共找到 100 个AI工具
点击任意工具查看详细信息
该产品是一个基于LoRA技术的卡通抽象扁平插画模型,由北京奇点星宇科技有限公司开发。它专注于生成可爱卡通风格的扁平插画,适用于需要快速生成插画素材的设计师和艺术家。产品背景信息显示,它支持在线生成和下载,具有较高的用户互动性和社区活跃度。价格方面,产品提供免费试用和付费选项,具体价格未在页面中明确标注。
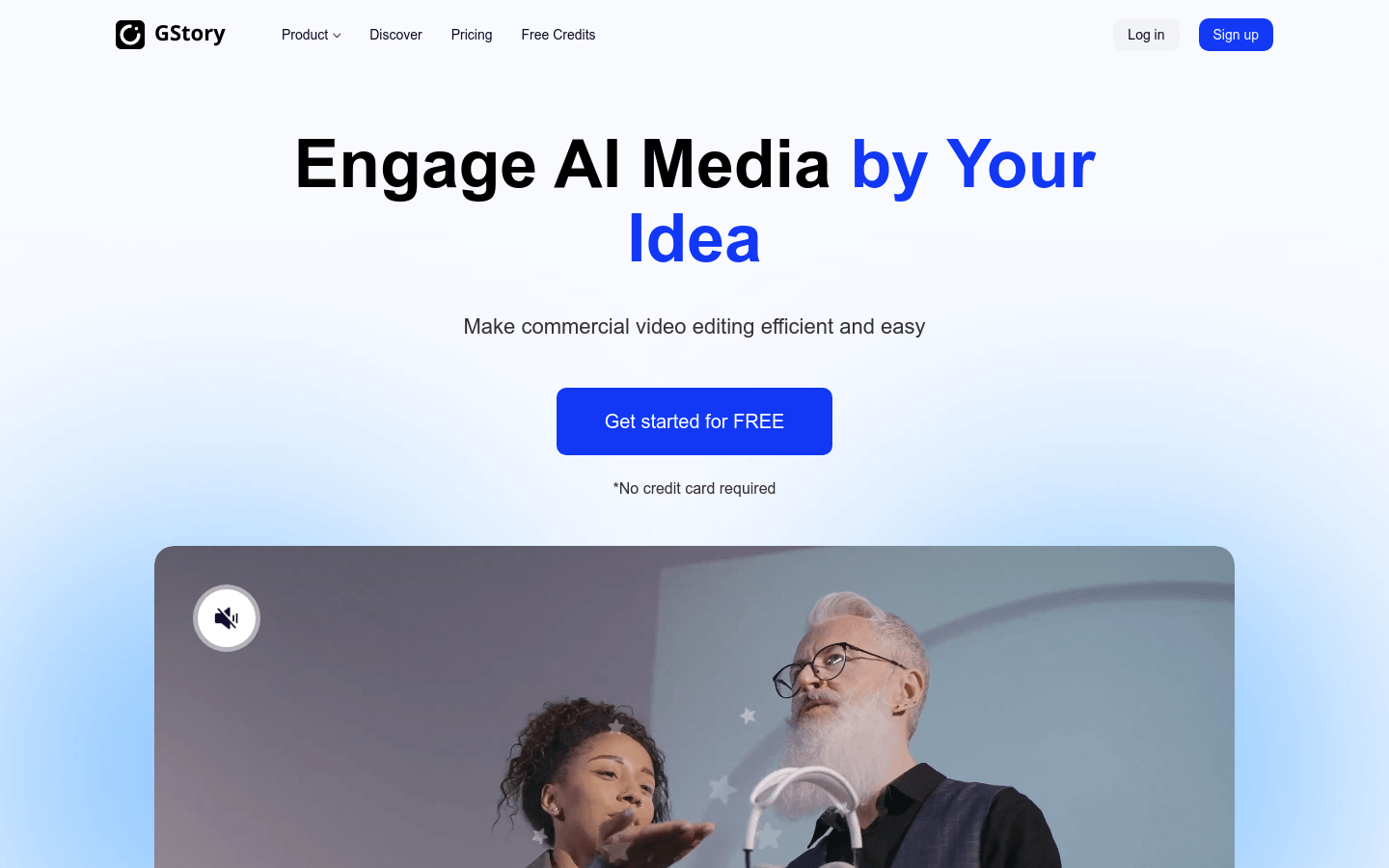
GStory是一个在线视频和图片编辑平台,提供多种智能编辑功能,如背景更换、增强器、水印去除和AI图像生成器。它通过AI技术简化商业视频编辑流程,提高效率,降低成本,并被超过50,000家不同规模的公司所信赖。
Project Concept 是 Adobe 推出的一款基于 AI 的创意概念化和情绪板工具,旨在帮助创意专业人士在项目初期快速探索和迭代创意概念。它利用 Adobe 的 Firefly 生成式 AI 模型,允许用户混合图像、变换资产区域、混合风格和背景等。该产品支持多人协作,并与 Adobe Creative Cloud 集成,使得与 Photoshop、Illustrator 或 Adobe Express 的工作流程无缝衔接。Project Concept 还通过 Content Credentials 技术尊重艺术家的工作,确保图像来源的透明度和 AI 使用的合规性。
PicLooks是一个提供AI生成的免费真实风格头像的网站,旨在为设计师和营销人员提供高质量的头像图片,用于设计原型、营销材料等。这些头像图片完全由AI生成,避免了使用传统库存照片网站的图片可能带来的版权问题。用户可以快速找到符合需求的头像,节省了大量搜索时间,并且可以用于商业用途,无需担心版权问题。
Yaelokre OC Maker是一个在线平台,允许用户轻松创建和个性化他们的原创角色。该平台强调定制化、用户友好的设计和社区参与,用户可以创建反映个人风格的特色角色。它提供了逼真的视觉效果、用户友好的界面、角色多样性、社区参与和24/7客户支持等特点。此外,它还提供了快速开始的模板,同时保留了定制每个细节的灵活性。
Easy Sticker Maker是一个基于人工智能的在线贴纸生成器,它利用深度学习和生成对抗网络等技术,根据用户的文字描述生成具有视觉吸引力的定制贴纸。该产品支持多语言,易于使用,无需专业技能,适合个人和商业项目使用。它提供了一个免费试用,并有多种定价计划供用户选择。
Hot Tattoo AI是一个革命性的AI纹身生成器,它允许用户轻松创建自定义纹身设计。无论是为男性还是女性寻找完美的纹身设计,该平台都能激发独特且个性化的艺术作品,满足您的个人风格和偏好。该技术的主要优点包括直观易用、设计丰富多样、能够快速生成纹身设计,并且支持与纹身艺术家的协作创作。此外,它还提供了对当前流行趋势的洞察,帮助用户和艺术家保持最新。
3D Mesh Generation是Anything World推出的一款在线3D模型生成工具,它利用人工智能技术,允许用户通过简单的文字描述或上传图片来快速生成3D模型。这项技术的重要性在于它极大地简化了3D模型的创建过程,使得没有专业3D建模技能的用户也能轻松创建出高质量的3D内容。产品背景信息显示,Anything World致力于通过其平台提供创新的3D内容创建解决方案,而3D Mesh Generation是其产品线中的重要组成部分。关于价格,用户可以在注册后查看具体的定价方案。
AI Comic Factory是一个创新的在线平台,旨在帮助用户轻松创建独特的漫画。用户可以通过输入描述性的提示或上传图片来生成各种风格的漫画,包括角色、场景和对话的选项。该平台提供定制选项,如版式布局、角色设计和对话生成,以增强漫画的视觉效果。凭借用户友好的步骤和可调设置,实现高质量的结果变得简单。无论是个人娱乐还是创意项目,AI Comic Factory都使得漫画创作过程变得高效且愉快。
AI Poster Maker AI海报生成是一个利用人工智能技术,帮助用户无需设计技能即可创建引人注目海报的在线工具。它通过用户描述的内容和选择的参数自动生成海报设计,大大简化了设计流程,提高了设计效率。产品背景是满足市场对快速、便捷设计工具的需求,特别适合需要快速产出设计内容的个人和企业。目前产品提供免费试用,具体价格和定位需要用户登录后查看详细信息。
OC Maker是一个在线平台,允许用户通过描述角色的外貌、个性和特殊能力来生成独特的原创角色。这个AI驱动的工具结合了创意和技术创新,使用户能够快速将想象中的角色变为可视化的形象。它的重要性在于提供了一个简单易用的界面,让没有专业设计技能的用户也能创造出个性化的角色,满足了创意表达和角色设计的需求。OC Maker的背景信息显示,它是由一群热爱角色设计的技术人员开发的,旨在帮助用户释放创造力,探索不同的角色宇宙。产品提供免费试用,并且有不同级别的订阅计划,以满足不同用户的需求。
Free AI Tattoo Generator是一个利用人工智能技术,将用户的文字描述转化为独特纹身设计的在线平台。它拥有29种不同的纹身风格供用户选择,能够在短时间内生成个性化的纹身设计图。该产品的主要优点包括无限的创造力、个性化定制、多样化的风格选择、快速高效以及成本效益。它不仅为专业纹身师提供了便利,也为没有绘画技能的纹身爱好者提供了创造专业品质设计的机会。
Blind Box Studio是一个基于网站的设计工具,它通过ComfyUI Workflow平台为用户提供了一个可以自由探索和构建创意工作流的环境。该工具支持用户通过节点图来构建和修改设计流程,适用于多种设计领域,如图像编辑、3D建模等。Blind Box Studio的主要优点在于其高度的自定义性和灵活性,用户可以根据自己的需求创建独特的工作流程。此外,它还支持与多种插件和扩展的集成,进一步增强了其功能性。
