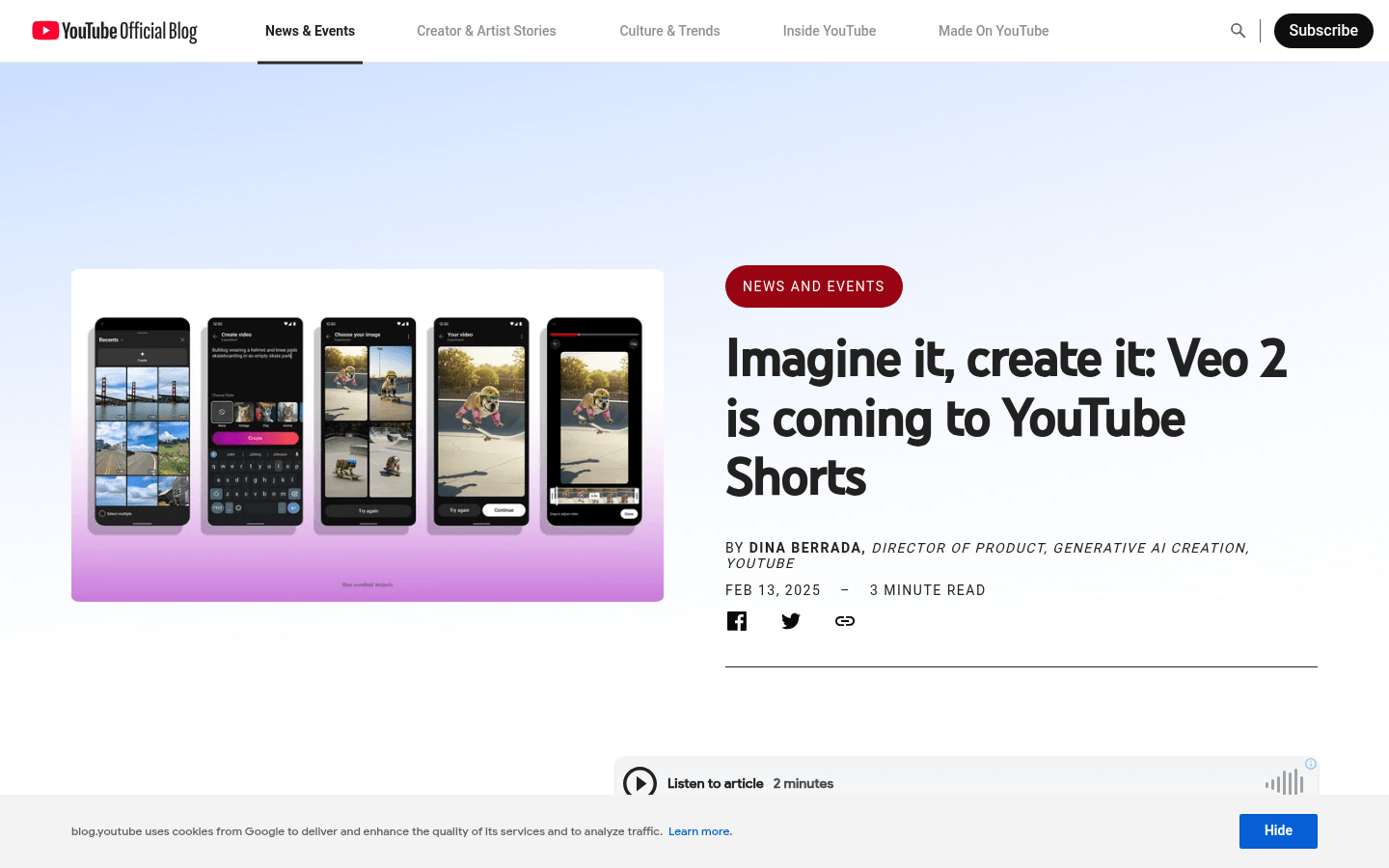
Dream Screen 是 YouTube Shorts 的一项功能,通过集成 Google DeepMind 的 Veo 2 模型,能够根据文本提示生成高质量的视频背景或独立视频片段。该工具的主要优点是能够快速生成与创作者想象相符的视频内容,支持多种主题、风格和电影效果。它还通过 SynthID 水印和清晰标签标明 AI 生成内容,确保透明性和合规性。Dream Screen 的推出旨在帮助创作者更高效地实现创意想法,提升内容创作的多样性和趣味性。
CineMaster 是一款专注于高质量电影级视频生成的框架,通过 3D 意识和可控性,让用户能够像专业电影导演一样精确地控制场景中的对象放置、相机运动以及渲染帧的布局。该框架通过两阶段操作实现:第一阶段通过交互式工作流让用户在 3D 空间中直观地构建条件信号;第二阶段将这些信号作为文本到视频扩散模型的指导,生成用户期望的视频内容。CineMaster 的主要优点是其高度的可控性和 3D 意识,能够生成高质量的动态视频内容,适用于影视制作、广告创作等领域。
Magic 1-For-1 是一个专注于高效视频生成的模型,其核心功能是将文本和图像快速转换为视频。该模型通过将文本到视频的生成任务分解为文本到图像和图像到视频两个子任务,优化了内存使用并减少了推理延迟。其主要优点包括高效性、低延迟和可扩展性。该模型由北京大学 DA-Group 团队开发,旨在推动交互式基础视频生成领域的发展。目前该模型及相关代码已开源,用户可以免费使用,但需遵守开源许可协议。
Adobe Firefly 是一款基于人工智能技术的视频生成工具。它能够根据用户提供的简单提示或图像快速生成高质量的视频片段。该技术利用先进的 AI 算法,通过对大量视频数据的学习和分析,实现自动化的视频创作。其主要优点包括操作简单、生成速度快、视频质量高。Adobe Firefly 面向创意工作者、视频制作者以及需要快速生成视频内容的用户,提供高效、便捷的视频创作解决方案。目前该产品处于 Beta 测试阶段,用户可以免费使用,未来可能会根据市场需求和产品发展进行定价和定位。
Krea Chat 是一款基于 AI 的设计工具,通过聊天界面提供强大的设计功能。它结合了 DeepSeek 的 AI 技术和 Krea 的设计工具套件,用户可以通过自然语言交互生成图像、视频等设计内容。这种创新的交互方式极大地简化了设计流程,降低了设计门槛,使用户能够快速实现创意。Krea Chat 的主要优点包括易于使用、高效生成设计内容以及强大的 AI 驱动功能。它适合需要快速生成设计素材的创作者、设计师和市场营销人员,能够帮助他们节省时间并提升工作效率。
