找到 360 个相关的AI工具
imini AI是一款聚合GPT-5、Grok 4、Gemini 2.5 Pro、Claude Opus 4 Thinking、DeepSeek R1等最新AI大模型的超级AI智能体。它具有出色的智能交互功能,为用户提供高效的聊天、深度研究、报告撰写等服务。定位于提升用户工作和生活效率。
Nano Banana 是谷歌推出的前沿 AI 图像生成与编辑模型,代表了 AI 绘画工具向创意伙伴的转变。它能够理解图像上下文,并进行高精度的图像编辑,支持多样化的创作方式,适合艺术家、设计师和任何对创意表达感兴趣的人士使用。
VO3 AI是由Veo3 AI技术驱动的创新视觉生成平台,通过最先进的深度学习将脚本、想法或提示转化为沉浸式视频,提升数字体验。
FLUX.1 Krea [dev] 是一个拥有 120 亿参数的修正流转换器,专为从文本描述生成高质量图像而设计。该模型经过指导蒸馏训练,使其更高效,且开放权重推动科学研究和艺术创作。产品强调其美学摄影能力和强大的提示遵循能力,是对封闭源替代品的有力竞争。使用该模型的用户能够进行个人、科学和商业用途,推动创新的工作流程。
蓝耘元生代 AIDC OS 是一款专注于 GPU 算力云服务的产品,旨在为企业和开发者提供强大的计算能力和灵活的资源配置。该产品支持多种 GPU 型号,按需计费,适用于深度学习、图形渲染等领域。其主要优点在于高性能的计算资源、可扩展的存储解决方案以及合规的云服务环境,满足不同规模企业的需求。价格为每小时 1.50 元到 1.60 元不等,依据所选 GPU 型号而定。
ZenCtrl 是一个综合工具包,旨在解决图像生成中的核心挑战。无需微调,可从单个主体图像生成多视角、高分辨率的图像。它能够控制形状、姿势、相机角度和上下文,非常适合进行产品摄影、时尚试穿等场景。该工具包还将发布 API,便于集成与使用。
OmniAvatar 是一种先进的音频驱动视频生成模型,能够生成高质量的虚拟形象动画。其重要性在于结合了音频和视觉内容,实现高效的身体动画,适用于各种应用场景。该技术利用深度学习算法,实现高保真的动画生成,支持多种输入形式,定位于影视、游戏和社交领域。该模型是开源的,促进了技术的共享与应用。
Hailo AI on the Edge Processors提供AI加速器和视觉处理器,支持边缘设备解决方案,旨在实现新时代的AI边缘处理和视频增强。产品定位于提供高性能深度学习应用,同时支持感知和视频增强。
BAGEL是一款可扩展的统一多模态模型,它正在革新AI与复杂系统的交互方式。该模型具有对话推理、图像生成、编辑、风格转移、导航、构图、思考等功能,通过深度学习视频和网络数据进行预训练,为生成高保真度、逼真图像提供了基础。
Veo 3 是最新的视频生成模型,旨在通过更高的现实主义和音频效果,提供 4K 输出,能更准确地遵循用户的提示。这一技术代表了视频生成领域的重大进步,具有更强的创造控制能力。Veo 3 的推出是对 Veo 2 的一次重要升级,旨在帮助创作者实现他们的创意愿景。该产品适合需要高质量视频生成的创意行业,从广告到游戏开发等多个领域。无具体价格信息披露。
Blip 3o 是一个基于 Hugging Face 平台的应用程序,利用先进的生成模型从文本生成图像,或对现有图像进行分析和回答。该产品为用户提供了强大的图像生成和理解能力,非常适合设计师、艺术家和开发者。此技术的主要优点是其高效的图像生成速度和优质的生成效果,同时还支持多种输入形式,增强了用户体验。该产品是免费的,定位于开放给广大用户使用。
MNN-LLM 是一款高效的推理框架,旨在优化和加速大语言模型在移动设备和本地 PC 上的部署。它通过模型量化、混合存储和硬件特定优化,解决高内存消耗和计算成本的问题。MNN-LLM 在 CPU 基准测试中表现卓越,速度显著提升,适合需要隐私保护和高效推理的用户。
DreamO 是一种先进的图像定制模型,旨在提高图像生成的保真度和灵活性。该框架结合了 VAE 特征编码,适用于各种输入,特别是在角色身份的保留方面表现出色。支持消费级 GPU,具有 8 位量化和 CPU 卸载功能,适应不同硬件环境。该模型的不断更新使其在解决过度饱和和面部塑料感问题上取得了一定进展,旨在为用户提供更优质的图像生成体验。
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
PrimitiveAnything 是一种利用自回归变换器生成 3D 模型的技术,能够自动创建细致的 3D 原始装配体。这项技术的主要优点在于其能通过深度学习快速生成复杂的 3D 形状,从而极大地提高了设计师的工作效率。该产品适用于各类设计应用,价格为免费使用,定位于 3D 建模领域。
DeerFlow 是一个深度研究框架,旨在结合语言模型与如网页搜索、爬虫及 Python 执行等专用工具,以推动深入研究工作。该项目源于开源社区,强调贡献回馈,具备多种灵活的功能,适合各类研究需求。
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
parakeet-tdt-0.6b-v2 是一个 600 百万参数的自动语音识别(ASR)模型,旨在实现高质量的英语转录,具有准确的时间戳预测和自动标点符号、大小写支持。该模型基于 FastConformer 架构,能够高效地处理长达 24 分钟的音频片段,适合开发者、研究人员和各行业应用。
