共找到 100 个AI工具
点击任意工具查看详细信息
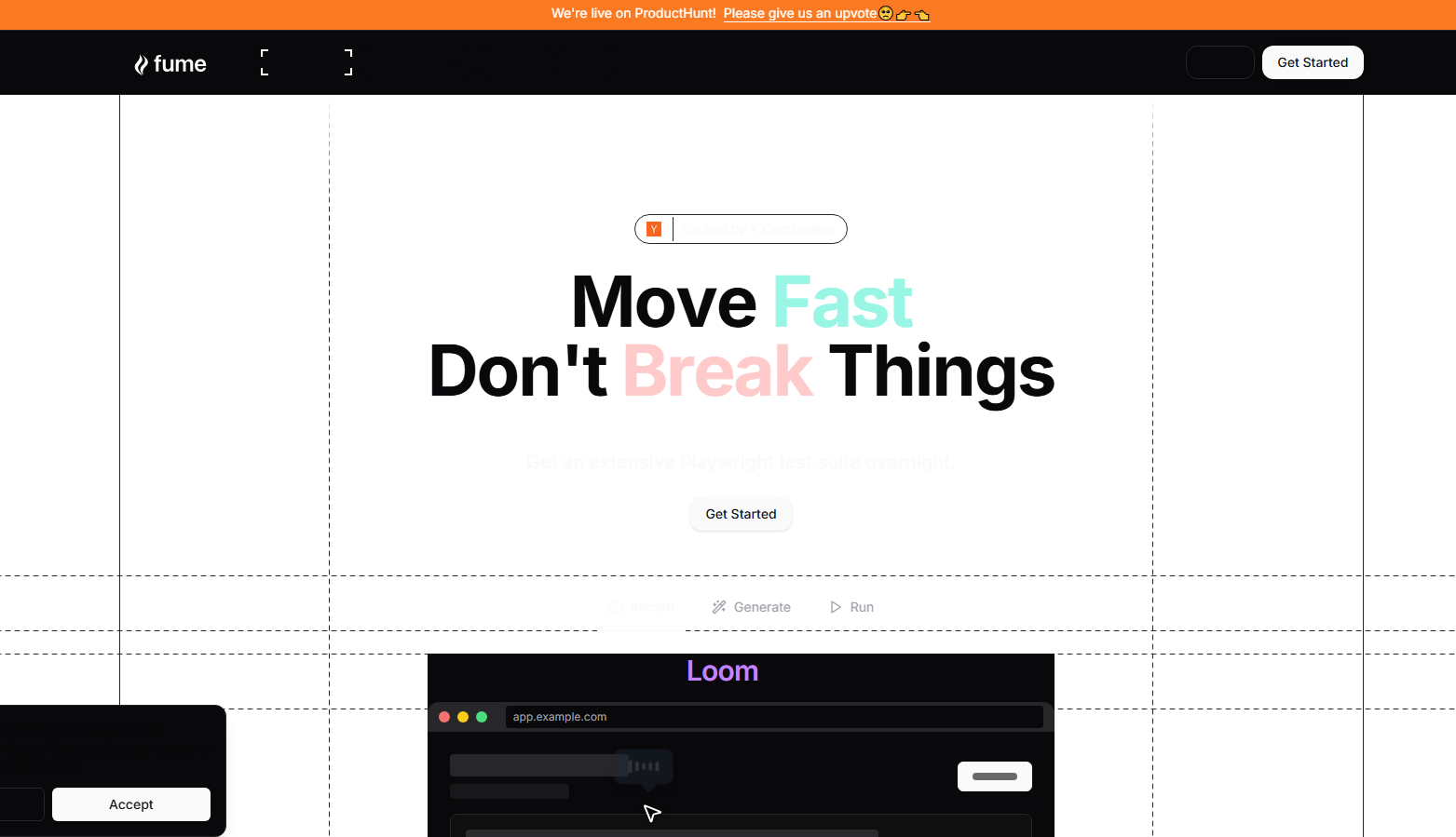
Fume是一款AI测试工具,利用人工智能技术为用户提供无忧的AI测试体验。它能够根据用户的录制视频生成和维护Playwright端到端浏览器测试,极大地简化了测试流程,提高了测试效率。
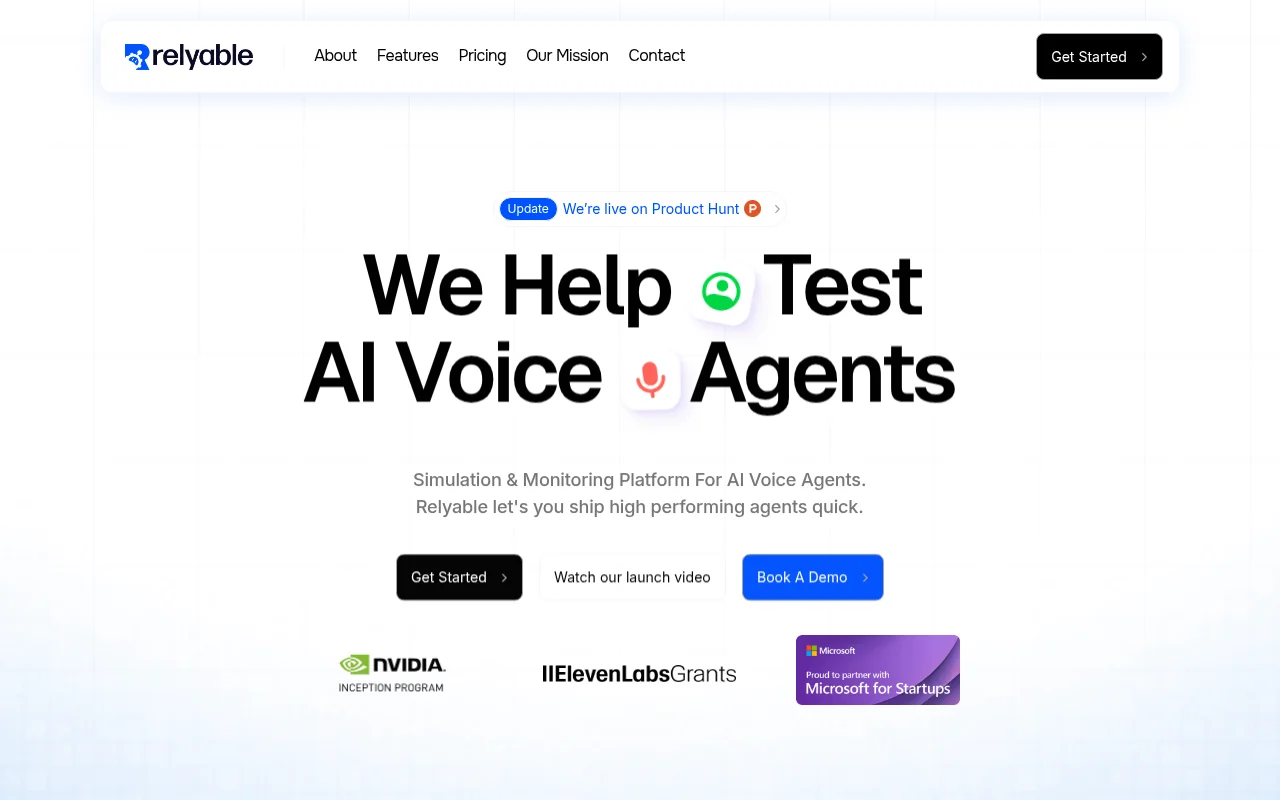
Relyable 是一个自动化 AI 代理测试与监控工具,通过模拟和智能分析,帮助用户评估、优化和监控 AI 语音代理的表现。它能够帮助用户快速部署生产就绪的 AI 代理,提高工作效率。
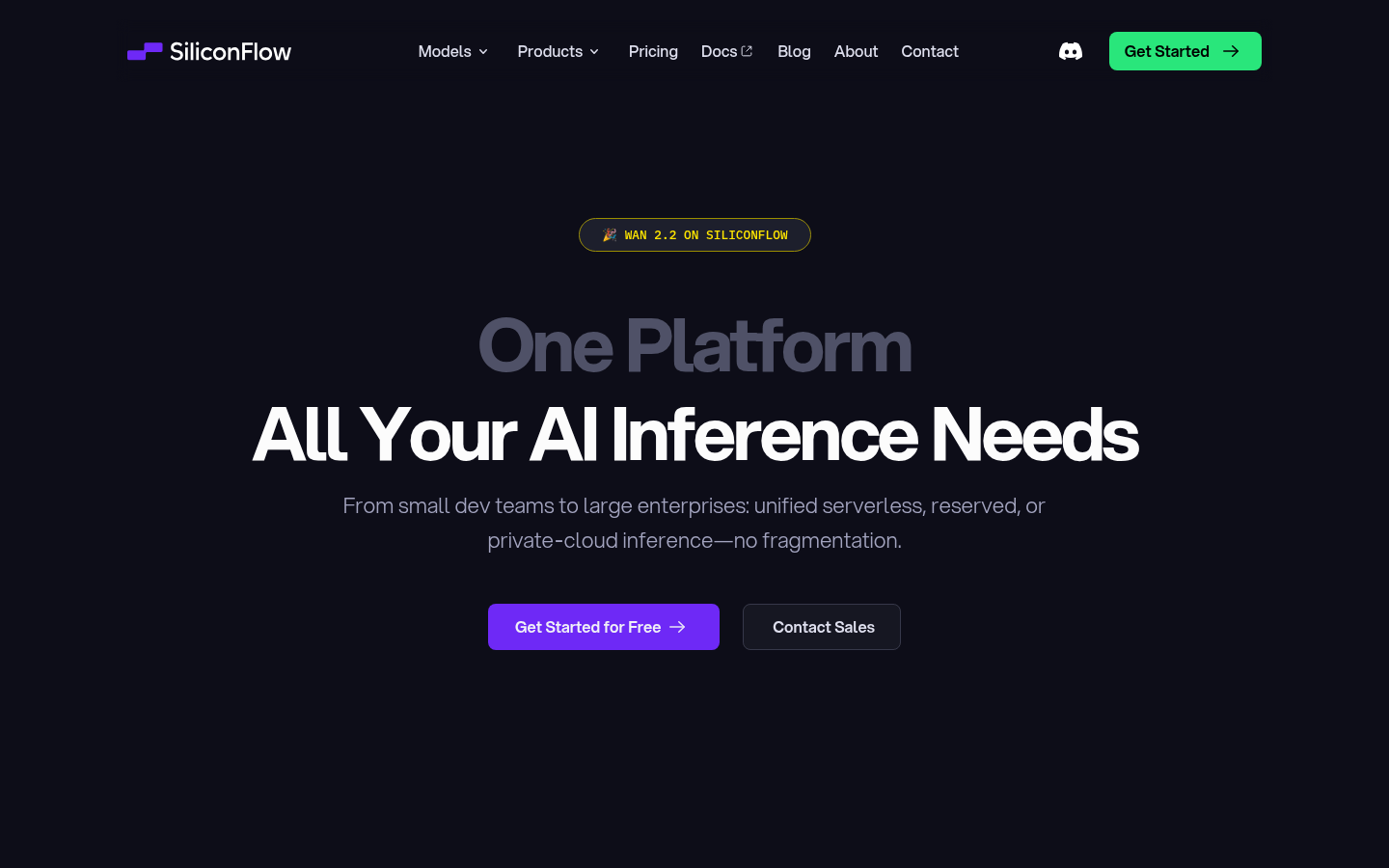
SiliconFlow是一款为开发者提供LLM部署、AI模型托管和推理API的AI基础设施。它通过优化的堆栈为用户提供更低的延迟、更高的吞吐量和可预测的成本。
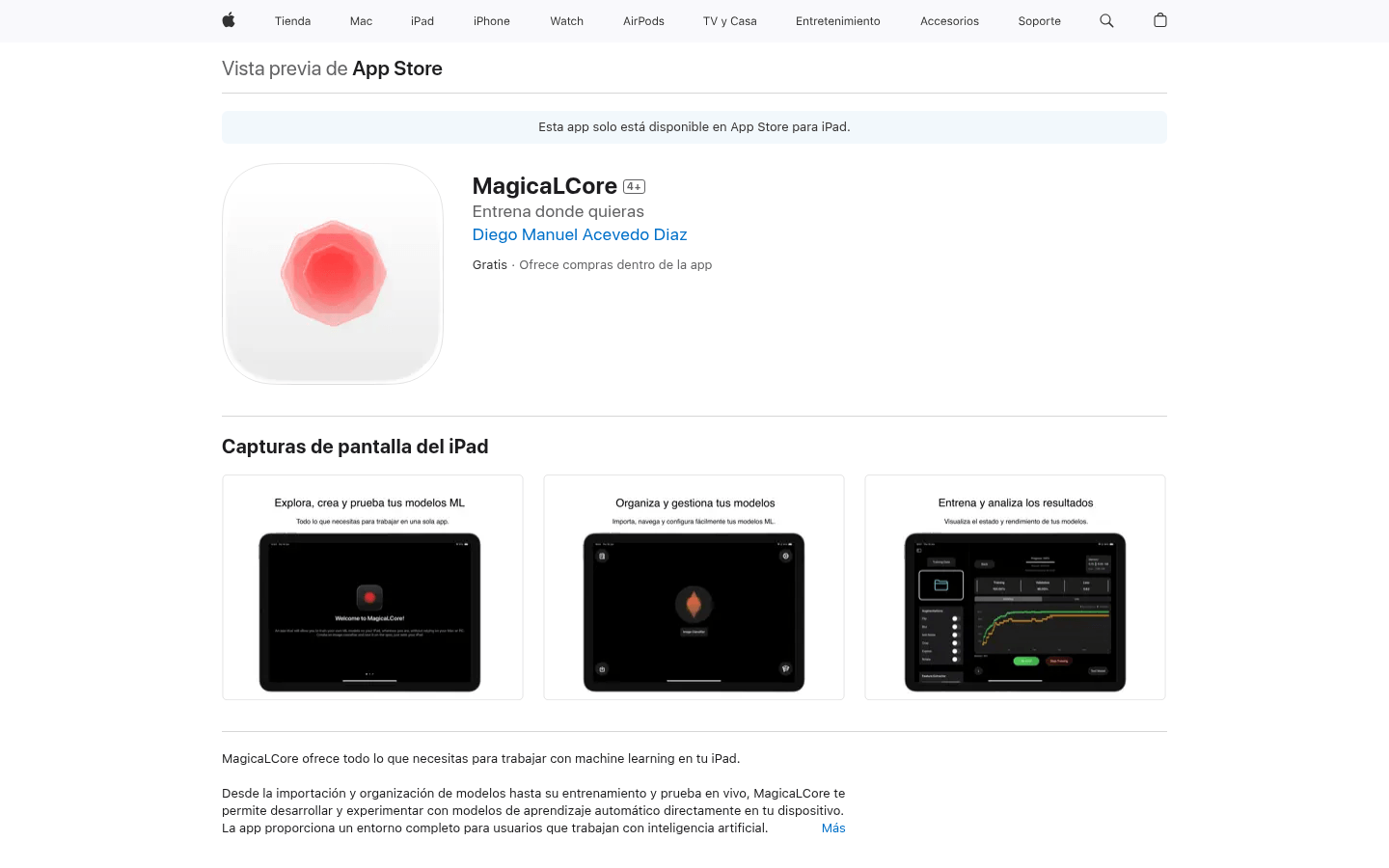
MagicaLCore是一款能够在iPad上进行机器学习工作的应用。用户可以导入、组织、训练和实时测试机器学习模型,直接在设备上开发和实验模型。
Labelbox是一个为AI团队设计的数据工厂,旨在提供构建、运营和数据标注的解决方案。其主要优点包括灵活的标注工具、自动化数据流程、丰富的数据管理功能等。背景信息:Labelbox致力于帮助AI团队提高数据标注效率和模型训练质量,定位于提供全面的数据管理和标注平台。
OpenTrain AI是一个人工智能训练数据市场,可以让您直接雇佣全球经过审核的人工数据专家,使用您喜欢的标注软件。降低成本,保持控制,快速构建高质量的AI训练数据。
Genie Studio 是智元机器人专为具身智能场景打造的一站式开发平台,具备数据采集、模型训练、仿真评测、模型推理的全链路产品能力。它为开发者提供从‘采’到‘训’到‘测’再到‘推’的标准化解决方案,极大地降低了开发门槛,提升了开发效率。该平台通过高效的数据采集、灵活的模型训练、精准的仿真评测和无缝的模型推理,推动了具身智能技术的快速发展和应用。Genie Studio 不仅提供了强大的工具,还为具身智能的规模化落地提供了支持,加速了行业向标准化、平台化、量产化的新阶段跃进。
Awesome-LLM-Post-training 是一个专注于大型语言模型(LLM)后训练方法的资源库。它提供了关于 LLM 后训练的深入研究,包括教程、调查和指南。该资源库基于论文《LLM Post-Training: A Deep Dive into Reasoning Large Language Models》,旨在帮助研究人员和开发者更好地理解和应用 LLM 后训练技术。该资源库免费开放,适合学术研究和工业应用。
ARGO 是一个多平台 AI 客户端,旨在为用户提供强大的人工智能助手,具备自主思考、任务规划和复杂任务处理的能力。其主要优势在于在用户设备上本地运行,确保数据隐私与安全。适合需要高效管理和处理任务的用户群体,支持多种操作系统。永久开源免费。
LLMs.txt生成器是一个由Firecrawl提供支持的在线工具,旨在帮助用户从网站生成用于LLM训练和推理的整合文本文件。它通过整合网页内容,为训练大型语言模型提供高质量的文本数据,从而提高模型的性能和准确性。该工具的主要优点是操作简单、高效,能够快速生成所需的文本文件。它主要面向需要大量文本数据进行模型训练的开发者和研究人员,为他们提供了一种便捷的解决方案。
AI21-Jamba-Large-1.6 是由 AI21 Labs 开发的混合 SSM-Transformer 架构基础模型,专为长文本处理和高效推理而设计。该模型在长文本处理、推理速度和质量方面表现出色,支持多种语言,并具备强大的指令跟随能力。它适用于需要处理大量文本数据的企业级应用,如金融分析、内容生成等。该模型采用 Jamba Open Model License 授权,允许在许可条款下进行研究和商业使用。
MoBA(Mixture of Block Attention)是一种创新的注意力机制,专为长文本上下文的大语言模型设计。它通过将上下文划分为块,并让每个查询令牌学习关注最相关的块,从而实现高效的长序列处理。MoBA 的主要优点是能够在全注意力和稀疏注意力之间无缝切换,既保证了性能,又提高了计算效率。该技术适用于需要处理长文本的任务,如文档分析、代码生成等,能够显著降低计算成本,同时保持模型的高性能表现。MoBA 的开源实现为研究人员和开发者提供了强大的工具,推动了大语言模型在长文本处理领域的应用。
OLMoE 是由 Ai2 开发的开源语言模型应用,旨在为研究人员和开发者提供一个完全开放的工具包,用于在设备上进行人工智能实验。该应用支持在 iPhone 和 iPad 上离线运行,确保用户数据完全私密。它基于高效的 OLMoE 模型构建,通过优化和量化,使其在移动设备上运行时保持高性能。该应用的开源特性使其成为研究和开发新一代设备端人工智能应用的重要基础。
