共找到 28 个AI工具
点击任意工具查看详细信息
Entropy-based sampling 是一种基于熵理论的采样技术,用于提升语言模型在生成文本时的多样性和准确性。该技术通过计算概率分布的熵和方差熵来评估模型的不确定性,从而在模型可能陷入局部最优或过度自信时调整采样策略。这种方法有助于避免模型输出的单调重复,同时在模型不确定性较高时增加输出的多样性。
Llama-3.2-1B是由Meta公司发布的多语言大型语言模型,专注于文本生成任务。该模型使用优化的Transformer架构,并通过监督式微调(SFT)和人类反馈的强化学习(RLHF)进行调优,以符合人类对有用性和安全性的偏好。该模型支持8种语言,包括英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语,并在多种对话使用案例中表现优异。
Qwen2.5系列语言模型是一系列开源的decoder-only稠密模型,参数规模从0.5B到72B不等,旨在满足不同产品对模型规模的需求。这些模型在自然语言理解、代码生成、数学推理等多个领域表现出色,特别适合需要高性能语言处理能力的应用场景。Qwen2.5系列模型的发布,标志着在大型语言模型领域的一次重要进步,为开发者和研究者提供了强大的工具。
XVERSE-MoE-A36B是由深圳元象科技自主研发的多语言大型语言模型,采用混合专家模型(MoE)架构,具有2554亿的总参数规模和360亿的激活参数量。该模型支持包括中、英、俄、西等40多种语言,特别在中英双语上表现优异。模型使用8K长度的训练样本,并通过精细化的数据采样比例和动态数据切换策略,保证了模型的高质量和多样性。此外,模型还针对MoE架构进行了定制优化,提升了计算效率和整体吞吐量。
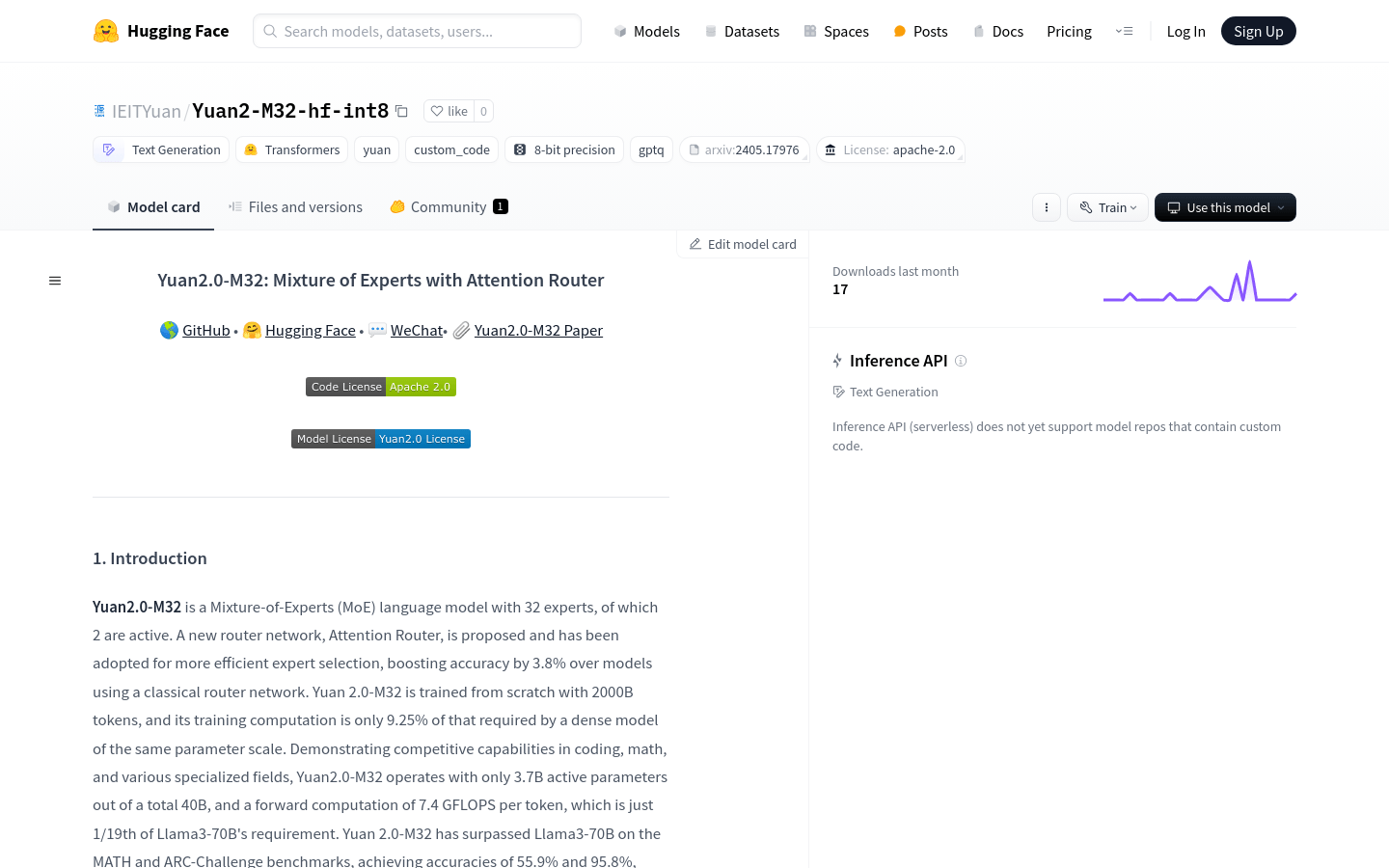
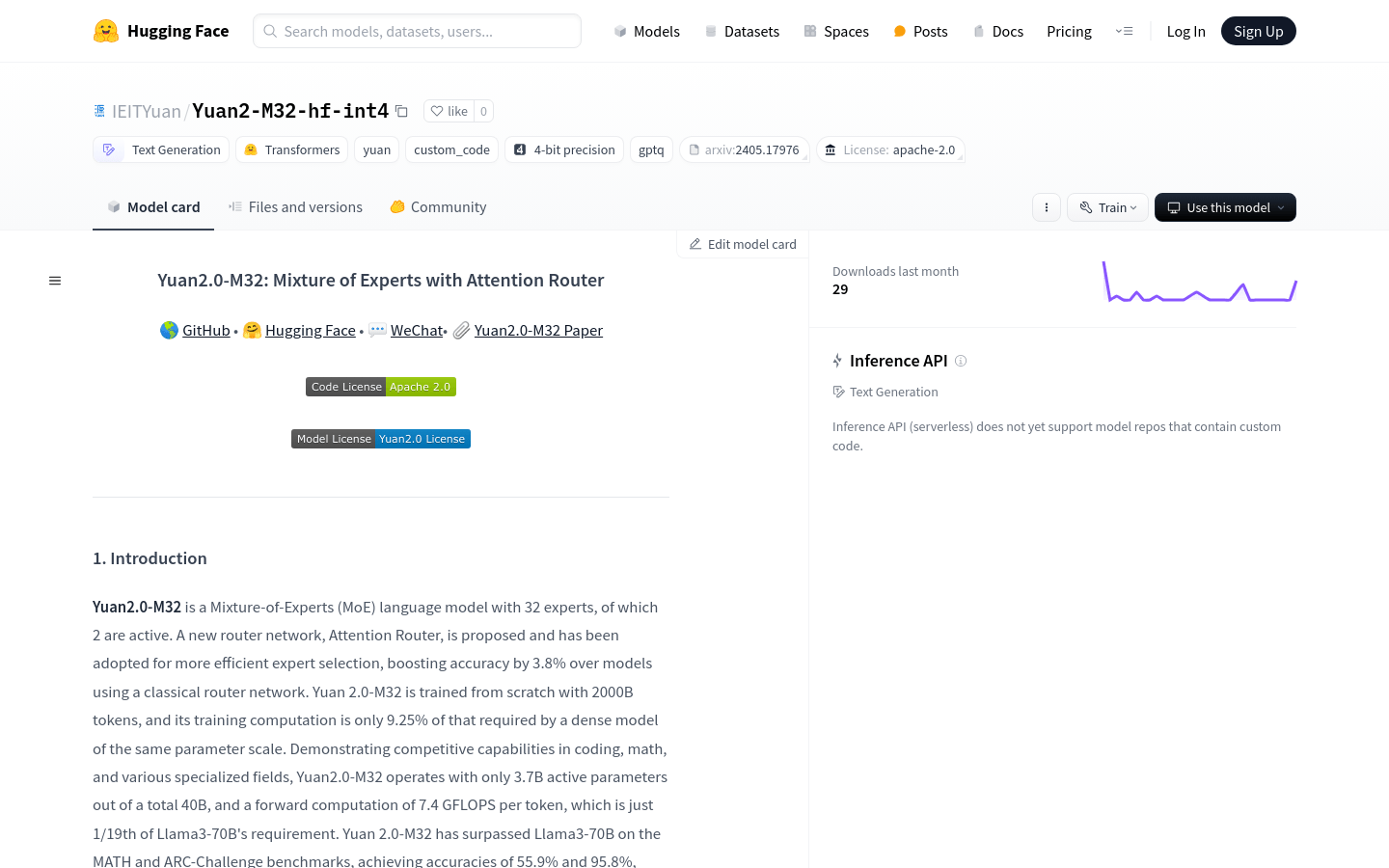
