共找到 63 个AI工具
点击任意工具查看详细信息
Image Describer图像描述生成器是一款利用人工智能技术,通过上传图像并根据用户需求输出图像描述的工具。它能够理解图像内容,并生成详细的描述或解释,帮助用户更好地理解图片含义。这款工具不仅适用于普通用户,还能辅助视障人士通过文本转语音功能了解图片内容。图像描述生成器的重要性在于它能够提升图像内容的可访问性,增强信息的传播效率。
Viewly是一款强大的AI图片识别应用,它能够识别图片中的内容,并通过AI技术进行作诗和翻译成多国语言。它代表了当前人工智能在图像识别和语言处理领域的前沿技术,主要优点包括高识别准确率、多语言支持和创造性的AI作诗功能。Viewly的背景信息显示,它是一个持续更新的产品,致力于为用户提供更多创新功能。目前,产品是免费提供给用户的。
PimEyes是一个利用面部识别技术提供反向图片搜索服务的网站,用户可以通过上传照片来查找互联网上与该照片相似的图片或个人信息。这项服务在保护隐私、寻找失踪人口以及版权验证等方面具有重要价值。PimEyes通过其先进的算法,为用户提供了一个强大的工具,以帮助他们在网络上查找和识别图像。
Ultralytics YOLO11是基于之前YOLO系列模型的进一步发展,引入了新特性和改进,以提高性能和灵活性。YOLO11旨在快速、准确、易于使用,非常适合广泛的目标检测、跟踪、实例分割、图像分类和姿态估计任务。
Revisit Anything 是一个视觉位置识别系统,通过图像片段检索技术,能够识别和匹配不同图像中的位置。它结合了SAM(Spatial Attention Module)和DINO(Distributed Knowledge Distillation)技术,提高了视觉识别的准确性和效率。该技术在机器人导航、自动驾驶等领域具有重要的应用价值。
Joy Caption Alpha One 是一款基于人工智能的图像描述生成器,能够将图片内容转化为文字描述。它利用深度学习技术,通过理解图片中的物体、场景和动作,生成准确且生动的描述。这项技术在辅助视障人士理解图片内容、增强图片搜索功能以及提升社交媒体内容的可访问性方面具有重要意义。
OpenCV是一个跨平台的开源计算机视觉和机器学习软件库,它提供了一系列编程功能,包括但不限于图像处理、视频分析、特征检测、机器学习等。该库广泛应用于学术研究和商业项目中,因其强大的功能和灵活性而受到开发者的青睐。
GOT-OCR2.0是一个开源的OCR模型,旨在通过一个统一的端到端模型推动光学字符识别技术向OCR-2.0迈进。该模型支持多种OCR任务,包括但不限于普通文本识别、格式化文本识别、细粒度OCR、多裁剪OCR和多页OCR。它基于最新的深度学习技术,能够处理复杂的文本识别场景,并且具有较高的准确率和效率。
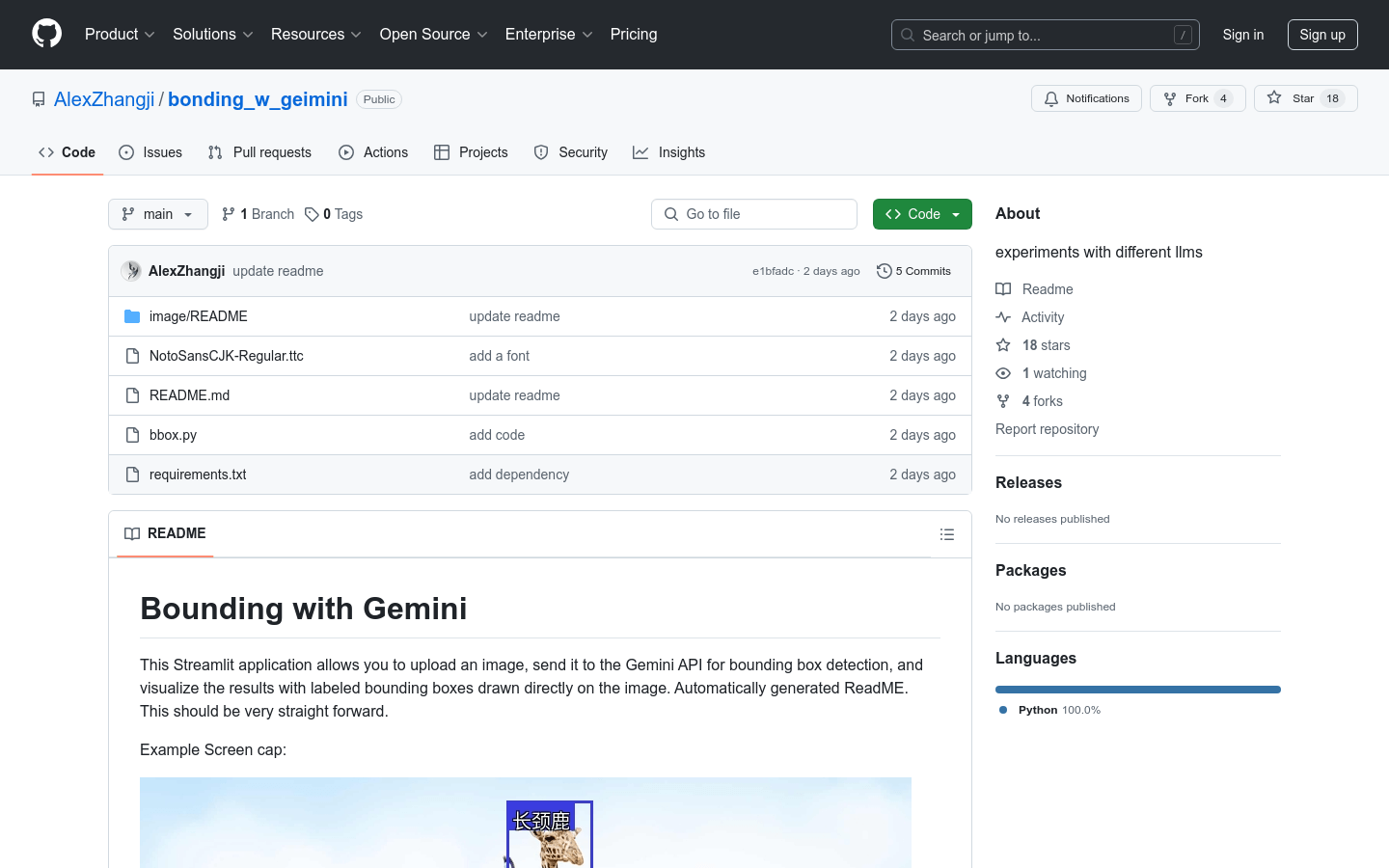
bonding_w_geimini是一个基于Streamlit框架开发的图像处理应用,它允许用户上传图片,通过Gemini API进行物体检测,并在图片上直接绘制出物体的边界框。这个应用利用了机器学习模型来识别和定位图片中的物体,对于图像分析、数据标注和自动化图像处理等领域具有重要意义。
