共找到 32 个AI工具
点击任意工具查看详细信息
薯图宝是一款旨在提升图文制作效率的批量生成工具,它通过个性化模板和文案数据组合,快速生成大量图片,适用于小红书、抖音、视频号等全平台图文制作。产品背景信息显示,薯图宝能够极大提升生产效率,降低成本,特别适合需要大量图文内容的企业或个人使用。价格方面,提供年卡和永久两种套餐,满足不同用户的需求。
MM1.5是一系列多模态大型语言模型(MLLMs),旨在增强文本丰富的图像理解、视觉指代表明和接地以及多图像推理的能力。该模型基于MM1架构,采用以数据为中心的模型训练方法,系统地探索了整个模型训练生命周期中不同数据混合的影响。MM1.5模型从1B到30B参数不等,包括密集型和混合专家(MoE)变体,并通过广泛的实证研究和消融研究,提供了详细的训练过程和决策见解,为未来MLLM开发研究提供了宝贵的指导。
NVLM-D-72B是NVIDIA推出的一款多模态大型语言模型,专注于视觉-语言任务,并且通过多模态训练提升了文本性能。该模型在视觉-语言基准测试中取得了与业界领先模型相媲美的成绩。
Llama-3.2-11B-Vision 是 Meta 发布的一款多模态大型语言模型(LLMs),它结合了图像和文本处理的能力,旨在提高视觉识别、图像推理、图像描述和回答有关图像的一般问题的性能。该模型在常见的行业基准测试中的表现超过了众多开源和封闭的多模态模型。
Llama-3.2-90B-Vision是Meta公司发布的一款多模态大型语言模型(LLM),专注于视觉识别、图像推理、图片描述和回答有关图片的一般问题。该模型在常见的行业基准测试中超越了许多现有的开源和封闭的多模态模型。
NVLM 1.0是一系列前沿级的多模态大型语言模型(LLMs),在视觉-语言任务上取得了与领先专有模型和开放访问模型相媲美的先进成果。值得注意的是,NVLM 1.0在多模态训练后,其文本性能甚至超过了其LLM主干模型。我们为社区开源了模型权重和代码。
Pixtral-12B-2409是由Mistral AI团队开发的多模态模型,包含12B参数的多模态解码器和400M参数的视觉编码器。该模型在多模态任务中表现出色,支持不同尺寸的图像,并在文本基准测试中保持最前沿的性能。它适用于需要处理图像和文本数据的高级应用,如图像描述生成、视觉问答等。
Pixtral 12B 是 Mistral AI 团队开发的一款多模态 AI 模型,它能够理解自然图像和文档,具备出色的多模态任务处理能力,同时在文本基准测试中也保持了最先进的性能。该模型支持多种图像尺寸和宽高比,能够在长上下文窗口中处理任意数量的图像,是 Mistral Nemo 12B 的升级版,专为多模态推理而设计,不牺牲关键文本处理能力。
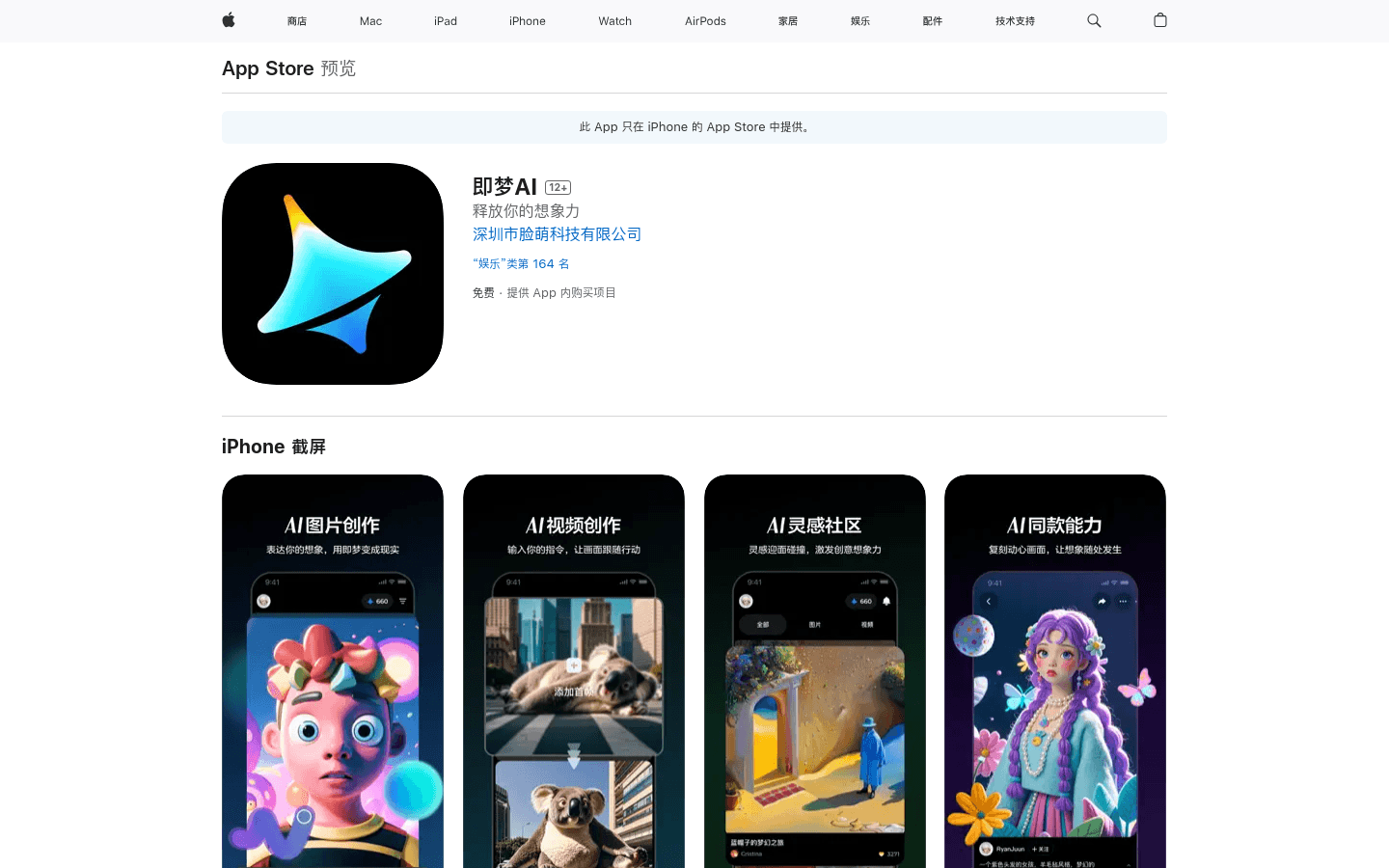
即梦AI是一个专为创意爱好者打造的AI表达平台,通过自然语言描述生成独一无二的图片和视频,支持编辑和分享功能,让用户的想象力得到充分展现。深圳市脸萌科技有限公司开发,提供即梦会员订阅服务,享受更多特权。