Yuan2.0-M32-hf-int8是一个具有32个专家的混合专家(MoE)语言模型,其中2个是活跃的。该模型通过采用新的路由网络——注意力路由器,提高了专家选择的效率,使得准确率比使用传统路由网络的模型提高了3.8%。Yuan2.0-M32从头开始训练,使用了2000亿个token,其训练计算量仅为同等参数规模的密集模型所需计算量的9.25%。该模型在编程、数学和各种专业领域展现出竞争力,并且只使用37亿个活跃参数,占总参数40亿的一小部分,每个token的前向计算仅为7.4 GFLOPS,仅为Llama3-70B需求的1/19。Yuan2.0-M32在MATH和ARC-Challenge基准测试中超越了Llama3-70B,分别达到了55.9%和95.8%的准确率。
Yuan2.0-M32是一个具有32个专家的混合专家(MoE)语言模型,其中2个处于活跃状态。引入了新的路由网络——注意力路由器,以提高专家选择的效率,使模型在准确性上比使用传统路由器网络的模型提高了3.8%。Yuan2.0-M32从头开始训练,使用了2000亿个token,其训练计算量仅为同等参数规模密集型模型所需计算量的9.25%。在编码、数学和各种专业领域表现出竞争力,Yuan2.0-M32在总参数40亿中只有3.7亿活跃参数,每个token的前向计算量为7.4 GFLOPS,仅为Llama3-70B需求的1/19。Yuan2.0-M32在MATH和ARC-Challenge基准测试中超越了Llama3-70B,准确率分别达到了55.9%和95.8%。
Yuan2.0-M32是一个具有32个专家的混合专家(MoE)语言模型,其中2个是活跃的。提出了一种新的路由网络——注意力路由,用于更高效的专家选择,提高了3.8%的准确性。该模型从零开始训练,使用了2000B个token,其训练计算量仅为同等参数规模的密集模型所需计算量的9.25%。在编码、数学和各种专业领域表现出竞争力,仅使用3.7B个活跃参数,每个token的前向计算量仅为7.4 GFLOPS,仅为Llama3-70B需求的1/19。在MATH和ARC-Challenge基准测试中超越了Llama3-70B,准确率分别达到了55.9%和95.8%。
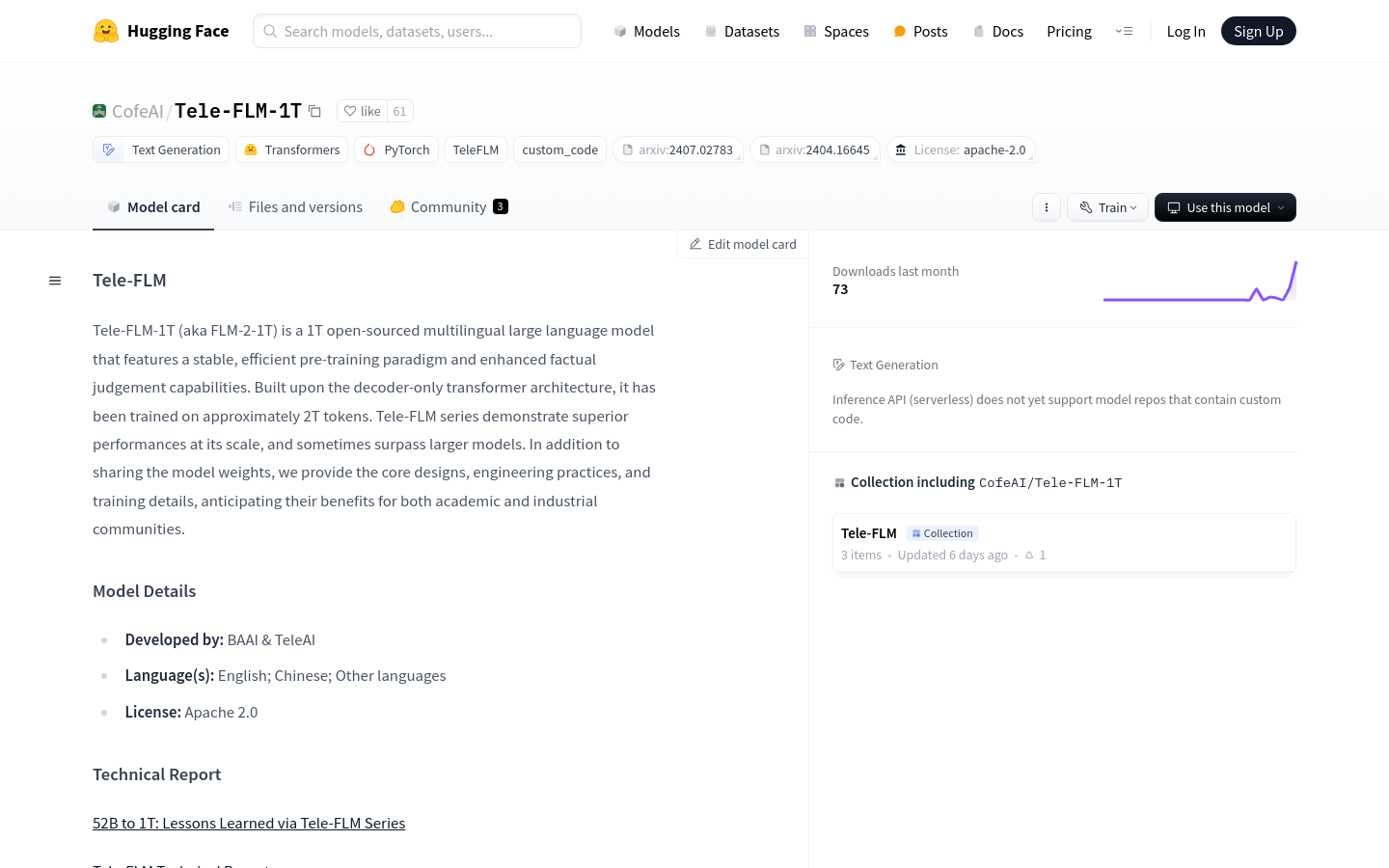
