共找到 40 个AI工具
点击任意工具查看详细信息
GaussianCity是一个专注于高效生成无边界3D城市的框架,基于3D高斯绘制技术。该技术通过紧凑的3D场景表示和空间感知的高斯属性解码器,解决了传统方法在生成大规模城市场景时面临的内存和计算瓶颈。其主要优点是能够在单次前向传递中快速生成大规模3D城市,显著优于现有技术。该产品由南洋理工大学S-Lab团队开发,相关论文发表于CVPR 2025,代码和模型已开源,适用于需要高效生成3D城市环境的研究人员和开发者。
Funes是一个创新的在线博物馆项目,通过众包摄影测量技术将全球人类建筑转化为3D模型,旨在创建一个免费、可访问的庞大3D数据库。该项目以阿根廷作家博尔赫斯笔下的'博闻强记的福内斯'命名,象征着对人类物质记忆的永恒保存。Funes不仅是一个技术展示平台,更是一个文化传承项目,通过数字化手段保护人类文明的建筑遗产。
DiffSplat 是一种创新的 3D 生成技术,能够从文本提示和单视图图像快速生成 3D 高斯点云。该技术通过利用大规模预训练的文本到图像扩散模型,实现了高效的 3D 内容生成。它解决了传统 3D 生成方法中数据集有限和无法有效利用 2D 预训练模型的问题,同时保持了 3D 一致性。DiffSplat 的主要优点包括高效的生成速度(1~2 秒内完成)、高质量的 3D 输出以及对多种输入条件的支持。该模型在学术研究和工业应用中具有广泛前景,尤其是在需要快速生成高质量 3D 模型的场景中。
ComfyUI-Hunyuan3DWrapper 是一个基于 ComfyUI 的插件,封装了 Hunyuan3D-2 模型,用于高效的 3D 图像生成和纹理处理。该工具通过简化 Hunyuan3D-2 模型的使用流程,使得用户能够在 ComfyUI 环境下快速实现高质量的 3D 模型生成和纹理渲染。它支持自定义配置和扩展,适用于需要高效 3D 内容创作的用户。
StructLDM是一个结构化潜在扩散模型,用于从2D图像学习3D人体生成。它能够生成多样化的视角一致的人体,并支持不同级别的可控生成和编辑,如组合生成和局部服装编辑等。该模型在无需服装类型或掩码条件的情况下,实现了服装无关的生成和编辑。项目由南洋理工大学S-Lab的Tao Hu、Fangzhou Hong和Ziwei Liu提出,相关论文发表于ECCV 2024。
Stable Point Aware 3D (SPAR3D) 是 Stability AI 推出的先进3D生成模型。它能够在不到一秒的时间内,从单张图像中实现3D对象的实时编辑和完整结构生成。SPAR3D采用独特的架构,结合精确的点云采样与先进的网格生成技术,为3D资产创建提供了前所未有的控制力。该模型免费提供给商业和非商业用途,可在Hugging Face下载权重,GitHub获取代码,或通过Stability AI开发者平台API访问。
