共找到 100 个AI工具
点击任意工具查看详细信息
ComfyUI-Fluxtapoz是一个为Flux在ComfyUI中编辑图像而设计的节点集合。它允许用户通过一系列节点操作来对图像进行编辑和风格转换,特别适用于需要进行图像处理和创意工作的专业人士。这个项目目前是开源的,遵循GPL-3.0许可协议,意味着用户可以自由地使用、修改和分发该软件,但需要遵守开源许可的相关规定。
FaceFusion Labs 是一个专注于面部操作的领先平台,它利用先进的技术来实现面部特征的融合和操作。该平台主要优点包括高精度的面部识别和融合能力,以及对开发者友好的API接口。FaceFusion Labs 背景信息显示,它在2024年10月15日进行了初始提交,由Henry Ruhs主导开发。产品定位为开源项目,鼓励社区贡献和协作。
DisEnvisioner是一种先进的图像生成技术,它通过分离和增强主题特征来生成定制化的图像,无需繁琐的调整或依赖多张参考图片。该技术有效地区分并增强了主题特征,同时过滤掉了不相关的属性,实现了在编辑性和身份保持方面的卓越个性化质量。DisEnvisioner的研究背景基于当前图像生成领域对于从视觉提示中提取主题特征的需求,它通过创新的方法解决了现有技术在这一领域的挑战。
FacePoke是一款人工智能驱动的实时头部和面部变换工具,它允许用户通过直观的拖放界面操纵面部特征,为肖像注入生命力,实现逼真的动画和表情。FacePoke利用先进的AI技术,确保所有编辑都保持自然和逼真的外观,同时自动调整周围的面部区域,保持图像的整体完整性。这款工具以其用户友好的界面、实时编辑功能和先进的AI驱动调整而脱颖而出,适合各种技能水平的用户,无论是专业内容创作者还是初学者。
Pic Pic AI编辑器是一个强大的AI图片编辑工具,它提供了多种功能,如照片增强、背景去除、物体移除等,使用户能够轻松地对照片进行专业级别的编辑。该产品以用户友好的界面和高效的AI技术为依托,旨在简化图片编辑流程,提高编辑效率,同时保证输出的图像质量。Pic Pic AI编辑器适合各种水平的用户,无论是社交媒体用户、电商卖家还是专业摄影师,都能通过这个平台提升他们的图像处理能力。
photo4you是一个基于人工智能技术的在线证件照制作网站,用户无需下载或安装任何软件即可轻松创建证件照片。该网站支持多种标准尺寸,适用于护照、签证、驾照等官方文件。它通过智能背景移除功能,自动去除照片背景,确保证件照具有清晰、专业的外观。用户可以立即下载制作好的证件照,节省了时间和麻烦。photo4you提供高分辨率的输出,适合打印或数字提交。
PMRF(Posterior-Mean Rectified Flow,后验均值修正流)是一种新提出的图像恢复算法,旨在解决图像恢复任务中的失真-感知质量权衡问题。它通过结合后验均值和修正流的方式,提出了一种新颖的图像恢复框架,能够在降低图像失真同时保证图像的感知质量。
DepthFlow是一个高度可定制的视差着色器,用于动画化您的图像。它是一个免费且开源的ImmersityAI替代品,能够将图像转换成具有2.5D视差效果的视频。该工具拥有快速的渲染能力,支持多种后处理效果,如晕影、景深、镜头畸变等。它支持多种参数调整,能够创建灵活的运动效果,并且内置了多种预设动画。此外,它还支持视频编码导出,包括H264、HEVC、AV1等格式,并且提供了无需水印的用户体验。
Minionverse是一个基于AI的创意工作流,它通过使用不同的节点和模型来生成图像。这个工作流的灵感来自于一个在线的glif应用,并且提供了一个视频教程来指导用户如何使用。它包含了多种自定义节点,能够进行文本替换、条件加载、图像保存等操作,非常适合需要进行图像生成和编辑的用户。
PuLID-Flux ComfyUI implementation 是一个基于ComfyUI的图像处理模型,它利用了PuLID技术和Flux模型来实现对图像的高级定制和处理。这个项目是cubiq/PuLID_ComfyUI的灵感来源,是一个原型,它使用了一些方便的模型技巧来处理编码器部分。开发者希望在更正式地重新实现之前测试模型的质量。为了获得更好的结果,推荐使用16位或8位的GGUF模型版本。
Posterior-Mean Rectified Flow(PMRF)是一种新颖的图像恢复算法,它通过优化后验均值和矫正流模型来最小化均方误差(MSE),同时保证图像的逼真度。PMRF算法简单而高效,其理论基础是将后验均值预测(最小均方误差估计)优化到与真实图像分布相匹配。该算法在图像恢复任务中表现出色,能够处理噪声、模糊等多种退化问题,并且具有较好的感知质量。
FaceFusion是一个行业领先的面部操作平台,专注于面部交换、唇形同步和深度操作技术。它利用先进的人工智能技术,为用户提供高度逼真的面部操作体验。FaceFusion在图像处理和视频制作领域具有广泛的应用,尤其是在娱乐和媒体行业。