Stager AI是一个为房地产行业设计的虚拟家居布置和图片编辑器,利用人工智能技术帮助用户快速、轻松地提升房产图片的吸引力,从而提高房产的在线展示效果和销售转化率。它支持一键式虚拟布置、图片增强、地板更换、墙面粉刷、草坪替换和天空替换等功能,无需用户具备专业的图片编辑技能。Stager AI旨在帮助房地产经纪人、摄影师和Airbnb房东等用户群体,通过提升房产图片的专业度来吸引更多潜在买家或租客。
IconGen.io是一个由AI驱动的图标生成器,用户可以通过它快速创建适用于商业、演示文稿等场合的精美图标。该工具利用人工智能技术,简化了图标设计流程,使得即使是没有设计背景的用户也能轻松创建出专业的图标。IconGen.io的主要优点包括快速生成、易于使用、设计多样化,适合需要提升品牌形象的用户。
LOGO123是一个提供专业LOGO设计服务的平台,它利用人工智能技术为用户设计个性化的LOGO,并通过设计师PK的方式为用户挑选出最佳的设计方案。该平台支持在线提交设计需求,用户可以选择多种套餐服务,包括LOGO设计、品牌VI设计、广告海报设计以及商标注册等。LOGO123致力于为用户提供高品质、全方位的品牌设计服务。
3DTopia-XL 是一个基于扩散变换器(DiT)构建的高质量3D资产生成技术,使用一种新颖的3D表示方法 PrimX。该技术能够将3D形状、纹理和材质编码到一个紧凑的N x D张量中,每个标记是一个体积原语,锚定在形状表面上,用体素化载荷编码符号距离场(SDF)、RGB和材质。这一过程仅需5秒即可从文本/图像输入生成3D PBR资产,适用于图形管道。
Adobe Express QR 码生成器是一个在线工具,允许用户无需下载任何软件即可快速生成可扫描的二维码。用户可以自定义二维码的颜色和样式,以匹配其品牌或个人风格。该工具支持多种文件格式下载,适用于商业营销、个人品牌推广等多种场景。Adobe Express 提供了大量模板和设计资源,使得即使是设计新手也能轻松创建引人注目的二维码。
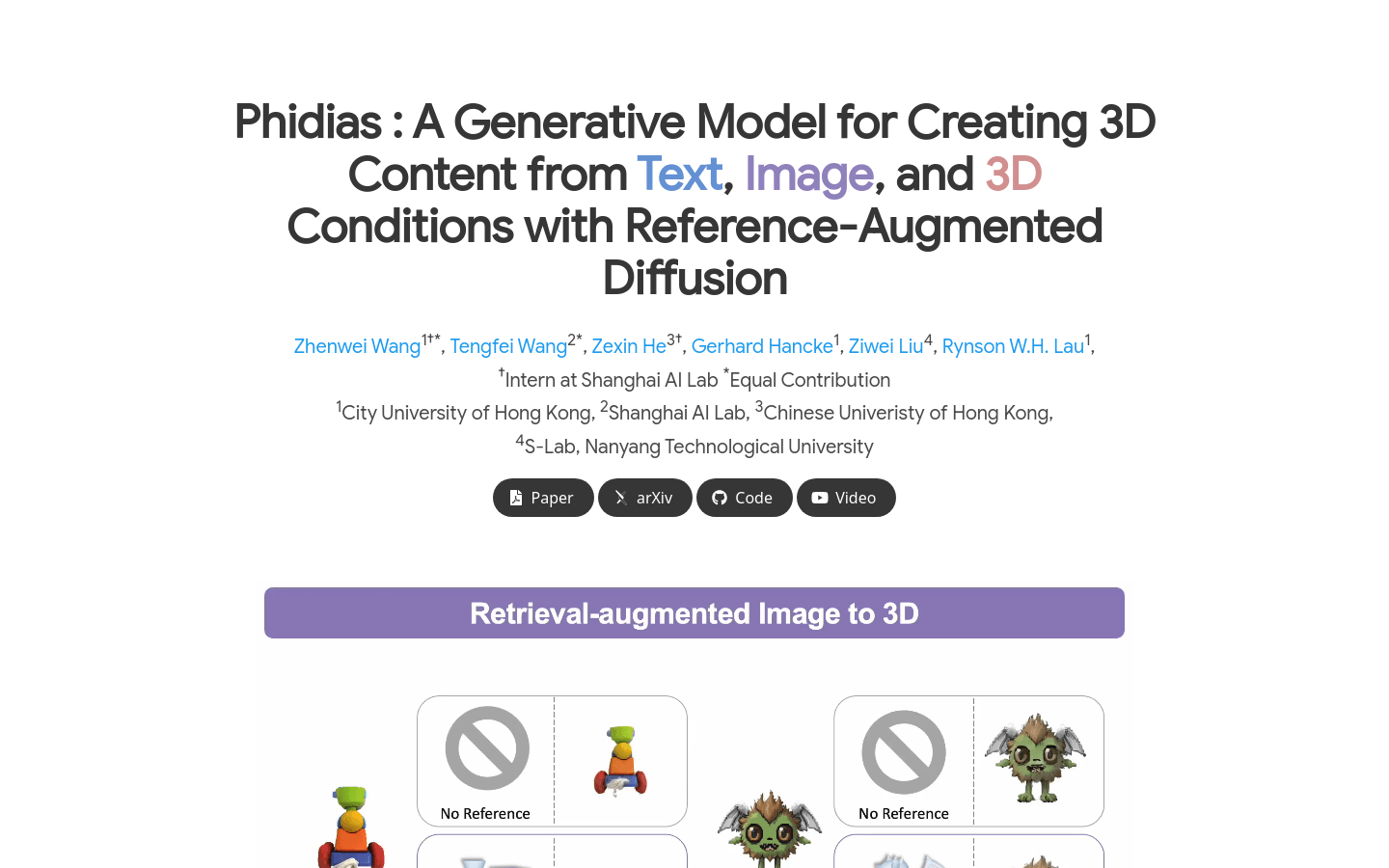
Phidias是一个创新的生成模型,它利用扩散技术进行参考增强的3D生成。该模型通过图像、文本或3D条件生成高质素的3D资产,并且能够在几秒钟内完成。它通过整合三个关键组件:动态调节条件强度的Meta-ControlNet、动态参考路由以及自参考增强,显著提高了生成质量、泛化能力和可控性。Phidias为使用文本、图像和3D条件进行3D生成提供了统一框架,并具有多种应用场景。
触站是一个为插画师、设计师和艺术爱好者提供作品展示、交流和学习的平台。它汇集了众多P站(pixiv)画师与认证画师的作品,包括动漫图片、动漫壁纸、插画、CG原画等。触站不仅为艺术家提供了一个展示自己作品的空间,也为爱好者提供了一个发现和学习优秀作品的场所。
Magickimg AI贴纸生成器是一个利用人工智能技术,根据用户输入的提示词快速生成个性化贴纸的在线工具。它主要面向需要为社交媒体、聊天应用等增添个性化元素的用户。产品背景基于深度学习技术,通过用户友好的界面,提供简单快捷的操作体验。产品的主要优点包括快速生成、易于操作、高质量输出以及安全可靠的服务。
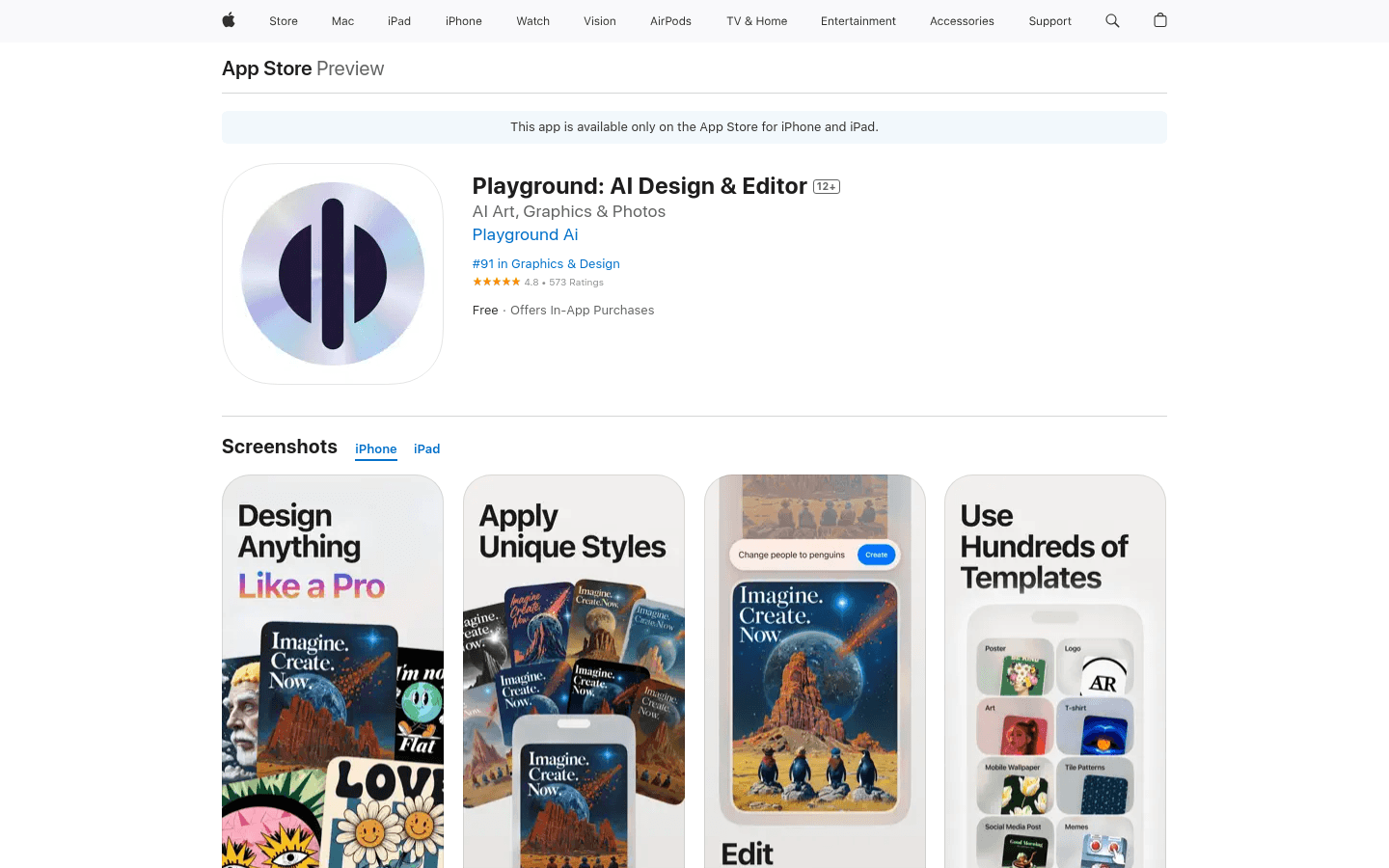
Playground: AI Design & Editor是一款利用人工智能技术,让用户能够通过简单的文字描述快速生成和编辑艺术作品的应用程序。它提供了数百种预设计模板和多种风格,用户可以根据自己的需求进行无限次的编辑和调整,直到达到满意的设计效果。该应用适合需要快速设计各类图形素材的用户,无论是商业用途还是个人爱好,都能通过Playground的AI工具轻松实现创意。
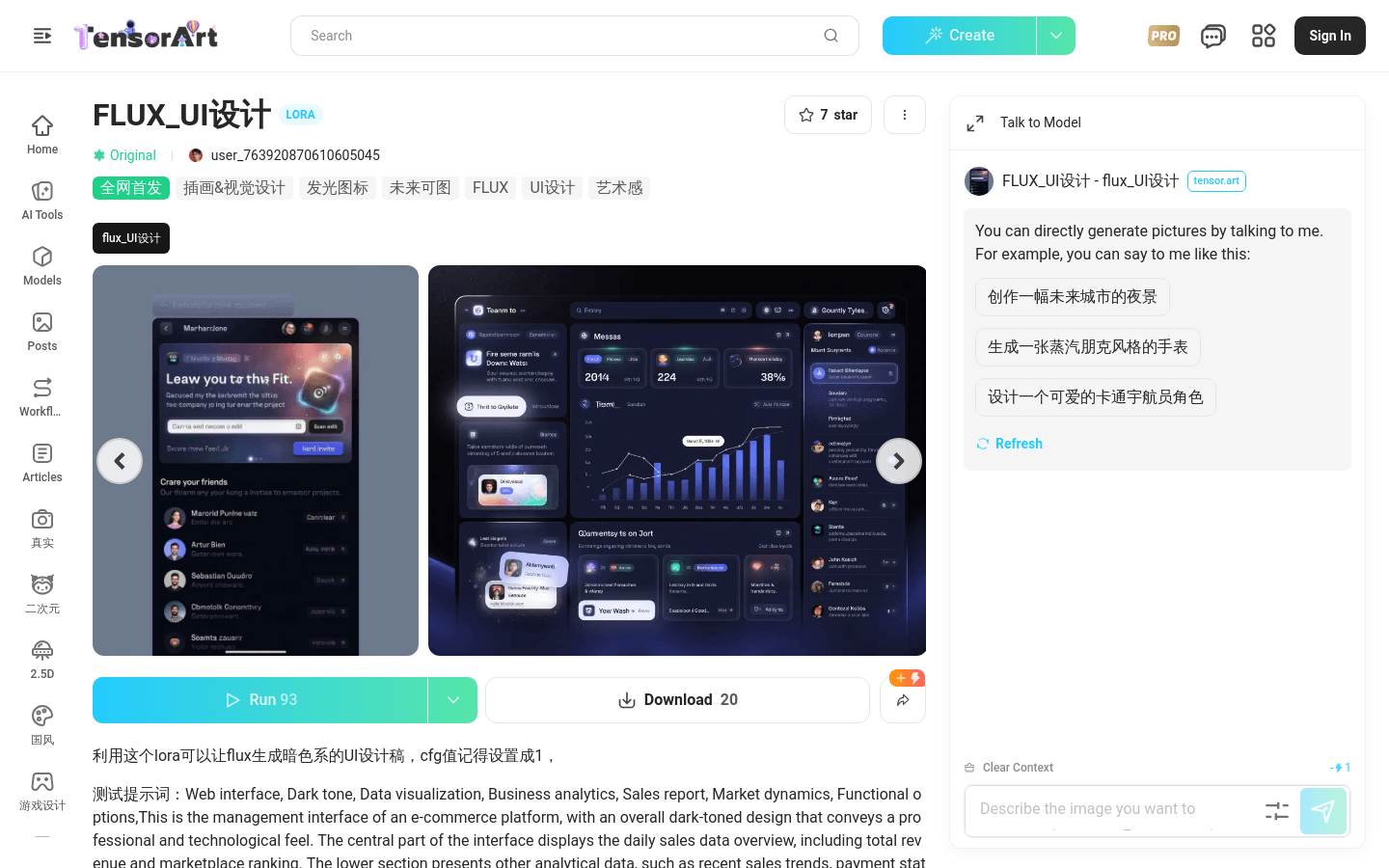
FLUX_UI设计是一个利用AI技术辅助用户生成具有艺术感的UI设计模型。它特别适用于B端的深色UI设计,支持发光效果,能够生成具有专业感和技术感的电商管理界面。该模型通过数据可视化和商业洞察,为商家提供全面的运营决策支持。
FLUX Y2K TYPEFACE是一个基于LoRA技术的文本/字体生成模型,能够以高精度生成Y2K风格的文本、字体、标志和徽章。该模型由Black Forest Labs, Inc.授权,代表了文本和字体生成技术的新进展,具有高度的创造性和实用性。
AI Icon Generator是一个在线设计工具,利用人工智能技术帮助用户快速生成个性化的图标。它通过分析用户需求,提供多样化的图标设计选项,满足不同设计场景的需求。该产品以其高效性、易用性和创新性在设计领域中占有一席之地,特别适合需要快速产出设计素材的专业人士和团队。
DressCode是一个文本驱动的3D服装生成框架,旨在为新手民主化设计,为时尚设计、虚拟试穿和数字人类创造提供巨大潜力。它首先介绍了SewingGPT,这是一个基于GPT的架构,集成了交叉注意力和文本条件嵌入,以文本指导生成缝纫图案。然后,它定制了一个预训练的Stable Diffusion,以生成基于瓦片的基于物理的渲染(PBR)纹理。通过利用大型语言模型,该框架通过自然语言交互生成CG友好的服装,还促进了图案完成和纹理编辑,通过用户友好的交互简化了设计过程。
Canva可画魔力工作室是一个集成了AI工具的在线设计平台,提供从文案生成、图片编辑到动画制作等一系列设计功能。它通过简化设计流程,使个人创作者和团队能够快速实现创意构想,提升工作效率。魔力工作室的AI功能包括文案自动生成、图像智能编辑等,旨在帮助用户以更少的时间和成本完成高质量的设计作品。
SceneTeller是一个创新的3D场景生成平台,它利用最新的生成式人工智能技术,允许用户通过自然语言描述来设计室内3D场景。这项技术大大降低了3D设计的技术门槛,使得非专业用户也能轻松创建个性化的3D空间。产品的主要优点包括易用性、高效率和创意自由度。
AI Drawing Pro是一款利用人工智能技术将用户的文字描述转化为视觉艺术作品的应用程序。它支持多种艺术风格,如3D卡通、动画、油画、水彩、素描、国画和扁平插画等,为用户提供了丰富的创作空间。用户无需专业技能即可轻松创作出令人惊叹的艺术作品,并且可以轻松保存和分享自己的创作。