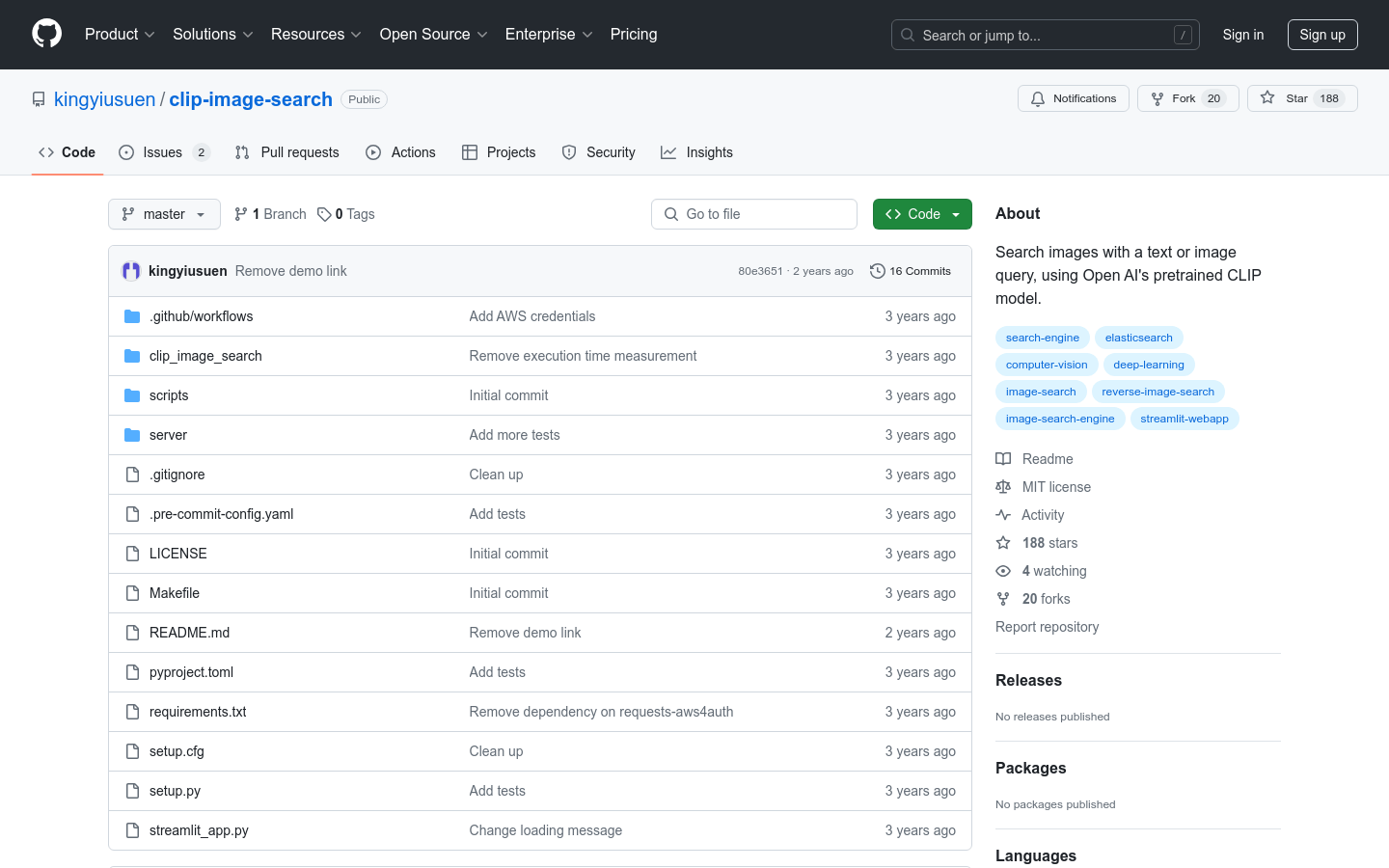
clip-image-search是一个基于Open AI的预训练CLIP模型的图像搜索工具,能够通过文本或图片查询来检索图片。CLIP模型通过训练将图像和文本映射到同一潜在空间,使得可以通过相似度度量进行比较。该工具使用Unsplash数据集中的图片,并利用Amazon Elasticsearch Service进行k-最近邻搜索,通过AWS Lambda函数和API网关部署查询服务,前端使用Streamlit开发。
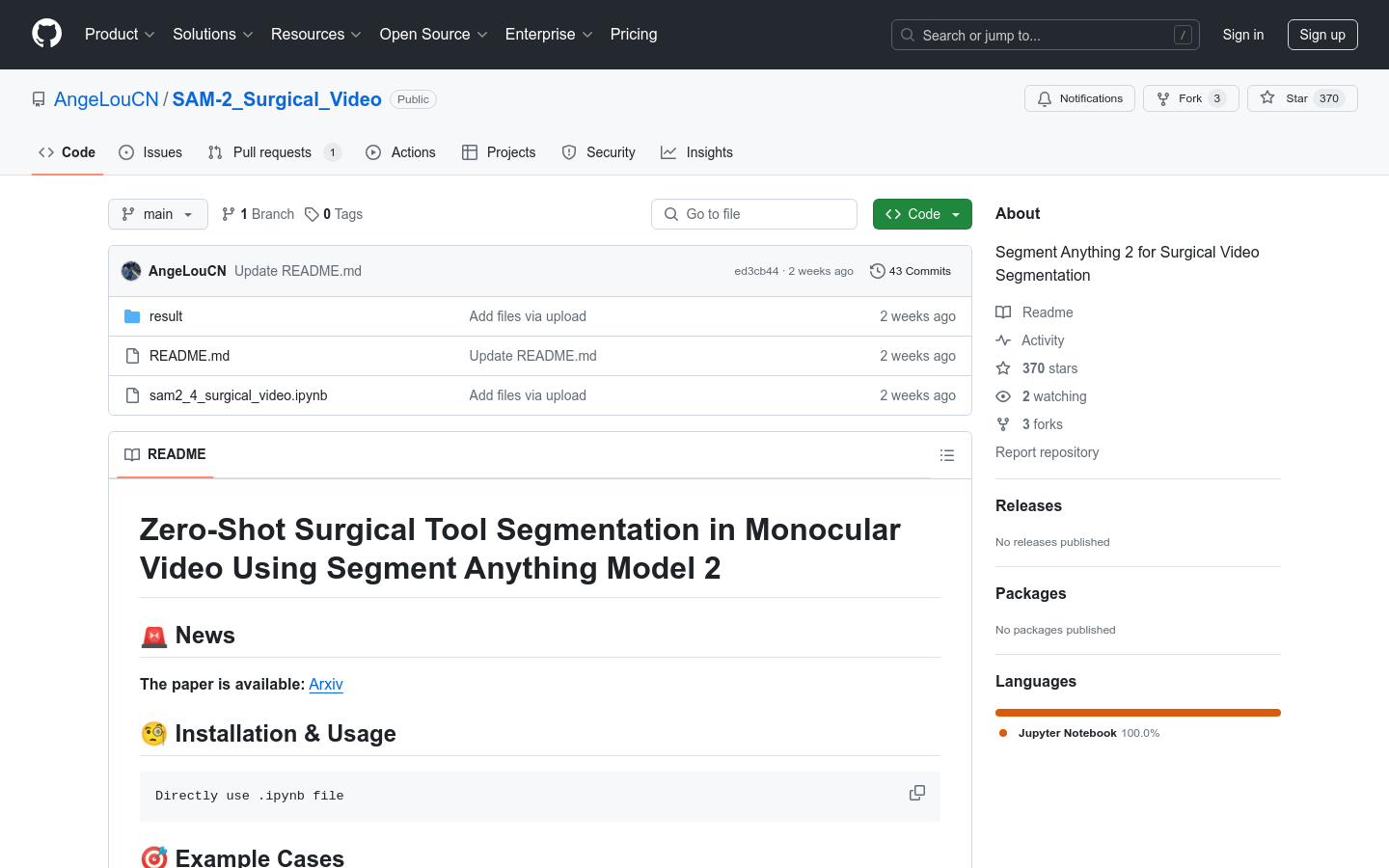
Segment Anything 2 for Surgical Video Segmentation 是一个基于Segment Anything Model 2的手术视频分割模型。它利用先进的计算机视觉技术,对手术视频进行自动分割,以识别和定位手术工具,提高手术视频分析的效率和准确性。该模型适用于内窥镜手术、耳蜗植入手术等多种手术场景,具有高精度和高鲁棒性的特点。
SAM-guided Graph Cut for 3D Instance Segmentation是一种利用3D几何和多视图图像信息进行3D实例分割的深度学习方法。该方法通过3D到2D查询框架,有效利用2D分割模型进行3D实例分割,通过图割问题构建超点图,并通过图神经网络训练,实现对不同类型场景的鲁棒分割性能。
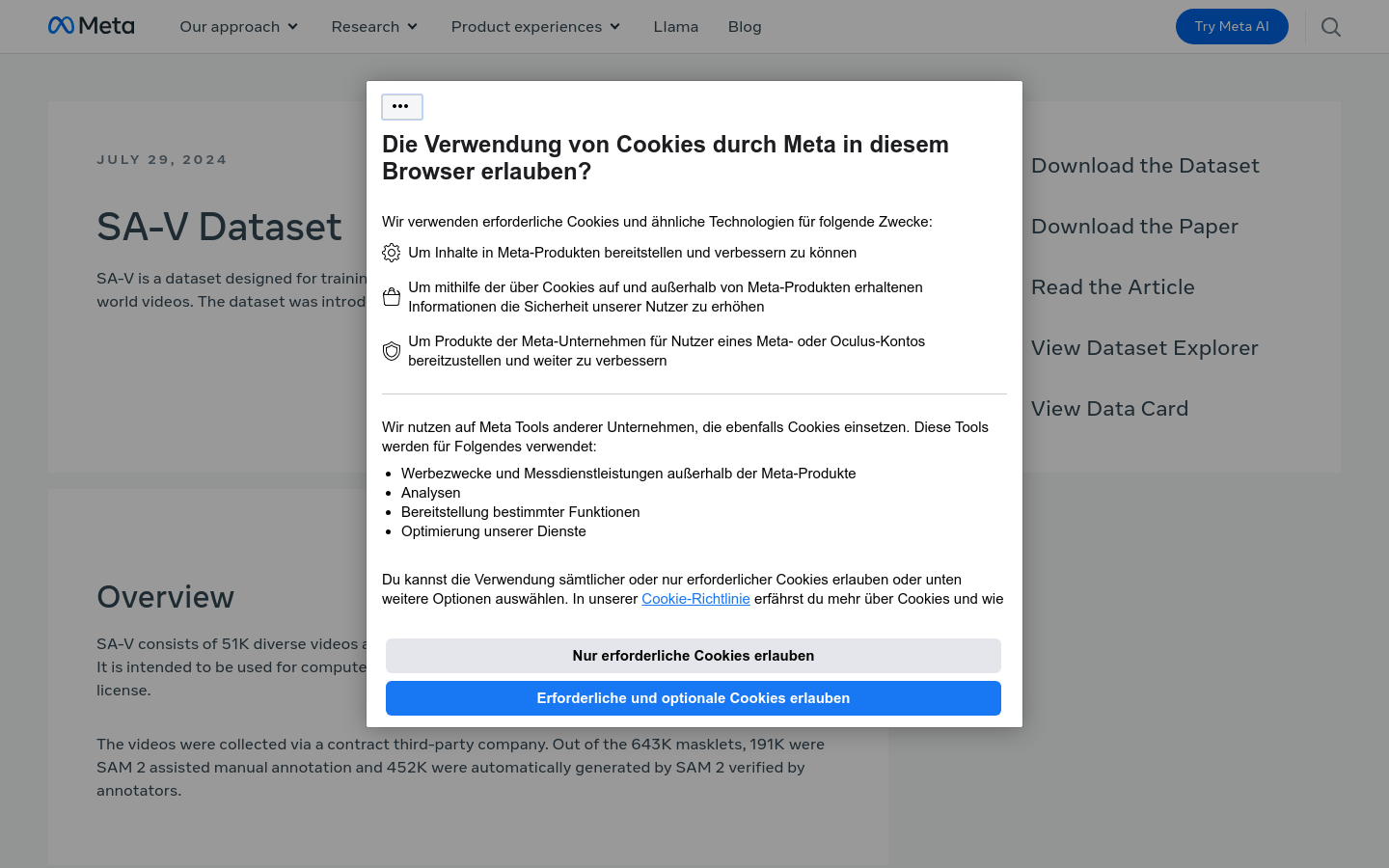
SA-V Dataset是一个专为训练通用目标分割模型设计的开放世界视频数据集,包含51K个多样化视频和643K个时空分割掩模(masklets)。该数据集用于计算机视觉研究,允许在CC BY 4.0许可下使用。视频内容多样,包括地点、对象和场景等主题,掩模从建筑物等大规模对象到室内装饰等细节不等。
Segment Anything Model 2 (SAM 2)是Meta公司AI研究部门FAIR推出的一个视觉分割模型,它通过简单的变换器架构和流式内存设计,实现实时视频处理。该模型通过用户交互构建了一个模型循环数据引擎,收集了迄今为止最大的视频分割数据集SA-V。SAM 2在该数据集上训练,提供了在广泛任务和视觉领域中的强大性能。
Meta Segment Anything Model 2 (SAM 2)是Meta公司开发的下一代模型,用于视频和图像中的实时、可提示的对象分割。它实现了最先进的性能,并且支持零样本泛化,即无需定制适配即可应用于之前未见过的视觉内容。SAM 2的发布遵循开放科学的方法,代码和模型权重在Apache 2.0许可下共享,SA-V数据集也在CC BY 4.0许可下共享。
RapidLayout是一个专注于文档图像版面分析的开源工具,能够对文档类别图像进行版面结构分析,定位标题、段落、表格和图片等各个部分。它支持多种语言和场景的版面分析,包括中文和英文,能够满足不同业务场景的需求。
