共找到 82 个AI工具
点击任意工具查看详细信息
Huxe是一款将日常信息转化为个性化音频情报的产品。其重要性在于为用户提供了一种便捷、高效的信息获取方式,让用户在无法看屏幕的场景下也能轻松获取所需信息。主要优点包括个性化定制、互动性强、能将各种问题转化为音频解释等。产品背景可能是为了满足人们在快节奏生活中对便捷信息获取的需求。价格信息未提及,从内容来看可能是免费使用。产品定位为帮助用户在通勤、锻炼、休息等场景下,无需长时间滚动屏幕就能及时获取感兴趣的信息。
Katalog是一个通过AI语音播报文章的工具。它利用超逼真的AI声音播报您保存的文章,提供顶级的听取体验。Katalog还在公共测试阶段免费使用,未来可能会推出免费和付费版本。
FlowSpeech是一个免费的 AI 播客生成器,利用最新的语音合成技术将文本转换为自然人声,适合各种用户需求。它支持多种格式的输入,包括 PDF、TXT 等,方便用户快速获取信息。提供多种订阅选项,帮助创作者更高效地制作播客。
Notigo是一款AI实时会议摘要生成器,能够自动生成会议摘要,帮助用户不再错过重要内容。其主要优点包括高质量的笔记、结构化的内容、精确的摘要、多语言支持等。
Spark-TTS 是一种基于大语言模型的高效文本到语音合成模型,具有单流解耦语音令牌的特性。它利用大语言模型的强大能力,直接从代码预测的音频进行重建,省略了额外的声学特征生成模型,从而提高了效率并降低了复杂性。该模型支持零样本文本到语音合成,能够跨语言和代码切换场景,非常适合需要高自然度和准确性的语音合成应用。它还支持虚拟语音创建,用户可以通过调整参数(如性别、音高和语速)来生成不同的语音。该模型的背景是为了解决传统语音合成系统中效率低下和复杂性高的问题,旨在为研究和生产提供高效、灵活且强大的解决方案。目前,该模型主要面向学术研究和合法应用,如个性化语音合成、辅助技术和语言研究等。
Llasa是一个基于Llama框架的文本到语音(TTS)基础模型,专为大规模语音合成任务设计。该模型利用16万小时的标记化语音数据进行训练,具备高效的语言生成能力和多语言支持。其主要优点包括强大的语音合成能力、低推理成本和灵活的框架兼容性。该模型适用于教育、娱乐和商业场景,能够为用户提供高质量的语音合成解决方案。目前该模型在Hugging Face上免费提供,旨在推动语音合成技术的发展和应用。
LLaDA是一种新型的扩散模型,通过扩散过程生成文本,与传统的自回归模型不同。它在语言生成的可扩展性、指令遵循、上下文学习、对话能力和压缩能力等方面表现出色。该模型由中国人民大学和蚂蚁集团的研究人员开发,具有8B的规模,完全从零开始训练。其主要优点是能够通过扩散过程灵活地生成文本,支持多种语言任务,如数学问题解答、代码生成、翻译和多轮对话等。LLaDA的出现为语言模型的发展提供了新的方向,尤其是在生成质量和灵活性方面。
Lemonfox.ai Text-to-Speech API 是一款专注于文本转语音(TTS)的API服务。它利用先进的AI技术,能够快速将文本转换为自然流畅的语音,支持多种语言和口音,适用于多种场景,如语音播报、有声读物制作等。其主要优点包括低成本、高质量、易于集成,能够帮助企业或开发者快速实现语音功能,提升用户体验。该产品定位为面向企业和开发者的高效、经济的TTS解决方案,价格合理,提供免费试用,性价比高。
IndexTTS 是一种基于 GPT 风格的文本到语音(TTS)模型,主要基于 XTTS 和 Tortoise 进行开发。它能够通过拼音纠正汉字发音,并通过标点符号控制停顿。该系统在中文场景中引入了字符-拼音混合建模方法,显著提高了训练稳定性、音色相似性和音质。此外,它还集成了 BigVGAN2 来优化音频质量。该模型在数万小时的数据上进行训练,性能超越了当前流行的 TTS 系统,如 XTTS、CosyVoice2 和 F5-TTS。IndexTTS 适用于需要高质量语音合成的场景,如语音助手、有声读物等,其开源性质也使其适合学术研究和商业应用。
