共找到 64 个AI工具
点击任意工具查看详细信息
AI Hug Video Generator是一个在线平台,使用先进的机器学习技术将静态照片转换成动态、逼真的拥抱视频。用户可以根据自己的珍贵照片创建个性化、充满情感的视频。该技术通过分析真实人类互动来创建真实感的数字拥抱,包括微妙的手势和情感。平台提供了用户友好的界面,无论是技术爱好者还是视频制作新手,都能轻松制作AI拥抱视频。此外,生成的视频是高清的,适合在任何平台上分享,确保在每个屏幕上都能呈现出色的效果。
MIMO是一个通用的视频合成模型,能够模仿任何人在复杂动作中与物体互动。它能够根据用户提供的简单输入(如参考图像、姿势序列、场景视频或图像)合成具有可控属性(如角色、动作和场景)的角色视频。MIMO通过将2D视频编码为紧凑的空间代码,并将其分解为三个空间组成部分(主要人物、底层场景和浮动遮挡)来实现这一点。这种方法允许用户灵活控制,空间运动表达以及3D感知合成,适用于交互式真实世界场景。
LVCD 是一种基于参考的线稿视频上色技术,采用大规模预训练的视频扩散模型,生成色彩化动画视频。该技术通过Sketch-guided ControlNet和Reference Attention,实现了对快速和大幅度运动的动画视频进行色彩化处理,同时保证了时间上的连贯性。LVCD的主要优点包括生成色彩化动画视频的时间连贯性、处理大运动的能力以及高质量的输出结果。
ComfyUI-LumaAI-API是一个为ComfyUI设计的插件,它允许用户直接在ComfyUI中使用Luma AI API。Luma AI API基于Dream Machine视频生成模型,由Luma开发。该插件通过提供多种节点,如文本到视频、图像到视频、视频预览等,极大地丰富了视频生成的可能性,为视频创作者和开发者提供了便捷的工具。
通义万相AI创意作画是一款利用人工智能技术,将用户的文字描述或图像转化为视频内容的产品。它通过先进的AI算法,能够理解用户的创意意图,自动生成具有艺术感的视频。该产品不仅能够提升内容创作的效率,还能激发用户的创造力,适用于广告、教育、娱乐等多个领域。
Loopy是一个端到端的音频驱动视频扩散模型,专门设计了跨剪辑和内部剪辑的时间模块以及音频到潜在表示模块,使模型能够利用数据中的长期运动信息来学习自然运动模式,并提高音频与肖像运动的相关性。这种方法消除了现有方法中手动指定的空间运动模板的需求,实现了在各种场景下更逼真、高质量的结果。
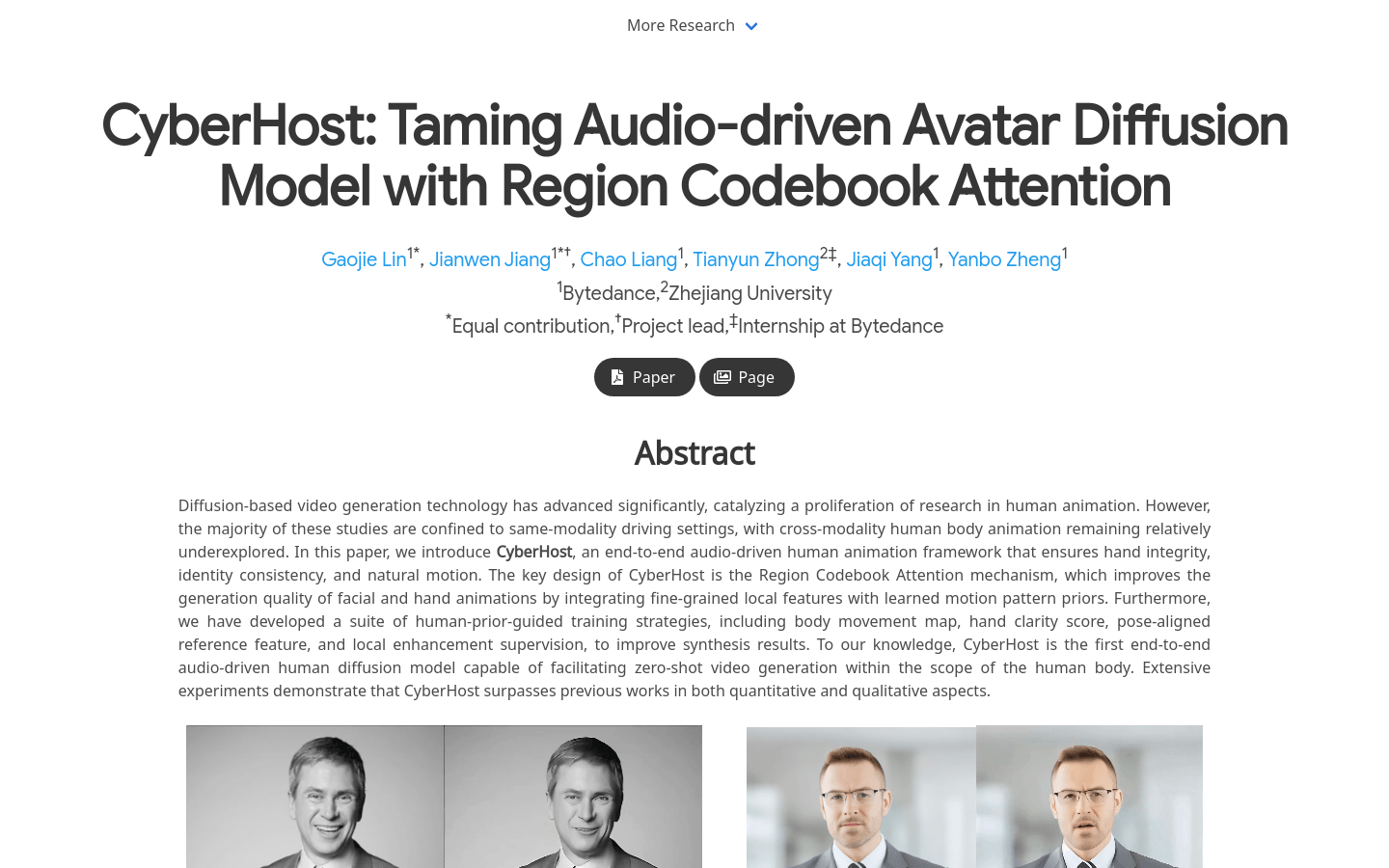
CyberHost是一个端到端音频驱动的人体动画框架,通过区域码本注意力机制,实现了手部完整性、身份一致性和自然运动的生成。该模型利用双U-Net架构作为基础结构,并通过运动帧策略进行时间延续,为音频驱动的人体动画建立了基线。CyberHost通过一系列以人为先导的训练策略,包括身体运动图、手部清晰度评分、姿势对齐的参考特征和局部增强监督,提高了合成结果的质量。CyberHost是首个能够在人体范围内实现零样本视频生成的音频驱动人体扩散模型。
EmoTalk3D是一个专注于3D虚拟人头合成的研究项目,它通过收集多视角视频、情感注释和每帧3D几何数据来解决传统3D人头合成中存在的视角一致性和情感表达不足的问题。该项目提出了一种新颖的方法,通过训练EmoTalk3D数据集,实现了情感可控的3D人头合成,具有增强的唇部同步和渲染质量。EmoTalk3D模型能够生成具有广泛视角和高渲染质量的3D动画,同时捕捉到动态面部细节,如皱纹和微妙表情。
