共找到 50 个AI工具
点击任意工具查看详细信息
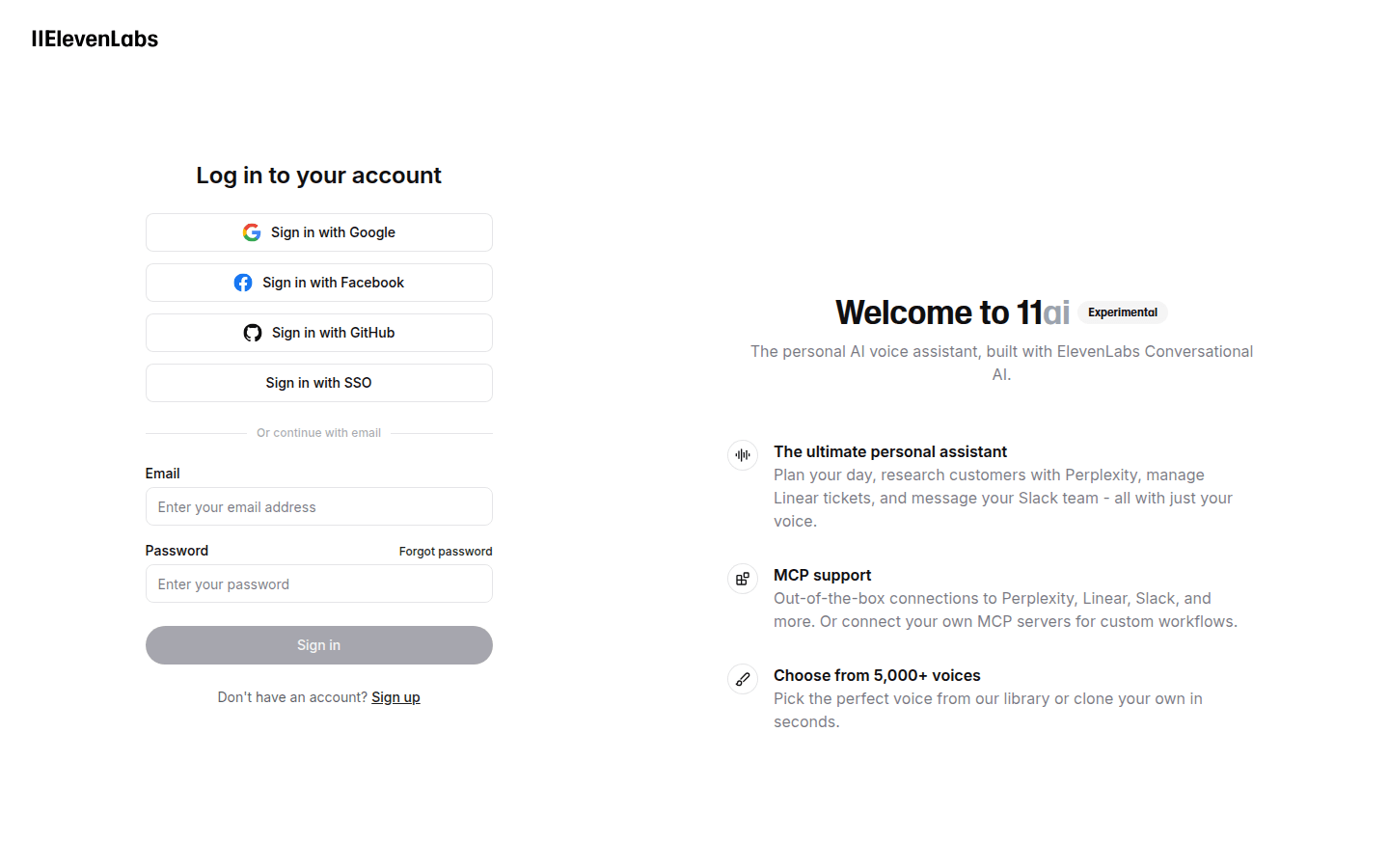
11.ai是一个个人AI语音助手,通过ElevenLabs Conversational AI构建。它可以计划您的日程,研究客户信息,管理工单并与Slack团队交流,所有这些都可以通过语音实现。
Speechly是一款旨在将您的语音转化为结构化的电子邮件的工具,无需手动输入,即可轻松获得清晰易读的信息,支持多达100种语言。
Pinch 是一款创新的实时 AI 语音翻译工具,旨在消除视频通话中的语言障碍。它利用先进的 AI 技术,提供即时、准确的语音翻译,支持 30 多种语言。该产品适用于跨国企业、教育机构、家庭和个人,帮助用户实现无缝沟通。Pinch 的主要优点包括高翻译准确率、支持多种语言以及无需额外设备即可使用。它通过减少语言障碍,促进了全球范围内的商业合作、教育交流和家庭联系,具有重要的商业和教育价值。
DuRT 是一款专注于 macOS 系统的语音识别和翻译工具。它通过本地 AI 模型和系统服务实现语音的实时识别与翻译,支持多种语音识别方法,提高了识别的准确度和语言支持范围。该产品以悬浮框形式展示结果,方便用户在使用过程中快速获取信息。其主要优点包括高准确度、隐私保护(不收集用户信息)以及便捷的操作体验。DuRT 定位为一款高效生产力工具,旨在帮助用户在多语言环境下更高效地进行沟通和工作。目前产品可在 Mac App Store 下载,具体价格未在页面中明确提及。
Sesame 是一个专注于语音技术的跨学科产品和研究团队,旨在通过自然语音交互,让用户与计算机的交互更加自然和高效。其主要产品包括个人语音伴侣和轻量级可穿戴眼镜设备,旨在实现计算机的拟人化,帮助用户更好地组织信息、提升效率。产品的主要优点是语音交互的自然性和设备的便携性,适合日常使用。目前,Sesame 正在积极招聘,致力于推动语音技术的创新。
Scribe 是由 ElevenLabs 开发的高精度语音转文字模型,旨在处理真实世界音频的不可预测性。它支持99种语言,提供单词级时间戳、说话人分离和音频事件标记等功能。Scribe 在 FLEURS 和 Common Voice 基准测试中表现卓越,超越了 Gemini 2.0 Flash、Whisper Large V3 和 Deepgram Nova-3 等领先模型。它显著降低了传统服务不足语言(如塞尔维亚语、粤语和马拉雅拉姆语)的错误率,这些语言在竞争模型中的错误率通常超过40%。Scribe 提供 API 接口供开发者集成,并将推出低延迟版本以支持实时应用。
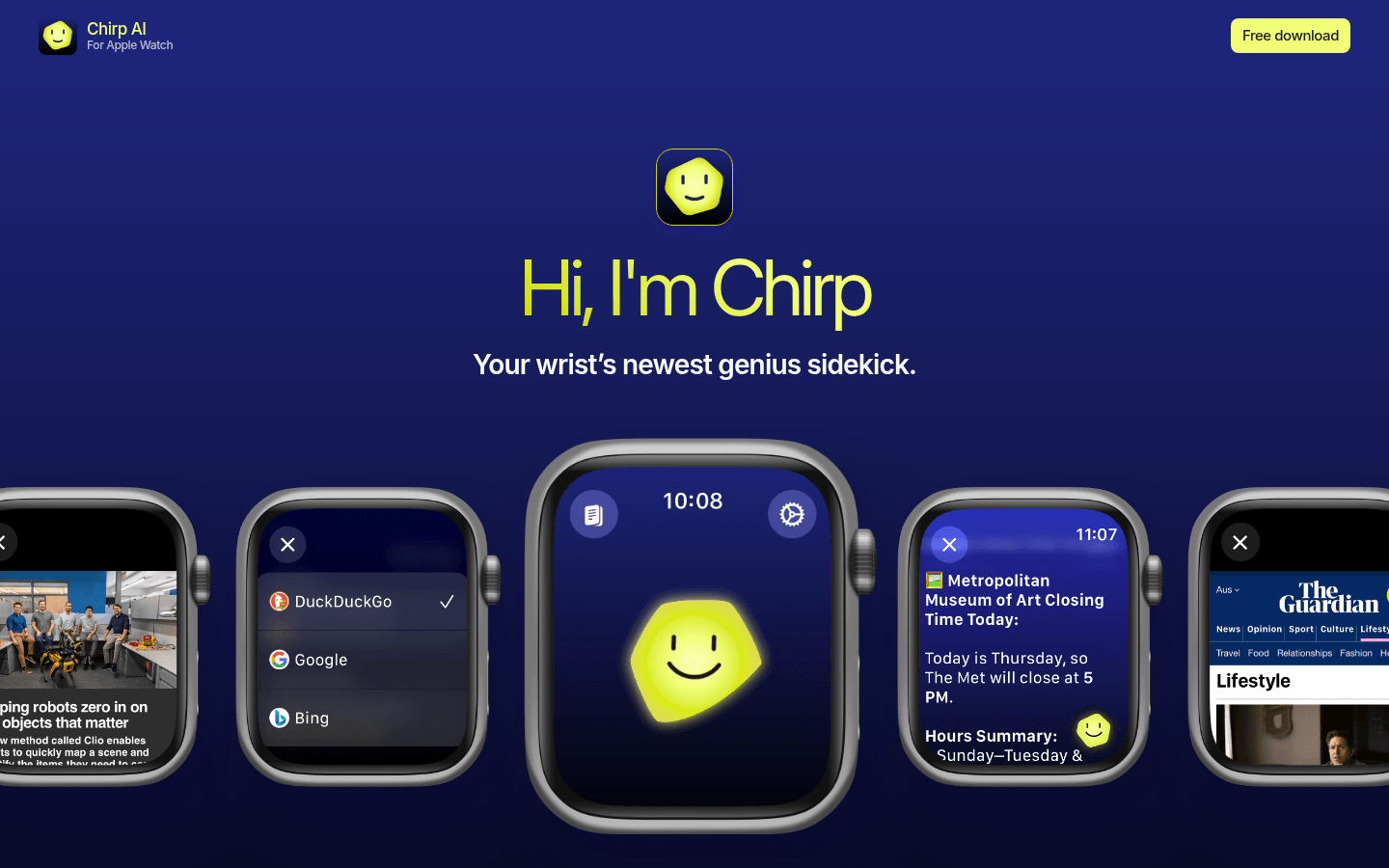
