共找到 44 个AI工具
点击任意工具查看详细信息
Suno V5音乐生成器是一个基于Suno V5模型功能构建的独立音乐生成器,并非官方产品。它提供强大的音乐生成能力,具有录音棚级人声生成、多乐器支持、局部音轨编辑等突破性功能。其主要优点包括极速生成高质量成品、风格模板与歌词联动、可控结构等。产品支持免费额度与按次付费,新用户有免费试用积分,还可通过每日签到等方式获取额外积分,适合初创公司、创作者和音乐技术创新者等用于音乐创作。
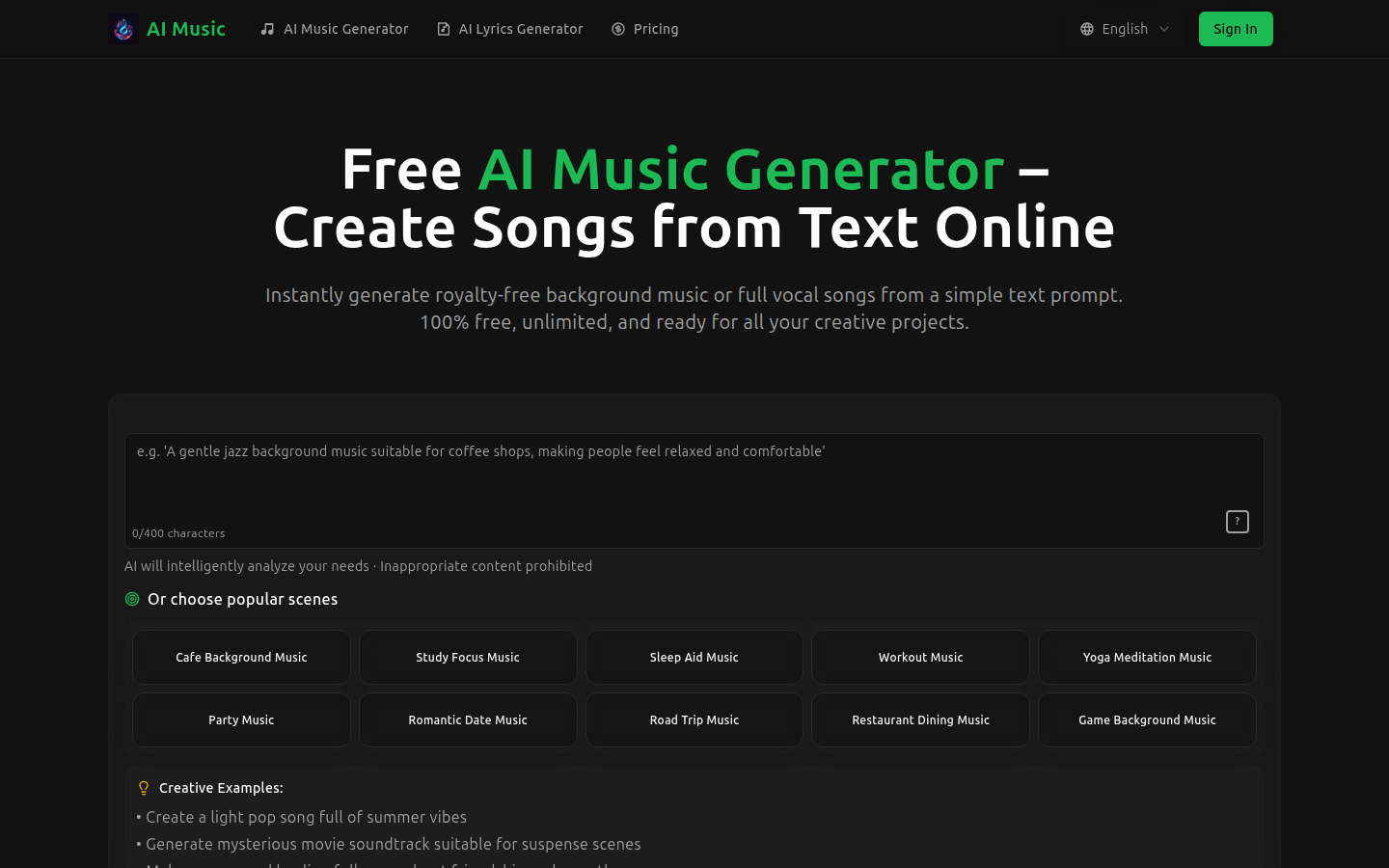
AI音乐生成器是一个强大的工具,利用文本提示创建独特高质量的音乐。它可生成背景音乐、带有歌词的完整歌曲,是各种创意项目的理想选择。产品免费、无限制,并提供丰富的音乐风格和情绪选择。
Musicful是一款在线AI音乐生成器,用户可以通过输入文本即可创作出独特的歌曲、节拍、DJ音效等,无需音乐经验。产品价格分为基础、标准和专业套餐,适用于个人创作者、视频制作人、游戏开发者等。
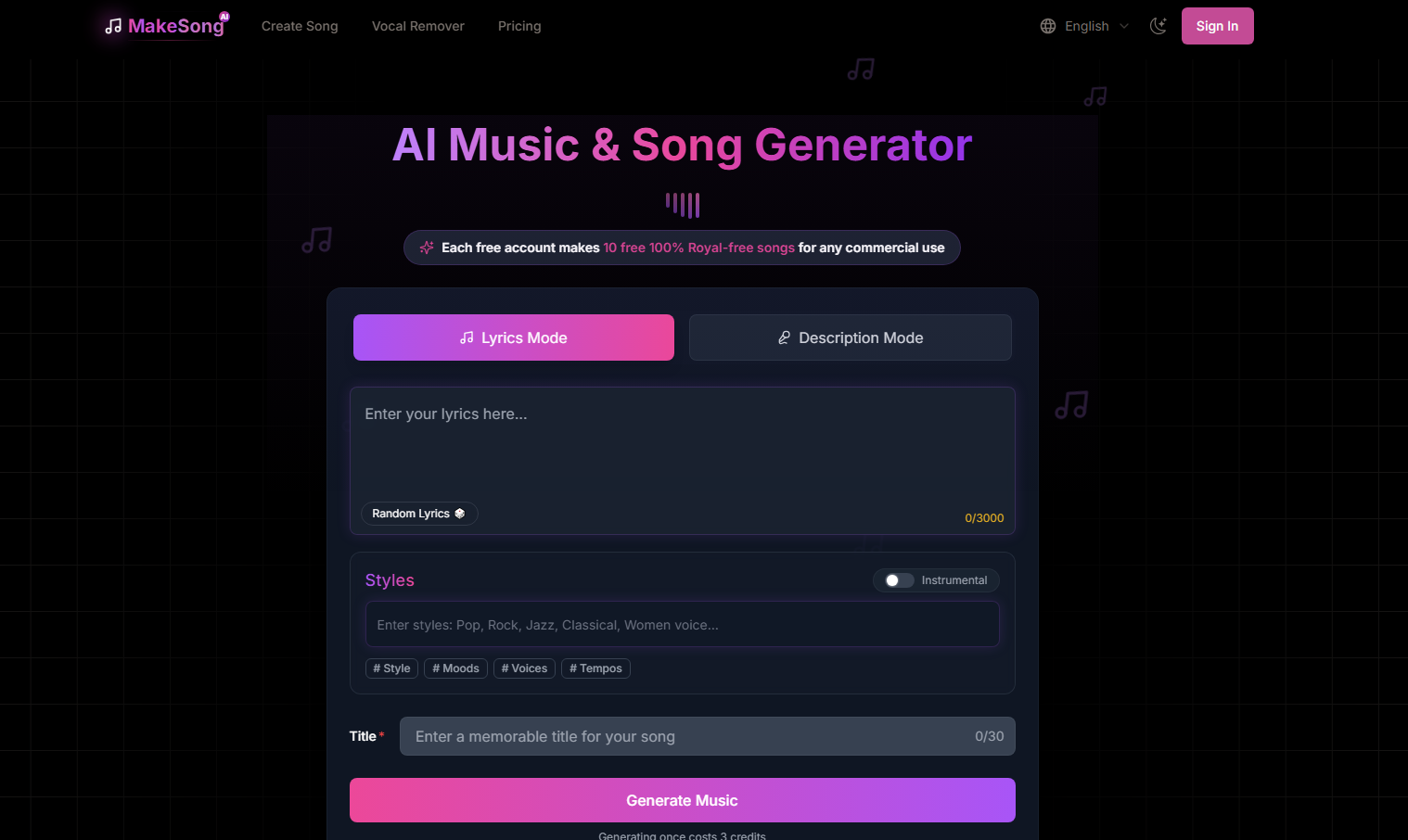
MakeSong 是一款创新的 AI 歌曲生成器,能够根据用户提供的文本或歌词快速生成高质量的音乐。它为音乐创作者提供了无限的可能性,无论是制作个人作品、商业广告,还是为社交媒体内容生成背景音乐,都可以轻松实现。该产品支持多种音乐风格,并提供不同的价格套餐,适合不同需求的用户。
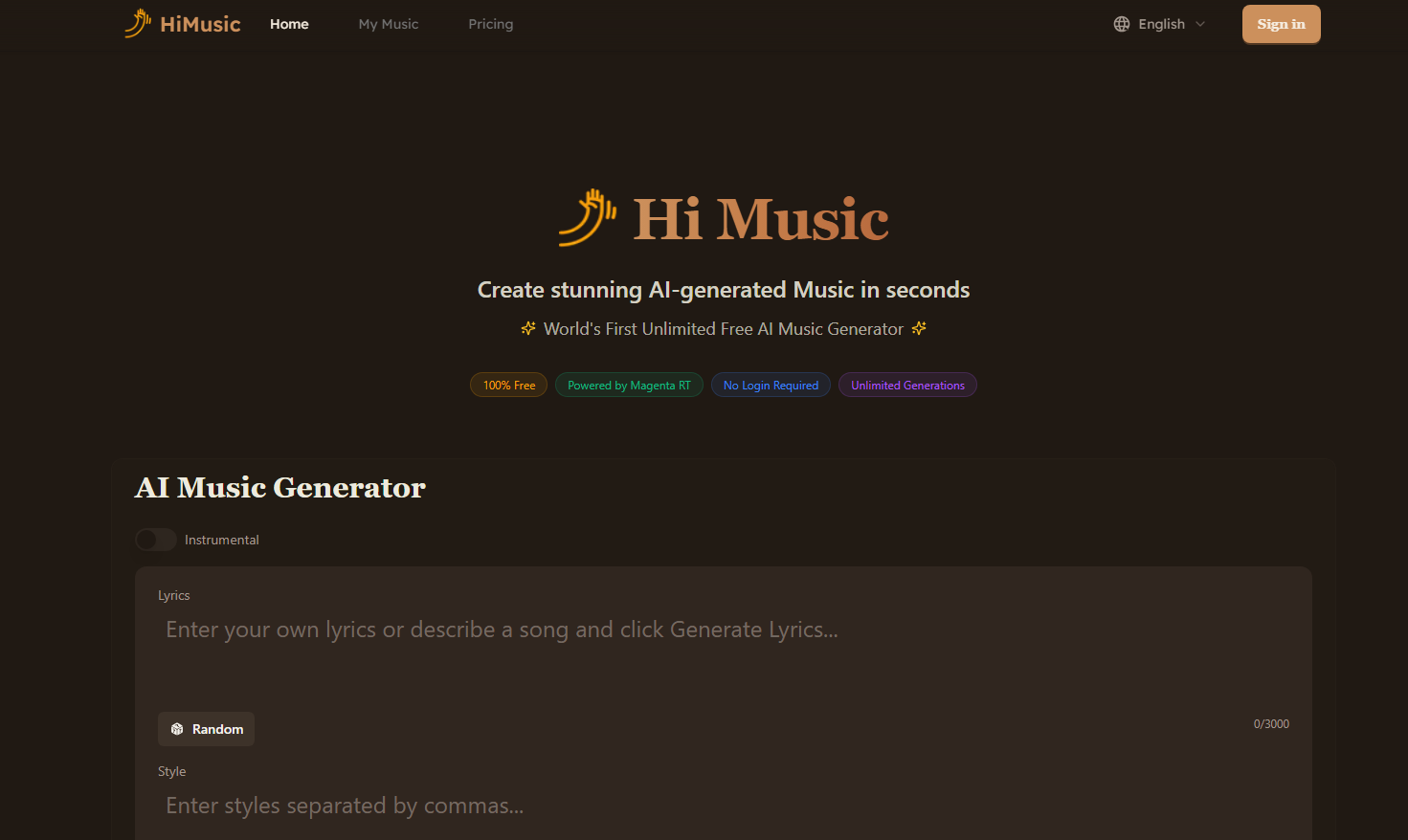
HiMusic是世界上第一个无限免费AI音乐生成器,采用Magenta RT技术。用户可以生成器无限量的音乐,无需登录,支持乐器、歌词等参数的随机生成。价格定位免费,旨在让音乐创作更便捷。
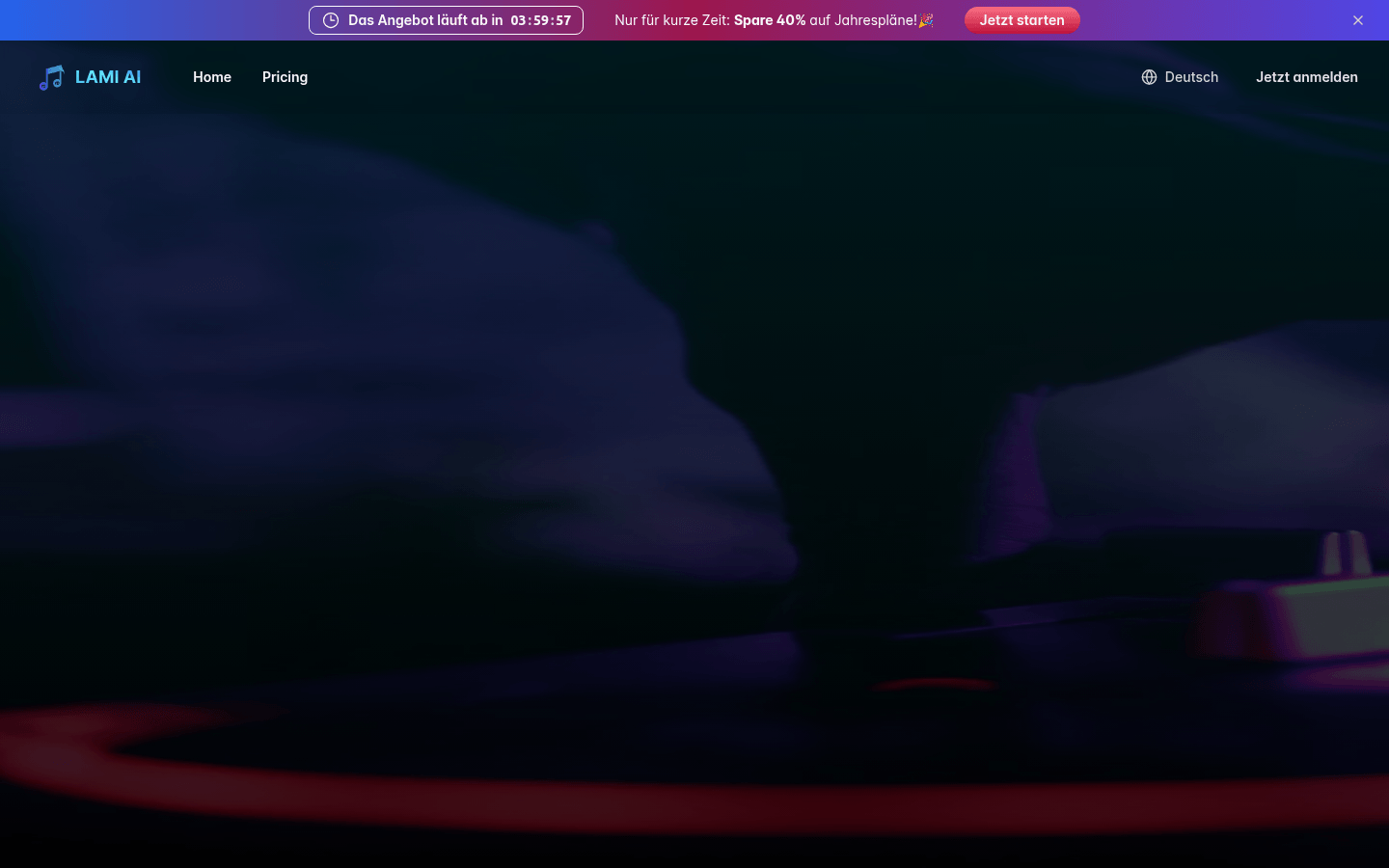