光影魔术手是一款功能丰富的图像处理软件,它提供了多种修图工具和AI技术,帮助用户轻松编辑和美化照片。软件界面友好,操作简单,支持多种图像格式,适合各种水平的用户使用。
StableDelight是一个先进的模型,专注于从纹理表面去除镜面反射。它基于StableNormal的成功,后者专注于提高单目法线估计的稳定性。StableDelight通过应用这一概念来解决去除反射的挑战性任务。训练数据包括Hypersim、Lumos以及来自TSHRNet的各种镜面高光去除数据集。此外,我们在扩散训练过程中整合了多尺度SSIM损失和随机条件尺度技术,以提高一步扩散预测的清晰度。
Colorful Diffuse Intrinsic Image Decomposition 是一种图像处理技术,它能够将野外拍摄的照片分解为反照率、漫反射阴影和非漫反射残留部分。这项技术通过逐步移除单色照明和Lambertian世界假设,实现了对图像中多彩漫反射阴影的估计,包括多个照明和场景中的二次反射,同时模型了镜面反射和可见光源。这项技术对于图像编辑应用,如去除镜面反射和像素级白平衡,具有重要意义。
这是一种通过利用从2D图像扩散模型提取的先验来创建可重新照明的辐射场的方法。该方法能够将单照明条件下捕获的多视图数据转换为具有多照明效果的数据集,并通过3D高斯splats表示可重新照明的辐射场。这种方法不依赖于精确的几何形状和表面法线,因此更适合处理具有复杂几何形状和反射BRDF的杂乱场景。
opencv_contrib是OpenCV的额外模块库,用于开发和测试新的图像处理功能。这些模块通常在API稳定、经过充分测试并被广泛接受后,才会被整合到OpenCV的核心库中。该库允许开发者使用最新的图像处理技术,推动计算机视觉领域的创新。
OpenCV是一个跨平台的开源计算机视觉和机器学习软件库,它提供了一系列编程功能,包括但不限于图像处理、视频分析、特征检测、机器学习等。该库广泛应用于学术研究和商业项目中,因其强大的功能和灵活性而受到开发者的青睐。
Diffusers Image Outpaint 是一个基于扩散模型的图像外延技术,它能够根据已有的图像内容,生成图像的额外部分。这项技术在图像编辑、游戏开发、虚拟现实等领域具有广泛的应用前景。它通过先进的机器学习算法,使得图像生成更加自然和逼真,为用户提供了一种创新的图像处理方式。
FLUX.1-dev-Controlnet-Inpainting-Alpha是由AlimamaCreative Team发布的AI图像修复模型,专门用于修复和填补图像中的缺失或损坏部分。该模型在768x768分辨率下表现最佳,能够实现高质量的图像修复。作为alpha版本,它展示了在图像修复领域的先进技术,并且随着进一步的训练和优化,预计将提供更加卓越的性能。
FLUX-Controlnet-Inpainting 是由阿里妈妈创意团队发布的基于FLUX.1-dev模型的图像修复工具。该工具利用深度学习技术对图像进行修复,填补缺失部分,适用于图像编辑和增强。它在768x768分辨率下表现最佳,能够提供高质量的图像修复效果。目前该工具处于alpha测试阶段,未来将推出更新版本。
finegrain-object-cutter 是一个基于Hugging Face Spaces平台的图像编辑工具,它利用先进的机器学习技术来实现对图像中对象的细粒度切割。该工具的主要优点在于其高精度和易用性,用户可以通过简单的操作来实现复杂的图像编辑任务。它特别适合需要对图像进行精细处理的设计师和开发者,可以广泛应用于图像编辑、增强现实、虚拟现实等领域。
FlexClip AI Image to Image Generator是一个在线的图像转换工具,它利用先进的AI技术将用户上传的图片转换成不同的艺术风格。该产品通过不断更新的AI模型,保证高质量的图像风格转换,适用于专业和个人使用。它还提供了丰富的AI功能,如AI文本到图像、AI文本到视频和AI背景移除器,以加速照片和视频的创作过程。
RapidLayoutRecover是一个专门针对文档类图像的版面还原工具,它能够整合版面分析、文字识别、表格识别和公式识别的结果,还原文档的原始版面布局信息。该工具对于文档数字化、档案管理以及学术研究等领域具有重要价值,能够显著提高文档处理的效率和准确性。
Visual Try-On Chrome Extension是一款Chrome浏览器插件,利用人工智能图像处理技术,让用户能够在任何电子商务网站上虚拟试穿衣物。该插件通过OpenAI GPT-4捕捉产品主图,上传用户图片至Cloudinary,使用Hugging Face上的Kolors模型进行AI处理,并将结果存储在浏览器缓存中以提高可用性。它保护用户隐私,不将个人数据或图片发送至服务器,仅在Hugging Face进行AI处理时例外。