Chirp AI 是一款专为 Apple Watch 设计的智能语音助手应用。它通过强大的语音识别和人工智能技术,让用户能够仅通过语音指令完成各种操作,如发送信息、获取信息、搜索网络等,极大地提升了用户在移动场景下的操作效率。该产品的主要优点是无需频繁使用手机,即可实现高效的信息交互和任务处理。它适用于那些希望在日常生活中减少对手机依赖,同时又能快速获取信息和完成任务的用户。目前该应用提供免费下载,定位为提升用户生产力和便捷性的智能工具。
FireRedASR-AED-L 是一个开源的工业级自动语音识别模型,专为满足高效率和高性能的语音识别需求而设计。该模型采用基于注意力的编码器-解码器架构,支持普通话、中文方言和英语等多种语言。它在公共普通话语音识别基准测试中达到了新的最高水平,并且在歌唱歌词识别方面表现出色。该模型的主要优点包括高性能、低延迟和广泛的适用性,适用于各种语音交互场景。其开源特性使得开发者可以自由地使用和修改代码,进一步推动语音识别技术的发展。
FireRedASR 是一个开源的工业级普通话自动语音识别模型,采用 Encoder-Decoder 和 LLM 集成架构。它包含两个变体:FireRedASR-LLM 和 FireRedASR-AED,分别针对高性能和高效能需求设计。该模型在普通话基准测试中表现出色,同时在方言和英文语音识别上也有良好表现。它适用于需要高效语音转文字的工业级应用,如智能助手、视频字幕生成等。模型开源,便于开发者集成和优化。
Whisper Turbo 是基于 Whisper Large-v3 模型优化的语音识别工具,专为快速语音转录而设计。它利用先进的 AI 技术,能够高效地将不同音频源的语音转换为文本,支持多种语言和口音。该工具免费提供给用户,旨在帮助人们节省时间和精力,提高工作效率。其主要面向需要快速准确转录语音内容的用户,如博主、内容创作者、企业等,为他们提供便捷的语音转文字解决方案。
RealtimeSTT是一个开源的语音识别模型,能够实时将语音转换为文本。它使用了先进的语音活动检测技术,可以自动检测语音的开始和结束,无需手动操作。此外,它还支持唤醒词激活功能,用户可以通过说出特定的唤醒词来启动语音识别。该模型具有低延迟、高效率的特点,适合需要实时语音转录的应用场景,如语音助手、会议记录等。它基于Python开发,易于集成和使用,且在GitHub上开源,社区活跃,不断有新的更新和改进。