DeepSeek-R1-Distill-Qwen-32B 是由 DeepSeek 团队开发的高性能语言模型,基于 Qwen-2.5 系列进行蒸馏优化。该模型在多项基准测试中表现出色,尤其是在数学、代码和推理任务上。其主要优点包括高效的推理能力、强大的多语言支持以及开源特性,便于研究人员和开发者进行二次开发和应用。该模型适用于需要高性能文本生成的场景,如智能客服、内容创作和代码辅助等,具有广泛的应用前景。
该产品是一个AI驱动的数据科学团队模型,旨在帮助用户以更快的速度完成数据科学任务。它通过一系列专业的数据科学代理(Agents),如数据清洗、特征工程、建模等,来自动化和加速数据科学工作流程。该产品的主要优点是能够显著提高数据科学工作的效率,减少人工干预,适用于需要快速处理和分析大量数据的企业和研究机构。产品目前处于Beta阶段,正在积极开发中,可能会有突破性变化。它采用MIT许可证,用户可以在GitHub上免费使用和贡献代码。
Bespoke Labs专注于提供高质量的定制化数据集服务,以支持工程师进行精确的模型微调。公司由Google DeepMind的前员工Mahesh和UT Austin的Alex共同创立,旨在改善高质量数据的获取,这对于推动领域发展至关重要。Bespoke Labs提供的工具和平台,如Minicheck、Evalchemy和Curator,都是围绕数据集的创建和管理设计的,以提高数据的质量和模型的性能。
OpenEMMA是一个开源项目,复现了Waymo的EMMA模型,提供了一个端到端框架用于自动驾驶车辆的运动规划。该模型利用预训练的视觉语言模型(VLMs)如GPT-4和LLaVA,整合文本和前视摄像头输入,实现对未来自身路径点的精确预测,并提供决策理由。OpenEMMA的目标是为研究人员和开发者提供易于获取的工具,以推进自动驾驶研究和应用。
DRT-o1-14B是一个神经机器翻译模型,旨在通过长链推理来提升翻译的深度和准确性。该模型通过挖掘含有比喻或隐喻的英文句子,并采用多代理框架(包括翻译者、顾问和评估者)来合成长思考的机器翻译样本。DRT-o1-14B基于Qwen2.5-14B-Instruct作为主干进行训练,具有14.8B的参数量,支持BF16张量类型。该模型的重要性在于其能够处理复杂的翻译任务,尤其是在需要深入理解和推理的情况下,提供了一种新的解决方案。
DRT-o1-7B是一个致力于将长思考推理成功应用于神经机器翻译(MT)的模型。该模型通过挖掘适合长思考翻译的英文句子,并提出了一个包含翻译者、顾问和评估者三个角色的多代理框架来合成MT样本。DRT-o1-7B和DRT-o1-14B使用Qwen2.5-7B-Instruct和Qwen2.5-14B-Instruct作为骨干网络进行训练。该模型的主要优点在于其能够处理复杂的语言结构和深层次的语义理解,这对于提高机器翻译的准确性和自然性至关重要。
AMD ROCm™ 6.3是AMD开源平台的一个重要里程碑,引入了先进的工具和优化,以提升在AMD Instinct GPU加速器上的AI、机器学习(ML)和高性能计算(HPC)工作负载。ROCm 6.3旨在增强从创新AI初创企业到HPC驱动行业的广泛客户的开发人员生产力。
MLPerf Client是由MLCommons共同开发的新基准测试,旨在评估个人电脑(从笔记本、台式机到工作站)上大型语言模型(LLMs)和其他AI工作负载的性能。该基准测试通过模拟真实世界的AI任务,提供清晰的指标,以了解系统如何处理生成性AI工作负载。MLPerf Client工作组希望这个基准测试能够推动创新和竞争,确保个人电脑能够应对AI驱动的未来挑战。
Trillium TPU是Google Cloud的第六代Tensor Processing Unit(TPU),专为AI工作负载设计,提供增强的性能和成本效益。它作为Google Cloud AI Hypercomputer的关键组件,通过集成的硬件系统、开放软件、领先的机器学习框架和灵活的消费模型,支持大规模AI模型的训练、微调和推理。Trillium TPU在性能、成本效率和可持续性方面都有显著提升,是AI领域的重要进步。
SPDL(Scalable and Performant Data Loading)是由Meta Reality Labs开发的一种新的数据加载解决方案,旨在提高AI模型训练的效率。它采用基于线程的并行处理,相比传统的基于进程的解决方案,SPDL在普通Python解释器中实现了高吞吐量,并且消耗的计算资源更少。SPDL与Free-Threaded Python兼容,在禁用GIL的情况下,比启用GIL的FT Python实现更高的吞吐量。SPDL的主要优点包括高吞吐量、易于理解的性能、不封装预处理操作、不引入领域特定语言(DSL)、无缝集成异步工具、灵活性、简单直观以及容错性。SPDL的背景信息显示,随着模型规模的增长,对数据的计算需求也随之增加,而SPDL通过最大化GPU的利用,加快了模型训练的速度。
