共找到 61 个AI工具
点击任意工具查看详细信息
Firecrawl MCP Server 是一款集成了强大网页抓取功能的插件,支持多种 LLM 客户端如 Cursor 和 Claude。它能高效地抓取、搜索和提取网页内容,并提供自动重试及流量限制等功能,适合开发者和研究人员使用。该产品具有高度的灵活性与可扩展性,可用于批量抓取和深度研究。
DeepSeek-Prover-V2-671B 是一个先进的人工智能模型,旨在提供强大的推理能力。它基于最新的技术,适用于多种应用场景。该模型是开源的,旨在促进人工智能技术的民主化与普及,降低技术壁垒,使更多开发者和研究者能够利用 AI 技术进行创新。通过使用该模型,用户可以提升他们的工作效率,推动各类项目的进展。
Atom of Thoughts (AoT) 是一种新型推理框架,通过将解决方案表示为原子问题的组合,将推理过程转化为马尔可夫过程。该框架通过分解和收缩机制,显著提升了大语言模型在推理任务上的性能,同时减少了计算资源的浪费。AoT 不仅可以作为独立的推理方法,还可以作为现有测试时扩展方法的插件,灵活结合不同方法的优势。该框架开源且基于 Python 实现,适合研究人员和开发者在自然语言处理和大语言模型领域进行实验和应用。
ViDoRAG 是阿里巴巴自然语言处理团队开发的一种新型多模态检索增强生成框架,专为处理视觉丰富文档的复杂推理任务设计。该框架通过动态迭代推理代理和高斯混合模型(GMM)驱动的多模态检索策略,显著提高了生成模型的鲁棒性和准确性。ViDoRAG 的主要优点包括高效处理视觉和文本信息、支持多跳推理以及可扩展性强。该框架适用于需要从大规模文档中检索和生成信息的场景,例如智能问答、文档分析和内容创作。其开源特性和灵活的模块化设计使其成为研究人员和开发者在多模态生成领域的重要工具。
Level-Navi Agent是一个开源的通用网络搜索代理框架,能够将复杂问题分解并逐步搜索互联网上的信息,直至回答用户问题。它通过提供Web24数据集,覆盖金融、游戏、体育、电影和事件等五大领域,为评估模型在搜索任务上的表现提供了基准。该框架支持零样本和少样本学习,为大语言模型在中文网络搜索代理领域的应用提供了重要参考。
M2RAG是一个用于多模态上下文中的检索增强生成的基准测试代码库。它通过多模态检索文档来回答问题,评估多模态大语言模型(MLLMs)在利用多模态上下文知识方面的能力。该模型在图像描述、多模态问答、事实验证和图像重排等任务上进行了评估,旨在提升模型在多模态上下文学习中的有效性。M2RAG为研究人员提供了一个标准化的测试平台,有助于推动多模态语言模型的发展。
olmOCR是由Allen Institute for Artificial Intelligence (AI2)开发的一个开源工具包,旨在将PDF文档线性化,以便用于大型语言模型(LLM)的训练。该工具包通过将PDF文档转换为适合LLM处理的格式,解决了传统PDF文档结构复杂、难以直接用于模型训练的问题。它支持多种功能,包括自然文本解析、多版本比较、语言过滤和SEO垃圾信息移除等。olmOCR的主要优点是能够高效处理大量PDF文档,并通过优化的提示策略和模型微调,提高文本解析的准确性和效率。该工具包适用于需要处理大量PDF数据的研究人员和开发者,尤其是在自然语言处理和机器学习领域。
MLGym是由Meta的GenAI团队和UCSB NLP团队开发的一个开源框架和基准,用于训练和评估AI研究代理。它通过提供多样化的AI研究任务,推动强化学习算法的发展,帮助研究人员在真实世界的研究场景中训练和评估模型。该框架支持多种任务,包括计算机视觉、自然语言处理和强化学习等领域,旨在为AI研究提供一个标准化的测试平台。