On-device Sora 是一个开源项目,旨在通过线性比例跳跃(LPL)、时间维度标记合并(TDTM)和动态加载并发推理(CI-DL)等技术,实现在移动设备(如 iPhone 15 Pro)上高效的视频生成。该项目基于 Open-Sora 模型开发,能够根据文本输入生成高质量视频。其主要优点包括高效性、低功耗和对移动设备的优化。该技术适用于需要在移动设备上快速生成视频内容的场景,如短视频创作、广告制作等。项目目前开源,用户可以免费使用。
Lumina-Video 是 Alpha-VLLM 团队开发的一个视频生成模型,主要用于从文本生成高质量的视频内容。该模型基于深度学习技术,能够根据用户输入的文本提示生成对应的视频,具有高效性和灵活性。它在视频生成领域具有重要意义,为内容创作者提供了强大的工具,能够快速生成视频素材。目前该项目已开源,支持多种分辨率和帧率的视频生成,并提供了详细的安装和使用指南。
Goku 是一个专注于视频生成的人工智能模型,能够根据文本提示生成高质量的视频内容。该模型基于先进的流式生成技术,能够生成流畅且具有吸引力的视频,适用于多种场景,如广告、娱乐和创意内容制作。Goku 的主要优点在于其高效的生成能力和对复杂场景的出色表现能力,能够显著降低视频制作成本,同时提升内容的吸引力。该模型由香港大学和字节跳动的研究团队共同开发,旨在推动视频生成技术的发展。
ImageToVideo AI 是一款强大的在线工具,能够将静态图片转换为动态视频。它利用先进的人工智能技术,根据用户输入的文本描述和图像,生成高质量的视频内容。该工具的主要优点包括简单易用、支持多种图像格式、无需编辑技能即可生成视频,并且提供无水印的视频输出。它适合个人用户、内容创作者、品牌营销人员等,帮助他们以低成本制作高质量的视频内容,满足各种场景的需求。
VideoWorld是一个专注于从纯视觉输入(无标签视频)中学习复杂知识的深度生成模型。它通过自回归视频生成技术,探索如何仅通过视觉信息学习任务规则、推理和规划能力。该模型的核心优势在于其创新的潜在动态模型(LDM),能够高效地表示多步视觉变化,从而显著提升学习效率和知识获取能力。VideoWorld在视频围棋和机器人控制任务中表现出色,展示了其强大的泛化能力和对复杂任务的学习能力。该模型的研究背景源于对生物体通过视觉而非语言学习知识的模仿,旨在为人工智能的知识获取开辟新的途径。
AI Kungfu 是一个创新的人工智能平台,能够将普通照片转化为动态的功夫视频。它利用先进的 AI 技术分析照片,并应用真实的功夫动作生成逼真的武术动画。该技术能够理解传统武术风格,并在保持人物身份和特征的同时生成个性化视频内容。AI Kungfu 为用户提供了一种全新的方式来创作和分享功夫视频,无论是用于娱乐还是展示个人风格,都具有很高的趣味性和创意性。它支持多种传统和现代的武术风格,如少林、太极、咏春等,满足不同用户的需求。此外,该平台操作简单,无需技术背景即可使用,生成的视频可用于个人和商业用途。