ComfyUI-AdvancedLivePortrait是一个用于实时预览和编辑人脸表情的高级工具。它允许用户在视频中跟踪和编辑人脸,将表情插入到视频中,甚至从样本照片中提取表情。这个项目通过使用ComfyUI-Manager自动安装,简化了安装过程。它结合了图像处理和机器学习技术,为用户提供了一个强大的工具,用于创建动态和互动的媒体内容。
Flux Latent Detailer是一个实验性的工具,通过Flux的潜在空间插值技术,能够在图像中产生更精细的细节。该工具通过多遍处理,尝试在不破坏整体构图的情况下增强图像细节,同时避免过度处理的外观。开发者强调这是一个实验性项目,不提供支持,仅供分享。
Dark Gray Photography 深灰极简是一个专注于生成深灰色调和东亚女性形象的图像生成模型。该模型基于LoRA技术,通过深度学习训练,能够生成风格一致、色彩鲜明的图像。它特别适合需要在人像、产品、建筑和自然风景摄影中使用深灰色调的用户。
bonding_w_geimini是一个基于Streamlit框架开发的图像处理应用,它允许用户上传图片,通过Gemini API进行物体检测,并在图片上直接绘制出物体的边界框。这个应用利用了机器学习模型来识别和定位图片中的物体,对于图像分析、数据标注和自动化图像处理等领域具有重要意义。
Magnifier Lens Effect 是一个JavaScript库,允许用户为任何图片添加放大镜效果,并通过滚动鼠标滚轮来调整放大倍数。该库易于集成和自定义,适用于需要图像细节展示的网页。
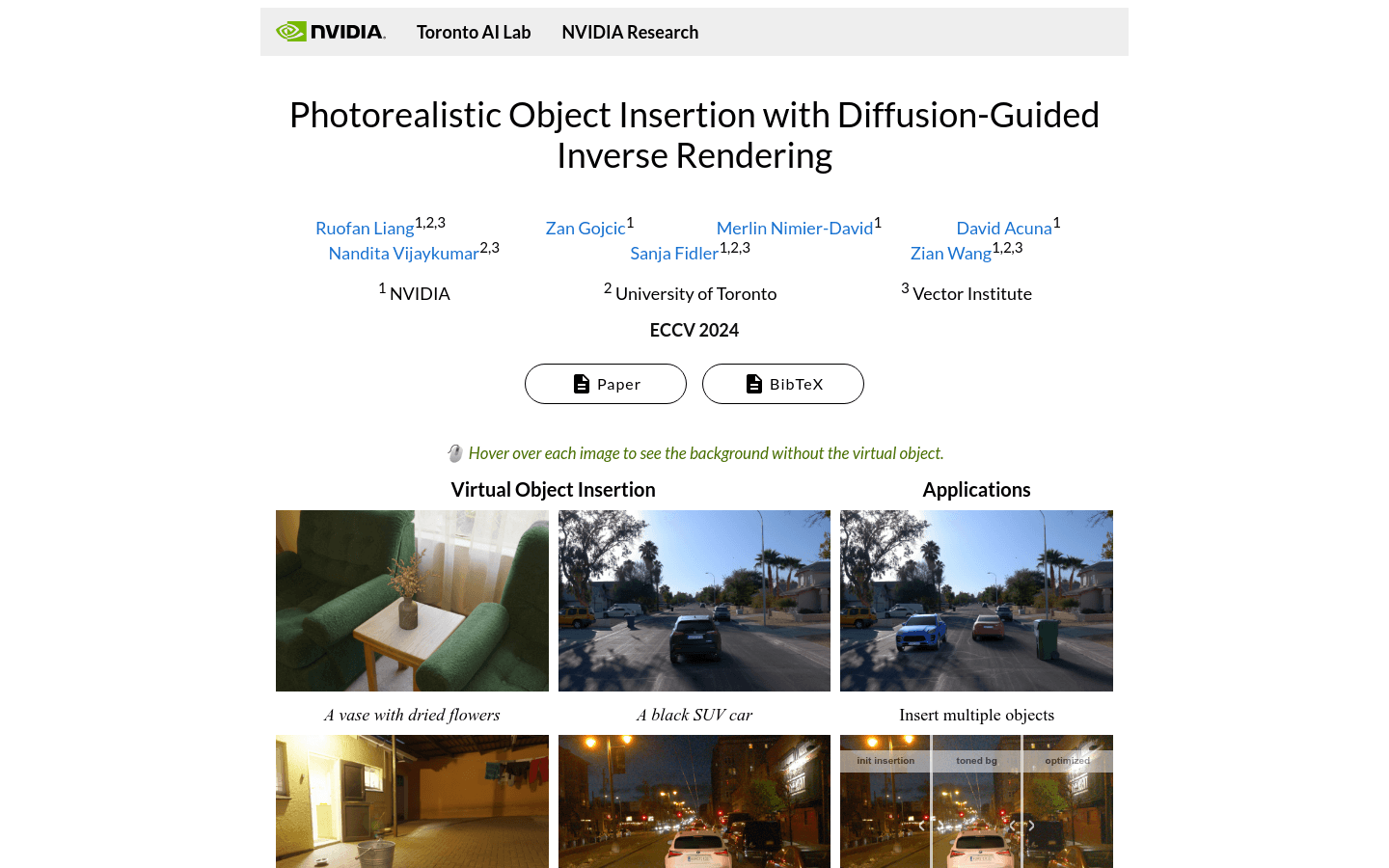
DiPIR是多伦多AI实验室与NVIDIA Research共同研发的一种基于物理的方法,它通过从单张图片中恢复场景照明,使得虚拟物体能够逼真地插入到室内外场景中。该技术不仅能够优化材质和色调映射,还能自动调整以适应不同的环境,提高图像的真实感。
MagicFixup 是 Adobe Research 推出的一个开源图像编辑模型,它通过观察动态视频来简化照片编辑过程。该模型利用深度学习技术,能够自动识别和修复图像中的缺陷,提高编辑效率,减少手动操作的需求。它基于 Stable Diffusion 1.4 模型进行训练,具有强大的图像处理能力,适用于专业图像编辑人员和爱好者。
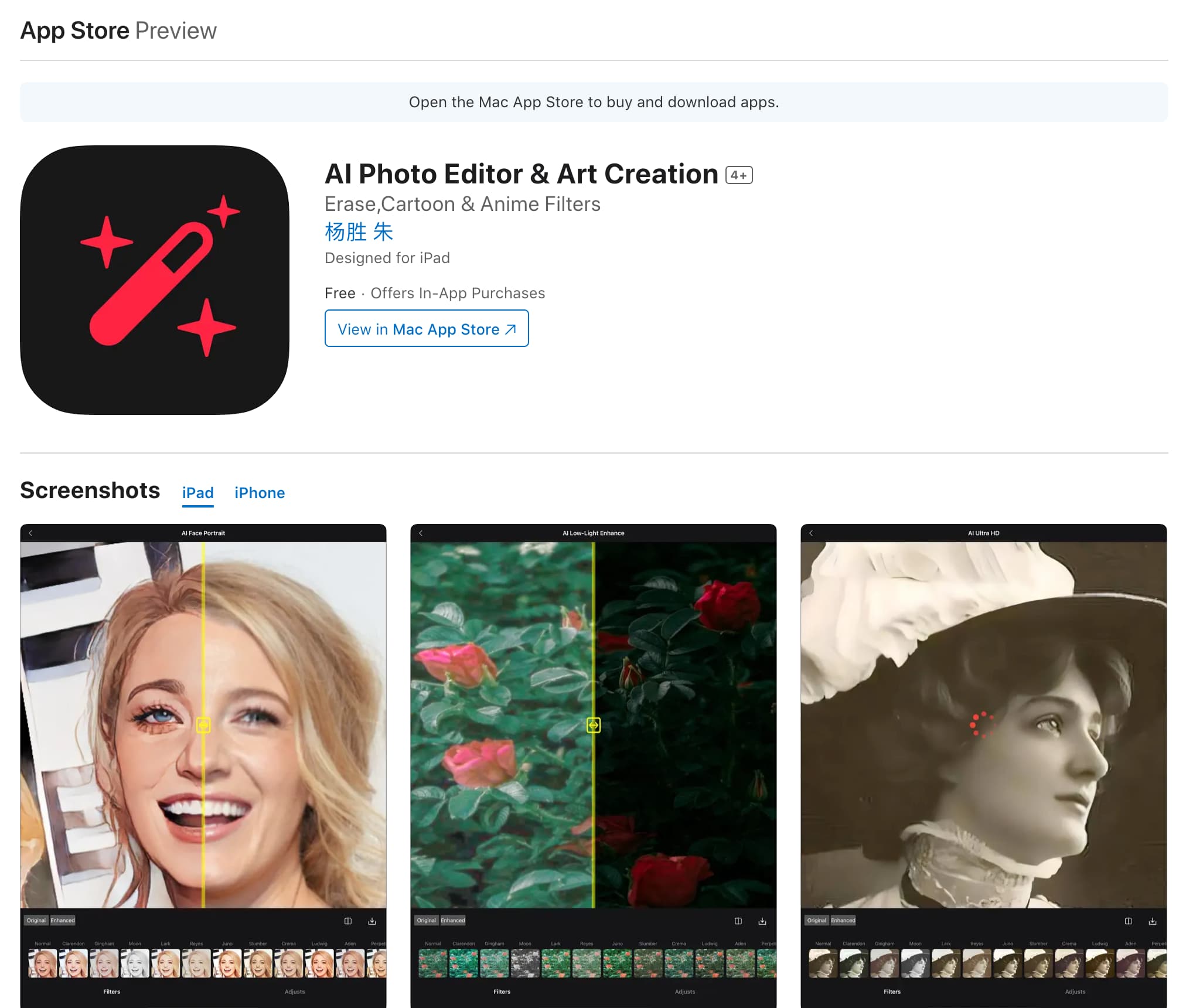
AI Photo Editor是一款由AI技术支持的高级照片编辑应用,提供无缝直观的体验,适合初学者和专业人士。它是一个一站式设计工作室,可以去除照片中不需要的物体,增强图像质量,应用惊人的滤镜,甚至将照片转换成动漫风格的肖像,所有这些都通过AI精确实现。无论你是出于娱乐目的编辑照片,还是追求专业质量的结果,这款应用都让这个过程变得简单且免费。
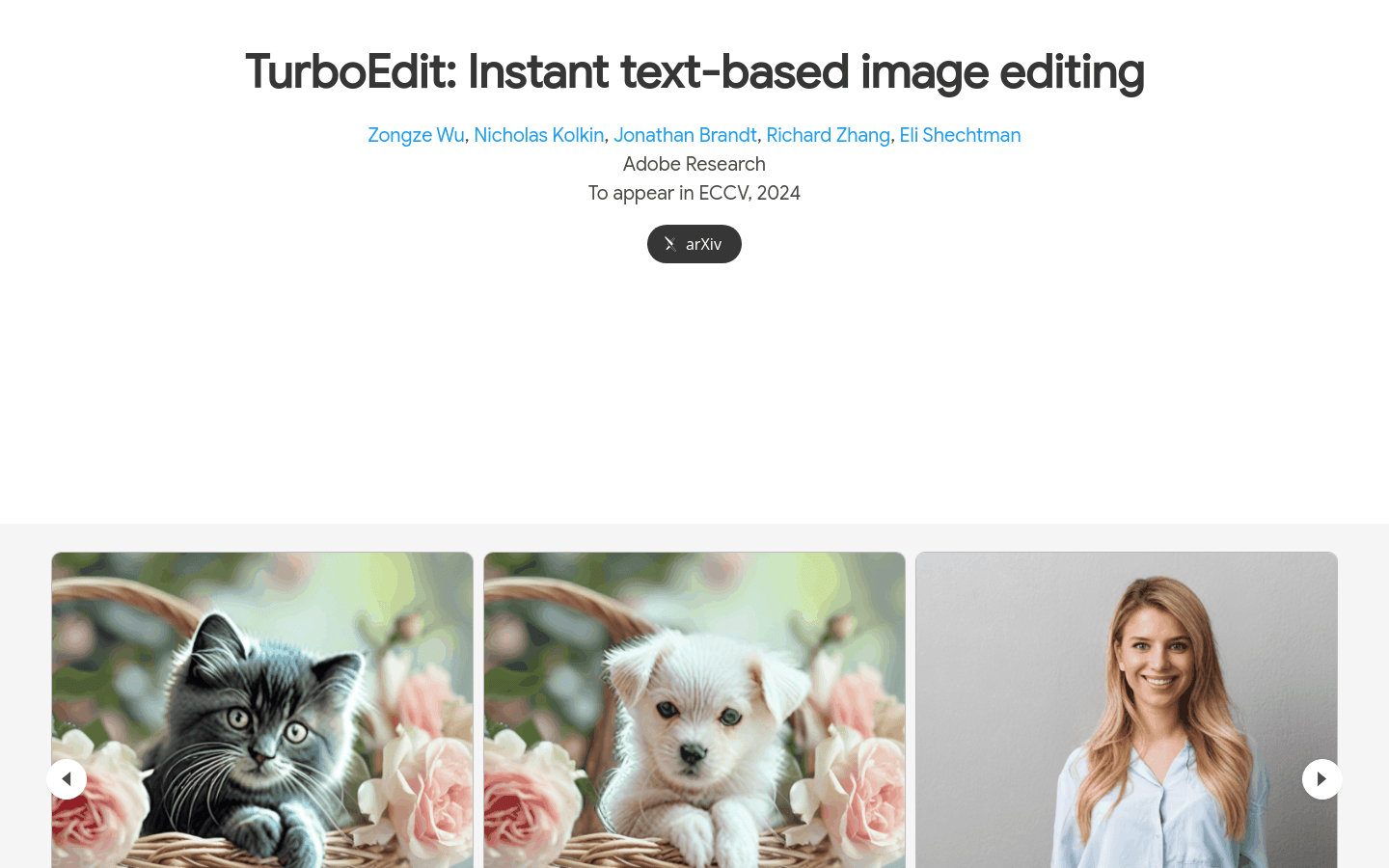
TurboEdit是一种基于Adobe Research开发的技术,旨在解决精确图像反转和解耦图像编辑的挑战。它通过迭代反转技术和基于文本提示的条件控制,实现了在几步内对图像进行精准编辑的能力。这项技术不仅快速,而且性能超越了现有的多步扩散模型编辑技术。
birefnet for background removal 是一个基于深度学习的图像处理模型,能够自动识别并去除图片中的背景,保留前景对象。这项技术在图像编辑、广告设计、产品展示等领域具有重要应用价值,主要优点包括操作简便、处理速度快、效果自然。产品背景信息包括其开发团队、技术原理以及市场定位等。
Amazon Titan Image Generator v2是AWS推出的一款AI图像生成模型,它通过使用参考图像、编辑现有视觉效果、去除背景、生成图像变体以及安全定制模型来保持品牌风格和主题一致性,从而简化工作流程、提高生产力,并将创意愿景变为现实。
PanoFree是一种创新的全景多视图图像生成技术,它通过迭代变形和上色解决了一致性和累积误差问题,无需额外的调优。该技术在实验中显示出显著的误差减少,提高了全局一致性,并在不增加额外调优的情况下提升了图像质量。与现有方法相比,PanoFree在时间和GPU内存使用上效率更高,同时保持了结果的多样性。
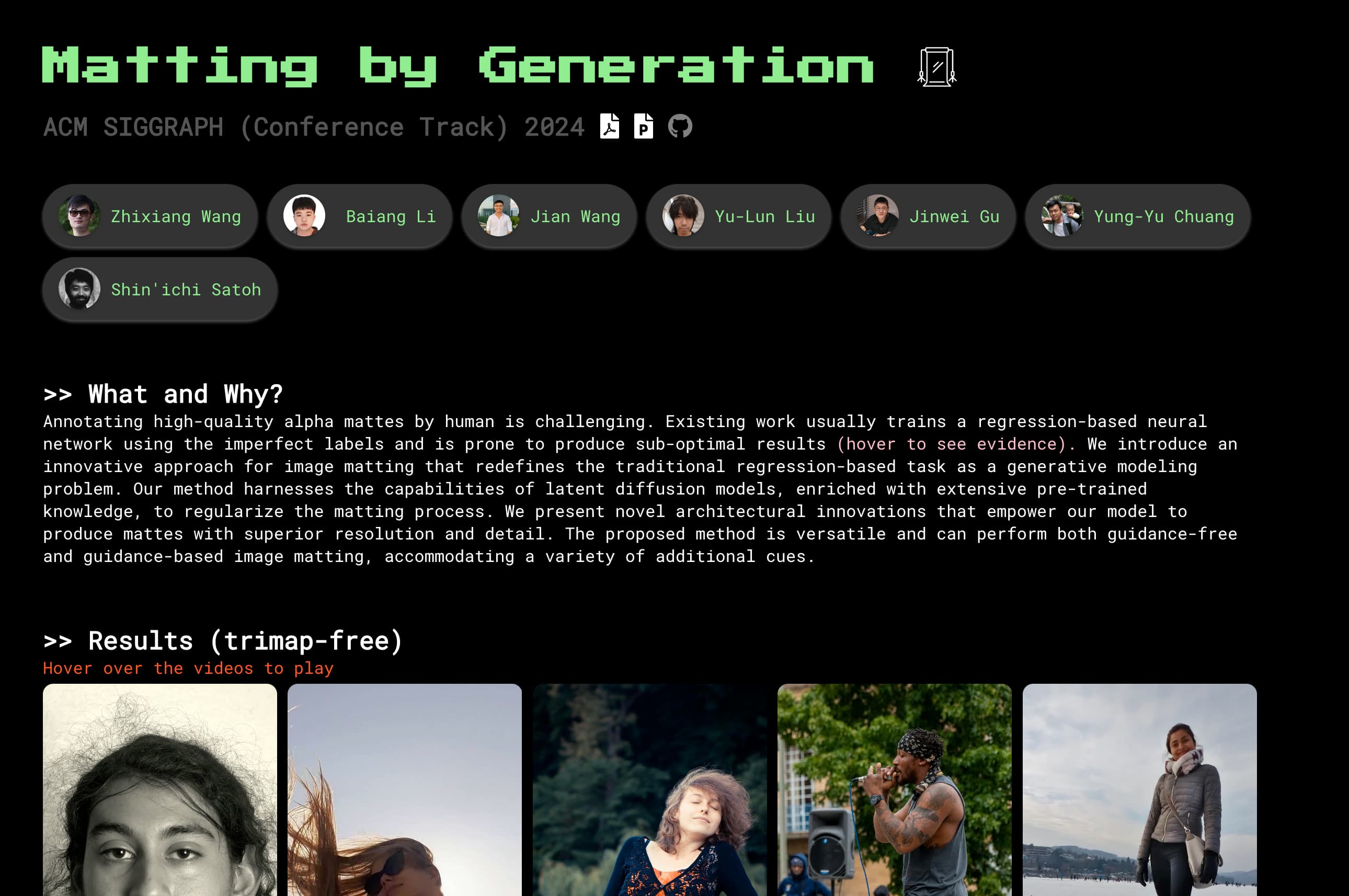
Matting by Generation是一个利用人工智能技术进行图像分割的在线工具。它能够识别图像中的前景和背景,实现精准分离,广泛应用于设计、视频制作和图像编辑等领域。产品的主要优点包括高效率、易操作和高质量的分割效果。