CameraBench 是一个用于分析视频中相机运动的模型,旨在通过视频理解相机的运动模式。它的主要优点在于利用生成性视觉语言模型进行相机运动的原理分类和视频文本检索。通过与传统的结构从运动 (SfM) 和实时定位与*构建 (SLAM) 方法进行比较,该模型在捕捉场景语义方面显示出了显著的优势。该模型已开源,适合研究人员和开发者使用,且后续将推出更多改进版本。
F Lite 是由 Freepik 和 Fal 开发的一个大型扩散模型,具有 100 亿个参数,专门训练于版权安全和适合工作环境 (SFW) 的内容。该模型基于 Freepik 的内部数据集,包含约 8000 万张合法合规的图像,标志着公开可用的模型在这一规模上首次专注于合法和安全的内容。它的技术报告提供了详细的模型信息,并且使用了 CreativeML Open RAIL-M 许可证进行分发。该模型的设计旨在推动人工智能的开放性和可用性。
Kimi-Audio 是一个先进的开源音频基础模型,旨在处理多种音频处理任务,如语音识别和音频对话。该模型在超过 1300 万小时的多样化音频数据和文本数据上进行了大规模预训练,具有强大的音频推理和语言理解能力。它的主要优点包括优秀的性能和灵活性,适合研究人员和开发者进行音频相关的研究与开发。
Describe Anything 模型(DAM)能够处理图像或视频的特定区域,并生成详细描述。它的主要优点在于可以通过简单的标记(点、框、涂鸦或掩码)来生成高质量的本地化描述,极大地提升了计算机视觉领域的图像理解能力。该模型由 NVIDIA 和多所大学联合开发,适合用于研究、开发和实际应用中。
Flex.2 是当前最灵活的文本到图像扩散模型,具备内置的重绘和通用控制功能。它是一个开源项目,由社区支持,旨在推动人工智能的民主化。Flex.2 具备 8 亿参数,支持 512 个令牌长度输入,并符合 OSI 的 Apache 2.0 许可证。此模型可以在许多创意项目中提供强大的支持。用户可以通过反馈不断改善模型,推动技术进步。
Nes2Net 是一个为基础模型驱动的语音反欺诈任务设计的轻量级嵌套架构,具有较低的错误率,适用于音频深度假造检测。该模型在多个数据集上表现优异,预训练模型和代码已在 GitHub 上发布,便于研究人员和开发者使用。适合音频处理和安全领域,主要定位于提高语音识别和反欺诈的效率和准确性。
该模型通过强化学习和高质量推理轨迹的掩蔽自监督微调,实现了对扩散大语言模型的推理能力的提升。此技术的重要性在于它能够优化模型的推理过程,减少计算成本,同时保证学习动态的稳定性。适合希望在写作和推理任务中提升效率的用户。
Wan2.1-FLF2V-14B 是一个开源的大规模视频生成模型,旨在推动视频生成领域的进步。该模型在多项基准测试中表现优异,支持消费者级 GPU,能够高效生成 480P 和 720P 的视频。它在文本到视频、图像到视频等多个任务中表现出色,具有强大的视觉文本生成能力,适用于各种实际应用场景。
FramePack 是一个创新的视频生成模型,旨在通过压缩输入帧的上下文来提高视频生成的质量和效率。其主要优点在于解决了视频生成中的漂移问题,通过双向采样方法保持视频质量,适合需要生成长视频的用户。该技术背景来源于对现有模型的深入研究和实验,以改进视频生成的稳定性和连贯性。
GLM-4-32B 是一个高性能的生成语言模型,旨在处理多种自然语言任务。它通过深度学习技术训练而成,能够生成连贯的文本和回答复杂问题。该模型适用于学术研究、商业应用和开发者,价格合理,定位精准,是自然语言处理领域的领先产品。
Pusa 通过帧级噪声控制引入视频扩散建模的创新方法,能够实现高质量的视频生成,适用于多种视频生成任务(文本到视频、图像到视频等)。该模型以其卓越的运动保真度和高效的训练过程,提供了一个开源的解决方案,方便用户进行视频生成任务。
UNO 是一个基于扩散变换器的多图像条件生成模型,通过引入渐进式跨模态对齐和通用旋转位置嵌入,实现高一致性的图像生成。其主要优点在于增强了对单一或多个主题生成的可控性,适用于各种创意图像生成任务。
VisualCloze 是一个通过视觉上下文学习的通用图像生成框架,旨在解决传统任务特定模型在多样化需求下的低效率问题。该框架不仅支持多种内部任务,还能泛化到未见过的任务,通过可视化示例帮助模型理解任务。这种方法利用了先进的图像填充模型的强生成先验,为图像生成提供了强有力的支持。
SkyReels-A2 是一个基于视频扩散变换器的框架,允许用户合成和生成视频内容。该模型通过利用深度学习技术,提供了灵活的创作能力,适合多种视频生成应用,尤其是在动画和特效制作方面。该产品的优点在于其开源特性和高效的模型性能,适合研究人员和开发者使用,且目前不收取费用。
MegaTTS 3 是由字节跳动开发的一款基于 PyTorch 的高效语音合成模型,具有超高质量的语音克隆能力。其轻量级架构只包含 0.45B 参数,支持中英文及代码切换,能够根据输入文本生成自然流畅的语音,广泛应用于学术研究和技术开发。
EasyControl 是一个为 Diffusion Transformer(扩散变换器)提供高效灵活控制的框架,旨在解决当前 DiT 生态系统中存在的效率瓶颈和模型适应性不足等问题。其主要优点包括:支持多种条件组合、提高生成灵活性和推理效率。该产品是基于最新研究成果开发的,适合在图像生成、风格转换等领域使用。