Clapper.app是一个开源的AI故事可视化工具,能够将剧本解读并渲染成故事板、视频、声音和音乐。目前,该工具仍处于早期开发阶段,并不适用于普通用户,因为一些功能尚未完成,也没有教程等。
Stable Video 4D (SV4D) 是基于 Stable Video Diffusion (SVD) 和 Stable Video 3D (SV3D) 的生成模型,它接受单一视角的视频并生成该对象的多个新视角视频(4D 图像矩阵)。该模型训练生成 40 帧(5 个视频帧 x 8 个摄像机视角)在 576x576 分辨率下,给定 5 个相同大小的参考帧。通过运行 SV3D 生成轨道视频,然后使用轨道视频作为 SV4D 的参考视图,并输入视频作为参考帧,进行 4D 采样。该模型还通过使用生成的第一帧作为锚点,然后密集采样(插值)剩余帧来生成更长的新视角视频。
FasterLivePortrait是一个基于深度学习的实时肖像动画化项目。它通过使用TensorRT在RTX 3090 GPU上实现30+ FPS的实时运行速度,包括预处理和后处理,而不仅仅是模型推理速度。该项目还实现了将LivePortrait模型转换为Onnx模型,并在RTX 3090上使用onnxruntime-gpu实现约70ms/帧的推理速度,支持跨平台部署。此外,该项目还支持原生gradio app,速度提升数倍,并支持多张人脸的同时推理。代码结构经过重构,不再依赖PyTorch,所有模型使用onnx或tensorrt进行推理。
RunwayML是一款领先的下一代创意套件,提供了丰富的工具,让用户能够将任何想法转化为现实。该应用通过其独特的文本到视频生成技术,让用户仅通过文本描述即可在手机上生成视频。其主要优点包括: 1. 文本到视频生成:用户只需输入文本描述,即可生成视频。 2. 实时更新:定期推出新功能和更新,确保用户始终能够使用最新的AI视频和图片工具。 3. 无缝资产转移:用户可以在手机和电脑之间无缝转移资产。 4. 多种订阅选项:提供标准、专业和每月1000次生成信用的订阅选项。
TCAN是一种基于扩散模型的新型人像动画框架,它能够保持时间一致性并很好地泛化到未见过的领域。该框架通过特有的模块,如外观-姿态自适应层(APPA层)、时间控制网络和姿态驱动的温度图,来确保生成的视频既保持源图像的外观,又遵循驱动视频的姿态,同时保持背景的一致性。
LivePortrait是一个基于隐式关键点框架的人像动画生成模型,它通过使用单一源图像作为外观参考,并从驱动视频、音频、文本或生成中获取动作(如面部表情和头部姿势),来合成逼真的视频。该模型不仅在计算效率和可控性之间取得了有效平衡,而且通过扩展训练数据、采用混合图像-视频训练策略、升级网络架构以及设计更好的运动转换和优化目标,显著提高了生成质量和泛化能力。
MimicMotion是由腾讯公司和上海交通大学联合研发的高质量人体动作视频生成模型。该模型通过信心感知的姿态引导,实现了对视频生成过程的可控性,提高了视频的时序平滑性,并减少了图像失真。它采用了先进的图像到视频的扩散模型,结合了时空U-Net和PoseNet,能够根据姿势序列条件生成任意长度的高质量视频。MimicMotion在多个方面显著优于先前的方法,包括手部生成质量、对参考姿势的准确遵循等。
Gen-3 Alpha 是 Runway 训练的一系列模型中的首个,它在新的基础设施上训练,专为大规模多模态训练而建。它在保真度、一致性和动作方面相较于 Gen-2 有重大改进,并朝着构建通用世界模型迈进了一步。该模型能够生成具有丰富动作、手势和情感的表达性人物角色,为叙事提供了新的机会。