PIKE-RAG 是微软开发的一种领域知识和推理增强生成模型,旨在通过知识提取、存储和推理逻辑增强大型语言模型(LLM)的能力。该模型通过多模块设计,能够处理复杂的多跳问答任务,并在工业制造、矿业和制药等领域显著提升了问答准确性。PIKE-RAG 的主要优点包括高效的知识提取能力、强大的多源信息整合能力和多步推理能力,使其在需要深度领域知识和复杂逻辑推理的场景中表现出色。
SWE-Lancer 是由 OpenAI 推出的一个基准测试,旨在评估前沿语言模型在真实世界中的自由软件工程任务中的表现。该基准测试涵盖了从 50 美元的漏洞修复到 32000 美元的功能实现等多种独立工程任务,以及模型在技术实现方案之间的选择等管理任务。通过模型将性能映射到货币价值,SWE-Lancer 为研究 AI 模型开发的经济影响提供了新的视角,并推动了相关研究的发展。
Goedel-Prover 是一款专注于自动化定理证明的开源大型语言模型。它通过将自然语言数学问题翻译为形式化语言(如 Lean 4),并生成形式化证明,显著提升了数学问题的自动化证明效率。该模型在 miniF2F 基准测试中达到了 57.6% 的成功率,超越了其他开源模型。其主要优点包括高性能、开源可扩展性以及对数学问题的深度理解能力。Goedel-Prover 旨在推动自动化定理证明技术的发展,并为数学研究和教育提供强大的工具支持。
OpenThinker-32B 是由 Open Thoughts 团队开发的一款开源推理模型。它通过扩展数据规模、验证推理路径和扩展模型大小来实现强大的推理能力。该模型在数学、代码和科学等推理基准测试中表现卓越,超越了现有的开放数据推理模型。其主要优点包括开源数据、高性能和可扩展性。该模型基于 Qwen2.5-32B-Instruct 进行微调,并在大规模数据集上训练,旨在为研究人员和开发者提供强大的推理工具。
RAG-FiT是一个强大的工具,旨在通过检索增强生成(RAG)技术提升大型语言模型(LLMs)的能力。它通过创建专门的RAG增强数据集,帮助模型更好地利用外部信息。该库支持从数据准备到模型训练、推理和评估的全流程操作。其主要优点包括模块化设计、可定制化工作流以及对多种RAG配置的支持。RAG-FiT基于开源许可,适合研究人员和开发者进行快速原型开发和实验。
Open-source DeepResearch 是一个开源项目,旨在通过开源的框架和工具复现类似 OpenAI Deep Research 的功能。该项目基于 Hugging Face 平台,利用开源的大型语言模型(LLM)和代理框架,通过代码代理和工具调用实现复杂的多步推理和信息检索。其主要优点是开源、可定制性强,并且能够利用社区的力量不断改进。该项目的目标是让每个人都能在本地运行类似 DeepResearch 的智能代理,使用自己喜爱的模型,并且完全本地化和定制化。
node-DeepResearch 是一个基于 Jina AI 技术的深度研究模型,专注于通过持续搜索和阅读网页来寻找问题的答案。它利用 Gemini 提供的 LLM 能力和 Jina Reader 的网页搜索功能,能够处理复杂的查询任务,并通过多步骤的推理和信息整合来生成答案。该模型的主要优点在于其强大的信息检索能力和推理能力,能够处理复杂的、需要多步骤解答的问题。它适用于需要深入研究和信息挖掘的场景,如学术研究、市场分析等。目前该模型是开源的,用户可以通过 GitHub 获取代码并自行部署使用。