Fai-Fuzer是一个基于AI技术的图像编辑工具,它能够通过先进的控制网络技术,实现对图像的精确编辑和控制。该工具的主要优点在于其高度的灵活性和精确性,可以广泛应用于图像修复、美化以及创意编辑等领域。
ComfyUI-segment-anything-2是一个基于segment-anything-2模型的图像分割库,它允许用户通过ComfyUI节点轻松实现图像分割功能。该库目前处于开发阶段,但功能已经基本可用。它通过自动下载模型并集成到ComfyUI中,为用户提供了一个简单易用的图像分割解决方案。
Meta Segment Anything Model 2 (SAM 2)是Meta公司开发的下一代模型,用于视频和图像中的实时、可提示的对象分割。它实现了最先进的性能,并且支持零样本泛化,即无需定制适配即可应用于之前未见过的视觉内容。SAM 2的发布遵循开放科学的方法,代码和模型权重在Apache 2.0许可下共享,SA-V数据集也在CC BY 4.0许可下共享。
Alchemist是一种利用预训练的文本到图像模型和合成数据,允许用户在图像中编辑物体的材质属性的技术。它通过微调合成数据集,实现了对物体的特定材质属性(如粗糙度、金属感、基础颜色饱和度和透明度)的参数化编辑控制。这项技术的主要优点包括在保持物体几何形状和图像光照不变的同时,能够改变物体的属性,甚至在物体透明化时,能够真实地填充背后的背景、隐藏的内部结构和折射光效果。
Stable-Hair 是一种新颖的基于扩散模型的发型转移方法,能够稳健地将真实世界的多样化发型转移到用户提供的面部图像上,用于虚拟试戴。该方法在处理复杂和多样化的发型时表现出色,能够保持原有身份内容和结构,同时实现高度详细和高保真的转移效果。
Diffree是一个基于文本引导的图像修复模型,它能够通过文本描述来添加新对象到图像中,同时保持背景的一致性、空间适宜性和对象的相关性和质量。该模型通过训练在OABench数据集上,使用稳定扩散模型和额外的掩码预测模块,能够独特地预测新对象的位置,实现仅通过文本指导的对象添加。
image-matting 是一个基于开源模型 briaai/RMBG-1.4 的AI抠图项目。该项目旨在通过学习AI技术、GUI开发、前端学习以及i18n国际化等技术,实现本地模型算法的图像抠图功能。它支持单张和批量抠图,用户可以通过拖拽和粘贴的方式快速进行图像处理。项目还提供了打包后的运行文件下载链接,方便用户使用。
ComfyUI-LivePortraitKJ是一个开源项目,通过ComfyUI节点为LivePortrait提供支持。它允许用户在实时视频和图片中实现面部特征的捕捉和动画效果,支持多种面部检测技术,包括Insightface和MediaPipe。该项目采用MIT许可证,提供了更好的Mac支持,并优化了性能和效率,允许在ComfyUI环境中实现接近实时的视图体验。
TruthPix是一款AI图像检测工具,旨在帮助用户识别经过AI篡改的照片。该应用通过先进的AI技术,能够快速、准确地识别出图像中的克隆和篡改痕迹,从而避免用户在社交媒体等平台上被虚假信息误导。该应用的主要优点包括:安全性高,所有检测都在设备上完成,不上传数据;检测速度快,分析一张图片仅需不到400毫秒;支持多种AI生成图像的检测技术,如GANs、Diffusion Models等。
ViTMatte是一个基于预训练纯视觉变换器(Plain Vision Transformers, ViTs)的图像抠图系统。它利用混合注意力机制和卷积颈部来优化性能与计算之间的平衡,并引入了细节捕获模块以补充抠图所需的细节信息。ViTMatte是首个通过简洁的适配释放ViT在图像抠图领域潜力的工作,继承了ViT在预训练策略、简洁的架构设计和灵活的推理策略等方面的优势。在Composition-1k和Distinctions-646这两个最常用的图像抠图基准测试中,ViTMatte达到了最先进的性能,并以较大优势超越了先前的工作。
PaintsUndo是一个专注于数字绘画行为的AI模型,能够模拟和重现绘画过程中的笔触和步骤。它通过分析输入的静态图像,提取出绘画的草图,实现从外部草图的插值,甚至能将动漫风格的作品转换为草图风格。此模型在图像处理领域具有重要性,可广泛应用于艺术创作、教育和娱乐。
UltraPixel是一种先进的超高清图像合成技术,旨在推动图像分辨率达到新的高度。这项技术由香港科技大学(广州)、华为诺亚方舟实验室、马克斯·普朗克信息学研究所等机构共同研发。它在图像合成、文本到图像的转换、个性化定制等方面具有显著优势,能够生成高达4096x4096分辨率的图像,满足专业图像处理和视觉艺术的需求。
