
产品详情
Murf AI是一款多功能的AI语音生成器,提供20种语言、120多个真实的语音,可快速生成专业的语音解说。可用于广告、演讲、教育等多种场景。定价请参考官网。
主要功能
适用人群
广告、演讲、教育等场景
快速访问
访问官网 →所属分类
相关推荐
发现更多类似的优质AI工具
Huxe
Huxe是一款将日常信息转化为个性化音频情报的产品。其重要性在于为用户提供了一种便捷、高效的信息获取方式,让用户在无法看屏幕的场景下也能轻松获取所需信息。主要优点包括个性化定制、互动性强、能将各种问题转化为音频解释等。产品背景可能是为了满足人们在快节奏生活中对便捷信息获取的需求。价格信息未提及,从内容来看可能是免费使用。产品定位为帮助用户在通勤、锻炼、休息等场景下,无需长时间滚动屏幕就能及时获取感兴趣的信息。

Katalog
Katalog是一个通过AI语音播报文章的工具。它利用超逼真的AI声音播报您保存的文章,提供顶级的听取体验。Katalog还在公共测试阶段免费使用,未来可能会推出免费和付费版本。
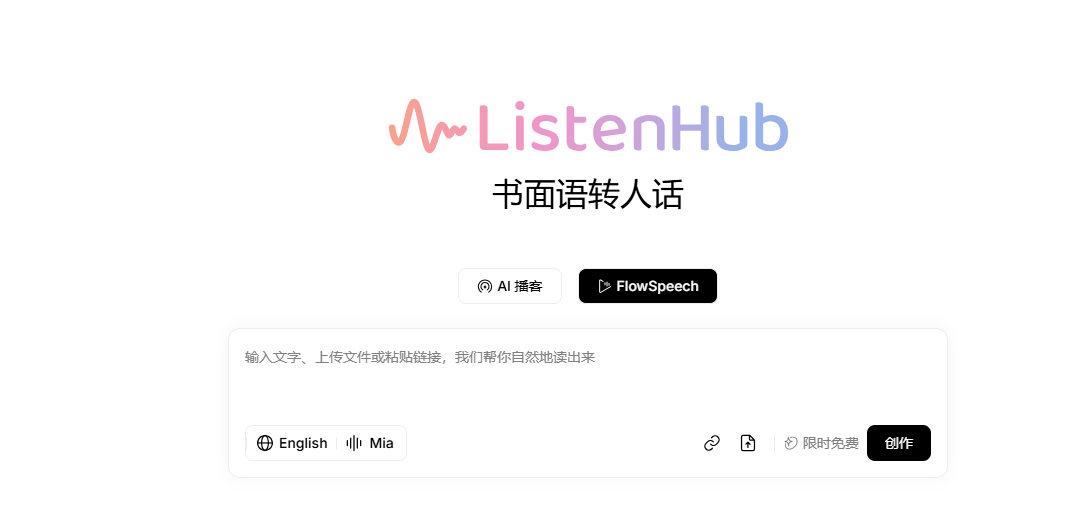
FlowSpeech
FlowSpeech是一个免费的 AI 播客生成器,利用最新的语音合成技术将文本转换为自然人声,适合各种用户需求。它支持多种格式的输入,包括 PDF、TXT 等,方便用户快速获取信息。提供多种订阅选项,帮助创作者更高效地制作播客。

notigo.ai
Notigo是一款AI实时会议摘要生成器,能够自动生成会议摘要,帮助用户不再错过重要内容。其主要优点包括高质量的笔记、结构化的内容、精确的摘要、多语言支持等。

Spark-TTS
Spark-TTS 是一种基于大语言模型的高效文本到语音合成模型,具有单流解耦语音令牌的特性。它利用大语言模型的强大能力,直接从代码预测的音频进行重建,省略了额外的声学特征生成模型,从而提高了效率并降低了复杂性。该模型支持零样本文本到语音合成,能够跨语言和代码切换场景,非常适合需要高自然度和准确性的语音合成应用。它还支持虚拟语音创建,用户可以通过调整参数(如性别、音高和语速)来生成不同的语音。该模型的背景是为了解决传统语音合成系统中效率低下和复杂性高的问题,旨在为研究和生产提供高效、灵活且强大的解决方案。目前,该模型主要面向学术研究和合法应用,如个性化语音合成、辅助技术和语言研究等。

Llasa
Llasa是一个基于Llama框架的文本到语音(TTS)基础模型,专为大规模语音合成任务设计。该模型利用16万小时的标记化语音数据进行训练,具备高效的语言生成能力和多语言支持。其主要优点包括强大的语音合成能力、低推理成本和灵活的框架兼容性。该模型适用于教育、娱乐和商业场景,能够为用户提供高质量的语音合成解决方案。目前该模型在Hugging Face上免费提供,旨在推动语音合成技术的发展和应用。