OpenDeepResearcher 是一个基于 AI 的研究工具,通过结合 SERPAPI、Jina 和 OpenRouter 等服务,能够根据用户输入的查询主题,自动进行多轮迭代搜索,直至收集到足够的信息并生成最终报告。该工具的核心优势在于其高效的异步处理能力、去重功能以及强大的 LLM 决策支持,能够显著提升研究效率。它主要面向需要进行大量文献搜索和信息整理的科研人员、学生以及相关领域的专业人士,帮助他们快速获取高质量的研究资料。该工具目前以开源形式提供,用户可以根据需要自行部署和使用。
DeepSeek-R1-Distill-Qwen-7B 是一个经过强化学习优化的推理模型,基于 Qwen-7B 进行了蒸馏优化。它在数学、代码和推理任务上表现出色,能够生成高质量的推理链和解决方案。该模型通过大规模强化学习和数据蒸馏技术,显著提升了推理能力和效率,适用于需要复杂推理和逻辑分析的场景。
DeepSeek-R1-Zero 是由 DeepSeek 团队开发的推理模型,专注于通过强化学习提升模型的推理能力。该模型在无需监督微调的情况下,展现出强大的推理行为,如自我验证、反思和生成长链推理。其主要优点包括高效推理能力、无需预训练即可使用,以及在数学、代码和推理任务上的卓越表现。该模型基于 DeepSeek-V3 架构开发,支持大规模推理任务,适用于研究和商业应用。
DeepSeek-R1 是 DeepSeek 团队推出的第一代推理模型,通过大规模强化学习训练,无需监督微调即可展现出卓越的推理能力。该模型在数学、代码和推理任务上表现优异,与 OpenAI-o1 模型相当。DeepSeek-R1 还提供了多种蒸馏模型,适用于不同规模和性能需求的场景。其开源特性为研究社区提供了强大的工具,支持商业使用和二次开发。
PatronusAI/Llama-3-Patronus-Lynx-70B-Instruct是一个基于Llama-3架构的大型语言模型,旨在检测在RAG设置中的幻觉问题。该模型通过分析给定的文档、问题和答案,评估答案是否忠实于文档内容。其主要优点在于高精度的幻觉检测能力和强大的语言理解能力。该模型由Patronus AI开发,适用于需要高精度信息验证的场景,如金融分析、医学研究等。该模型目前为免费使用,但具体的商业应用可能需要与开发者联系。
Imitate Before Detect 是一种创新的文本检测技术,旨在提高对机器修订文本的检测能力。该技术通过模仿大型语言模型(LLM)的风格偏好,能够更准确地识别出经过机器修订的文本。其核心优势在于能够有效区分机器生成和人类写作的细微差别,从而在文本检测领域具有重要的应用价值。该技术的背景信息显示,它能够显著提高检测的准确性,并且在处理开源LLM修订文本时,AUC值提升了13%,在检测GPT-3.5和GPT-4o修订文本时分别提升了5%和19%。其定位是为研究人员和开发者提供一种高效的文本检测工具。
Eurus-2-7B-SFT是基于Qwen2.5-Math-7B模型进行微调的大型语言模型,专注于数学推理和问题解决能力的提升。该模型通过模仿学习(监督微调)的方式,学习推理模式,能够有效解决复杂的数学问题和编程任务。其主要优点在于强大的推理能力和对数学问题的准确处理,适用于需要复杂逻辑推理的场景。该模型由PRIME-RL团队开发,旨在通过隐式奖励的方式提升模型的推理能力。