ElevenReader Publishing 是由 ElevenLabs 推出的创新平台,利用 AI 音频模型将书籍转化为高质量有声书。它解决了传统有声书制作成本高、流程复杂的问题,为作者提供了一个快速、免费且全球分发的解决方案。该平台支持多种文件格式导入,用户可以预览音频并选择喜欢的 AI 语音。此外,它还提供听众报告和分析功能,帮助作者更好地了解受众。其主要优点是零成本、快速生成和全球分发,适合独立作者和出版商。
ElevenLabs Studio 是一个专注于音频内容创作的平台,利用先进的人工智能技术,能够将文本内容转化为高质量的音频。其主要优点包括支持多种文件格式、提供丰富的语音库、能够根据情感和上下文调整语音表达等。该平台适用于有声读物制作、播客创作等场景,能够帮助创作者高效地生成音频内容,提升创作效率和质量。其定价策略可能因用户需求和使用场景而异,具体价格可参考官网的定价页面。
该产品是一个 Chrome 扩展程序,旨在改善 ChatGPT 的朗读功能。通过显示一个音频播放器,用户可以更方便地控制朗读过程,如暂停、快进等。它主要面向视力不佳或喜欢听读的用户,帮助他们更高效地使用 ChatGPT。该产品是开源的,用户可以选择安装扩展程序或手动将代码集成到自己的脚本管理器中。其免费的特性使其具有较高的可访问性。
Zonos-v0.1-hybrid 是由 Zyphra 开发的一款开源文本转语音模型,它能够根据文本提示生成高度自然的语音。该模型经过大量英语语音数据训练,采用 eSpeak 进行文本归一化和音素化,再通过变换器或混合骨干网络预测 DAC 令牌。它支持多种语言,包括英语、日语、中文、法语和德语,并且可以对生成语音的语速、音调、音频质量和情绪等进行精细控制。此外,它还具备零样本语音克隆功能,仅需 5 到 30 秒的语音样本即可实现高保真语音克隆。该模型在 RTX 4090 上的实时因子约为 2 倍,运行速度较快。它还配备了易于使用的 gradio 界面,并且可以通过 Docker 文件简单安装和部署。目前,该模型在 Hugging Face 上提供,用户可以免费使用,但需要自行部署。
TurboTTS 是一款基于先进人工智能技术的文本转语音工具。它能够将书面文本快速转化为自然、逼真的语音,支持多达70种语言和300多种真实语音类型。该技术的主要优点在于其高质量的语音输出、简单易用的界面以及快速高效的内容生成能力。其背景信息显示,该平台已被全球超过228,000名创作者使用,每天处理超过5,000万条配音文本,提供99.9%的正常运行时间保证和98%的用户满意度。TurboTTS 提供免费和付费两种计划,适合个人和专业用户。
Sonofa 是一款基于人工智能技术的产品,能够将各种形式的阅读内容(如网页、PDF文件、图片中的文字)转化为播客形式的音频内容。这种技术利用了先进的文本转语音(TTS)和自然语言处理(NLP)能力,将文字内容转化为自然流畅的语音,让用户能够在不阅读的情况下获取信息。该产品的主要优点是极大地提高了信息获取的灵活性和效率,尤其适合那些在通勤、锻炼或休闲时无法阅读的人群。Sonofa 的背景信息显示,它旨在通过创新的方式帮助用户更好地利用碎片化时间,提升个人学习和工作效率。目前,Sonofa 提供的服务可能是基于订阅模式的付费服务,具体价格和定位尚未明确。
Kokoro TTS是一款专注于文本转语音的AI模型,其主要功能是将文本内容转换为自然流畅的语音输出。该模型基于StyleTTS 2架构,拥有8200万参数,能够在保持高质量语音合成的同时,提供高效的性能和较低的资源消耗。其多语言支持和可定制的语音包使其能够满足不同用户在多种场景下的需求,如制作有声读物、播客、培训视频等,尤其适合教育领域,帮助提升内容的可访问性和吸引力。此外,Kokoro TTS是开源的,用户可以免费使用,这使得它在成本效益上具有显著优势。
Hailuo AI Audio利用先进的语音合成技术,将文本转换为自然流畅的语音。其主要优点是能够生成高质量、富有表现力的语音,适用于多种场景,如有声读物制作、语音播报等。该产品定位为专业级音频合成工具,目前提供限时免费体验,旨在为用户提供高效、便捷的语音生成解决方案。
