找到 268 个相关的AI工具
BestModelAI是一款智能AI模型选择工具,能自动从100多个选项中选择最适合的模型,无需用户了解模型复杂性。其主要优点在于智能路由到最佳模型、无需专业知识、使用方便快捷。
WorldPM-72B 是一个通过大规模训练获得的统一偏好建模模型,具有显著的通用性和较强的表现能力。该模型基于 15M 偏好数据,展示了在客观知识的偏好识别方面的巨大潜力。适合用于生成更高质量的文本内容,尤其在写作领域具有重要的应用价值。
TaoPrompt是一款专业的AI提示生成工具,能够快速而准确地创建AI提示,帮助用户优化与ChatGPT、Claude、Gemini等AI模型的交互体验。它能够帮助用户节省时间,提高工作效率,适用于各种领域的需求。
ImagineArt AI工具是一款人工智能艺术生成工具,利用先进的AI技术,可以将文字描述转化为生动的图像作品。其主要优点包括快速生成图像、灵活性高、用户友好,定位于为用户提供创意灵感和图像生成解决方案。
AI说唱生成器是一款利用AI技术从文本创作说唱音乐的工具,能够快速生成独特的说唱音乐作品。其优势在于快速创作、帮助解决创作障碍、提供免费音乐等。
GLM-4-32B 是一个高性能的生成语言模型,旨在处理多种自然语言任务。它通过深度学习技术训练而成,能够生成连贯的文本和回答复杂问题。该模型适用于学术研究、商业应用和开发者,价格合理,定位精准,是自然语言处理领域的领先产品。
Dream 7B 是由香港大学 NLP 组和华为诺亚方舟实验室联合推出的最新扩散大语言模型。它在文本生成领域展现了优异的性能,特别是在复杂推理、长期规划和上下文连贯性等方面。该模型采用了先进的训练方法,具有强大的计划能力和灵活的推理能力,为各类 AI 应用提供了更为强大的支持。
MeshifAI 是一个先进的文本到 3D 模型生成平台,旨在帮助开发者在应用程序、游戏和网站中快速集成高质量的 3D 生成功能。凭借其强大的 AI 技术,用户只需输入描述,便可生成逼真的 3D 模型,极大地简化了 3D 设计过程。该平台易于使用,适合各种开发需求。
DeepSeek-V3-0324 是一个先进的文本生成模型,具有 685 亿参数,采用 BF16 和 F32 张量类型,能够支持高效的推理和文本生成。该模型的主要优点在于其强大的生成能力和开放源码的特性,使其可以被广泛应用于多种自然语言处理任务。该模型的定位是为开发者和研究人员提供一个强大的工具,帮助他们在文本生成领域取得突破。
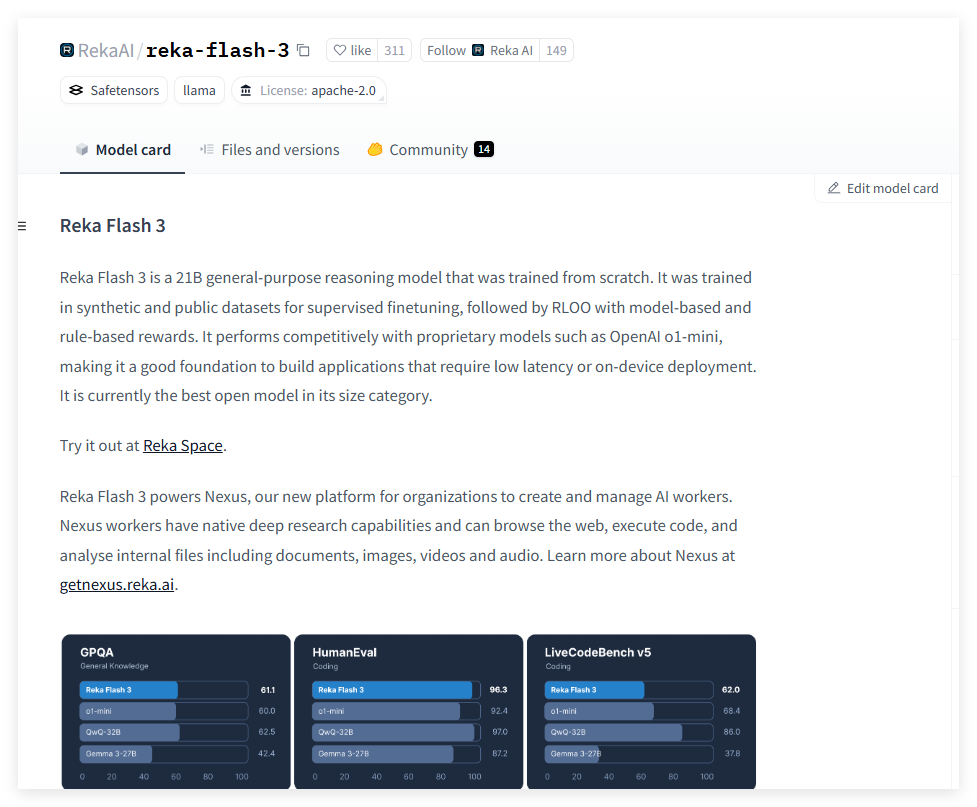
Reka Flash 3 是一款从零开始训练的 21 亿参数的通用推理模型,利用合成和公共数据集进行监督微调,结合基于模型和基于规则的奖励进行强化学习。该模型在低延迟和设备端部署应用中表现优异,具有较强的研究能力。它目前是同类开源模型中的最佳选择,适合于各种自然语言处理任务和应用场景。
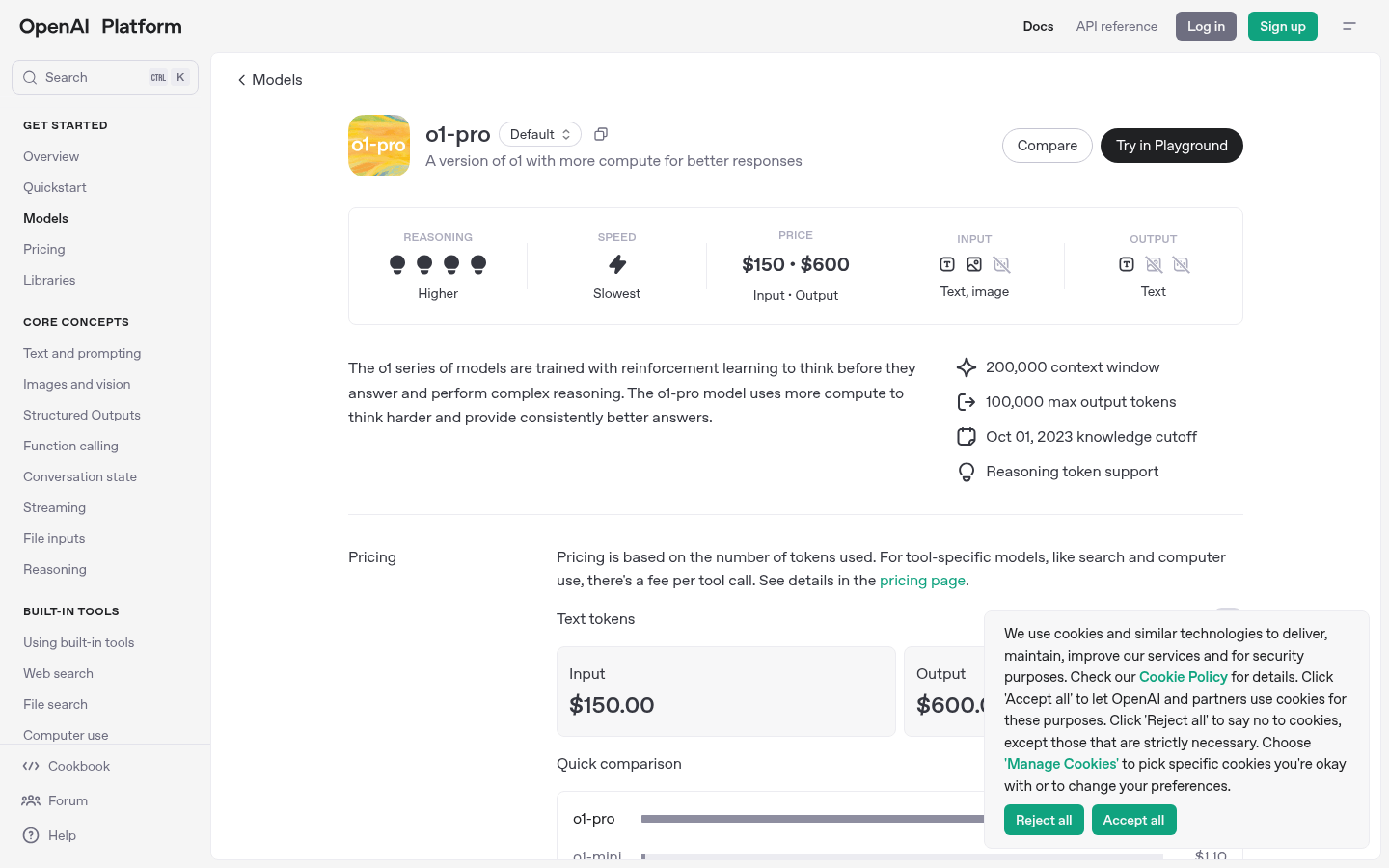
o1-pro 模型是一种先进的人工智能语言模型,专为提供高质量文本生成和复杂推理设计。其在推理和响应准确性上表现优越,适合需要高精度文本处理的应用场景。该模型的定价基于使用的 tokens,输入每百万 tokens 价格为 150 美元,输出每百万 tokens 价格为 600 美元,适合企业和开发者在其应用中集成高效的文本生成能力。
Venice 是一个以隐私保护为核心的人工智能平台,提供文本生成、图像生成和代码生成等多种功能。它强调用户数据的私密性,所有数据仅存储在用户设备上,不会上传至服务器。该平台利用领先的开源 AI 技术,提供无审查、无偏见的智能服务,旨在为用户提供一个自由探索创意和知识的环境。Venice 提供免费和付费两种账户选项,付费用户可享受更高分辨率的图像、无水印、无限制的提示次数等高级功能。
SmolVLM2 是一种轻量级的视频语言模型,旨在通过分析视频内容生成相关的文本描述或视频亮点。该模型具有高效性、低资源消耗的特点,适合在多种设备上运行,包括移动设备和桌面客户端。其主要优点是能够快速处理视频数据并生成高质量的文本输出,为视频内容创作、视频分析和教育等领域提供了强大的技术支持。该模型由 Hugging Face 团队开发,定位为高效、轻量化的视频处理工具,目前处于实验阶段,用户可以免费试用。
LLMs.txt生成器是一个由Firecrawl提供支持的在线工具,旨在帮助用户从网站生成用于LLM训练和推理的整合文本文件。它通过整合网页内容,为训练大型语言模型提供高质量的文本数据,从而提高模型的性能和准确性。该工具的主要优点是操作简单、高效,能够快速生成所需的文本文件。它主要面向需要大量文本数据进行模型训练的开发者和研究人员,为他们提供了一种便捷的解决方案。
QwQ-32B 是 Qwen 系列的推理模型,专注于复杂问题的思考和推理能力。它在下游任务中表现出色,尤其是在解决难题方面。该模型基于 Qwen2.5 架构,经过预训练和强化学习优化,具有 325 亿参数,支持 131072 个完整上下文长度的处理能力。其主要优点包括强大的推理能力、高效的长文本处理能力和灵活的部署选项。该模型适用于需要深度思考和复杂推理的场景,如学术研究、编程辅助和创意写作等。
olmOCR-7B-0225-preview 是由 Allen Institute for AI 开发的先进文档识别模型,旨在通过高效的图像处理和文本生成技术,将文档图像快速转换为可编辑的纯文本。该模型基于 Qwen2-VL-7B-Instruct 微调,结合了强大的视觉和语言处理能力,适用于大规模文档处理任务。其主要优点包括高效处理能力、高精度文本识别以及灵活的提示生成方式。该模型适用于研究和教育用途,遵循 Apache 2.0 许可证,强调负责任的使用。