Tele-FLM-1T是一个开源的1T多语言大型语言模型,基于解码器仅Transformer架构,经过约2T tokens的训练。该模型在规模上展现出卓越的性能,有时甚至超越了更大的模型。除了分享模型权重外,还提供了核心设计、工程实践和训练细节,期待对学术和工业社区都有所裨益。
Meta Llama 3.1是一系列预训练和指令调整的多语言大型语言模型(LLMs),包含8B、70B和405B三种大小的模型,专门针对多语言对话使用案例进行了优化,并在行业基准测试中表现优异。该模型使用优化的transformer架构,并通过监督式微调(SFT)和人类反馈的强化学习(RLHF)进一步与人类偏好对齐,以确保其有用性和安全性。
Meta Llama 3.1是Meta公司推出的一种大型语言模型,拥有70亿参数,支持8种语言的文本生成和对话。该模型使用优化的Transformer架构,并通过监督微调(SFT)和人类反馈强化学习(RLHF)进行调优,以符合人类对有用性和安全性的偏好。它旨在为商业和研究用途提供支持,特别是在多语言对话场景下表现出色。
Meta Llama 3 是 Meta 推出的最新大型语言模型,旨在为个人、创作者、研究人员和各类企业解锁大型语言模型的能力。该模型包含从8B到70B参数的不同规模版本,支持预训练和指令调优。模型通过 GitHub 仓库提供,用户可以通过下载模型权重和分词器进行本地推理。Meta Llama 3 的发布标志着大型语言模型技术的进一步普及和应用,具有广泛的研究和商业潜力。
DCLM-Baseline-7B是一个7亿参数的语言模型,由DataComp for Language Models (DCLM)团队开发,主要使用英语。该模型旨在通过系统化的数据整理技术来提高语言模型的性能。模型训练使用了PyTorch与OpenLM框架,优化器为AdamW,学习率为2e-3,权重衰减为0.05,批次大小为2048序列,序列长度为2048个token,总训练token数达到了2.5T。模型训练硬件使用了H100 GPU。
Gemma是由Google开发的一系列轻量级、先进的开放模型,基于与Gemini模型相同的研究和技术构建。它们是文本到文本的解码器仅大型语言模型,适用于多种文本生成任务,如问答、摘要和推理。Gemma模型的相对较小的尺寸使其能够在资源有限的环境中部署,如笔记本电脑、桌面或您自己的云基础设施,使每个人都能接触到最先进的AI模型,并促进创新。