Audiblez是一个利用Kokoro高质量语音合成技术,将普通电子书(.epub格式)转换为.m4b格式有声书的工具。它支持多种语言和声音,用户可以通过简单的命令行操作完成转换,极大地丰富了电子书的阅读体验,尤其适合在开车、运动等不方便阅读的场景下使用。该工具由Claudio Santini在2025年开发,遵循MIT许可证免费开源。
nijivoiceにじボイス是一个利用人工智能技术实现的语音生成平台,用户可以通过选择不同的角色和输入文本来生成富有情感的语音。这项技术的重要性在于它能够提供个性化的声音,满足从娱乐到商业的多种需求,并且操作简便,易于上手。产品背景信息显示,にじボイス提供了多种声音选择,适用于不同的场景,包括VTuber、虚拟角色、企业介绍视频、产品宣传、教育内容等。价格方面,にじボイス提供免费计划以及多种付费计划,以适应不同用户的需求。
Flash是ElevenLabs最新推出的文本转语音(Text-to-Speech, TTS)模型,它以75毫秒加上应用和网络延迟的速度生成语音,是低延迟、会话型语音代理的首选模型。Flash v2仅支持英语,而Flash v2.5支持32种语言,每两个字符消耗1个信用点。Flash在盲测中持续超越了同类超低延迟模型,是速度最快且具有质量保证的模型。
ChatGPT Podcast Generator是一个利用人工智能技术,帮助用户将文本内容快速转换成播客节目的平台。它通过AI声音、音频编辑器、协作功能等,使得内容创作者、市场营销人员和有故事要分享的个人能够轻松制作出高质量的播客内容。该产品以其易用性、高效性和无需专业录音设备的特点,满足了快节奏数字媒体环境下对音频内容的需求。
CosyVoice 2是由阿里巴巴集团的SpeechLab@Tongyi团队开发的语音合成模型,它基于监督离散语音标记,并结合了两种流行的生成模型:语言模型(LMs)和流匹配,实现了高自然度、内容一致性和说话人相似性的语音合成。该模型在多模态大型语言模型(LLMs)中具有重要的应用,特别是在交互体验中,响应延迟和实时因素对语音合成至关重要。CosyVoice 2通过有限标量量化提高语音标记的码本利用率,简化了文本到语音的语言模型架构,并设计了块感知的因果流匹配模型以适应不同的合成场景。它在大规模多语言数据集上训练,实现了与人类相当的合成质量,并具有极低的响应延迟和实时性。
OmniAudio-2.6B是一个2.6B参数的多模态模型,能够无缝处理文本和音频输入。该模型结合了Gemma-2B、Whisper turbo和一个自定义投影模块,与传统的将ASR和LLM模型串联的方法不同,它将这两种能力统一在一个高效的架构中,以最小的延迟和资源开销实现。这使得它能够安全、快速地在智能手机、笔记本电脑和机器人等边缘设备上直接处理音频文本。
AI Podcast Generator是一个在线服务,能够将PDF文件和网页内容快速转换成高质量的音频格式,使用专业的AI语音和可定制的说话风格,以实现完美的内容传递。这项技术的重要性在于它极大地提高了内容的可访问性和多样性,使得信息可以通过音频形式快速传播,特别适合需要将文本内容转化为音频以满足不同场景需求的用户。产品背景信息显示,它提供了快速处理、高音质输出和企业级解决方案,价格方面,提供了不同级别的订阅计划,以满足不同用户的需求。
Auralis是一个文本到语音(TTS)引擎,能够将文本快速转换为自然语音,支持语音克隆,并且处理速度极快,可以在几分钟内处理完整本小说。该产品以其高速、高效、易集成和高质量的音频输出为主要优点,适用于需要快速文本到语音转换的场景。Auralis基于Python API,支持长文本流式处理、内置音频增强、自动语言检测等功能。产品背景信息显示,Auralis由AstraMind AI开发,旨在提供一种实用于现实世界应用的文本到语音解决方案。产品价格未在页面上明确标注,但代码库在Apache 2.0许可下发布,可以免费用于项目中。