Evined Draw是一款创新的绘画应用,它结合了AI技术,为用户带来独特的绘画体验。用户可以每天根据新的主题进行绘画,并通过AI模型生成独特的图像,同时获得1到5的评分,以反映其作品与主题的契合度。这款应用适合所有水平的艺术家,提供了一个完美的平台来表达他们的艺术才能。
Adobe Firefly Vector AI是Adobe推出的一系列创意生成AI模型,旨在通过生成AI功能增强创意工作。Firefly模型和服务于Photoshop、Illustrator、Lightroom等Adobe创意应用中。它通过文本到图像、生成填充、生成扩展等功能,帮助用户以前所未有的控制力和创造力生成丰富、逼真的图像和艺术作品。Firefly的训练数据包括Adobe Stock的授权内容、公开许可内容和公共领域内容,确保其商业使用安全。Adobe致力于负责任地开发生成AI,并通过与创意社区的紧密合作,不断改进技术,支持和提升创意过程。
Microsoft Designer 是一款由微软公司开发的应用,利用人工智能技术帮助用户进行创意设计和图片编辑。该应用支持用户通过文字描述生成图片、制作个性化壁纸、设计节日和生日卡片等。其主要优点包括强大的AI生成能力、易用性以及丰富的设计模板。
社交媒体图片生成器是uBrand品牌创意工作室推出的一款在线设计工具,它能够帮助用户快速生成适合社交媒体的图片封面。该工具利用人工智能技术,简化了设计流程,提高了设计效率,使得即使是设计新手也能轻松制作出专业水准的图片。
AI Logo Designs Gallery是一个在线平台,利用人工智能技术为用户提供个性化的Logo设计服务。用户只需输入品牌名称和一些基本的设计要求,AI即可生成多种风格的Logo供选择。该平台支持多种行业和风格,包括极简、中等复杂度等,满足不同用户的需求。
Logo Galleria是一个利用人工智能技术提供在线标志设计的平台。用户只需输入企业名称、行业和设计偏好,即可快速生成定制的标志概念。它为初创公司、内容创作者等提供了一个经济实惠且易于使用的解决方案,帮助他们建立强大的品牌标识。
color4bg.js 是一个使用 WebGL 和 JavaScript 生成动态、抽象且视觉震撼的背景图像的 JavaScript 库。它允许用户自定义多达六种颜色,以生成背景图案,支持动态动画效果,并可通过种子值确保每次生成相同的图案,便于集成到网页设计中。
ClotheDreamer是一个基于3D高斯的文本引导服装生成模型,能够从文本描述生成高保真的、可穿戴的3D服装资产。它采用了一种新颖的表示方法Disentangled Clothe Gaussian Splatting (DCGS),允许服装和人体分别进行优化。该技术通过双向Score Distillation Sampling (SDS)来提高服装和人体渲染的质量,并支持自定义服装模板输入。ClotheDreamer的合成3D服装可以轻松应用于虚拟试穿,并支持物理精确的动画。
GENTYPE 是一个创新的在线工具,它允许用户将任何图像或对象转换成独特的字母表。这项技术不仅为设计师提供了无限的创意空间,还能用于教育和娱乐领域,帮助人们以新颖的方式学习和表达信息。
MeshAnything是一个利用自回归变换器进行艺术家级网格生成的模型,它可以将任何3D表示形式的资产转换为艺术家创建的网格(AMs),这些网格可以无缝应用于3D行业。它通过较少的面数生成网格,显著提高了存储、渲染和模拟效率,同时实现了与先前方法相当的精度。
Illustration Generator是Icons8推出的AI图像生成器,由专业艺术家和工程师团队打造。它能够根据用户提供的文本提示或参考图像,生成具有一致艺术风格的插图,满足网页、桌面和移动应用、社交媒体、市场营销等设计需求。AI模型基于Icons8艺术家制作的视觉素材进行训练,确保生成的AI艺术作品具有一致性和专业外观。
FontStudio是一个创新的字体效果生成模型,它利用自适应扩散技术,能够在不规则的字体形状画布上生成连贯一致的视觉内容。这项技术突破了传统矩形画布的限制,为多语言字体设计提供了新的解决方案。FontStudio系统在用户偏好研究中显示出明显的优势,甚至在与Adobe Firefly等顶尖商业产品比较时,也获得了78%的美学胜出率。
SketchDeco是一个创新的在线工具,它能够将黑白草图、遮罩和色彩调色板转化为逼真的彩色图像,无需用户定义文本提示。这项技术结合了ControlNet和分阶段生成的方法,使用Stable Diffusion v1.5和BLIP-2文本提示,提供了忠实的图像生成和用户导向的色彩化。它不仅快速、无需训练,而且与消费级Nvidia RTX 4090 Super GPU兼容,为创意专业人士和爱好者提供了宝贵的资源。
MaPa是一种创新的方法,能够根据文本描述为3D网格生成材质。该技术通过创建分段的程序化材质图来表示外观,支持高质量渲染,并在编辑上提供了显著的灵活性。利用预训练的2D扩散模型,MaPa在不需要大量配对数据的情况下,架起了文本描述和材质图之间的桥梁。该技术通过分解形状为多个部分,并设计了控制段的扩散模型来合成与网格部分对齐的2D图像,进而初始化材质图的参数,并通过可微分渲染模块进行微调,以产生符合文本描述的材质。广泛的实验表明,MaPa在逼真度、分辨率和可编辑性方面优于现有技术。
Sticker Creator是微软推出的一个在线工具,用户可以通过它创建个性化的贴纸和图像。它支持多种风格和元素,如3D渲染、像素艺术、卡通风格等,用户可以根据自己的需求生成独特的视觉内容。该工具的背景是微软致力于提供创新的设计解决方案,以满足用户在数字媒体和创意表达方面的需求。
TimeUi是一个为ComfyUI设计的自定义时间轴节点系统,旨在创建类似于视频/动画编辑工具的时间轴,但无需依赖传统的时间代码。用户可以轻松添加、删除或重新排列行,提供流畅的用户体验。系统支持图像上传和管理,允许用户直接将图像上传到节点或附加其他“上传图像”节点,简化工作流程。此外,每个时间轴行包含多种自定义设置,如切换图像遮罩的可见性,增强对图像调整的控制。节点可以独立工作或与其他外部节点一起工作,轻松切换设置如IP适配器、图像负片、注意力遮罩、剪辑视觉、遮罩等,以微调输出。
