共找到 43 个AI工具
点击任意工具查看详细信息
夸克・造点 AI 是一个利用先进的 AI 技术生成图像和视频的平台,用户可以通过简单的输入生成视觉内容。它的主要优点是快速高效,适用于设计师、艺术家和内容创作者。该产品为用户提供灵活的创作工具,帮助他们在短时间内实现创意构思,定价模式灵活,为用户提供了更多选择。
图片转视频AI生成器利用先进的AI模型,将静态图片转换为引人注目的视频,适用于社交媒体创作者和任何想要体验AI视频生成的人。产品定位于简化视频制作流程,提高效率。
AI Animate Image利用先进的AI技术,将静态图片转化为生动的动画,提供专业级动画质量和流畅的动态效果。
Grok Imagine是由Aurora引擎驱动的AI图像和视频生成平台,可生成多领域的逼真图像和动态视频内容。其核心技术基于Aurora引擎的自回归图像模型,为用户提供高质量、多样化的视觉创作体验。
WAN 2.1 LoRA T2V是一款能够根据文本提示生成视频的工具,通过LoRA模块的定制训练,用户可以定制化生成视频,适用于品牌叙事、粉丝内容和风格化动画。产品背景丰富,提供高度定制化的视频生成体验。
Openjourney 是一个高保真的开源项目,旨在模拟 MidJourney 的界面,利用 Google 的 Gemini SDK 进行 AI 图像和视频生成。该项目支持使用 Imagen 4 生成高质量图像,以及使用 Veo 2 和 Veo 3 进行文本到视频和图像到视频的转换。它适合需要进行图像生成和视频制作的开发者和创作者,提供了用户友好的界面和实时生成体验,能够助力创意工作与项目开发。
a2e.ai是一款AI工具,提供AI头像、唇形同步、语音克隆、文字生成视频等功能。该产品具有高清晰度、高一致性、高效生成速度等优点,适用于各种场景,提供完整的头像AI工具集。
FlyAgt是一个AI图像和视频生成平台,提供先进的AI工具,从创建到编辑再到增强图像。它的主要优点在于价格实惠,提供多种专业工具,并保护用户隐私。
iMyFone DreamVid是一款强大的AI图像转视频工具,通过上传照片,AI可以将静态图像转化为生动的视频,包括拥抱、亲吻、面部交换等特效。该工具背景信息丰富,价格适中,定位于个人用户和小型企业。
