共找到 100 个AI工具
点击任意工具查看详细信息
Hallo2是一种基于潜在扩散生成模型的人像图像动画技术,通过音频驱动生成高分辨率、长时的视频。它通过引入多项设计改进,扩展了Hallo的功能,包括生成长时视频、4K分辨率视频,并增加了通过文本提示增强表情控制的能力。Hallo2的主要优点包括高分辨率输出、长时间的稳定性以及通过文本提示增强的控制性,这使得它在生成丰富多样的肖像动画内容方面具有显著优势。
Flux AI是一个利用先进AI算法来生成高质量图像的平台。它通过深度学习模型,能够在几秒钟内将用户的想法转化为视觉杰作。该平台提供实时生成、自定义输出、多语言支持、伦理AI和无缝集成等特点,旨在帮助用户快速实现创意,提高工作效率。Flux AI的背景信息显示,它致力于负责任的AI开发,尊重版权,避免偏见,并促进积极的社会影响。
ComfyGen 是一个专注于文本到图像生成的自适应工作流系统,它通过学习用户提示来自动化并定制有效的工作流。这项技术的出现,标志着从使用单一模型到结合多个专业组件的复杂工作流的转变,旨在提高图像生成的质量。ComfyGen 背后的主要优点是能够根据用户的文本提示自动调整工作流,以生成更高质量的图像,这对于需要生成特定风格或主题图像的用户来说非常重要。
AnimeGen是一个利用先进AI模型将文本提示转化为动漫风格图片的在线工具。它通过复杂的算法和机器学习技术,为用户提供了一种简单快捷的方式来生成高质量的动漫图片,非常适合艺术家、内容创作者和动漫爱好者探索新的创作可能性。AnimeGen支持80多种语言,生成的图片公开显示并可被搜索引擎抓取,是一个多功能的创意工具。
AnyPhoto.co是一个利用人工智能技术提供图片风格化和艺术效果的在线平台。它通过LoRA(低秩适应)技术,实现了高效模型适应性、精细风格控制、快速处理速度和卓越图像质量。用户可以上传自己的肖像照片,轻松转换成手绘素描,并尝试多种独特的绘画风格,创造独一无二的艺术作品。平台界面友好,支持个性化调整,提供高完成度的输出,非常适合需要快速、高质量图像处理的用户。
ComfyUI-Fluxtapoz是一个为Flux在ComfyUI中编辑图像而设计的节点集合。它允许用户通过一系列节点操作来对图像进行编辑和风格转换,特别适用于需要进行图像处理和创意工作的专业人士。这个项目目前是开源的,遵循GPL-3.0许可协议,意味着用户可以自由地使用、修改和分发该软件,但需要遵守开源许可的相关规定。
Toy Box Flux是一个基于AI生成图像训练的3D渲染模型,它结合了现有的3D LoRA模型和Coloring Book Flux LoRA的权重,形成了独特的风格。该模型特别适合生成具有特定风格的玩具设计图像。它在物体和人物主体上表现最佳,动物的表现则因训练图像中的数据不足而不稳定。此外,该模型还能提高室内3D渲染的真实感。计划在v2版本中通过混合更多生成的输出和预先存在的输出来加强这种风格的一致性。
DisEnvisioner是一种先进的图像生成技术,它通过分离和增强主题特征来生成定制化的图像,无需繁琐的调整或依赖多张参考图片。该技术有效地区分并增强了主题特征,同时过滤掉了不相关的属性,实现了在编辑性和身份保持方面的卓越个性化质量。DisEnvisioner的研究背景基于当前图像生成领域对于从视觉提示中提取主题特征的需求,它通过创新的方法解决了现有技术在这一领域的挑战。
Animate-X是一个基于LDM的通用动画框架,用于各种角色类型(统称为X),包括人物拟态角色。该框架通过引入姿势指示器来增强运动表示,可以更全面地从驱动视频中捕获运动模式。Animate-X的主要优点包括对运动的深入建模,能够理解驱动视频的运动模式,并将其灵活地应用到目标角色上。此外,Animate-X还引入了一个新的Animated Anthropomorphic Benchmark (A2Bench) 来评估其在通用和广泛适用的动画图像上的性能。