Lami AI音乐生成器是一款先进的AI工具,能将文字快速转化为原创音乐,支持商用。提供AI人声消除、音轨分离等功能,降低音乐创作门槛。
LyricsToSongAI.com是领先的AI音乐生成器和AI歌曲生成器,能够从文本或歌词创建专业质量的歌曲。该产品背景信息包括拥有10K全球用户、98%满意度率、服务于150个国家。
AI说唱生成器是一款利用AI技术从文本创作说唱音乐的工具,能够快速生成独特的说唱音乐作品。其优势在于快速创作、帮助解决创作障碍、提供免费音乐等。
Lyria 2 是最新的音乐生成模型,能够创作多种风格的高保真音乐,适用于复杂的音乐作品。该模型不仅为音乐创作者提供了强大的工具,还推动了音乐生成技术的发展,提升了创作效率。Lyria 2 的目标是让音乐创作变得更加简单和可及,为专业音乐人和爱好者提供灵活的创作支持。
Mureka 是一个 AI 音乐生成平台,旨在帮助用户将文本或提示转化为高质量的音乐作品。该产品通过智能算法处理用户的歌词和音乐风格选择,生成具有专业品质的歌曲,非常适合音乐创作者和爱好者。Mureka 提供无限次创作,并保证所生成的音乐免版税,适合任何商业用途。
AbletonMCP 是一款将 Ableton Live 与 Claude AI 连接的插件,利用模型上下文协议(MCP),能够实现音乐制作、音轨创建及实时会话操控。此工具不仅简化了音乐创作过程,还提高了工作效率,特别适合音乐制作人和创作者,帮助他们通过 AI 技术来激发灵感和快速实现创意。该插件的价格信息未提供,但用户可以在 GitHub 上免费下载和使用。
NotaGen 是一款创新的符号音乐生成模型,通过预训练、微调和强化学习三个阶段提升音乐生成质量。它利用大语言模型技术,能够生成高质量的古典乐谱,为音乐创作带来新的可能性。该模型的主要优点包括高效生成、风格多样和高质量输出。它适用于音乐创作、教育和研究等领域,具有广泛的应用前景。
