共找到 6 个AI工具
点击任意工具查看详细信息
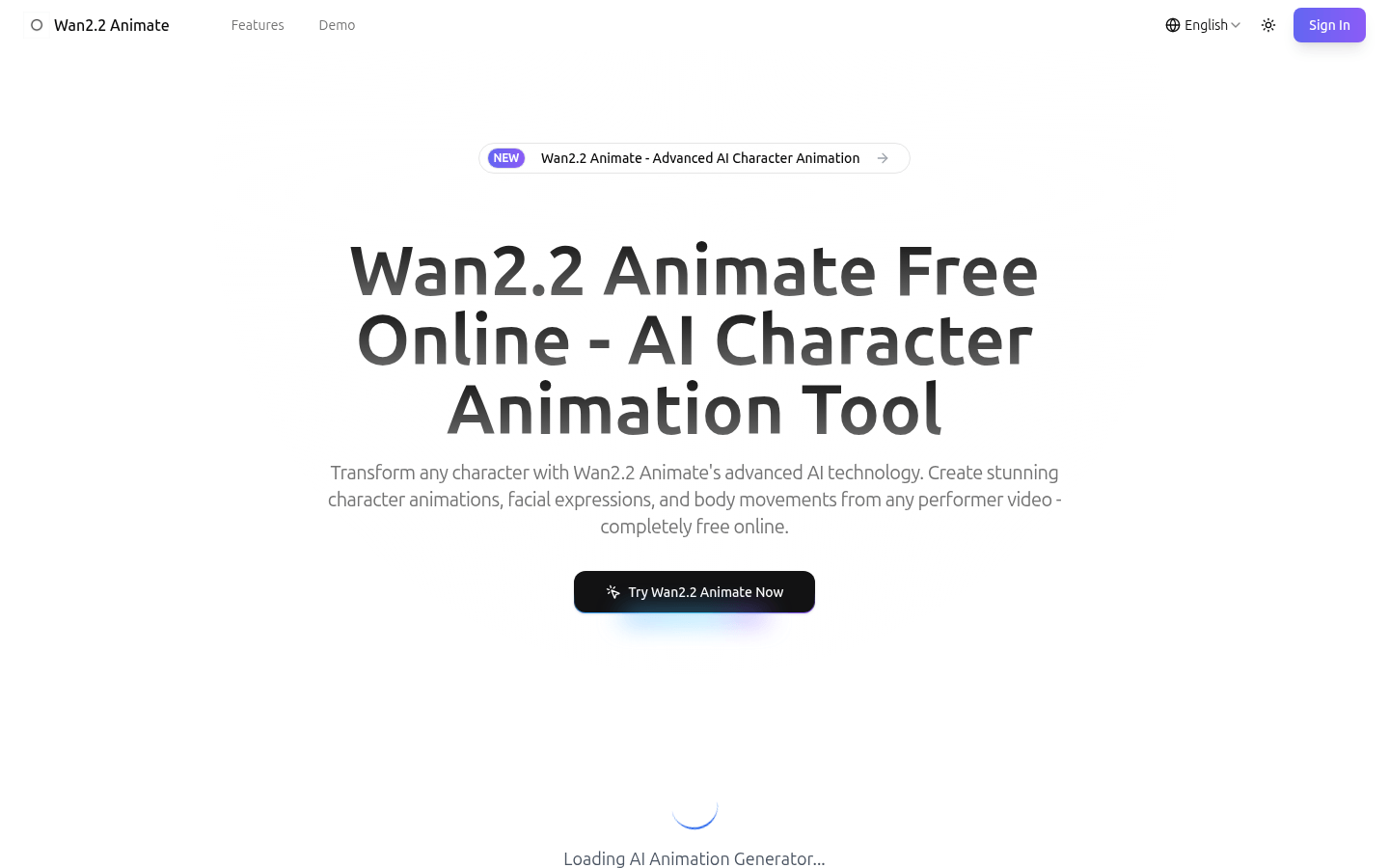
Wan2.2 Animate是一款免费的在线高级AI角色动画工具,基于阿里巴巴通义实验室前沿研究和严格学术研究成果开发,采用开源技术,模型权重可在Hugging Face和ModelScope平台获取。其主要优点在于提供精确的面部表情控制、身体动作复制、无缝角色替换等功能,能在保持原始动作、环境背景和光照等条件下进行角色动画创作,且无需注册,可直接在浏览器运行,适合学术研究、效果展示和创意实验等。
CameraBench 是一个用于分析视频中相机运动的模型,旨在通过视频理解相机的运动模式。它的主要优点在于利用生成性视觉语言模型进行相机运动的原理分类和视频文本检索。通过与传统的结构从运动 (SfM) 和实时定位与*构建 (SLAM) 方法进行比较,该模型在捕捉场景语义方面显示出了显著的优势。该模型已开源,适合研究人员和开发者使用,且后续将推出更多改进版本。
LongVU是一种创新的长视频语言理解模型,通过时空自适应压缩机制减少视频标记的数量,同时保留长视频中的视觉细节。这一技术的重要性在于它能够处理大量视频帧,且在有限的上下文长度内仅损失少量视觉信息,显著提升了长视频内容理解和分析的能力。LongVU在多种视频理解基准测试中均超越了现有方法,尤其是在理解长达一小时的视频任务上。此外,LongVU还能够有效地扩展到更小的模型尺寸,同时保持最先进的视频理解性能。