RealAnime - Detailed V1 是一个基于Stable Diffusion的LoRA模型,专门用于生成逼真的动漫风格图像。该模型通过深度学习技术,能够理解并生成高质量的动漫人物图像,满足动漫爱好者和专业插画师的需求。它的重要性在于能够大幅度提高动漫风格图像的生成效率和质量,为动漫产业提供强大的技术支持。目前,该模型在Tensor.Art平台上提供,用户可以通过在线方式使用,无需下载安装,方便快捷。价格方面,用户可以通过购买Buffet计划来解锁下载权益,享受更灵活的使用方式。
FacePoke是一款人工智能驱动的实时头部和面部变换工具,它允许用户通过直观的拖放界面操纵面部特征,为肖像注入生命力,实现逼真的动画和表情。FacePoke利用先进的AI技术,确保所有编辑都保持自然和逼真的外观,同时自动调整周围的面部区域,保持图像的整体完整性。这款工具以其用户友好的界面、实时编辑功能和先进的AI驱动调整而脱颖而出,适合各种技能水平的用户,无论是专业内容创作者还是初学者。
Meissonic是一个非自回归的掩码图像建模文本到图像合成模型,能够生成高分辨率的图像。它被设计为可以在消费级显卡上运行。这项技术的重要性在于其能够利用现有的硬件资源,为用户带来高质量的图像生成体验,同时保持了较高的运行效率。Meissonic的背景信息包括其在arXiv上发表的论文,以及在Hugging Face上的模型和代码。
由清华大学团队开发的文本到图像生成模型,开源,在图像生成领域有广泛应用前景,有高分辨率输出等优点。
Flux Ghibsky Illustration 是一个基于文本生成图像的模型,它结合了宫崎骏动画工作室的奇幻细节和新海诚作品中的宁静天空,创造出迷人的场景。该模型特别适合创造梦幻般的视觉效果,用户可以通过特定的触发词来生成具有独特审美的图像。它是基于Hugging Face平台的开源项目,允许用户下载模型并在Replicate上运行。
Easy Anime Maker是一个基于人工智能的动漫生成器,它使用深度学习技术,如生成对抗网络,将用户输入的文本描述或上传的照片转换成动漫风格的艺术作品。这项技术的重要性在于它降低了创作动漫艺术的门槛,使得没有专业绘画技能的用户也能创造出个性化的动漫图像。产品背景信息显示,它是一个在线平台,用户可以通过简单的文本提示或上传照片来生成动漫艺术,非常适合动漫爱好者和需要快速生成动漫风格图像的专业人士。产品提供免费试用,用户注册后可以获得5个免费积分,如果需要更多生成需求,可以选择购买积分,无需订阅。
Image Describer图像描述生成器是一款利用人工智能技术,通过上传图像并根据用户需求输出图像描述的工具。它能够理解图像内容,并生成详细的描述或解释,帮助用户更好地理解图片含义。这款工具不仅适用于普通用户,还能辅助视障人士通过文本转语音功能了解图片内容。图像描述生成器的重要性在于它能够提升图像内容的可访问性,增强信息的传播效率。
FLUX.1-dev-Controlnet-Inpainting-Beta是由阿里妈妈创意团队开发的一个图像修复模型,该模型在图像修复领域具有显著的改进,支持1024x1024分辨率的直接处理和生成,无需额外的放大步骤,提供更高质量和更详细的输出结果。模型经过微调,能够捕捉和再现修复区域的更多细节,并通过增强的提示解释提供对生成内容的更精确控制。
FLUX.1-Turbo-Alpha是一个基于FLUX.1-dev模型的8步蒸馏Lora,由AlimamaCreative Team发布。该模型使用多头鉴别器来提高蒸馏质量,可以用于文本到图像(T2I)、修复控制网络等FLUX相关模型。推荐使用指导比例为3.5,Lora比例为1。该模型在1M开源和内部源图像上进行训练,采用对抗性训练提高质量,固定原始FLUX.1-dev变换器作为鉴别器主干,并在每层变换器上添加多头。
FLUX.1-dev-LoRA-One-Click-Creative-Template 是一个基于 LoRA 训练的图像生成模型,由 Shakker-Labs 提供。该模型专注于创意照片生成,能够将用户的文本提示转化为具有创意性的图像。模型使用了先进的文本到图像的生成技术,特别适合需要快速生成高质量图像的用户。它是基于 Hugging Face 平台,可以方便地进行部署和使用。模型的非商业使用是免费的,但商业使用需要遵守相应的许可协议。