roboflow/sports 是一个开源的计算机视觉工具集,专注于体育领域的应用。它利用先进的图像处理技术,如目标检测、图像分割、关键点检测等,来解决体育分析中的挑战。这个工具集由Roboflow开发,旨在推动计算机视觉技术在体育领域的应用,并通过社区贡献不断优化。
Album AI是一个实验性项目,它使用gpt-4o-mini作为视觉模型,自动识别相册中图像文件的元数据,并利用RAG技术实现与相册的对话。它既可以作为传统相册使用,也可以作为图像知识库,辅助大型语言模型进行内容生成。
TruthPix是一款AI图像检测工具,旨在帮助用户识别经过AI篡改的照片。该应用通过先进的AI技术,能够快速、准确地识别出图像中的克隆和篡改痕迹,从而避免用户在社交媒体等平台上被虚假信息误导。该应用的主要优点包括:安全性高,所有检测都在设备上完成,不上传数据;检测速度快,分析一张图片仅需不到400毫秒;支持多种AI生成图像的检测技术,如GANs、Diffusion Models等。
MASt3R是由Naver Corporation开发的一种用于3D图像匹配的先进模型,它专注于提升计算机视觉领域中的几何3D视觉任务。该模型利用了最新的深度学习技术,通过训练能够实现对图像之间精确的3D匹配,对于增强现实、自动驾驶以及机器人导航等领域具有重要意义。
image-textualization 是一个自动框架,用于生成丰富和详细的图像描述。该框架利用深度学习技术,能够自动从图像中提取信息,并生成准确、详细的描述文本。这项技术在图像识别、内容生成和辅助视觉障碍人士等领域具有重要应用价值。
HunyuanCaptioner是一款基于LLaVA实现的文本到图像技术模型,能够生成与图像高度一致的文本描述,包括物体描述、物体关系、背景信息、图像风格等。它支持中文和英文的单图和多图推理,并可通过Gradio进行本地演示。
Florence-2是由微软开发的高级视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示,执行诸如图像描述、目标检测和分割等任务。它利用FLD-5B数据集,包含54亿个注释,覆盖1.26亿张图像,精通多任务学习。其序列到序列的架构使其在零样本和微调设置中均表现出色,证明是一个有竞争力的视觉基础模型。
Florence-2-large是由微软开发的先进视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示来执行如图像描述、目标检测和分割等任务。它利用包含54亿注释的5.4亿图像的FLD-5B数据集,精通多任务学习。其序列到序列的架构使其在零样本和微调设置中均表现出色,证明是一个有竞争力的视觉基础模型。
emo-visual-data 是一个公开的表情包视觉标注数据集,它通过使用 glm-4v 和 step-free-api 项目完成的视觉标注,收集了5329个表情包。这个数据集可以用于训练和测试多模态大模型,对于理解图像内容和文本描述之间的关系具有重要意义。