ControlNet++是一种基于ControlNet架构的新型网络设计,支持10多种控制类型,用于条件文本到图像的生成,并能生成与midjourney视觉可比的高分辨率图像。它通过两个新模块扩展了原有ControlNet,支持使用相同网络参数的不同图像条件,并支持多条件输入而不增加计算负担。该模型已开源,旨在让更多人享受图像生成与编辑的便利。
Magic Insert 是一种创新的图像编辑技术,它允许用户将任意风格的图像主题拖放到另一种风格的目标图像中,并实现风格感知和逼真的插入。这项技术通过解决风格感知个性化和在风格化图像中进行真实对象插入的两个子问题,正式定义了风格感知拖放的问题,并提出了一种方法来解决它。Magic Insert 的方法显著优于传统的图像修复技术。此外,还提供了一个名为 SubjectPlop 的数据集,以促进该领域的评估和未来发展。
OccFusion是一种创新的人体渲染技术,利用3D高斯散射和预训练的2D扩散模型,即使在人体部分被遮挡的情况下也能高效且高保真地渲染出完整的人体图像。这项技术通过三个阶段的流程:初始化、优化和细化,显著提高了在复杂环境下人体渲染的准确性和质量。
InstantStyle-Plus 是一种先进的图像生成模型,专注于在文本到图像的生成过程中实现样式迁移,同时保持原始内容的完整性。它通过分解风格迁移任务为风格注入、空间结构保持和语义内容保持三个子任务,利用InstantStyle框架,以一种高效、轻量的方式实现风格注入。该模型通过反转内容潜在噪声和使用Tile ControlNet来保持空间构图,并通过全局语义适配器增强语义内容的保真度。此外,还使用风格提取器作为鉴别器,提供额外的风格指导。InstantStyle-Plus 的主要优点在于它能够在不牺牲内容完整性的前提下,实现风格与内容的和谐统一。
ComfyUI-Fast-Style-Transfer是一个基于PyTorch框架开发的快速神经风格迁移插件,它允许用户通过简单的操作实现图像的风格转换。该插件基于fast-neural-style-pytorch项目,目前只移植了基础的推理功能。用户可以自定义风格,通过训练自己的模型来实现独特的风格迁移效果。
AutoStudio是一个基于大型语言模型的多轮交互式图像生成框架,它通过三个代理与一个基于稳定扩散的代理来生成高质量图像。该技术在多主题一致性方面取得了显著进步,通过并行UNet结构和主题初始化生成方法,提高了图像生成的质量和一致性。
MimicBrush是一种创新的图像编辑模型,它允许用户通过指定源图像中的编辑区域和提供一张野外参考图像来实现零样本图像编辑。该模型能够自动捕捉两者之间的语义对应关系,并一次性完成编辑。MimicBrush的开发基于扩散先验,通过自监督学习捕捉不同图像间的语义关系,实验证明其在多种测试案例下的有效性及优越性。
AI Playground是Intel为Arc GPU用户推出的一款桌面客户端应用程序,旨在简化AI图像创造、编辑和AI驱动的答案获取过程。它利用Intel Xe-cores和专为AI设计的XMX引擎,为用户提供了一种无需深入了解AI即可轻松使用AI的方式。该应用程序预计将于今年夏天免费提供下载,支持本地控制,保护用户数据隐私,并且界面友好,易于操作。此外,AI Playground还提供了模型灵活性和开放项目,鼓励开发者和AI爱好者进行实验和创新。
ComfyUI_omost是一个基于ComfyUI框架实现的Omost模型,它允许用户与大型语言模型(LLM)进行交互,以获取类似JSON的结构化布局提示。该模型目前处于开发阶段,其节点结构可能会有变化。它通过LLM Chat和Region Condition两个部分,将JSON条件转换为ComfyUI的区域格式,用于图像生成和编辑。
InstaDrag 是一种快速高质量的基于拖拽的图像编辑技术,利用视频中的信息进行训练,能够在大约 1 秒内实现像素级控制。通过消除梯度导向等耗时操作,提高了编辑速度和准确性。该技术能够广泛应用于图像编辑领域。
TryOnDiffusion是一种创新的图像合成技术,它通过两个UNets(Parallel-UNet)的结合,实现了在单一网络中同时保持服装细节和适应显著的身体姿势及形状变化。这项技术在保持服装细节的同时,能够适应不同的身体姿势和形状,解决了以往方法在细节保持和姿势适应上的不足,达到了业界领先的性能。
krita-ai-diffusion是一个开源的Krita插件,旨在简化AI图像生成过程。它允许用户在Krita中通过AI技术修复图像中的选定区域、扩展画布以及从头开始创建新图像。插件支持文本提示,并提供强大的自定义选项,适合高级用户。它利用了Stable Diffusion技术,并与ComfyUI后端结合,提供了本地化、无需调整的图像生成体验。