DiffRhythm 是一种创新的音乐生成模型,利用潜在扩散技术实现了快速且高质量的全曲生成。该技术突破了传统音乐生成方法的限制,无需复杂的多阶段架构和繁琐的数据准备,仅需歌词和风格提示即可在短时间内生成长达 4 分 45 秒的完整歌曲。其非自回归结构确保了快速的推理速度,极大地提升了音乐创作的效率和可扩展性。该模型由西北工业大学音频、语音和语言处理小组(ASLP@NPU)和香港中文大学(深圳)大数据研究院共同开发,旨在为音乐创作提供一种简单、高效且富有创造力的解决方案。
CLaMP 3 是一种先进的音乐信息检索模型,通过对比学习对齐乐谱、演奏信号、音频录音与多语言文本的特征,支持跨模态和跨语言的音乐检索。它能够处理未对齐的模态和未见的语言,展现出强大的泛化能力。该模型基于大规模数据集 M4-RAG 训练,涵盖全球多种音乐传统,支持多种音乐检索任务,如文本到音乐、图像到音乐等。
InspireMusic 是一个专注于音乐、歌曲和音频生成的 AIGC 工具包和模型框架,采用 PyTorch 开发。它通过音频标记化和解码过程,结合自回归 Transformer 和条件流匹配模型,实现高质量音乐生成。该工具包支持文本提示、音乐风格、结构等多种条件控制,能够生成 24kHz 和 48kHz 的高质量音频,并支持长音频生成。此外,它还提供了方便的微调和推理脚本,方便用户根据需求调整模型。InspireMusic 的开源旨在赋能普通用户通过音乐创作提升研究中的音效表现。
YuE是一个开创性的开源基础模型系列,专为音乐生成设计,能够将歌词转化为完整的歌曲。它能够生成包含吸引人的主唱和配套伴奏的完整歌曲,支持多种音乐风格。该模型基于深度学习技术,具有强大的生成能力和灵活性,能够为音乐创作者提供强大的工具支持。其开源特性也使得研究人员和开发者可以在此基础上进行进一步的研究和开发。