PlayNote是一款利用尖端AI语音合成技术,将各种文件和数据转换成音频创作的产品。它支持多种文件格式,包括PDF、CSV、TXT等文档,以及PNG、JPEG等图片格式,还有MP4、MOV等视频格式,以及WAV、MP3等音频格式。用户可以上传文件,PlayNote会将文件内容转化为音频,方便用户在各种场合下收听。这项技术的重要性在于它能够提高信息的可访问性,特别是对于视觉障碍人士或者在无法阅读的情况下需要获取信息的用户。PlayNote的背景信息显示,它是由PlayAI提供的,旨在通过技术创新提升工作效率和生活质量。关于价格,用户可以访问Pricing页面了解更多详情。
offmute是一款利用大型语言模型(LLM)进行会议转录和角色识别的智能工具。它通过分析音频和视频内容,将会议对话转换成文本,同时识别不同的发言者。该产品支持多种处理层级,从经济型到高级处理选项,满足不同用户的需求。它还能生成包含关键点、行动项和参与者资料的结构化报告,提高会议内容的可检索性和可操作性。
AI Voice Lab免费 AI 文字转语音神器是一个利用最新的类GPT AI语音模型技术,提供超级逼真的配音结果,支持20+种语言和100+种声音,每天提供免费使用次数,适用于视频、音频制作等多种场景,提高内容吸引力。
Read To Me是一个在线服务,它使用户能够将PDF文件转换成音频格式,从而在各种设备上收听,提高信息获取的便捷性和效率。这项技术的主要优点包括一键转换、随时随地的收听体验、提升生产力、简单透明的定价、清晰的音质和安全的文件处理。产品背景信息显示,Read To Me旨在减少长时间盯着屏幕的需求,通过音频形式让人们在通勤、锻炼或做家务时也能学习。价格方面,Read To Me采用按文件付费的方式,没有隐藏费用和重复订阅费用。
OuteTTS是一个使用纯语言建模方法生成语音的实验性文本到语音模型。它的重要性在于能够通过先进的语言模型技术,将文本转换为自然听起来的语音,这对于语音合成、语音助手和自动配音等领域具有重要意义。该模型由OuteAI开发,提供了Hugging Face模型和GGUF模型的支持,并且可以通过接口进行语音克隆等高级功能。
OuteTTS-0.1-350M是一款基于纯语言模型的文本到语音合成技术,它不需要外部适配器或复杂架构,通过精心设计的提示和音频标记实现高质量的语音合成。该模型基于LLaMa架构,使用350M参数,展示了直接使用语言模型进行语音合成的潜力。它通过三个步骤处理音频:使用WavTokenizer进行音频标记化、CTC强制对齐创建精确的单词到音频标记映射、以及遵循特定格式的结构化提示创建。OuteTTS的主要优点包括纯语言建模方法、声音克隆能力、与llama.cpp和GGUF格式的兼容性。
Fish Agent V0.1 3B是一个开创性的语音转语音模型,能够以前所未有的精确度捕捉和生成环境音频信息。该模型采用了无语义标记架构,消除了传统语义编码器/解码器的需求。此外,它还是一个尖端的文本到语音(TTS)模型,训练数据涵盖了700,000小时的多语言音频内容。作为Qwen-2.5-3B-Instruct的继续预训练版本,它在200B语音和文本标记上进行了训练。该模型支持包括英语、中文在内的8种语言,每种语言的训练数据量不同,其中英语和中文各约300,000小时,其他语言各约20,000小时。
文字转语音工具是一款在线服务产品,它能够将文本内容转换成自然流畅的语音输出,支持74种不同的语言和318种不同的声音风格。这项技术的应用场景广泛,包括视频配音、有声读物制作、公告通知、出海营销和外语学习等。产品的主要优点包括支持多语言、多声音选择、无需下载安装、不限使用次数和时长,且完全免费。它为内容创作者、营销人员、教育工作者和语言学习者提供了极大的便利。
VALL-E 2 是微软亚洲研究院推出的一款语音合成模型,它通过重复感知采样和分组编码建模技术,大幅提升了语音合成的稳健性与自然度。该模型能够将书面文字转化为自然语音,适用于教育、娱乐、多语言交流等多个领域,为提高无障碍性、增强跨语言交流等方面发挥重要作用。