UniAnimate是一个用于人物图像动画的统一视频扩散模型框架。它通过将参考图像、姿势指导和噪声视频映射到一个共同的特征空间,以减少优化难度并确保时间上的连贯性。UniAnimate能够处理长序列,支持随机噪声输入和首帧条件输入,显著提高了生成长期视频的能力。此外,它还探索了基于状态空间模型的替代时间建模架构,以替代原始的计算密集型时间Transformer。UniAnimate在定量和定性评估中都取得了优于现有最先进技术的合成结果,并且能够通过迭代使用首帧条件策略生成高度一致的一分钟视频。
VideoTetris是一个新颖的框架,它实现了文本到视频的生成,特别适用于处理包含多个对象或对象数量动态变化的复杂视频生成场景。该框架通过空间时间组合扩散技术,精确地遵循复杂的文本语义,并通过操作和组合去噪网络的空间和时间注意力图来实现。此外,它还引入了一种新的参考帧注意力机制,以提高自回归视频生成的一致性。VideoTetris在组合文本到视频生成方面取得了令人印象深刻的定性和定量结果。
Depth Anything V2 是一个经过改进的单目深度估计模型,它通过使用合成图像和大量未标记的真实图像进行训练,提供了比前一版本更精细、更鲁棒的深度预测。该模型在效率和准确性方面都有显著提升,速度比基于Stable Diffusion的最新模型快10倍以上。
MotionClone是一个训练无关的框架,允许从参考视频进行运动克隆,以控制文本到视频的生成。它利用时间注意力机制在视频反转中表示参考视频中的运动,并引入了主时间注意力引导来减轻注意力权重中噪声或非常微妙运动的影响。此外,为了协助生成模型合成合理的空间关系并增强其提示跟随能力,提出了一种利用参考视频中的前景粗略位置和原始分类器自由引导特征的位置感知语义引导机制。
WorldDreamer是一个创新的视频生成模型,它通过预测遮蔽的视觉令牌来理解并模拟世界动态。它在图像到视频合成、文本到视频生成、视频修复、视频风格化以及动作到视频生成等多个方面表现出色。该模型借鉴了大型语言模型的成功经验,将世界建模视为一个无监督的视觉序列建模挑战,通过将视觉输入映射到离散的令牌并预测被遮蔽的令牌来实现。
Follow-Your-Pose是一个文本到视频生成的模型,它利用姿势信息和文本描述来生成可编辑、可控制姿势的角色视频。这项技术在数字人物创作领域具有重要应用价值,解决了缺乏综合数据集和视频生成先验模型的限制。通过两阶段训练方案,结合预训练的文本到图像模型,实现了姿势可控的视频生成。
MotionFollower是一个轻量级的得分引导扩散模型,用于视频运动编辑。它通过两个轻量级信号控制器,分别对姿势和外观进行控制,不涉及繁重的注意力计算。该模型设计了基于双分支架构的得分引导原则,包括重建和编辑分支,显著增强了对纹理细节和复杂背景的建模能力。实验表明,MotionFollower在GPU内存使用上比最先进的运动编辑模型MotionEditor减少了约80%,同时提供了更优越的运动编辑性能,并独家支持大范围的摄像机运动和动作。
可灵大模型是一款具备强大视频生成能力的自研大模型,采用先进的技术实现长达 2 分钟视频生成、模拟物理世界特性、概念组合能力等,可生成电影级画面。
CamCo是一个创新的图像到视频生成框架,它能够生成具有3D一致性的高质量视频。该框架通过Plücker坐标引入相机信息,并提出了一种符合几何一致性的双线约束注意力模块。此外,CamCo在通过运动结构算法估计相机姿态的真实世界视频上进行了微调,以更好地合成物体运动。
EasyAnimate 是一个基于 transformer 架构的流水线,可以用于生成 AI 照片和视频,训练基线模型和 Lora 模型以用于 Diffusion Transformer。支持直接从预训练的 EasyAnimate 模型进行预测,生成不同分辨率、约 6 秒(24fps)的视频。用户还可以训练自己的基线模型和 Lora 模型以执行特定风格转换。