SEED-Story是一个基于大型语言模型(MLLM)的多模态长篇故事生成模型,能够根据用户提供的图片和文本生成丰富、连贯的叙事文本和风格一致的图片。它代表了人工智能在创意写作和视觉艺术领域的前沿技术,具有生成高质量、多模态故事内容的能力,为创意产业提供了新的可能性。
BizyAir 是一个由siliconflow开发的插件,旨在帮助用户克服环境和硬件限制,更轻松地使用ComfyUI生成高质量内容。它支持在任何环境下运行,无需担心环境或硬件要求。
Glyph-ByT5-v2 是微软亚洲研究院推出的一个用于准确多语言视觉文本渲染的模型。它不仅支持10种不同语言的准确视觉文本渲染,而且在美学质量上也有显著提升。该模型通过创建高质量的多语言字形文本和平面设计数据集,构建多语言视觉段落基准,并利用最新的步态感知偏好学习方法来提高视觉美学质量。
AI PhotoCaption—Text Generator是一款利用先进的GPT-4 Vision技术,自动为用户上传的图片生成吸引人的社交媒体配文的应用程序。它通过分析图片内容,提供多种语言选项,并允许用户选择不同的语气风格,以适应不同社交媒体平台的特点。该应用旨在节省用户时间,提高帖子的参与度,并通过独特的AI增强配文展示用户的创造力,同时实现跨文化沟通。
Phi-3 Vision是一个轻量级、最先进的开放多模态模型,基于包括合成数据和经过筛选的公开可用网站在内的数据集构建,专注于文本和视觉的非常高质量的推理密集数据。该模型属于Phi-3模型家族,多模态版本支持128K上下文长度(以token计),经过严格的增强过程,结合了监督微调和直接偏好优化,以确保精确的指令遵循和强大的安全措施。
Mini-Gemini是由香港中文大学终身教授贾佳亚团队开发的多模态模型,具备精准的图像理解能力和高质量的训练数据。该模型结合图像推理和生成,提供不同规模的版本,性能与GPT-4和DALLE3相媲美。Mini-Gemini采用Gemini的视觉双分支信息挖掘方法和SDXL技术,通过卷积网络编码图像并利用Attention机制挖掘信息,同时结合LLM生成文本链接两个模型。
EMAGE是一种统一的整体共话手势生成模型,通过表情丰富的掩蔽音频手势建模来生成自然的手势动作。它可以从音频输入中捕捉语音和韵律信息,并生成相应的身体姿势和手势动作序列。EMAGE能够生成高度动态和表现力丰富的手势,从而增强虚拟人物的互动体验。
Al Comic Factory利用大型语言模型和SDXL技术自动生成有情感、有故事性的漫画内容。用户只需提供简单文本提示,AI Comic Factory即可生成包含人物对话和场景描述的漫画。支持多种配置、用户交互、多语言内容创建、批量生成漫画变体等功能。