ScreenSpot-Pro是一个专门用于评估高分辨率专业计算机使用环境下的GUI定位模型的基准测试。它涵盖了23个应用程序,分布在5个专业领域和3个操作系统中,突出了模型在与复杂软件交互时面临的挑战。现有的模型准确率仅为18.9%,这强调了进一步研究的必要性。该产品旨在推动GUI定位模型的发展,提高专业应用的可用性和性能。
FlexRAG是一个用于检索增强生成(RAG)任务的灵活且高性能的框架。它支持多模态数据、无缝配置管理和开箱即用的性能,适用于研究和原型开发。该框架使用Python编写,具有轻量级和高性能的特点,能够显著提高RAG工作流的速度和减少延迟。其主要优点包括支持多种数据类型、统一的配置管理以及易于集成和扩展。
Zasper 是一个专为数据科学设计的集成开发环境(IDE),它从底层设计支持大规模并发处理,具有极小的内存占用、卓越的速度以及处理大量并发连接的能力。它非常适合运行类似 Jupyter notebook 的 REPL 风格的数据应用。Zasper 的主要优点在于其高效的并发处理能力和轻量级的资源占用,使其在数据科学领域具有重要的应用价值。目前,Zasper 提供的是开源版本,适合数据科学家和开发者使用。
Llama-3-Patronus-Lynx-8B-Instruct是由Patronus AI开发的一个基于meta-llama/Meta-Llama-3-8B-Instruct模型的微调版本,主要用于检测在RAG设置中的幻觉。该模型训练于包含CovidQA、PubmedQA、DROP、RAGTruth等多个数据集,包含人工标注和合成数据。它能够评估给定文档、问题和答案是否忠实于文档内容,不提供文档之外的新信息,也不与文档信息相矛盾。
Patronus-Lynx-8B-Instruct-v1.1是基于meta-llama/Meta-Llama-3.1-8B-Instruct模型的微调版本,主要用于检测RAG设置中的幻觉。该模型经过CovidQA、PubmedQA、DROP、RAGTruth等多个数据集的训练,包含人工标注和合成数据。它能够评估给定文档、问题和答案是否忠实于文档内容,不提供超出文档范围的新信息,也不与文档信息相矛盾。
SakanaAI/asal是一个利用基础模型(Foundation Models, FMs)来自动化搜索人工生命(Artificial Life, ALife)的科研项目。该项目通过结合最新的人工智能技术,特别是视觉语言基础模型,来发现能够产生目标现象、生成时间开放性新颖性以及照亮整个有趣多样的模拟空间的人工生命模拟。它能够跨越多种ALife基底,包括Boids、Particle Life、Game of Life、Lenia和神经细胞自动机等,展示了通过技术手段加速人工生命研究的潜力。
GraphRAG Visualizer是一个基于网络的工具,旨在可视化和探索微软GraphRAG工具产生的数据。GraphRAG是微软开发的一种用于生成图结构数据的技术,GraphRAG Visualizer通过让用户上传parquet文件,无需额外软件或脚本即可轻松查看和分析数据。该工具的主要优点包括图形可视化、数据表格展示、搜索功能以及本地处理数据,确保数据安全和隐私。
Deepthought-8B是一个小型但功能强大的推理模型,它基于LLaMA-3.1 8B构建,旨在使AI推理更加透明和可控。尽管模型相对较小,但它实现了与更大模型相媲美的复杂推理能力。该模型以其独特的问题解决方法而设计,将其思考过程分解为清晰、独特、有记录的步骤,并将推理过程以结构化的JSON格式输出,便于理解和验证其决策过程。