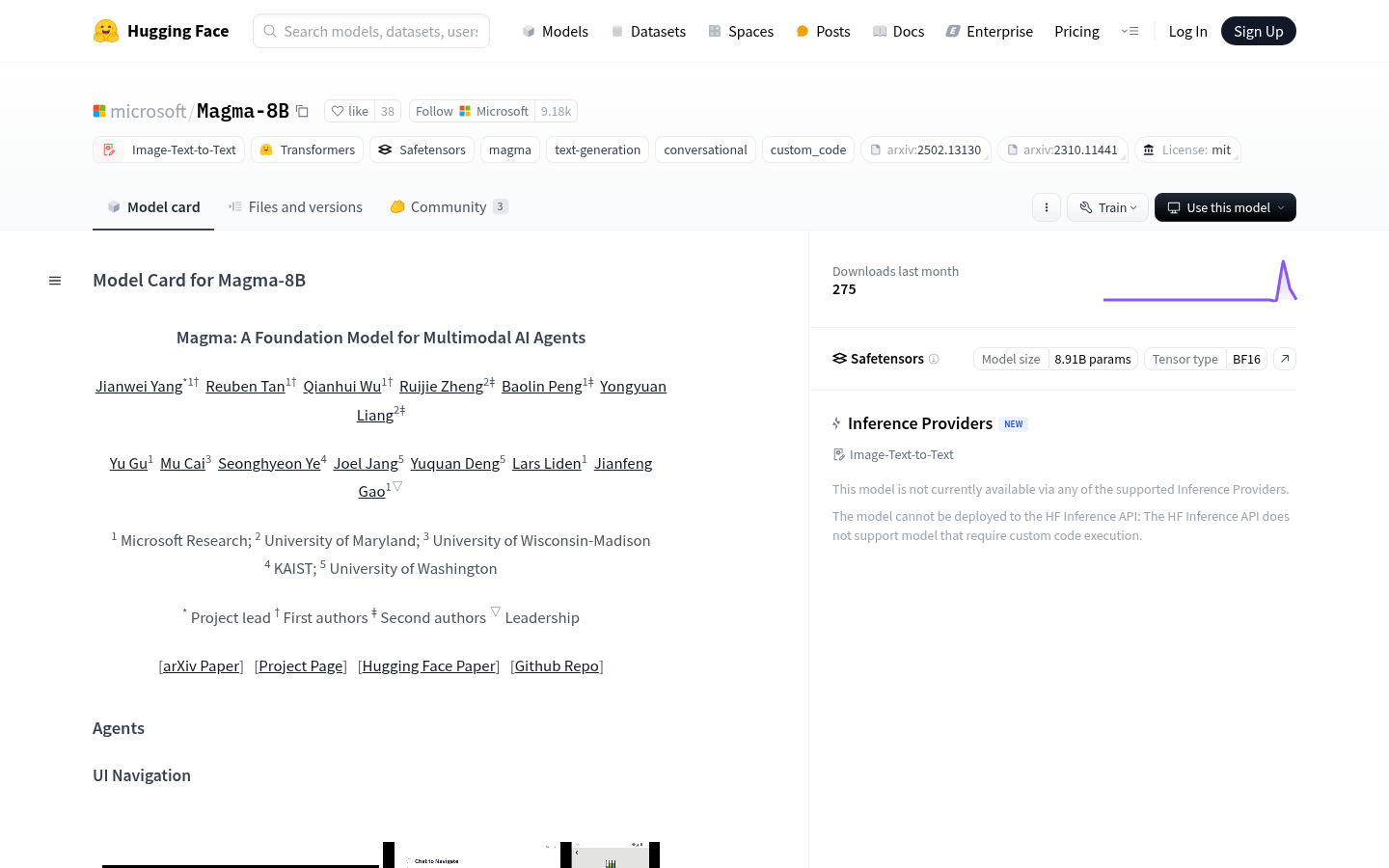
Magma-8B 是微软开发的一款多模态 AI 基础模型,专为研究多模态 AI 代理而设计。它结合了文本和图像输入,能够生成文本输出,并具备视觉规划和代理能力。该模型使用了 Meta LLaMA-3 作为语言模型骨干,并结合 CLIP-ConvNeXt-XXLarge 视觉编码器,支持从无标签视频数据中学习时空关系,具有强大的泛化能力和多任务适应性。Magma-8B 在多模态任务中表现出色,特别是在空间理解和推理方面。它为多模态 AI 研究提供了强大的工具,推动了虚拟和现实环境中复杂交互的研究。
s1是一个推理模型,专注于通过少量样本实现高效的文本生成能力。它通过预算强制技术在测试时进行扩展,能够匹配o1-preview的性能。该模型由Niklas Muennighoff等人开发,相关研究发表在arXiv上。模型使用Safetensors技术,具有328亿参数,支持文本生成任务。其主要优点是能够通过少量样本实现高质量的推理,适合需要高效文本生成的场景。
Xwen-Chat由xwen-team开发,为满足高质量中文对话模型需求而生,填补领域空白。其有多个版本,具备强大语言理解与生成能力,可处理复杂语言任务,生成自然对话内容,适用于智能客服等场景,在Hugging Face平台免费提供。
SmolVLM-256M 是由 Hugging Face 开发的多模态模型,基于 Idefics3 架构,专为高效处理图像和文本输入而设计。它能够回答关于图像的问题、描述视觉内容或转录文本,且仅需不到 1GB 的 GPU 内存即可运行推理。该模型在多模态任务上表现出色,同时保持轻量化架构,适合在设备端应用。其训练数据来自 The Cauldron 和 Docmatix 数据集,涵盖文档理解、图像描述等多领域内容,使其具备广泛的应用潜力。目前该模型在 Hugging Face 平台上免费提供,旨在为开发者和研究人员提供强大的多模态处理能力。
DeepSeek-R1-Distill-Qwen-14B 是 DeepSeek 团队开发的一款基于 Qwen-14B 的蒸馏模型,专注于推理和文本生成任务。该模型通过大规模强化学习和数据蒸馏技术,显著提升了推理能力和生成质量,同时降低了计算资源需求。其主要优点包括高性能、低资源消耗和广泛的适用性,适用于需要高效推理和文本生成的场景。
DeepSeek-R1-Distill-Qwen-32B 是由 DeepSeek 团队开发的高性能语言模型,基于 Qwen-2.5 系列进行蒸馏优化。该模型在多项基准测试中表现出色,尤其是在数学、代码和推理任务上。其主要优点包括高效的推理能力、强大的多语言支持以及开源特性,便于研究人员和开发者进行二次开发和应用。该模型适用于需要高性能文本生成的场景,如智能客服、内容创作和代码辅助等,具有广泛的应用前景。
AI ContentCraft 是一个强大的内容创作平台,旨在帮助创作者快速生成故事、播客脚本和多媒体内容。它通过集成文本生成、语音合成和图像生成技术,为创作者提供一站式的解决方案。该工具支持中英文内容转换,适合需要高效创作的用户。其技术栈包括 DeepSeek AI、Kokoro TTS 和 Replicate API,确保高质量的内容生成。产品目前开源免费,适合个人和团队使用。
InternLM3 是由 InternLM 团队开发的一系列高性能语言模型,专注于文本生成任务。该模型通过多种量化技术优化,能够在不同硬件环境下高效运行,同时保持出色的生成质量。其主要优点包括高效的推理性能、多样化的应用场景以及对多种文本生成任务的优化支持。InternLM3 适用于需要高质量文本生成的开发者和研究人员,能够帮助他们在自然语言处理领域快速实现应用。
MiniMax-Text-01是一个由MiniMaxAI开发的大型语言模型,拥有4560亿总参数,其中每个token激活459亿参数。它采用了混合架构,结合了闪电注意力、softmax注意力和专家混合(MoE)技术,通过先进的并行策略和创新的计算-通信重叠方法,如线性注意力序列并行主义加(LASP+)、变长环形注意力、专家张量并行(ETP)等,将训练上下文长度扩展到100万token,并能在推理时处理长达400万token的上下文。在多个学术基准测试中,MiniMax-Text-01展现出了顶级模型的性能。
Dria-Agent-a-7B是一个基于Qwen2.5-Coder系列训练的大型语言模型,专注于代理应用。它采用Pythonic函数调用方式,与传统JSON函数调用方法相比,具有单次并行多函数调用、自由形式推理和动作以及即时复杂解决方案生成等优势。该模型在多个基准测试中表现出色,包括Berkeley Function Calling Leaderboard (BFCL)、MMLU-Pro和Dria-Pythonic-Agent-Benchmark (DPAB)。模型大小为76.2亿参数,采用BF16张量类型,支持文本生成任务。其主要优点包括强大的编程辅助能力、高效的函数调用方式以及在特定领域的高准确率。该模型适用于需要复杂逻辑处理和多步骤任务执行的应用场景,如自动化编程、智能代理等。目前,该模型在Hugging Face平台上提供,供用户免费使用。
该模型是量化版大型语言模型,采用4位量化技术,降低存储与计算需求,适用于自然语言处理,参数量8.03B,免费且可用于非商业用途,适合资源受限环境下高性能语言应用需求者。