LLaDA
LLaDA是一种新型的扩散模型,通过扩散过程生成文本,与传统的自回归模型不同。它在语言生成的可扩展性、指令遵循、上下文学习、对话能力和压缩能力等方面表现出色。该模型由中国人民大学和蚂蚁集团的研究人员开发,具有8B的规模,完全从零开始训练。其主要优点是能够通过扩散过程灵活地生成文本,支持多种语言任务,如数学问题解答、代码生成、翻译和多轮对话等。LLaDA的出现为语言模型的发展提供了新的方向,尤其是在生成质量和灵活性方面。

Lemonfox.ai Text-to-Speech API
Lemonfox.ai Text-to-Speech API 是一款专注于文本转语音(TTS)的API服务。它利用先进的AI技术,能够快速将文本转换为自然流畅的语音,支持多种语言和口音,适用于多种场景,如语音播报、有声读物制作等。其主要优点包括低成本、高质量、易于集成,能够帮助企业或开发者快速实现语音功能,提升用户体验。该产品定位为面向企业和开发者的高效、经济的TTS解决方案,价格合理,提供免费试用,性价比高。

IndexTTS
IndexTTS 是一种基于 GPT 风格的文本到语音(TTS)模型,主要基于 XTTS 和 Tortoise 进行开发。它能够通过拼音纠正汉字发音,并通过标点符号控制停顿。该系统在中文场景中引入了字符-拼音混合建模方法,显著提高了训练稳定性、音色相似性和音质。此外,它还集成了 BigVGAN2 来优化音频质量。该模型在数万小时的数据上进行训练,性能超越了当前流行的 TTS 系统,如 XTTS、CosyVoice2 和 F5-TTS。IndexTTS 适用于需要高质量语音合成的场景,如语音助手、有声读物等,其开源性质也使其适合学术研究和商业应用。