AnimateAnyone是一个基于深度学习的视频生成模型,它能够将静态图片或视频转换为动画。该模型由Novita AI非官方实现,灵感来源于MooreThreads/Moore-AnimateAnyone的实现,并在训练过程和数据集上进行了调整。
MusePose是由腾讯音乐娱乐的Lyra Lab开发的一款图像到视频的生成框架,旨在通过姿势控制信号生成虚拟人物的视频。它是Muse开源系列的最后一个构建块,与MuseV和MuseTalk一起,旨在推动社区向生成具有全身运动和交互能力的虚拟人物的愿景迈进。MusePose基于扩散模型和姿势引导,能够生成参考图像中人物的舞蹈视频,并且结果质量超越了当前几乎所有同一主题的开源模型。
FIFO-Diffusion是一种基于预训练扩散模型的新颖推理技术,用于文本条件视频生成。它能够无需训练生成无限长的视频,通过迭代执行对角去噪,同时处理队列中一系列连续帧的逐渐增加的噪声水平;该方法在头部出队一个完全去噪的帧,同时在尾部入队一个新的随机噪声帧。此外,引入了潜在分割来减少训练推理差距,并通过前瞻去噪来利用前向引用的好处。
Veo是Google最新推出的视频生成模型,能够生成高质量的1080p分辨率视频,支持多种电影和视觉风格。它通过先进的自然语言和视觉语义理解,能够精确捕捉用户创意愿景,生成与提示语调一致且细节丰富的视频内容。Veo模型提供前所未有的创意控制水平,理解电影术语如“延时摄影”或“航拍景观”,创造出连贯一致的画面,使人物、动物和物体在镜头中逼真地移动。
ID-Animator是一种零样本人类视频生成方法,能够在不需要进一步训练的情况下,根据单个参考面部图像进行个性化视频生成。该技术继承了现有的基于扩散的视频生成框架,并加入了面部适配器以编码与身份相关的嵌入。通过这种方法,ID-Animator能够在视频生成过程中保持人物身份的细节,同时提高训练效率。
VASA-1是由微软研究院开发的一个模型,专注于实时生成与音频相匹配的逼真人脸动画。该技术通过深度学习算法,能够根据输入的语音内容,自动生成相应的口型和面部表情,为用户提供一种全新的交互体验。VASA-1的主要优势在于其高度逼真的生成效果和实时响应能力,使得虚拟角色能够更加自然地与用户进行互动。目前,VASA-1主要应用于虚拟助手、在线教育、娱乐等领域,其定价策略尚未公布,但预计将提供免费试用版本供用户体验。
Imagen提供先进的生成式媒体能力。Gemini模型非常适用于高级推理和通用用例,而任务特定的生成AI模型可以帮助企业提供专业能力。今天预览的文本到动态图片功能使Imagen在企业工作负载中更加强大。这允许营销和创意团队根据文本提示生成动态图片,如GIF等。初始时,动态图片将以每秒24帧(fps)的速度交付,分辨率为360x640像素,持续时间为4秒,计划进行持续增强。考虑到该模型专为企业应用设计,它擅长主题,如自然、食物图像和动物。它可以生成一系列的摄像机角度和动作,同时支持整个序列的一致性。Imagen的动态图片生成功能配备了安全过滤器和数字水印,以维护创作者和用户之间的信任承诺。此外,我们还通过高级照片编辑功能更新了Imagen 2.0的图像生成能力,包括修补和扩展。现在在Vertex AI上通用的这些功能,使用户可以轻松地删除图像中不需要的元素、添加新元素,并扩展图像边界,以创造更广阔的视野。此外,我们基于Google DeepMind的SynthID技术的数字水印功能现已通用,使客户能够生成隐形水印并验证Imagen系列模型生成的图像和动态图像。