Home Assistant Voice Preview Edition是一款开源、注重隐私的语音助手硬件产品,旨在提供一种开放、本地化、私人化的语音控制解决方案。它允许用户通过语音控制家中的智能设备,同时确保用户的语音数据不会离开本地网络,保护用户隐私。该产品背景是响应对隐私保护日益增长的需求,特别是在智能家居领域。价格方面,产品定价为59美元,推荐零售价,具体价格可能会因零售商而异。
OmniAudio-2.6B是一个2.6B参数的多模态模型,能够无缝处理文本和音频输入。该模型结合了Gemma-2B、Whisper turbo和一个自定义投影模块,与传统的将ASR和LLM模型串联的方法不同,它将这两种能力统一在一个高效的架构中,以最小的延迟和资源开销实现。这使得它能够安全、快速地在智能手机、笔记本电脑和机器人等边缘设备上直接处理音频文本。
Shortcut by Poised是一个基于语音的AI助手,旨在通过自然对话的方式提升用户的工作效率。它允许用户通过语音输入快速获得答案、整理思路、起草消息、电子邮件和文档,同时保持工作流程的连贯性。产品通过AI技术将自然语言转换为精炼的文本,并提供多种语言风格选项,满足不同场合的需求。Shortcut by Poised的背景信息显示,它在Product Hunt上发布,并即将推出Windows和移动应用版本,目前Mac版本已可下载。
ClearerVoice-Studio是一个开源的AI驱动语音处理工具包,专为研究人员、开发者和最终用户设计。它提供了语音增强、语音分离、目标说话人提取等功能,并提供了最新的预训练模型以及训练和推理脚本,全部可通过此仓库访问。该工具包以其预训练模型、易用性、全面功能和社区驱动的特点而受到青睐。
Najva是一款专为Mac设计的AI驱动的语音助手,它结合了先进的本地语音识别技术和强大的AI模型,将您的语音转换成智能文本。这款应用特别适合那些思维速度比打字速度快的用户,如作家、开发者、医疗专业人员等。Najva以其轻量级、原生Swift应用、零追踪和完全免费等特点,为用户提供了一个注重隐私和效率的工作流程解决方案。
Transcribro是一款运行在Android平台上的私有、设备端语音识别键盘和文字服务应用,它使用whisper.cpp来运行OpenAI Whisper系列模型,并结合Silero VAD进行语音活动检测。该应用提供了语音输入键盘,允许用户通过语音进行文字输入,并且可以被其他应用显式使用,或者设置为用户选择的语音转文字应用,部分应用可能会使用它来进行语音转文字。Transcribro的背景是为用户提供一种更安全、更私密的语音转文字解决方案,避免了云端处理可能带来的隐私泄露问题。该应用是开源的,用户可以自由地查看、修改和分发代码。