DreamMat是一款能够根据文本提示为3D网格生成物理基础渲染(PBR)材质的创新模型。它通过解决现有2D扩散模型在材质分解上的不足,生成与给定几何体和光照环境一致且无内置阴影效果的高质量PBR材质。这一技术对于游戏和电影制作等下游任务具有重要意义,因为它能显著提升渲染质量并增强用户的视觉体验。
Stylar AI的2D to 3D Image Converter是一个强大的图像转换工具,它利用先进的Image-to-Image技术,将平面2D图像转换为3D图像。这款工具提供高质量的图像转换和多种风格选项,能够满足用户对图像进行3D化的需求。产品的主要功能包括上传图片、选择3D效果、下载3D创作等。它还提供了多种3D风格,如3D卡通效果、3D艺术作品等,以及将草图转换为3D设计的功能。
美间AI创意商拍是一个专注于电商领域的在线设计平台,它通过人工智能技术,帮助用户快速生成电商所需的各种设计图,如主图、头图等。该平台的核心优势在于其高效的设计生成速度和丰富的模板资源,能够满足不同品类商品的设计需求,从而提升电商运营的效率和效果。
Boords是一个AI角色生成器,通过帮助用户创建一致、可识别的AI角色,并将它们放置在任何场景中,简化角色设计的过程。它提供了强大的角色编辑功能,用户可以轻松自定义角色的外貌和特征。Boords还支持快速生成具有不同服装和表情的角色变体,以满足各种场景需求。用户可以使用简单的图像序列创建有趣的故事板,并轻松构建引人注目的角色驱动故事。Boords已被世界顶级视频团队的65万名专业人士信赖,大大简化了他们的前期制作流程。
Interactive3D是一个先进的3D生成模型,它通过交互式设计为用户提供了精确的控制能力。该模型采用两阶段级联结构,利用不同的3D表示方法,允许用户在生成过程的任何中间步骤进行修改和引导。它的重要性在于能够实现用户对3D模型生成过程的精细控制,从而创造出满足特定需求的高质量3D模型。
百度文库推出的智能漫画创作工具,具有以下优势:1.一站式创作流程,从创意到成品无缝衔接。2.多种漫画风格可选,如韩系卡通、浪漫厚涂等。3.人物形象、表情、场景等描绘精细生动,媲美漫画家水准。4.内置智能编辑器,可对细节进行精修。5.无需专业绘画技能,有创意即可创作。6.目前处于公测阶段,可关注公众号预约体验。
StableDesign项目旨在为生成式室内设计提供数据集和训练方法。用户上传空房间图片和文字提示,生成装修效果图。通过爱彼迎数据下载、特征提取和ControlNet模型训练,结合图像处理和自然语言处理技术,提供新思路和方法。
Adobe Express GPT是Adobe为ChatGPT Plus用户提供的定制GPT,可以根据用户的文字提示快速匹配Adobe Express的20多万个专业设计模板,并将匹配结果直接导入Adobe Express进行进一步编辑和发布。插件还集成了Adobe Firefly等生成式AI功能,如文本到图像、对象移除等,帮助用户轻松创建出色的视觉内容。Adobe致力于负责任地开发AI技术,Firefly模型使用授权内容训练,可安全用于商业用途。
GRM是一种大规模的重建模型,能够在0.1秒内从稀疏视图图像中恢复3D资产,并且在8秒内实现生成。它是一种前馈的基于Transformer的模型,能够高效地融合多视图信息将输入像素转换为像素对齐的高斯分布,这些高斯分布可以反投影成为表示场景的密集3D高斯分布集合。我们的Transformer架构和使用3D高斯分布的方式解锁了一种可扩展、高效的重建框架。大量实验结果证明了我们的方法在重建质量和效率方面优于其他替代方案。我们还展示了GRM在生成任务(如文本到3D和图像到3D)中的潜力,通过与现有的多视图扩散模型相结合。
Stable Video 3D是Stability AI推出的新模型,它在3D技术领域取得了显著进步,与之前发布的Stable Zero123相比,提供了大幅改进的质量和多视角支持。该模型能够在没有相机条件的情况下,基于单张图片输入生成轨道视频,并且能够沿着指定的相机路径创建3D视频。
DragAnything是一款利用实体表示实现任意物体运动控制的产品。与拖动像素的传统方式不同,DragAnything可以实现真正的实体级运动控制。它可以实现用户轨迹交互,并具有SAM功能。该产品可以精确控制物体的运动,生成高质量视频,用户只需在交互过程中绘制一条轨迹。DragAnything可实现对前景、背景和相机等不同元素的多样化运动控制。定位于设计领域,适用于需要对视频中物体进行精细控制的场景。产品定价未公开。
3D AI Studio 是一款基于人工智能技术的在线工具,可以轻松生成定制的 3D 模型。适用于设计师、开发者和创意人士,提供高质量的数字资产。用户可以通过AI生成器快速创建3D模型,并以FBX、GLB或USDZ格式导出。3D AI Studio具有高性能、用户友好的界面、自动生成真实纹理等特点,可大幅缩短建模时间和降低成本。
Leonardo.Ai Realtime Canvas是一个实时智能绘图工具。它使用AI技术,可以即时将简单草图转换为高质量图像,极大地提升了设计师的创作效率。与传统设计流程相比,Leonardo.Ai允许设计师跳过手工绘制和后期处理的繁琐步骤,专注创意本身。关键功能包括:实时绘图转换、图像增强、智能扩充等。适用于平面设计、插画设计、UI设计等领域。
ComfyUI-Mana-Nodes是一套为ComfyUI设计的自定义节点,包括将字体转换为图像动画的功能。用户可以通过这些节点创建动态图像和视频效果。项目遵循MIT许可证,鼓励社区贡献和个性化定制。
ComfyUI-3D-Pack是一个强大的3D处理插件集合,它为ComfyUI提供了处理3D模型(网格、纹理等)的能力,集成了各种前沿3D重建和渲染算法,如3D高斯采样、NeRF不同iable渲染等,可以实现单视角图像快速重建3D高斯模型,并可转换为三角网格模型,同时还提供了交互式3D可视化界面。