YuE 是由香港科技大学和多模态艺术投影团队开发的开源音乐生成模型。它能够根据给定的歌词生成长达 5 分钟的完整歌曲,包括人声和伴奏部分。该模型通过多种技术创新,如语义增强音频标记器、双标记技术和歌词链式思考等,解决了歌词到歌曲生成的复杂问题。YuE 的主要优点是能够生成高质量的音乐作品,并且支持多种语言和音乐风格,具有很强的可扩展性和可控性。该模型目前免费开源,旨在推动音乐生成技术的发展。
AI音乐生成器是一个基于人工智能的在线平台,能够快速生成原创音乐。它利用复杂的机器学习模型和神经网络技术,分析数百万首歌曲的模式和结构,生成高质量的旋律、和声和人声。该产品的主要优点是能够快速实现音乐创作,支持多种流派和风格的定制,并提供灵活的生成选项。它适合音乐创作者、内容制作者和企业用户,能够帮助他们节省创作时间,激发灵感,并生成符合特定需求的音乐。产品提供免费试用和多种付费计划,满足不同用户的需求。
Kokoro-82M是一个由hexgrad创建并托管在Hugging Face上的文本到语音(TTS)模型。它具有8200万参数,使用Apache 2.0许可证开源。该模型在2024年12月25日发布了v0.19版本,并提供了10种独特的语音包。Kokoro-82M在TTS Spaces Arena中排名第一,显示出其在参数规模和数据使用上的高效性。它支持美国英语和英国英语,可用于生成高质量的语音输出。
TangoFlux是一个高效的文本到音频(TTA)生成模型,拥有515M参数,能够在单个A40 GPU上仅用3.7秒生成长达30秒的44.1kHz音频。该模型通过提出CLAP-Ranked Preference Optimization (CRPO)框架,解决了TTA模型对齐的挑战,通过迭代生成和优化偏好数据来增强TTA对齐。TangoFlux在客观和主观基准测试中均实现了最先进的性能,并且所有代码和模型均开源,以支持TTA生成的进一步研究。