DreamActor-M1 是一个基于扩散变换器 (DiT) 的人类动画框架,旨在实现细粒度的整体可控性、多尺度适应性和长期时间一致性。该模型通过混合引导,能够生成高表现力和真实感的人类视频,适用于从肖像到全身动画的多种场景。其主要优势在于高保真度和身份保留,为人类行为动画带来了新的可能性。
QVQ-Max 是 Qwen 团队推出的视觉推理模型,能够理解和分析图像及视频内容,提供解决方案。它不仅限于文本输入,更能够处理复杂的视觉信息。适合需要多模态信息处理的用户,如教育、工作和生活场景。该产品是基于深度学习和计算机视觉技术开发,适用于学生、职场人士和创意工作者。此版本为首发,后续将持续优化。
BizGen 是一个先进的模型,专注于文章级别的视觉文本渲染,旨在提升信息图表的生成质量和效率。该产品利用深度学习技术,能够准确渲染多种语言的文本,提升信息的可视化效果。适合研究人员和开发者使用,助力创造更具吸引力的视觉内容。
Video-T1 是一个视频生成模型,通过测试时间缩放技术(TTS)显著提升生成视频的质量和一致性。该技术允许在推理过程中使用更多的计算资源,从而优化生成结果。相较于传统的视频生成方法,TTS 能够提供更高的生成质量和更丰富的内容表达,适用于数字创作领域。该产品的定位主要面向研究人员和开发者,价格信息未明确。
RF-DETR 是一个基于变压器的实时目标检测模型,旨在为边缘设备提供高精度和实时性能。它在 Microsoft COCO 基准测试中超过了 60 AP,具有竞争力的性能和快速的推理速度,适合各种实际应用场景。RF-DETR 旨在解决现实世界中的物体检测问题,适用于需要高效且准确检测的行业,如安防、自动驾驶和智能监控等。
混元T1 是腾讯推出的超大规模推理模型,基于强化学习技术,通过大量后训练显著提升推理能力。它在长文处理和上下文捕捉上表现突出,同时优化了计算资源的消耗,具备高效的推理能力。适用于各类推理任务,尤其在数学、逻辑推理等领域表现优异。该产品以深度学习为基础,结合实际反馈不断优化,适合科研、教育等多个领域的应用。
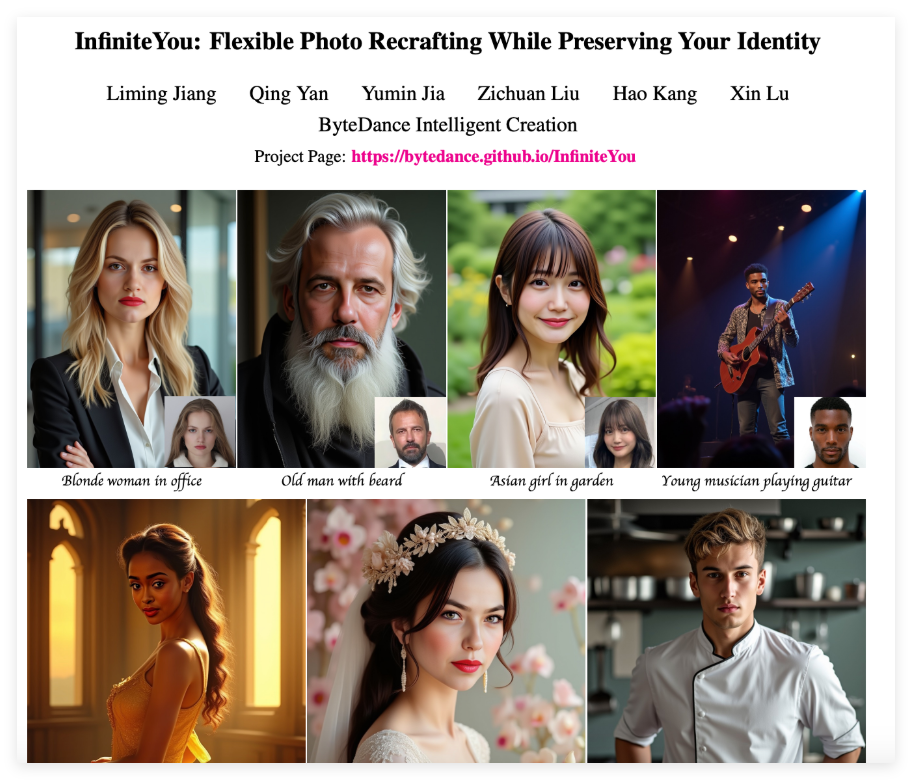
InfiniteYou(InfU)是一个基于扩散变换器的强大框架,旨在实现灵活的图像重构,并保持用户身份。它通过引入身份特征并采用多阶段训练策略,显著提升了图像生成的质量和美学,同时改善了文本与图像的对齐。该技术对提高图像生成的相似性和美观性具有重要意义,适用于各种图像生成任务。
Pruna 是一个为开发者设计的模型优化框架,通过一系列压缩算法,如量化、修剪和编译等技术,使得机器学习模型在推理时更快、体积更小且计算成本更低。产品适用于多种模型类型,包括 LLMs、视觉转换器等,且支持 Linux、MacOS 和 Windows 等多个平台。Pruna 还提供了企业版 Pruna Pro,解锁更多高级优化功能和优先支持,助力用户在实际应用中提高效率。
长上下文调优(LCT)旨在解决当前单次生成能力与现实叙事视频制作之间的差距。该技术通过数据驱动的方法直接学习场景级一致性,支持交互式多镜头开发和合成生成,适用于视频制作的各个方面。
Thera 是一种先进的超分辨率技术,能够在不同尺度下生成高质量图像。其主要优点在于内置物理观察模型,有效避免了混叠现象。该技术由 ETH Zurich 的研究团队开发,适用于图像增强和计算机视觉领域,尤其在遥感和摄影测量中具有广泛应用。
Inductive Moment Matching (IMM) 是一种先进的生成模型技术,主要用于高质量图像生成。该技术通过创新的归纳矩匹配方法,显著提高了生成图像的质量和多样性。其主要优点包括高效性、灵活性以及对复杂数据分布的强大建模能力。IMM 由 Luma AI 和斯坦福大学的研究团队开发,旨在推动生成模型领域的发展,为图像生成、数据增强和创意设计等应用提供强大的技术支持。该项目开源了代码和预训练模型,方便研究人员和开发者快速上手和应用。
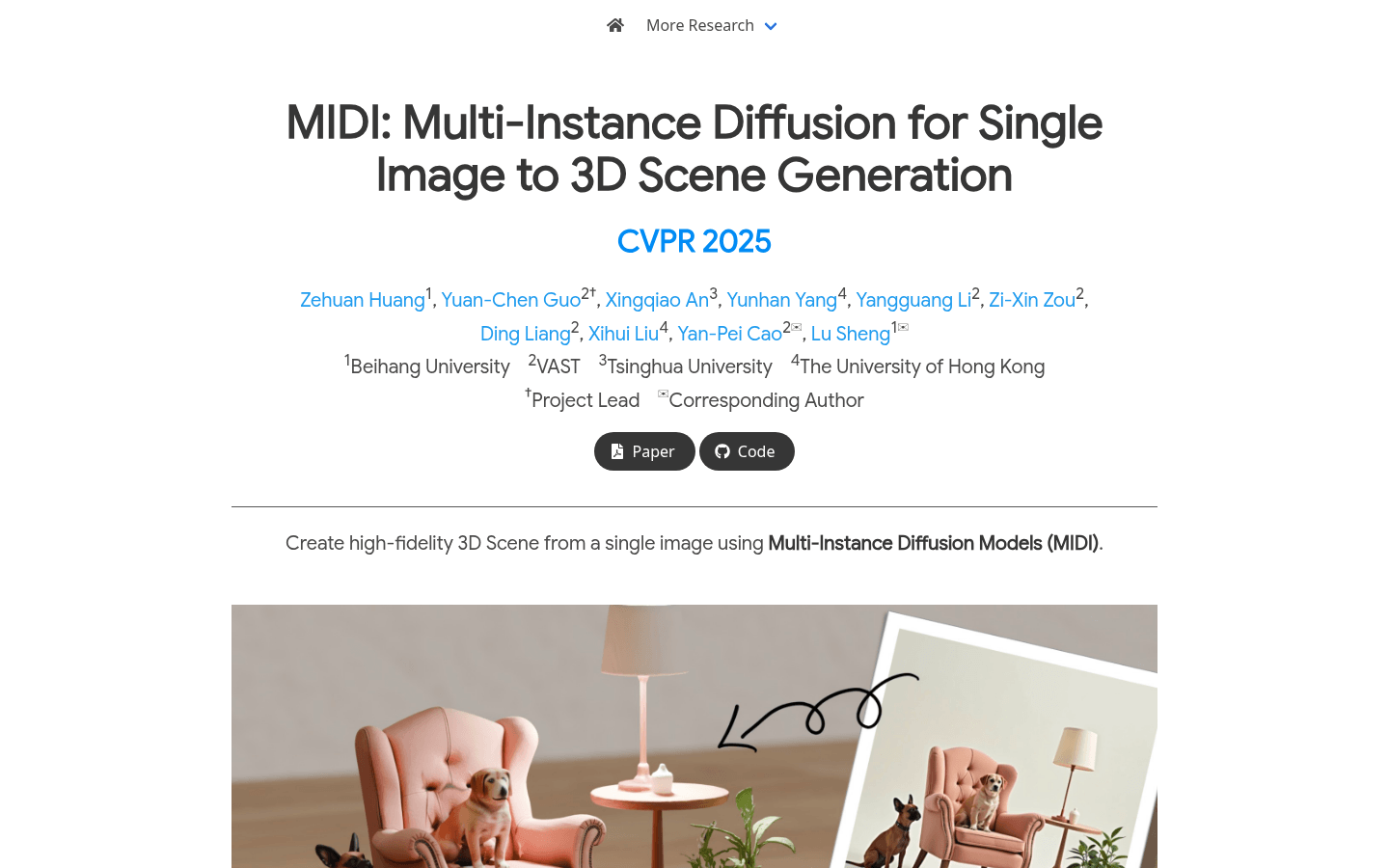
MIDI是一种创新的图像到3D场景生成技术,它利用多实例扩散模型,能够从单张图像中直接生成具有准确空间关系的多个3D实例。该技术的核心在于其多实例注意力机制,能够有效捕捉物体间的交互和空间一致性,无需复杂的多步骤处理。MIDI在图像到场景生成领域表现出色,适用于合成数据、真实场景数据以及由文本到图像扩散模型生成的风格化场景图像。其主要优点包括高效性、高保真度和强大的泛化能力。
R1-Omni 是一个创新的多模态情绪识别模型,通过强化学习提升模型的推理能力和泛化能力。该模型基于 HumanOmni-0.5B 开发,专注于情绪识别任务,能够通过视觉和音频模态信息进行情绪分析。其主要优点包括强大的推理能力、显著提升的情绪识别性能以及在分布外数据上的出色表现。该模型适用于需要多模态理解的场景,如情感分析、智能客服等领域,具有重要的研究和应用价值。
Flux 是由字节跳动开发的一个高性能通信重叠库,专为 GPU 上的张量和专家并行设计。它通过高效的内核和对 PyTorch 的兼容性,支持多种并行化策略,适用于大规模模型训练和推理。Flux 的主要优点包括高性能、易于集成和对多种 NVIDIA GPU 架构的支持。它在大规模分布式训练中表现出色,尤其是在 Mixture-of-Experts (MoE) 模型中,能够显著提高计算效率。