InternVL2.5-MPO是一个先进的多模态大型语言模型系列,基于InternVL2.5和混合偏好优化(MPO)构建。该系列模型在多模态任务中表现出色,能够处理图像、文本和视频数据,并生成高质量的文本响应。模型采用'ViT-MLP-LLM'范式,通过像素unshuffle操作和动态分辨率策略优化视觉处理能力。此外,模型还引入了多图像和视频数据的支持,进一步扩展了其应用场景。InternVL2.5-MPO在多模态能力评估中超越了多个基准模型,证明了其在多模态领域的领先地位。
PatronusAI/Llama-3-Patronus-Lynx-70B-Instruct是一个基于Llama-3架构的大型语言模型,旨在检测在RAG设置中的幻觉问题。该模型通过分析给定的文档、问题和答案,评估答案是否忠实于文档内容。其主要优点在于高精度的幻觉检测能力和强大的语言理解能力。该模型由Patronus AI开发,适用于需要高精度信息验证的场景,如金融分析、医学研究等。该模型目前为免费使用,但具体的商业应用可能需要与开发者联系。
CAG(Cache-Augmented Generation)是一种创新的语言模型增强技术,旨在解决传统RAG(Retrieval-Augmented Generation)方法中存在的检索延迟、检索错误和系统复杂性等问题。通过在模型上下文中预加载所有相关资源并缓存其运行时参数,CAG能够在推理过程中直接生成响应,无需进行实时检索。这种方法不仅显著降低了延迟,提高了可靠性,还简化了系统设计,使其成为一种实用且可扩展的替代方案。随着大型语言模型(LLMs)上下文窗口的不断扩展,CAG有望在更复杂的应用场景中发挥作用。
PRIME-RL/Eurus-2-7B-PRIME是一个基于PRIME方法训练的7B参数的语言模型,旨在通过在线强化学习提升语言模型的推理能力。该模型从Eurus-2-7B-SFT开始训练,利用Eurus-2-RL-Data数据集进行强化学习。PRIME方法通过隐式奖励机制,使模型在生成过程中更加注重推理过程,而不仅仅是结果。该模型在多项推理基准测试中表现出色,相较于其SFT版本平均提升了16.7%。其主要优点包括高效的推理能力提升、较低的数据和模型资源需求,以及在数学和编程任务中的优异表现。该模型适用于需要复杂推理能力的场景,如编程问题解答和数学问题求解。
llmstxt-generator 是一个用于生成LLM(大型语言模型)训练和推理所需的网站内容整合文本文件的工具。它通过爬取网站内容,将其合并成一个文本文件,支持生成标准的llms.txt和完整的llms-full.txt版本。该工具由firecrawl_dev提供支持进行网页爬取,并使用GPT-4-mini进行文本处理。其主要优点包括无需API密钥即可使用基本功能,同时提供Web界面和API访问,方便用户快速生成所需的文本文件。
Llama-3-Patronus-Lynx-8B-Instruct是由Patronus AI开发的一个基于meta-llama/Meta-Llama-3-8B-Instruct模型的微调版本,主要用于检测在RAG设置中的幻觉。该模型训练于包含CovidQA、PubmedQA、DROP、RAGTruth等多个数据集,包含人工标注和合成数据。它能够评估给定文档、问题和答案是否忠实于文档内容,不提供文档之外的新信息,也不与文档信息相矛盾。
EXAONE 3.5是LG AI Research开发的一系列指令调优的双语(英语和韩语)生成模型,参数范围从2.4B到32B。这些模型支持长达32K令牌的长上下文处理,并在真实世界用例和长上下文理解方面展现出最先进的性能,同时在与最近发布的类似大小模型相比的一般领域中保持竞争力。EXAONE 3.5模型包括:1) 2.4B模型,优化用于小型或资源受限设备的部署;2) 7.8B模型,与前代模型大小相匹配,但提供改进的性能;3) 32B模型,提供强大的性能。
Patronus-Lynx-8B-Instruct-v1.1是基于meta-llama/Meta-Llama-3.1-8B-Instruct模型的微调版本,主要用于检测RAG设置中的幻觉。该模型经过CovidQA、PubmedQA、DROP、RAGTruth等多个数据集的训练,包含人工标注和合成数据。它能够评估给定文档、问题和答案是否忠实于文档内容,不提供超出文档范围的新信息,也不与文档信息相矛盾。
Llama-3.1-70B-Instruct-AWQ-INT4是一个由Hugging Face托管的大型语言模型,专注于文本生成任务。该模型拥有70B个参数,能够理解和生成自然语言文本,适用于多种文本相关的应用场景,如内容创作、自动回复等。它基于深度学习技术,通过大量的数据训练,能够捕捉语言的复杂性和多样性。模型的主要优点包括高参数量带来的强大表达能力,以及针对特定任务的优化,使其在文本生成领域具有较高的效率和准确性。
HuatuoGPT-o1-7B是由FreedomIntelligence开发的医疗领域大型语言模型(LLM),专为高级医疗推理设计。该模型在提供最终回答之前,会生成复杂的思考过程,反映并完善其推理。HuatuoGPT-o1-7B支持中英文,能够处理复杂的医疗问题,并以'思考-回答'的格式输出结果,这对于提高医疗决策的透明度和可靠性至关重要。该模型基于Qwen2.5-7B,经过特殊训练以适应医疗领域的需求。
