产品详情
SceneScript是Reality Labs研究团队开发的一种新型3D场景重建技术。该技术利用AI来理解和重建复杂的3D场景,能够从单张图片中创建详细的3D模型。SceneScript通过结合多种先进的深度学习技术,如半监督学习、自监督学习和多模态学习,显著提高了3D重建的准确性和效率。
主要功能
适用人群
适用于计算机视觉领域的研究人员、开发者以及对3D建模和场景重建感兴趣的用户。
使用示例
研究人员使用SceneScript技术来改进无人驾驶汽车的视觉系统
游戏开发者利用SceneScript从真实照片创建游戏场景
电影制作人员通过SceneScript技术将2D概念图转换为3D模型
快速访问
访问官网 →所属分类
相关推荐
发现更多类似的优质AI工具

AI Hug Video
AI Hug Video Generator是一个在线平台,使用先进的机器学习技术将静态照片转换成动态、逼真的拥抱视频。用户可以根据自己的珍贵照片创建个性化、充满情感的视频。该技术通过分析真实人类互动来创建真实感的数字拥抱,包括微妙的手势和情感。平台提供了用户友好的界面,无论是技术爱好者还是视频制作新手,都能轻松制作AI拥抱视频。此外,生成的视频是高清的,适合在任何平台上分享,确保在每个屏幕上都能呈现出色的效果。

MIMO
MIMO是一个通用的视频合成模型,能够模仿任何人在复杂动作中与物体互动。它能够根据用户提供的简单输入(如参考图像、姿势序列、场景视频或图像)合成具有可控属性(如角色、动作和场景)的角色视频。MIMO通过将2D视频编码为紧凑的空间代码,并将其分解为三个空间组成部分(主要人物、底层场景和浮动遮挡)来实现这一点。这种方法允许用户灵活控制,空间运动表达以及3D感知合成,适用于交互式真实世界场景。

LVCD
LVCD 是一种基于参考的线稿视频上色技术,采用大规模预训练的视频扩散模型,生成色彩化动画视频。该技术通过Sketch-guided ControlNet和Reference Attention,实现了对快速和大幅度运动的动画视频进行色彩化处理,同时保证了时间上的连贯性。LVCD的主要优点包括生成色彩化动画视频的时间连贯性、处理大运动的能力以及高质量的输出结果。

ComfyUI-LumaAI-API
ComfyUI-LumaAI-API是一个为ComfyUI设计的插件,它允许用户直接在ComfyUI中使用Luma AI API。Luma AI API基于Dream Machine视频生成模型,由Luma开发。该插件通过提供多种节点,如文本到视频、图像到视频、视频预览等,极大地丰富了视频生成的可能性,为视频创作者和开发者提供了便捷的工具。

通义万相AI视频生成
通义万相AI创意作画是一款利用人工智能技术,将用户的文字描述或图像转化为视频内容的产品。它通过先进的AI算法,能够理解用户的创意意图,自动生成具有艺术感的视频。该产品不仅能够提升内容创作的效率,还能激发用户的创造力,适用于广告、教育、娱乐等多个领域。