Skywork-o1-Open-PRM-Qwen-2.5-7B是由昆仑科技Skywork团队开发的一系列模型,这些模型结合了o1风格的慢思考和推理能力。这个模型系列不仅在输出中展现出天生的思考、规划和反思能力,而且在标准基准测试中显示出推理技能的显著提升。它代表了AI能力的战略进步,将一个原本较弱的基础模型推向了推理任务的最新技术(SOTA)。
Skywork-o1-Open-PRM-Qwen-2.5-1.5B是Skywork团队开发的一系列模型,这些模型结合了o1风格的慢思考和推理能力。该模型专门设计用于通过增量过程奖励增强推理能力,适合解决小规模的复杂问题。与简单的OpenAI o1模型复现不同,Skywork o1 Open系列模型不仅在输出中展现出固有的思考、规划和反思能力,而且在标准基准测试中的推理技能有显著提升。这一系列代表了AI能力的一次战略性进步,将原本较弱的基础模型推向了推理任务的最新技术(SOTA)。
Skywork-o1-Open-Llama-3.1-8B是由昆仑科技Skywork团队开发的一系列模型,这些模型结合了o1风格的慢思考和推理能力。该系列模型不仅在输出中展现出天生的思考、规划和反思能力,而且在标准基准测试中的推理技能有显著提升。这一系列代表了AI能力的战略进步,将原本较弱的基础模型推向了推理任务的最新技术(SOTA)。
QwQ-32B-Preview是一个由Qwen团队开发的实验性研究模型,旨在提高人工智能的推理能力。该模型展示了有前景的分析能力,但也存在一些重要的限制。模型在数学和编程方面表现出色,但在常识推理和细微语言理解方面还有提升空间。该模型使用了transformers架构,具有32.5B个参数,64层,以及40个注意力头(GQA)。产品背景信息显示,QwQ-32B-Preview是基于Qwen2.5-32B模型的进一步开发,具有更深层次的语言理解和生成能力。
QwQ(Qwen with Questions)是一款由Qwen团队开发的实验性研究模型,旨在提升人工智能的推理能力。它以一种哲学精神,对每个问题都抱有真正的好奇和怀疑,通过自我提问和反思来寻求更深层次的真理。QwQ在数学和编程领域表现出色,尤其是在处理复杂问题时。尽管它仍在学习和成长,但它已经展现出了在技术领域深度推理的重要潜力。
LLNL/LUAR是一个基于Transformer的模型,用于学习作者表示,主要用于作者验证的跨领域迁移研究。该模型在EMNLP 2021论文中被介绍,研究了在一个领域学习的作者表示是否能迁移到另一个领域。模型的主要优点包括能够处理大规模数据集,并在多个不同的领域(如亚马逊评论、同人小说短篇故事和Reddit评论)中进行零样本迁移。产品背景信息包括其在跨领域作者验证领域的创新性研究,以及在自然语言处理领域的应用潜力。该产品是开源的,遵循Apache-2.0许可协议,可以免费使用。
ZipPy是一个研究性质的快速AI检测工具,它使用压缩比来间接测量文本的困惑度。ZipPy通过比较AI生成的语料库与提供的样本之间的相似性来进行分类。该工具的主要优点是速度快、可扩展性强,并且可以嵌入到其他系统中。ZipPy的背景信息显示,它是作为对现有大型语言模型检测系统的补充,这些系统通常使用大型模型来计算每个词的概率,而ZipPy提供了一种更快的近似方法。
Chonkie是一个为检索增强型生成(RAG)应用设计的文本分块库,它轻量级、快速,并且易于使用。该库提供了多种文本分块方法,支持多种分词器,并且具有高性能。Chonkie的主要优点包括丰富的功能、易用性、快速处理速度、广泛的支持和轻量级的设计。它适用于需要高效处理文本数据的开发者和研究人员,特别是在自然语言处理和机器学习领域。Chonkie是开源的,遵循MIT许可证,可以免费使用。