Movie Gen Bench是由Facebook Research发布的视频生成评估基准测试,旨在为未来在视频生成领域的研究提供公平且易于比较的标准。该基准测试包括Movie Gen Video Bench和Movie Gen Audio Bench两个部分,分别针对视频内容生成和音频生成进行评估。Movie Gen Bench的发布,对于推动视频生成技术的发展和评估具有重要意义,它能够帮助研究人员和开发者更好地理解和改进视频生成模型的性能。
DenseAV是一种新颖的双编码器定位架构,通过观看视频学习高分辨率、语义有意义的视听对齐特征。它能够无需明确定位监督即可发现单词的“意义”和声音的“位置”,并且自动发现并区分这两种关联类型。DenseAV的定位能力来自于一种新的多头特征聚合操作符,它直接比较密集的图像和音频表示进行对比学习。此外,DenseAV在语义分割任务上显著超越了先前的艺术水平,并且在使用参数少于一半的情况下,在跨模态检索上超越了ImageBind。
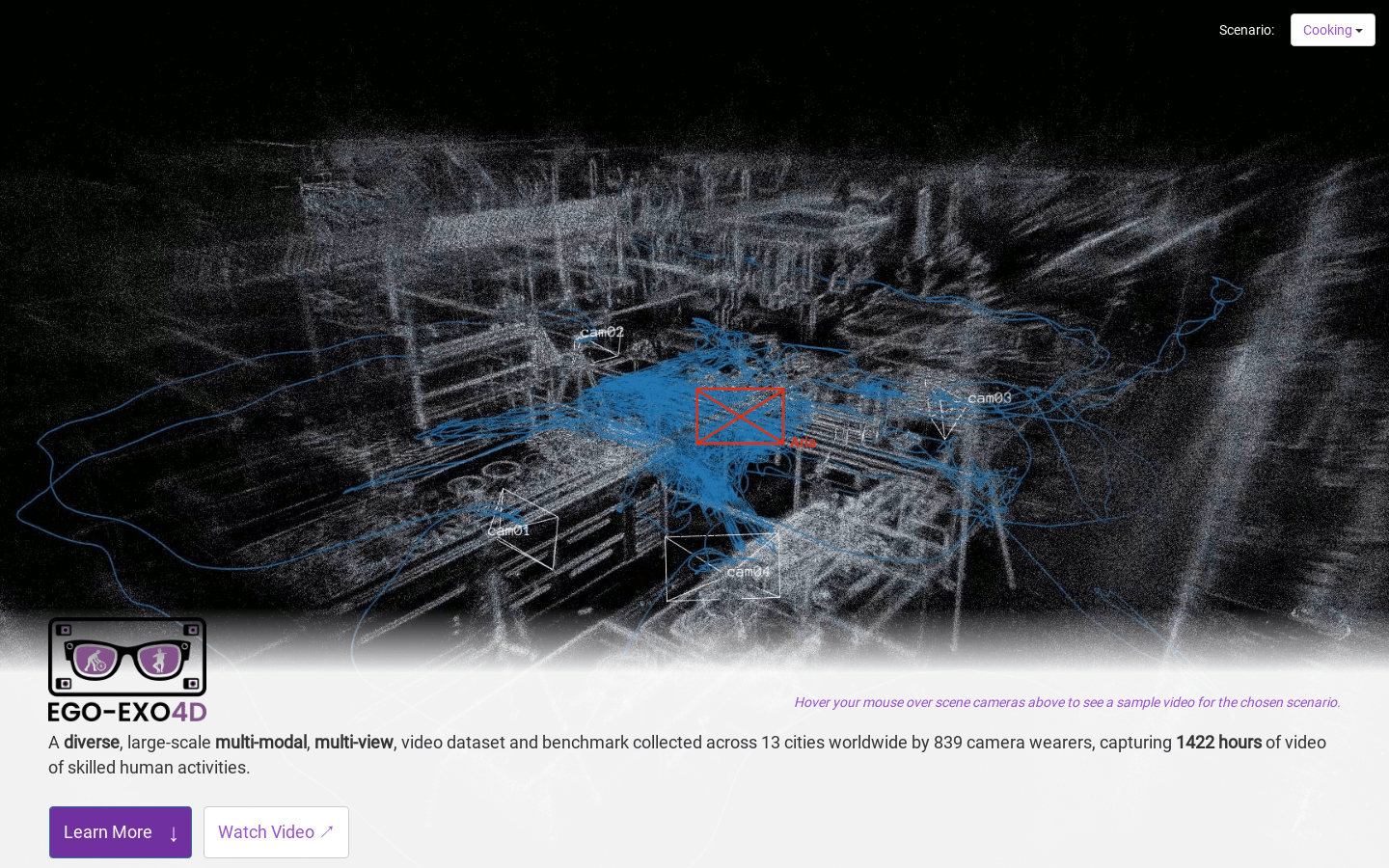
Ego-Exo4D 是一个多模态多视角视频数据集和基准挑战,以捕捉技能人类活动的自我中心和外部中心视频为中心。它支持日常生活活动的多模态机器感知研究。该数据集由 839 位佩戴摄像头的志愿者在全球 13 个城市收集,捕捉了 1422 小时的技能人类活动视频。该数据集提供了专家评论、参与者提供的教程样式的叙述和一句话的原子动作描述等三种自然语言数据集,配对视频使用。Ego-Exo4D 还捕获了多视角和多种感知模态,包括多个视角、七个麦克风阵列、两个 IMUs、一个气压计和一个磁强计。数据集记录时严格遵守隐私和伦理政策,参与者的正式同意。欲了解更多信息,请访问官方网站。
探索 视频 分类下的其他子分类
399 个工具
346 个工具
323 个工具
181 个工具
130 个工具
124 个工具
64 个工具
49 个工具
研究工具 是 视频 分类下的热门子分类,包含 6 个优质AI工具