Grounding DINO 1.5是由IDEA Research开发,旨在推进开放世界目标检测技术边界的高级模型系列。该系列包含两个模型:Grounding DINO 1.5 Pro和Grounding DINO 1.5 Edge,分别针对广泛的应用场景和边缘计算场景进行了优化。
PaliGemma是Google发布的一款先进的视觉语言模型,它结合了图像编码器SigLIP和文本解码器Gemma-2B,能够理解图像和文本,并通过联合训练实现图像和文本的交互理解。该模型专为特定的下游任务设计,如图像描述、视觉问答、分割等,是研究和开发领域的重要工具。
AI Image Description Generator 是一个基于ERNIE 3.5或GEMINI-PRO-1.5 API的图像描述生成器,能够准确提取图像中的关键元素,并解读其背后的创作意图。它支持多语言,集成了clerk.com用户管理平台,并使用Next.js构建全栈Web应用程序。该技术在科学研究、艺术创作以及图像与文本之间的互搜领域有广泛应用。
ImageInWords (IIW) 是一个由人类参与的循环注释框架,用于策划超详细的图像描述,并生成一个新的数据集。该数据集通过评估自动化和人类并行(SxS)指标来实现最先进的结果。IIW 数据集在生成描述时,比以往的数据集和GPT-4V输出在多个维度上有了显著提升,包括可读性、全面性、特异性、幻觉和人类相似度。此外,使用IIW数据微调的模型在文本到图像生成和视觉语言推理方面表现出色,能够生成更接近原始图像的描述。
ImagenHub是一个一站式库,用于标准化所有条件图像生成模型的推理和评估。该项目首先定义了七个突出的任务并创建了高质量的评估数据集。其次,我们构建了一个统一的推理管道来确保公平比较。第三,我们设计了两个人工评估指标,即语义一致性和感知质量,并制定了全面的指南来评估生成的图像。我们训练专家评审员根据提出的指标来评估模型输出。该人工评估在76%的模型上实现了高的评估者间一致性。我们全面地评估了约30个模型,并观察到三个关键发现:(1)现有模型的性能普遍不令人满意,除了文本引导的图像生成和主题驱动的图像生成外,74%的模型整体得分低于0.5。(2)我们检查了已发表论文中的声明,发现83%的声明是正确的。(3)除了主题驱动的图像生成外,现有的自动评估指标都没有高于0.2的斯皮尔曼相关系数。未来,我们将继续努力评估新发布的模型,并更新排行榜以跟踪条件图像生成领域的进展。
Scenic 是一个专注于基于注意力模型的计算机视觉研究的代码库,提供优化训练和评估循环、基线模型等功能,适用于图像、视频、音频等多模态数据。提供 SOTA 模型和基线,支持快速原型设计,价格免费。
SPRIGHT是一个专注于空间关系的大规模视觉语言数据集和模型。它通过重新描述600万张图像构建了SPRIGHT数据集,显著增加了描述中的空间短语。该模型在444张包含大量物体的图像上进行微调训练,从而优化生成具有空间关系的图像。SPRIGHT在多个基准测试中实现了空间一致性的最新水平,同时提高了图像质量评分。
ComfyUI-PixelArt-Detector是一个用于检测像素艺术的开源工具,它可以集成到ComfyUI中,帮助用户识别和处理像素艺术图像。