Instant 3D AI是一个利用人工智能技术,能够将2D图像快速转换成3D模型的在线平台。该技术的重要性在于它极大地简化了3D模型的创建过程,使得非专业人士也能轻松创建高质量的3D模型。产品背景信息显示,Instant 3D AI已经获得了1400多位创作者的信任,并获得了4.8/5的优秀评分。产品的主要优点包括快速生成3D模型、用户友好的操作界面以及高用户满意度。价格方面,Instant 3D AI提供免费试用,让用户可以先体验产品再决定是否付费。
TRELLIS 3D AI是一款利用人工智能技术将图片转换成3D资产的专业工具。它通过结合先进的神经网络和结构化潜在技术(Structured LATents, SLAT),能够保持输入图片的结构完整性和视觉细节,生成高质量的3D资产。产品背景信息显示,TRELLIS 3D AI被全球专业人士信赖,用于可靠的图像到3D资产的转换。与传统的3D建模工具不同,TRELLIS 3D AI提供了一个无需复杂操作的图像到3D资产的转换过程。产品价格为免费,适合需要快速、高效生成3D资产的用户。
MegaSaM是一个系统,它允许从动态场景的单目视频中准确、快速、稳健地估计相机参数和深度图。该系统突破了传统结构从运动和单目SLAM技术的局限,这些技术通常假设输入视频主要包含静态场景和大量视差。MegaSaM通过深度视觉SLAM框架的精心修改,能够扩展到真实世界中复杂动态场景的视频,包括具有未知视场和不受限制相机路径的视频。该技术在合成和真实视频上的广泛实验表明,与先前和并行工作相比,MegaSaM在相机姿态和深度估计方面更为准确和稳健,运行时间更快或相当。
GenEx是一个AI模型,它能够从单张图片创建一个完全可探索的360°3D世界。用户可以互动地探索这个生成的世界。GenEx在想象空间中推进具身AI,并有潜力将这些能力扩展到现实世界的探索。
TRELLIS是一个基于统一结构化潜在表示和修正流变换器的原生3D生成模型,能够实现多样化和高质量的3D资产创建。该模型通过整合稀疏的3D网格和从强大的视觉基础模型提取的密集多视图视觉特征,全面捕获结构(几何)和纹理(外观)信息,同时在解码过程中保持灵活性。TRELLIS模型能够处理高达20亿参数,并在包含50万个多样化对象的大型3D资产数据集上进行训练。该模型在文本或图像条件下生成高质量结果,显著超越现有方法,包括规模相似的最近方法。TRELLIS还展示了灵活的输出格式选择和局部3D编辑能力,这些是以前模型所没有提供的。代码、模型和数据将被发布。
PSHuman是一个创新的框架,它利用多视图扩散模型和显式重构技术,从单张图片中重建出逼真的3D人体模型。这项技术的重要性在于它能够处理复杂的自遮挡问题,并且在生成的面部细节上避免了几何失真。PSHuman通过跨尺度扩散模型联合建模全局全身形状和局部面部特征,实现了细节丰富且保持身份特征的新视角生成。此外,PSHuman还通过SMPL-X等参数化模型提供的身体先验,增强了不同人体姿态下的跨视图身体形状一致性。PSHuman的主要优点包括几何细节丰富、纹理保真度高以及泛化能力强。
这是一个能够从单张图片生成3D世界的AI系统,它允许用户进入任何图片并进行3D探索。这项技术改善了控制和一致性,将改变我们制作电影、游戏、模拟器以及其他数字表现形式的方式。它代表了空间智能的第一步,通过在浏览器中实时渲染生成的世界,用户可以体验不同的相机效果、3D效果,并深入探索经典画作。