Universal-2是AssemblyAI推出的最新语音识别模型,它在准确度和精确度上超越了前一代Universal-1,能够更好地捕捉人类语言的复杂性,为用户提供无需二次检查的音频数据。这一技术的重要性在于它能够为产品体验提供更敏锐的洞察力、更快的工作流程和一流的产品体验。Universal-2在专有名词识别、文本格式化和字母数字识别方面都有显著提升,减少了实际应用中的词错误率。
Moonshine 是一系列为资源受限设备优化的语音转文本模型,非常适合实时、设备上的应用程序,如现场转录和语音命令识别。在 HuggingFace 维护的 OpenASR 排行榜中使用的测试数据集上,Moonshine 的词错误率(WER)优于同样大小的 OpenAI Whisper 模型。此外,Moonshine 的计算需求随着输入音频的长度而变化,这意味着较短的输入音频处理得更快,与 Whisper 模型不同,后者将所有内容都作为 30 秒的块来处理。Moonshine 处理 10 秒音频片段的速度是 Whisper 的 5 倍,同时保持相同或更好的 WER。
GLM-4-Voice是由清华大学团队开发的端到端语音模型,能够直接理解和生成中英文语音,进行实时语音对话。它通过先进的语音识别和合成技术,实现了语音到文本再到语音的无缝转换,具备低延迟和高智商的对话能力。该模型在语音模态下的智商和合成表现力上进行了优化,适用于需要实时语音交互的场景。
Whispo是一款利用人工智能技术的语音听写工具,它能够将用户的语音实时转换成文字。这款工具使用了OpenAI Whisper技术进行语音识别,并支持使用自定义API进行语音转写,还允许通过大型语言模型进行转录后处理。Whispo支持多种操作系统,包括macOS(Apple Silicon)和Windows x64,并且所有数据都存储在本地,保障了用户隐私。它的设计背景是为了提高那些需要大量文字输入的用户的工作效率,无论是编程、写作还是日常记录。Whispo目前是免费试用的,但具体的定价策略尚未在页面上明确。
Flow by Wispr是一款致力于提高语音输入效率的应用程序。它通过先进的语音识别技术,使得用户能够以比传统键盘打字快三倍的速度进行文字输入。Flow by Wispr特别适合需要快速记录和编辑文本的用户,例如作家、记者、学生和专业人士。产品目前仅支持苹果硅芯片的Mac电脑,未来将扩展到更多平台。
Silvia是一款能够适应用户说话方式的语音输入系统,支持用户在不同语言之间自由切换,即使在句子中也能无缝切换。它支持英语和西班牙语,并且即将支持法语、罗马尼亚语、德语和荷兰语。Silvia作为苹果应用商店中的扩展,可以用于所有聊天平台,如iMessage、WhatsApp、Signal、Telegram、Messenger等,让用户在任何需要打字的地方都能使用语音输入。