Keyframer是一个由Apple研发的基于大语言模型的动画生成工具原型。它可以通过文本描述,自动为SVG图像添加动画效果并转换为CSS代码。用户无需编程经验,就可以简单上传图像、输入文本描述,Keyframer会自动生成代码。相比其他AI生成动画方案,Keyframer更简单易用。目前还处于原型阶段,公开可用性有待观察。
ComfyUI-3D-Pack是一个强大的3D处理节点插件包,它为ComfyUI提供了处理3D输入(网格、UV纹理等)的能力,使用了最前沿的算法,如3D高斯采样、神经辐射场等。这个项目可以让用户只用单张图片就可以快速生成3D高斯模型,并可以将高斯模型转换成网格,实现3D重建。它还支持多视图图像作为输入,允许在给定的3D网格上映射多视图渲染的纹理贴图。该插件包处于开发中,尚未正式发布到ComfyUI插件库,但已经支持诸如大型多视图高斯模型、三平面高斯变换器、3D高斯采样、深度网格三角剖分、3D文件加载保存等功能。它的目标是成为ComfyUI处理3D内容的强大工具。
Glif StyleHunter是一款Chrome浏览器扩展,你可以在网页上选择任意图像,并根据你的提示词生成各种风格的混合图像。只需右键点击图像并输入你的提示词,就能将该图像风格直接应用到你想要创造的新图像上,无论是模仿那个风格,还是将其与其他风格结合创造出全新的作品。这个扩展为用户提供了一个直观且灵活的方式,来探索和实验不同的视觉艺术风格,以及将这些风格应用于自己的创意项目中。
BlockFusion是一种基于扩散的模型,可以生成3D场景,并无缝地将新的块整合到场景中。它通过对随机裁剪自完整3D场景网格的3D块数据集进行训练。通过逐块拟合,所有训练块都被转换为混合神经场:其中包含几何特征的三面体,然后是用于解码有符号距离值的多层感知器(MLP)。变分自动编码器用于将三面体压缩到潜在的三面体空间,对其进行去噪扩散处理。扩散应用于潜在表示,可以实现高质量和多样化的3D场景生成。在生成过程中扩展场景时,只需附加空块以与当前场景重叠,并外推现有的潜在三面体以填充新块。外推是通过在去噪迭代过程中使用来自重叠三面体的特征样本来调节生成过程完成的。潜在三面体外推产生语义和几何上有意义的过渡,与现有场景和谐地融合。使用2D布局调节机制来控制场景元素的放置和排列。实验结果表明,BlockFusion能够生成多样化、几何一致且质量高的室内外大型3D场景。
StrokeNUWA是一项开创性的工作,探索了在矢量图形上更好的视觉表示“划分标记”,其视觉语义丰富,与LLMs自然兼容,并具有高度压缩性。配备划分标记,StrokeNUWA在矢量图形生成任务的各种指标上显著超越传统的LLM-based和基于优化的方法。此外,StrokeNUWA在推理速度上实现了高达94倍的加速,与先前方法相比具有卓越的SVG代码压缩比达6.9%。
Media2Face是一款通过音频、文本和图像多模态引导的共语言面部动画生成工具。它首先利用通用神经参数化面部资产(GNPFA)将面部几何和图像映射到高度通用的表情潜在空间,然后从大量视频中提取高质量的表情和准确的头部姿态,构建了M2F-D数据集。最后,采用GNPFA潜在空间中的扩散模型进行共语言面部动画生成。该工具不仅在面部动画合成方面具有高保真度,还拓展了表现力和样式适应性。
InternLM-XComposer2是一款领先的视觉语言模型,擅长自由形式文本图像合成与理解。该模型不仅能够理解传统的视觉语言,还能熟练地从各种输入中构建交织的文本图像内容,如轮廓、详细的文本规范和参考图像,实现高度可定制的内容创作。InternLM-XComposer2提出了一种部分LoRA(PLoRA)方法,专门将额外的LoRA参数应用于图像标记,以保留预训练语言知识的完整性,实现精确的视觉理解和具有文学才能的文本构成之间的平衡。实验结果表明,基于InternLM2-7B的InternLM-XComposer2在生成高质量长文本多模态内容方面优越,以及在各种基准测试中其出色的视觉语言理解性能,不仅明显优于现有的多模态模型,还在某些评估中与甚至超过GPT-4V和Gemini Pro。这凸显了它在多模态理解领域的卓越能力。InternLM-XComposer2系列模型具有7B参数,可在https://github.com/InternLM/InternLM-XComposer 上公开获取。
Comfy Textures是一个Unreal Engine插件,它将编辑器与ComfyUI集成,允许您使用生成式扩散模型快速创建和调整场景的纹理。支持单视点和多视点纹理投影,可以用于透视和正交摄像机。还支持纹理编辑和图像到图像工作流。可以无缝工作于Unreal Engine 5.x和4.x。
CreativeSynth是一款创新的统一框架,基于扩散模型,具有协调多模态输入和多任务处理的能力。通过将多模态特征与定制的注意力机制相结合,CreativeSynth实现了将现实语义内容导入艺术领域,通过反演和实时风格转换精确操纵图像风格和内容,同时保持原始模型参数的完整性。严格的定性和定量评估凸显了CreativeSynth在增强艺术图像的保真度方面的优势,并保留了它们固有的美学本质。通过弥合生成模型与艺术精髓之间的鸿沟,CreativeSynth成为定制数字调色板。
3DTopia是一个两阶段的文本到3D生成模型。第一阶段使用扩散模型快速生成候选项。第二阶段优化第一阶段选择的资产。该模型可以在5分钟内实现高质量的文本到3D生成。
Davinci Pencil是专为iPad量身定制的绘画应用。借助人工智能的帮助,您可以释放绘画技能的潜能,将您最疯狂的想法和幻想变成美丽的画作。我们简单易用的界面简化了您的绘画体验,让您在几秒钟内想象、绘画和涂鸦。我们经常更新数据库,不断为您带来新鲜的美学。主要功能包括:AI渲染功能,细节配置,在渲染图像上绘制叠加,绘制对比,查看所有绘画图像,创建多个页面,选择自定义尺寸。使用Davinci Pencil增强您的绘画,将您的想象力变成画作!