multi-token prediction模型是Facebook基于大型语言模型研究开发的技术,旨在通过预测多个未来令牌来提高模型的效率和性能。该技术允许模型在单次前向传播中生成多个令牌,从而加快生成速度并可能提高模型的准确性。该模型在非商业研究用途下免费提供,但使用时需遵守Meta的隐私政策和相关法律法规。
Samba是一个简单而强大的混合模型,具有无限的上下文长度。它的架构非常简单:Samba = Mamba + MLP + 滑动窗口注意力 + 层级MLP堆叠。Samba-3.8B模型在Phi3数据集上训练了3.2万亿个token,主要基准测试(例如MMLU、GSM8K和HumanEval)上的表现大大超过了Phi3-mini。Samba还可以通过最少的指令调整实现完美的长上下文检索能力,同时保持与序列长度的线性复杂度。这使得Samba-3.8B-instruct在下游任务(如长上下文摘要)上表现出色。
GLM-4-9B-Chat-1M 是智谱 AI 推出的新一代预训练模型,属于 GLM-4 系列的开源版本。它在语义、数学、推理、代码和知识等多方面的数据集测评中展现出较高的性能。该模型不仅支持多轮对话,还具备网页浏览、代码执行、自定义工具调用和长文本推理等高级功能。支持包括日语、韩语、德语在内的26种语言,并特别推出了支持1M上下文长度的模型版本,适合需要处理大量数据和多语言环境的开发者和研究人员使用。
GLM-4-9B是智谱AI推出的新一代预训练模型,属于GLM-4系列中的开源版本。它在语义、数学、推理、代码和知识等多方面的数据集测评中表现优异,具备多轮对话、网页浏览、代码执行、自定义工具调用和长文本推理等高级功能。此外,还支持包括日语、韩语、德语在内的26种语言,并有支持1M上下文长度的模型版本。
MiLM-6B是由小米公司开发的大规模预训练语言模型,参数规模达到64亿,它在中文基础模型评测数据集C-Eval和CMMLU上均取得同尺寸最好的效果。该模型代表了自然语言处理领域的最新进展,具有强大的语言理解和生成能力,可以广泛应用于文本生成、机器翻译、问答系统等多种场景。