EasyMusic AI Music Generator是一个利用人工智能技术,将创意快速转化为专业音乐曲目的平台。它无需音乐专业知识,即可为内容创作者提供最先进的AI音乐生成服务。产品通过训练数百万首歌曲的模型,分析用户输入,创造出独特的音乐。它以快速、易用和高度创造性的特点,改变了音乐创作的方式,让创作音乐变得更加便捷和经济。
AI Sound Effect Generator是一款革命性的工具,它利用先进的AI技术将书面描述转换成自定义音效。该技术结合了自然语言处理和神经音频合成,以产生高质量的输出。系统使用在大量音频数据集上训练的深度学习模型来理解复杂的音频特征,并生成相应的效果。它适用于需要快速获取自定义音效的内容创作者、游戏开发者和音频专业人士。AI Sound Effect Generator处理详细的描述和上下文信息,创建细腻、层次分明的音频效果,以匹配您的创意愿景。无论是环境氛围、机械噪音、音乐元素还是抽象效果,我们的系统都能准确且保真地生成。这种音频生成方法通过人工智能的力量提供了创意可能性。
Sketch2Sound是一个生成音频的模型,能够从一组可解释的时间变化控制信号(响度、亮度、音高)以及文本提示中创建高质量的声音。该模型能够在任何文本到音频的潜在扩散变换器(DiT)上实现,并且只需要40k步的微调和每个控制一个单独的线性层,使其比现有的方法如ControlNet更加轻量级。Sketch2Sound的主要优点包括从声音模仿中合成任意声音的能力,以及在保持输入文本提示和音频质量的同时,遵循输入控制的大致意图。这使得声音艺术家能够结合文本提示的语义灵活性和声音手势或声音模仿的表现力和精确度来创造声音。