VideoJAM 是一种创新的视频生成框架,旨在通过联合外观 - 运动表示来提升视频生成模型的运动连贯性和视觉质量。该技术通过引入内指导机制(Inner-Guidance),利用模型自身预测的运动信号动态引导视频生成,从而在生成复杂运动类型时表现出色。VideoJAM 的主要优点是能够显著提高视频生成的连贯性,同时保持高质量的视觉效果,且无需对训练数据或模型架构进行大规模修改,即可应用于任何视频生成模型。该技术在视频生成领域具有重要的应用前景,尤其是在需要高度运动连贯性的场景中。
Go with the Flow 是一种创新的视频生成技术,通过使用扭曲噪声代替传统的高斯噪声,实现了对视频扩散模型运动模式的高效控制。该技术无需对原始模型架构进行修改,即可在不增加计算成本的情况下,实现对视频中物体和相机运动的精确控制。其主要优点包括高效性、灵活性和可扩展性,能够广泛应用于图像到视频生成、文本到视频生成等多种场景。该技术由 Netflix Eyeline Studios 等机构的研究人员开发,具有较高的学术价值和商业应用潜力,目前开源免费提供给公众使用。
OmniHuman-1 是一个端到端的多模态条件人类视频生成框架,能够基于单张人像和运动信号(如音频、视频或其组合)生成人类视频。该技术通过混合训练策略克服了高质量数据稀缺的问题,支持任意宽高比的图像输入,生成逼真的人类视频。它在弱信号输入(尤其是音频)方面表现出色,适用于多种场景,如虚拟主播、视频制作等。
Story Flicks 是一个基于AI大模型的故事短视频生成工具。它通过结合先进的语言模型和图像生成技术,能够根据用户输入的故事主题快速生成包含AI生成图像、故事内容、音频和字幕的高清视频。该产品利用了当前流行的AI技术,如OpenAI、阿里云等平台的模型,为用户提供高效、便捷的内容创作方式。它主要面向需要快速生成视频内容的创作者、教育工作者和娱乐行业从业者,具有高效、低成本的特点,能够帮助用户节省大量时间和精力。
leapfusion-hunyuan-image2video 是一种基于 Hunyuan 模型的图像到视频生成技术。它通过先进的深度学习算法,将静态图像转换为动态视频,为内容创作者提供了一种全新的创作方式。该技术的主要优点包括高效的内容生成、灵活的定制化能力以及对高质量视频输出的支持。它适用于需要快速生成视频内容的场景,如广告制作、视频特效等领域。该模型目前以开源形式发布,供开发者和研究人员免费使用,未来有望通过社区贡献进一步提升其性能。