ElevenReader Publishing
ElevenReader Publishing 是由 ElevenLabs 推出的创新平台,利用 AI 音频模型将书籍转化为高质量有声书。它解决了传统有声书制作成本高、流程复杂的问题,为作者提供了一个快速、免费且全球分发的解决方案。该平台支持多种文件格式导入,用户可以预览音频并选择喜欢的 AI 语音。此外,它还提供听众报告和分析功能,帮助作者更好地了解受众。其主要优点是零成本、快速生成和全球分发,适合独立作者和出版商。
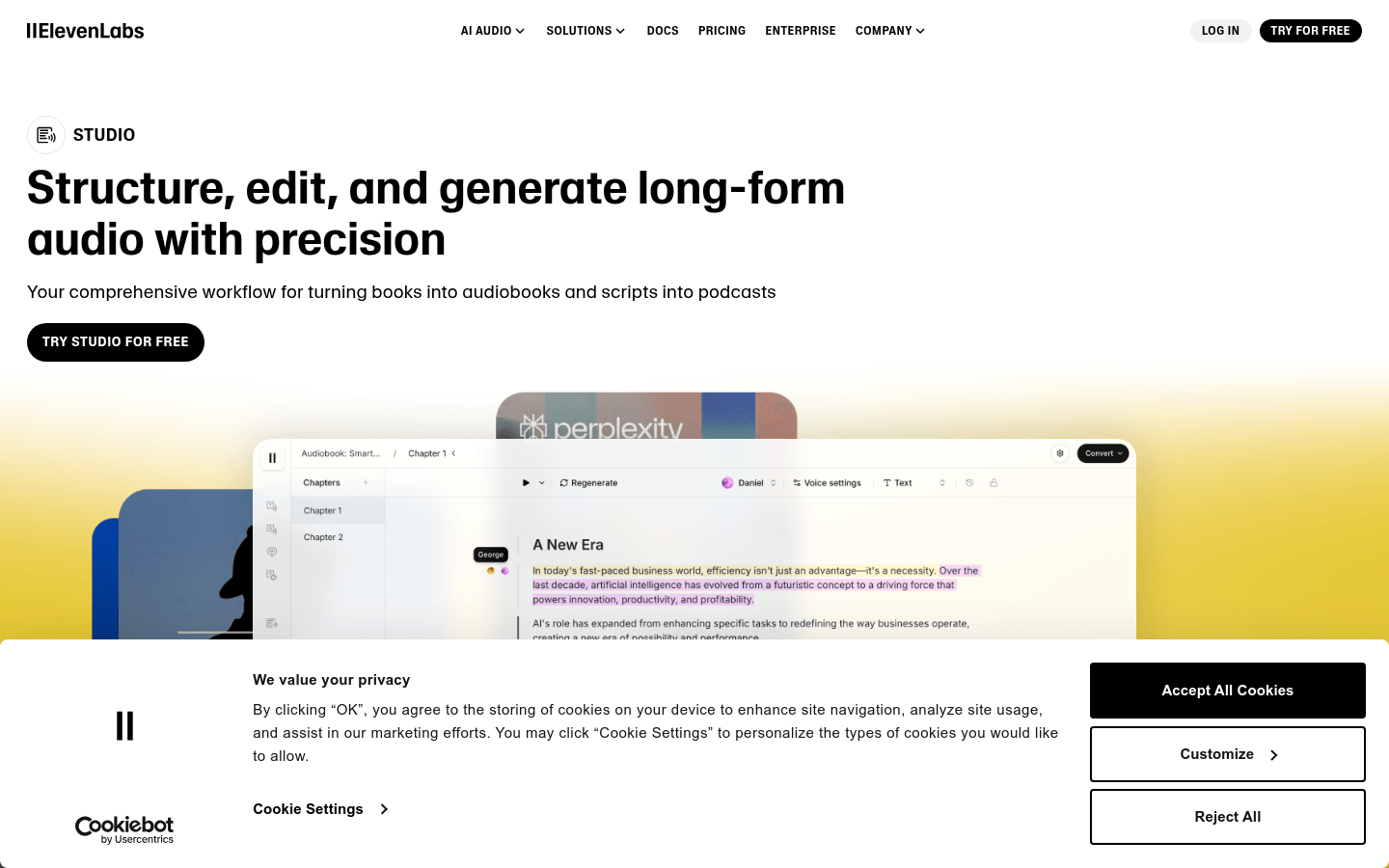
ElevenLabs Studio
ElevenLabs Studio 是一个专注于音频内容创作的平台,利用先进的人工智能技术,能够将文本内容转化为高质量的音频。其主要优点包括支持多种文件格式、提供丰富的语音库、能够根据情感和上下文调整语音表达等。该平台适用于有声读物制作、播客创作等场景,能够帮助创作者高效地生成音频内容,提升创作效率和质量。其定价策略可能因用户需求和使用场景而异,具体价格可参考官网的定价页面。
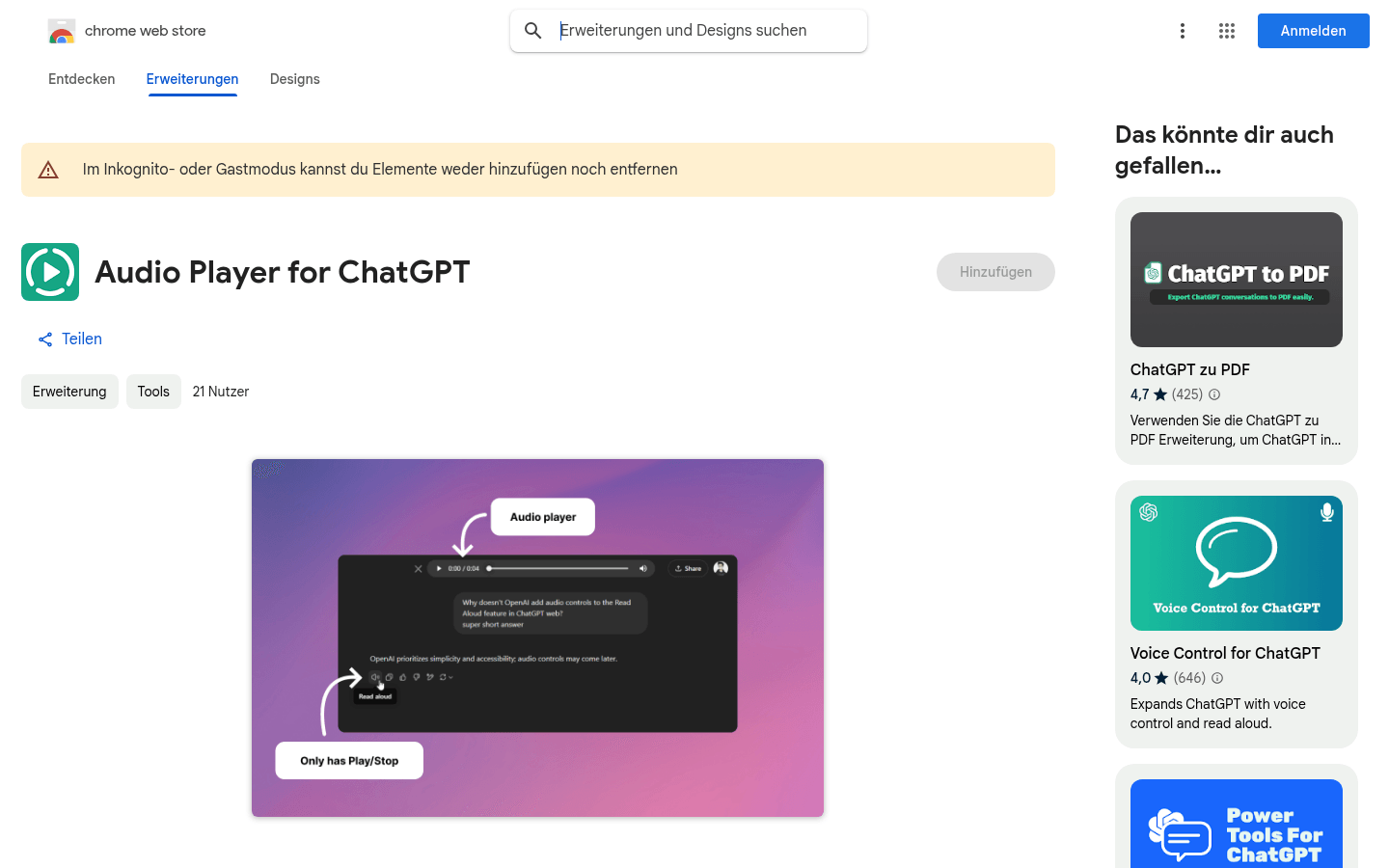
Audio player for ChatGPT
该产品是一个 Chrome 扩展程序,旨在改善 ChatGPT 的朗读功能。通过显示一个音频播放器,用户可以更方便地控制朗读过程,如暂停、快进等。它主要面向视力不佳或喜欢听读的用户,帮助他们更高效地使用 ChatGPT。该产品是开源的,用户可以选择安装扩展程序或手动将代码集成到自己的脚本管理器中。其免费的特性使其具有较高的可访问性。