OLMo-2-1124-7B-SFT是由艾伦人工智能研究所(AI2)发布的一个英文文本生成模型,它是OLMo 2 7B模型的监督微调版本,专门针对Tülu 3数据集进行了优化。Tülu 3数据集旨在提供多样化任务的顶尖性能,包括聊天、数学问题解答、GSM8K、IFEval等。该模型的主要优点包括强大的文本生成能力、多样性任务处理能力以及开源的代码和训练细节,使其成为研究和教育领域的有力工具。
Aria-Base-64K是Aria系列的基础模型之一,专为研究目的和继续训练而设计。该模型在长文本预训练阶段后形成,经过33B个token(21B多模态,12B语言,69%为长文本)的训练。它适合于长视频问答数据集或长文档问答数据集的继续预训练或微调,即使在资源有限的情况下,也可以通过短指令调优数据集进行后训练,并转移到长文本问答场景。该模型能够理解多达250张高分辨率图像或多达500张中等分辨率图像,并在语言和多模态场景中保持强大的基础性能。
Foundry AI是一个专注于构建、评估和改进AI代理的平台,旨在提供可靠的结果。该平台通过实时反馈实现持续改进,允许自定义控制人工干预,并进行A/B测试以优化性能。Foundry AI由行业专家构建,与传统自动化相比,它提供了一个更智能的AI管理系统,能够实现更高质量的AI结果,快速有效的改进和智能的人工-AI协作。
Llama-3.1-Tulu-3-8B-SFT是Tülu3模型家族中的一员,这是一个领先的指令遵循模型家族,提供完全开源的数据、代码和配方,旨在为现代后训练技术提供全面的指南。该模型不仅在聊天任务上表现出色,还在MATH、GSM8K和IFEval等多样化任务上展现了卓越的性能。
智谱清流AI开放平台是一个企业级AI智能体开发平台,利用智谱大模型技术,帮助企业快速构建专业级智能体,实现大模型到业务场景的快速应用。平台提供模型服务、智能体构建、数据安全、效果评测和系统集成等功能,支持企业通过内网部署和本地存储保护数据,确保数据安全和知识产权。智谱AI开放平台以其领先的技术、灵活的工作流编排、自主调用企业定义的数据知识和工具,以及成熟的AI原生应用落地经验,成为企业数字化转型的重要助力。
OuteTTS-0.1-350M是一款基于纯语言模型的文本到语音合成技术,它不需要外部适配器或复杂架构,通过精心设计的提示和音频标记实现高质量的语音合成。该模型基于LLaMa架构,使用350M参数,展示了直接使用语言模型进行语音合成的潜力。它通过三个步骤处理音频:使用WavTokenizer进行音频标记化、CTC强制对齐创建精确的单词到音频标记映射、以及遵循特定格式的结构化提示创建。OuteTTS的主要优点包括纯语言建模方法、声音克隆能力、与llama.cpp和GGUF格式的兼容性。
Tencent-Hunyuan-Large(混元大模型)是由腾讯推出的业界领先的开源大型混合专家(MoE)模型,拥有3890亿总参数和520亿激活参数。该模型在自然语言处理、计算机视觉和科学任务等领域取得了显著进展,特别是在处理长上下文输入和提升长上下文任务处理能力方面表现出色。混元大模型的开源,旨在激发更多研究者的创新灵感,共同推动AI技术的进步和应用。
Fish Agent V0.1 3B是一个开创性的语音转语音模型,能够以前所未有的精确度捕捉和生成环境音频信息。该模型采用了无语义标记架构,消除了传统语义编码器/解码器的需求。此外,它还是一个尖端的文本到语音(TTS)模型,训练数据涵盖了700,000小时的多语言音频内容。作为Qwen-2.5-3B-Instruct的继续预训练版本,它在200B语音和文本标记上进行了训练。该模型支持包括英语、中文在内的8种语言,每种语言的训练数据量不同,其中英语和中文各约300,000小时,其他语言各约20,000小时。
π0是一个通用型机器人基础模型,旨在通过实体化训练让AI系统获得物理智能,能够执行各种任务,就像大型语言模型和聊天机器人助手一样。π0通过训练在机器人上的实体经验获得物理智能,能够直接输出低级电机命令,控制多种不同的机器人,并可以针对特定应用场景进行微调。π0的开发代表了人工智能在物理世界应用方面的重要进步,它通过结合大规模多任务和多机器人数据收集以及新的网络架构,提供了迄今为止最有能力、最灵巧的通用型机器人政策。
Decart是一个高效的AI平台,提供了在训练和推理大型生成模型方面的数量级改进。利用这些先进的能力,Decart能够训练基础的生成交互模型,并使每个人都能在实时中访问。Decart的OASIS模型是一个实时生成的AI开放世界模型,代表了实时视频生成的未来。该平台还提供了对1000+ NVIDIA H100 Tensor Core GPU集群进行训练或推理的能力,为AI视频生成领域带来了突破性进展。
ComfyOnline提供了一个在线环境,用于运行ComfyUI工作流,并能够生成API以便于AI应用开发。它无需昂贵的硬件投资,无需复杂的设置或安装,仅按运行时间收费,自动扩展以满足需求,帮助用户轻松部署AI应用。