video-starter-kit 是一个强大的开源工具包,用于构建基于 AI 的视频应用。它基于 Next.js、Remotion 和 fal.ai 构建,简化了在浏览器中使用 AI 视频模型的复杂性。该工具包支持多种先进的视频处理功能,如多剪辑视频合成、音频轨道集成和语音支持等,同时提供了开发者友好的工具,如元数据编码和视频处理管道。它适用于需要高效视频生成和处理的开发者和创作者。
GameFactory 是一个创新的通用世界模型,专注于从少量的《我的世界》游戏视频数据中学习,并利用预训练视频扩散模型的先验知识来生成新的游戏内容。该技术的核心优势在于其开放领域的生成能力,能够根据用户输入的文本提示和操作指令生成多样化的游戏场景和互动体验。它不仅展示了强大的场景生成能力,还通过多阶段训练策略和可插拔的动作控制模块,实现了高质量的交互式视频生成。该技术在游戏开发、虚拟现实和创意内容生成等领域具有广阔的应用前景,目前尚未明确其价格和商业化定位。
AI Kissing Video Generator Free 是一款基于先进人工智能技术的在线平台,能够将普通静态照片转化为自然流畅的浪漫接吻动画。该技术利用深度学习模型,专门针对浪漫互动进行训练,确保生成的动画高度逼真且自然。产品注重用户隐私与数据安全,所有上传内容在处理后自动删除。其主要面向情侣、内容创作者、婚礼策划师等群体,提供高质量的浪漫视频生成服务。产品提供免费试用版本,同时有付费升级选项,满足不同用户的需求。
Seaweed-APT是一种用于视频生成的模型,通过对抗性后训练技术,实现了大规模文本到视频的单步生成。该模型能够在短时间内生成高质量的视频,具有重要的技术意义和应用价值。其主要优点是速度快、生成效果好,适用于需要快速生成视频的场景。目前尚未明确具体的价格和市场定位。
Luma Ray2 是一款先进的视频生成模型,基于 Luma 新的多模态架构训练,计算能力是 Ray1 的 10 倍。它能够理解文本指令,并可接受图像和视频输入,生成具有快速连贯动作、超逼真细节和逻辑事件序列的视频,使生成的视频更接近生产就绪状态。目前提供文本到视频的生成功能,图像到视频、视频到视频和编辑功能即将推出。产品主要面向需要高质量视频生成的用户,如视频创作者、广告公司等,目前仅对付费订阅用户开放,可通过官网链接尝试使用。
MemenomeLM是一个创新的在线教育工具,通过将PDF文档转化为视频内容,帮助用户更高效地学习。它利用先进的AI技术,将枯燥的文字转化为生动的视频,使学习变得更加有趣和高效。产品主要面向学生群体,尤其是那些需要处理大量阅读材料的学生。它提供了多种视频格式和声音效果,以满足不同用户的需求。MemenomeLM有免费版和付费版,付费版提供更多功能,如更多的视频生成次数、高级AI声音和专属服务器等。