HunyuanVideo-I2V 是腾讯开源的图像到视频生成模型,基于 HunyuanVideo 架构开发。该模型通过图像潜在拼接技术,将参考图像信息有效整合到视频生成过程中,支持高分辨率视频生成,并提供可定制的 LoRA 效果训练功能。该技术在视频创作领域具有重要意义,能够帮助创作者快速生成高质量的视频内容,提升创作效率。
QwQ-32B 是 Qwen 系列的推理模型,专注于复杂问题的思考和推理能力。它在下游任务中表现出色,尤其是在解决难题方面。该模型基于 Qwen2.5 架构,经过预训练和强化学习优化,具有 325 亿参数,支持 131072 个完整上下文长度的处理能力。其主要优点包括强大的推理能力、高效的长文本处理能力和灵活的部署选项。该模型适用于需要深度思考和复杂推理的场景,如学术研究、编程辅助和创意写作等。
CogView4-6B 是由清华大学知识工程组开发的文本到图像生成模型。它基于深度学习技术,能够根据用户输入的文本描述生成高质量的图像。该模型在多个基准测试中表现优异,尤其是在中文文本生成图像方面具有显著优势。其主要优点包括高分辨率图像生成、支持多种语言输入以及高效的推理速度。该模型适用于创意设计、图像生成等领域,能够帮助用户快速将文字描述转化为视觉内容。
UniTok是一种创新的视觉分词技术,旨在弥合视觉生成和理解之间的差距。它通过多码本量化技术,显著提升了离散分词器的表示能力,使其能够捕捉到更丰富的视觉细节和语义信息。这一技术突破了传统分词器在训练过程中的瓶颈,为视觉生成和理解任务提供了一种高效且统一的解决方案。UniTok在图像生成和理解任务中表现出色,例如在ImageNet上实现了显著的零样本准确率提升。该技术的主要优点包括高效性、灵活性以及对多模态任务的强大支持,为视觉生成和理解领域带来了新的可能性。
PhotoDoodle 是一个专注于艺术图像编辑的深度学习模型,通过少量样本对数据进行训练,能够快速实现图像的艺术化编辑。该技术的核心优势在于其高效的少样本学习能力,能够在仅有少量图像对的情况下学习到复杂的艺术效果,从而为用户提供强大的图像编辑功能。该模型基于深度学习框架开发,具有较高的灵活性和可扩展性,可以应用于多种图像编辑场景,如艺术风格转换、特效添加等。其背景信息显示,该模型由新加坡国立大学 Show Lab 团队开发,旨在推动艺术图像编辑技术的发展。目前,该模型通过开源方式提供给用户,用户可以根据自身需求进行使用和二次开发。
DeepSeek Profile Data 是一个专注于深度学习框架性能分析的项目。它通过 PyTorch Profiler 捕获训练和推理框架的性能数据,帮助研究人员和开发者更好地理解计算与通信重叠策略以及底层实现细节。这些数据对于优化大规模分布式训练和推理任务至关重要,能够显著提升系统的效率和性能。该项目是 DeepSeek 团队在深度学习基础设施领域的重要贡献,旨在推动社区对高效计算策略的探索。
Expert Parallelism Load Balancer (EPLB)是一种用于深度学习中专家并行(EP)的负载均衡算法。它通过冗余专家策略和启发式打包算法,确保不同GPU之间的负载平衡,同时利用组限制专家路由减少节点间数据流量。该算法对于大规模分布式训练具有重要意义,能够提高资源利用率和训练效率。
DualPipe是一种创新的双向流水线并行算法,由DeepSeek-AI团队开发。该算法通过优化计算与通信的重叠,显著减少了流水线气泡,提高了训练效率。它在大规模分布式训练中表现出色,尤其适用于需要高效并行化的深度学习任务。DualPipe基于PyTorch开发,易于集成和扩展,适合需要高性能计算的开发者和研究人员使用。
DeepGEMM是一个专注于高效FP8矩阵乘法的CUDA库。它通过细粒度缩放和多种优化技术,如Hopper TMA特性、持久化线程专业化、全JIT设计等,显著提升了矩阵运算的性能。该库主要面向深度学习和高性能计算领域,适用于需要高效矩阵运算的场景。它支持NVIDIA Hopper架构的Tensor Core,并且在多种矩阵形状下展现出卓越的性能。DeepGEMM的设计简洁,核心代码仅约300行,易于学习和使用,同时性能与专家优化的库相当或更好。开源免费的特性使其成为研究人员和开发者进行深度学习优化和开发的理想选择。
DeepEP 是一个专为混合专家模型(MoE)和专家并行(EP)设计的通信库。它提供了高吞吐量和低延迟的全连接 GPU 内核,支持低精度操作(如 FP8)。该库针对非对称域带宽转发进行了优化,适合训练和推理预填充任务。此外,它还支持流处理器(SM)数量控制,并引入了一种基于钩子的通信-计算重叠方法,不占用任何 SM 资源。DeepEP 的实现虽然与 DeepSeek-V3 论文略有差异,但其优化的内核和低延迟设计使其在大规模分布式训练和推理任务中表现出色。
FlexHeadFA 是一个基于 FlashAttention 的改进模型,专注于提供快速且内存高效的精确注意力机制。它支持灵活的头维度配置,能够显著提升大语言模型的性能和效率。该模型的主要优点包括高效利用 GPU 资源、支持多种头维度配置以及与 FlashAttention-2 和 FlashAttention-3 兼容。它适用于需要高效计算和内存优化的深度学习场景,尤其在处理长序列数据时表现出色。
