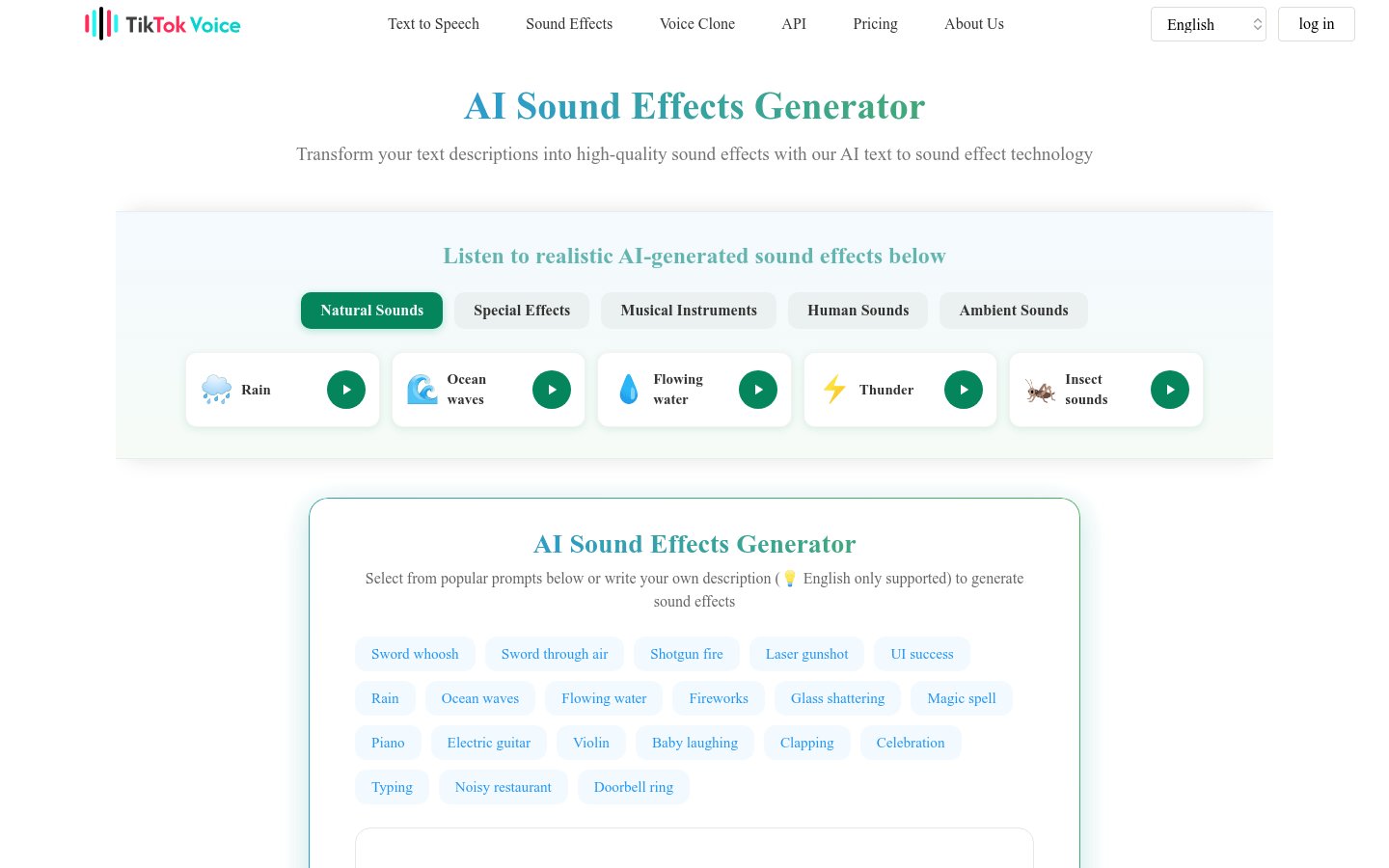
产品详情
AI Sound Effect Generator是一款革命性的工具,它利用先进的AI技术将书面描述转换成自定义音效。该技术结合了自然语言处理和神经音频合成,以产生高质量的输出。系统使用在大量音频数据集上训练的深度学习模型来理解复杂的音频特征,并生成相应的效果。它适用于需要快速获取自定义音效的内容创作者、游戏开发者和音频专业人士。AI Sound Effect Generator处理详细的描述和上下文信息,创建细腻、层次分明的音频效果,以匹配您的创意愿景。无论是环境氛围、机械噪音、音乐元素还是抽象效果,我们的系统都能准确且保真地生成。这种音频生成方法通过人工智能的力量提供了创意可能性。
主要功能
使用教程
适用人群
目标受众包括内容创作者、游戏开发者和音频专业人士。这款产品适合他们,因为它可以快速生成高质量的自定义音效,满足他们在创作过程中对音效的即时需求,同时提供专业级别的音质和无需版税的使用权。
使用示例
- 视频制作中,为不同场景添加环境氛围音效。
- 游戏开发中,为角色动作生成独特的音效。
- 社交媒体内容中,为视频添加引人入胜的背景音乐和特效音。
快速访问
访问官网 →所属分类
相关推荐
发现更多类似的优质AI工具

BPM Finder
BPM Finder是一款先进的BPM分析工具,能够准确检测任何音频源的节奏,具有三种强大的分析模式。它为音乐创作者和DJ提供了专业的BPM检测功能,可实现精准的节奏分析。