Glyph-ByT5是一种定制的文本编码器,旨在提高文本到图像生成模型中的视觉文本渲染准确性。它通过微调字符感知的ByT5编码器并使用精心策划的成对字形文本数据集来实现。将Glyph-ByT5与SDXL集成后,形成了Glyph-SDXL模型,使设计图像生成中的文本渲染准确性从低于20%提高到接近90%。该模型还能够实现段落文本的自动多行布局渲染,字符数量从几十到几百字符都能保持较高的拼写准确性。此外,通过使用少量高质量的包含视觉文本的真实图像进行微调,Glyph-SDXL在开放域真实图像中的场景文本渲染能力也有了大幅提升。这些令人鼓舞的成果旨在鼓励进一步探索为不同具有挑战性的任务设计定制的文本编码器。
DexCap是一种便携手部动作捕捉系统,结合了全息测距和电磁场技术,提供准确、抗遮挡的手腕和手指运动跟踪,并通过对环境的3D观测进行数据采集。DexIL算法利用逆运动学和基于点云的模仿学习,直接从人类手部动作数据中训练灵巧的机器手技能。系统支持选项的人机协同校正机制,利用这一丰富数据集,机器手能够复制人类动作,还能根据人类手动作进一步提高表现。
Genie是一个从互联网视频训练的基础世界模型,可以从合成图像、照片甚至素描中生成无限多的可玩(可控制动作的)世界。
VisualVibe AI是一个将图片转换为引人入胜故事和描述的终极工具。它可以为社交媒体爱好者、讲故事者和内容创作者提供帮助。主要功能包括:Caption Magic可以为任何图片生成配图;Instant Hashtags可以生成相关话题标签来增加内容被发现的可能性;Compelling Stories可以将普通图片转换为非凡故事。功能强大,使用简单。
这是一个iOS和Mac应用,使用生成式AI为用户的照片、视频和社交媒体帖子自动生成吸引人的标题和副标题。关键功能包括自动识别照片内容并生成与之匹配的文本,支持自定义风格和词汇量,可直接在Instagram等平台上分享加工后的照片。
Runway 是一个创意工具平台,提供视频编辑、图像生成、人工智能训练等功能。它可以帮助用户生成视频、编辑图像、训练自定义 AI 模型等。Runway 提供多种 AI 魔法工具,包括视频到视频、文本 / 图像转视频、删除背景和资产管理,最新的动态笔刷支持一抹图像变视频。用户可以根据自己的需求选择适合的工具进行创作。Runway 适用于广泛的创作场景,包括设计、视频制作、音乐、写作等。
截图转代码是一个简单的应用程序,它使用GPT-4 Vision生成代码,并使用DALL-E 3生成类似的图片。该应用程序具有React/Vite前端和FastAPI后端,您需要具有访问GPT-4 Vision API的OpenAI API密钥。
inchat是一款基于人工智能的绘画与写作助手APP。它集成了图片生成、文章撰写、智能聊天等多种功能,可以大幅提高用户的工作效率。该APP采用了先进的深度学习算法,可以根据用户需求自动生成各类高质量图片,还可以快速撰写出语义流畅、结构清晰的长文短文。此外,APP内置智能AI机器人,支持人机自然语音对话。inchat非常适合从事设计、写作、自媒体等创意工作的用户。