Url to Text Converter是一个利用人工智能技术,从网页中提取主要相关内容并转换为文本的在线工具。它通过AI技术识别并提取网页上的核心信息,支持JavaScript渲染,使用住宅IP地址以帮助绕过某些限制,从而提供更准确和全面的内容提取服务。
Wondercraft是一个创新的在线服务,能够将作者的书稿转化为听起来像作者本人声音的语音阅读。这项技术不仅节省了作者在录音棚录制和雇佣音频专家编辑混音的时间和金钱,而且提供了一个高效、经济的解决方案,让作者能够专注于创作而不必为音频制作分心。
TTSynth.com是一个免费的在线文本转语音(TTS)生成器,它使用先进的AI技术将书面文本转换为自然发音的语音。该服务支持多种语言和口音,适用于全球用户。它提供了高质量的音频输出,并且用户可以轻松下载TTS MP3文件。TTS技术在教育、营销、无障碍解决方案等多个领域都有广泛的应用。
文本转语音技术是一种将文本信息转换为语音的技术,广泛应用于辅助阅读、语音助手、有声读物制作等领域。它通过模拟人类语音,提高了信息获取的便捷性,尤其对视力障碍者或在无法使用眼睛阅读的情况下非常有帮助。
TTSMaker是一款在线的文本转语音平台,通过AI人工智能算法将文本轻松转换成音频。它支持50多种语言和300多个语音包风格,适用于视频配音、有声读物、教育培训和产品营销等多种场景。用户可以免费使用TTSMaker合成语音,并且拥有合成的音频文件的100%版权,可以用于任何合法的商业用途。
该产品是一个先进的在线文字转语音工具,使用人工智能技术将文本转换为自然逼真的语音。它支持多种语言和语音风格,适用于广告、视频旁白、有声书制作等场景,增强了内容的可访问性和吸引力。产品背景信息显示,它为数字营销人员、内容创作者、有声书作者和教育工作者提供了极大的便利。
Picture to Text是一款在线图片文字识别工具,能够批量提取和复制图片中的文字内容。它免费转换照片为可编辑的文字。
Pen2txt是一款利用OCR和人工智能进行手写文本识别的产品。它可以将手写笔记转换为可编辑、可搜索的数字文本,适用于学生、专业人士以及任何需要将纸质文件转换为数字形式的人群。Pen2txt凭借准确、可搜索和可编辑的结果,提高了工作效率。
Imagen A Texto是一个在线工具,可以将图像转换为可编辑的文本。它使用先进的OCR技术,确保准确提取图像中的文本。用户只需上传图像,工具会自动识别并提取文本。适用于转换文件、书籍、引用等。它支持多种图像格式,界面简单易用。
Narakeet是一个在线工具,允许用户轻松创建逼真的文本转语音和旁白视频。它提供了多种语言和声音选择,支持多种文件格式上传,并允许用户自定义音量、速度和输出格式。Narakeet的定价模式为一次性支付,无需订阅,适合商业用户和需要大量音频文件的用户。
ttsMP3是一个免费的多语言文本转语音工具,支持28种以上的语言和口音。用户可以将文本转换为自然流利的语音,并可在线收听或下载为MP3文件。适用于电子学习、演示、YouTube视频以及提高网站的可访问性等场景。
Luvvoice是一个免费的文字转语音工具,提供200多种声音选择,可根据用户需求将文本转化为语音。Luvvoice具有易用性、多语言支持和高质量的声音合成等优势。Luvvoice的定价非常实惠,让用户可以免费使用更多功能,同时也提供付费的高级功能。
Ad Auris是一款能够将文章转换为语音并播放的应用。用户可以随时随地听取自己感兴趣的文章内容,同时支持保存到平台如Spotify。该应用定位于提升用户的阅读效率和便利性,使用户能够在忙碌的生活中享受阅读的乐趣。
Ytube是一款全能平台,能够以独特的方式将您的YouTube视频转化为各种文本格式。无需让您的内容局限于一个媒介。