Free AI Anime Generator是一个基于人工智能技术的在线平台,它允许用户通过简单的点击操作生成高质量的动漫风格图片。这个平台利用先进的AI算法,使得即使是非专业人士也能轻松创造出独特的艺术作品。它不仅为动漫爱好者提供了一个实现创意的平台,也为艺术家和设计师提供了一个探索新创意的工具。该平台完全免费,易于使用,是动漫艺术创作领域的一次创新。
Flux 1.1 Pro AI是一个基于人工智能的高级图像生成平台,它利用尖端的AI技术将用户的文本提示转化为高质量的视觉效果。该平台在图像生成速度上提高了6倍,图像质量显著改善,并增强了对提示的遵从性。Flux 1.1 Pro AI不仅适用于艺术家和设计师,还适用于内容创作者、营销人员等专业人士,帮助他们在各自的领域中实现视觉想法,提升创作效率和质量。
OneIMG是一个基于人工智能技术的在线图片生成工具,它通过用户输入的文本描述来生成相应的图片。这种技术的应用可以极大地提高设计师和创意工作者的工作效率,因为它可以快速地将创意转化为视觉图像。OneIMG的背景信息显示,它是一个创新的产品,旨在通过AI技术简化图片创作流程。目前,OneIMG提供免费试用,但具体的定价策略尚未明确。
Cooraft是一款利用人工智能技术将普通照片转化为艺术作品的应用程序。它能够将自拍和日常照片转化为具有创意和艺术性的动画和渲染图,提供从3D卡通到经典绘画等多种艺术风格。Cooraft不仅能够美化人像,还能将素描、绘画、线稿等多种输入转化为新的渲染图,实现从2D到3D的转变。此外,Cooraft还提供了订阅服务,用户可以通过订阅获得更多高级功能。
Momo XL是一个基于SDXL的动漫风格模型,经过微调,能够生成高质量、细节丰富、色彩鲜艳的动漫风格图像。它特别适合艺术家和动漫爱好者使用,并且支持基于标签的提示,确保输出结果的准确性和相关性。此外,Momo XL还兼容大多数LoRA模型,允许用户进行多样化的定制和风格转换。
ACE是一个基于扩散变换的全能创造者和编辑器,它能够通过统一的条件格式Long-context Condition Unit (LCU)输入,实现多种视觉生成任务的联合训练。ACE通过高效的数据收集方法解决了训练数据缺乏的问题,并通过多模态大型语言模型生成准确的文本指令。ACE在视觉生成领域具有显著的性能优势,可以轻松构建响应任何图像创建请求的聊天系统,避免了视觉代理通常采用的繁琐流程。
Viewly是一款强大的AI图片识别应用,它能够识别图片中的内容,并通过AI技术进行作诗和翻译成多国语言。它代表了当前人工智能在图像识别和语言处理领域的前沿技术,主要优点包括高识别准确率、多语言支持和创造性的AI作诗功能。Viewly的背景信息显示,它是一个持续更新的产品,致力于为用户提供更多创新功能。目前,产品是免费提供给用户的。
PixelHaha是一个AI艺术图像生成器,它允许用户通过文本提示(prompt)来创造各种风格的AI艺术作品。用户可以根据自己的灵感来描述想要的图像,然后由AI将这些描述转化为图像。这个产品的重要性在于它能够快速将创意转化为视觉作品,极大地降低了艺术创作的门槛,并且提供了一个独特的AI角色来与用户的灵魂伴侣相结合。
DressRecon是一个用于从单目视频重建时间一致的4D人体模型的方法,专注于处理非常宽松的服装或手持物体交互。该技术结合了通用的人体先验知识(从大规模训练数据中学习得到)和针对单个视频的特定“骨骼袋”变形(通过测试时优化进行拟合)。DressRecon通过学习一个神经隐式模型来分离身体与服装变形,作为单独的运动模型层。为了捕捉服装的微妙几何形状,它利用基于图像的先验知识,如人体姿势、表面法线和光流,在优化过程中进行调整。生成的神经场可以提取成时间一致的网格,或者进一步优化为显式的3D高斯,以提高渲染质量和实现交互式可视化。DressRecon在包含高度挑战性服装变形和物体交互的数据集上,提供了比以往技术更高的3D重建保真度。