MAP-NEO是一个完全开源的大型语言模型,它包括预训练数据、数据处理管道(Matrix)、预训练脚本和对齐代码。该模型从零开始训练,使用了4.5T的英文和中文token,展现出与LLaMA2 7B相当的性能。MAP-NEO在推理、数学和编码等具有挑战性的任务中表现出色,超越了同等规模的模型。为了研究目的,我们致力于实现LLM训练过程的完全透明度,因此我们全面发布了MAP-NEO,包括最终和中间检查点、自训练的分词器、预训练语料库以及高效稳定的优化预训练代码库。
kan-gpt是一个基于PyTorch的Generative Pre-trained Transformers (GPTs) 实现,它利用Kolmogorov-Arnold Networks (KANs) 进行语言建模。该模型在文本生成任务中展现出了潜力,特别是在处理长距离依赖关系时。它的重要性在于为自然语言处理领域提供了一种新的模型架构,有助于提升语言模型的性能。
Llama-3 70B Instruct Gradient 1048k是一款由Gradient AI团队开发的先进语言模型,它通过扩展上下文长度至超过1048K,展示了SOTA(State of the Art)语言模型在经过适当调整后能够学习处理长文本的能力。该模型使用了NTK-aware插值和RingAttention技术,以及EasyContext Blockwise RingAttention库,以高效地在高性能计算集群上进行训练。它在商业和研究用途中具有广泛的应用潜力,尤其是在需要长文本处理和生成的场景中。
Mixtral-8x22B是一个预训练的生成式稀疏专家语言模型。它由Mistral AI团队开发,旨在推进人工智能的开放发展。该模型具有141B个参数,支持多种优化部署方式,如半精度、量化等,以满足不同的硬件和应用场景需求。Mixtral-8x22B可以用于文本生成、问答、翻译等自然语言处理任务。
RecurrentGemma是谷歌开发的一系列开放语言模型,采用创新的循环架构设计,在文本生成任务上性能优异,包括问答、摘要和推理等。与Gemma模型相比,RecurrentGemma所需的内存更少,生成长序列的推理速度更快。该模型提供了预训练和针对指令的微调版本,可广泛应用于内容创作、对话AI等场景。