OMat24是由Meta的FAIR Chemistry团队发布的一系列模型检查点,这些模型在不同的模型大小和训练策略上有所不同。这些模型使用了EquiformerV2架构,旨在推动材料科学领域的研究,通过机器学习模型来预测材料的性质,从而加速新材料的发现和开发。这些模型在公开的数据集上进行了预训练,并提供了不同规模的版本,以适应不同的研究需求。
Aya Expanse 32B是由Cohere For AI开发的多语言大型语言模型,拥有32亿参数,专注于提供高性能的多语言支持。它结合了先进的数据仲裁、多语言偏好训练、安全调整和模型合并技术,以支持23种语言,包括阿拉伯语、中文(简体和繁体)、捷克语、荷兰语、英语、法语、德语、希腊语、希伯来语、印地语、印尼语、意大利语、日语、韩语、波斯语、波兰语、葡萄牙语、罗马尼亚语、俄语、西班牙语、土耳其语、乌克兰语和越南语。该模型的发布旨在使社区基础的研究工作更加易于获取,通过发布高性能的多语言模型权重,供全球研究人员使用。
Llama模型是Meta公司推出的大型语言模型,通过量化技术,使得模型体积更小、运行速度更快,同时保持了模型的质量和安全性。这些模型特别适用于移动设备和边缘部署,能够在资源受限的设备上提供快速的设备内推理,同时减少内存占用。量化Llama模型的开发,标志着在移动AI领域的一个重要进步,使得更多的开发者能够在不需要大量计算资源的情况下,构建和部署高质量的AI应用。
AIxBlock是一个集成平台,使用去中心化的计算资源快速产品化AI模型,具有灵活性和完全的隐私控制。它通过区块链技术,为AI项目提供去中心化的超级计算能力,降低计算成本高达90%,并通过点对点交易减少成本,无需交易费用。AIxBlock还强调数据的隐私和安全性,提供在本地基础设施上运行的平台选项,确保数据和模型的隐私。此外,它还提供了一个无代码的AI生态系统,从概念到商业化,支持整个AI开发旅程。
Spirit LM是一个基础多模态语言模型,能够自由混合文本和语音。该模型基于一个7B预训练的文本语言模型,通过持续在文本和语音单元上训练来扩展到语音模式。语音和文本序列被串联为单个令牌流,并使用一个小的自动策划的语音-文本平行语料库,采用词级交错方法进行训练。Spirit LM有两个版本:基础版使用语音音素单元(HuBERT),而表达版除了音素单元外,还使用音高和风格单元来模拟表达性。对于两个版本,文本都使用子词BPE令牌进行编码。该模型不仅展现了文本模型的语义能力,还展现了语音模型的表达能力。此外,我们展示了Spirit LM能够在少量样本的情况下跨模态学习新任务(例如ASR、TTS、语音分类)。
Liquid Foundation Models (LFMs) 是一系列新型的生成式AI模型,它们在各种规模上都达到了最先进的性能,同时保持了更小的内存占用和更高效的推理效率。LFMs 利用动态系统理论、信号处理和数值线性代数的计算单元,可以处理包括视频、音频、文本、时间序列和信号在内的任何类型的序列数据。这些模型是通用的AI模型,旨在处理大规模的序列多模态数据,实现高级推理,并做出可靠的决策。
Emu3是一套最新的多模态模型,仅通过下一个token预测进行训练,能够处理图像、文本和视频。它在生成和感知任务上超越了多个特定任务的旗舰模型,并且不需要扩散或组合架构。Emu3通过将多模态序列统一到一个单一的transformer模型中,简化了复杂的多模态模型设计,展示了在训练和推理过程中扩展的巨大潜力。
Future AGI是一个自动化AI模型评估平台,通过自动评分AI模型输出,消除了手动QA评估的需求,使QA团队能够专注于更战略性的任务,提高效率和带宽高达10倍。该平台使用自然语言定义对业务最重要的指标,提供增强的灵活性和控制力,以评估模型性能,确保与业务目标的一致性。它还通过整合性能数据和用户反馈到开发过程中,创建了一个持续改进的循环,使AI在每次互动中变得更智能。
1X 世界模型是一种机器学习程序,能够模拟世界如何响应机器人的行为。它基于视频生成和自动驾驶汽车世界模型的技术进步,为机器人提供了一个虚拟模拟器,能够预测未来的场景并评估机器人策略。这个模型不仅能够处理复杂的对象交互,如刚体、掉落物体的影响、部分可观察性、可变形物体和铰接物体,还能够在不断变化的环境中进行评估,这对于机器人技术的发展至关重要。
Weavel是一个AI提示工程师,它通过追踪、数据集管理、批量测试和评估等功能,帮助用户优化大型语言模型(LLM)的应用。Weavel与Weavel SDK结合使用,能够自动记录并添加LLM生成的数据到您的数据集中,实现无缝集成和针对特定用例的持续改进。此外,Weavel能够自动生成评估代码,并使用LLM作为复杂任务的公正裁判,简化评估流程,确保准确、细致的性能指标。