CAT4D是一个利用多视图视频扩散模型从单目视频中生成4D场景的技术。它能够将输入的单目视频转换成多视角视频,并重建动态的3D场景。这项技术的重要性在于它能够从单一视角的视频资料中提取并重建出三维空间和时间的完整信息,为虚拟现实、增强现实以及三维建模等领域提供了强大的技术支持。产品背景信息显示,CAT4D由Google DeepMind、Columbia University和UC San Diego的研究人员共同开发,是一个前沿的科研成果转化为实际应用的案例。
LucidFusion是一个灵活的端到端前馈框架,用于从未摆姿势、稀疏和任意数量的多视图图像中生成高分辨率3D高斯。该技术利用相对坐标图(RCM)来对齐不同视图间的几何特征,使其在3D生成方面具有高度适应性。LucidFusion能够与原始单图像到3D的流程无缝集成,生成512x512分辨率的详细3D高斯,适合广泛的应用场景。
DimensionX是一个基于视频扩散模型的3D和4D场景生成技术,它能够从单张图片中创建出具有可控视角和动态变化的三维和四维场景。这项技术的主要优点包括高度的灵活性和逼真度,能够根据用户提供的提示词生成各种风格和主题的场景。DimensionX的背景信息显示,它是由一群研究人员共同开发的,旨在推动图像生成技术的发展。目前,该技术是免费提供给研究和开发社区使用的。
GenXD是一个专注于3D和4D场景生成的框架,它利用日常生活中常见的相机和物体运动来联合研究一般的3D和4D生成。由于社区缺乏大规模的4D数据,GenXD首先提出了一个数据策划流程,从视频中获取相机姿态和物体运动强度。基于此流程,GenXD引入了一个大规模的现实世界4D场景数据集:CamVid-30K。通过利用所有3D和4D数据,GenXD框架能够生成任何3D或4D场景。它提出了多视图-时间模块,这些模块分离相机和物体运动,无缝地从3D和4D数据中学习。此外,GenXD还采用了掩码潜在条件,以支持多种条件视图。GenXD能够生成遵循相机轨迹的视频以及可以提升到3D表示的一致3D视图。它在各种现实世界和合成数据集上进行了广泛的评估,展示了GenXD在3D和4D生成方面与以前方法相比的有效性和多功能性。
Hunyuan3D-1是腾讯推出的一个统一框架,用于文本到3D和图像到3D的生成。该框架采用两阶段方法,第一阶段使用多视图扩散模型快速生成多视图RGB图像,第二阶段通过前馈重建模型快速重建3D资产。Hunyuan3D-1.0在速度和质量之间取得了令人印象深刻的平衡,显著减少了生成时间,同时保持了生成资产的质量和多样性。
腾讯混元3D是一个开源的3D生成模型,旨在解决现有3D生成模型在生成速度和泛化能力上的不足。该模型采用两阶段生成方法,第一阶段使用多视角扩散模型快速生成多视角图像,第二阶段通过前馈重建模型快速重建3D资产。混元3D-1.0模型能够帮助3D创作者和艺术家自动化生产3D资产,支持快速单图生3D,10秒内完成端到端生成,包括mesh和texture提取。