HuatuoGPT-o1-8B 是一个专为高级医疗推理设计的医疗领域大型语言模型(LLM)。它在提供最终响应之前会生成一个复杂的思考过程,反映并完善其推理过程。该模型基于LLaMA-3.1-8B构建,支持英文,并且采用'thinks-before-it-answers'的方法,输出格式包括推理过程和最终响应。此模型在医疗领域具有重要意义,因为它能够处理复杂的医疗问题并提供深思熟虑的答案,这对于提高医疗决策的质量和效率至关重要。
EXAONE-3.5-32B-Instruct-AWQ是LG AI Research开发的一系列指令调优的双语(英语和韩语)生成模型,参数从2.4B到32B不等。这些模型支持长达32K令牌的长上下文处理,在真实世界用例和长上下文理解方面展现出最先进的性能,同时在与最近发布的类似大小模型相比,在通用领域保持竞争力。该模型通过AWQ量化技术,实现了4位组级别的权重量化,优化了模型的部署效率。
Winihelper是一款由大学生团队开发的AI工具集,旨在通过先进的multi-agent系统架构和自研技术,优化工作流程,释放个人的全部潜能。产品依托北京绘感科技有限公司的万亿级专业数据库,提供高质量论文和专业百科词条,以专业写手的语气定制算法生成文本,让AI成为超级打工人。
EXAONE-3.5-2.4B-Instruct-AWQ是由LG AI Research开发的一系列双语(英语和韩语)指令调优生成模型,参数范围从2.4B到32B。这些模型支持长达32K令牌的长上下文处理,并且在真实世界用例和长上下文理解方面展现出最先进的性能,同时在与近期发布的类似大小模型相比,在通用领域保持竞争力。该模型在部署到小型或资源受限设备上进行了优化,并且采用了AWQ量化技术,实现了4位群组权重量化(W4A16g128)。
API.box是一个提供先进AI接口的平台,旨在帮助开发者快速集成AI功能到他们的项目中。它提供全面的API文档和详细的调用日志,确保高效开发和系统性能稳定。API.box具备企业级安全性和强大可扩展性,支持高并发需求,同时提供免费试用和商业用途的输出许可,是开发者和企业的理想选择。
Image to Prompt AI是一个利用人工智能技术将图像转换成详细文本描述的工具。它通过高级AI技术准确分析图像内容,提供详细的描述和洞察,帮助用户将视觉内容转化为文本,增强内容的可访问性和搜索引擎优化(SEO)。该产品背景信息显示,它支持多种图像格式,并且每天为用户提供20次免费图像到文本的转换服务,适合内容创作者、市场营销人员和企业主使用。
EXAONE-3.5-32B-Instruct是由LG AI Research开发的一系列指令调优的双语(英语和韩语)生成模型,包含从2.4B到32B参数的不同模型。这些模型支持长达32K令牌的长上下文处理,并在真实世界用例和长上下文理解方面展现出了最先进的性能,同时在与近期发布的类似大小模型相比时,在通用领域也保持了竞争力。
Llama-Lynx-70b-4bit-Quantized是由PatronusAI开发的一个大型文本生成模型,具有70亿参数,并且经过4位量化处理,以优化模型大小和推理速度。该模型基于Hugging Face的Transformers库构建,支持多种语言,特别是在对话生成和文本生成领域表现出色。它的重要性在于能够在保持较高性能的同时减少模型的存储和计算需求,使得在资源受限的环境中也能部署强大的AI模型。
Llama-lynx-70b-4bitAWQ是一个由Hugging Face托管的70亿参数的文本生成模型,使用了4-bit精度和AWQ技术。该模型在自然语言处理领域具有重要性,特别是在需要处理大量数据和复杂任务时。它的优势在于能够生成高质量的文本,同时保持较低的计算成本。产品背景信息显示,该模型与'transformers'和'safetensors'库兼容,适用于文本生成任务。
PatronusAI/glider-gguf是一个基于Hugging Face平台的高性能量化语言模型,采用GGUF格式,支持多种量化版本,如BF16、Q8_0、Q5_K_M、Q4_K_M等。该模型基于phi3架构,拥有3.82B参数,主要优点包括高效的计算性能和较小的模型体积,适用于需要快速推理和低资源消耗的场景。产品背景信息显示,该模型由PatronusAI提供,适合需要进行自然语言处理和文本生成的开发者和企业使用。
EXAONE-3.5-7.8B-Instruct是由LG AI Research开发的一系列指令调优的双语(英语和韩语)生成模型,参数范围从2.4B到32B。这些模型支持长达32K令牌的长上下文处理,并在真实世界用例和长上下文理解方面展现出最先进的性能,同时在与近期发布的类似大小模型相比,在通用领域保持竞争力。
EXAONE-3.5-2.4B-Instruct是LG AI Research开发的一系列双语(英语和韩语)指令调优的生成模型,参数范围从2.4B到32B。这些模型支持长达32K令牌的长上下文处理,并在真实世界用例和长上下文理解方面展现出最先进的性能,同时在与最近发布的类似大小模型相比的通用领域中保持竞争力。该模型特别适合需要处理长文本和多语言需求的场景,如自动翻译、文本摘要、对话系统等。
EXAONE 3.5是LG AI Research开发的一系列双语(英语和韩语)指令调优的生成模型,参数从2.4B到32B不等。这些模型支持长达32K令牌的长上下文处理,在真实世界用例和长上下文理解方面展现出了最先进的性能,同时在与近期发布的类似大小模型相比,在通用领域保持竞争力。EXAONE 3.5模型包括:1) 2.4B模型,优化用于部署在小型或资源受限的设备上;2) 7.8B模型,与前代模型大小匹配但提供改进的性能;3) 32B模型,提供强大的性能。