Make-A-Shape是一个新的3D生成模型,旨在以高效的方式训练大规模数据,能够利用1000万个公开可用的形状。我们创新性地引入了小波树表示法,通过制定子带系数滤波方案来紧凑地编码形状,然后通过设计子带系数打包方案将表示布置在低分辨率网格中,使其可生成扩散模型。此外,我们还提出了子带自适应训练策略,使我们的模型能够有效地学习生成粗细小波系数。最后,我们将我们的框架扩展为受额外输入条件控制,以使其能够从各种模态生成形状,例如单/多视图图像、点云和低分辨率体素。在大量实验中,我们展示了无条件生成、形状完成和条件生成等各种应用。我们的方法不仅在提供高质量结果方面超越了现有技术水平,而且在几秒内高效生成形状,通常在大多数条件下仅需2秒钟。
RPG-DiffusionMaster是一个全新的无需训练的文本到图像生成/编辑框架,利用多模态LLM的链式推理能力增强文本到图像扩散模型的组合性。该框架采用MLLM作为全局规划器,将复杂图像生成过程分解为多个子区域内的简单生成任务。同时提出了互补的区域扩散以实现区域化的组合生成。此外,在提出的RPG框架中闭环地集成了文本引导的图像生成和编辑,从而增强了泛化能力。大量实验证明,RPG-DiffusionMaster在多类别对象组合和文本-图像语义对齐方面优于DALL-E 3和SDXL等最先进的文本到图像扩散模型。特别地,RPG框架与各种MLLM架构(例如MiniGPT-4)和扩散骨干(例如ControlNet)兼容性广泛。
AnimatableDreamer是一个从单眼视频中生成和重建可动画非刚体3D模型的框架。它能够生成不同类别的非刚体对象,同时遵循从视频中提取的对象运动。关键技术是提出的典范分数蒸馏方法,将生成维度从4D简化到3D,在视频中的不同帧进行降噪,同时在唯一的典范空间内进行蒸馏过程。这样可以保证时间一致的生成和不同姿态下的形态逼真性。借助可微分变形,AnimatableDreamer将3D生成器提升到4D,为非刚体3D模型的生成和重建提供了新视角。此外,与一致性扩散模型的归纳知识相结合,典范分数蒸馏可以从新视角对重建进行正则化,从而闭环增强生成过程。大量实验表明,该方法能够从单眼视频生成高灵活性的文本指导3D模型,同时重建性能优于典型的非刚体重建方法。
HexaGen3D是一种用于从文本提示生成高质量3D资产的创新方法。它利用大型预训练的2D扩散模型,通过微调预训练的文本到图像模型来联合预测6个正交投影和相应的潜在三面体,然后解码这些潜在值以生成纹理网格。HexaGen3D不需要每个样本的优化,可在7秒内从文本提示中推断出高质量且多样化的对象,相较于现有方法,提供了更好的质量与延迟权衡。此外,HexaGen3D对于新对象或组合具有很强的泛化能力。
InseRF是一种通过文本提示和2D边界框在NeRF重建的3D场景中生成新对象的方法。它能够从用户提供的文本描述和一个参考视点中的2D边界框中生成新的3D对象,并将其插入到场景中。该方法能够在不需要显式3D信息的情况下实现可控的、与3D一致的对象插入。通过在多个3D场景中进行试验,证明了InseRF方法相对于现有方法的有效性。
URHand是第一个能够在不同视角、姿势、光照和身份之间实现泛化的通用光照手模型。该模型可以使用手机拍摄的图像进行少拍摄个性化,并且可以在新的光照条件下实现逼真渲染。基于神经网络多视角手部图像的光照,我们构建了强大的通用光照先验。我们提出了一种神经渲染器,它采用了空间变化的线性照明模型,并以物理启发的阴影作为输入特征。通过移除非线性激活和偏差,我们的特定设计的照明模型明确保持了光传输的线性性。我们还引入了基于物理的模型和神经光照模型的联合学习,进一步提高了保真度和泛化性能。大量实验表明,我们的方法在质量和泛化能力方面都优于现有方法。我们还展示了如何从手机对未曾见过的身份进行快速个性化。
Make-A-Character(Mach)是一个用户友好的框架,旨在从文本描述中创建栩栩如生的3D头像。该框架利用大型语言和视觉模型的力量进行文本意图理解和中间图像生成,然后经过一系列面向人的视觉感知和3D生成模块。我们的系统提供了一种直观的方法,让用户在2分钟内打造可控、逼真、完全实现的3D角色,同时还能轻松与现有的CG流水线进行集成,实现动态表现。
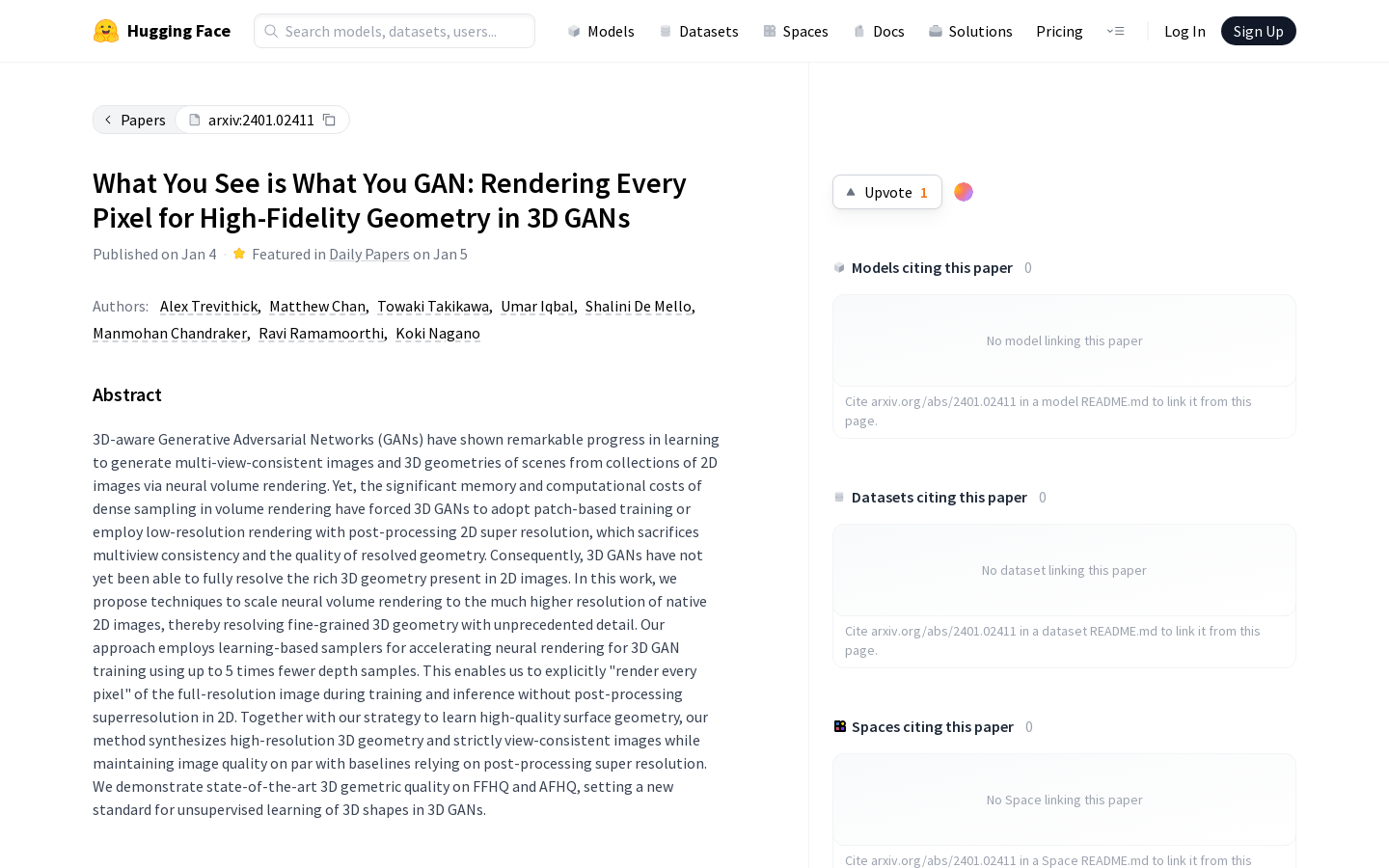