ChatGPT Text Divider是一个在线工具,可以将长篇文本分割成 3000 个字的块。它适用于需要处理大量文本的用户,例如研究人员、作家、编辑等。使用该工具,用户只需将文本粘贴进输入框,点击 “分割文本” 按钮即可得到分割后的文本块。用户还可以将分割后的文本块导出为文件以便后续处理。
Peech是一款文本转语音工具,可将任何网络文章、电子书或其他文本转换为引人入胜的有声读物。无论您是有阅读障碍、注意力不集中、视觉障碍,还是只想听而不想读,都可以使用Peech将文本转换为音频。同时,Peech还提供多种语言支持,智能选择合适的语音角色,支持多种输入格式,并能分析内容选择合适的语音。无论是个人使用还是出版商,Peech都能将文字转换为引人入胜的有声读物。
Speechimo是一款文本转语音工具,能够将文本转化为高质量的人声,逼真程度让人惊叹。它可以广泛应用于视频、播客、有声书等领域,为用户提供高效、省时省力的内容创作体验。用户可以在不花大价钱聘请专业配音员的情况下,轻松地为自己的项目生成专业级的语音。Speechimo的定价灵活,提供14天免费试用,之后用户可以根据需求选择不同的订阅方案。
AnyToSpeech是一款简洁易用的文字转语音解决方案,支持将文本、PDF、文档、扫描件和图片转换为语音。用户可以免费使用500个字符,超出部分需登录使用。该产品还提供文档、网址、扫描件或图片转语音的功能,并支持生成AI语音、教育、YouTube视频内容创作、文章转音频、有声书、PDF文档朗读、新闻摘要、播客制作等多种应用场景。用户可根据需求选择不同的价格套餐,提供一次性购买和包月订阅两种付费方式,并且产品还提供免费试用、退款政策和随时取消订阅等服务。
Clipboard TTS是一款专为阅读障碍人群设计的电脑客户端软件,支持49种语言和100多种声音,可将剪贴板中的文本内容转换成语音朗读,同时支持自动翻译、自动字典、图像转文本等功能,提供多种字体和背景颜色可供选择,支持自定义替换、历史记录等功能,为用户提供极致的阅读体验。
AI Case Convert是一款智能大小写转换工具,可以将文本自动转换为大写、小写、首字母大写或句子大小写。它不需要使用Excel或Python,让您能够快速将文本转换为所需的大小写格式。该工具功能强大,简单易用,适用于各种场景。
Free Text to Speech Online Converter是一个多语言文本转语音的在线平台。它支持超过20种语言,拥有自然的发音,无需注册即可免费使用,转换速度快。
Call Assistant是一款由Anthropic开发的AI助手插件,可以为电话会议自动生成准确的文字记录和内容摘要,提高团队工作效率。
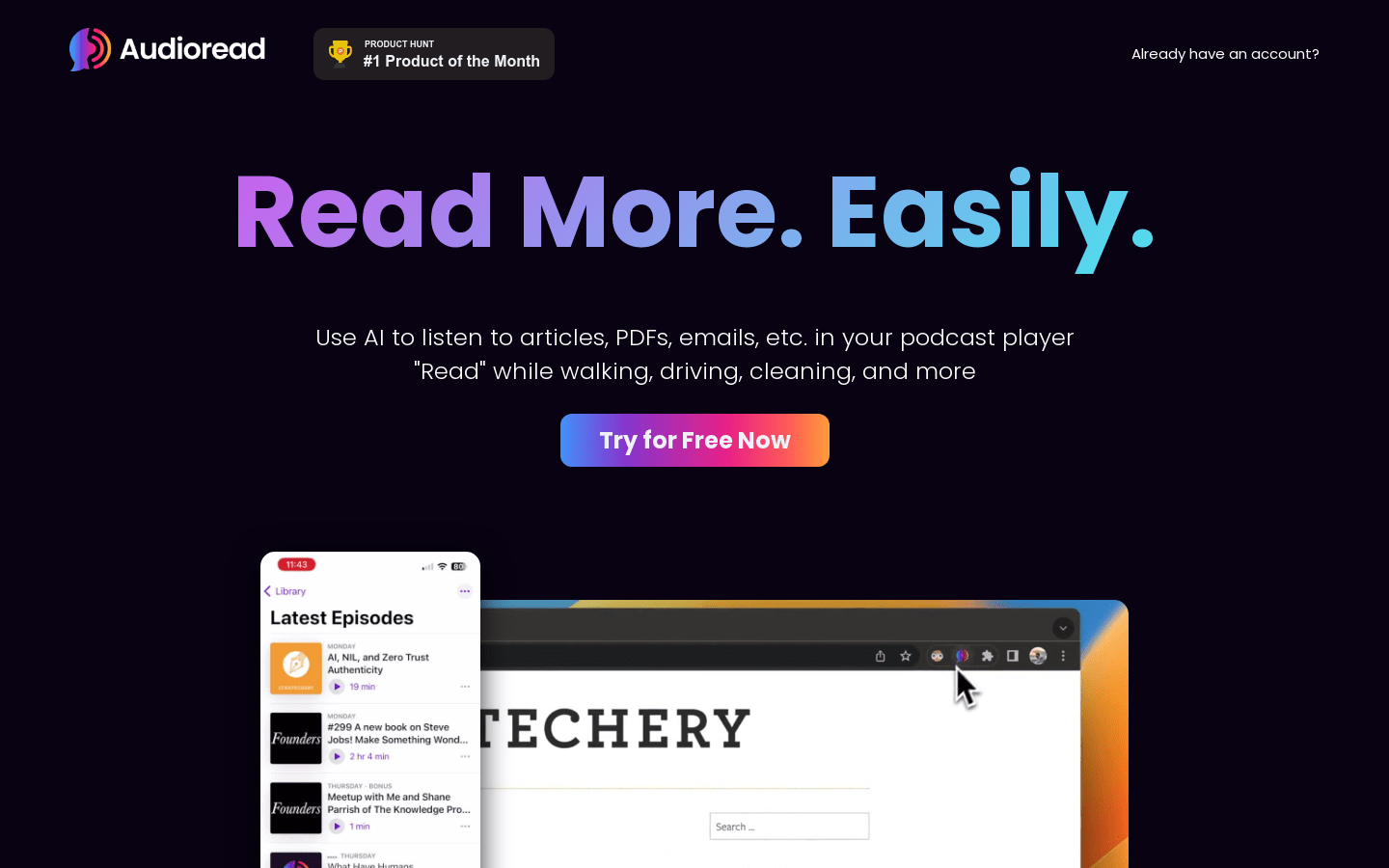
Audioread是一款利用人工智能将文字转换为语音的工具。其具备超逼真的文本转语音引擎,能够以自然而专业的叙述风格朗读任何文本,旨在长时间收听,训练有素,几乎无法与真实有声书叙述者区分开来。用户可以使用网页应用、浏览器插件、iOS快捷方式或Android应用程序将文字转换为音频,也可以转发电子邮件、拖放PDF、复制/粘贴文本或者高亮文本。Audioread还支持创建并订阅私人播客,用户可以在任何播客应用程序中订阅私人播客,如Apple Podcasts、Google Podcasts、Spotify等。此外,用户还可以在浏览器中收听,无需安装任何应用。Audioread还提供付费服务,包括月度订阅,每月9.99美元,每次转换最多10万字,每日最多50万字,支持77种语言。
Talk to PDF是一个在线文档朗读工具。它可以自动将PDF、PPT、Word等文档中的文字转成语音朗读出来,使阅读体验更加便捷、有趣。用户只需上传文档,Talk to PDF就可以生成语音版本,支持可调节语速、自动滚屏等功能。适合需要大量阅读文档的用户,如学生、老师、白领等。