Chat GPT Diagram是一个功能强大的浏览器扩展,旨在通过无缝转换Mermaid、PlantUML、SVG和HTML代码块为视觉吸引力的图片,提升你在聊天平台上的交流体验。它自动检测聊天对话中的代码块,并立即将它们转换为视觉上令人赏心悦目的图片,使你的讨论更加引人入胜和易于理解。通过Chat GPT Diagram,你可以方便地以清晰简洁的方式传达复杂的想法,无需额外的工具或软件。
GPT Diagram Maker是一款能够通过自然语言生成流程图、时序图、甘特图、UML图等各种类型的图表的插件。用户只需提供文本描述,插件即可快速将其转换为相应的图表。可用于制作培训材料、演示文稿、营销活动、报告等。插件支持Google Slides和Google Docs的快速插入。
我们使用人工智能算法为您的品牌生成定制化、独特且美观的二维码。您可以将AI生成的二维码整合到市场推广材料、产品包装、业务卡片等多种场景中,从而提升品牌识别度并增强客户互动。我们的二维码不仅具备功能性,同时兼具视觉吸引力,能够充分契合您的品牌理念和美学风格。
Ambience是一个Chrome插件,将生产力、灵感和引人注目的视觉效果融合成一个无缝的体验。您的新标签页将通过每小时刷新的AI生成壁纸焕发活力,保持新鲜和令人兴奋。为了激发您的创造力,每个惊人的背景都配有一个激励人心的AI生成名言。由先进的Leap API驱动,Ambience带您进入充满独特视觉效果的艺术之旅。好奇艺术背后的灵感是什么?窥探一下为每个AI生成的杰作提供动力的图像提示,并下载您喜欢的壁纸。Ambience不仅仅是一张漂亮的图片。这是一个体验,灵感源源不断,专注力锐利,动力不减,都归功于这个奇妙的Ambience Chrome插件。
Bright Eye是一个多功能的生成和分析 AI 应用,通过结合文本和图像生成以及基于计算机视觉的工具,提供一个独特的移动体验,用于移动个人(AI4MI,移动个人的人工智能)。它可以回答问题、生成短篇故事、诗歌、文章、艺术作品、进行数学计算,并从照片中提取信息。
Midjourney Stats是一个网站,可以实时查看Midjourney各型号的平均等待时间。您可以了解到何时使用Relax模式以及节约Fast时间最有效。
Inscripto AI是一款基于先进的GPT和DALL-E API技术的AI驱动内容和图像生成工具,旨在提升创造力和生产力。其易于使用的界面能够快速生成吸引人的内容和图像,是创意构思、想法探索和内容创作的理想工具。通过使用AI生成的内容,可以节省时间并提高工作效率。Inscripto AI采用Firebase身份验证,提供安全的登录过程,并支持用户使用Google ID进行无缝体验。适合13岁以上的用户使用,适用于各种创意追求。下载该应用,解锁您的创造力,开启在任何主题上生成独特内容和图像的新体验。
探索 生产力 分类下的其他子分类
1361 个工具
904 个工具
767 个工具
619 个工具
607 个工具
431 个工具
406 个工具
398 个工具
AI图像生成 是 生产力 分类下的热门子分类,包含 32 个优质AI工具