Anyline是一个ControlNet线条预处理器,能够从大多数图像中准确提取对象边缘、图像细节和文本内容。它基于“Tiny and Efficient Model for the Edge Detection Generalization (TEED)”论文的创新努力,是当前最先进的视觉算法之一。Anyline与Mistoline ControlNet模型结合,形成完整的SDXL工作流程,最大化精确控制并发挥SDXL模型的生成能力。
星绘是一款提供丰富 AI 生图能力的应用,让用户可以通过上传图片、输入关键词,自由切换风格,如像素风、赛博朋克、日式漫画等,即刻拥有虚拟人生体验。用户可以探索平行世界,自由输入 AI 形象,并进行 AI Cosplay,同时享受 AI 写真和 AI 造型师功能。应用还支持图片风格化,如古典油画、街头涂鸦、中式水墨等。
ComfyUI-IC-Light是ComfyUI的原生插件,用于实现IC-Light技术。该技术允许用户通过一系列工作流程生成背景和重新打光,从而增强图像的视觉效果。它的重要性在于能够提供更自然和逼真的图像处理结果,尤其适用于需要高级图像编辑功能的用户。
Stable Artisan是一款利用Stability AI平台API的Discord机器人,它通过自然语言提示将用户的思想转化为令人惊叹的图像,支持多主题提示、图像质量和拼写能力,是创意图像生成的强大工具。
IC-Light项目旨在通过先进的机器学习技术,对图像的照明条件进行操纵,从而实现一致的光照效果。它提供了两种类型的模型:文本条件重照明模型和背景条件模型,两者均以前景图像作为输入。该技术的重要性在于它能够在不依赖复杂提示的情况下,通过简单的文本描述或背景条件,实现对图像照明的精确控制,这对于图像编辑、增强现实、虚拟现实等领域具有重要意义。
IntrinsicAnything 是一种先进的图像逆渲染技术,它通过学习扩散模型来优化材质恢复过程,解决了在未知静态光照条件下捕获的图像中物体材质恢复的问题。该技术通过生成模型学习材质先验,将渲染方程分解为漫反射和镜面反射项,利用现有丰富的3D物体数据进行训练,有效地解决了逆渲染过程中的歧义问题。此外,该技术还开发了一种从粗到细的训练策略,利用估计的材质引导扩散模型产生多视图一致性约束,从而获得更稳定和准确的结果。
PuLID 是一个专注于人脸身份定制的深度学习模型,通过对比对齐技术实现高保真度的人脸身份编辑。该模型能够减少对原始模型行为的干扰,同时提供多种应用,如风格变化、IP融合、配饰修改等。
AI 图像擦除器是一款基于人工智能技术的工具,能够快速、简单地从照片中删除不需要的内容,提高照片的整体质量。该工具操作简便,免费使用,适用于个人和专业用户。
图片去水印工具利用强大的 AI 技术,帮助用户快速去除图像上的水印,提高创作自由和社交媒体效果。产品定位于提供便捷的水印去除服务,以增强用户体验为目标。
AI 背景移除器通过人工智能检测图片主体、创建蒙版并消除背景。支持 PNG、JPG、WebP 格式,无需担心影响图片尺寸和质量。让您轻松制作透明背景图片。
ZeST是由牛津大学、Stability AI 和 MIT CSAIL 研究团队共同开发的图像材质迁移技术,它能够在无需任何先前训练的情况下,实现从一张图像到另一张图像中对象的材质迁移。ZeST支持单一材质的迁移,并能处理单一图像中的多重材质编辑,用户可以轻松地将一种材质应用到图像中的多个对象上。此外,ZeST还支持在设备上快速处理图像,摆脱了对云计算或服务器端处理的依赖,大大提高了效率。
超能画布是百度网盘荣誉出品的AI创意生成工具,可以根据您上传的人像图片自动生成各种风格的创意图像,如写实、唯美、奇幻等,帮助摄影师提高工作效率,为每个人实现图像创意. 该工具提供免费试用,并有灵活的付费模式满足不同需求.
HairFastGAN是一种用于高分辨率、接近实时性能和出色重建的发型转移方法。该方法包括在StyleGAN的FS潜在空间中运行的新架构、增强的修复方法以及用于更好的对齐、颜色转移和后处理的改进编码器。在最困难的情况下,该方法可以在不到一秒的时间内将发型形状和颜色从一张图片转移到另一张图片。
DreamWalk是一种基于扩散指引的文本感知图像生成方法,可对图像的风格和内容进行细粒度控制,无需对扩散模型进行微调或修改内部层。支持多种风格插值和空间变化的引导函数,可广泛应用于各种扩散模型。
SwapAnything是一个新颖的框架,可以根据参考给出的个性化概念,交换图像中的任意对象,同时保持上下文不变。相较于现有的个性化主题交换方法,SwapAnything有三个独特优势:(1)精确控制任意对象和部分而非主题,(2)更忠实地保留上下文像素,(3)更好地将个性化概念适应到图像中。它通过有针对性的变量交换来在潜在特征图上实现区域控制,交换被遮罩的变量以保持忠实的上下文和初始的语义概念交换。然后,通过外观调整,无缝地将语义概念调整到原始图像中,包括目标位置、形状、风格和内容。在人工和自动评估上的广泛结果表明,我们的方法在个性化交换方面比基准方法有显著改进。此外,SwapAnything展示了在单个对象、多个对象、部分对象和跨领域交换任务上的精确和忠实交换能力。SwapAnything还在基于文本的交换和超出交换的任务上取得了出色表现,如对象插入。