DreamWaltz-G是一个创新的框架,用于从文本驱动生成3D头像和表达性的全身动画。它的核心是骨架引导的评分蒸馏和混合3D高斯头像表示。该框架通过整合3D人类模板的骨架控制到2D扩散模型中,提高了视角和人体姿势的一致性,从而生成高质量的头像,解决了多重面孔、额外肢体和模糊等问题。此外,混合3D高斯头像表示通过结合神经隐式场和参数化3D网格,实现了实时渲染、稳定的SDS优化和富有表现力的动画。DreamWaltz-G在生成和动画3D头像方面非常有效,无论是视觉质量还是动画表现力都超越了现有方法。此外,该框架还支持多种应用,包括人类视频重演和多主题场景组合。
PMRF(Posterior-Mean Rectified Flow,后验均值修正流)是一种新提出的图像恢复算法,旨在解决图像恢复任务中的失真-感知质量权衡问题。它通过结合后验均值和修正流的方式,提出了一种新颖的图像恢复框架,能够在降低图像失真同时保证图像的感知质量。
BlinkShot 是一个基于Together AI的实时AI图像生成器,它利用Flux技术在用户输入提示时毫秒级生成图像。该产品是100%免费且开源的,旨在为创意人士和开发者提供快速生成图像的能力,以支持他们的设计和创意工作。
Inverse Painting 是一种基于扩散模型的方法,能够从一幅目标画作生成绘画过程的时间流逝视频。该技术通过训练学习真实艺术家的绘画过程,能够处理多种艺术风格,并生成类似人类艺术家的绘画过程视频。它结合了文本和区域理解,定义了一组绘画指令,并使用新颖的扩散基础渲染器更新画布。该技术不仅能够处理训练中有限的丙烯画风格,还能为广泛的艺术风格和流派提供合理的结果。
HeadshotAI是一个利用人工智能技术生成逼真头像的平台,它使用先进的算法分析上传的照片,生成具有专业摄影效果的头像。这项技术的重要性在于,它让个人能够以更低的成本和更便捷的方式,获得高质量的头像,从而提升个人品牌和职业形象。HeadshotAI的主要优点包括无与伦比的真实感、轻松定制、快速生成、价格亲民以及无缝集成。
Depth Pro是一个用于单目深度估计的研究项目,它能够快速生成高精度的深度图。该模型利用多尺度视觉变换器进行密集预测,并结合真实与合成数据集进行训练,以实现高准确度和细节捕捉。它在标准GPU上生成2.25百万像素深度图仅需0.3秒,具有速度快、精度高的特点,对于机器视觉和增强现实等领域具有重要意义。
Minionverse是一个基于AI的创意工作流,它通过使用不同的节点和模型来生成图像。这个工作流的灵感来自于一个在线的glif应用,并且提供了一个视频教程来指导用户如何使用。它包含了多种自定义节点,能够进行文本替换、条件加载、图像保存等操作,非常适合需要进行图像生成和编辑的用户。
Flex3D是一个两阶段流程,能够从单张图片或文本提示生成高质量的3D资产。该技术代表了3D重建领域的最新进展,可以显著提高3D内容的生成效率和质量。Flex3D的开发得到了Meta的支持,并且团队成员在3D重建和计算机视觉领域有着深厚的背景。
Flux_小红书真实风格模型是一款专注于生成极度真实自然日常照片的AI模型。它利用最新的人工智能技术,通过深度学习算法,能够生成具有小红书真实感风格的照片。该模型特别适合需要在社交媒体上发布高质量、真实感照片的用户,以及进行艺术创作和设计工作的专业人士。模型提供了多种参数设置,以适应不同的使用场景和需求。
FLUX1.1 [pro] 是 Black Forest Labs 发布的最新图像生成模型,它在速度和图像质量上都有显著提升。该模型提供六倍于前代的速度,同时改善了图像质量、提示遵循度和多样性。FLUX1.1 [pro] 还提供了更高级的定制化选项,以及更优的性价比,适合需要高效、高质量图像生成的开发者和企业。
PuLID-Flux ComfyUI implementation 是一个基于ComfyUI的图像处理模型,它利用了PuLID技术和Flux模型来实现对图像的高级定制和处理。这个项目是cubiq/PuLID_ComfyUI的灵感来源,是一个原型,它使用了一些方便的模型技巧来处理编码器部分。开发者希望在更正式地重新实现之前测试模型的质量。为了获得更好的结果,推荐使用16位或8位的GGUF模型版本。
OpenFLUX.1是一个基于FLUX.1-schnell模型的微调版本,移除了蒸馏过程,使其可以进行微调,并且拥有开源、宽松的许可证Apache 2.0。该模型能够生成令人惊叹的图像,并且只需1-4步即可完成。它是一个尝试去除蒸馏过程,创建一个可以微调的开源许可模型。