Everlyn AI是世界领先的AI视频生成器和免费AI图片生成器,使用先进的AI技术将您的想法转化为令人惊叹的视觉效果。它具有颠覆性的性能指标,包括15秒快速生成速度、25倍降低成本、8倍更高效率。
Describe Anything 模型(DAM)能够处理图像或视频的特定区域,并生成详细描述。它的主要优点在于可以通过简单的标记(点、框、涂鸦或掩码)来生成高质量的本地化描述,极大地提升了计算机视觉领域的图像理解能力。该模型由 NVIDIA 和多所大学联合开发,适合用于研究、开发和实际应用中。
vivago.ai 是一个免费的 AI 生成工具和社区,提供文本转图像、图像转视频等功能,让创作变得更加简单高效。用户可以免费生成高质量的图像和视频,支持多种 AI 编辑工具,方便用户进行创作和分享。该平台的定位是为广大创作者提供易用的 AI 工具,满足他们在视觉创作上的需求。
Stable Virtual Camera是Stability AI开发的一个1.3B参数的通用扩散模型,属于Transformer图像转视频模型。其重要性在于为新型视图合成(NVS)提供了技术支持,能够根据输入视图和目标相机生成3D一致的新场景视图。主要优点是可自由指定目标相机轨迹,能生成大视角变化且时间上平滑的样本,无需额外神经辐射场(NeRF)蒸馏即可保持高一致性,还能生成长达半分钟的高质量无缝循环视频。该模型仅可免费用于研究和非商业用途,定位是为研究人员和非商业创作者提供创新的图像转视频解决方案。
Pippo 是由 Meta Reality Labs 和多所高校合作开发的生成模型,能够从单张普通照片生成高分辨率的多人视角视频。该技术的核心优势在于无需额外输入(如参数化模型或相机参数),即可生成高质量的 1K 分辨率视频。它基于多视角扩散变换器架构,具有广泛的应用前景,如虚拟现实、影视制作等。Pippo 的代码已开源,但不包含预训练权重,用户需要自行训练模型。
Animate Anyone 2 是一种基于扩散模型的角色图像动画技术,能够生成与环境高度适配的动画。它通过提取环境表示作为条件输入,解决了传统方法中角色与环境缺乏合理关联的问题。该技术的主要优点包括高保真度、环境适配性强以及动态动作处理能力出色。它适用于需要高质量动画生成的场景,如影视制作、游戏开发等领域,能够帮助创作者快速生成具有环境交互的角色动画,节省时间和成本。