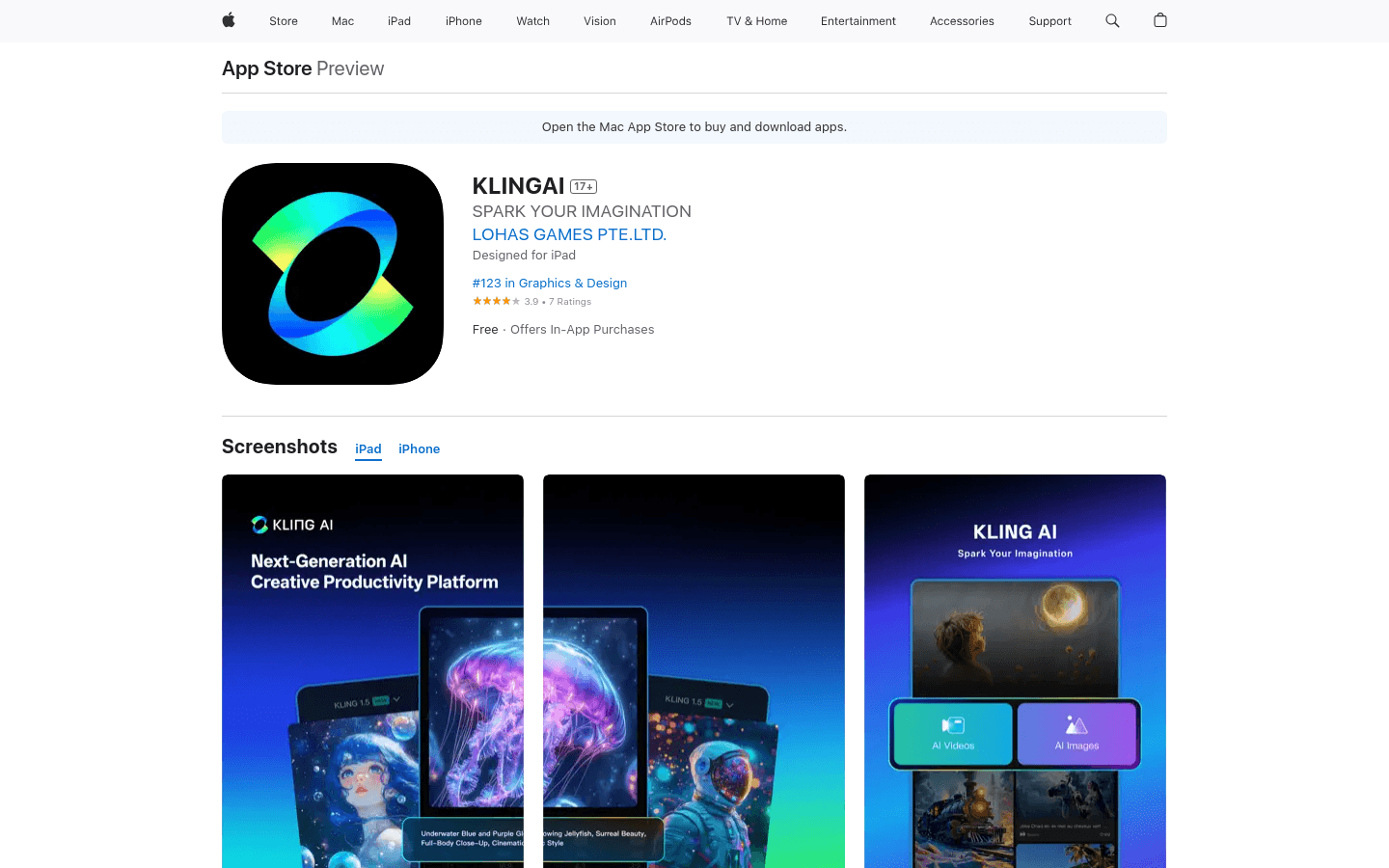
KLINGAI是一个由Kling大模型和Kolors大模型驱动的下一代AI创意工作室,受到全球创作者的高度评价。它支持视频和图像的生成与编辑,用户可以在这里释放想象力,或从其他创作者的作品中获取灵感,将想法变为现实。该应用在App Store中属于图形与设计类别,排名123,拥有3.9的用户评分。它适用于iPad,提供免费下载,但包含应用内购买项目。
Hallo3是一种用于肖像图像动画的技术,它利用预训练的基于变换器的视频生成模型,能够生成高度动态和逼真的视频,有效解决了非正面视角、动态对象渲染和沉浸式背景生成等挑战。该技术由复旦大学和百度公司的研究人员共同开发,具有强大的泛化能力,为肖像动画领域带来了新的突破。
Diffusion as Shader (DaS) 是一种创新的视频生成控制模型,旨在通过3D感知的扩散过程实现对视频生成的多样化控制。该模型利用3D跟踪视频作为控制输入,能够在统一的架构下支持多种视频控制任务,如网格到视频生成、相机控制、运动迁移和对象操作等。DaS的主要优势在于其3D感知能力,能够有效提升生成视频的时间一致性,并在短时间内通过少量数据微调即可展现出强大的控制能力。该模型由香港科技大学等多所高校的研究团队共同开发,旨在推动视频生成技术的发展,为影视制作、虚拟现实等领域提供更为灵活和高效的解决方案。
API.box是一个提供先进AI接口的平台,旨在帮助开发者快速集成AI功能到他们的项目中。它提供全面的API文档和详细的调用日志,确保高效开发和系统性能稳定。API.box具备企业级安全性和强大可扩展性,支持高并发需求,同时提供免费试用和商业用途的输出许可,是开发者和企业的理想选择。
Image To Video是一个利用人工智能技术将用户的静态图片转换成动态视频的平台。该产品通过AI技术实现图片动画化,使得内容创作者能够轻松制作出具有自然动作和过渡的视频内容。产品的主要优点包括快速处理、每日免费信用点数、高质量输出和易于下载。Image To Video的背景信息显示,它旨在帮助用户以低成本或无成本的方式,将图片转化为视频,从而提高内容的吸引力和互动性。产品定位于内容创作者、数字艺术家和营销专业人士,提供免费试用和高质量的视频生成服务。
Synthesys是一个AI内容生成平台,提供AI视频、AI语音和AI图像生成服务。它通过使用先进的人工智能技术,帮助用户以更低的成本和更简单的操作生成专业级别的内容。Synthesys的产品背景基于当前市场对于高质量、低成本内容生成的需求,其主要优点包括支持多种语言的超真实语音合成、无需专业设备即可生成高清视频、以及用户友好的界面设计。平台的定价策略包括免费试用和不同级别的付费服务,定位于满足不同规模企业的内容生成需求。