Stable Video Portraits是一种创新的混合2D/3D生成方法,利用预训练的文本到图像模型(2D)和3D形态模型(3D)生成逼真的动态人脸视频。该技术通过人特定的微调,将一般2D稳定扩散模型提升到视频模型,通过提供时间序列的3D形态模型作为条件,并引入时间去噪过程,生成具有时间平滑性的人脸影像,可以编辑和变形为文本定义的名人形象,无需额外的测试时微调。该方法在定量和定性分析中均优于现有的单目头部化身方法。
Posterior-Mean Rectified Flow(PMRF)是一种新颖的图像恢复算法,它通过优化后验均值和矫正流模型来最小化均方误差(MSE),同时保证图像的逼真度。PMRF算法简单而高效,其理论基础是将后验均值预测(最小均方误差估计)优化到与真实图像分布相匹配。该算法在图像恢复任务中表现出色,能够处理噪声、模糊等多种退化问题,并且具有较好的感知质量。
PhysGen是一个创新的图像到视频生成方法,它能够将单张图片和输入条件(例如,对图片中物体施加的力和扭矩)转换成现实、物理上合理且时间上连贯的视频。该技术通过将基于模型的物理模拟与数据驱动的视频生成过程相结合,实现了在图像空间中的动态模拟。PhysGen的主要优点包括生成的视频在物理和外观上都显得逼真,并且可以精确控制,通过定量比较和全面的用户研究,展示了其在现有数据驱动的图像到视频生成工作中的优越性。
CogView3是一个基于级联扩散的文本到图像生成系统,使用中继扩散框架。该系统通过将高分辨率图像生成过程分解为多个阶段,并通过中继超分辨率过程,在低分辨率生成结果上添加高斯噪声,从而开始从这些带噪声的图像进行扩散过程。CogView3在生成图像方面超越了SDXL,具有更快的生成速度和更高的图像质量。
Revisit Anything 是一个视觉位置识别系统,通过图像片段检索技术,能够识别和匹配不同图像中的位置。它结合了SAM(Spatial Attention Module)和DINO(Distributed Knowledge Distillation)技术,提高了视觉识别的准确性和效率。该技术在机器人导航、自动驾驶等领域具有重要的应用价值。
GGHead是一种基于3D高斯散射表示的3D生成对抗网络(GAN),用于从2D图像集合中学习3D头部先验。该技术通过利用模板头部网格的UV空间的规则性,预测一组3D高斯属性,从而简化了预测过程。GGHead的主要优点包括高效率、高分辨率生成、全3D一致性,并且能够实现实时渲染。它通过一种新颖的总变差损失来提高生成的3D头部的几何保真度,确保邻近渲染像素来自UV空间中相近的高斯。
Omni-Zero-Couples是一个使用diffusers管道的零样本风格化情侣肖像创作模型。它利用深度学习技术,无需预先定义的风格样本,即可生成具有特定艺术风格的情侣肖像。这种技术在艺术创作、个性化礼物制作和数字娱乐领域具有广泛的应用前景。
Flux.1-dev Controlnet Upscaler 是一个基于Hugging Face平台的图像放大模型,它使用先进的深度学习技术来提高图像的分辨率,同时保持图像质量。该模型特别适合需要对图像进行无损放大的场景,如图像编辑、游戏开发、虚拟现实等。
HelloMeme是一个集成了空间编织注意力的扩散模型,旨在将高保真和丰富的条件嵌入到图像生成过程中。该技术通过提取驱动视频中的每一帧特征,并将其作为输入到HMControlModule,从而生成视频。通过进一步优化Animatediff模块,提高了生成视频的连续性和保真度。此外,HelloMeme还支持通过ARKit面部混合形状控制生成的面部表情,以及基于SD1.5的Lora或Checkpoint,实现了框架的热插拔适配器,不会影响T2I模型的泛化能力。
Cog inference for flux models 是一个用于FLUX.1 [schnell] 和 FLUX.1 [dev] 模型的推理引擎,由Black Forest Labs开发。它支持编译与量化,敏感内容检查,以及img2img支持,旨在提高图像生成模型的性能和安全性。