文本转语音技术是一种将文本信息转换为语音的技术,广泛应用于辅助阅读、语音助手、有声读物制作等领域。它通过模拟人类语音,提高了信息获取的便捷性,尤其对视力障碍者或在无法使用眼睛阅读的情况下非常有帮助。
TTSMaker是一款在线的文本转语音平台,通过AI人工智能算法将文本轻松转换成音频。它支持50多种语言和300多个语音包风格,适用于视频配音、有声读物、教育培训和产品营销等多种场景。用户可以免费使用TTSMaker合成语音,并且拥有合成的音频文件的100%版权,可以用于任何合法的商业用途。
该产品是一个先进的在线文字转语音工具,使用人工智能技术将文本转换为自然逼真的语音。它支持多种语言和语音风格,适用于广告、视频旁白、有声书制作等场景,增强了内容的可访问性和吸引力。产品背景信息显示,它为数字营销人员、内容创作者、有声书作者和教育工作者提供了极大的便利。
BeMyEars 是一款实时字幕生成工具,利用本地设备完成语音识别,为听障人士和需要字幕的用户提供极致体验。其主要优点包括多语言支持、多源输入、隐私保护等。
boff.ai是一款基于人工智能的语音识别和自然语言处理技术的网站。它的主要优点是快速准确地识别用户的语音输入并能够理解其意图,从而提供相应的回答和建议。boff.ai的定位是提供智能的语音助手服务,帮助用户更高效地处理信息和完成任务。
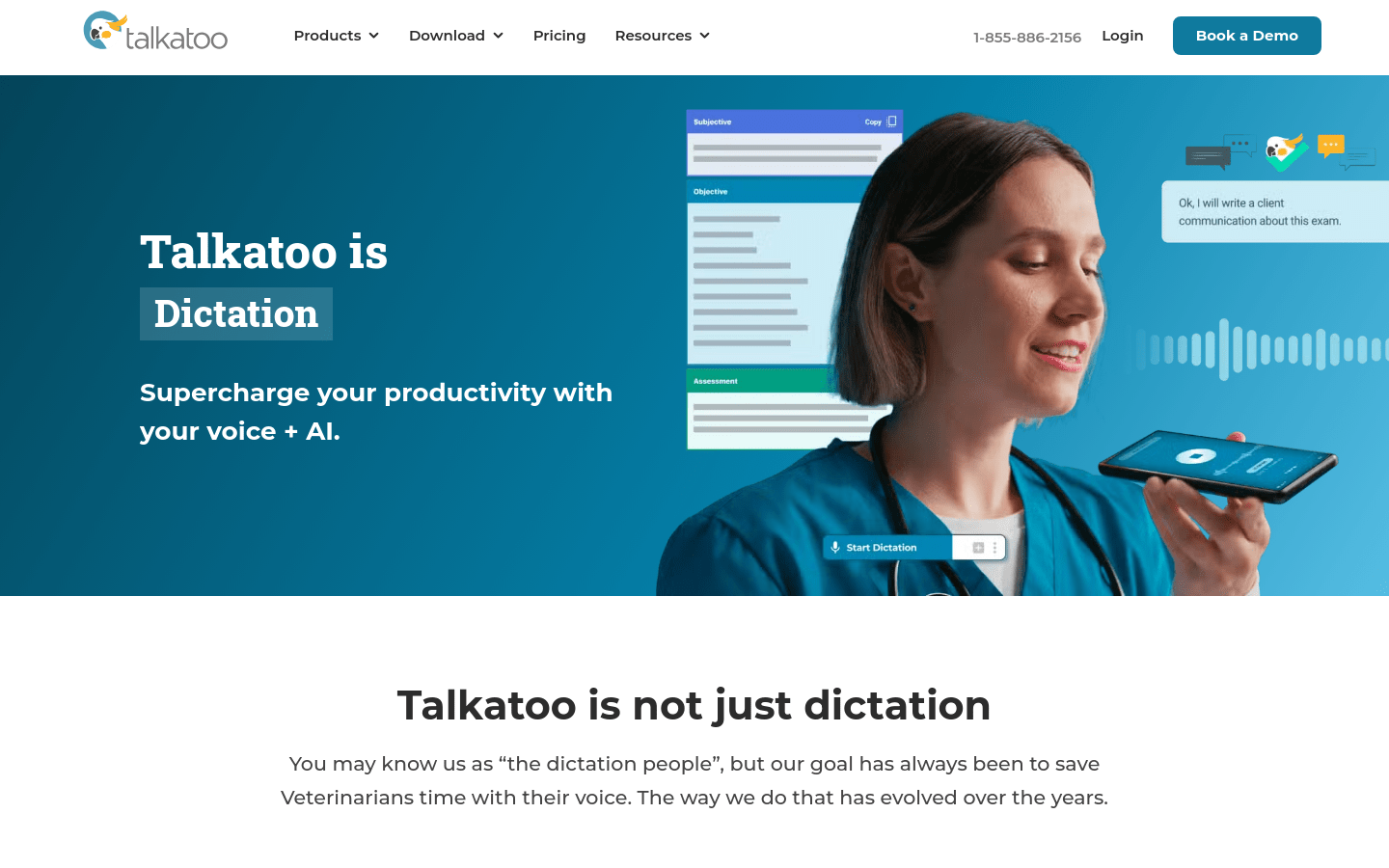
Talkatoo是一款口述软件,可以比平均打字速度快5倍地转录内容,帮助用户节省时间。它提供了三种级别的控制,用户可以选择更自动化的方式来使用。Talkatoo具有验证记录、自动格式化记录和桌面口述等功能,适用于兽医等行业的专业人士。定价根据具体需求而定。Talkatoo还可以自动转化成SOAP(主诉、体检、诊断、处方)模板,提高医疗记录的效率。
01 Light是一款语音控制界面,可以让你用语音控制家用电脑执行各种操作。它的优势是操作便捷、语音识别准确。定价暂未公布,定位是家用电脑的语音控制辅助工具。
WhisperKit由Argmax公司推出,是一个基于Whisper项目的推理工具包,它允许在iOS和macOS应用程序中进行语音识别和转录。该项目的目标是收集开发者反馈,并在几周内发布一个稳定的候选版本,以加速设备上推理的生产化。
OutSkill是专为日常PC用户打造的AI桌面语音助手,能够轻松执行多项任务、个性化整合各种应用和游戏,智能识别用户需求并相应操作。它能够彻底改变我们与计算机的互动方式,摆脱了频繁切换应用和任务的烦恼,只需语音指令,让AI来完成工作,提高生产力,减轻工作负担。立即加入等待列表,体验便利无限!