Magic团队开发的超长上下文模型(LTM)能够处理高达100M tokens的上下文信息,这在AI领域是一个重大突破。该技术主要针对软件开发领域,通过在推理过程中提供大量代码、文档和库的上下文,极大地提升了代码合成的质量和效率。与传统的循环神经网络和状态空间模型相比,LTM模型在存储和检索大量信息方面具有明显优势,能够构建更复杂的逻辑电路。此外,Magic团队还与Google Cloud合作,利用NVIDIA GB200 NVL72构建下一代AI超级计算机,进一步推动模型的推理和训练效率。
Zamba2-mini是由Zyphra Technologies Inc.发布的小型语言模型,专为设备端应用设计。它在保持极小的内存占用(<700MB)的同时,实现了与更大模型相媲美的评估分数和性能。该模型采用了4bit量化技术,具有7倍参数下降的同时保持相同性能的特点。Zamba2-mini在推理效率上表现出色,与Phi3-3.8B等更大模型相比,具有更快的首令牌生成时间、更低的内存开销和更低的生成延迟。此外,该模型的权重已开源发布(Apache 2.0),允许研究人员、开发者和公司利用其能力,推动高效基础模型的边界。
Cerebras Inference是Cerebras公司推出的AI推理平台,提供20倍于GPU的速度和1/5的成本。它利用Cerebras的高性能计算技术,为大规模语言模型、高性能计算等提供快速、高效的推理服务。该平台支持多种AI模型,包括医疗、能源、政府和金融服务等行业应用,具有开放源代码的特性,允许用户训练自己的基础模型或微调开源模型。
Datalab 的 AI For Document Intelligence 是一系列用于文档智能处理的AI模型,包括OCR、布局分析、PDF转Markdown等。这些模型代表了文档处理技术的最新发展,易于使用,并且是开源的,可以广泛应用于提高文档处理的效率和准确性。
Mystic Turbo Registry是一款由Mystic.ai开发的高性能AI模型加载器,采用Rust语言编写,专门针对减少AI模型的冷启动时间进行了优化。它通过提高容器加载效率,显著减少了模型从启动到运行所需的时间,为用户提供了更快的模型响应速度和更高的运行效率。
LLM Quality Beefer-Upper是一款旨在通过自动化批评、反思和改进来提升大型语言模型(LLM)响应质量的网站。它采用思维链方法,已被证明是提高LLM质量和准确性的最佳方法。用户可以使用和细化定制和预构建的多代理提示模板,以获得最可靠和高质量的输出。该网站目前使用Claude Sonnet 3.5 API,因为它是市场上最好的LLM。一旦有更优秀的模型出现,它将立即采用,因为提供最高质量的输出是该应用的唯一目标。
UbiOps是一个AI基础设施平台,帮助团队快速运行他们的AI和机器学习工作负载作为可靠和安全的微服务,而无需改变现有的工作流程。它提供了零DevOps的超快速管道、优化的计算资源、支持LLMs和CV模型等功能。UbiOps支持混合和多云工作负载编排,允许在私有或公共云环境中部署模型,确保数据和模型始终留在用户的环境中。此外,UbiOps还提供了内置的安全特性,如端到端加密、安全数据存储和访问控制,帮助企业符合相关法规。
GPUDeploy是一个提供低成本按需GPU资源的网站,专为机器学习和人工智能任务设计,用户可以立即启动预配置的GPU实例,以支持复杂的计算任务。该产品主要优点包括低成本、即时可用性以及预配置的便利性,适合需要快速部署机器学习模型和算法的企业和个人。
Arcee Spark是一个7B参数的语言模型,它在紧凑的包体中提供高性能,证明小型模型也能与大型模型相媲美。它是7B-15B范围内得分最高的模型,并且在MT-Bench基准测试中超越了GPT 3.5和Claude 2.1等更大模型。它适用于实时应用、边缘计算场景、成本效益高的AI实施、快速原型设计和增强数据隐私的本地部署。
Source.Plus是一个专业的AI训练数据搜索平台,它允许用户通过高级搜索操作符来精确地搜索、筛选和整理所需的数据集。它支持多种数据来源,包括Wikimedia Commons、NMNH - Botany Dept.等,提供广泛的图像和文档资源。平台还具备文件上传功能,使用户能够进一步自定义和丰富自己的数据集。Source.Plus的主要优点包括其强大的搜索能力、数据来源的多样性以及对AI训练数据的特别优化。
Samba-1 Turbo是一个提供AI模型选择和应用的平台,它允许开发者通过免费的开发者推理服务来试用、比较和评估Samba-1中各种专家模型。此外,平台还提供一些构建在Samba-1之上的演示业务应用程序,以及开源语言专家SambaLingo。Samba-1 Turbo旨在为开发者提供强大的工具,以简化AI模型的集成和应用过程。
Refuel LLM-2 是一款为数据标注、清洗和丰富而设计的先进语言模型。它在约30种数据标注任务的基准测试中超越了所有现有的最先进语言模型,包括GPT-4-Turbo、Claude-3-Opus和Gemini-1.5-Pro。Refuel LLM-2 旨在提高数据团队的工作效率,减少在数据清洗、规范化、标注等前期工作上的手动劳动,从而更快地实现数据的商业价值。