PortraitGen是一个基于多模态生成先验的2D肖像视频编辑工具,能够将2D肖像视频提升到4D高斯场,实现多模态肖像编辑。该技术通过追踪SMPL-X系数和使用神经高斯纹理机制,可以快速生成3D肖像并进行编辑。它还提出了一种迭代数据集更新策略和多模态人脸感知编辑模块,以提高表情质量和保持个性化面部结构。
这是一种通过利用从2D图像扩散模型提取的先验来创建可重新照明的辐射场的方法。该方法能够将单照明条件下捕获的多视图数据转换为具有多照明效果的数据集,并通过3D高斯splats表示可重新照明的辐射场。这种方法不依赖于精确的几何形状和表面法线,因此更适合处理具有复杂几何形状和反射BRDF的杂乱场景。
diffusion-e2e-ft是一个开源的图像条件扩散模型微调工具,它通过微调预训练的扩散模型来提高特定任务的性能。该工具支持多种模型和任务,如深度估计和法线估计,并提供了详细的使用说明和模型检查点。它在图像处理和计算机视觉领域具有重要应用,能够显著提升模型在特定任务上的准确性和效率。
MagicFace是一种无需训练即可实现个性化人像合成的技术,它能够根据给定的多个概念生成高保真度的人像图像。这项技术通过精确地将参考概念特征在像素级别集成到生成区域中,实现了多概念的个性化定制。MagicFace引入了粗到细的生成流程,包括语义布局构建和概念特征注入两个阶段,通过Reference-aware Self-Attention (RSA)和Region-grouped Blend Attention (RBA)机制实现。该技术不仅在人像合成和多概念人像定制方面表现出色,还可用于纹理转移,增强其多功能性和实用性。
StoryMaker是一个专注于文本到图像生成的AI模型,能够根据文本描述生成具有连贯性的角色和场景图像。它通过结合先进的图像生成技术和人脸编码技术,为用户提供了一个强大的工具,用于创作故事性强的视觉内容。该模型的主要优点包括高效的图像生成能力、对细节的精确控制以及对用户输入的高度响应。它在创意产业、广告和娱乐领域有着广泛的应用前景。
Diffusers Image Outpaint 是一个基于扩散模型的图像外延技术,它能够根据已有的图像内容,生成图像的额外部分。这项技术在图像编辑、游戏开发、虚拟现实等领域具有广泛的应用前景。它通过先进的机器学习算法,使得图像生成更加自然和逼真,为用户提供了一种创新的图像处理方式。
Open-MAGVIT2是由腾讯ARC实验室开源的一个自回归图像生成模型系列,包含从300M到1.5B不同规模的模型。该项目复现了Google的MAGVIT-v2分词器,实现了在ImageNet 256×256数据集上达到1.17 rFID的先进重建性能。通过引入不对称分词技术,将大词汇表分解为不同大小的子词汇表,并引入'下一个子标记预测'来增强子标记间的交互,以提高生成质量。所有模型和代码均已开源,旨在推动自回归视觉生成领域的创新和创造力。
OmniGen是一个创新的扩散框架,它将多种图像生成任务统一到单一模型中,无需特定任务的网络或微调。这一技术简化了图像生成流程,提高了效率,降低了开发和维护成本。
ViewCrafter 是一种新颖的方法,它利用视频扩散模型的生成能力以及基于点的表示提供的粗略3D线索,从单个或稀疏图像合成通用场景的高保真新视角。该方法通过迭代视图合成策略和相机轨迹规划算法,逐步扩展3D线索和新视角覆盖的区域,从而扩大新视角的生成范围。ViewCrafter 可以促进各种应用,例如通过优化3D-GS表示实现沉浸式体验和实时渲染,以及通过场景级文本到3D生成实现更富有想象力的内容创作。
FLUX.1-dev-LoRA-Dark-Fantasy是由Shakker AI的GUIZANG(歸藏)训练的LoRA模型,专注于生成幻想生物和角色。该模型受到Klee、Odilon Redon、Eyvind Earle等艺术家的影响,能够生成具有电影质感、复杂光影效果和精细细节的图像。模型遵循flux-1-dev-non-commercial-license,适用于非商业用途。