Cos Stable Diffusion XL 1.0 Base调整为使用余弦连续EDM VPred调度。最重要的特性是其产生从纯黑到纯白的全色彩范围图像,同时对图像每一步的变化率进行了更细微的改进。 Edit Stable Diffusion XL 1.0 Base调整为使用余弦连续EDM VPred调度,并升级为执行图像编辑。此模型以源图像和提示作为输入,将提示解释为如何改变图像的指令。 定价:免费使用。 定位:用于生成艺术品、设计等创意过程中,在教育或创意工具中的应用,研究生成模型,部署具有生成有害内容潜力的模型,探究理解生成模型的局限性和偏见。
DesignEdit是一款集成了各种空间感知图像编辑功能的统一框架。它通过将空间感知图像编辑任务分解为多层潜在表征的分解和融合两个子任务来实现。首先将源图像的潜在表征分割为多个层,包括若干个目标层和一个需要可靠修复的不完整背景层。为了避免额外的调优,我们进一步探索了self-attention机制内部的修复能力,引入了一种key-masking self-attention方案,能够在遮蔽区域传播周围的上下文信息,同时降低对遮蔽区域外的影响。其次,我们提出了一种基于指令的潜在融合方法,将多层潜在表征贴在画布潜在空间上。我们还引入了一种潜在空间的伪影抑制机制来增强修复质量。由于这种多层表征固有的模块化优势,我们可以实现精确的图像编辑,并且我们的方法在多个编辑任务上都取得了出色的表现,超越了最新的空间编辑方法。
iFoto的Cleanup Pictures是一款在线图片修复工具,可轻松删除照片中的不需要的物体、人物、文字和水印。适用于快速改善电子商务图片的质量。
InstantStyle 是一个通用框架,利用两种简单但强大的技术,实现对参考图像中风格和内容的有效分离。其原则包括将内容从图像中分离出来、仅注入到风格块中,并提供样式风格的合成和图像生成等功能。InstantStyle 可以帮助用户在文本到图像生成过程中保持风格,为用户提供更好的生成体验。
该算法旨在简化动画上色流程。传统上,数字画师需要逐帧为线框动画手动上色,这个过程非常耗时耗力。本算法只需要画师为第一帧上色,就能自动将颜色传播到后续所有画面,大大提高了工作效率。算法的核心是一个新颖的包含关系匹配模块,可以精准捕捉动画中物体形变、遮挡等细节,确保上色的准确性。该算法开发了一个专门的数据集用于训练,能充分发挥算法的上色能力。相比现有技术,该算法展现出卓越的上色质量和鲁棒性。
ComfyUI-PixelArt-Detector是一个用于检测像素艺术的开源工具,它可以集成到ComfyUI中,帮助用户识别和处理像素艺术图像。
SwinIR 是一款基于 Swin Transformer 进行图像恢复的官方 PyTorch 实现,在经典、轻量级和真实世界图像超分辨率、灰度 / 彩色图像去噪以及 JPEG 压缩伪影去除等任务中取得了最先进的性能。它由浅层特征提取、深层特征提取和高质量图像重建组成,具有卓越的性能和参数优化。
ObjectDrop是一种监督方法,旨在实现照片级真实的物体删除和插入。它利用了一个计数事实数据集和自助监督技术。主要功能是可以从图像中移除物体及其对场景产生的影响(如遮挡、阴影和反射),也能够将物体以极其逼真的方式插入图像。它通过在一个小型的专门捕获的数据集上微调扩散模型来实现物体删除,而对于物体插入,它采用自助监督方式利用删除模型合成大规模的计数事实数据集,在此数据集上训练后再微调到真实数据集,从而获得高质量的插入模型。相比之前的方法,ObjectDrop在物体删除和插入的真实性上有了显著提升。
ComfyUI-SuperBeasts是一款用于增强图像动态范围和视觉吸引力的图像处理应用程序。它提供了一组可调整的参数,用于根据用户偏好微调HDR效果。该应用程序具有以下特点:调整阴影、高光和整体HDR效果的强度;应用伽马校正以控制整体亮度和对比度;增强对比度和色彩饱和度,使结果更加生动;通过在LAB颜色空间处理图像来保留颜色准确性;利用基于亮度的掩码进行针对性调整;将调整后的亮度与原始亮度进行混合,以实现平衡效果。
FlashFace通过特征图编码人脸身份并引入解耦集成策略,优秀地保留细节和遵循指令,适用于语言提示下的人脸交换等应用。
Stability AI开发者平台现提供一套全面的API服务,包括图像生成、增强、外延画和编辑,旨在提升媒体创作的质量和效率。