Mazaal是一个无代码AI平台,可以将您的数据转化为强大的AI模型,无需编写任何代码。它提供了多种预训练模型,可以用于优化生产、管理库存、预测需求等。Mazaal可以自动化工作流程,提高效率,并帮助您解决业务中的各种问题。
TensorDock 是一个为需要无可妥协可靠性的工作负载而构建的专业云服务提供商。它提供多种 GPU 服务器选项,包括 NVIDIA H100 SXMs,以及针对深度学习、AI 和渲染的最具成本效益的虚拟机基础设施。TensorDock 还提供全托管容器托管服务,具备操作系统级监控、自动扩展和负载均衡功能。此外,TensorDock 提供世界级别的企业支持,由专业人员提供服务。
AI快站是一个为AI开发者设计的服务平台,提供HuggingFace模型的免费加速下载,解决大模型下载缓慢和断开的问题,支持高达4M/s的下载速度,大幅减少等待时间,提高开发效率。
Portkey是一个LLMOps平台,帮助企业更快地开发、发布、维护和迭代生成式AI应用和功能。通过Portkey的可观测性套件和AI网关,数百个团队可以发布可靠、高效和快速的应用。价格根据需求定制。
ragobble是一个利用人工智能将音频文件转换为文档的平台。通过将在线视频和音频信息转换为可向量化的RAG文档,用户可以将生成的文档应用于其LLM实例或服务器,为其模型提供最新的知识。ragobble提供了一种快速简单的方式,将视频音频转换为文档,使用户可以为模型提供最新的信息,从而可以推断出仅在几秒钟前记录的数据。
KPU (Knowledge Processing Unit) 是一种专有的丰富框架,利用了大型语言模型的强大功能,并将推理和数据处理分离在一个能够解决复杂任务的开放系统中。它由推理引擎、执行引擎和虚拟上下文窗口三个主要组件组成。推理引擎负责设计解决用户任务的分步计划,利用了可插拔的大型语言模型(目前广泛测试了 GPT-4 Turbo)。执行引擎接收来自推理引擎的命令并执行,结果作为反馈发送回推理引擎进行重新规划。虚拟上下文窗口管理推理引擎和执行引擎之间的数据和信息输入输出。这种分离推理和执行的架构使大型语言模型能专注于推理,避免了谎言、数据处理或检索最新信息等缺陷。KPU 旨在提升任务质量和性能,解决大数据量、多模态内容、开放性问题解决和交互性等挑战。
Aipify是您AI动力API需求的最佳选择。通过Aipify,您可以获得结构化的响应、强大的性能以及安全、快速、实惠、可扩展的访问最新的AI模型,包括GPT-4,以增强您的应用程序功能。
该项目专注于实现实时的全身人对人形机器人的遥操作,旨在通过学习人类的动作和行为来控制机器人。
Answer.AI致力于通过基础研究的突破来开发实用的终端用户产品。该实验室发布了一个开源系统,基于FSDP和QLoRA,允许用户在家中使用两个24GB GPU训练一个70亿参数的语言模型。此外,Answer.AI还发布了关于历史上最伟大的研发实验室的历史分析文章,以及对实验室的研究议程和背景的介绍。
Qualcomm AI Hub提供由高通优化和验证的AI模型,支持多种设备和平台。所有模型都针对高通AI引擎的硬件加速进行了优化,利用CPU、GPU和NPU的所有计算核心。
iGOT.ai是一个零编码GPT开发平台,可帮助用户无需编程就可以构建、定义、探索和执行GPT模型,从而简化AI引擎的创建。它提供了一个直观的界面,用户可以通过自然语言描述问题和解决方案,平台会自动将其转换成GPT可以理解的推理对象,然后执行任务并审核结果,确保得到最优的输出。主要功能包括语句探索、推理对象创建、用户测试、LLM任务执行等。适用于各行各业将专业知识自动化的企业用户。
Athina AI是一个用于监控和调试LLM(大型语言模型)模型的工具。它可以帮助你发现和修复LLM模型在生产环境中的幻觉和错误,并提供详细的分析和改进建议。Athina AI支持多种LLM模型,可以配置定制化的评估来满足不同的使用场景。你可以通过Athina AI来检测错误的输出、分析成本和准确性、调试模型输出、探索对话内容以及比较不同模型的性能表现等。
Ramen AI是一款现代化的工具集,用于构建、测试和部署基于LLM的内容分类应用。它提供完整的AI工具集,让您能够轻松构建、评估、部署和监控内容分类。Ramen AI支持灵活的分类管理,可即时进行测试,以获得快速准确的结果。它还提供多种分类方法,为您选择最佳的分类方式。您还可以使用Ramen AI的API,将分类应用集成到您的代码中,甚至可以在Google表格中使用Ramen AI的公式。Ramen AI还提供AI生成的测试数据集,节省手动生成验证数据集的时间。它还可以监控和报告分类应用的使用情况,帮助您了解变化趋势。Ramen AI适用于各种分类应用场景,包括医疗、金融、零售、法律、客服、教育和研究等。
Lumino是一个机器学习模型训练平台,可以降低50-70%的成本。用户可以在其广泛的计算资源网络上训练机器学习模型,同时也可以供应计算资源。该平台通过去除中间商(如AWS、GCP和Azure)并直接连接计算资源提供商,显著降低成本。所有模型和训练集都可以追溯到经过加密验证的证据,实现完全的问责制。此外,Lumino采用去中心化和无需许可的网络结构,阻止集中式云平台和专制国家滥用权力。