DisPose是一种用于控制人类图像动画的方法,它通过运动场引导和关键点对应来提高视频生成的质量。这项技术能够从参考图像和驱动视频中生成视频,同时保持运动对齐和身份信息的一致性。DisPose通过从稀疏的运动场和参考图像生成密集的运动场,提供区域级别的密集引导,同时保持稀疏姿态控制的泛化能力。此外,它还从参考图像中提取与姿态关键点对应的扩散特征,并将这些点特征转移到目标姿态,以提供独特的身份信息。DisPose的主要优点包括无需额外的密集输入即可提取更通用和有效的控制信号,以及通过即插即用的混合ControlNet提高生成视频的质量和一致性,而无需冻结现有模型参数。
Ruyi-Models是一个图像到视频的模型,能够生成高达768分辨率、每秒24帧的电影级视频,支持镜头控制和运动幅度控制。使用RTX 3090或RTX 4090显卡,可以无损生成512分辨率、120帧的视频。该模型以其高质量的视频生成能力和对细节的精确控制而受到关注,尤其在需要生成高质量视频内容的领域,如电影制作、游戏制作和虚拟现实体验中具有重要应用价值。
Ruyi-Mini-7B是由CreateAI团队开发的开源图像到视频生成模型,具有约71亿参数,能够从输入图像生成360p到720p分辨率的视频帧,最长5秒。模型支持不同宽高比,并增强了运动和相机控制功能,提供更大的灵活性和创造力。该模型在Apache 2.0许可下发布,意味着用户可以自由使用和修改。
INFP是一个音频驱动的交互式头部生成框架,专为双人对话设计。它可以根据双人对话中的双轨音频和一个任意代理的单人肖像图像动态合成具有逼真面部表情和节奏性头部姿态动作的言语、非言语和交互式代理视频。该框架轻量而强大,适用于视频会议等即时通讯场景。INFP代表交互式(Interactive)、自然(Natural)、快速(Flash)和通用(Person-generic)。
AI Kissing Video Generator是一个利用先进人工智能技术的视频生成平台,可以将用户的照片转换成逼真的亲吻视频。这项技术代表了数字内容创作的未来,能够捕捉特殊时刻,创造浪漫、专业质量的视频。产品的主要优点包括100%由AI驱动、高清质量输出、自定义提示以及易于使用的界面。它适合内容创作者、数字艺术家以及任何希望创造独特、引人入胜的浪漫内容的人。
Ruyi是图森未来发布的图生视频大模型,专为在消费级显卡上运行而设计,并提供详尽的部署说明和ComfyUI工作流,以便用户能够快速上手。Ruyi凭借在帧间一致性、动作流畅性方面的卓越表现,以及和谐自然的色彩呈现和构图,将为视觉叙事提供全新的可能性。同时,该模型还针对动漫和游戏场景进行深度学习,将成为ACG爱好者理想的创意伙伴。