Fast GraphRAG是一个为可解释、高精度、代理驱动的检索工作流程而设计的流线型和可提示的框架。它通过构建图谱来提供人类可导航的知识视图,支持查询、可视化和更新。该框架旨在大规模运行,无需沉重的资源或成本要求,自动生成和优化图谱以适应特定领域和本体需求,并支持实时更新。Fast GraphRAG利用PageRank基于图的探索,增强了准确性和可靠性,并且完全异步,提供完整的类型支持,以实现健壮和可预测的工作流程。
askrepo是一个基于LLM(大型语言模型)的源代码阅读工具,它能够读取Git管理的文本文件内容,发送至Google Gemini API,并根据指定的提示提供问题的答案。该产品代表了自然语言处理和机器学习技术在代码分析领域的应用,其主要优点包括能够理解和解释代码的功能,帮助开发者快速理解新项目或复杂代码库。产品背景信息显示,askrepo适用于需要深入理解代码的场景,尤其是在代码审查和维护阶段。该产品是开源的,可以免费使用。
O1-Journey是由上海交通大学GAIR研究组发起的一个项目,旨在复制和重新想象OpenAI的O1模型的能力。该项目提出了“旅程学习”的新训练范式,并构建了首个成功整合搜索和学习在数学推理中的模型。这个模型通过试错、纠正、回溯和反思等过程,成为处理复杂推理任务的有效方法。
paper-reviewer是一个开源项目,旨在自动化地从arXiv论文生成全面的评审,并将其转化为博客文章。该项目提供了一套工具,帮助用户构建自己的论文评审博客。它通过两个Python脚本collect.py和convert.py实现,分别用于收集和生成评审以及将评审转化为博客文章。该工具对于研究人员和学术工作者来说非常有用,因为它可以节省他们评审论文的时间,并帮助他们更有效地分享研究成果。
SELA是一个创新系统,它通过将蒙特卡洛树搜索(MCTS)与基于大型语言模型(LLM)的代理结合起来,增强了自动化机器学习(AutoML)。传统的AutoML方法经常产生低多样性和次优的代码,限制了它们在模型选择和集成方面的有效性。SELA通过将管道配置表示为树,使代理能够智能地探索解决方案空间,并根据实验反馈迭代改进其策略。
LongRAG是一个基于大型语言模型(LLM)的双视角、鲁棒的检索增强型生成系统范式,旨在增强对复杂长文本知识的理解和检索能力。该模型特别适用于长文本问答(LCQA),能够处理全局信息和事实细节。产品背景信息显示,LongRAG通过结合检索和生成技术,提升了对长文本问答任务的性能,特别是在需要多跳推理的场景中。该模型是开源的,可以免费使用,主要面向研究者和开发者。
ROCKET-1是一个视觉-语言模型(VLMs),专门针对开放世界环境中的具身决策制定而设计。该模型通过视觉-时间上下文提示协议,将VLMs与策略模型之间的通信连接起来,利用来自过去和当前观察的对象分割来指导策略-环境交互。ROCKET-1通过这种方式,能够解锁VLMs的视觉-语言推理能力,使其能够解决复杂的创造性任务,尤其是在空间理解方面。ROCKET-1在Minecraft中的实验表明,该方法使代理能够完成以前无法实现的任务,突出了视觉-时间上下文提示在具身决策制定中的有效性。