CosyVoice语音生成大模型2.0-0.5B是一个高性能的语音合成模型,支持零样本、跨语言的语音合成,能够根据文本内容直接生成相应的语音输出。该模型由通义实验室提供,具有强大的语音合成能力和广泛的应用场景,包括但不限于智能助手、有声读物、虚拟主播等。模型的重要性在于其能够提供自然、流畅的语音输出,极大地丰富了人机交互的体验。
SunoAiFree是一个前沿的AI音乐生成平台,专注于音乐生成和文本到音乐的转换。它提供免费的AI音乐生成服务,使用户能够快速创作出符合行业标准的高质量音乐曲目。SunoAiFree的技术先进,支持多种语言输入,能够理解并生成相应的音乐,具有快速的音乐生成速度和高质量的输出,满足不同用户的需求。
MelodyFlow是一个基于文本控制的高保真音乐生成和编辑模型,它使用连续潜在表示序列,避免了离散表示的信息丢失问题。该模型基于扩散变换器架构,经过流匹配目标训练,能够生成和编辑多样化的高质量立体声样本,且具有文本描述的简单性。MelodyFlow还探索了一种新的正则化潜在反转方法,用于零样本测试时的文本引导编辑,并展示了其在多种音乐编辑提示中的优越性能。该模型在客观和主观指标上进行了评估,证明了其在标准文本到音乐基准测试中的质量与效率上与评估基线相当,并且在音乐编辑方面超越了以往的最先进技术。
UniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示,通过统一的编码器-解码器转换器架构桥接这些模态。它通过微调现有的单模态预训练模型,显著降低了计算需求。UniMuMo在音乐、动作和文本模态的所有单向生成基准测试中都取得了有竞争力的结果。