这款产品是一种3D GAN技术,通过学习基于神经体积渲染的方法,能够以前所未有的细节解析细粒度的3D几何。产品采用学习型采样器,加速3D GAN训练,使用更少的深度采样,实现在训练和推断过程中直接渲染完整分辨率图像的每个像素,同时学习高质量的表面几何,合成高分辨率3D几何和严格视角一致的图像。产品在FFHQ和AFHQ上展示了最先进的3D几何质量,为3D GAN中的无监督学习建立了新的标准。
Steerable Motion是一个用于批量创意插值的ComfyUI节点。我们的目标是展示在图像作为视频模型演变时,如何以最佳方式驱动运动。
艺术二维码是一款利用AI绘画技术生成艺术风格的二维码的工具。用户可以通过上传自己的二维码图片,选择不同的艺术风格,生成独特的艺术二维码。艺术二维码可以用于个人博客、社交媒体、名片等场景,帮助用户提升品牌形象。
锦书是一个创新艺术字生成工具,提供丰富的艺术字体样式和效果,用户可以快速生成个性化的艺术字作品。该工具定位于为用户提供便捷、高效的艺术字生成服务,无需专业设计技能即可制作出精美的艺术字作品。
SceneWiz3D是一种新颖的方法,可以从文本中合成高保真的3D场景。它采用混合的3D表示,对对象采用显式表示,对场景采用隐式表示。用户可以通过传统的文本到3D方法或自行提供对象来生成对象。为了配置场景布局并自动放置对象,我们在优化过程中应用了粒子群优化技术。此外,在文本到场景的情况下,对于场景的某些部分(例如角落、遮挡),很难获得多视角监督,导致几何形状劣质。为了缓解这种监督缺失,我们引入了RGBD全景扩散模型作为额外先验,从而实现了高质量的几何形状。广泛的评估支持我们的方法实现了比以前的方法更高的质量,可以生成详细且视角一致的3D场景。
roomGPT是一个可以上传房间照片,使用AI技术生成理想房间效果的在线服务。用户只需上传现有房间的照片,系统就可以生成不同风格的房间设计效果,供用户选择喜欢的风格。该服务使用了控制网(ControlNet)机器学习模型,可以生成房间的不同变体。roomGPT免费开源版本可以本地部署使用,也提供了付费的SaaS服务。
Stable Zero123是一种用于视图条件图像生成的内部训练模型。与之前的尖端技术Zero123-XL相比,Stable Zero123产生了显着改进的结果。它通过三项关键创新实现了这一目标:1. 从Objaverse中大幅过滤的改进训练数据集,仅保留高质量的3D对象,并且比以前的方法更加真实地渲染。2. 在训练和推断过程中,我们为模型提供了估计的摄像机角度。这种高程条件使其能够做出更明智、更高质量的预测。3. 预先计算的数据集(预先计算的潜变量)和支持更高批处理量的改进数据加载器,再加上第一项创新,使得训练效率比Zero123-XL提高了40倍。该模型现在已经在Hugging Face上发布,以便研究人员和非商业用户下载和进行实验。
GPT Chart Maker是基于ChatGPT的人工智能图表生成工具,能够在几秒钟内创建出令人印象深刻的图表和图形,轻松获得专业的信息图表。
3D高斯泼溅技术资源集合,涵盖生态系统与工具、研究论文、Unity高斯散射项目等内容。该技术在3D编辑、实时点云重照明、逆渲染、数据压缩、防锯齿等领域有广泛应用,对于对3D高斯泼溅技术感兴趣的人群具有很高的参考价值。
Generative Powers of Ten是一种利用文本到图像模型生成多尺度一致内容的方法,能够实现对场景的极端语义缩放,例如从森林的广角景观视图到树枝上昆虫的微距拍摄。这种表示方式使我们能够渲染连续缩放视频,或者交互式地探索场景的不同尺度。我们通过一种联合多尺度扩散采样方法实现这一点,该方法鼓励在不同尺度之间保持一致性,同时保留每个单独采样过程的完整性。由于每个生成的尺度都由不同的文本提示指导,我们的方法能够实现比传统的超分辨率方法更深层次的缩放,后者可能难以在完全不同的尺度上创建新的上下文结构。我们在图像超分辨率和外部绘制的替代技术上对我们的方法进行了定性比较,并表明我们的方法在生成一致的多尺度内容方面最为有效。
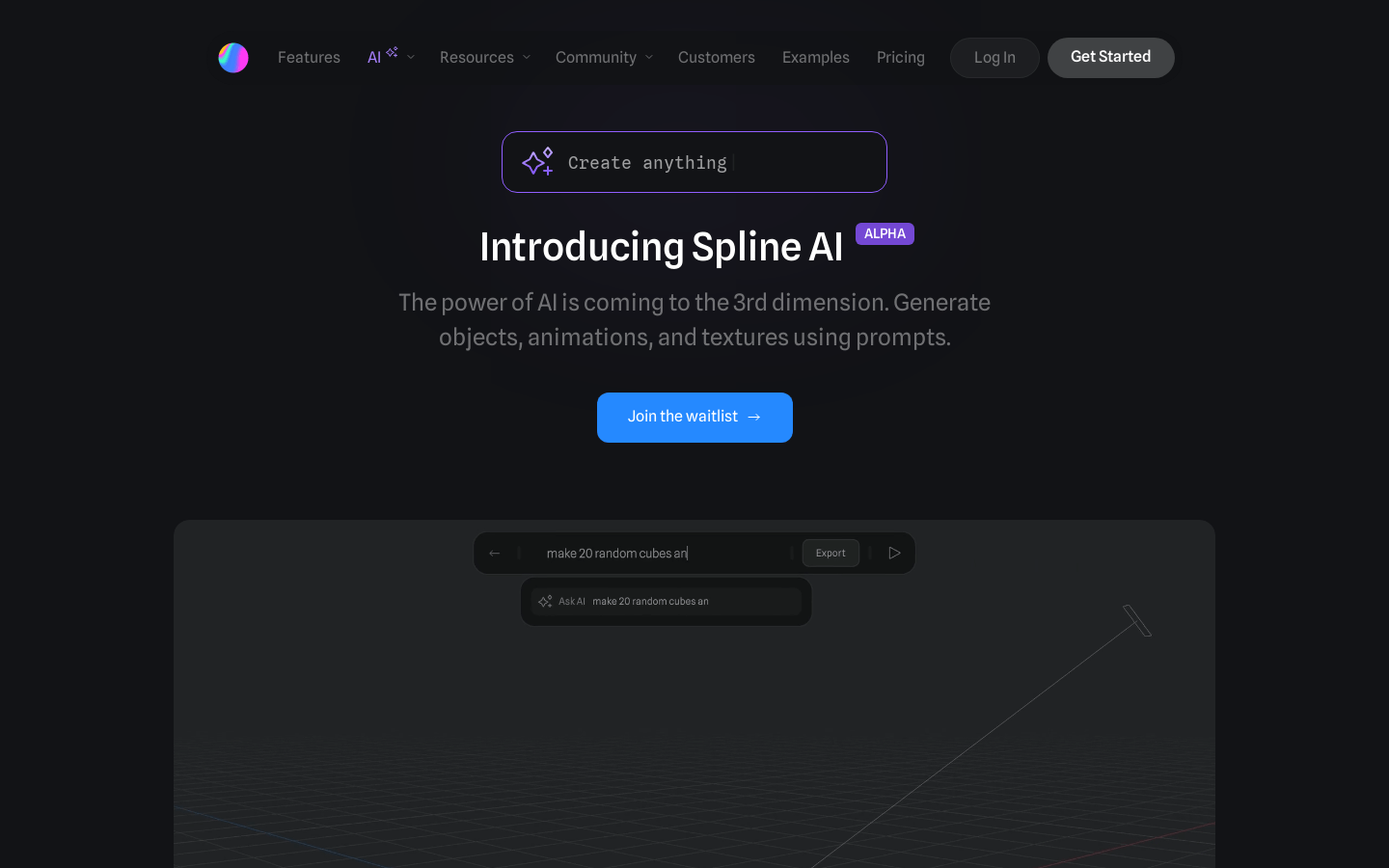
Spline AI是一款通过AI快速生成3D对象、动画和纹理的工具。使用简单的提示,设计师可以更快地将创意变为现实。产品功能包括:生成3D对象和场景、编辑对象、应用材质、添加光照、生成无缝纹理等。Spline AI还提供AI纹理功能,可以根据文本提示生成无缝纹理。该产品适用于设计师、艺术家和创意团队。