Griffon 是第一个具有本地化能力的高分辨率(超过1K)LVLM,可以描述您感兴趣的区域中的所有内容。在最新版本中,Griffon 支持视觉语言共指。您可以输入图像或一些描述。Griffon 在 REC、目标检测、目标计数、视觉/短语定位和 REG 方面表现出色。定价:免费试用。
magi是一个用于自动为漫画生成文本记录的模型,它能够检测漫画中的角色、文本块和面板,并将它们按照正确的顺序排列。此外,该模型还能够聚类角色,将文本与其对应的说话者匹配,并执行OCR以提取文本。
极空间AI实验室是北京天顶星智能信息技术有限公司推出的家庭私有云产品中的新功能。它包括自然语言搜索、相似图片搜索和图片文字识别等功能,旨在帮助用户更快捷地管理和使用存储在极空间中的图片。
yolov9是YOLOv9论文的实现,它通过使用可编程梯度信息来学习用户想要学习的内容。这个项目是一个开源的深度学习模型,主要用于目标检测任务,具有高效和准确的优势。
YOLOv8是YOLO系列目标检测模型的最新版本,能够在图像或视频中准确快速地识别和定位多个对象,并实时跟踪它们的移动。相比之前版本,YOLOv8在检测速度和精确度上都有很大提升,同时支持多种额外的计算机视觉任务,如实例分割、姿态估计等。YOLOv8可通过多种格式部署在不同硬件平台上,提供一站式的端到端目标检测解决方案。
Vision Arena是一个由Hugging Face创建的开源平台,用于测试和比较不同的计算机视觉模型效果。它提供了一个友好的界面,允许用户上传图片并通过不同模型处理,从而直观地对比结果质量。平台预装了主流的图像分类、对象检测、语义分割等模型,也支持自定义模型。关键优势是开源免费,使用简单,支持多模型并行测试,有利于模型效果评估和选择。适用于计算机视觉研发人员、算法工程师等角色,可以加速计算机视觉模型的实验和调优。
JoyTag是一款先进的AI视觉模型,用于为图像打标签,注重性积极和包容性。采用Danbooru标签模式,适用于手绘图到摄影等各种图像。支持超过5000个标签的多标签分类,可用于自动图像标注,适用于训练缺乏文本对的扩散模型等广泛应用。模型性能优越,基于ViT架构,采用CNN stem和GAP头。
YOLO-World是一款先进的实时开放词汇物体检测器,基于You Only Look Once (YOLO)系列检测器,并通过视觉-语言建模和大规模数据集的预训练,增强了开放词汇检测能力。其采用新的可重新参数化的视觉-语言路径聚合网络(RepVL-PAN)和区域-文本对比损失,促进了视觉和语言信息之间的交互。YOLO-World在零-shot方式下高效地检测各种对象,具有高效率。在具有挑战性的LVIS数据集上,YOLO-World在V100上实现了35.4 AP和52.0 FPS,在准确性和速度方面均优于许多最新方法。此外,经过微调的YOLO-World在多项下游任务上表现出色,包括物体检测和开放词汇实例分割。
Yi-VL-34B是 Yi Visual Language(Yi-VL)模型的开源版本,是一种多模态模型,能够理解和识别图像,并进行关于图像的多轮对话。Yi-VL 在最新的基准测试中表现出色,在 MMM 和 CMMMU 两个基准测试中均排名第一。