Dark fantasy FLUX是一个专注于生成幻想生物和角色的AI模型,擅长创造具有流体金属质感的服装和带有魔法或科技光效的图像。它能够生成具有暗色调氛围的图片,同时不影响对写实内容的响应。该模型由Black Forest Labs, Inc.授权,适用于非商业用途。
Pixtral-12b-240910是由Mistral AI团队发布的多模态大型语言模型,它能够处理和理解图像以及文本信息。该模型采用了先进的神经网络架构,能够通过图像和文本的结合输入,提供更加丰富和准确的输出结果。它在图像识别、自然语言处理和多模态交互方面展现出卓越的性能,对于需要图像和文本同时处理的应用场景具有重要意义。
LongLLaVA是一个多模态大型语言模型,通过混合架构高效扩展至1000图像,旨在提升图像处理和理解能力。该模型通过创新的架构设计,实现了在大规模图像数据上的有效学习和推理,对于图像识别、分类和分析等领域具有重要意义。
RECE是一种文本到图像扩散模型的概念擦除技术,它通过在模型训练过程中引入正则化项来实现对特定概念的可靠和高效擦除。这项技术对于提高图像生成模型的安全性和控制性具有重要意义,特别是在需要避免生成不适当内容的场景中。RECE技术的主要优点包括高效率、高可靠性和易于集成到现有模型中。
M&M VTO是一种混合搭配的虚拟试穿方法,它接受多张服装图片、服装布局的文本描述以及一个人的图片作为输入,输出是这些服装在指定布局下穿在给定人物身上的可视化效果。该技术的主要优点包括:单阶段扩散模型,无需超分辨率级联,能够在1024x512分辨率下混合搭配多件服装,同时保留和扭曲复杂的服装细节;架构设计(VTO UNet Diffusion Transformer)能够分离去噪和人物特定特征,实现高效的身份保留微调策略;通过文本输入控制多件服装的布局,专门针对虚拟试穿任务微调。M&M VTO在定性和定量方面都达到了最先进的性能,并为通过语言引导和多件服装试穿开辟了新的可能性。
FlexClip AI Image to Image Generator是一个在线的图像转换工具,它利用先进的AI技术将用户上传的图片转换成不同的艺术风格。该产品通过不断更新的AI模型,保证高质量的图像风格转换,适用于专业和个人使用。它还提供了丰富的AI功能,如AI文本到图像、AI文本到视频和AI背景移除器,以加速照片和视频的创作过程。
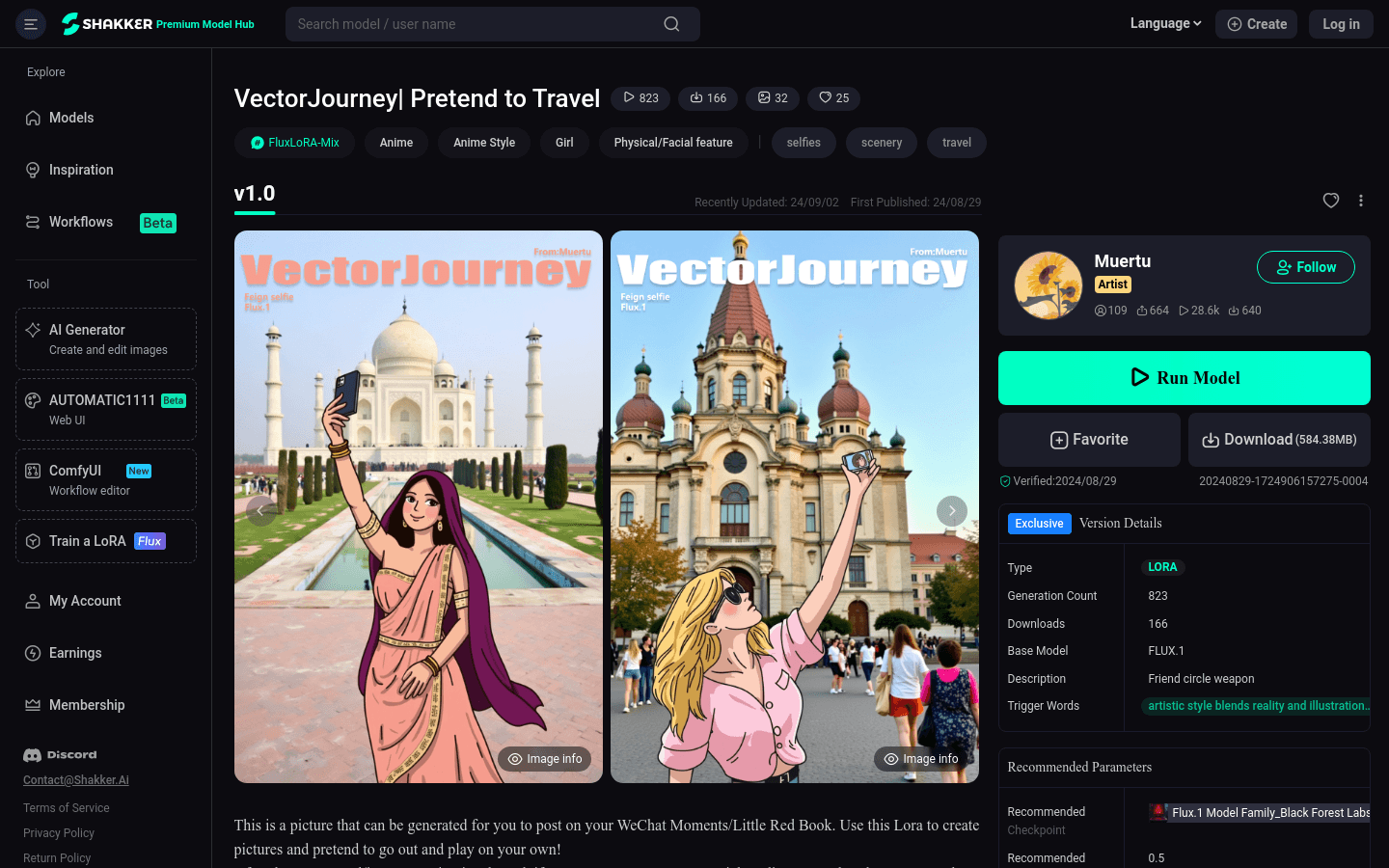
VectorJourney是一个利用AI技术生成旅行风格图片的模型,用户可以通过简单的文字描述生成具有旅行元素的卡通风格图片。该模型特别适合想要在社交媒体上分享旅行体验,但又不想露脸的用户。它通过融合现实与插画元素的艺术风格,提供了一种新颖的虚拟旅行体验。
OmniRe 是一种用于高效重建高保真动态城市场景的全面方法,它通过设备日志来实现。该技术通过构建基于高斯表示的动态神经场景图,以及构建多个局部规范空间来模拟包括车辆、行人和骑行者在内的各种动态行为者,从而实现了对场景中不同对象的全面重建。OmniRe 允许我们全面重建场景中存在的不同对象,并随后实现所有参与者实时参与的重建场景的模拟。在 Waymo 数据集上的广泛评估表明,OmniRe 在定量和定性方面都大幅超越了先前的最先进方法。
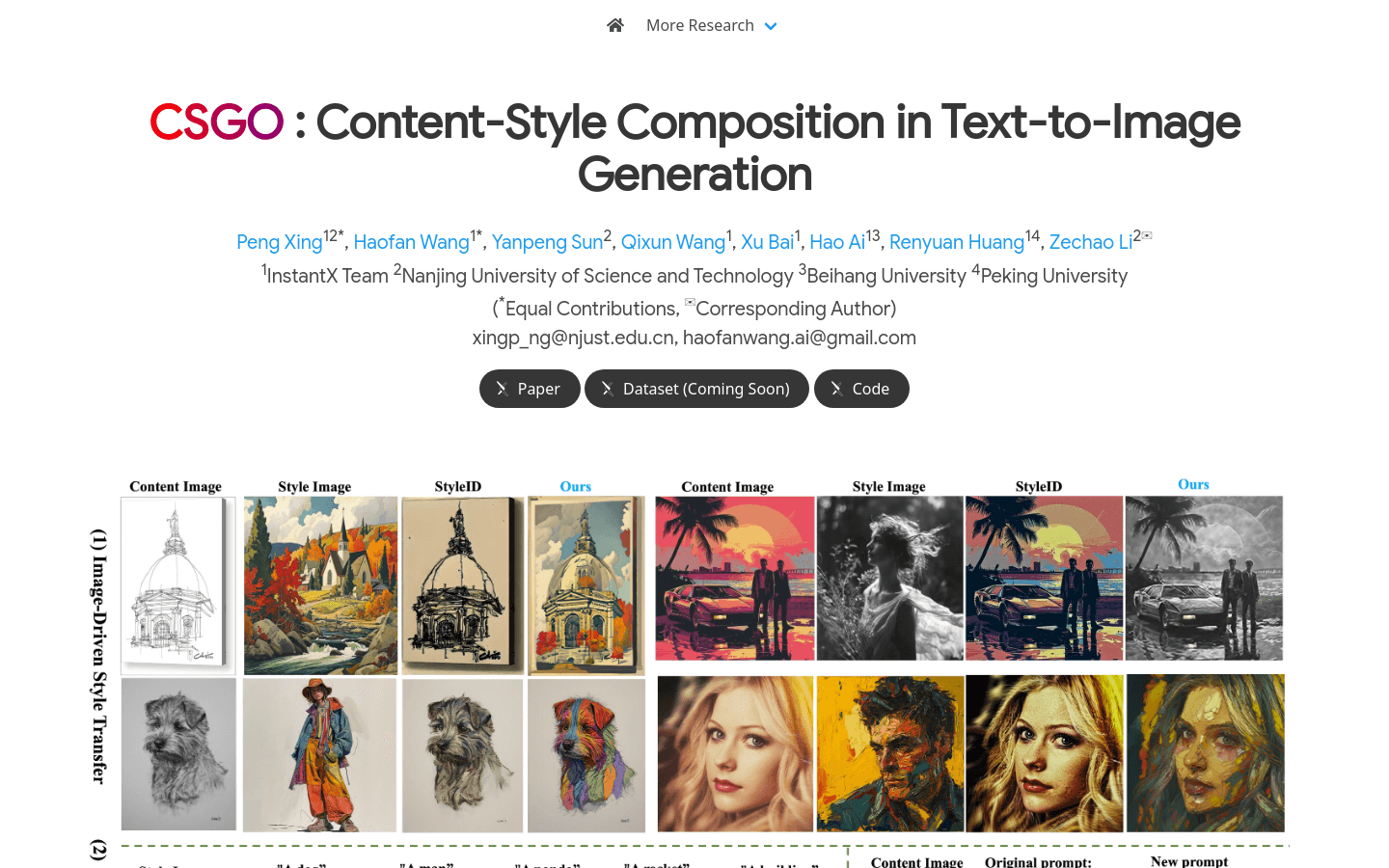
CSGO是一个基于内容风格合成的文本到图像生成模型,它通过一个数据构建管道生成并自动清洗风格化数据三元组,构建了首个大规模的风格迁移数据集IMAGStyle,包含210k图像三元组。CSGO模型采用端到端训练,明确解耦内容和风格特征,通过独立特征注入实现。它实现了图像驱动的风格迁移、文本驱动的风格合成以及文本编辑驱动的风格合成,具有无需微调即可推理、保持原始文本到图像模型的生成能力、统一风格迁移和风格合成等优点。
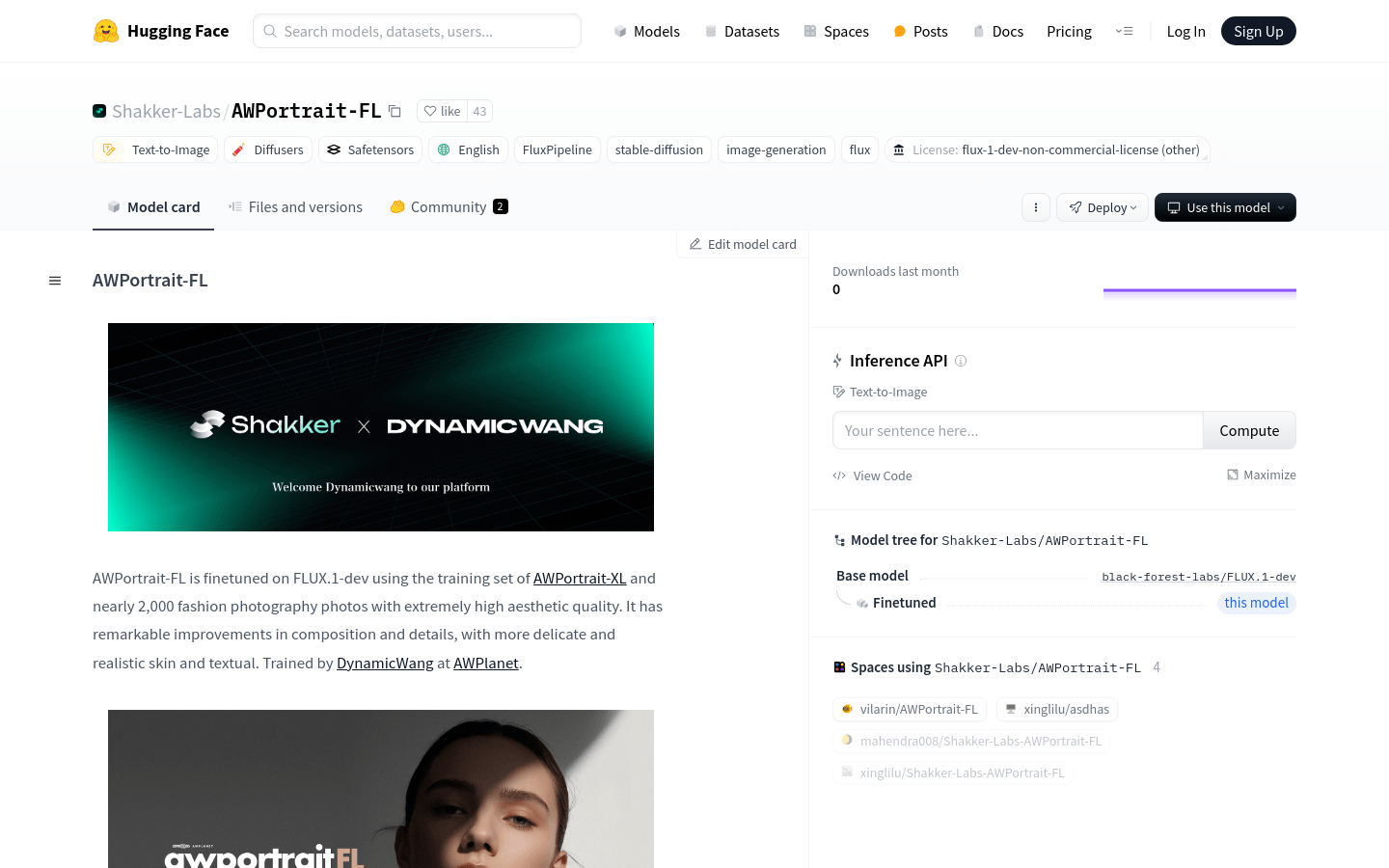
AWPortrait-FL是一个在FLUX.1-dev基础上进行微调的高级人像生成模型,使用了AWPortrait-XL训练集和近2000张高质量时尚摄影照片进行训练。该模型在构图和细节上有着显著的提升,能够生成皮肤和纹理更加细腻、逼真的人像。由DynamicWang在AWPlanet上训练完成。