GAGAvatar是一种基于高斯模型的3D头像重建与动画生成技术,它能够在单张图片的基础上快速生成3D头像,并实现实时的面部表情动画。这项技术的主要优点包括高保真度的3D模型生成、快速的渲染速度以及对未见身份的泛化能力。GAGAvatar通过创新的双提升方法捕捉身份和面部细节,利用全局图像特征和3D可变形模型来控制表情,为数字头像的研究和应用提供了新的基准。
Long-LRM是一个用于3D高斯重建的模型,能够从一系列输入图像中重建出大场景。该模型能在1.3秒内处理32张960x540分辨率的源图像,并且仅在单个A100 80G GPU上运行。它结合了最新的Mamba2模块和传统的transformer模块,通过高效的token合并和高斯修剪步骤,在保证质量的同时提高了效率。与传统的前馈模型相比,Long-LRM能够一次性重建整个场景,而不是仅重建场景的一小部分。在大规模场景数据集上,如DL3DV-140和Tanks and Temples,Long-LRM的性能可与基于优化的方法相媲美,同时效率提高了两个数量级。
书生·天际LandMark是一个基于NeRF技术的实景三维大模型,它实现了100平方公里的4K高清训练,具备实时渲染和自由编辑的能力。这项技术代表了城市级三维建模和渲染的新高度,具有极高的训练和渲染效率,为城市规划、建筑设计和虚拟现实等领域提供了强大的工具。
Mug Life通过将计算机图形学专业知识与最新的计算机视觉技术相结合,创造出令人惊叹的3D角色。其技术分为三个阶段:拆解、动画和重构,结合社交平台,让用户能够连接和分享创作。
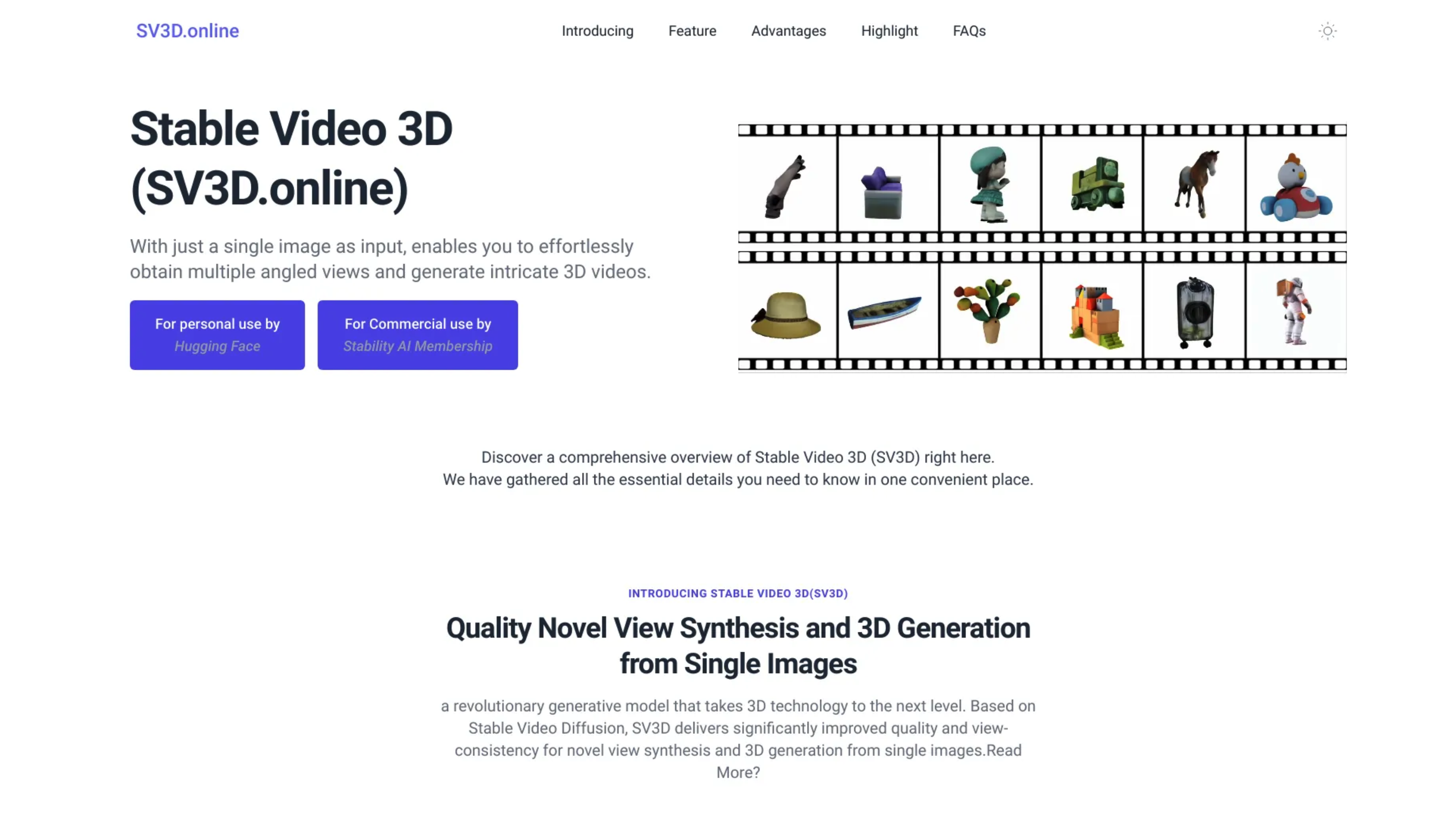
SV3D Online是一款稳定的在线3D视频合成工具,能够将单个图像转化为引人入胜的3D视角和网格。
CRM是一个高保真的单图像到3D纹理网格的生成模型,它通过整合几何先验到网络设计中,能够从单个输入图像生成六个正交视图图像,然后利用卷积U-Net创建高分辨率的三平面(triplane)。CRM进一步使用Flexicubes作为几何表示,便于在纹理网格上进行直接的端到端优化。整个模型能够在10秒内从图像生成高保真的纹理网格,无需测试时优化。
Depthify.ai是一个工具,可以将RGB图像转换为与Apple Vision Pro和Meta Quest兼容的各种空间格式。通过转换RGB图像为空间照片,可以为各种计算机视觉和3D建模应用提供支持。它可以生成深度图、立体图像和HEIC文件,可在Apple Vision Pro上使用。
DUSt3R是一种新颖的密集和无约束立体3D重建方法,适用于任意图像集合。它不需要事先了解相机校准或视点姿态信息,通过将成对重建问题视为点图的回归,放宽了传统投影相机模型的严格约束。DUSt3R提供了一种统一的单目和双目重建方法,并在多图像情况下提出了一种简单有效的全局对齐策略。基于标准的Transformer编码器和解码器构建网络架构,利用强大的预训练模型。DUSt3R直接提供场景的3D模型和深度信息,并且可以从中恢复像素匹配、相对和绝对相机信息。