X-Dyna是一种创新的零样本人类图像动画生成技术,通过将驱动视频中的面部表情和身体动作迁移到单张人类图像上,生成逼真且富有表现力的动态效果。该技术基于扩散模型,通过Dynamics-Adapter模块,将参考外观上下文有效整合到扩散模型的空间注意力中,同时保留运动模块合成流畅复杂动态细节的能力。它不仅能够实现身体姿态控制,还能通过本地控制模块捕捉与身份无关的面部表情,实现精确的表情传递。X-Dyna在多种人类和场景视频的混合数据上进行训练,能够学习物理人体运动和自然场景动态,生成高度逼真和富有表现力的动画。
Hallo3是一种用于肖像图像动画的技术,它利用预训练的基于变换器的视频生成模型,能够生成高度动态和逼真的视频,有效解决了非正面视角、动态对象渲染和沉浸式背景生成等挑战。该技术由复旦大学和百度公司的研究人员共同开发,具有强大的泛化能力,为肖像动画领域带来了新的突破。
DisPose是一种用于控制人类图像动画的方法,它通过运动场引导和关键点对应来提高视频生成的质量。这项技术能够从参考图像和驱动视频中生成视频,同时保持运动对齐和身份信息的一致性。DisPose通过从稀疏的运动场和参考图像生成密集的运动场,提供区域级别的密集引导,同时保持稀疏姿态控制的泛化能力。此外,它还从参考图像中提取与姿态关键点对应的扩散特征,并将这些点特征转移到目标姿态,以提供独特的身份信息。DisPose的主要优点包括无需额外的密集输入即可提取更通用和有效的控制信号,以及通过即插即用的混合ControlNet提高生成视频的质量和一致性,而无需冻结现有模型参数。
Ruyi-Models是一个图像到视频的模型,能够生成高达768分辨率、每秒24帧的电影级视频,支持镜头控制和运动幅度控制。使用RTX 3090或RTX 4090显卡,可以无损生成512分辨率、120帧的视频。该模型以其高质量的视频生成能力和对细节的精确控制而受到关注,尤其在需要生成高质量视频内容的领域,如电影制作、游戏制作和虚拟现实体验中具有重要应用价值。