Together AI 提供最快速、最高效的工具和基础设施,帮助用户构建通用 AI 模型。与我们专业的 AI 团队合作,致力于您的成功。
BafCloud是一个一体化云平台,简化AI开发流程。我们提供单一API访问,包含大量的AI模型和代理人。您可以轻松管理、调优和部署大规模语言模型,使用用户友好的界面。您可以快速构建适用于任何用例的定制AI代理人,确保无缝集成和协作。加入BafCloud,加速AI项目的头脑风暴、构建、集成和部署。
Appen是一个提供专业工具和专业知识的公司,致力于构建更美好的未来。我们的产品帮助客户构建创新的人工智能应用,提供高质量的数据标注、数据采集和数据处理服务。我们的优势是丰富的经验、灵活的解决方案和可靠的合作关系。我们的定价根据项目的复杂性和规模而定。Appen的定位是成为创新世界级AI应用的首选合作伙伴。
XSpecs是一款AI驱动的单一源软件平台,能够从高层需求中生成明确的规范,并直接部署为GraphQL本机后端代码,实现在几小时内完成几周的软件开发。它能帮助开发团队更快地交付高质量的软件。
Algomax简化LLM和RAG模型的评估,优化提示开发,并通过直观的仪表板提供对定性指标的独特洞察。我们的评估引擎精确评估LLM,并通过广泛测试确保可靠性。平台提供了全面的定性和定量指标,帮助您更好地理解模型的行为,并提供具体的改进建议。Algomax的用途广泛,适用于各个行业和领域。
Llog是一个协作监控LLM应用程序的终端到终端平台,为团队提供洞察力,了解他们的LLM应用程序在生产后的情况。团队成员可以在一个协作空间中审查日志、标记重要事项并分配任务。无论团队规模多大,都可以在任何价格层级下享受无限的席位支持。通过直接观察用户交互,全面了解终端用户的行为,并永远不再担心LLM实际上在说什么。使用我们简单的格式,进行几个API请求,即可立即在我们的平台上查看结果。
Openlayer是一个评估工具,适用于您的开发和生产流程,帮助您自信地发布高质量的模型。它提供强大的测试、评估和可观察性,无需猜测您的提示是否足够好。支持LLMs、文本分类、表格分类、表格回归等功能。通过实时通知让您在AI模型失败时获得通知,让您自信地发布。
Klu是一款全能的LLM应用平台,可以在Klu上快速构建、评估和优化基于LLM技术的应用。它提供了多种最先进的LLM模型选择,让用户可以根据自己的需求进行选择和调整。Klu还支持团队协作、版本管理、数据评估等功能,为AI团队提供了一个全面而便捷的开发平台。
Pulze.ai是一站式LLM开发自动化平台,提供单一API,将所有最佳LLM插入您的产品,并在几分钟内简化您的LLM功能开发。Pulze.ai的API遵循LLMOps最佳实践,并使您的团队轻松使用。Pulze.ai允许您一次测试所有最佳模型,以加速开发。您可以在Pulze.ai内动态控制预算和成本目标,并在扩展时保护您的利润。Pulze.ai还提供企业级安全性,以管理所有用户数据的数据隐私和安全性。Pulze.ai提供了多个功能点,如上传数据源、优化结果、一键部署、实时跟踪和版本控制等。
GPTs Hunt是一个为用户寻找适合各种需求的GPT(生成对抗网络)的平台。它提供了多种GPT模型供用户选择,包括OpenAI的ChatGPT4和DALLE3等。用户可以根据自己的需求浏览不同的GPT模型,了解它们的功能、优势、定价和定位等信息,并选择最适合自己的GPT模型。
Replicate是一款机器学习模型运行和部署的工具,无需自行配置环境,可以快速运行和部署机器学习模型。Replicate提供了Python库和API接口,支持运行和查询模型。社区共享了成千上万个可用的机器学习模型,涵盖了文本理解、视频编辑、图像处理等多个领域。使用Replicate和相关工具,您可以快速构建自己的项目并进行部署。
Qlik AutoML是一款为分析团队提供无代码、自动化机器学习的工具。它能够快速生成模型、进行预测和决策规划。用户可以轻松创建机器学习实验,识别数据中的关键因素并训练模型。同时,它还支持完全可解释的AI,可以展示预测的原因和影响。用户可以将数据发布或直接集成到Qlik Sense应用中进行全交互式分析和模拟。
Aporia是一款ML模型管理的可观测性平台,通过一个综合性的仪表盘监控您的ML模型,以确保最佳的机器学习模型性能。它提供了可解释性、监控、根本原因分析、LLM可观测性、Gen AI和Guardrails等功能。Aporia的平台功能强大,支持数据集成、定制化、大数据支持和安全与隐私等特点。
CentML 是一个高效、节约成本的 AI 模型训练和部署平台。通过使用 CentML,您可以提升 GPU 效率、降低延迟、提高吞吐量,实现计算的高性价比和强大性能。