FlashMLA 是一个针对 Hopper GPU 优化的高效 MLA 解码内核,专为变长序列服务设计。它基于 CUDA 12.3 及以上版本开发,支持 PyTorch 2.0 及以上版本。FlashMLA 的主要优势在于其高效的内存访问和计算性能,能够在 H800 SXM5 上实现高达 3000 GB/s 的内存带宽和 580 TFLOPS 的计算性能。该技术对于需要大规模并行计算和高效内存管理的深度学习任务具有重要意义,尤其是在自然语言处理和计算机视觉领域。FlashMLA 的开发灵感来源于 FlashAttention 2&3 和 cutlass 项目,旨在为研究人员和开发者提供一个高效的计算工具。
QwQ-Max-Preview 是 Qwen 系列的最新成果,基于 Qwen2.5-Max 构建。它在数学、编程以及通用任务中展现了更强的能力,同时在与 Agent 相关的工作流中也有不错的表现。作为即将发布的 QwQ-Max 的预览版,这个版本还在持续优化中。其主要优点包括深度推理、数学、编程和 Agent 任务的强大能力。未来计划以 Apache 2.0 许可协议开源发布 QwQ-Max 以及 Qwen2.5-Max,旨在推动跨领域应用的创新。
Claude 3.7 Sonnet 是 Anthropic 推出的最新混合推理模型,能够实现快速响应和深度推理的无缝切换。它在编程、前端开发等领域表现出色,并通过 API 提供对推理深度的精细控制。该模型不仅提升了代码生成和调试能力,还优化了对复杂任务的处理,适用于企业级应用。其定价与前代产品一致,输入每百万 token 收费 3 美元,输出每百万 token 收费 15 美元。
VLM-R1 是一种基于强化学习的视觉语言模型,专注于视觉理解任务,如指代表达理解(Referring Expression Comprehension, REC)。该模型通过结合 R1(Reinforcement Learning)和 SFT(Supervised Fine-Tuning)方法,展示了在领域内和领域外数据上的出色性能。VLM-R1 的主要优点包括其稳定性和泛化能力,使其能够在多种视觉语言任务中表现出色。该模型基于 Qwen2.5-VL 构建,利用了先进的深度学习技术,如闪存注意力机制(Flash Attention 2),以提高计算效率。VLM-R1 旨在为视觉语言任务提供一种高效且可靠的解决方案,适用于需要精确视觉理解的应用场景。
BioEmu 是微软开发的一种深度学习模型,用于模拟蛋白质的平衡系综。该技术通过生成式深度学习方法,能够高效地生成蛋白质的结构样本,帮助研究人员更好地理解蛋白质的动态行为和结构多样性。该模型的主要优点在于其可扩展性和高效性,能够处理复杂的生物分子系统。它适用于生物化学、结构生物学和药物设计等领域的研究,为科学家提供了一种强大的工具来探索蛋白质的动态特性。
FlashVideo 是一款专注于高效高分辨率视频生成的深度学习模型。它通过分阶段的生成策略,首先生成低分辨率视频,再通过增强模型提升至高分辨率,从而在保证细节的同时显著降低计算成本。该技术在视频生成领域具有重要意义,尤其是在需要高质量视觉内容的场景中。FlashVideo 适用于多种应用场景,包括内容创作、广告制作和视频编辑等。其开源性质使得研究人员和开发者可以灵活地进行定制和扩展。
DeepSeek 模型兼容性检测是一个用于评估设备是否能够运行不同规模 DeepSeek 模型的工具。它通过检测设备的系统内存、显存等配置,结合模型的参数量、精度位数等信息,为用户提供模型运行的预测结果。该工具对于开发者和研究人员在选择合适的硬件资源以部署 DeepSeek 模型时具有重要意义,能够帮助他们提前了解设备的兼容性,避免因硬件不足而导致的运行问题。DeepSeek 模型本身是一种先进的深度学习模型,广泛应用于自然语言处理等领域,具有高效、准确的特点。通过该检测工具,用户可以更好地利用 DeepSeek 模型进行项目开发和研究。
Huginn-0125是一个由马里兰大学帕克分校Tom Goldstein实验室开发的潜变量循环深度模型。该模型拥有35亿参数,经过8000亿个token的训练,在推理和代码生成方面表现出色。其核心特点是通过循环深度结构在测试时动态调整计算量,能够根据任务需求灵活增加或减少计算步骤,从而在保持性能的同时优化资源利用。该模型基于开源的Hugging Face平台发布,支持社区共享和协作,用户可以自由下载、使用和进一步开发。其开源性和灵活的架构使其成为研究和开发中的重要工具,尤其是在资源受限或需要高性能推理的场景中。
该产品是一个用于大规模深度循环语言模型的预训练代码库,基于Python开发。它在AMD GPU架构上进行了优化,能够在4096个AMD GPU上高效运行。该技术的核心优势在于其深度循环架构,能够有效提升模型的推理能力和效率。它主要用于研究和开发高性能的自然语言处理模型,特别是在需要大规模计算资源的场景中。该代码库开源且基于Apache-2.0许可证,适合学术研究和工业应用。