ComfyUI-IF_MemoAvatar是一个基于记忆引导扩散的模型,用于生成表达性的视频。该技术允许用户从单一图像和音频输入创建富有表现力的说话头像视频。这项技术的重要性在于其能够将静态图像转化为动态视频,同时保留图像中人物的面部特征和情感表达,为视频内容创作提供了新的可能性。该模型由Longtao Zheng等人开发,并在arXiv上发布相关论文。
HelloMeme是一个集成了空间编织注意力(Spatial Knitting Attentions)的扩散模型,用于嵌入高级别和细节丰富的条件。该模型支持图像和视频的生成,具有改善生成视频与驱动视频之间表情一致性、减少VRAM使用、优化算法等优点。HelloMeme由HelloVision团队开发,属于HelloGroup Inc.,是一个前沿的图像和视频生成技术,具有重要的商业和教育价值。
Qwen2-VL-72B是Qwen-VL模型的最新迭代,代表了近一年的创新成果。该模型在视觉理解基准测试中取得了最新的性能,包括MathVista、DocVQA、RealWorldQA、MTVQA等。它能够理解超过20分钟的视频,并可以集成到手机、机器人等设备中,进行基于视觉环境和文本指令的自动操作。除了英语和中文,Qwen2-VL现在还支持图像中不同语言文本的理解,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。模型架构更新包括Naive Dynamic Resolution和Multimodal Rotary Position Embedding (M-ROPE),增强了其多模态处理能力。
Qwen2-VL-7B是Qwen-VL模型的最新迭代,代表了近一年的创新成果。该模型在视觉理解基准测试中取得了最先进的性能,包括MathVista、DocVQA、RealWorldQA、MTVQA等。它能够理解超过20分钟的视频,为基于视频的问题回答、对话、内容创作等提供高质量的支持。此外,Qwen2-VL还支持多语言,除了英语和中文,还包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。模型架构更新包括Naive Dynamic Resolution和Multimodal Rotary Position Embedding (M-ROPE),增强了其多模态处理能力。