Free AI Vocal Remover & Stem Splitter
音乐与声音分离是一项在线服务,使用先进的AI技术将音乐中的人声和伴奏进行分离。其主要优点在于快速、免费且无需登录,可帮助用户轻松分离音乐中的不同元素。
Music Eleven AI
Music Eleven AI是一款AI音乐生成器,使用先进的机器学习模型,能够从文本描述中生成完整的音乐作品,包括旋律、和声、节奏和人声。产品具有商业授权,支持30多种音乐风格,适用于创作者、音乐人和企业。价格分为Starter、Creator和Professional三个计划。
Singify Vocal Remover
Singify Vocal Remover是一款利用先进AI技术提取音乐中人声和乐器的工具。它能够准确提取歌曲的人声,并隔离单独的鼓、贝斯、钢琴、电吉他、原声吉他和合成器等部分。该工具免费易用,保留原始音频细节,支持多种音频输出格式。

Dubnote
Dubnote是一款专为音乐家设计的会话录音应用程序,帮助他们捕捉和整理音乐创意。用户可以将录音整理到文件夹中,自动拆分为部分,并使用表情符号或注释标记关键时刻。这款应用的主要优点在于帮助音乐家更好地管理和保存创意灵感。
voicss
Voicss是一款AI音轨去除器,能够智能分离音乐中的人声和背景音乐,适用于音乐编辑、卡拉OK制作等领域,无需下载软件。
Echovox Studio
Echovox Studio是一款功能强大的音乐制作软件,拥有先进的录音和混音功能,可用于制作各种音乐类型。它的主要优点在于直观易用的界面和丰富的音频处理工具。

Audio-SDS
Audio-SDS 是一个将 Score Distillation Sampling(SDS)概念应用于音频扩散模型的框架。该技术能够在不需要专门数据集的情况下,利用大型预训练模型进行多种音频任务,如物理引导的冲击声合成和基于提示的源分离。其主要优点在于通过一系列迭代优化,使得复杂的音频生成任务变得更为高效。此技术具有广泛的应用前景,能够为未来的音频生成和处理研究提供坚实基础。

AudioX
Audiox是一款利用AI技术生成专业音频的工具,无需音乐知识,可快速创建令人惊叹的音乐和声音效果。其主要优点包括创作便捷、音质优良、使用简单,适用于音乐制作、视频制作、声效设计等领域。

Soundlabs AI
Soundlabs AI 是一款面向音乐制作人的音频工具,专注于实时声音和乐器转换。它通过先进的 AI 技术,将用户的声音转换为高质量的虚拟歌手或乐器音色,无缝集成到任何数字音频工作站(DAW)中。该技术的主要优点包括实时转换、高质量音频输出以及丰富的音色模型库。Soundlabs AI 不仅提升了音乐创作的灵活性,还为创作者提供了无限的创意可能性,无论是在流行音乐、电子音乐还是其他流派中都能发挥重要作用。其价格定位明确,提供多种购买选项,包括一次性购买和订阅服务,满足不同用户的需求。

GenSFX
GenSFX 是一款基于先进 AI 技术的音效生成工具,通过将文本描述转化为专业音效,为用户提供高效、便捷的音效创作方案。其主要优点包括:无需专业音效制作知识,用户只需输入文字描述,即可快速生成所需音效;生成的音效质量高,能满足不同场景需求;操作简单,无需复杂设置。该产品主要面向内容创作者、游戏开发者等需要定制音效的用户群体,帮助他们节省时间和成本,提升创作效率。目前 GenSFX 为用户免费提供服务,降低了音效创作的门槛,使更多人能够轻松获取高质量音效。

AIVocal
AIVocal是一款基于人工智能技术的在线人声消除工具,它能够在短时间内从任何歌曲中去除人声,创建伴奏带、分离乐器音轨,并提升音乐制作效率。该产品以其高效率、高精度和易用性,满足了音乐制作人、内容创作者和翻唱艺术家的需求。AIVocal支持多种音频格式,如MP3、WAV和FLAC,适合专业音乐制作和日常娱乐使用。

Sketch2Sound
Sketch2Sound是一个生成音频的模型,能够从一组可解释的时间变化控制信号(响度、亮度、音高)以及文本提示中创建高质量的声音。该模型能够在任何文本到音频的潜在扩散变换器(DiT)上实现,并且只需要40k步的微调和每个控制一个单独的线性层,使其比现有的方法如ControlNet更加轻量级。Sketch2Sound的主要优点包括从声音模仿中合成任意声音的能力,以及在保持输入文本提示和音频质量的同时,遵循输入控制的大致意图。这使得声音艺术家能够结合文本提示的语义灵活性和声音手势或声音模仿的表现力和精确度来创造声音。

Vocal Remover Online
Vocal Remover Online 是一个基于深度学习技术的网站,能够从音频或视频中分离出人声和伴奏。这项技术对于音乐制作人、视频制作者和卡拉OK爱好者来说非常有用,因为它可以轻松地分离出伴奏和人声,使得用户可以用于音乐创作、视频编辑或个人娱乐。产品提供免费的基础服务,并可能对高级功能和批量处理收取一定费用。

ComfyUI-MMAudio
ComfyUI-MMAudio是一个基于ComfyUI的插件,它允许用户利用MMAudio模型进行音频处理。该插件的主要优点在于能够提供高质量的音频生成和处理能力,支持多种音频模型,并且易于集成到现有的音频处理流程中。产品背景信息显示,它是由kijai开发的,并且是开源的,可以在GitHub上找到。目前,该插件主要面向技术爱好者和音频处理专业人士,可以免费使用。

MMAudio
MMAudio是一种多模态联合训练技术,旨在高质量的视频到音频合成。该技术能够根据视频和文本输入生成同步音频,适用于各种应用场景,如影视制作、游戏开发等。其重要性在于提升了音频生成的效率和质量,适合需要音频合成的创作者和开发者使用。