SPARC是一种用于图文对预训练的简单方法,旨在从图像-文本对中预训练更细粒度的多模态表示。它利用稀疏相似度度量和对图像块和语言标记进行分组,通过对比细粒度的序列损失和全局图像与文本嵌入之间的对比损失,学习同时编码全局和局部信息的表示。SPARC在粗粒度信息的图像级任务和细粒度信息的区域级任务上均表现出改进,包括分类、检索、目标检测和分割。此外,SPARC提高了模型的可信度和图像描述能力。
VMamba是一种视觉状态空间模型,结合了卷积神经网络(CNNs)和视觉Transformer(ViTs)的优势,实现了线性复杂度而不牺牲全局感知。引入了Cross-Scan模块(CSM)来解决方向敏感问题,能够在各种视觉感知任务中展现出优异的性能,并且随着图像分辨率的增加,相对已有基准模型表现出更为显著的优势。
GenSAM是一种针对迷彩对象检测(COD)的方法,它使用Cross-modal Chains of Thought Prompting (CCTP)技术来理解视觉提示,并利用通用文本提示来获取可靠的视觉提示。该方法通过渐进式掩膜生成(PMG)在测试时自动生成并优化视觉提示,无需额外训练,实现高效准确的迷彩目标分割。
Open-Vocabulary SAM是一个基于SAM和CLIP的视觉基础模型,专注于交互式分割和识别任务。它通过SAM2CLIP和CLIP2SAM两个独特的知识传输模块,实现了SAM和CLIP的统一框架。在各种数据集和检测器上的广泛实验表明,Open-Vocabulary SAM在分割和识别任务中的有效性,明显优于简单组合SAM和CLIP的朴素基准。此外,结合图像分类数据训练,该方法可以分割和识别大约22,000个类别。
Pose Anything是一种基于图形的通用姿势估计方法,旨在使关键点定位适用于任意物体类别,使用单个模型,需要最少带有注释关键点的支持图像。该方法通过全新设计的图形转换解码器利用关键点之间的几何关系,提高了关键点定位的准确性。Pose Anything在MP-100基准测试中表现优异,超过了先前的最先进技术,并在1-shot和5-shot设置下取得显著改进。与以往的CAPE方法相比,该方法的端到端训练显示出可扩展性和效率。
GenAlt生成在线图像的描述性替代文本,为那些需要的人提供帮助。只需右键单击图像,然后单击“从GenAlt获取替代文本”,即可获得图像的描述作为其替代文本。要查看生成的标题并将其复制到剪贴板上,只需选择“从GenAlt复制AI图像描述”。用户的一些GenAlt见证如下: 1. “GenAlt对我理解照片很有帮助......比现有工具好。”——无障碍倡导者和Twitch主播 2. “GenAlt真的比互联网上的其他应用程序更有帮助,帮助我更好地描述图片。”——高中二年级学生Remi 3. “GenAlt易于使用,有助于让社交媒体对我更具可访问性。”——大学新生Aaron
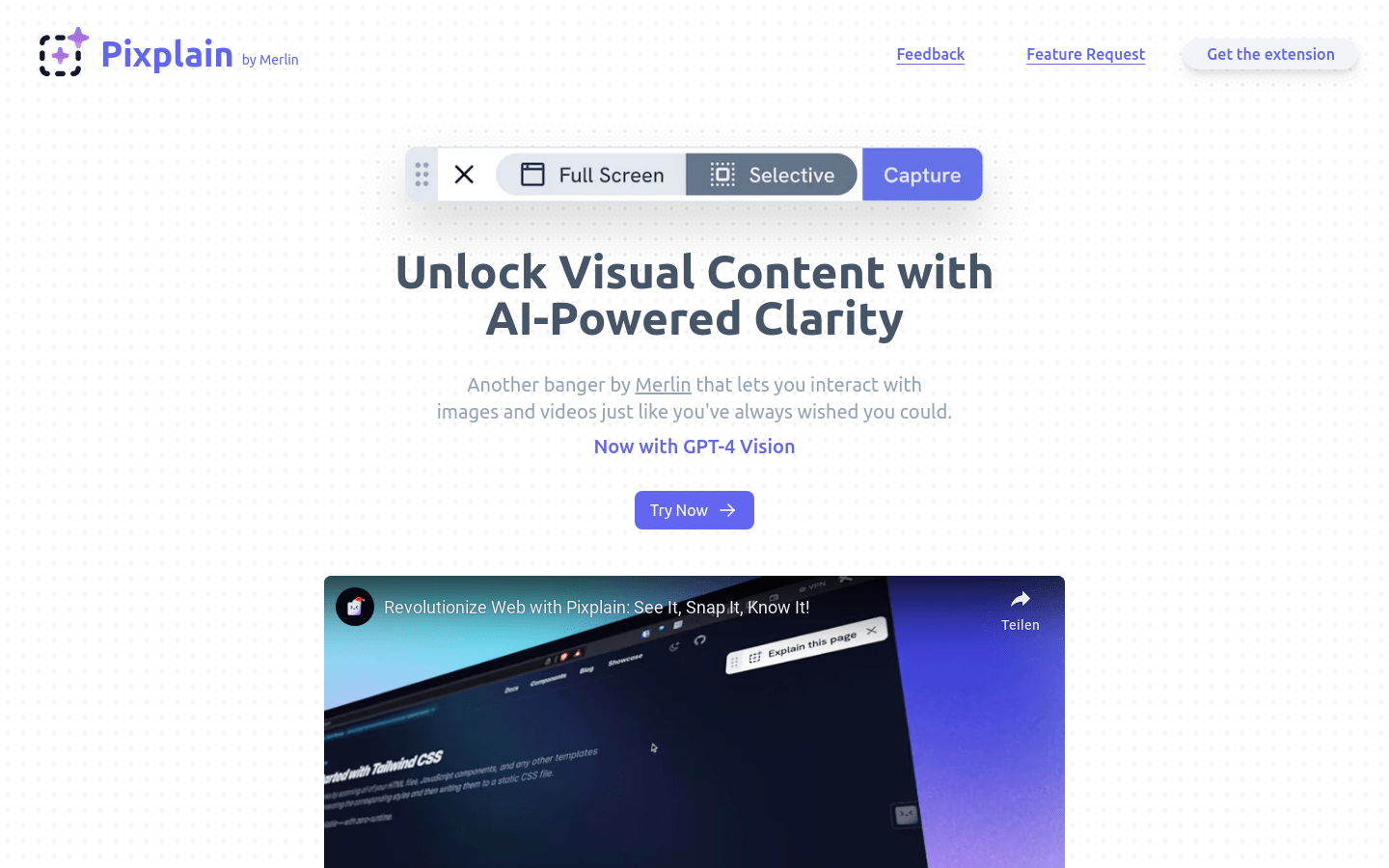