QA-MDT是一个开源的音乐生成模型,集成了最先进的模型用于音乐生成。它基于多个开源项目,如AudioLDM、PixArt-alpha、MDT、AudioMAE和Open-Sora等。QA-MDT模型通过使用不同的训练策略,能够生成高质量的音乐。此模型特别适合对音乐生成有兴趣的研究人员和开发者使用。
Stable Audio ControlNet 是一个基于 Stable Audio Open 的音乐生成模型,通过 DiT ControlNet 进行微调,能够在具有 16GB VRAM 的 GPU 上使用,支持音频控制。此模型仍在开发中,但已经能够实现音乐的生成和控制,具有重要的技术意义和应用前景。
YourMusic是一个基于SUNO AI 3.5模型的人工智能技术音乐生成平台,它利用深度学习算法分析音乐数据和风格,融合音符、和弦和节奏,为音乐创作者、爱好者以及寻求独特音乐体验的用户提供个性化的音乐作品。
JASCO是一个结合了符号和基于音频的条件的文本到音乐生成模型,它能够根据全局文本描述和细粒度的局部控制生成高质量的音乐样本。JASCO基于流匹配建模范式和一种新颖的条件方法,允许音乐生成同时受到局部(例如和弦)和全局(文本描述)的控制。通过信息瓶颈层和时间模糊来提取与特定控制相关的信息,允许在同一个文本到音乐模型中结合符号和基于音频的条件。
Stable Audio Open 1.0是一个利用自编码器、基于T5的文本嵌入和基于变压器的扩散模型来生成长达47秒的立体声音频的AI模型。它通过文本提示生成音乐和音频,支持研究和实验,以探索生成性AI模型的当前能力。该模型在Freesound和Free Music Archive (FMA)的数据集上进行训练,确保了数据的多样性和版权合法性。
SunoAI.ai是一款革命性的AI音乐生成器,可以即时创建独特的AI MP3歌曲,免费使用。立即下载并享受创新的音乐!