SIGNeRF是一种用于快速和可控的NeRF场景编辑以及场景集成对象生成的新方法。它引入了一种新的生成更新策略,确保在编辑图像时保持3D一致性,而无需进行迭代优化。SIGNeRF利用了ControlNet的深度条件图像扩散模型的优势,通过几个简单的步骤在单个前向传递中编辑现有的NeRF场景。它可以生成新的对象到现有的NeRF场景中,也可以编辑已存在的对象,从而实现对场景的精确控制。
HAAR是一种基于文本输入的生成模型,可生成逼真的3D发型。它采用文本提示作为输入,生成准备用于各种计算机图形动画应用的3D发型资产。与当前基于AI的生成模型不同,HAAR利用3D发丝作为基础表示,通过2D视觉问答系统自动注释生成的合成发型模型。我们提出了一种基于文本引导的生成方法,使用条件扩散模型在潜在的发型UV空间生成引导发丝,并使用潜在的上采样过程重建含有数十万发丝的浓密发型,给定文本描述。生成的发型可以使用现成的计算机图形技术进行渲染。
Gaussian SLAM能够从RGBD数据流重建可渲染的3D场景。它是第一个能够以照片级真实感重建现实世界场景的神经RGBD SLAM方法。通过利用3D高斯作为场景表示的主要单元,我们克服了以往方法的局限性。我们观察到传统的3D高斯在单目设置下很难使用:它们无法编码准确的几何信息,并且很难通过单视图顺序监督进行优化。通过扩展传统的3D高斯来编码几何信息,并设计一种新颖的场景表示以及增长和优化它的方法,我们提出了一种能够重建和渲染现实世界数据集的SLAM系统,而且不会牺牲速度和效率。高斯SLAM能够重建和以照片级真实感渲染现实世界场景。我们在常见的合成和真实世界数据集上对我们的方法进行了评估,并将其与其他最先进的SLAM方法进行了比较。最后,我们证明了我们得到的最终3D场景表示可以通过高效的高斯飞溅渲染实时渲染。
Tafi Avatar是一款AI Text-to-3D角色引擎,是创建定制3D角色的最快方式。它提供了数百万个高质量的3D资源,无需任何先前的3D经验即可开始使用。您可以通过文本提示输入,无需自己设计3D角色。Tafi Avatar速度快、质量高,适用于多种场景和用途。
Looking Glass Blocks是第一个为3D创作者打造的全息共享平台。它提供了一个内置的人工智能转换工具,可以将任何2D图像转换为全息图。用户可以将全息图分享和嵌入到互联网上的任何设备,并直接投射到Looking Glass显示器上。无需调整光照或纹理,可以按照设计的方式展示3D场景。Looking Glass Blocks还提供了一个发现平台,让用户可以发现和分享其他创作者创建的全息图。
3DFY.ai使用人工智能技术从文本或仅一个图像生成高质量的3D模型。现在任何人都可以快速创建各行业的引人注目的3D资源。我们提供3DFY Prompt、3DFY Megapacks和3DFY Image等服务。我们的技术基于先进的AI基础设施,确保模型质量和独特性。定价请访问官方网站获取详细信息。