FLOAT是一种音频驱动的人像视频生成方法,它基于流匹配生成模型,将生成建模从基于像素的潜在空间转移到学习到的运动潜在空间,实现了时间上一致的运动设计。该技术引入了基于变换器的向量场预测器,并具有简单而有效的逐帧条件机制。此外,FLOAT支持语音驱动的情感增强,能够自然地融入富有表现力的运动。广泛的实验表明,FLOAT在视觉质量、运动保真度和效率方面均优于现有的音频驱动说话人像方法。
CAT4D是一个利用多视图视频扩散模型从单目视频中生成4D场景的技术。它能够将输入的单目视频转换成多视角视频,并重建动态的3D场景。这项技术的重要性在于它能够从单一视角的视频资料中提取并重建出三维空间和时间的完整信息,为虚拟现实、增强现实以及三维建模等领域提供了强大的技术支持。产品背景信息显示,CAT4D由Google DeepMind、Columbia University和UC San Diego的研究人员共同开发,是一个前沿的科研成果转化为实际应用的案例。
Fashion-VDM是一个视频扩散模型(VDM),用于生成虚拟试穿视频。该模型接受一件衣物图片和人物视频作为输入,旨在生成人物穿着给定衣物的高质量试穿视频,同时保留人物的身份和动作。与传统的基于图像的虚拟试穿相比,Fashion-VDM在衣物细节和时间一致性方面表现出色。该技术的主要优点包括:扩散式架构、分类器自由引导增强控制、单次64帧512px视频生成的渐进式时间训练策略,以及联合图像-视频训练的有效性。Fashion-VDM在视频虚拟试穿领域树立了新的行业标准。
MimicTalk是一种基于神经辐射场(NeRF)的个性化三维说话面部生成技术,它能够在几分钟内模仿特定身份的静态外观和动态说话风格。这项技术的主要优点包括高效率、高质量的视频生成以及对目标人物说话风格的精确模仿。MimicTalk通过一个通用的3D面部生成模型作为基础,并通过静态-动态混合适应流程来学习个性化的静态外观和面部动态,同时提出了一种上下文风格化的音频到运动(ICS-A2M)模型,以生成与目标人物说话风格相匹配的面部运动。MimicTalk的技术背景是基于深度学习和计算机视觉领域的最新进展,特别是在人脸合成和动画生成方面。目前,该技术是免费提供给研究和开发社区的。