EXAONE-3.5-2.4B-Instruct-GGUF是由LG AI Research开发的一系列双语(英语和韩语)指令调优的生成型模型,参数范围从2.4B到32B。这些模型支持长达32K令牌的长上下文处理,并在真实世界用例和长上下文理解方面展现出最先进的性能,同时在与近期发布的类似大小模型相比,在通用领域保持竞争力。该模型的重要性在于其优化了在小型或资源受限设备上的部署,同时提供了强大的性能。
CohereForAI/c4ai-command-r7b-12-2024是一个7B参数的多语言模型,专注于推理、总结、问答和代码生成等高级任务。该模型支持检索增强生成(RAG)和工具使用,能够使用和组合多个工具来完成更复杂的任务。它在企业相关的代码用例上表现优异,支持23种语言。
OLMo-2-1124-7B-RM是由Hugging Face和Allen AI共同开发的一个大型语言模型,专注于文本生成和分类任务。该模型基于7B参数的规模构建,旨在处理多样化的语言任务,包括聊天、数学问题解答、文本分类等。它是基于Tülu 3数据集和偏好数据集训练的奖励模型,用于初始化RLVR训练中的价值模型。OLMo系列模型的发布,旨在推动语言模型的科学研究,通过开放代码、检查点、日志和相关的训练细节,促进了模型的透明度和可访问性。
Deepthought-8B是一个小型但功能强大的推理模型,它基于LLaMA-3.1 8B构建,旨在使AI推理更加透明和可控。尽管模型相对较小,但它实现了与更大模型相媲美的复杂推理能力。该模型以其独特的问题解决方法而设计,将其思考过程分解为清晰、独特、有记录的步骤,并将推理过程以结构化的JSON格式输出,便于理解和验证其决策过程。
Qwen2-VL-7B是Qwen-VL模型的最新迭代,代表了近一年的创新成果。该模型在视觉理解基准测试中取得了最先进的性能,包括MathVista、DocVQA、RealWorldQA、MTVQA等。它能够理解超过20分钟的视频,为基于视频的问题回答、对话、内容创作等提供高质量的支持。此外,Qwen2-VL还支持多语言,除了英语和中文,还包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。模型架构更新包括Naive Dynamic Resolution和Multimodal Rotary Position Embedding (M-ROPE),增强了其多模态处理能力。
Llama-3.3-70B-Instruct是由Meta开发的一个70亿参数的大型语言模型,专门针对多语言对话场景进行了优化。该模型使用优化的Transformer架构,并通过监督式微调(SFT)和基于人类反馈的强化学习(RLHF)来提高其有用性和安全性。它支持多种语言,并能够处理文本生成任务,是自然语言处理领域的一项重要技术。
OLMo-2-1124-7B-SFT是由艾伦人工智能研究所(AI2)发布的一个英文文本生成模型,它是OLMo 2 7B模型的监督微调版本,专门针对Tülu 3数据集进行了优化。Tülu 3数据集旨在提供多样化任务的顶尖性能,包括聊天、数学问题解答、GSM8K、IFEval等。该模型的主要优点包括强大的文本生成能力、多样性任务处理能力以及开源的代码和训练细节,使其成为研究和教育领域的有力工具。
OLMo-2-1124-13B-SFT是由Allen AI研究所开发的一个大型语言模型,经过在特定数据集上的监督微调,旨在提高在多种任务上的表现,包括聊天、数学问题解答、文本生成等。该模型基于Transformers库和PyTorch框架,支持英文,拥有Apache 2.0的开源许可证,适用于研究和教育用途。
INTELLECT-1-Instruct是一个由Prime Intellect训练的10亿参数语言模型,从零开始在1万亿个英文文本和代码token上进行训练。该模型支持文本生成,并且具有分布式训练的能力,能够在不可靠的、全球分布的工作者上进行高性能训练。它使用了DiLoCo算法进行训练,并利用自定义的int8 all-reduce内核来减少通信负载,显著降低了通信开销。这个模型的背景信息显示,它是由30个独立的社区贡献者提供计算支持,并在3个大洲的14个并发节点上进行训练。
OLMo-2-1124-7B-DPO是由Allen人工智能研究所开发的一个大型语言模型,经过特定的数据集进行监督式微调,并进一步进行了DPO训练。该模型旨在提供在多种任务上,包括聊天、数学问题解答、文本生成等的高性能表现。它是基于Transformers库构建的,支持PyTorch,并以Apache 2.0许可发布。
OLMo-2-1124-13B-DPO是经过监督微调和DPO训练的13B参数大型语言模型,主要针对英文,旨在提供在聊天、数学、GSM8K和IFEval等多种任务上的卓越性能。该模型是OLMo系列的一部分,旨在推动语言模型的科学研究。模型训练基于Dolma数据集,并公开代码、检查点、日志和训练细节。
DOLMino dataset mix for OLMo2 stage 2 annealing training是一个混合了多种高质数据的数据集,用于在OLMo2模型训练的第二阶段。这个数据集包含了网页页面、STEM论文、百科全书等多种类型的数据,旨在提升模型在文本生成任务中的表现。它的重要性在于为开发更智能、更准确的自然语言处理模型提供了丰富的训练资源。