MagicTime是一种基于文本描述生成高质量变化视频的模型。它通过学习时间流逝视频中的物理知识,实现了高度逼真的变化过程模拟。该模型包括MagicAdapter、Dynamic Frames Extraction和Magic Text-Encoder三个主要组件,可以有效地从文本中理解变化过程并生成对应的视频。同时,项目团队还开发了专门的时间流逝视频数据集ChronoMagic,为变化视频生成提供支持。综合实验结果表明,MagicTime在生成动态逼真的变化视频方面表现优秀,为打造物理世界的变化模拟器提供了新思路。
MuseV是一个基于扩散模型的虚拟人视频生成框架,支持无限长度视频生成,采用了新颖的视觉条件并行去噪方案。它提供了预训练的虚拟人视频生成模型,支持Image2Video、Text2Image2Video、Video2Video等功能,兼容Stable Diffusion生态系统,包括基础模型、LoRA、ControlNet等。它支持多参考图像技术,如IPAdapter、ReferenceOnly、ReferenceNet、IPAdapterFaceID等。MuseV的优势在于可生成高保真无限长度视频,定位于视频生成领域。
Make-Your-Anchor是一个基于扩散模型的2D虚拟形象生成框架。它只需一段1分钟左右的视频素材就可以自动生成具有精确上身和手部动作的主播风格视频。该系统采用了一种结构引导的扩散模型来将3D网格状态渲染成人物外观。通过两阶段训练策略,有效地将运动与特定外观相绑定。为了生成任意长度的时序视频,将frame-wise扩散模型的2D U-Net扩展到3D形式,并提出简单有效的批重叠时序去噪模块,从而突破推理时的视频长度限制。最后,引入了一种基于特定身份的面部增强模块,提高输出视频中面部区域的视觉质量。实验表明,该系统在视觉质量、时序一致性和身份保真度方面均优于现有技术。
AniPortrait是一个根据音频和图像输入生成会说话、唱歌的动态视频的项目。它能够根据音频和静态人脸图片生成逼真的人脸动画,口型保持一致。支持多种语言和面部重绘、头部姿势控制。功能包括音频驱动的动画合成、面部再现、头部姿势控制、支持自驱动和音频驱动的视频生成、高质量动画生成以及灵活的模型和权重配置。
SceneScript是Reality Labs研究团队开发的一种新型3D场景重建技术。该技术利用AI来理解和重建复杂的3D场景,能够从单张图片中创建详细的3D模型。SceneScript通过结合多种先进的深度学习技术,如半监督学习、自监督学习和多模态学习,显著提高了3D重建的准确性和效率。
StreamingT2V 是一种先进的自回归技术,可以创建具有丰富动态运动的长视频,没有任何停滞。它确保视频中的时间一致性,与描述性文本紧密对齐,并保持高帧级图像质量。
MOTIA是一个基于测试时适应的扩散方法,利用源视频内的内在内容和运动模式来有效进行视频外延画。该方法包括内在适应和外在渲染两个主要阶段,旨在提升视频外延画的质量和灵活性。
DynamiCrafter是一种文生视频模型,能够根据输入的图像和文本生成约2秒长的动态视频。这个模型经过训练,可以生成分辨率为576x1024的高分辨率视频。主要优势是能够捕捉输入图像和文本描述的动态效果,生成逼真的短视频内容。适用于视频制作、动画创作等场景,为内容创作者提供高效的生产力工具。该模型目前处于研究阶段,仅供个人和研究用途使用。