FastHunyuan是由Hao AI Lab开发的加速版HunyuanVideo模型,能够在6次扩散步骤中生成高质量视频,相比原始HunyuanVideo模型的50步扩散,速度提升约8倍。该模型在MixKit数据集上进行一致性蒸馏训练,具有高效率和高质量的特点,适用于需要快速生成视频的场景。
ComfyUI-HunyuanVideoWrapper-IP2V是一个基于HunyuanVideo的视频生成工具,它允许用户通过图像提示生成视频(IP2V),即利用图像作为生成视频的条件,提取图像的概念和风格。这项技术主要优点在于能够将图像的风格和内容融入视频生成过程中,而不仅仅是作为视频的第一帧。产品背景信息显示,该工具目前处于实验阶段,但已经可以工作,且对VRAM有较高要求,至少需要20GB。
Veo 2是Google DeepMind开发的最新视频生成模型,它代表了视频生成技术的一个重大进步。Veo 2能够逼真地模拟真实世界的物理效果和广泛的视觉风格,同时遵循简单和复杂的指令。该模型在细节、逼真度和减少人工痕迹方面显著优于其他AI视频模型。Veo 2的高级运动能力让其能够精确地表示运动,并且能够精确地遵循详细的指令,创造出各种镜头风格、角度和运动。Veo 2在视频生成领域的重要性体现在其增强了视频内容的多样性和质量,为电影制作、游戏开发、虚拟现实等领域提供了强大的技术支持。
CausVid是一个先进的视频生成模型,它通过将预训练的双向扩散变换器适配为因果变换器,实现了即时视频帧的生成。这一技术的重要性在于它能够显著减少视频生成的延迟,使得视频生成能够以交互式帧率(9.4FPS)在单个GPU上进行流式生成。CausVid模型支持从文本到视频的生成,以及零样本图像到视频的生成,展现了视频生成技术的新高度。
HelloMeme是一个集成了空间编织注意力(Spatial Knitting Attentions)的扩散模型,用于嵌入高级别和细节丰富的条件。该模型支持图像和视频的生成,具有改善生成视频与驱动视频之间表情一致性、减少VRAM使用、优化算法等优点。HelloMeme由HelloVision团队开发,属于HelloGroup Inc.,是一个前沿的图像和视频生成技术,具有重要的商业和教育价值。
SynCamMaster是一种先进的视频生成技术,它能够从多样化的视角同步生成多摄像机视频。这项技术通过预训练的文本到视频模型,增强了视频内容在不同视角下的动态一致性,对于虚拟拍摄等应用场景具有重要意义。该技术的主要优点包括能够处理开放世界视频的任意视角生成,整合6自由度摄像机姿态,并设计了一种渐进式训练方案,利用多摄像机图像和单目视频作为补充,显著提升了模型性能。