Pixplain是一个AI驱动的浏览器插件,它可以让用户与图片和视频进行交互,就像实现了你一直以来的愿望。Pixplain使用最新的AI模型比如GPT-4视觉,可以更好地理解图像内容并给出解释。 主要功能: - 一键获取图像和页面内容的解释 - 支持GPT-4等顶级AI模型 轻松复制、更新或修改提示,获得更流畅的创作体验 - 可以移动Pixplain窗口,获得最佳的页面视图
GLEE 是一个针对图片和视频的通用对象基础模型,通过统一的框架实现了定位和识别图像和视频中的对象,并能应用于各种对象感知任务。GLEE 通过联合训练来自不同监督水平的各种数据源,形成通用的对象表示,在保持最先进性能的同时,能够有效地进行零样本迁移和泛化。它还具备良好的可扩展性和鲁棒性。
Vision AI 提供了三种计算机视觉产品,包括 Vertex AI Vision、自定义机器学习模型和 Vision API。您可以使用这些产品从图像中提取有价值的信息,进行图像分类和搜索,并创建各种计算机视觉应用。Vision AI 提供简单易用的界面和功能强大的预训练模型,满足不同用户需求。
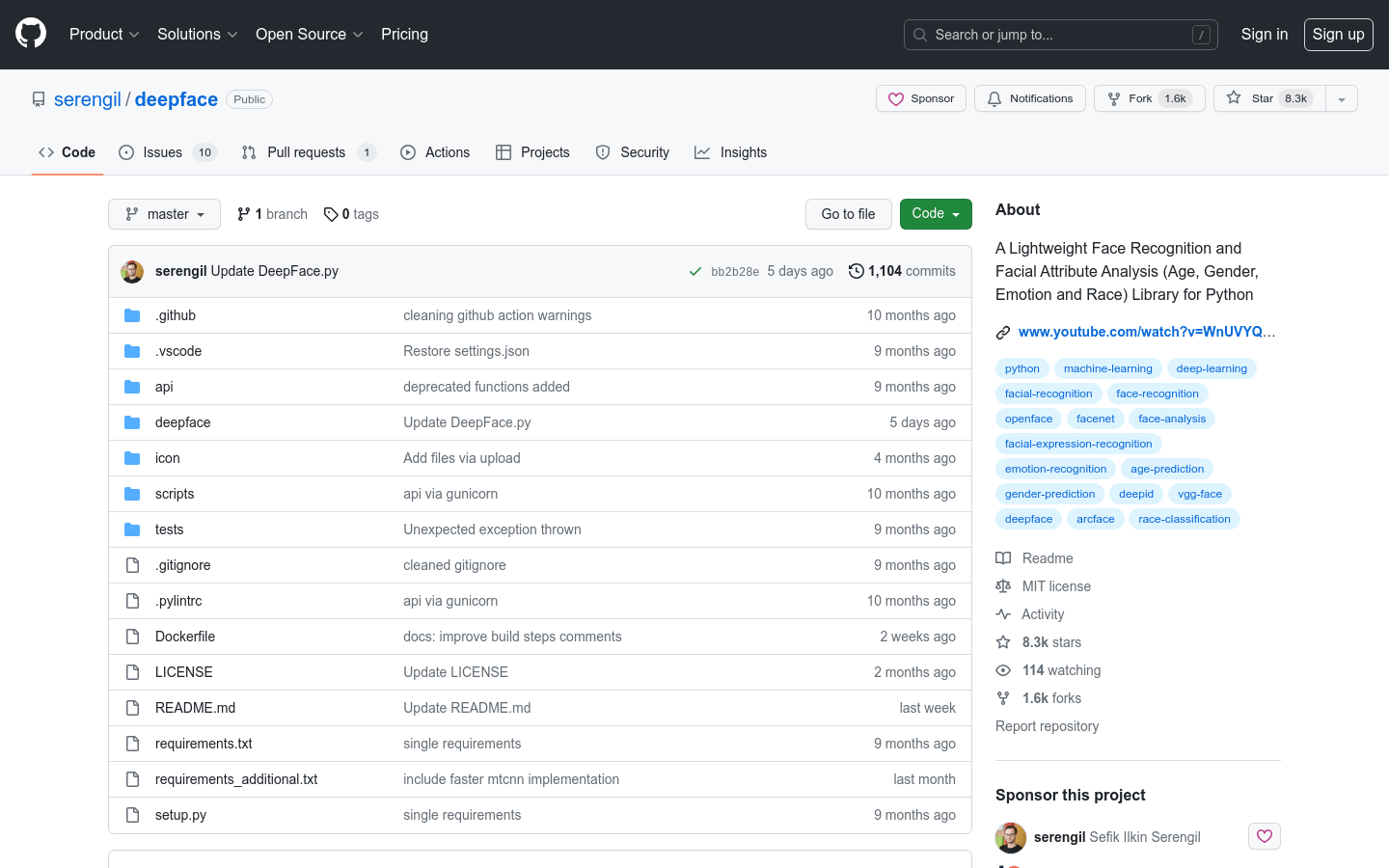
DeepFace 是一个轻量级的人脸识别和面部属性分析(年龄、性别、情绪和种族)库。它包装了最先进的模型:VGG-Face、Google FaceNet、OpenFace、Facebook DeepFace、DeepID、ArcFace、Dlib 和 SFace。该库提供了人脸验证、人脸识别、面部属性分析等功能。DeepFace 的优势在于其高准确性和多样化的模型选择。
AI VISION 是一款突破性的图像识别应用程序,利用先进的图像识别技术,能够识别图像并为您的问题提供即时答案。具有无与伦比的准确性,无论您是好奇的探索者、专注的学生还是需要快速准确信息的专业人士,AI VISION 都能满足您的需求。它还提供实时解答功能,无缝的用户体验和无限的可能性。AI VISION 适用于教育研究、旅行见解或满足好奇心,让您在每次遇到图像时做出更明智、更明智的决策。
Cola是一种使用语言模型(LM)来聚合2个或更多视觉-语言模型(VLM)输出的方法。我们的模型组装方法被称为Cola(COordinative LAnguage model or visual reasoning)。Cola在LM微调(称为Cola-FT)时效果最好。Cola在零样本或少样本上下文学习(称为Cola-Zero)时也很有效。除了性能提升外,Cola还对VLM的错误更具鲁棒性。我们展示了Cola可以应用于各种VLM(包括大型多模态模型如InstructBLIP)和7个数据集(VQA v2、OK-VQA、A-OKVQA、e-SNLI-VE、VSR、CLEVR、GQA),并且它始终提高了性能。
GenAlt是一个在线生成图像描述的辅助文本工具。只需右键点击图像,点击“获取GenAlt的替代文本”,即可获取该图像的描述作为替代文本。GenAlt得到了用户的一些好评,让使用者更好地理解图片。您可以通过安装该插件来提升图片的可访问性。
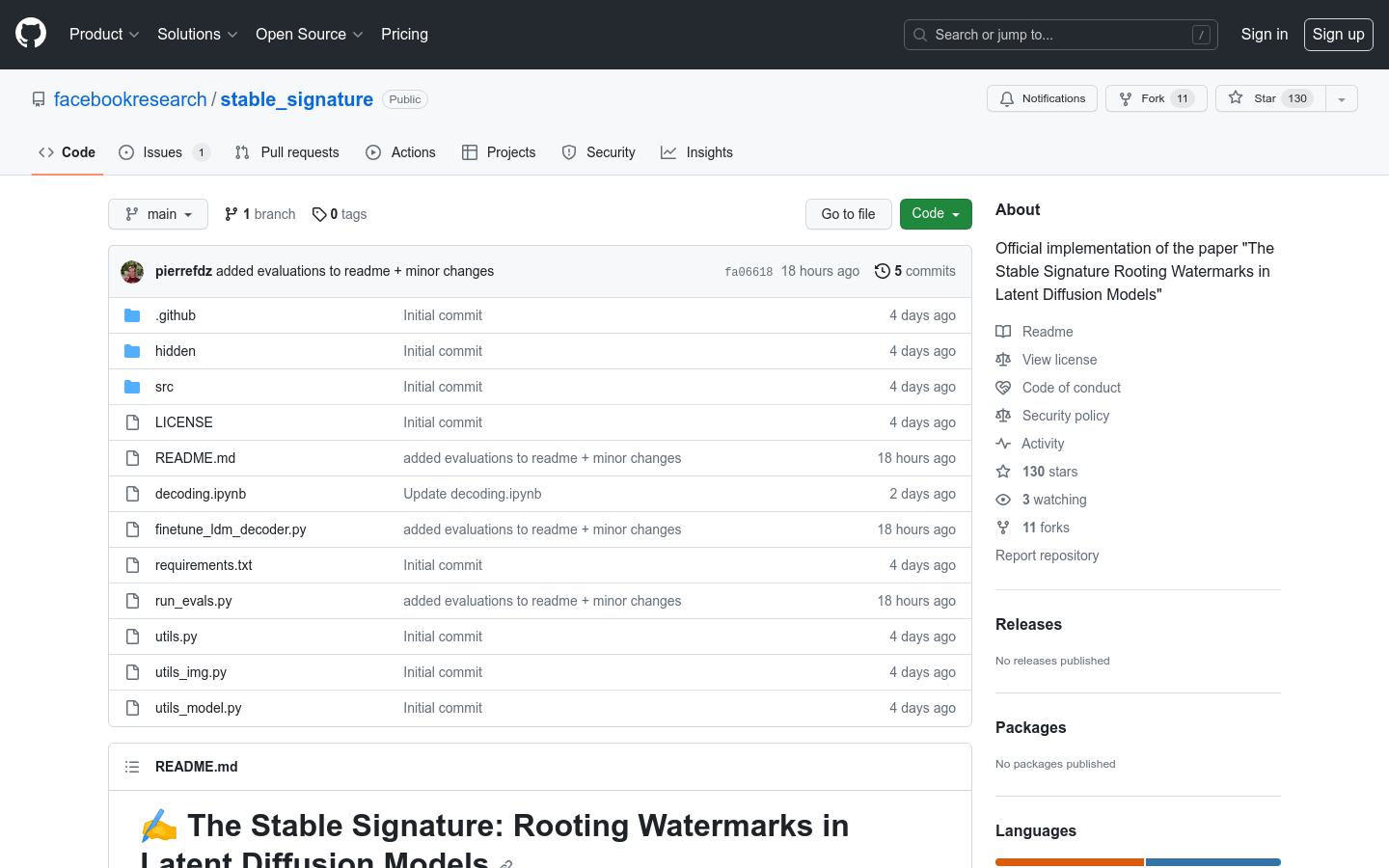