VLOGGER是一种从单张人物输入图像生成文本和音频驱动的讲话人类视频的方法,它建立在最近生成扩散模型的成功基础上。我们的方法包括1)一个随机的人类到3D运动扩散模型,以及2)一个新颖的基于扩散的架构,通过时间和空间控制增强文本到图像模型。这种方法能够生成长度可变的高质量视频,并且通过对人类面部和身体的高级表达方式轻松可控。与以前的工作不同,我们的方法不需要为每个人训练,也不依赖于人脸检测和裁剪,生成完整的图像(而不仅仅是面部或嘴唇),并考虑到正确合成交流人类所需的广泛场景(例如可见的躯干或多样性主体身份)。
AtomoVideo是一个新颖的高保真图像到视频(I2V)生成框架,它从输入图像生成高保真视频,与现有工作相比,实现了更好的运动强度和一致性,并且无需特定调整即可与各种个性化T2I模型兼容。
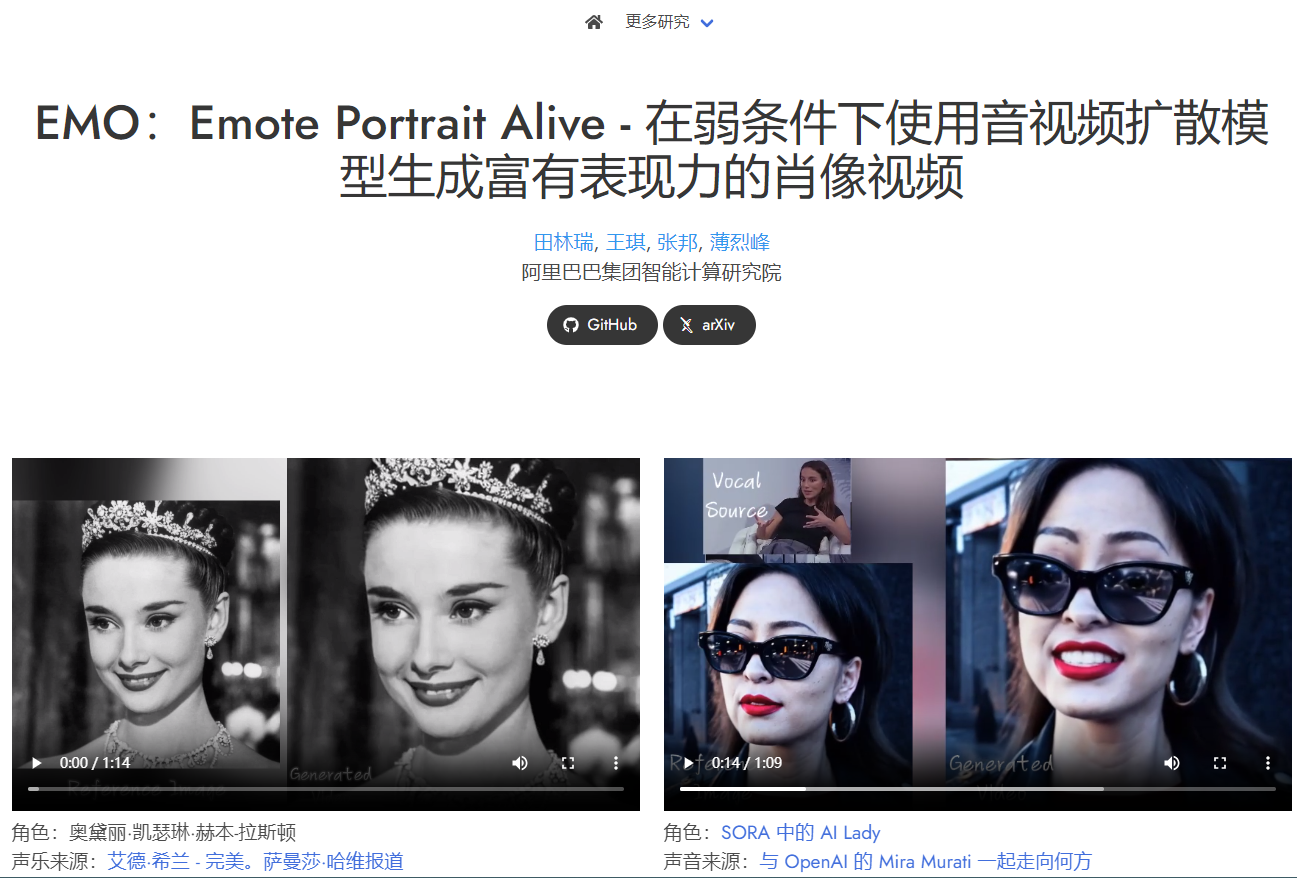
阿里巴巴的EMO: 是一款生成具有表情丰富的面部表情视频的工具,可以根据输入的角色图像和声音音频生成各种头部姿势和表情的声音头像视频。支持多语言歌曲和各种肖像风格,能够根据音频节奏生成动态、表现丰富的动画角色。
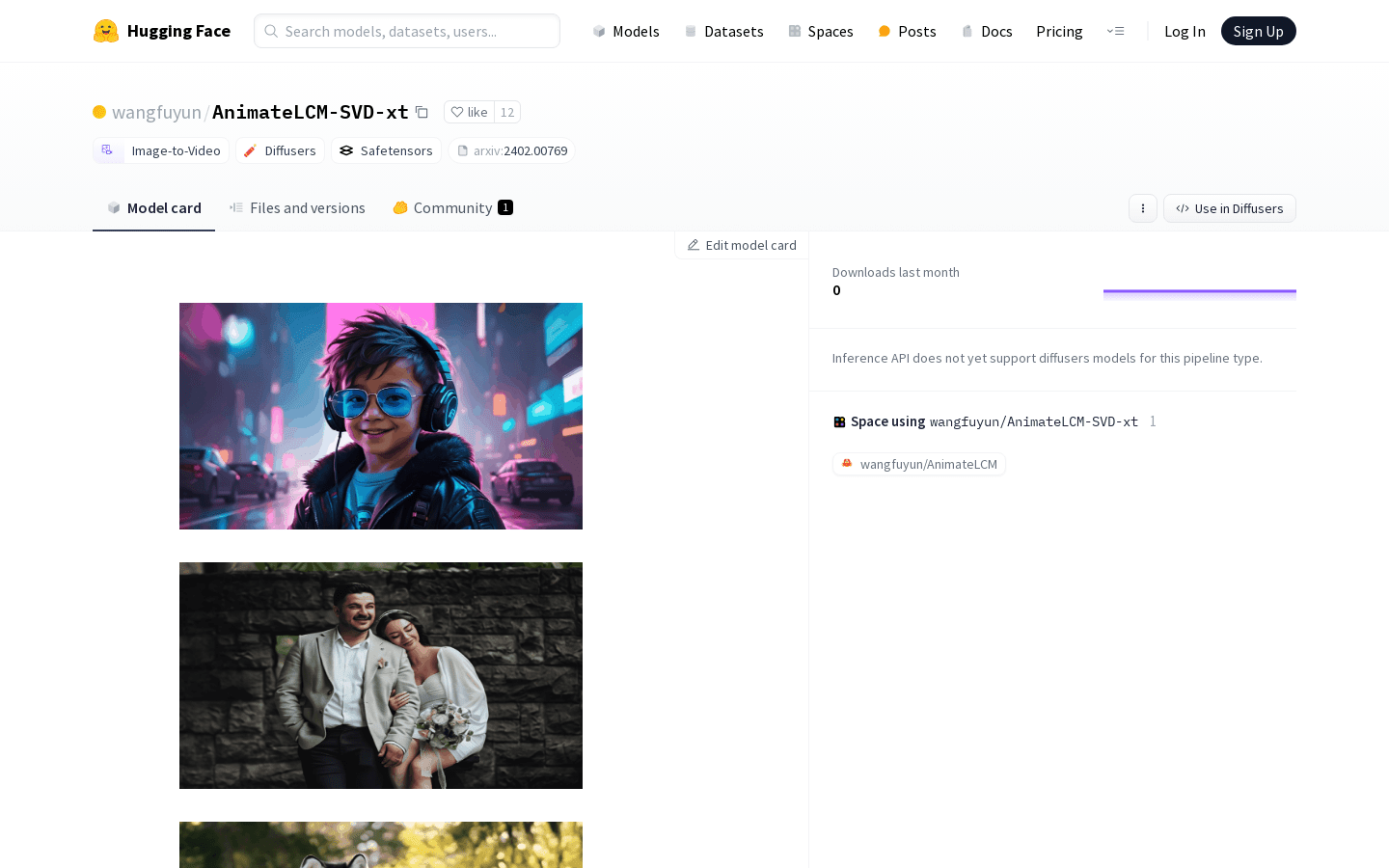
AnimateLCM-SVD-xt是一种新的图像到视频生成模型,可以在很少的步骤内生成高质量、连贯性好的视频。该模型通过一致性知识蒸馏和立体匹配学习技术,使生成视频更加平稳连贯,同时大大减少了计算量。关键特点包括:1) 4-8步内生成25帧576x1024分辨率视频;2) 比普通视频diffusion模型降低12.5倍计算量;3) 生成视频质量好,无需额外分类器引导。
Sora是一个基于大规模训练的文本控制视频生成扩散模型。它能够生成长达1分钟的高清视频,涵盖广泛的视觉数据类型和分辨率。Sora通过在视频和图像的压缩潜在空间中训练,将其分解为时空位置补丁,实现了可扩展的视频生成。Sora还展现出一些模拟物理世界和数字世界的能力,如三维一致性和交互,揭示了继续扩大视频生成模型规模来发展高能力模拟器的前景。
Meshy-2是我们3D生成AI产品系列的最新成员,距离Meshy-1发布已经过去三个月。这个版本在Text to 3D领域有着巨大的飞跃,为3D对象提供更好结构的网格和丰富的几何细节。在Meshy-2中,Text to 3D提供了四种风格选择:真实、卡通、低多边形和Voxel,以满足各种艺术偏好并激发新的创意方向。我们提高了生成速度,不影响质量,预览时间约为25秒,精细结果在5分钟内完成。此外,Meshy-2引入了用户友好的网格编辑器,具有多边形数量控制和四边形网格转换系统,以提供更多3D项目中的控制和灵活性。Text to Texture功能经过优化,以更清晰的效果呈现纹理,速度提高一倍。Image to 3D的增强功能在2分钟内生成更高质量的结果。我们正在将重心从Discord转移到Web应用,鼓励用户在Web应用社区中分享AI生成的3D艺术。
DynamiCrafter是一款由Jinbo Xing、Menghan Xia等人开发的图像动画工具。通过利用预训练的视频扩散先验,DynamiCrafter可以基于文本提示为开放域的静止图像添加动画效果。该工具支持高分辨率模型,提供更好的动态效果、更高的分辨率和更强的一致性。DynamiCrafter主要用于故事视频生成、循环视频生成和生成帧插值等场景。
Stable Video Diffusion (SVD) 1.1 Image-to-Video 是一个扩散模型,通过将静止图像作为条件帧,生成相应的视频。该模型是一个潜在扩散模型,经过训练,能够从图像生成短视频片段。在分辨率为 1024x576 的情况下,该模型训练生成 25 帧视频,其训练基于相同大小的上下文帧,并从 SVD Image-to-Video [25 frames] 进行了微调。微调时,固定了6FPS和Motion Bucket Id 127的条件,以提高输出的一致性,而无需调整超参数。