该项目可以将漫画/图片中的文字进行翻译,主要功能包括文本检测、光学字符识别(OCR)、机器翻译和图像修补。它支持多种语言如日语、中文、英语和韩语等,可实现近乎完美的翻译效果。该项目主要面向漫画爱好者和图像处理工作者,可以方便地阅读外语漫画或进行图像的多语言处理。此外,它还提供Web服务、在线演示和命令行工具等多种使用方式,具有良好的可用性。该项目代码开源,欢迎大家一起完善和贡献。
Freepik Reimagine是一款基于人工智能的图像创作工具,可以利用先进的AI算法为您的现有图像创建全新的版本和风格。无需繁琐的编辑操作,只需上传图像并设置所需的变化,AI就能自动生成全新的图像变体。该工具具有强大的创作能力,可以根据用户需求改变图像的风格、构图、色彩等元素,为您带来无限的创意可能。同时,它操作简单,即使是没有专业背景的用户也能快速上手。无论您是设计师、艺术家还是创意爱好者,都可以利用Freepik Reimagine激发无穷创意,提高工作效率。该工具目前处于公测阶段,免费使用。
img2img-turbo是一个开源项目,它是对原始img2img项目的改进,旨在提供更快的图像到图像转换速度。该项目使用了先进的深度学习技术,能够处理各种图像转换任务,如风格迁移、图像着色、图像修复等。
Upscale.media插件使用先进的AI技术,提供图片放大和增强功能,只需几次点击即可简化您的图像处理工作流程。成千上万的用户已经使用Upscale.media来节省时间并获得出色的结果。
Blur ID 是一款自动打码工具,能够检测照片/截图中包含的隐私文本、头像和二维码,并自动打码以保护隐私。用户可以自定义头像实现沉浸式打码效果。该应用程序完全在本地运行,无需服务器,保证隐私安全。支持打码的内容包括人脸、敏感文字、头像、二维码和条形码。软件通过不断优化模型来提高识别准确率。Blur ID提供了免费版本及付费的订阅服务,付费版本提供更多高级功能。
Polycam的高斯模糊创建工具可以让你免费将图像转换为沉浸式的3D模糊图像,你可以预览、分享和导出这些模糊图像。该工具支持20-200张PNG或JPG格式图像输入,输入图像需遵循影像测量最佳实践,保证图像清晰、均匀曝光和无运动模糊效果。生成的3D模糊可在Unity和Unreal等引擎中使用,插件不断更新以支持更多软件。该工具还提供Gallery功能用于浏览和分享社区创作。
FineControlNet是一个基于Pytorch的官方实现,用于生成可通过空间对齐的文本控制输入(如2D人体姿势)和实例特定的文本描述来控制图像实例的形状和纹理的图像。它可以使用从简单的线条画作为空间输入,到复杂的人体姿势。FineControlNet确保了实例和环境之间自然的交互和视觉协调,同时获得了Stable Diffusion的质量和泛化能力,但具有更多的控制能力。
remove-background-webgpu 是一个运行于浏览器中的小程序,利用WebGPU技术实现快速的图片背景移除。它可帮助用户在不下载任何额外软件的情况下,快速获取无背景的图片。
StableDrag是一种基于点的图像编辑框架,旨在解决现有拖拽方法存在的不准确点跟踪和运动监督不完整的问题。它设计了一种判别式点跟踪方法和基于置信度的潜在增强策略,前者可精确定位更新的手柄点,从而提高长距离操作的稳定性;后者则负责确保所有操作步骤中优化的潜在表示质量尽可能高。该框架实例化了两种图像编辑模型StableDrag-GAN和StableDrag-Diff,能够通过广泛的定性实验和DragBench上的定量评估,获得更稳定的拖拽性能。
sd-forge-layerdiffuse是一个用于生成透明图像和图层的工作在进行中的扩展,它利用了潜在透明度技术。该工具目前支持图像生成和基本图层功能,但透明图像到图像的转换尚未完成。代码库高度动态,未来一个月可能会有大量变化。
sd-forge-layerdiffusion是一个工作进行中的扩展,用于通过Forge为SD WebUI生成透明图像和图层。该扩展支持原生透明扩散处理,能够生成透明玻璃、半透明发光效果等复杂效果。目前,图像生成和基本图层功能已经可用,但透明img2img功能尚未完成。代码库高度动态,未来一个月可能会有大量变化。
Glif是一个能够使用人工智能重新混合网络上的任何图像的插件。它提供了各种AI工作流,让用户能够通过右键单击图像、编写提示或使用AI的创意重新定义图像的风格。Glif由AI工作流驱动,任何人都可以在其上构建。请合理使用,建议在公共域资源上使用,如Public Domain Review或artvee等。定价信息请查看官方网站。
探索 图像 分类下的其他子分类
832 个工具
771 个工具
543 个工具
522 个工具
352 个工具
95 个工具
68 个工具
63 个工具
AI图像编辑 是 图像 分类下的热门子分类,包含 196 个优质AI工具