InspireMusic 是一个专注于音乐、歌曲和音频生成的 AIGC 工具包和模型框架,采用 PyTorch 开发。它通过音频标记化和解码过程,结合自回归 Transformer 和条件流匹配模型,实现高质量音乐生成。该工具包支持文本提示、音乐风格、结构等多种条件控制,能够生成 24kHz 和 48kHz 的高质量音频,并支持长音频生成。此外,它还提供了方便的微调和推理脚本,方便用户根据需求调整模型。InspireMusic 的开源旨在赋能普通用户通过音乐创作提升研究中的音效表现。
Lumina-Video 是 Alpha-VLLM 团队开发的一个视频生成模型,主要用于从文本生成高质量的视频内容。该模型基于深度学习技术,能够根据用户输入的文本提示生成对应的视频,具有高效性和灵活性。它在视频生成领域具有重要意义,为内容创作者提供了强大的工具,能够快速生成视频素材。目前该项目已开源,支持多种分辨率和帧率的视频生成,并提供了详细的安装和使用指南。
Brain2Qwerty 是一种创新的非侵入式脑机接口技术,旨在通过解码大脑活动来实现文本输入。该技术利用深度学习架构,结合脑电图(EEG)或脑磁图(MEG)信号,能够将大脑活动转化为文本输出。这种技术的重要性在于为失去语言能力或运动能力的患者提供了一种安全、有效的沟通方式,同时缩小了侵入式和非侵入式脑机接口之间的差距。目前该技术仍处于研究阶段,但其潜在应用前景广阔,未来有望在医疗、康复等领域发挥重要作用。
VisoMaster是一款专注于视频替换和编辑的桌面客户端软件。它利用先进的AI技术,能够在图像和视频中实现高质量的替换,效果自然逼真。该软件操作简单,支持多种输入输出格式,并通过GPU加速提高处理效率。VisoMaster的主要优点是易于使用、高效处理以及高度定制化,适合视频创作者、影视后期制作人员以及对视频编辑有需求的普通用户。软件目前免费提供给用户,旨在帮助用户快速生成高质量的视频内容。
MNN 是阿里巴巴淘系技术开源的深度学习推理引擎,支持 TensorFlow、Caffe、ONNX 等主流模型格式,兼容 CNN、RNN、GAN 等常用网络。它通过极致优化算子性能,全面支持 CPU、GPU、NPU,充分发挥设备算力,广泛应用于阿里巴巴 70+ 场景下的 AI 应用。MNN 以高性能、易用性和通用性著称,旨在降低 AI 部署门槛,推动端智能的发展。
LLaSA_training 是一个基于 LLaMA 的语音合成训练项目,旨在通过优化训练时间和推理时间的计算资源,提升语音合成模型的效率和性能。该项目利用开源数据集和内部数据集进行训练,支持多种配置和训练方式,具有较高的灵活性和可扩展性。其主要优点包括高效的数据处理能力、强大的语音合成效果以及对多种语言的支持。该项目适用于需要高性能语音合成解决方案的研究人员和开发者,可用于开发智能语音助手、语音播报系统等应用场景。
VideoJAM 是一种创新的视频生成框架,旨在通过联合外观 - 运动表示来提升视频生成模型的运动连贯性和视觉质量。该技术通过引入内指导机制(Inner-Guidance),利用模型自身预测的运动信号动态引导视频生成,从而在生成复杂运动类型时表现出色。VideoJAM 的主要优点是能够显著提高视频生成的连贯性,同时保持高质量的视觉效果,且无需对训练数据或模型架构进行大规模修改,即可应用于任何视频生成模型。该技术在视频生成领域具有重要的应用前景,尤其是在需要高度运动连贯性的场景中。
BEN2(Background Erase Network)是一个创新的图像分割模型,采用了Confidence Guided Matting(CGM)流程。它通过一个细化网络专门处理模型置信度较低的像素,从而实现更精确的抠图效果。BEN2在头发抠图、4K图像处理、目标分割和边缘细化方面表现出色。其基础模型是开源的,用户可以通过API或Web演示免费试用完整模型。该模型训练数据包括DIS5k数据集和22K专有分割数据集,能够满足多种图像处理需求。
DeepResearch123是一个AI研究资源导航平台,旨在为研究人员、开发者和爱好者提供丰富的AI研究资源、文档和实践案例。该平台涵盖了机器学习、深度学习和人工智能等多个领域的最新研究成果,帮助用户快速了解和掌握相关知识。其主要优点是资源丰富、分类清晰,便于用户查找和学习。该平台面向对AI研究感兴趣的各类人群,无论是初学者还是专业人士都能从中受益。目前平台免费开放,用户无需付费即可使用所有功能。
node-DeepResearch 是一个基于 Jina AI 技术的深度研究模型,专注于通过持续搜索和阅读网页来寻找问题的答案。它利用 Gemini 提供的 LLM 能力和 Jina Reader 的网页搜索功能,能够处理复杂的查询任务,并通过多步骤的推理和信息整合来生成答案。该模型的主要优点在于其强大的信息检索能力和推理能力,能够处理复杂的、需要多步骤解答的问题。它适用于需要深入研究和信息挖掘的场景,如学术研究、市场分析等。目前该模型是开源的,用户可以通过 GitHub 获取代码并自行部署使用。
MatAnyone 是一种先进的视频抠像技术,专注于通过一致的记忆传播实现稳定的视频抠像。它通过区域自适应记忆融合模块,结合目标指定的分割图,能够在复杂背景中保持语义稳定性和细节完整性。该技术的重要性在于它能够为视频编辑、特效制作和内容创作提供高质量的抠像解决方案,尤其适用于需要精确抠像的场景。MatAnyone 的主要优点是其在核心区域的语义稳定性和边界细节的精细处理能力。它由南洋理工大学和商汤科技的研究团队开发,旨在解决传统抠像方法在复杂背景下的不足。