Qwen1.5-MoE-A2.7B是一款大规模的MoE(Mixture of Experts)语言模型,仅有27亿个激活参数,但性能可与70亿参数模型相媲美。相比传统大模型,该模型训练成本降低75%,推理速度提高1.74倍。它采用特别的MoE架构设计,包括细粒度专家、新的初始化方法和路由机制等,大幅提升了模型效率。该模型可用于自然语言处理、代码生成等多种任务。
WhiteRabbitNeo-7B-v1.5a 是WhiteRabbitNeo系列的一个版本,这是一系列大规模、面向自然语言处理任务的预训练语言模型。该模型能够支持文本生成、摘要、翻译等多种任务。
Yi-9B是01.AI研发的下一代开源双语大型语言模型系列之一。训练数据量达3T,展现出强大的语言理解、常识推理、阅读理解等能力。在代码、数学、常识推理和阅读理解等方面表现卓越,是同尺寸开源模型中的佼佼者。适用于个人、学术和商业用途。
LLaMA Pro 是一种用于大规模自然语言处理的模型。通过使用 Transformer 模块的扩展,该模型可以在不遗忘旧知识的情况下,高效而有效地利用新语料库来提升模型的知识。LLaMA Pro 具有出色的性能,在通用任务、编程和数学方面都表现出色。它是基于 LLaMA2-7B 进行初始化的通用模型。LLaMA Pro 和其指导类模型(LLaMA Pro-Instruct)在各种基准测试中均取得了先进的性能,展示了在智能代理中进行推理和处理各种任务的巨大潜力。该模型为将自然语言和编程语言进行整合提供了宝贵的见解,为在各种环境中有效运作的先进语言代理的开发奠定了坚实的基础。
Mistral是一个小型但强大的开源自然语言处理模型,可适用于多种使用场景。Mistral 7B模型性能优于Llama 2 13B模型,拥有自然的编程能力和8000个序列长度。Mistral采用Apache 2.0许可证发布,易于在任何云端和个人电脑GPU上部署使用。
探索 编程 分类下的其他子分类
768 个工具
465 个工具
368 个工具
294 个工具
140 个工具
85 个工具
66 个工具
61 个工具
AI语言模型 是 编程 分类下的热门子分类,包含 28 个优质AI工具