LivePortrait是一款AI驱动的动画制作工具,由快手科技开源,能够将静态照片快速转化为逼真的动态视频。它支持真实照片、动画风格和艺术肖像等多种风格,并提供精确的动作控制,如眼睛和嘴唇的自然运动。LivePortrait还具备多样化的风格支持、自定义动画模式、增强的图像处理功能,以及快速的创作过程。
HiDream.ai是一个专注于图像和视频创作的网站,利用人工智能技术提供多种功能。其重要性在于帮助用户更轻松地创建高质量的图像和视频内容。该产品具有功能丰富、操作简单等优点,适用于各种需要进行图像和视频创作的用户。目前,部分功能可能需要付费或免费试用。
Animate Old Photos是一个利用Kling AI技术将老照片转化为生动视频的网站。它通过AI技术使旧时记忆重新焕发活力,为用户带来更加生动和动态的体验。该产品目前处于beta测试阶段,免费提供服务,但随着高级功能的增加,未来可能会推出付费计划。
Haiper AI 是构建下一代内容创作的最佳感知基础模型的使命。它提供以下主要功能:文本转视频,图片动画,视频重绘,导演视角。Haiper AI 可以将文字内容和静态图片无缝转化为动态视频,只需拖放图像即可使其栩栩如生。使用 Haiper AI 的重绘工具,您可以轻松修改视频的颜色、纹理和元素,以提升视觉内容的品质。通过高级控制工具,您可以像导演一样调整镜头角度、灯光效果、角色姿势和物体运动。Haiper AI 适用于各种场景,如内容创作、设计、营销等。定价请参考官方网站。
BasedLabs.ai是您获取AI视频和工具的首选来源。我们提供功能强大的AI视频工具,同时也是一个活跃的社区,让您可以与其他创作者互动和分享作品。我们的工具包括视频生成和克隆功能,可以帮助您快速生成惊人的AI视频作品。
MagicAnimate是一款基于扩散模型的先进框架,用于人体图像动画。它能够从单张图像和动态视频生成动画视频,具有时域一致性,能够保持参考图像的特征,并显著提升动画的保真度。MagicAnimate支持使用来自各种来源的动作序列进行图像动画,包括跨身份的动画和未见过的领域,如油画和电影角色。它还与DALLE3等T2I扩散模型无缝集成,可以根据文本生成的图像赋予动态动作。MagicAnimate由新加坡国立大学Show Lab和Bytedance字节跳动共同开发。