AnimateLCM是一个使用深度学习生成动画视频的模型。它可以仅使用极少的采样步骤就生成高保真的动画视频。与直接在原始视频数据集上进行一致性学习不同,AnimateLCM采用了解耦的一致性学习策略,将图像生成先验知识和运动生成先验知识的萃取进行解耦,从而提高了训练效率并增强了生成的视觉质量。此外,AnimateLCM还可以与Stable Diffusion社区的插件模块配合使用,实现各种可控生成功能。AnimateLCM已经在基于图像的视频生成和基于布局的视频生成中验证了其性能。
Lumiere是一个文本到视频扩散模型,旨在合成展现真实、多样和连贯运动的视频,解决视频合成中的关键挑战。我们引入了一种空时U-Net架构,可以一次性生成整个视频的时间持续,通过模型的单次传递。这与现有的视频模型形成对比,后者合成远距离的关键帧,然后进行时间超分辨率处理,这种方法本质上使得全局时间一致性难以实现。通过部署空间和(重要的是)时间的下采样和上采样,并利用预训练的文本到图像扩散模型,我们的模型学会直接生成多个时空尺度下的全帧率、低分辨率视频。我们展示了最先进的文本到视频生成结果,并展示了我们的设计轻松促进了各种内容创作任务和视频编辑应用,包括图像到视频、视频修补和风格化生成。
ActAnywhere是一个用于自动生成与前景主体运动和外观相符的视频背景的生成模型。该任务涉及合成与前景主体运动和外观相一致的背景,同时也符合艺术家的创作意图。ActAnywhere利用大规模视频扩散模型的力量,并专门定制用于此任务。ActAnywhere以一系列前景主体分割作为输入,以描述所需场景的图像作为条件,生成与条件帧相一致的连贯视频,同时实现现实的前景和背景交互。该模型在大规模人机交互视频数据集上进行训练。大量评估表明该模型的性能明显优于基准,可以泛化到各种分布样本,包括非人类主体。
ComfyUI-Moore-AnimateAnyone是一个基于Moore-AnimateAnyone模型实现的ComfyUI自定义节点,可以通过简单的文本描述生成相应的人体动画。该节点易于安装和使用,支持多种人体姿态和动作的生成,可用于提升设计作品的质量。其输出动画细腻自然,为创作者提供了强大的工具。
I2V-Adapter旨在将静态图像转换为动态、逼真的视频序列,同时保持原始图像的保真度。它使用轻量级适配器模块并行处理带噪声的视频帧和输入图像。此模块充当桥梁,有效地将输入连接到模型的自注意力机制,保持空间细节,无需更改T2I模型的结构。I2V-Adapter参数少于传统模型,并确保与现有的T2I模型和控制工具兼容。实验结果表明,I2V-Adapter能够生成高质量的视频输出,这对于AI驱动的视频生成,尤其是创意应用领域,具有重大意义。
MagicVideo-V2是一个集成了文本到图像模型、视频运动生成器、参考图像嵌入模块和帧插值模块的端到端视频生成管道。其架构设计使得MagicVideo-V2能够生成外观美观、高分辨率的视频,具有出色的保真度和平滑性。通过大规模用户评估,它展现出比Runway、Pika 1.0、Morph、Moon Valley和Stable Video Diffusion等领先的文本到视频系统更优越的性能。
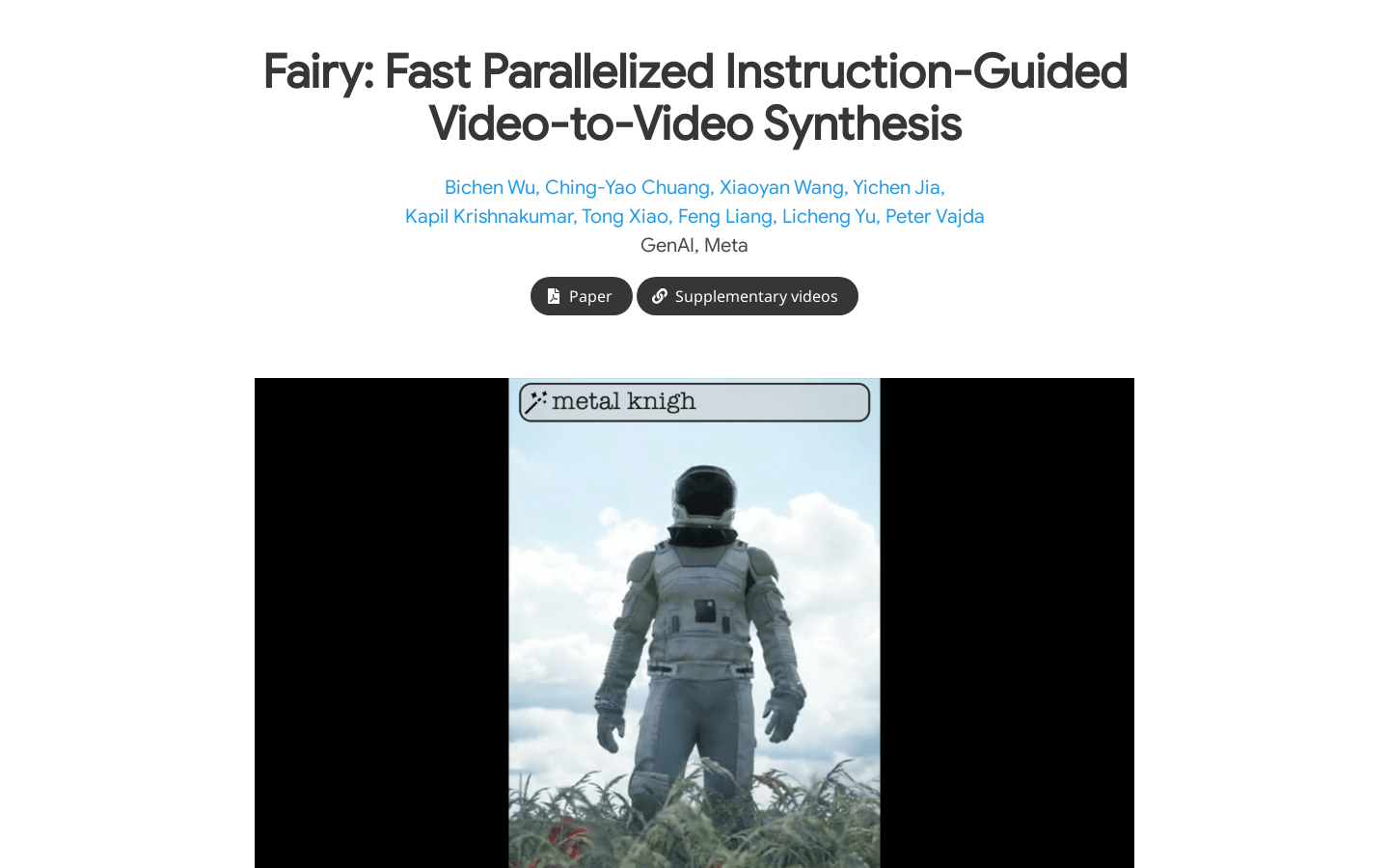
Fairy是一个针对视频编辑应用的简约但强大的图像编辑扩散模型的适应。它的核心是基于锚的跨帧注意机制,这种机制隐式地在帧之间传播扩散特征,确保了更好的时间连贯性和高保真度合成。Fairy不仅解决了以前模型的内存和处理速度限制,还通过独特的数据增强策略改善了时间一致性。