ChatMusician是一个开源的大型语言模型(LLM),它通过持续的预训练和微调,集成了音乐能力。该模型基于文本兼容的音乐表示法(ABC记谱法),将音乐视为第二语言。ChatMusician能够在不依赖外部多模态神经结构或分词器的情况下,理解和生成音乐。
Stability AI 高保真文本转语音模型旨在提供对大规模数据集进行训练的语音合成模型的自然语言引导。它通过标注不同的说话者身份、风格和录音条件来进行自然语言引导。然后将此方法应用于45000小时的数据集,用于训练语音语言模型。此外,该模型提出了提高音频保真度的简单方法,尽管完全依赖于发现的数据,但在很大程度上表现出色。
WhisperKit是一个用于自动语音识别模型压缩与优化的工具。它支持对模型进行压缩和优化,并提供了详细的性能评估数据。WhisperKit还提供了针对不同数据集和模型格式的质量保证认证,并支持本地复现测试结果。
StemGen是一款端到端音乐生成模型,训练成能够聆听音乐背景并做出适当回应的模型。它建立在非自回归语言模型类型的架构上,类似于SoundStorm和VampNet。更多细节请参阅论文。该页面展示了该架构模型的多个示例输出。
Music ControlNet 是一种基于扩散的音乐生成模型,可以提供多个精确的、时变的音乐控制。它可以根据旋律、动态和节奏控制生成音频,并且可以部分指定时间上的控制。与其他音乐生成模型相比,Music ControlNet 具有更高的旋律准确度,并且参数更少、数据量更小。定价信息请访问官方网站。
BGM 猫提供版权背景音乐一站式服务,正版商业授权,AI 智能生成曲库,免费无限,快捷授权,一键下载。
AI音乐生成器(AMG)是一款通过简单描述即可生成音频片段的AI工具。它由Meta的AudioCraft技术提供支持。每秒0.008美元,试用版可生成60秒。
MusicLM是一个模型,可以根据文本描述生成高保真音乐。它可以生成24kHz的音频,音乐风格和文本描述一致,并支持根据旋律进行条件生成。通过使用MusicCaps数据集,模型在音频质量和与文本描述的一致性方面优于之前的系统。MusicLM可以应用于不同的场景,如生成音乐片段、根据画作描述生成音乐等。
MuseNet是一个深度神经网络模型,可以生成4分钟的音乐作品,使用10种不同的乐器,并且可以结合多种音乐风格,从乡村到莫扎特再到披头士。MuseNet通过学习预测数十万个MIDI文件中的下一个音符,发现了和声、节奏和风格的模式。该模型采用了与GPT-2相同的通用无监督学习技术,可以预测音频或文本序列中的下一个标记。
Vagabond AI是一个先进的市场,让艺术家们使用人工智能克隆他们的声音,并通过区块链技术分享生成的音频内容的所有权。它提供了一个平台,用于创建人工智能生成的声音模型、NFT和歌词,促进创作者和用户之间的合作。它还提供定制化、区块链安全和灵活的使用场景。
ClearCypherAI是一家总部位于美国的AI初创公司,致力于构建前沿的解决方案。我们的产品包括文本转语音(T2A)、语音转文本(A2T)和语音转语音(A2A),支持多语言、多模态、实时语音智能。我们还提供自然语言数据集、威胁评估、AI定制平台等服务。我们的产品具有高度定制性、先进的技术和优质的客户支持。
探索 音乐 分类下的其他子分类
260 个工具
85 个工具
80 个工具
44 个工具
32 个工具
28 个工具
27 个工具
24 个工具
AI模型 是 音乐 分类下的热门子分类,包含 44 个优质AI工具