Data Sherlocks是一款强大的数据分析和生成AI工具,帮助用户发现数据的潜力,并提供自己的生成AI模型。它提供多种功能和优势,包括数据可视化、模型训练、生成AI应用等。定价灵活,适用于个人和企业用户。
Contentable.ai是一个综合的AI模型测试平台,可以帮助用户快速测试、原型和共享AI模型。它提供了一套完整的工具和功能,使用户能够轻松构建和部署AI模型,从而提高工作效率。
promptfoo是一个用于评估LLM prompt质量和进行测试的库。它能够帮助您创建测试用例,设置评估指标,并与现有的测试和CI流程集成。promptfoo还提供了一个Web Viewer,让您可以轻松地比较不同的prompt和模型输出。它被用于服务超过1000万用户的LLM应用程序。
Parea AI是一个LLM平台,帮助开发者通过严格的测试和版本控制来改进LLM应用的性能。它提供了实验不同提示版本、评估和比较不同测试用例的提示、一键优化提示、分享等功能。通过Parea,您可以优化AI开发工作流程,提高生产力。
Lepton AI是一款以开发者为中心的AI平台,提供高效、可扩展、分钟级运行的AI应用程序。它可以帮助用户在不到几分钟的时间内构建和运行AI应用程序,而不需要担心基础设施和规模问题。Lepton AI的优势在于其易用性、可扩展性和灵活性,使其成为开发人员和企业的首选AI平台。定价方案灵活,适合不同规模和需求的用户。
Domino Data Lab是一个统一、协作、管控的端到端企业级AI平台。该平台可以在任何环境下构建、部署和管理AI模型,访问任何环境下的数据、工具、计算和项目。Domino Data Lab通过建立最佳实践、跟踪生产中的模型以及加强治理,帮助企业加速AI应用、扩大AI规模,同时确保治理并降低成本。
DataRobot 是面向企业的开放 AI 平台,支持全面的 AI 生命周期管理,包括自动机器学习、模型监控以及 AI 管控。该平台支持在云和混合环境下的可扩展、可再生的 AI,可应用于各行各业的预测建模和生成式 AI,帮助企业快速实施 AI 并产生价值。
AutoDL为您提供专业的GPU租用服务,秒级计费、稳定好用,高规格机房,7×24小时服务。您可以弹性部署AI模型,实现震撼上线,同时提供算法复现社区,一键复现经典算法。
四维时代人工智能技术开放平台通过深度学习算法,提供小物体建模、大场景建模、SLAM视觉追踪、人工智能视觉识别等数字化服务,实现数字世界与实体世界的高效连接。
Pezzo 是一款开发者第一的 LLMOps 平台,可以在几分钟内交付有影响力的基于人工智能的软件,而无需在质量上妥协。无缝交付、监控、测试和迭代,不会分心。Pezzo 拥有强大的功能,可以加速您的 AI 操作,让您专注于重要事项。
Query Vary提供开发人员设计、测试和优化提示的工具,确保可靠性、降低延迟并优化成本。它具有强大的功能,包括比较不同的LLM模型、跟踪成本、延迟和质量、版本控制提示、将调优的LLM直接嵌入JavaScript等。Query Vary适用于个人开发者、初创公司和大型企业,提供灵活的定价计划。
Abacus.AI是全球首个端到端AI平台,为常见的企业应用场景实现实时的大规模深度学习。通过我们先进的MLOps平台,您可以使用自己的模型或使用我们的神经网络技术创建高度准确的模型,并在各种应用场景中进行操作,包括预测、个性化、视觉、异常检测和NLP等。
ModularMind是一款无代码AI构建器,提供强大的人工智能功能,包括自然语言处理、图像识别、机器学习等。它能够帮助用户快速构建AI模型,无需编码。ModularMind还提供灵活的定价方案,适用于个人用户和企业用户。它定位于帮助用户解决AI开发难题,提高工作效率。
Gretel.ai是一款为开发者打造的合成数据平台。通过使用Gretel的API,您可以生成匿名和安全的合成数据,以便在保护隐私的同时更快地进行创新。通过训练生成式AI模型,验证模型和用例的质量和隐私分数,以及按需生成所需数量的数据,Gretel.ai使生成合成数据变得简单易用。Gretel的Python库使您可以在几行代码内生成合成数据。您还可以使用Gretel控制台无需编写代码即可开始生成合成数据。
AI工作室提供企业级AI和机器学习工具,帮助企业进行数字化转型,实时应用洞察力,辅助重要的业务决策。
数据科学家助手是您的完整MLOps、监控和AI质量与治理解决方案。它自动检测准确性、数据大小、模型漂移、运行时间、调度等的变化和趋势。通过提供统一的视图和关键指标,您可以全面了解您的机器学习环境。它还可以跟踪监控模型性能和数据漂移,以便快速识别准确性下降和数据质量变化。无需设置或等待基础架构配置,通过简单的代码集成,您就可以完全控制您发送的内容。您可以配置自定义警报和通知,以及可视化项目间的趋势和相关性。成为α用户即可获得免费访问。
探索 生产力 分类下的其他子分类
1361 个工具
904 个工具
767 个工具
619 个工具
607 个工具
431 个工具
406 个工具
398 个工具
模型训练与部署 是 生产力 分类下的热门子分类,包含 123 个优质AI工具