魔音工坊是一款功能强大的在线智能配音工具,能够快速高效地实现文字到语音的转换。它拥有强大的语音合成技术,提供真人录音质量的配音效果。用户只需输入文字,即可生成逼真的语音音频。魔音工坊支持中文、英文等多种语言的配音,提供不同性别、不同口音的人声音色。用户可以精心调整每个句子的语速、音调等参数,输出流畅自然的配音作品。该产品适用于视频创作者、主播、录音师等创作者,能大大提高他们的内容输出效率。
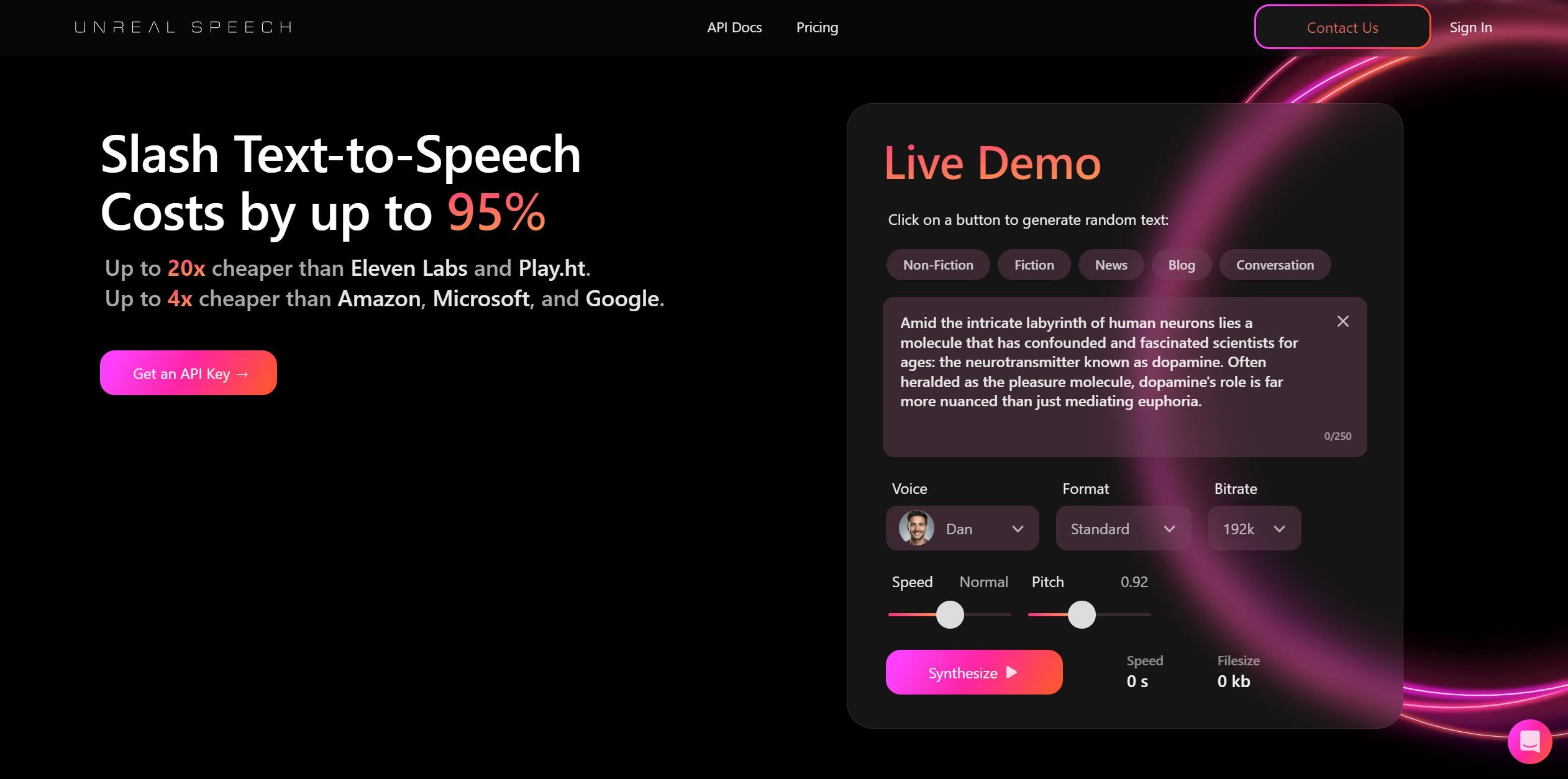
Unreal Speech是一个文本转语音的API,可将文本转换为语音,可帮助用户大幅降低语音合成成本。它比Eleven Labs和Play.ht便宜20倍,比Amazon、Microsoft和Google便宜4倍。Unreal Speech提供高质量的语音合成,并可根据用户的需要提供个性化的声音和格式选项。该API还支持实时演示和与其他语音合成引擎进行比较。定价根据字符数和音频时长计算,随着使用量的增加而享受折扣。
Manipulist是一个功能强大的在线文本处理工具,可以实现文本转换、提取、替换、排序、编码/解码等多种操作。它提供了添加文本、移除文本、替换文本、排序行、提取文本、修剪行、转换大小写、编码/解码等功能,可以高效地对文本进行提取和转换,实现用户所需的各种文本处理。
Clipchamp文字转语音生成器是一个免费的在线工具,可以为视频创建各种语言和口音的画外音。它提供了400多个逼真的声音,包括各种年龄、口音、女性、男性和中性音调。用户只需在文本框中输入文字,然后选择所需的语言和语速,即可生成预览并保存画外音。该工具非常适合创作者在社交媒体上吸引用户的目光,制作易于操作的YouTube教程视频,以及使用画外音创建有趣的游戏集锦视频。对于企业来说,它可以帮助创建风格一致的企业视频,通过旁白解说重构文化视频,优化培训视频和录屏。对于在线学习而言,使用画外音可以让视频更具有普适性且更易理解,使在线学习内容更具吸引力,并创建教学计划的重点。
Revoicer是一款基于人工智能的语音转文字在线工具,通过使用最先进的AI技术,可以快速、准确地将语音转换为文字。它提供80多种逼真的人声AI语音,支持多种语言,用户可以自定义语音类型、音调和速度,并添加不同情绪,如友好、愉快、悲伤、愤怒等。Revoicer是一个完全在线的应用程序,无需下载任何内容。
语音听写是一款免费的在线语音识别软件,可以通过语音输入来帮助您写邮件、文件和文章,无需打字。
BlogcastTM是一款基于AI技术的文字转语音软件。它可以从任何基于文本的内容生成清晰、自然的语音,用于制作播客、视频等。无需麦克风!价格根据不同的订阅计划,包括免费试用和按月/按年订阅。
FreeTTS是一款在线免费文本转语音工具,支持几乎所有语言。您可以使用自然发音的声音创建高质量的音频文件,适用于任何项目。支持SSML TTS,可自定义音频,提供暂停、音频格式等细节。产品完全免费,可以用于商业用途。
ReadSpeaker提供逼真的在线和离线语音合成解决方案,使您的产品和服务更具吸引力。我们的产品包括ReadSpeaker Online,ReadSpeaker Learning和ReadSpeaker Enterprise。无论是教育、企业学习还是定制语音合成,ReadSpeaker都可以满足您的需求。
文件语音转换是一款将文件转换成自然清晰语音的工具。通过支持多种文件导入方式,选择语言和声音,转换文件成语音,方便地下载或在线播放。支持多语言、离线使用,性能高效。适用于教育、商业等场景。
Sibylia是一款能够将您的内容转化为文字和音频描述的解决方案。利用我们的人工智能模型,提高您的视频内容的影响力,自动生成引人入胜的音频描述。通过Sibylia,您可以使您的创作对更多人无障碍可达。
Speech Intellect是第一个实时工作的语音转文字/文字转语音解决方案,完全使用了全新的AI专注的数学理论——Sense Theory。它考虑了客户发音的每个单词的意义。我们的解决方案基于自主研发的Sense-to-Sense算法,可以实现文本以带有语调和特定调性的声音重新产生。该解决方案可以轻松集成到各种业务场景中,如视频游戏中以人形声音复制脚本文本、呼叫中心与客户的交流、网站上的虚拟对话、智能家居中的舒适对话等等。我们的算法使用的是Sense,与市场上其他解决方案的算法不同。