Loopy model
Loopy是一个端到端的音频驱动视频扩散模型,专门设计了跨剪辑和内部剪辑的时间模块以及音频到潜在表示模块,使模型能够利用数据中的长期运动信息来学习自然运动模式,并提高音频与肖像运动的相关性。这种方法消除了现有方法中手动指定的空间运动模板的需求,实现了在各种场景下更逼真、高质量的结果。
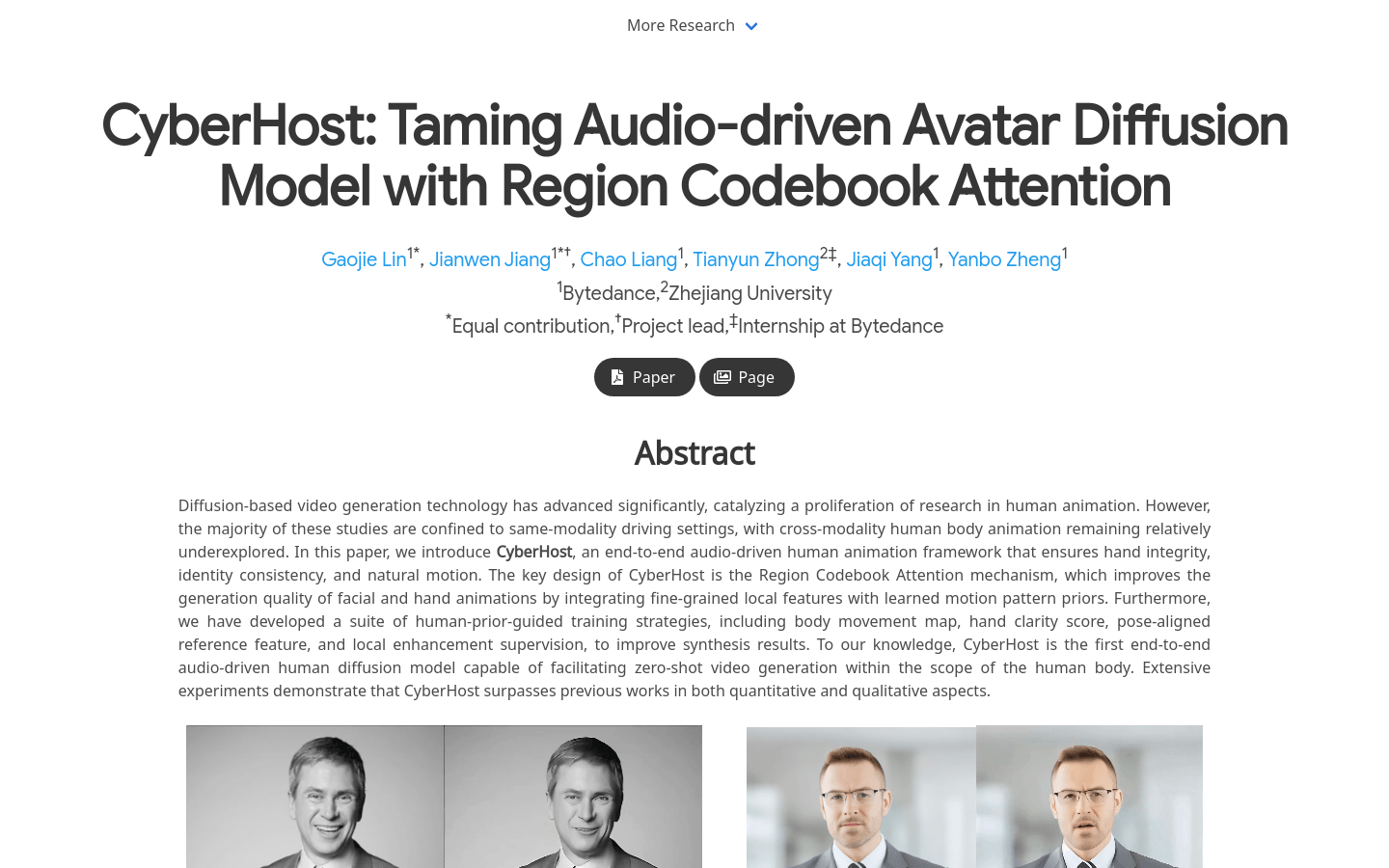
CyberHost
CyberHost是一个端到端音频驱动的人体动画框架,通过区域码本注意力机制,实现了手部完整性、身份一致性和自然运动的生成。该模型利用双U-Net架构作为基础结构,并通过运动帧策略进行时间延续,为音频驱动的人体动画建立了基线。CyberHost通过一系列以人为先导的训练策略,包括身体运动图、手部清晰度评分、姿势对齐的参考特征和局部增强监督,提高了合成结果的质量。CyberHost是首个能够在人体范围内实现零样本视频生成的音频驱动人体扩散模型。

EmoTalk3D
EmoTalk3D是一个专注于3D虚拟人头合成的研究项目,它通过收集多视角视频、情感注释和每帧3D几何数据来解决传统3D人头合成中存在的视角一致性和情感表达不足的问题。该项目提出了一种新颖的方法,通过训练EmoTalk3D数据集,实现了情感可控的3D人头合成,具有增强的唇部同步和渲染质量。EmoTalk3D模型能够生成具有广泛视角和高渲染质量的3D动画,同时捕捉到动态面部细节,如皱纹和微妙表情。