allenai/olmo-mix-1124数据集是由Hugging Face提供的一个大规模多模态预训练数据集,主要用于训练和优化自然语言处理模型。该数据集包含了大量的文本信息,覆盖了多种语言,并且可以用于各种文本生成任务。它的重要性在于提供了一个丰富的资源,使得研究人员和开发者能够训练出更加精准和高效的语言模型,进而推动自然语言处理技术的发展。
OLMo-2-1124-13B-Instruct是由Allen AI研究所开发的一款大型语言模型,专注于文本生成和对话任务。该模型在多个任务上表现出色,包括数学问题解答、科学问题解答等。它是基于13B参数的版本,经过在特定数据集上的监督微调和强化学习训练,以提高其性能和安全性。作为一个开源模型,它允许研究人员和开发者探索和改进语言模型的科学。
Skywork-o1-Open-Llama-3.1-8B是由昆仑科技Skywork团队开发的一系列模型,这些模型结合了o1风格的慢思考和推理能力。该系列模型不仅在输出中展现出天生的思考、规划和反思能力,而且在标准基准测试中的推理技能有显著提升。这一系列代表了AI能力的战略进步,将原本较弱的基础模型推向了推理任务的最新技术(SOTA)。
QwQ-32B-Preview是一个由Qwen团队开发的实验性研究模型,旨在提高人工智能的推理能力。该模型展示了有前景的分析能力,但也存在一些重要的限制。模型在数学和编程方面表现出色,但在常识推理和细微语言理解方面还有提升空间。该模型使用了transformers架构,具有32.5B个参数,64层,以及40个注意力头(GQA)。产品背景信息显示,QwQ-32B-Preview是基于Qwen2.5-32B模型的进一步开发,具有更深层次的语言理解和生成能力。
Llama-3.1-Tulu-3-8B-SFT是Tülu3模型家族中的一员,这是一个领先的指令遵循模型家族,提供完全开源的数据、代码和配方,旨在为现代后训练技术提供全面的指南。该模型不仅在聊天任务上表现出色,还在MATH、GSM8K和IFEval等多样化任务上展现了卓越的性能。
Llama-3.1-Tulu-3-70B-SFT是Tülu3模型家族的一部分,专为现代后训练技术提供全面指南而设计。该模型不仅在聊天任务上表现出色,还在MATH、GSM8K和IFEval等多种任务上实现了最先进的性能。它是基于公开可用的、合成的和人类创建的数据集训练的,主要使用英语,并遵循Llama 3.1社区许可协议。
TwinMind是一个个人AI侧边栏,可以理解会议和网站内容,为您提供实时答案,并根据上下文为您撰写任何内容。它允许您访问最新的AI模型,提出关于浏览器标签页、PDF、YouTube视频等的任何问题,提供会议和面试中的下一步建议,以及在侧边栏上搜索网络并即时获得答案。TwinMind注重隐私保护,不在任何地方存储您的音频,而是直接在设备上处理音频数据,确保音频不会被回放或稍后访问。
Llama-3.1-Tulu-3-8B-DPO是Tülu3模型家族中的一员,专注于指令遵循,提供完全开源的数据、代码和配方,旨在作为现代后训练技术的全面指南。该模型专为聊天以外的多样化任务设计,如MATH、GSM8K和IFEval,以达到最先进的性能。模型主要优点包括开源数据和代码、支持多种任务、以及优秀的性能。产品背景信息显示,该模型由Allen AI研究所开发,遵循Llama 3.1社区许可协议,适用于研究和教育用途。
Llama-3.1-Tulu-3-70B-DPO是Tülu3模型家族的一部分,专为现代后训练技术提供全面指南。该模型家族旨在除了聊天之外的多种任务上实现最先进的性能,如MATH、GSM8K和IFEval。它是基于公开可用的、合成的和人为创建的数据集训练的模型,主要使用英语,并遵循Llama 3.1社区许可协议。
Llama-3.1-Tulu-3-70B是Tülu3模型家族中的一员,专为现代后训练技术提供全面的指南。该模型不仅在聊天任务上表现出色,还在MATH、GSM8K和IFEval等多种任务上展现出了卓越的性能。作为一个开源模型,它允许研究人员和开发者访问和使用其数据和代码,以推动自然语言处理技术的发展。
Llama-3.1-Tulu-3-8B是Tülu3指令遵循模型家族的一部分,专为多样化任务设计,包括聊天、数学问题解答、GSM8K和IFEval等。这个模型家族以其卓越的性能和完全开源的数据、代码以及现代后训练技术的全面指南而著称。模型主要使用英文,并且是基于allenai/Llama-3.1-Tulu-3-8B-DPO模型微调而来。
Qwen Turbo 1M Demo是一个基于Hugging Face平台的人工智能模型演示。这个模型代表了自然语言处理技术的最新进展,特别是在中文文本理解和生成方面。它的重要性在于能够提供高效、准确的语言模型,以支持各种语言相关的应用,如机器翻译、文本摘要、问答系统等。Qwen Turbo 1M Demo以其较小的模型尺寸和快速的处理速度而受到青睐,适合需要快速部署和高效运行的场合。目前,该模型是免费试用的,具体价格和定位可能需要进一步的商业洽谈。
fixie-ai/ultravox-v0_4_1-llama-3_1-70b是一个基于预训练的Llama3.1-70B-Instruct和whisper-large-v3-turbo的大型语言模型,能够处理语音和文本输入,生成文本输出。该模型通过特殊伪标记<|audio|>将输入音频转换为嵌入,并与文本提示合并后生成输出文本。Ultravox的开发旨在扩展语音识别和文本生成的应用场景,如语音代理、语音到语音翻译和口语音频分析等。该模型遵循MIT许可,由Fixie.ai开发。