InstructVideo 是一种通过人类反馈用奖励微调来指导文本到视频的扩散模型的方法。它通过编辑的方式进行奖励微调,减少了微调成本,同时提高了微调效率。它使用已建立的图像奖励模型,通过分段稀疏采样和时间衰减奖励的方式提供奖励信号,显著提高了生成视频的视觉质量。InstructVideo 不仅能够提高生成视频的视觉质量,还能保持较强的泛化能力。欲了解更多信息,请访问官方网站。
VideoPoet 是一个大型语言模型,可将任何自回归语言模型转换为高质量视频生成器。它可以根据输入的文本描述生成视频,无需任何视觉或音频指导。VideoPoet 能够生成各种类型的视频,包括文本到视频、图像到视频、视频编辑、风格化和修复等。它可以用于电影制作、动画片、广告制作、虚拟现实等领域。VideoPoet 具有高质量的视频生成能力,并且可以灵活应用于不同的场景。
W.A.L.T是一个基于transformer的实景视频生成方法,通过联合压缩图像和视频到一个统一的潜在空间,实现跨模态的训练和生成。它使用了窗注意力机制来提高内存和训练效率。该方法在多个视频和图像生成基准测试上取得了最先进的性能。
MagicAnimate 是一款使用扩散模型实现的时域一致的人体图像动画工具。它可以通过对人体图像进行扩散模型的运算,实现高质量、自然流畅的人体动画效果。MagicAnimate 具有高度的可控性和灵活性,可以通过微调参数来实现不同的动画效果。它适用于人体动画创作、虚拟角色设计等领域。
Make Pixels Dance是一款高动态视频生成工具,通过输入图像或文字指令,生成丰富多样的动态视频效果。该工具具有基础模式和魔法模式,用户可以根据需求选择不同的模式生成视频。产品功能强大,操作简单易用,适用于各种创意视频制作场景。
DynVideo-E是一款利用动态NeRF技术进行大规模运动和视角变化的人体视频编辑工具。该工具将视频表示为3D前景规范化的人体空间,结合变形场和3D背景静态空间。通过利用重建损失、2D个性化扩散先验、3D扩散先验和局部部分超分辨率等技术,在多视角多姿势配置下编辑可动的规范化人体空间。同时,通过特征空间的风格转换损失将参考风格转移到3D背景模型中。用户可以在编辑后的视频-NeRF模型中根据源视频相机姿态进行相应的渲染。DynVideo-E不仅能够处理短视频,还能够处理大规模运动和视角变化的人体视频,为用户提供了更多直接可控的编辑方式。该工具在两个具有挑战性的数据集上的实验证明,相比于现有方法,DynVideo-E在人类偏好方面取得了50% ~ 95%的显著优势。DynVideo-E的代码和数据将会向社区发布。
MagicEdit是一款高保真、时间连贯的视频编辑模型,通过明确分离外观和运动的学习,支持视频风格化、局部编辑、视频混合和视频外扩等多种编辑应用。MagicEdit还支持视频外扩任务,无需重新训练即可实现。
Gen-2是一款多模态人工智能系统,可以根据文字、图片或视频剪辑生成新颖的视频。它可以通过将图像或文字提示的构图和风格应用于源视频的结构(Video to Video),或者仅使用文字(Text to Video)来实现。就像拍摄了全新的内容,而实际上并没有拍摄任何东西。Gen-2提供了多种模式,可以将任何图像、视频剪辑或文字提示转化为引人注目的影片作品。
探索 视频 分类下的其他子分类
399 个工具
346 个工具
323 个工具
181 个工具
130 个工具
124 个工具
49 个工具
39 个工具
AI图像生成 是 视频 分类下的热门子分类,包含 64 个优质AI工具