Zonos-v0.1-hybrid
Zonos-v0.1-hybrid 是由 Zyphra 开发的一款开源文本转语音模型,它能够根据文本提示生成高度自然的语音。该模型经过大量英语语音数据训练,采用 eSpeak 进行文本归一化和音素化,再通过变换器或混合骨干网络预测 DAC 令牌。它支持多种语言,包括英语、日语、中文、法语和德语,并且可以对生成语音的语速、音调、音频质量和情绪等进行精细控制。此外,它还具备零样本语音克隆功能,仅需 5 到 30 秒的语音样本即可实现高保真语音克隆。该模型在 RTX 4090 上的实时因子约为 2 倍,运行速度较快。它还配备了易于使用的 gradio 界面,并且可以通过 Docker 文件简单安装和部署。目前,该模型在 Hugging Face 上提供,用户可以免费使用,但需要自行部署。

TurboTTS
TurboTTS 是一款基于先进人工智能技术的文本转语音工具。它能够将书面文本快速转化为自然、逼真的语音,支持多达70种语言和300多种真实语音类型。该技术的主要优点在于其高质量的语音输出、简单易用的界面以及快速高效的内容生成能力。其背景信息显示,该平台已被全球超过228,000名创作者使用,每天处理超过5,000万条配音文本,提供99.9%的正常运行时间保证和98%的用户满意度。TurboTTS 提供免费和付费两种计划,适合个人和专业用户。

Sonofa
Sonofa 是一款基于人工智能技术的产品,能够将各种形式的阅读内容(如网页、PDF文件、图片中的文字)转化为播客形式的音频内容。这种技术利用了先进的文本转语音(TTS)和自然语言处理(NLP)能力,将文字内容转化为自然流畅的语音,让用户能够在不阅读的情况下获取信息。该产品的主要优点是极大地提高了信息获取的灵活性和效率,尤其适合那些在通勤、锻炼或休闲时无法阅读的人群。Sonofa 的背景信息显示,它旨在通过创新的方式帮助用户更好地利用碎片化时间,提升个人学习和工作效率。目前,Sonofa 提供的服务可能是基于订阅模式的付费服务,具体价格和定位尚未明确。

Kokoro TTS
Kokoro TTS是一款专注于文本转语音的AI模型,其主要功能是将文本内容转换为自然流畅的语音输出。该模型基于StyleTTS 2架构,拥有8200万参数,能够在保持高质量语音合成的同时,提供高效的性能和较低的资源消耗。其多语言支持和可定制的语音包使其能够满足不同用户在多种场景下的需求,如制作有声读物、播客、培训视频等,尤其适合教育领域,帮助提升内容的可访问性和吸引力。此外,Kokoro TTS是开源的,用户可以免费使用,这使得它在成本效益上具有显著优势。