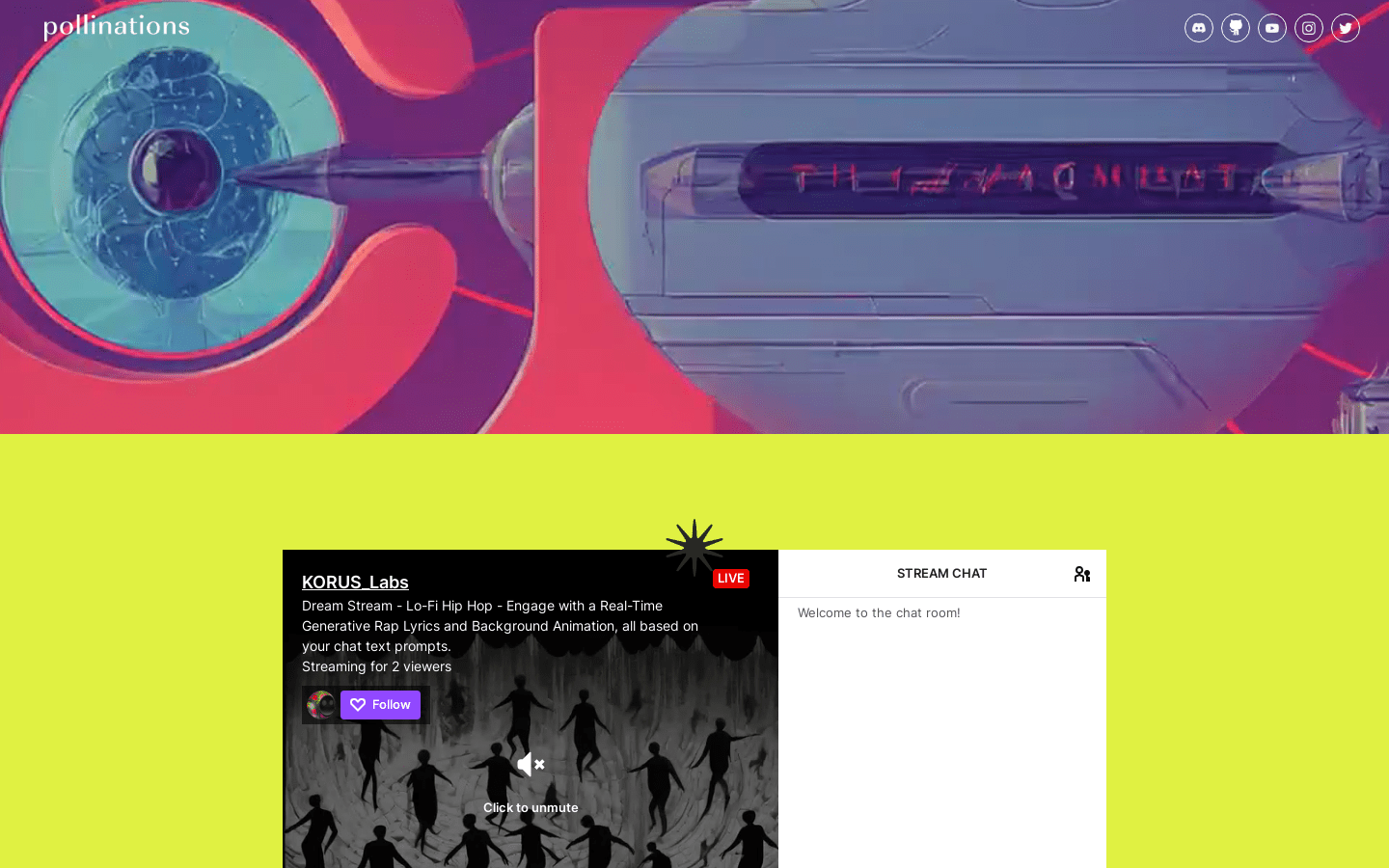
Pollinations是一个集合了数据科学家、机器学习专家、艺术家和未来学家的团队,在AI生态系统中深度参与。现在,Pollinations将重点放在AI音乐视频创作上,并将很快推出一款名为Dreamachine的激动人心的实时沉浸式AI产品。
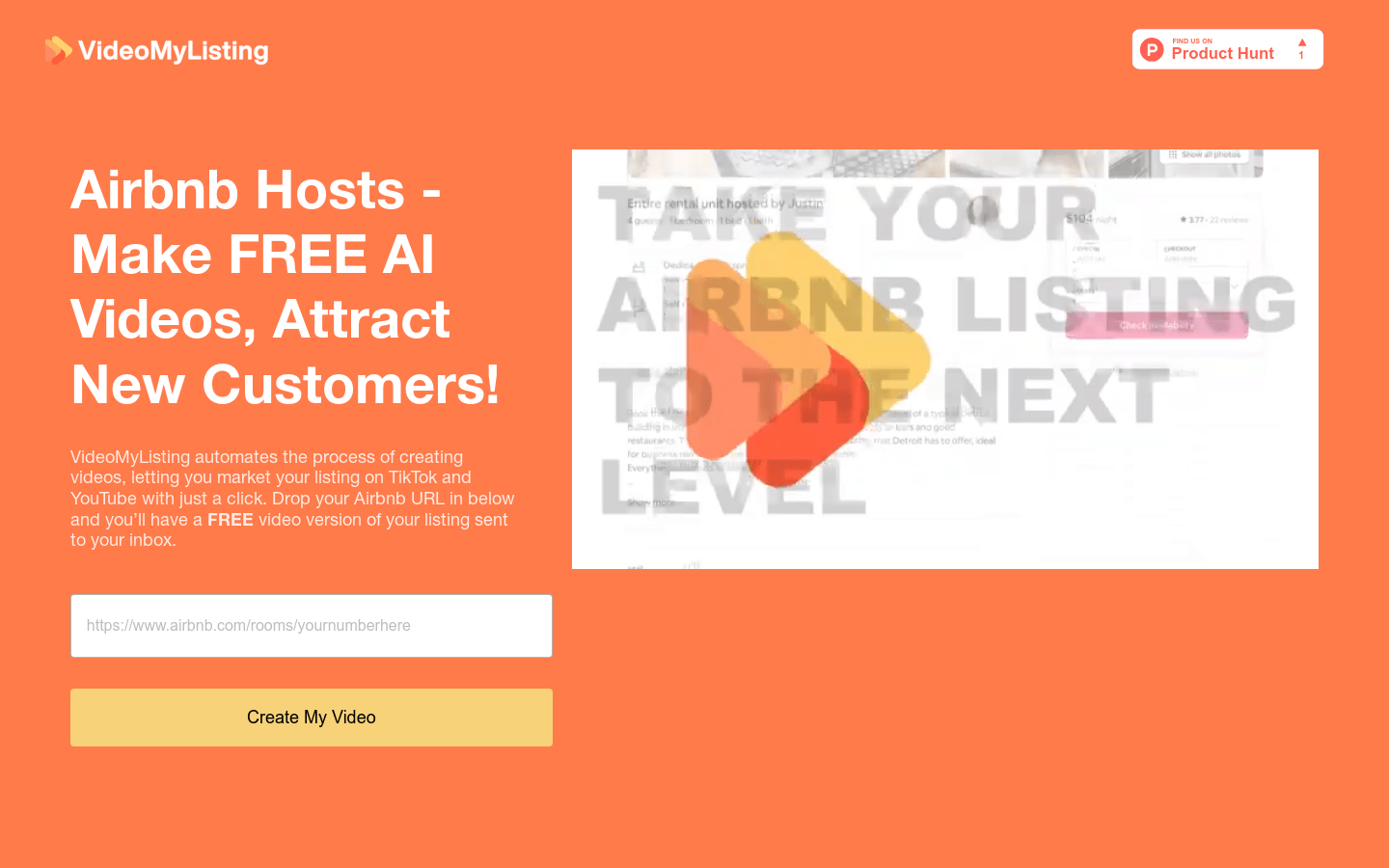
VideoMyListing是一个AI辅助视频生成工具,可以帮助Airbnb房东通过自动化生成视频来营销他们的房源。用户只需粘贴房源链接,VideoMyListing就会利用AI技术自动生成具有吸引力的视频,可用于在社交媒体平台上推广。该工具提供商业许可的内容,生成的视频格式为MP4,适用于Instagram、LinkedIn和Snapchat等社交视频服务。
LensGo 是一个免费的 AI 驱动的图像和视频制作工具,最适合定制化视频制作。它能帮助用户制作个性化的 AI 视频。
8 Arc是一款强大的文本转电影生成器。用户可以输入电影的剧本或简短的故事概念,通过AI生成符合要求的电影脚本。用户还可以描述角色和场景,生成完整的电影故事。8 Arc可以帮助用户轻松创建自己的电影剧本,为创作者提供灵感和创作工具。
THE FABLE STUDIO可以将您的想法转化为令人着迷的故事,利用AI的力量。您可以将简单的文本转化为具有风格和独创性的引人入胜的故事。通过选择的风格表达,我们的尖端技术将您的文字转化为独特的视频。您可以重新塑造喜欢的角色,改变故事的进程甚至改变喜欢的电影的结局。
Olm是一种基于光学语言模型的产品,可以帮助用户在几分钟内从头开始生成全新的视频。它能够创建、重新构思和理解多媒体,并生成与用户要求相符的内容。Olm具有以下主要功能:1. 生成全新的视频内容;2. 重新构思现有的视频内容;3. 理解和分析多媒体。Olm适用于各种场景,包括创作、教育、娱乐等领域。具体定价信息请访问官方网站。