Clapper.app
Clapper.app是一个开源的AI故事可视化工具,能够将剧本解读并渲染成故事板、视频、声音和音乐。目前,该工具仍处于早期开发阶段,并不适用于普通用户,因为一些功能尚未完成,也没有教程等。

SV4D
Stable Video 4D (SV4D) 是基于 Stable Video Diffusion (SVD) 和 Stable Video 3D (SV3D) 的生成模型,它接受单一视角的视频并生成该对象的多个新视角视频(4D 图像矩阵)。该模型训练生成 40 帧(5 个视频帧 x 8 个摄像机视角)在 576x576 分辨率下,给定 5 个相同大小的参考帧。通过运行 SV3D 生成轨道视频,然后使用轨道视频作为 SV4D 的参考视图,并输入视频作为参考帧,进行 4D 采样。该模型还通过使用生成的第一帧作为锚点,然后密集采样(插值)剩余帧来生成更长的新视角视频。

FasterLivePortrait
FasterLivePortrait是一个基于深度学习的实时肖像动画化项目。它通过使用TensorRT在RTX 3090 GPU上实现30+ FPS的实时运行速度,包括预处理和后处理,而不仅仅是模型推理速度。该项目还实现了将LivePortrait模型转换为Onnx模型,并在RTX 3090上使用onnxruntime-gpu实现约70ms/帧的推理速度,支持跨平台部署。此外,该项目还支持原生gradio app,速度提升数倍,并支持多张人脸的同时推理。代码结构经过重构,不再依赖PyTorch,所有模型使用onnx或tensorrt进行推理。

RunwayML App
RunwayML是一款领先的下一代创意套件,提供了丰富的工具,让用户能够将任何想法转化为现实。该应用通过其独特的文本到视频生成技术,让用户仅通过文本描述即可在手机上生成视频。其主要优点包括: 1. 文本到视频生成:用户只需输入文本描述,即可生成视频。 2. 实时更新:定期推出新功能和更新,确保用户始终能够使用最新的AI视频和图片工具。 3. 无缝资产转移:用户可以在手机和电脑之间无缝转移资产。 4. 多种订阅选项:提供标准、专业和每月1000次生成信用的订阅选项。

TCAN
TCAN是一种基于扩散模型的新型人像动画框架,它能够保持时间一致性并很好地泛化到未见过的领域。该框架通过特有的模块,如外观-姿态自适应层(APPA层)、时间控制网络和姿态驱动的温度图,来确保生成的视频既保持源图像的外观,又遵循驱动视频的姿态,同时保持背景的一致性。

LivePortrait
LivePortrait是一个基于隐式关键点框架的人像动画生成模型,它通过使用单一源图像作为外观参考,并从驱动视频、音频、文本或生成中获取动作(如面部表情和头部姿势),来合成逼真的视频。该模型不仅在计算效率和可控性之间取得了有效平衡,而且通过扩展训练数据、采用混合图像-视频训练策略、升级网络架构以及设计更好的运动转换和优化目标,显著提高了生成质量和泛化能力。

MimicMotion
MimicMotion是由腾讯公司和上海交通大学联合研发的高质量人体动作视频生成模型。该模型通过信心感知的姿态引导,实现了对视频生成过程的可控性,提高了视频的时序平滑性,并减少了图像失真。它采用了先进的图像到视频的扩散模型,结合了时空U-Net和PoseNet,能够根据姿势序列条件生成任意长度的高质量视频。MimicMotion在多个方面显著优于先前的方法,包括手部生成质量、对参考姿势的准确遵循等。

Gen-3 Alpha
Gen-3 Alpha 是 Runway 训练的一系列模型中的首个,它在新的基础设施上训练,专为大规模多模态训练而建。它在保真度、一致性和动作方面相较于 Gen-2 有重大改进,并朝着构建通用世界模型迈进了一步。该模型能够生成具有丰富动作、手势和情感的表达性人物角色,为叙事提供了新的机会。