Polycam是一款能够使用LiDAR扫描仪和摄影测量来捕捉现实的应用。它可以将现实世界的物体转换为3D模型,并且支持在iPhone、iPad、Android和Web上进行3D扫描和下载3D模型。Polycam的主要功能包括高精度的扫描、快速生成3D模型、可视化编辑和测量工具等。它适用于需要进行3D扫描和模型制作的用户,例如建筑师、设计师、艺术家等。Polycam提供免费和付费版本,付费版本提供更多高级功能和更大的模型导出尺寸。
CopernicAI是一个下一代生成式AI环境,利用最新的深度学习技术生成高质量的360度全景图像。它采用2+1D方法生成环境,结合2D图像和1D深度信息,为用户提供沉浸式的视觉体验。CopernicAI提供多种生成方式,包括生成360度全景图像、小行星图等,用户可以通过输入文字来生成不同风格和场景的图像。CopernicAI适用于各种应用场景,包括虚拟旅游、游戏开发、艺术创作等。产品定价详细信息请访问官方网站。
CSM AI是一个多模态的3D生成平台,可以从视频、图像或文本生成高分辨率的几何体、纹理和神经辐射场。它可以快速准确地创建环境和游戏,为开发者提供了全新的体验。CSM AI还提供API,方便开发者将其集成到自己的应用或平台中。适用于创建沉浸式的模拟器和游戏。
ScanTo3D iOS App是一款用于快速扫描房屋、建筑和其他大型环境的应用程序。它可以帮助用户创建准确的2D楼层平面图、BIM模型和3D可视化效果。通过扫描目标环境,该应用程序可以自动生成准确的尺寸和细节,为用户提供高效、便捷的建模工具。此外,ScanTo3D iOS App还提供了丰富的编辑和分享功能,让用户能够轻松管理和共享扫描数据。ScanTo3D iOS App定位于建筑、房地产和室内设计等领域的专业人士和爱好者。
in3D能在一分钟内将人物转化为逼真的全身3D头像,只需使用手机相机。使用in3D头像SDK将其集成到您的产品中。
Luma AI是一款基于人工智能技术的文字转3D工具,通过使用Luma AI,用户可以将文字快速转换成3D模型,并进行编辑和渲染,实现独特的视觉效果。Luma AI具有高效、易用和灵活的特点,适用于各种创意设计、广告制作和数字媒体项目。定价详细请参考官方网站。
Luma AI是一家专注于AI的技术公司,通过其创新技术,用户可以利用手机快速生成所需的3D模型。公司由拥有丰富3D计算机视觉经验的团队成立,其技术基于Neural Radiance Fields,能够基于少量2D图像对3D场景进行建模。Dream Machine是一个AI模型,能够直接从文本和图像快速生成高质量的逼真视频。它是一个高度可扩展且高效的transformer模型,专门针对视频进行训练,能够生成物理上准确、一致且充满事件的镜头。Dream Machine是构建通用想象力引擎的第一步,现已对所有人开放。
探索 图像 分类下的其他子分类
832 个工具
771 个工具
543 个工具
522 个工具
352 个工具
196 个工具
95 个工具
68 个工具
3D建模 是 图像 分类下的热门子分类,包含 40 个优质AI工具