huggingface/open-r1 是一个开源项目,致力于复现 DeepSeek-R1 模型。该项目提供了一系列脚本和工具,用于训练、评估和生成合成数据,支持多种训练方法和硬件配置。其主要优点是完全开放,允许开发者自由使用和改进,对于希望在深度学习和自然语言处理领域进行研究和开发的用户来说,是一个非常有价值的资源。该项目目前没有明确的定价,适合学术研究和商业用途。
Video Depth Anything 是一个基于深度学习的视频深度估计模型,能够为超长视频提供高质量、时间一致的深度估计。该技术基于 Depth Anything V2 开发,具有强大的泛化能力和稳定性。其主要优点包括对任意长度视频的深度估计能力、时间一致性以及对开放世界视频的良好适应性。该模型由字节跳动的研究团队开发,旨在解决长视频深度估计中的挑战,如时间一致性问题和复杂场景的适应性问题。目前,该模型的代码和演示已公开,供研究人员和开发者使用。
Janus-Pro-7B 是一个强大的多模态模型,能够同时处理文本和图像数据。它通过分离视觉编码路径,解决了传统模型在理解和生成任务中的冲突,提高了模型的灵活性和性能。该模型基于 DeepSeek-LLM 架构,使用 SigLIP-L 作为视觉编码器,支持 384x384 的图像输入,并在多模态任务中表现出色。其主要优点包括高效性、灵活性和强大的多模态处理能力。该模型适用于需要多模态交互的场景,例如图像生成和文本理解。
Janus-Pro-1B 是一个创新的多模态模型,专注于统一多模态理解和生成。它通过分离视觉编码路径,解决了传统方法在理解和生成任务中的冲突问题,同时保持了单个统一的 Transformer 架构。这种设计不仅提高了模型的灵活性,还使其在多模态任务中表现出色,甚至超越了特定任务的模型。该模型基于 DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base 构建,使用 SigLIP-L 作为视觉编码器,支持 384x384 的图像输入,并采用特定的图像生成 tokenizer。其开源性和灵活性使其成为下一代多模态模型的有力候选。
YuE是一个开创性的开源基础模型系列,专为音乐生成设计,能够将歌词转化为完整的歌曲。它能够生成包含吸引人的主唱和配套伴奏的完整歌曲,支持多种音乐风格。该模型基于深度学习技术,具有强大的生成能力和灵活性,能够为音乐创作者提供强大的工具支持。其开源特性也使得研究人员和开发者可以在此基础上进行进一步的研究和开发。
Tarsier 是由字节跳动研究团队开发的一系列大规模视频语言模型,旨在生成高质量的视频描述,并具备强大的视频理解能力。该模型通过两阶段训练策略(多任务预训练和多粒度指令微调)显著提升了视频描述的精度和细节。其主要优点包括高精度的视频描述能力、对复杂视频内容的理解能力以及在多个视频理解基准测试中取得的 SOTA(State-of-the-Art)结果。Tarsier 的背景基于对现有视频语言模型在描述细节和准确性上的不足进行改进,通过大规模高质量数据训练和创新的训练方法,使其在视频描述领域达到了新的高度。该模型目前未明确定价,主要面向学术研究和商业应用,适合需要高质量视频内容理解和生成的场景。
Flux-Midjourney-Mix2-LoRA 是一款基于深度学习的文本到图像生成模型,旨在通过自然语言描述生成高质量的图像。该模型基于Diffusion架构,结合了LoRA技术,能够实现高效的微调和风格化图像生成。其主要优点包括高分辨率输出、多样化的风格支持以及对复杂场景的出色表现能力。该模型适用于需要高质量图像生成的用户,如设计师、艺术家和内容创作者,能够帮助他们快速实现创意构思。
leapfusion-hunyuan-image2video 是一种基于 Hunyuan 模型的图像到视频生成技术。它通过先进的深度学习算法,将静态图像转换为动态视频,为内容创作者提供了一种全新的创作方式。该技术的主要优点包括高效的内容生成、灵活的定制化能力以及对高质量视频输出的支持。它适用于需要快速生成视频内容的场景,如广告制作、视频特效等领域。该模型目前以开源形式发布,供开发者和研究人员免费使用,未来有望通过社区贡献进一步提升其性能。
VideoLLaMA3是由DAMO-NLP-SG团队开发的前沿多模态基础模型,专注于图像和视频理解。该模型基于Qwen2.5架构,结合了先进的视觉编码器(如SigLip)和强大的语言生成能力,能够处理复杂的视觉和语言任务。其主要优点包括高效的时空建模能力、强大的多模态融合能力以及对大规模数据的优化训练。该模型适用于需要深度视频理解的应用场景,如视频内容分析、视觉问答等,具有广泛的研究和商业应用潜力。
Mo是一个专注于 AI 技术学习和应用的平台,旨在为用户提供从基础到高级的系统学习资源,帮助各类学习者掌握 AI 技能,并将其应用于实际项目中。无论你是大学生、职场新人,还是想提升自己技能的行业专家,Mo都能为你提供量身定制的课程、实战项目和工具,带你深入理解和应用人工智能。