KAG(Knowledge Augmented Generation)是一个专业的领域知识服务框架,旨在通过知识图谱和向量检索的优势,双向增强大型语言模型和知识图谱,解决RAG(Retrieval Augmentation Generation)技术在向量相似性与知识推理相关性之间的大差距、对知识逻辑不敏感等问题。KAG在多跳问答任务上的表现显著优于NaiveRAG、HippoRAG等方法,例如在hotpotQA上的F1分数相对提高了19.6%,在2wiki上提高了33.5%。KAG已成功应用于蚂蚁集团的两个专业知识问答任务中,包括政务问答和健康问答,与RAG方法相比,专业性得到了显著提升。
Aya Expanse是一个具有高级多语言能力的开放权重研究模型。它专注于将高性能的预训练模型与Cohere For AI一年的研究成果相结合,包括数据套利、多语言偏好训练、安全调整和模型合并。该模型是一个强大的多语言大型语言模型,服务于23种语言,包括阿拉伯语、中文(简体和繁体)、捷克语、荷兰语、英语、法语、德语、希腊语、希伯来语、印地语、印尼语、意大利语、日语、韩语、波斯语、波兰语、葡萄牙语、罗马尼亚语、俄语、西班牙语、土耳其语、乌克兰语和越南语。
Meta Lingua 是一个轻量级、高效的大型语言模型(LLM)训练和推理库,专为研究而设计。它使用了易于修改的PyTorch组件,使得研究人员可以尝试新的架构、损失函数和数据集。该库旨在实现端到端的训练、推理和评估,并提供工具以更好地理解模型的速度和稳定性。尽管Meta Lingua目前仍在开发中,但已经提供了多个示例应用来展示如何使用这个代码库。
Langtrace是一个开源的可观测性工具,用于收集和分析追踪和指标,帮助提升大型语言模型(LLM)应用的性能。它支持OpenTelemetry标准追踪,可自我托管,避免供应商锁定。Langtrace提供端到端的可观测性,帮助用户全面了解整个机器学习流程,包括RAG或微调模型。此外,Langtrace还支持建立反馈循环,通过追踪的LLM交互创建黄金数据集,不断测试和增强AI应用。
Tost AI是一个免费、非盈利、开源的服务,它为最新的AI论文提供推理服务,使用非盈利GPU集群。Tost AI不存储任何推理数据,所有数据在12小时内过期。此外,Tost AI提供将数据发送到Discord频道的选项。每个账户每天提供100个免费钱包余额,如果希望每天获得1100个钱包余额,可以订阅GitHub赞助者或Patreon。Tost AI将演示的所有利润都发送给论文的第一作者,其预算由公司和个人赞助者支持。
MInference 1.0 是一种稀疏计算方法,旨在加速长序列处理的预填充阶段。它通过识别长上下文注意力矩阵中的三种独特模式,实现了对长上下文大型语言模型(LLMs)的动态稀疏注意力方法,加速了1M token提示的预填充阶段,同时保持了LLMs的能力,尤其是检索能力。
FiddleCube是一个专注于数据科学领域的产品,它能够快速地从用户的数据中生成问答对,帮助用户评估大型语言模型(LLMs)。它提供了准确的黄金数据集,支持多种问题类型,并能够通过度量标准来评估数据的准确性。此外,FiddleCube还提供了诊断工具,帮助用户找出并改进性能不佳的查询。
SuperCLUE是一个用于评估和比较大型语言模型性能的在线平台。它提供了多种任务和排行榜,旨在为AI研究者和开发者提供一个标准化的测试环境。SuperCLUE支持各种AI应用场景,包括数学推理、代码生成、超长文本处理等,能够帮助用户准确评估模型在不同任务上的表现和能力。