Hermes 3是Nous Research公司推出的Hermes系列最新版大型语言模型(LLM),相较于Hermes 2,它在代理能力、角色扮演、推理、多轮对话、长文本连贯性等方面都有显著提升。Hermes系列模型的核心理念是将LLM与用户对齐,赋予终端用户强大的引导能力和控制权。Hermes 3在Hermes 2的基础上,进一步增强了功能调用和结构化输出能力,提升了通用助手能力和代码生成技能。
ChatGPT是由OpenAI训练的对话生成模型,能够以对话形式与人互动,回答后续问题,承认错误,挑战错误的前提,并拒绝不适当的请求。OpenAI日前买下了http://chat.com域名,该域名已经指向了ChatGPT。ChatGPT它是InstructGPT的姊妹模型,后者被训练以遵循提示中的指令并提供详细的回答。ChatGPT代表了自然语言处理技术的最新进展,其重要性在于能够提供更加自然和人性化的交互体验。产品背景信息包括其在2022年11月30日的发布,以及在研究预览期间免费提供给用户使用。
Aquila-VL-2B模型是一个基于LLava-one-vision框架训练的视觉语言模型(VLM),选用Qwen2.5-1.5B-instruct模型作为语言模型(LLM),并使用siglip-so400m-patch14-384作为视觉塔。该模型在自建的Infinity-MM数据集上进行训练,包含约4000万图像-文本对。该数据集结合了从互联网收集的开源数据和使用开源VLM模型生成的合成指令数据。Aquila-VL-2B模型的开源,旨在推动多模态性能的发展,特别是在图像和文本的结合处理方面。
Ferret-UI是首个以用户界面为中心的多模态大型语言模型(MLLM),专为指代表达、定位和推理任务设计。它基于Gemma-2B和Llama-3-8B构建,能够执行复杂的用户界面任务。这个版本遵循了Apple的研究论文,是一个强大的工具,可以用于图像文本到文本的任务,并且在对话和文本生成方面具有优势。
SmolLM2是一系列轻量级的语言模型,包含135M、360M和1.7B参数的版本。这些模型能够在保持轻量级的同时解决广泛的任务,特别适合在设备上运行。1.7B版本的模型在指令遵循、知识、推理和数学方面相较于前代SmolLM1-1.7B有显著进步。它使用包括FineWeb-Edu、DCLM、The Stack等多个数据集进行了训练,并且通过使用UltraFeedback进行了直接偏好优化(DPO)。该模型还支持文本重写、总结和功能调用等任务。
AI Sentence Generator是一个基于人工智能技术的工具,能够自动创建不同风格和主题的句子。它可以帮助作家、学生和内容创作者快速生成独特的句子。这个工具的主要优点包括节省内容创作的时间与精力、为遇到写作障碍的作者提供灵感、提供多样化的句子结构和词汇。产品背景信息显示,该工具主要面向需要快速生成文本内容的用户,无论是为了博客文章、社交媒体更新还是营销文案,都能提供帮助。目前,该工具主要支持英文,未来计划增加对其他语言的支持。
Aya模型是一个大规模的多语言生成性语言模型,能够在101种语言中遵循指令。该模型在多种自动和人类评估中优于mT0和BLOOMZ,尽管它覆盖的语言数量是后者的两倍。Aya模型使用包括xP3x、Aya数据集、Aya集合、DataProvenance集合的一个子集和ShareGPT-Command等多个数据集进行训练,并在Apache-2.0许可下发布,以推动多语言技术的发展。
Aya Expanse是一个具有高级多语言能力的开放权重研究模型。它专注于将高性能的预训练模型与Cohere For AI一年的研究成果相结合,包括数据套利、多语言偏好训练、安全调整和模型合并。该模型是一个强大的多语言大型语言模型,服务于23种语言,包括阿拉伯语、中文(简体和繁体)、捷克语、荷兰语、英语、法语、德语、希腊语、希伯来语、印地语、印尼语、意大利语、日语、韩语、波斯语、波兰语、葡萄牙语、罗马尼亚语、俄语、西班牙语、土耳其语、乌克兰语和越南语。
Aya Expanse 32B是由Cohere For AI开发的多语言大型语言模型,拥有32亿参数,专注于提供高性能的多语言支持。它结合了先进的数据仲裁、多语言偏好训练、安全调整和模型合并技术,以支持23种语言,包括阿拉伯语、中文(简体和繁体)、捷克语、荷兰语、英语、法语、德语、希腊语、希伯来语、印地语、印尼语、意大利语、日语、韩语、波斯语、波兰语、葡萄牙语、罗马尼亚语、俄语、西班牙语、土耳其语、乌克兰语和越南语。该模型的发布旨在使社区基础的研究工作更加易于获取,通过发布高性能的多语言模型权重,供全球研究人员使用。
Meta-spirit-lm是由Meta公司开发的一款先进的自然语言处理模型,它在Hugging Face平台上发布。这款模型在处理语言相关的任务时表现出色,如文本生成、翻译、问答等。它的重要性在于能够理解和生成自然语言,极大地推动了人工智能在语言理解领域的进步。该模型在开源社区中受到广泛关注,可以用于研究和商业用途,但需遵守FAIR Noncommercial Research License。
LightRAG是一个基于检索增强型生成模型,旨在通过结合检索和生成的优势来提升文本生成任务的性能。该模型在保持生成速度的同时,能够提供更准确和相关的信息,这对于需要快速且准确信息检索的应用场景尤为重要。LightRAG的开发背景是基于对现有文本生成模型的改进需求,特别是在需要处理大量数据和复杂查询时。该模型目前是开源的,可以免费使用,对于研究人员和开发者来说,它提供了一个强大的工具来探索和实现基于检索的文本生成任务。