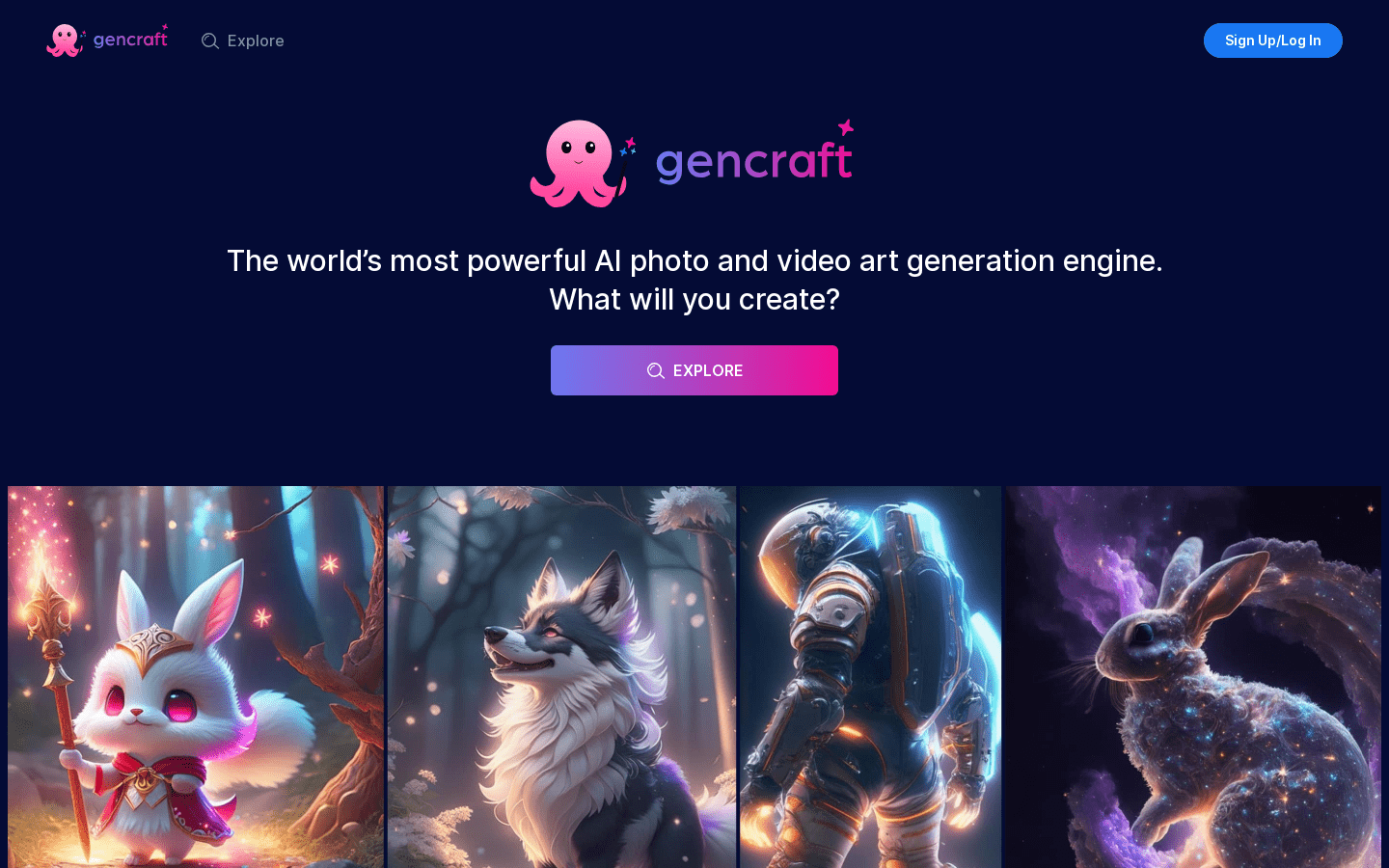
Gencraft是一款强大的AI图像和视频艺术生成引擎,可以将您的想法转化为惊人的AI生成艺术,无论是照片还是视频。您可以使用关键词来激发您的想象力,并将其与样式配对,以获得更个性化的结果。Gencraft适用于生产力、设计、写作、商业等领域,可以帮助您轻松地创造出真正代表您的创意品牌。
Vidnoz的Talking Head是一款在线工具,可让您在几分钟内创建逼真的说话头像。它利用人工智能技术生成具有口型和声音的头像视频,可用于销售、营销、沟通和支持等多种场景。Talking Head提供免费使用,同时也提供付费套餐以享受更多高级功能。
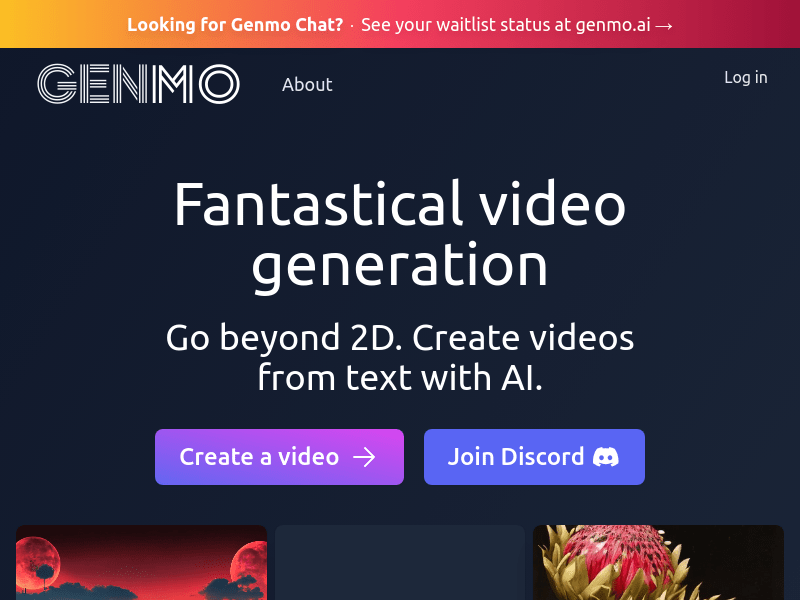
Genmokey是一个能够使用AI从文本生成视频的创意工具。它能够将您输入的文字转化为独特的视频作品,超越传统的2D效果。无论您是想创建个人视频、营销广告还是其他创意项目,Genmokey都能够帮助您实现想象力的极限。Genmokey是一个全面的视频生成工具,提供丰富的功能和定制选项。定价方案灵活,适合个人和企业使用。无论您是设计师、营销人员、创意从业者还是视频爱好者,Genmokey都将成为您的得力助手。
Luma AI是一家专注于AI的技术公司,通过其创新技术,用户可以利用手机快速生成所需的3D模型。公司由拥有丰富3D计算机视觉经验的团队成立,其技术基于Neural Radiance Fields,能够基于少量2D图像对3D场景进行建模。Dream Machine是一个AI模型,能够直接从文本和图像快速生成高质量的逼真视频。它是一个高度可扩展且高效的transformer模型,专门针对视频进行训练,能够生成物理上准确、一致且充满事件的镜头。Dream Machine是构建通用想象力引擎的第一步,现已对所有人开放。
探索 图像 分类下的其他子分类
832 个工具
771 个工具
543 个工具
522 个工具
352 个工具
196 个工具
95 个工具
68 个工具
视频生成 是 图像 分类下的热门子分类,包含 43 个优质AI工具