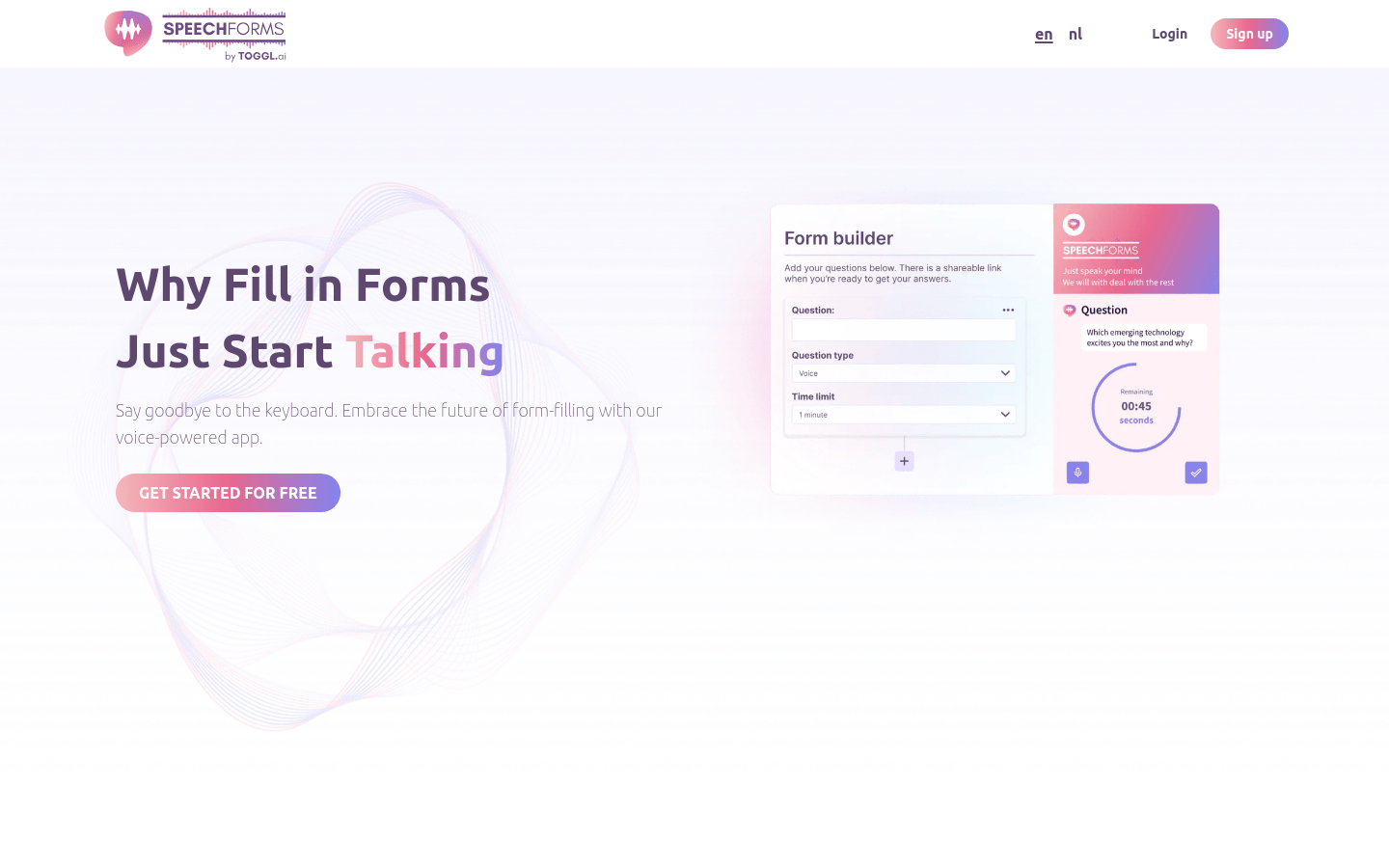
Speechforms是一款通过语音输入来填写表单的应用。它可以让用户摆脱键盘,以更直观的方式完成表单填写,实现了表单填写的未来。Speechforms提供免费试用,具体定价请参考官方网站。
Free Text to Speech Online Converter是一个多语言文本转语音的在线平台。它支持超过20种语言,拥有自然的发音,无需注册即可免费使用,转换速度快。
Koe 是一款AI语音转写工具,支持多种音视频文件格式,采用OpenAI Whisper模型本地转写,提供API服务,支持视频播放时生成字幕,AI翻译、语音听写等功能。早鸟价$12,永久授权两台设备。
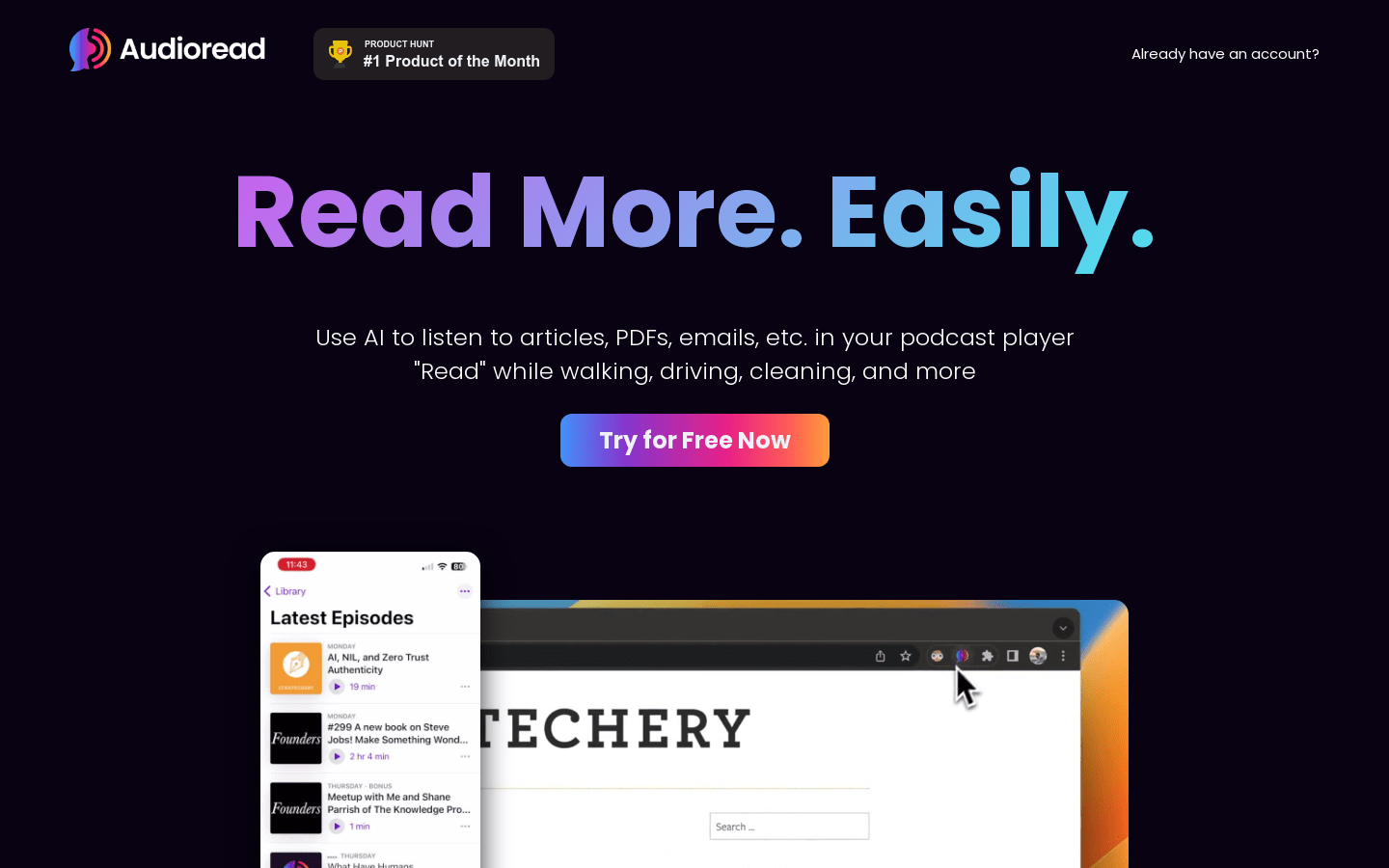
Audioread是一款利用人工智能将文字转换为语音的工具。其具备超逼真的文本转语音引擎,能够以自然而专业的叙述风格朗读任何文本,旨在长时间收听,训练有素,几乎无法与真实有声书叙述者区分开来。用户可以使用网页应用、浏览器插件、iOS快捷方式或Android应用程序将文字转换为音频,也可以转发电子邮件、拖放PDF、复制/粘贴文本或者高亮文本。Audioread还支持创建并订阅私人播客,用户可以在任何播客应用程序中订阅私人播客,如Apple Podcasts、Google Podcasts、Spotify等。此外,用户还可以在浏览器中收听,无需安装任何应用。Audioread还提供付费服务,包括月度订阅,每月9.99美元,每次转换最多10万字,每日最多50万字,支持77种语言。
Azure AI Speech Studio是一个语音服务平台,提供语音转文本、文本转语音等功能。它可以帮助应用实现语音聆听、理解和交流的能力。Speech Studio提供了多种语音功能,包括语音转文本、实时语音转文本、批处理语音转文本、自定义语音识别、语音翻译、文本转语音等。用户可以根据自己的需求选择合适的功能,并通过示例代码快速上手。Speech Studio还提供了学习资源,包括文档、快速入门指南、Microsoft 问答和Microsoft Learn等。