MeshGPT通过自回归地从经过训练以生成来自学习几何词汇的标记的变压器模型中采样来创建三角网格。这些标记然后可以被解码成三角网格的面。我们的方法生成干净、连贯和紧凑的网格,具有清晰的边缘和高保真度。MeshGPT在形状覆盖率上表现比现有的网格生成方法有显著改进,各种类别的FID得分提高了30个点。
4D-fy是一种文本到4D生成方法,通过混合分数蒸馏采样技术,结合了多种预训练扩散模型的监督信号,实现了高保真的文本到4D场景生成。其方法通过神经表示参数化4D辐射场,使用静态和动态多尺度哈希表特征,并利用体积渲染从表示中渲染图像和视频。通过混合分数蒸馏采样,首先使用3D感知文本到图像模型(3D-T2I)的梯度来优化表示,然后结合文本到图像模型(T2I)的梯度来改善外观,最后结合文本到视频模型(T2V)的梯度来增加场景的运动。4D-fy可以生成具有引人入胜外观、3D结构和运动的4D场景。
3D Paintbrus是一种通过文本描述自动为网格上的局部语义区域添加纹理的技术。该方法直接操作于网格上,生成无缝集成到标准图形流水线中的纹理贴图。同时产生指定编辑区域的本地化贴图和与之相适配的纹理贴图。我们利用级联扩散模型的多个阶段来监督局部编辑技术,从而增强纹理区域的细节和分辨率。该技术被称为级联分数蒸馏(CSD),能够同时以级联方式蒸馏多个分辨率的分数,实现对监督的粒度和全局理解的控制。我们展示了3D画笔在局部为不同语义区域内的各种形状添加纹理的有效性。
LiveSketch是一种将动画效果添加到手绘草图的工具。它可以根据文本提示自动生成矢量动画,让草图栩栩如生。该工具不需要复杂的训练,通过预训练的文本到视频模型来指导笔触的运动。它适用于设计师、动画师等需要给草图添加动画效果的用户。动画绘画可以在网站上使用。
draw-fast是一个快速绘图工具,使用TypeScript、CSS和JavaScript开发。它提供了快速绘图的功能,具有简洁易用的优势。定位于为用户提供快速绘图的解决方案。
ZipLoRA是一种有效合并独立训练的风格和主题LoRAs的方法,以实现在任何用户提供的主题和风格下生成内容。通过优化的方法,ZipLoRA能够保留原始LoRAs的内容和风格生成特性,同时能够重新上下文化参考对象,并具有控制风格程度的能力。该方法在主题和风格的保真度上取得了显著的改进。
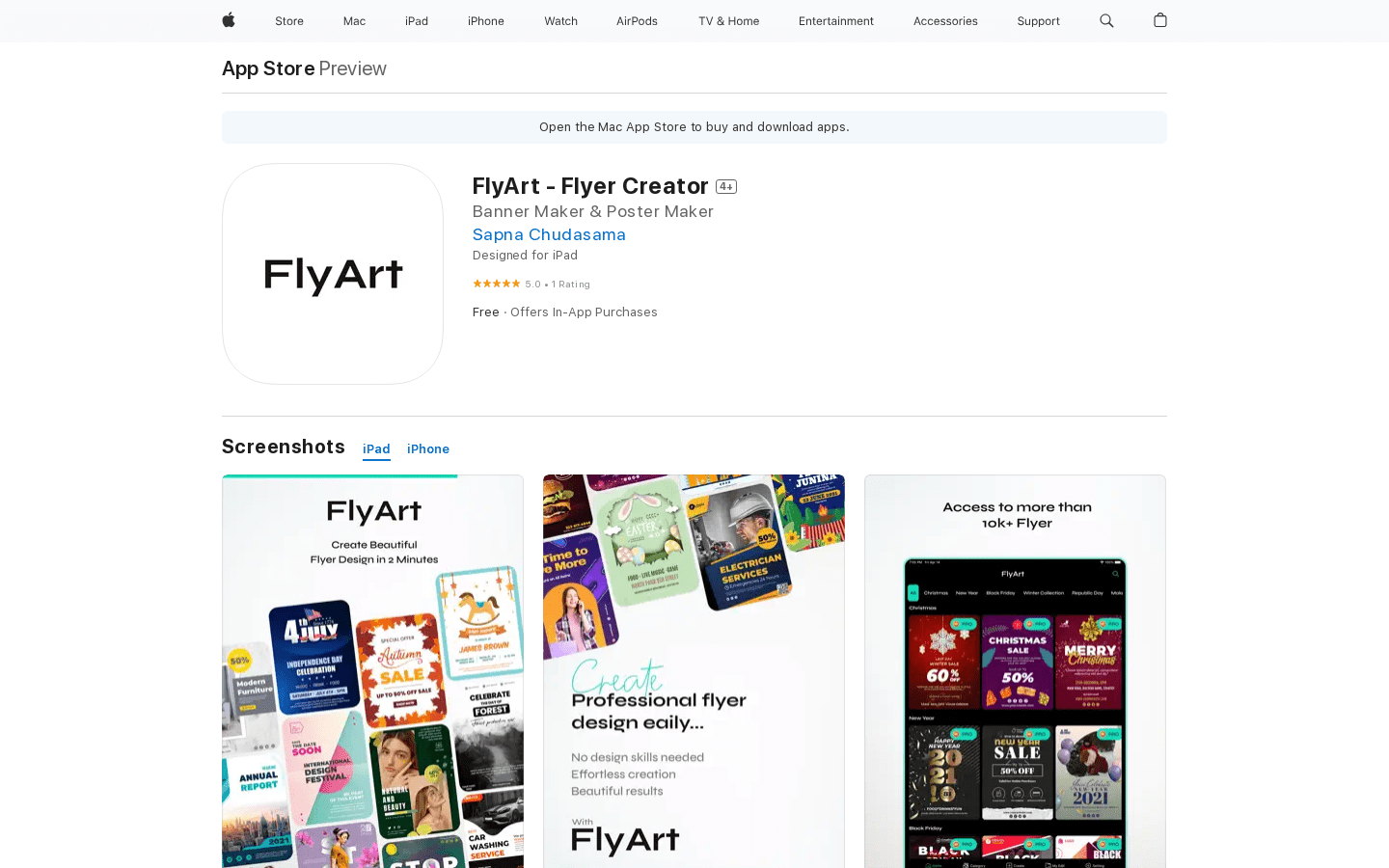
FlyArt 是一款终极图形设计应用,可轻松创建个性化宣传单。我们提供各种现成的宣传单模板,您可以根据需要进行定制。通过 FlyArt,您可以选择合适的设计并自定义它们,添加背景图片、贴纸、商标、字体和品牌颜色。FlyArt 帮助您的业务在社交媒体上脱颖而出,提供快速增长。
WxArt Ai是一款专业的绘画软件,拥有强大的AI引擎,为用户提供一系列创新功能。利用先进的AI内容生成技术,WxArt Ai可以创建各种图片,包括基于文本的艺术和基于图像的艺术。无论您是寻找墨水风格、多彩动漫、逼真风格还是二维作品,WxArt Ai都可以满足您的多样需求。
创新艺术字是一款能够通过自定义的概念,对文字进行变形和纹理生成的工具。用户可以通过该工具构建富有创意的个性化字形和纹理。该工具具有简单易用的界面和丰富多样的字体和纹理选项,可以满足用户在设计中对文字表现形式的需求。创新艺术字定位于为设计师、艺术家等提供创意灵感和设计元素。
AI Stickers是一项将您的文本转化为生动个性化贴纸的服务。告别单调的消息,用AI生成的贴纸在WhatsApp、Telegram等平台上表达自己。释放创造力,让对话变得生动有趣。
Genie 是 Luma 的 3D 生成基础模型的研究预览版。它可以生成各种三维模型,用于设计、创作和娱乐等领域。Genie 提供了丰富的功能,包括形状生成、纹理绘制、动画创建等。它可以应用于游戏开发、虚拟现实、电影特效等多个领域。Genie 的定价和定位将在正式发布前确定。
探索 设计 分类下的其他子分类
753 个工具
302 个工具
237 个工具
96 个工具
93 个工具
61 个工具
57 个工具
37 个工具
AI图像生成 是 设计 分类下的热门子分类,包含 127 个优质AI工具