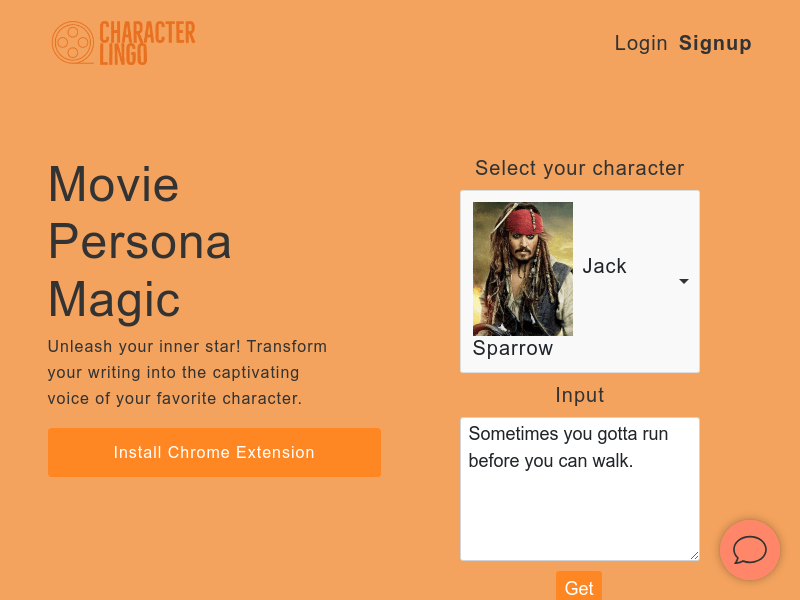
Character Lingo是一个可以将你的写作转换为你最喜爱的角色的声音的工具。通过使用这个工具,你可以选择你喜欢的电影、电视剧或漫画中的角色,并将你的文字转化为他们的口吻和语气。无论是在社交媒体上发布内容,还是在写作中加入角色的声音,Character Lingo都能帮助你将你的文字变得更加有趣、生动和吸引人。
Speechson是一款将文字转换为自然人声的工具,支持多种语言和声音选择。用户可以将文本转换为MP3或WAV音频格式,并进行下载和使用。产品具有900+种AI声音,覆盖144+种语言。
TTSLabs是一款在线语音合成与语音识别服务,提供高质量、自然流畅的语音合成和准确可靠的语音识别功能。通过简单的API调用,用户可以将文字转化为真实的语音,并且可以将语音转化为文本。TTSLabs提供多种语音风格和多国语言的支持,具有快速响应、高效稳定的特点。价格灵活透明,适用于个人开发者和企业用户。
UberTTS是一款采用先进的AI文本到语音技术,将文本转换为逼真的人类声音的产品。它适用于YouTube叙述、营销内容、教程内容、新闻叙述、有声书等各种用途。它提供了900多种标准和神经网络声音,支持超过144种语言和方言。用户可以自定义音量、速度、音调和暂停等参数。UberTTS还提供强大的声音工作室,可合并和增强音频效果,并支持多种格式的音频下载和分享。
AiVOOV是一个使用900多种逼真的语音和125多种语言将文本转换为语音的在线工具。它提供专业的语音合成服务,可以将您的文本转换为MP3和WAV格式的声音文件。无论是制作商业广告还是语音教学材料,AiVOOV都能帮助您快速生成高质量的语音。
在线文本转语音是一款免费的工具,可以将文本转换为真实的语音。它具有高音质、自然的语音效果,并支持多种语言和声音选择。用户只需输入文本,选择语言和声音,即可生成自定义的语音内容。该工具适用于多种场景,如视频配音、教育辅助、语音导航等。无论是Mac还是Windows用户,都可以轻松使用该工具。
Voiser是一款拥有550多种不同语音选项的文本转语音工具。它可以将文字转换为逼真的机器语音,并提供人类声音的最接近的机器语音。此外,Voiser还可以将语音文件转换为文字,提供快速且准确的语音转文本服务。Voiser是最佳的文本朗读和语音转换解决方案。
WellSaid Labs是一款顶级的企业级AI语音平台,帮助企业和顶级创作者实时将文本转化为语音。成千上万的公司使用它来创建引人入胜的内容和体验,节省时间和金钱,而又不会降低质量。平台提供多种声音人选,支持团队协作和共享项目,适用于企业的安全和合规要求。
TTSMaker是一款免费的在线文本转语音工具,支持多种语言和语音风格。它可以将文字转换为自然流畅的语音,并提供下载MP3和WAV格式的音频文件。TTSMaker能够广泛应用于阅读文本、朗读电子书等场景,适用于个人和商业用途。
Voicemaker®是一个在线文本转语音转换器,可以将文本转换为非常逼真的人声AI语音。您可以将语音下载为MP3、WAV音频格式。我们拥有130多种语言的1000多种AI语音。
Murf AI是一款多功能的AI语音生成器,提供20种语言、120多个真实的语音,可快速生成专业的语音解说。可用于广告、演讲、教育等多种场景。定价请参考官网。
Speechify是一款拥有数百万次下载的领先文本转语音应用。它能将任何你阅读的文档、文章、PDF、电子邮件等转化为声音,让你可以在任何设备上听到互联网的声音。Speechify提供免费试用。
探索 生产力 分类下的其他子分类
1361 个工具
904 个工具
767 个工具
619 个工具
607 个工具
431 个工具
406 个工具
398 个工具
文本转声音 是 生产力 分类下的热门子分类,包含 82 个优质AI工具