tiiuae/falcon-mamba-7b是由TII UAE开发的高性能因果语言模型,基于Mamba架构,专为生成任务设计。该模型在多个基准测试中展现出色的表现,并且能够在不同的硬件配置上运行,支持多种精度设置,以适应不同的性能和资源需求。模型的训练使用了先进的3D并行策略和ZeRO优化技术,使其在大规模GPU集群上高效训练成为可能。
Entropy-based sampling 是一种基于熵理论的采样技术,用于提升语言模型在生成文本时的多样性和准确性。该技术通过计算概率分布的熵和方差熵来评估模型的不确定性,从而在模型可能陷入局部最优或过度自信时调整采样策略。这种方法有助于避免模型输出的单调重复,同时在模型不确定性较高时增加输出的多样性。
AI句子生成器是一个基于人工智能技术的在线工具,它能够根据用户提供的主题和类型生成连贯且上下文相关的句子。这项技术对于作家、学生和任何希望提高写作技能的人都非常有价值。它通过复杂的自然语言处理技术和机器学习模型,确保每个生成的句子都是定制化的,以满足用户的需求。AI句子生成器的主要优点包括简化写作过程、节省时间、激发创造力,并帮助用户生成多样化的句子结构和语调,提高整体写作风格。
AMD-Llama-135m是一个基于LLaMA2模型架构训练的语言模型,能够在AMD MI250 GPU上流畅加载使用。该模型支持生成文本和代码,适用于多种自然语言处理任务。
Daily AI Writer是一个AI驱动的写作助手,它利用先进的人工智能技术帮助用户快速生成电子邮件、社交媒体帖子和文档。该产品提供AI辅助写作、智能回复助手、AI写作教练等功能,支持多语言,帮助用户提升写作技能,调整语气和风格以适应不同的读者群体。它适用于专业人士、学生、社交媒体爱好者、内容创作者和非母语人士,旨在提高写作效率和质量。
Llama-3.2-1B是由Meta公司发布的多语言大型语言模型,专注于文本生成任务。该模型使用优化的Transformer架构,并通过监督式微调(SFT)和人类反馈的强化学习(RLHF)进行调优,以符合人类对有用性和安全性的偏好。该模型支持8种语言,包括英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语,并在多种对话使用案例中表现优异。
Pixtral-12B-2409是由Mistral AI团队开发的多模态模型,包含12B参数的多模态解码器和400M参数的视觉编码器。该模型在多模态任务中表现出色,支持不同尺寸的图像,并在文本基准测试中保持最前沿的性能。它适用于需要处理图像和文本数据的高级应用,如图像描述生成、视觉问答等。
MiniMax模型矩阵是一套集成了多种AI大模型的产品,包括视频生成、音乐生成、文本生成和语音合成等,旨在通过先进的人工智能技术推动内容创作的革新。这些模型不仅能够提供高分辨率和高帧率的视频生成,还能创作各种风格的音乐,生成高质量的文本内容,以及提供超拟人音色的语音合成。MiniMax模型矩阵代表了AI在内容创作领域的前沿技术,具有高效、创新和多样化的特点,能够满足不同用户在创作上的需求。
XVERSE-MoE-A36B是由深圳元象科技自主研发的多语言大型语言模型,采用混合专家模型(MoE)架构,具有2554亿的总参数规模和360亿的激活参数量。该模型支持包括中、英、俄、西等40多种语言,特别在中英双语上表现优异。模型使用8K长度的训练样本,并通过精细化的数据采样比例和动态数据切换策略,保证了模型的高质量和多样性。此外,模型还针对MoE架构进行了定制优化,提升了计算效率和整体吞吐量。
DataGemma RIG是一系列微调后的Gemma 2模型,旨在帮助大型语言模型(LLMs)访问并整合来自Data Commons的可靠公共统计数据。该模型采用检索式生成方法,通过自然语言查询Data Commons的现有自然语言接口,对响应中的统计数据进行注释。DataGemma RIG在TPUv5e上使用JAX进行训练,目前是早期版本,主要用于学术和研究目的,尚未准备好用于商业或公众使用。
Jreader-lm-1.5b是由Jina AI开发的一款文本生成模型,专门用于将HTML格式的内容转换为Markdown格式。这一技术对于需要进行内容转换的开发者和内容创作者来说非常重要,因为它可以自动完成格式转换,提高工作效率。该模型在Hugging Face平台上提供,支持多语言,并且可以在Google Colab上免费试用。
Jina Reader-LM是一系列将HTML内容转换为Markdown内容的模型,适用于内容转换任务。该模型在精选的HTML及其对应Markdown内容上进行训练,能够高效地处理网页内容的格式转换,为内容创作者和开发者提供便利。
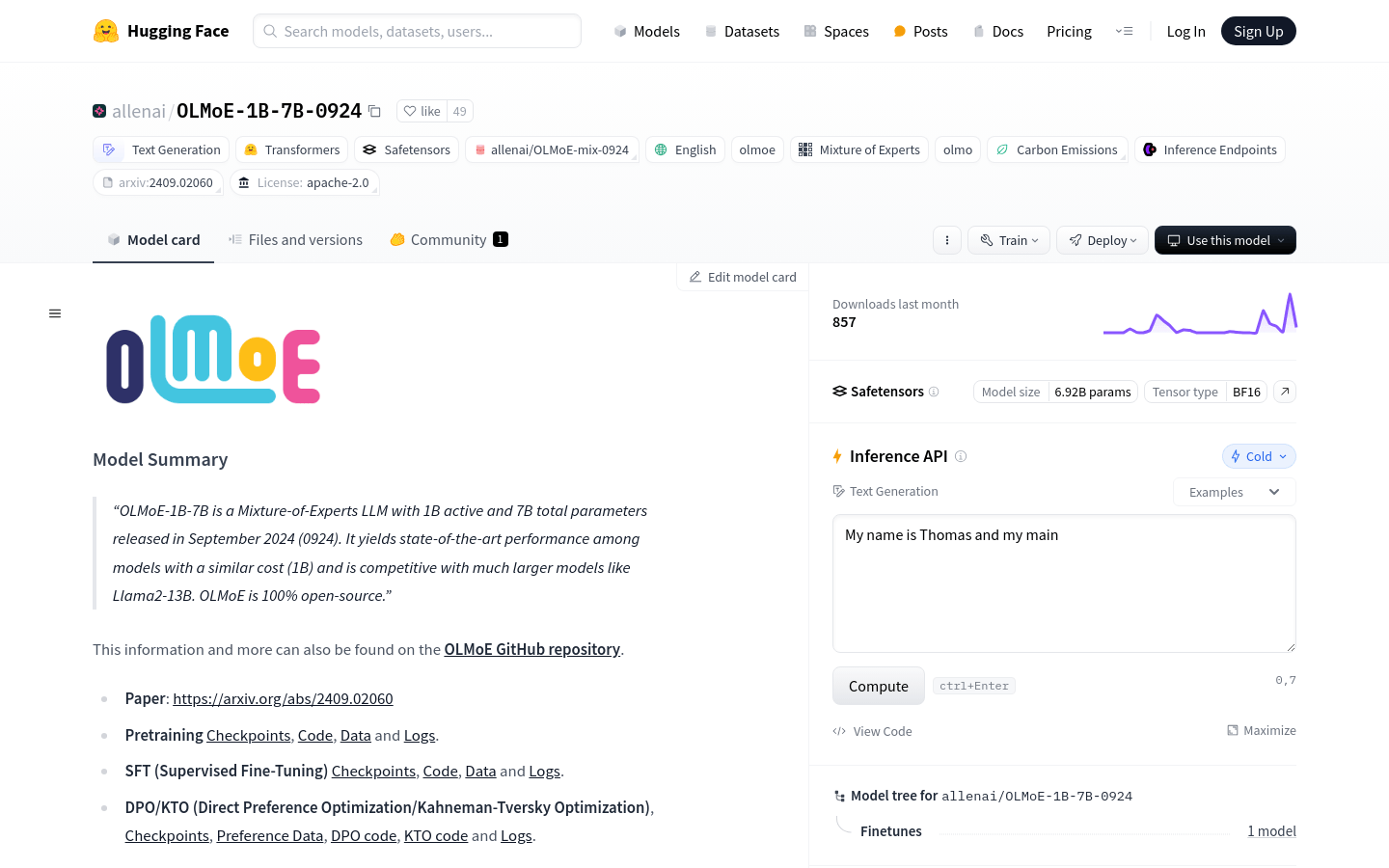
OLMoE-1B-7B 是一个具有1亿活跃参数和7亿总参数的专家混合型大型语言模型(LLM),于2024年9月发布。该模型在成本相似的模型中表现卓越,与更大的模型如Llama2-13B竞争。OLMoE完全开源,支持多种功能,包括文本生成、模型训练和部署等。
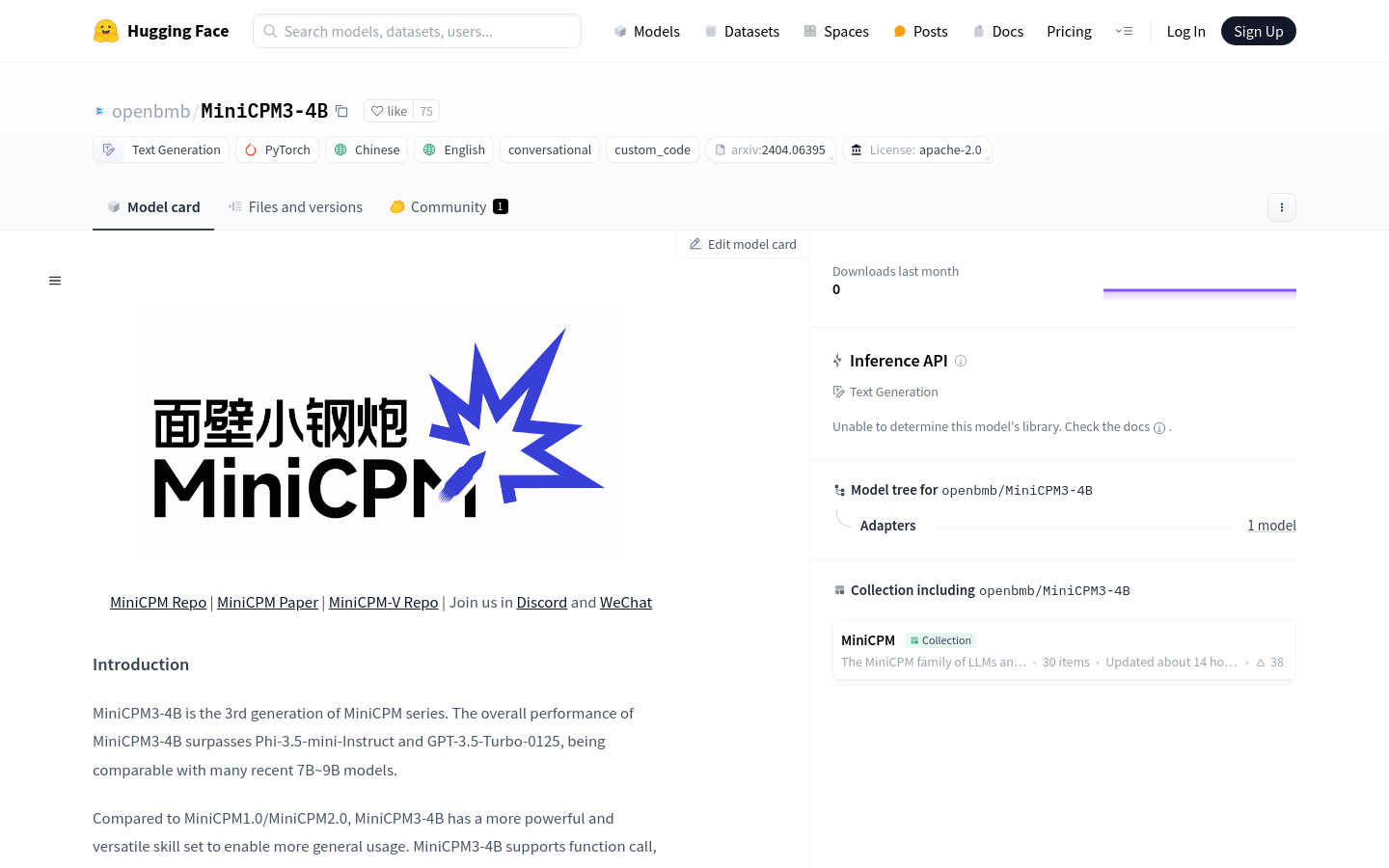
MiniCPM3-4B是MiniCPM系列的第三代产品,整体性能超越了Phi-3.5-mini-Instruct和GPT-3.5-Turbo-0125,与许多近期的7B至9B模型相当。与前两代相比,MiniCPM3-4B具有更强大的多功能性,支持函数调用和代码解释器,使其能够更广泛地应用于各种场景。此外,MiniCPM3-4B拥有32k的上下文窗口,配合LLMxMapReduce技术,理论上可以处理无限上下文,而无需大量内存。