SpeechPulse是一款语音识别和翻译软件。它使用OpenAI的Whisper语音到文本模型,实现实时的语音识别,支持多种语言。用户可以使用麦克风输入文字,也可以通过转录音视频文件进行语音识别和翻译。SpeechPulse可以在各种场景下使用,例如办公文档编辑、网页浏览、文件转录、视频字幕生成等。它具有极高的准确性和低延迟,并且完全离线使用。SpeechPulse提供免费版和付费版,付费版支持更多功能和更好的准确性。
Pronounce是一款免费的英语语音检查器,可以帮助您改善发音。通过录制您的声音,改善英语发音的准确性和流利度。
语言助手是一款智能语言处理应用,提供多种语言翻译、语音识别、语音合成等功能。优势包括高准确率、快速响应、支持多种语言等。该产品提供免费和付费版本,付费版本提供更多高级功能和无广告体验。定位于为用户提供便捷、高效的语言处理服务。
Lugs.ai是一款能够在电脑上准确实时生成字幕的插件。无需联网,支持电脑内的所有音频,包括麦克风录音和电脑上的声音。它使用AI技术,可以深度理解对话内容,并根据上下文进行准确的转写和字幕生成。Lugs.ai是由听力受损者开发的,始终以实际使用体验为依据进行不断优化。具备最佳的准确性和持续的更新。
语音听写是一款免费的在线语音识别软件,可以通过语音输入来帮助您写邮件、文件和文章,无需打字。
Speech Intellect是第一个实时工作的语音转文字/文字转语音解决方案,完全使用了全新的AI专注的数学理论——Sense Theory。它考虑了客户发音的每个单词的意义。我们的解决方案基于自主研发的Sense-to-Sense算法,可以实现文本以带有语调和特定调性的声音重新产生。该解决方案可以轻松集成到各种业务场景中,如视频游戏中以人形声音复制脚本文本、呼叫中心与客户的交流、网站上的虚拟对话、智能家居中的舒适对话等等。我们的算法使用的是Sense,与市场上其他解决方案的算法不同。
智能语音助手是一款基于人工智能技术的智能助手应用,通过语音识别和自然语言处理等技术,实现语音交互、信息查询、任务提醒等功能。它可以帮助用户高效管理日程安排,提供实时天气信息,播放音乐等。该产品定价合理,定位于提升用户工作和生活效率的智能助手。