Flex.1-alpha 是一个强大的文本到图像生成模型,基于80亿参数的修正流变换器架构。它继承了FLUX.1-schnell的特性,并通过训练指导嵌入器,使其无需CFG即可生成图像。该模型支持微调,并且具有开放源代码许可(Apache 2.0),适合在多种推理引擎中使用,如Diffusers和ComfyUI。其主要优点包括高效生成高质量图像、灵活的微调能力和开源社区支持。开发背景是为了解决图像生成模型的压缩和优化问题,并通过持续训练提升模型性能。
Frames 是 Runway 的核心产品之一,专注于图像生成领域。它通过深度学习技术,为用户提供高度风格化的图像生成能力。该模型允许用户定义独特的艺术视角,生成具有高度视觉保真度的图像。其主要优点包括强大的风格控制能力、高质量的图像输出以及灵活的创作空间。Frames 面向创意专业人士、艺术家和设计师,旨在帮助他们快速实现创意构思,提升创作效率。Runway 提供了多种使用场景和工具支持,用户可以根据需求选择不同的功能模块。价格方面,Runway 提供了付费和免费试用的选项,以满足不同用户的需求。
OmniThink 是一种创新的机器写作框架,旨在通过模拟人类的迭代扩展和反思过程,提升生成文章的知识密度。它通过知识密度指标衡量内容的独特性和深度,并通过信息树和概念池的结构化方式组织知识,从而生成高质量的长文本。该技术的核心优势在于能够有效减少冗余信息,提升内容的深度和新颖性,适用于需要高质量长文本生成的场景。
Seaweed-APT是一种用于视频生成的模型,通过对抗性后训练技术,实现了大规模文本到视频的单步生成。该模型能够在短时间内生成高质量的视频,具有重要的技术意义和应用价值。其主要优点是速度快、生成效果好,适用于需要快速生成视频的场景。目前尚未明确具体的价格和市场定位。
MangaNinja 是一种参考引导的线稿上色方法,它通过独特的设计确保精确的人物细节转录,包括用于促进参考彩色图像和目标线稿之间对应学习的块洗牌模块,以及用于实现细粒度颜色匹配的点驱动控制方案。该模型在自收集的基准测试中表现出色,超越了当前解决方案的精确上色能力。此外,其交互式点控制在处理复杂情况(如极端姿势和阴影)、跨角色上色、多参考协调等方面展现出巨大潜力,这些是现有算法难以实现的。MangaNinja 由来自香港大学、香港科技大学、通义实验室和蚂蚁集团的研究人员共同开发,相关论文已发表在 arXiv 上,代码也已开源。
InternLM3-8B-Instruct是InternLM团队开发的大型语言模型,具有卓越的推理能力和知识密集型任务处理能力。该模型在仅使用4万亿高质量词元进行训练的情况下,实现了比同级别模型低75%以上的训练成本,同时在多个基准测试中超越了Llama3.1-8B和Qwen2.5-7B等模型。它支持深度思考模式,能够通过长思维链解决复杂的推理任务,同时也具备流畅的用户交互能力。该模型基于Apache-2.0许可证开源,适用于需要高效推理和知识处理的各种应用场景。
MiniMax-01是一个具有4560亿总参数的强大语言模型,其中每个token激活459亿参数。它采用混合架构,结合了闪电注意力、softmax注意力和专家混合(MoE),通过先进的并行策略和创新的计算-通信重叠方法,如线性注意力序列并行主义加(LASP+)、varlen环形注意力、专家张量并行(ETP)等,将训练上下文长度扩展到100万tokens,在推理时可处理长达400万tokens的上下文。在多个学术基准测试中,MiniMax-01展现了顶级模型的性能。
rStar-Math是一项研究,旨在证明小型语言模型(SLMs)能够在不依赖于更高级模型的情况下,与OpenAI的o1模型相媲美甚至超越其数学推理能力。该研究通过蒙特卡洛树搜索(MCTS)实现“深度思考”,其中数学策略SLM在基于SLM的流程奖励模型的指导下进行测试时搜索。rStar-Math引入了三种创新方法来应对训练两个SLM的挑战,通过4轮自我演化和数百万个合成解决方案,将SLMs的数学推理能力提升到最先进水平。该模型在MATH基准测试中显著提高了性能,并在AIME竞赛中表现优异。
TimesFM是一个由Google Research开发的预训练时间序列预测模型,用于时间序列预测任务。该模型在多个数据集上进行了预训练,能够处理不同频率和长度的时间序列数据。其主要优点包括高性能、可扩展性强以及易于使用。该模型适用于需要准确预测时间序列数据的各种应用场景,如金融、气象、能源等领域。该模型在Hugging Face平台上免费提供,用户可以方便地下载和使用。
STAR是一种创新的视频超分辨率技术,通过将文本到视频扩散模型与视频超分辨率相结合,解决了传统GAN方法中存在的过度平滑问题。该技术不仅能够恢复视频的细节,还能保持视频的时空一致性,适用于各种真实世界的视频场景。STAR由南京大学、字节跳动等机构联合开发,具有较高的学术价值和应用前景。
TryOffAnyone是一个用于从穿着人身上生成平铺布料的深度学习模型。该模型能够将穿着衣物的人的图片转换成布料平铺图,这对于服装设计、虚拟试衣等领域具有重要意义。它通过深度学习技术,实现了高度逼真的布料模拟,使得用户可以更直观地预览衣物的穿着效果。该模型的主要优点包括逼真的布料模拟效果和较高的自动化程度,可以减少实际试衣过程中的时间和成本。



![FLUX.1 Krea [dev]](https://pic.chinaz.com/ai/2025/08/01/25080110475283667344.jpg)