Stable Signature是一种将水印嵌入图像中的方法,它使用潜在扩散模型(LDM)来提取和嵌入水印。该方法具有高度的稳定性和鲁棒性,可以在多种攻击下保持水印的可读性。Stable Signature提供了预训练模型和代码实现,用户可以使用它来嵌入和提取水印。
Lexy是一款基于AI技术的图像文字提取工具。它可以自动识别图像中的文字,并将其提取出来,方便用户进行后续处理和分析。Lexy具有高准确性和快速的识别速度,适用于各种图像文字提取场景。无论是需要从图片中提取文字的个人用户,还是需要进行大规模图像文字处理的企业用户,Lexy都可以满足您的需求。
GenAlt使用人工智能为没有图像描述的在线图片生成描述性的替代文本!只需右键单击图像,点击GenAlt获取图像描述,即可获得图像的描述作为其替代文本。请注意:GenAlt将显示为该图像生成的标题的短暂弹出窗口。
ALT AI: 添加图片描述的Alt文本是一个可访问性工具,可为互联网上的任何页面添加Alt文本。ALT AI旨在改善视觉障碍用户的网络体验。使用ALT AI Chrome插件,可以自动为页面上的每个图像添加Alt文本,替换任何现有的不准确的Alt描述。屏幕阅读器将朗读出ALT AI生成的Alt文本,以帮助用户更好地了解页面上的内容。
AI QR Code Reader是一个基于人工智能的二维码识别插件,能够高效识别各种形状、颜色和旋转的二维码。它具有快速、准确的识别能力,可以在浏览器中方便地进行二维码扫描。无论是哪种形状、颜色和旋转角度的二维码,都能够轻松识别。通过右键点击插件图标,即可打开二维码识别界面,识别结果将以气泡弹窗的形式显示。
Bing影像建立工具是一款由Microsoft Bing提供的智能搜索工具,可以帮助用户快速找到想要的图像信息,并获得奖励。
寻找照片可以帮助您解决照片混乱的问题。使用寻找照片,您可以通过物体、文字甚至人物来轻松搜索您的照片库,利用人工智能的力量。您再也不用花费几个小时来寻找那张完美的自拍照或是您可爱狗狗的有趣照片了。寻找照片会帮您索引照片,并且只需轻轻点击几下就可以轻松搜索。此外,寻找照片不仅实用,还很有趣!您可以用它来重新发现旧时光,创建您最喜爱的照片的拼贴画。出于对您照片安全的重视,我们的应用程序配备了一流的安全功能,确保您的私密照片保持私密。您可以信任寻找照片来保护您的回忆安全。
Face Age是一款基于人工智能技术的面部肌肤分析器。它能通过扫描用户的面部照片,快速分析出用户的肌肤年龄,并提供针对性的肌肤护理建议。Face Age具有精准的分析能力和智能化的算法,能够帮助用户了解自己的肌肤状况,选择合适的护肤产品和护理方法。Face Age还支持多种语言,并提供用户友好的界面和操作流程。无论是美容爱好者还是护肤专业人士,都可以通过Face Age获得准确的肌肤分析结果。
探索 图像 分类下的其他子分类
832 个工具
771 个工具
543 个工具
522 个工具
352 个工具
196 个工具
95 个工具
68 个工具
AI图像检测识别 是 图像 分类下的热门子分类,包含 63 个优质AI工具