AI实时字幕服务是一款基于人工智能的在线字幕服务,可以实时为会议或会议服务提供字幕和交互式转录。无需编程即可轻松集成到您的服务中。支持多种语言和方言,提供实时的字幕数据,帮助提升会议的可访问性和用户体验。
智能语音助手是一款能够将用户的声音转化为语音助手的插件。它可以帮助用户实现语音合成、语音识别等功能,让用户的声音变成实用的工具。优势:高度定制化,支持多种语言和声音风格;简单易用,只需几步操作即可完成配置;多场景应用,可用于个人助手、语音广播等领域。定价:免费试用,付费版本提供更多功能和支持。定位:为用户提供一个快速、便捷、高效的语音助手工具。
在线文本转语音是一款免费的工具,可以将文本转换为真实的语音。它具有高音质、自然的语音效果,并支持多种语言和声音选择。用户只需输入文本,选择语言和声音,即可生成自定义的语音内容。该工具适用于多种场景,如视频配音、教育辅助、语音导航等。无论是Mac还是Windows用户,都可以轻松使用该工具。
Voiser是一款拥有550多种不同语音选项的文本转语音工具。它可以将文字转换为逼真的机器语音,并提供人类声音的最接近的机器语音。此外,Voiser还可以将语音文件转换为文字,提供快速且准确的语音转文本服务。Voiser是最佳的文本朗读和语音转换解决方案。
小时AI是一款智能语音助手,通过语音指令帮助用户提高生产力。它具有语音识别、语音合成、智能对话等功能,可以帮助用户完成日常任务,如提醒日程、查询天气、发送短信等。小时AI定价灵活,提供免费和付费版本,适用于个人和企业用户。它定位于成为用户的私人助手,为用户提供高效便捷的语音交互体验。
TTSMaker是一款免费的在线文本转语音工具,支持多种语言和语音风格。它可以将文字转换为自然流畅的语音,并提供下载MP3和WAV格式的音频文件。TTSMaker能够广泛应用于阅读文本、朗读电子书等场景,适用于个人和商业用途。
探索 生产力 分类下的其他子分类
1361 个工具
904 个工具
767 个工具
619 个工具
607 个工具
431 个工具
406 个工具
398 个工具
语音识别 是 生产力 分类下的热门子分类,包含 50 个优质AI工具