Berkeley Function-Calling Leaderboard(伯克利函数调用排行榜)是一个专门用来评估大型语言模型(LLMs)准确调用函数(或工具)能力的在线平台。该排行榜基于真实世界数据,定期更新,提供了一个衡量和比较不同模型在特定编程任务上表现的基准。它对于开发者、研究人员以及对AI编程能力有兴趣的用户来说是一个宝贵的资源。
HyperCrawl是第一个为LLM(大型语言模型)和RAG(检索增强生成模型)应用设计的网络爬虫,旨在开发强大的检索引擎。它通过引入多种先进方法,显著减少了域名的爬取时间,提高了检索过程的效率。HyperCrawl是HyperLLM的一部分,致力于构建未来LLM的基础设施,这些模型需要更少的计算资源,并且性能超越现有的任何模型。
StarSearch是一个专注于git历史和贡献者分析的在线工具,它能够帮助用户快速获取有关贡献者活动的信息,识别关键贡献者,以及基于工作内容找到特定领域的专家。该工具对于开源项目维护者、开发者和团队领导者来说极为重要,因为它可以提高项目管理效率,优化团队协作,并促进技术社区的交流与合作。StarSearch是我们基于人工智能的功能,可以深入了解贡献者的历史和活动,带来透明度和对开源项目的全新深度认知。
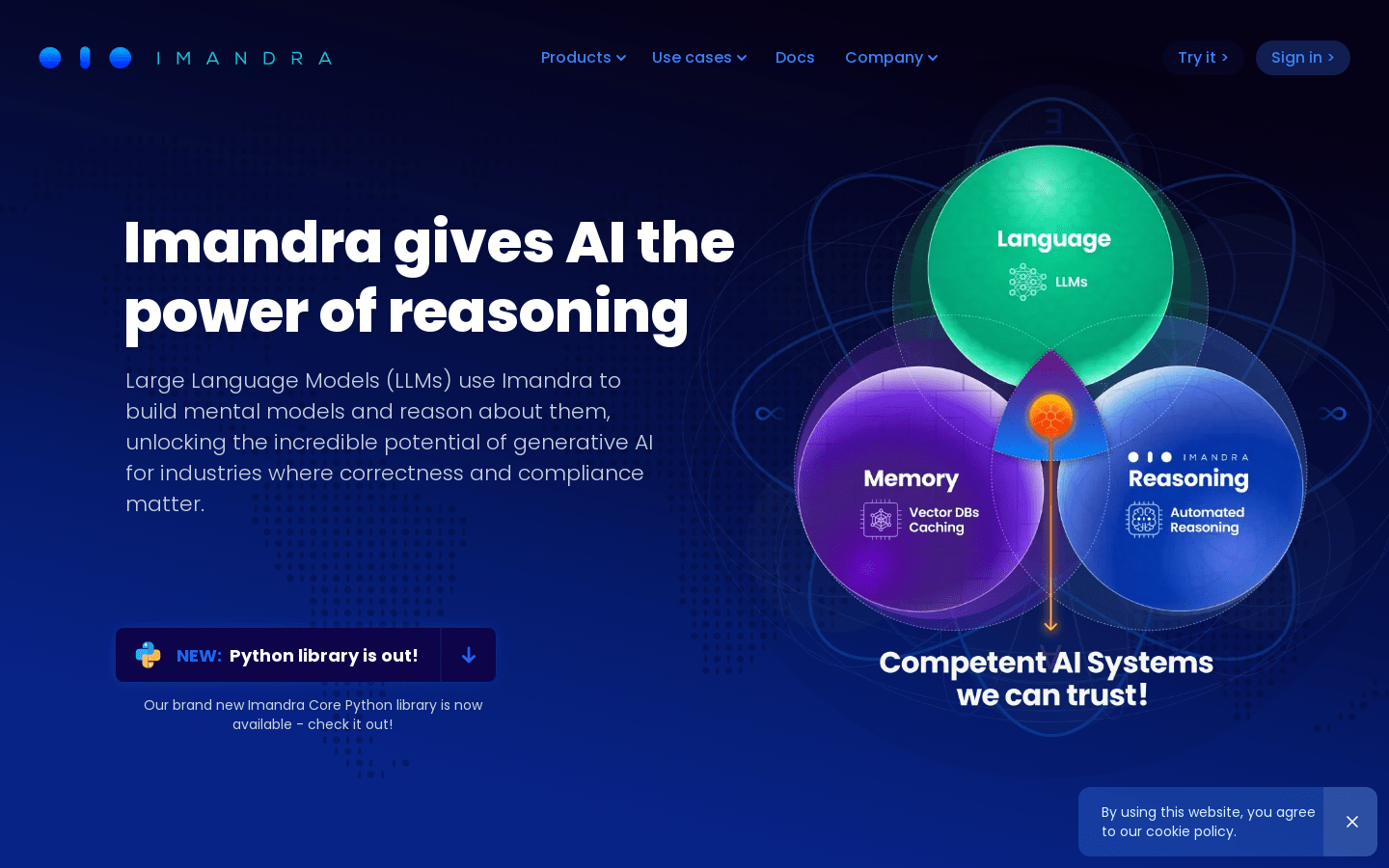
Imandra是一款基于自动推理和形式验证技术的AI工具套件。无论您是编写关键代码还是需要了解系统可能做出的无数复杂决策,使用Imandra可确保您创建的算法安全、可解释和公平。
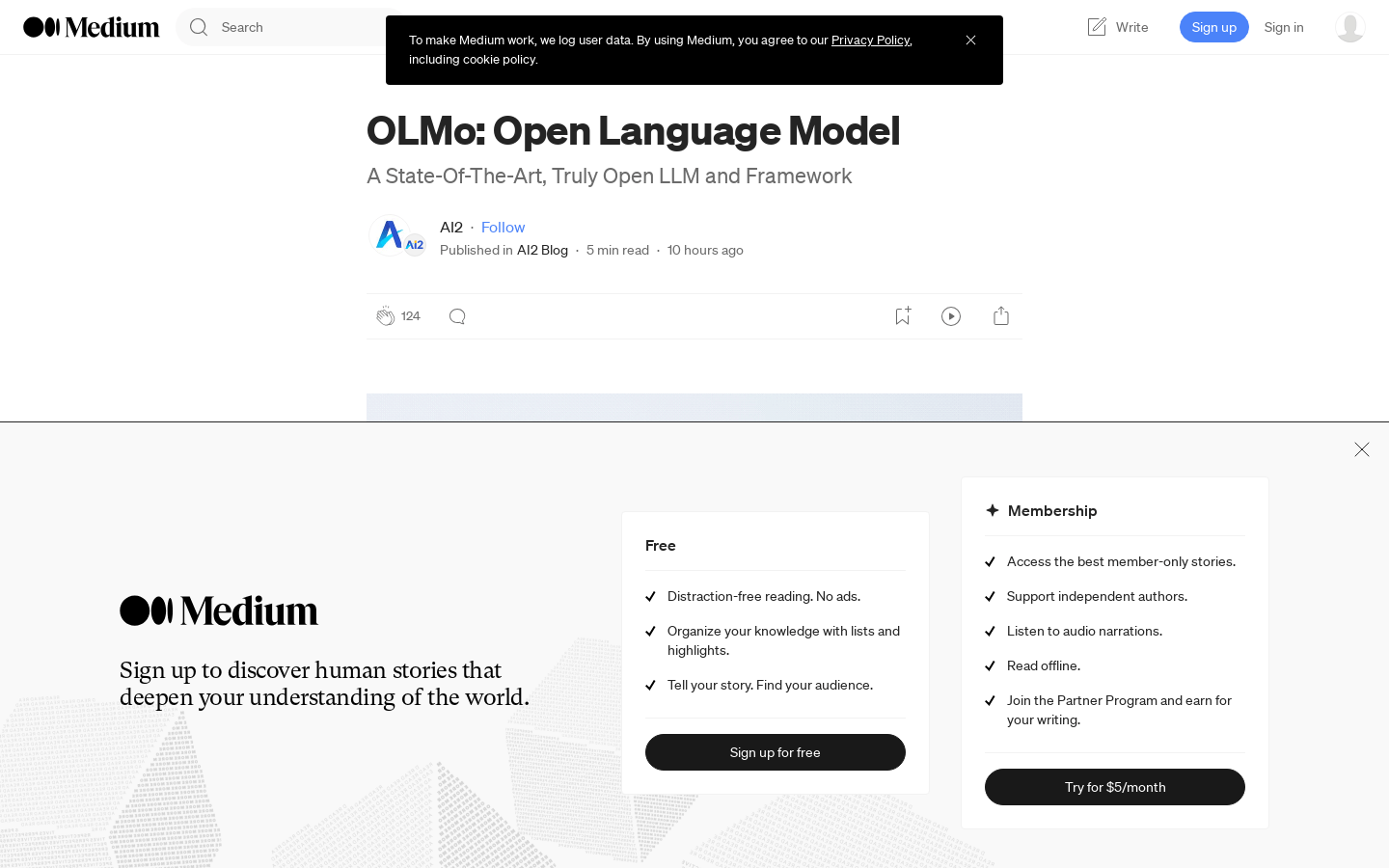
OLMo是一个开源的语言模型和训练框架,由AI2研究院发布。它提供了完整的训练数据、代码、模型参数、评估代码等资源,使研究人员能够训练并实验大规模语言模型。OLMo的优势在于真正开放,用户可以访问从数据到模型的完整信息,辅以丰富的文档,便于研究人员进行开放式研究和协作。该框架降低了语言模型研究的门槛,使更多人参与进来推动语言模型技术进步。
NLTK是一个领先的Python平台,用于处理人类语言数据。它提供了易于使用的接口,用于访问50多个语料库和词汇资源,如WordNet,并提供了一套文本处理库,用于分类、标记、解析和语义推理。它还提供了工业级NLP库的封装,并有一个活跃的讨论论坛。NLTK适用于语言学家、工程师、学生、教育者、研究人员和行业用户。NLTK可以免费使用,并且是一个开源的社区驱动项目。
Cerelyze是一个为工程师、研究人员和学者设计的工具,能够将技术研究论文转化为可用的代码。它提供了三个主要功能:1. 理解:通过与论文进行有意义的对话,深入理解研究论文。2. 实施:自动将论文中讨论的方法转化为Python代码或逐步说明,节省时间和精力。3. 运行:通过运行示例案例,快速了解论文并查看输出结果。Cerelyze还支持处理方程、表格和图形数据,并能够帮助工程师快速原型化算法,加速创新。
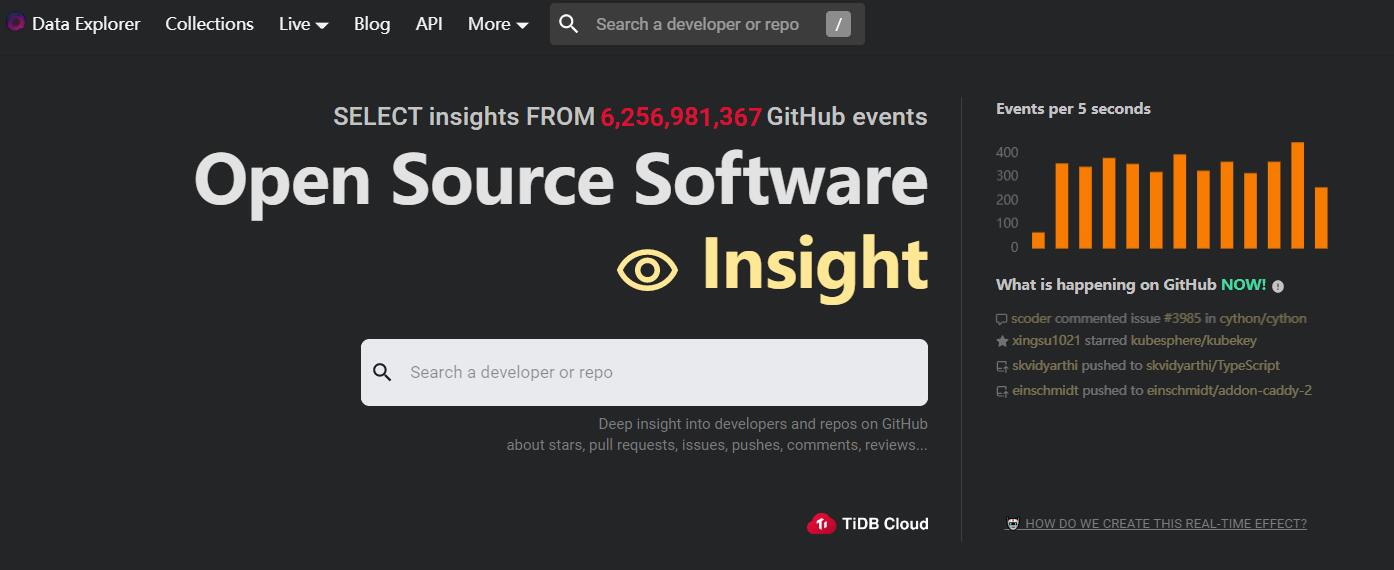
GitHub数据探索器是一款基于AI生成SQL的工具,能够让用户通过自然语言提问,生成相应的SQL查询语句,并可视化展示结果。它可以帮助用户无需具备SQL或绘图技能,快速地探索GitHub数据。GitHub数据探索器的数据源来自GH Archive,一个记录和存档GitHub事件数据的非营利项目。该工具适用于编程领域的数据分析和研究。
探索 编程 分类下的其他子分类
768 个工具
465 个工具
368 个工具
294 个工具
140 个工具
85 个工具
66 个工具
61 个工具
研究工具 是 编程 分类下的热门子分类,包含 61 个优质AI工具