FLUX.1-dev-LoRA-blended-realistic-illustration是一个基于LoRA技术的AI图像生成模型,由Muertu训练,专注于将卡通风格的人物与现实背景相结合,创造出独特的混合现实艺术效果。该模型在图像生成领域具有创新性,能够为艺术家和设计师提供新的创作工具,同时为图像处理和艺术创作提供新的视角。模型遵循flux-1-dev-non-commercial-license,适用于非商业用途。
Dark Gray Photography 深灰极简是一个专注于生成深灰色调和东亚女性形象的图像生成模型。该模型基于LoRA技术,通过深度学习训练,能够生成风格一致、色彩鲜明的图像。它特别适合需要在人像、产品、建筑和自然风景摄影中使用深灰色调的用户。
HivisionIDPhotos是一个轻量级的AI证件照制作工具,它利用先进的图像处理算法,能够智能识别和抠图,生成符合多种规格的证件照。该工具的开发背景是为了解决用户在不同场合下对证件照需求的快速响应,通过自动化的图像处理技术,提高证件照制作的效率和质量。产品的主要优点包括轻量级、高效率、易用性以及支持多种证件照规格。
GenWarp是一个用于从单张图像生成新视角图像的模型,它通过语义保持的生成变形框架,使文本到图像的生成模型能够学习在哪里变形和在哪里生成。该模型通过增强交叉视角注意力与自注意力来解决现有方法的局限性,通过条件化生成模型在源视图图像上,并纳入几何变形信号,提高了在不同领域场景下的性能。
Qwen2-VL是一款基于Qwen2打造的最新一代视觉语言模型,具备多语言支持和强大的视觉理解能力,能够处理不同分辨率和长宽比的图片,理解长视频,并可集成到手机、机器人等设备中进行自动操作。它在多个视觉理解基准测试中取得全球领先的表现,尤其在文档理解方面有明显优势。
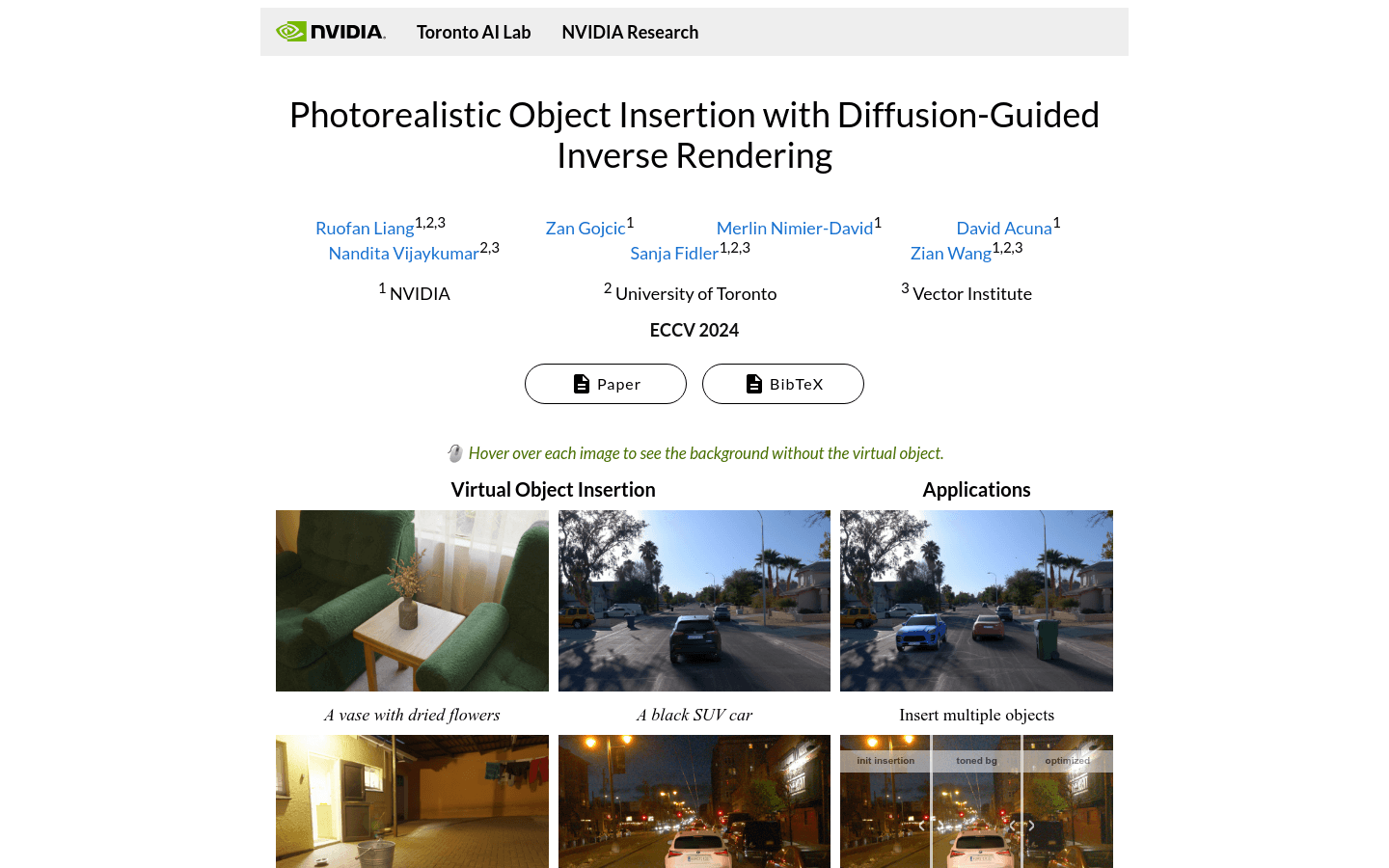
DiPIR是多伦多AI实验室与NVIDIA Research共同研发的一种基于物理的方法,它通过从单张图片中恢复场景照明,使得虚拟物体能够逼真地插入到室内外场景中。该技术不仅能够优化材质和色调映射,还能自动调整以适应不同的环境,提高图像的真实感。
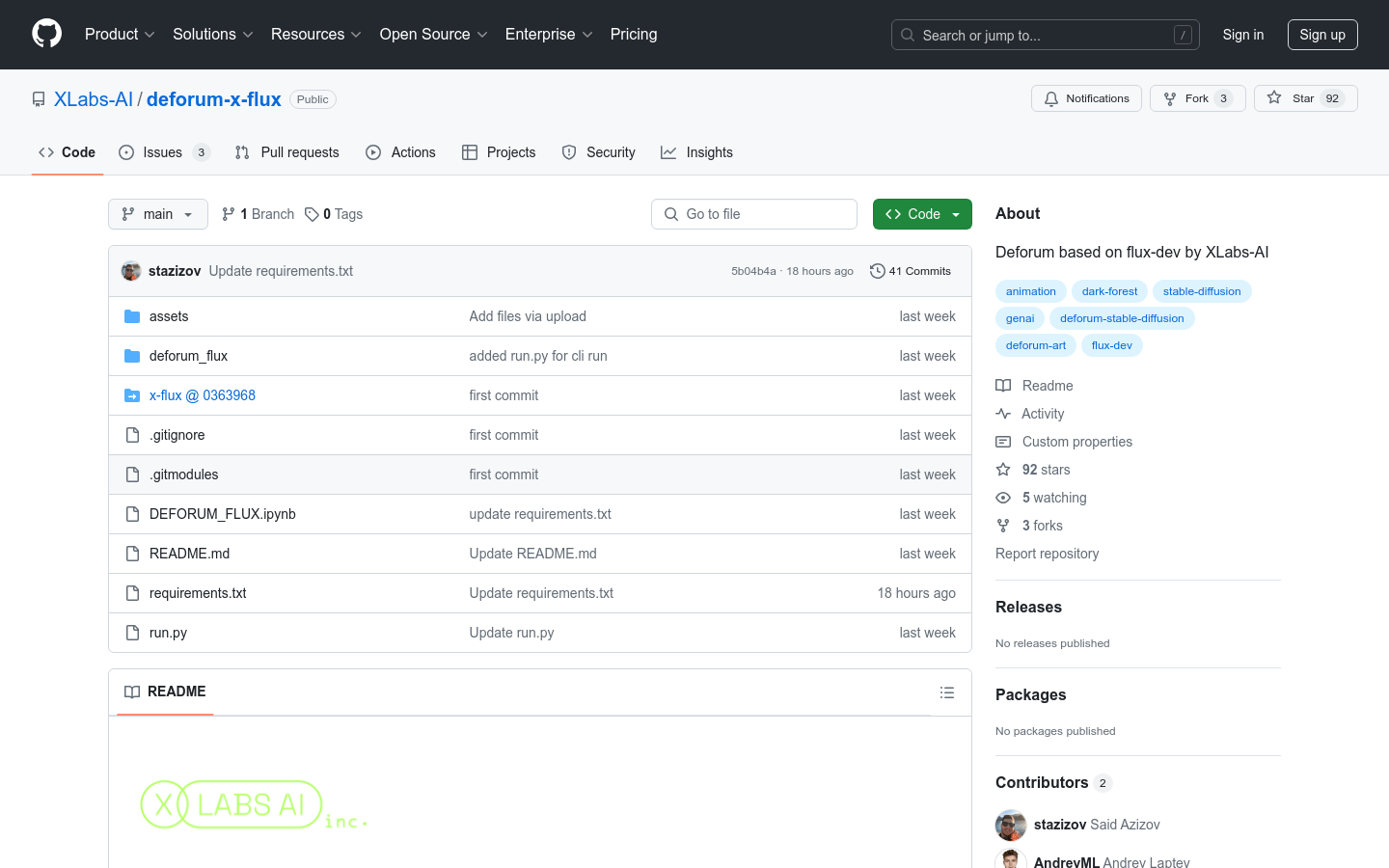
Deforum-x-flux是一个基于flux-dev的Deforum实现,由XLabs-AI开发。它是一个开源的图像生成模型,能够通过文本提示生成高度逼真的图像。该模型利用了最新的人工智能技术,具有生成高质量图像的能力,并且可以应用于多种场景,如艺术创作、游戏设计等。
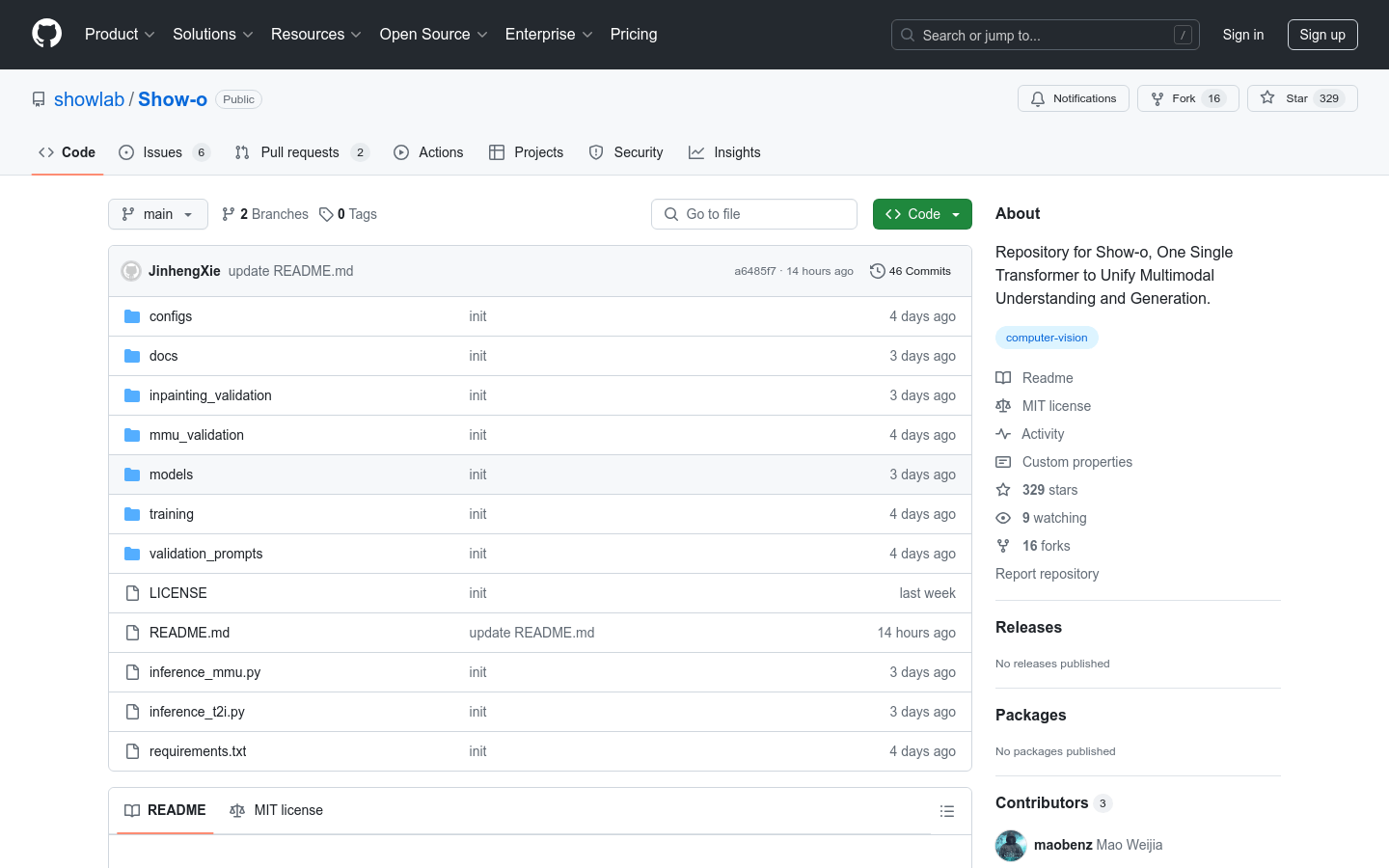
Show-o是一个用于多模态理解和生成的单一变换器模型,它能够处理图像字幕、视觉问答、文本到图像生成、文本引导的修复和扩展以及混合模态生成。该模型由新加坡国立大学的Show Lab和字节跳动共同开发,采用最新的深度学习技术,能够理解和生成多种模态的数据,是人工智能领域的一大突破。
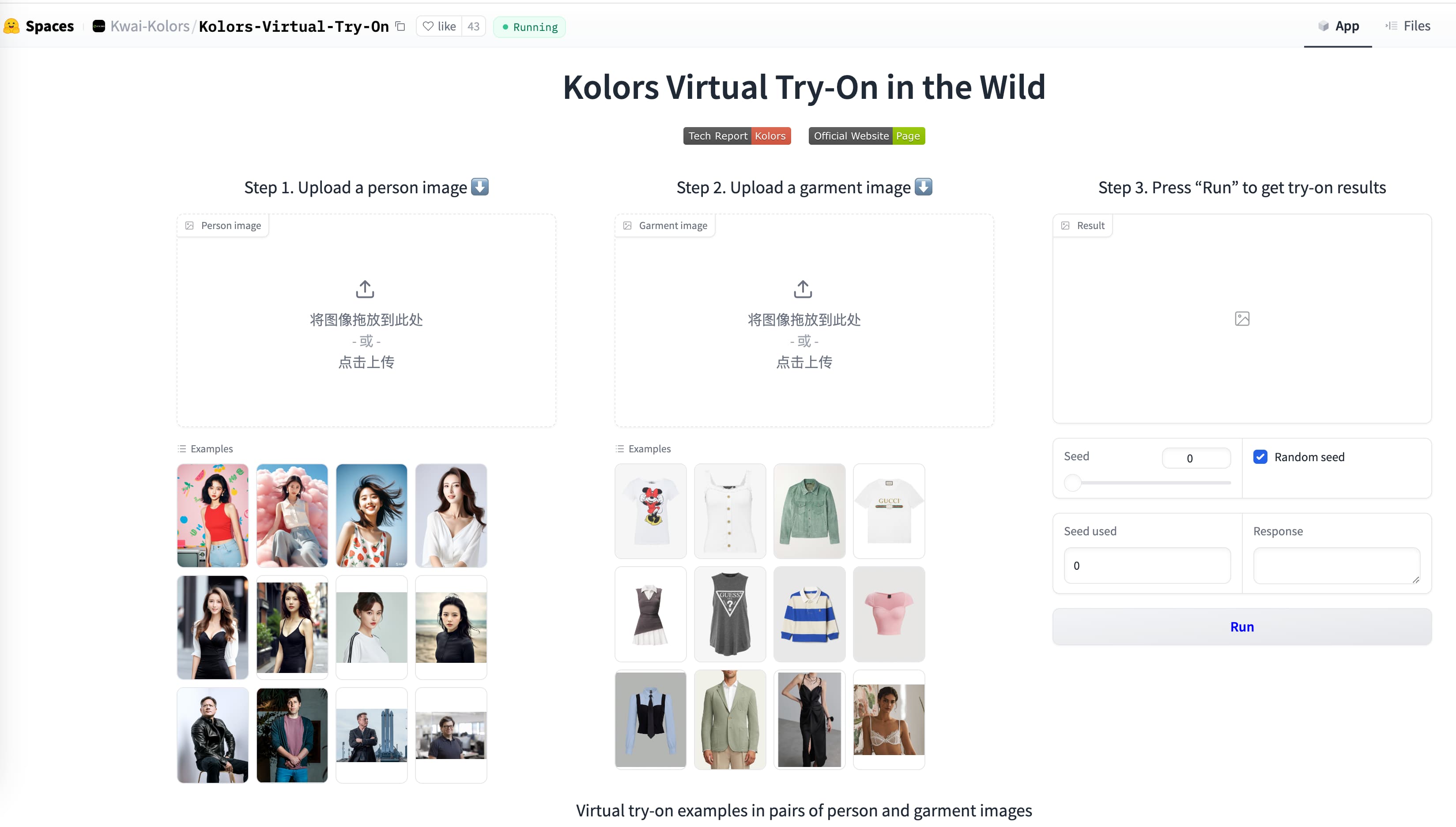
Kolors Virtual Try-On 是一款结合了人工智能和增强现实技术的虚拟试衣应用,能够根据给定的模特图和选定衣服生成自然美观的试穿效果。该产品支持从模特素材图到模特短视频的全流程生成,满足电商模特素材生成需求。
dark-fantasy-illustration-flux是一个基于FLUX1.-dev模型的LoRa适配器,专门用于生成受黑暗幻想复古插画启发的图像。它不需要特定的触发词,只需自然的语言提示即可生成图像,并且与其它LoRa模型兼容,适用于生成具有独特艺术风格的图像。
mPLUG-Owl3是一个多模态大型语言模型,专注于长图像序列的理解。它能够从检索系统中学习知识,与用户进行图文交替对话,并观看长视频,记住其细节。模型的源代码和权重已在HuggingFace上发布,适用于视觉问答、多模态基准测试和视频基准测试等场景。
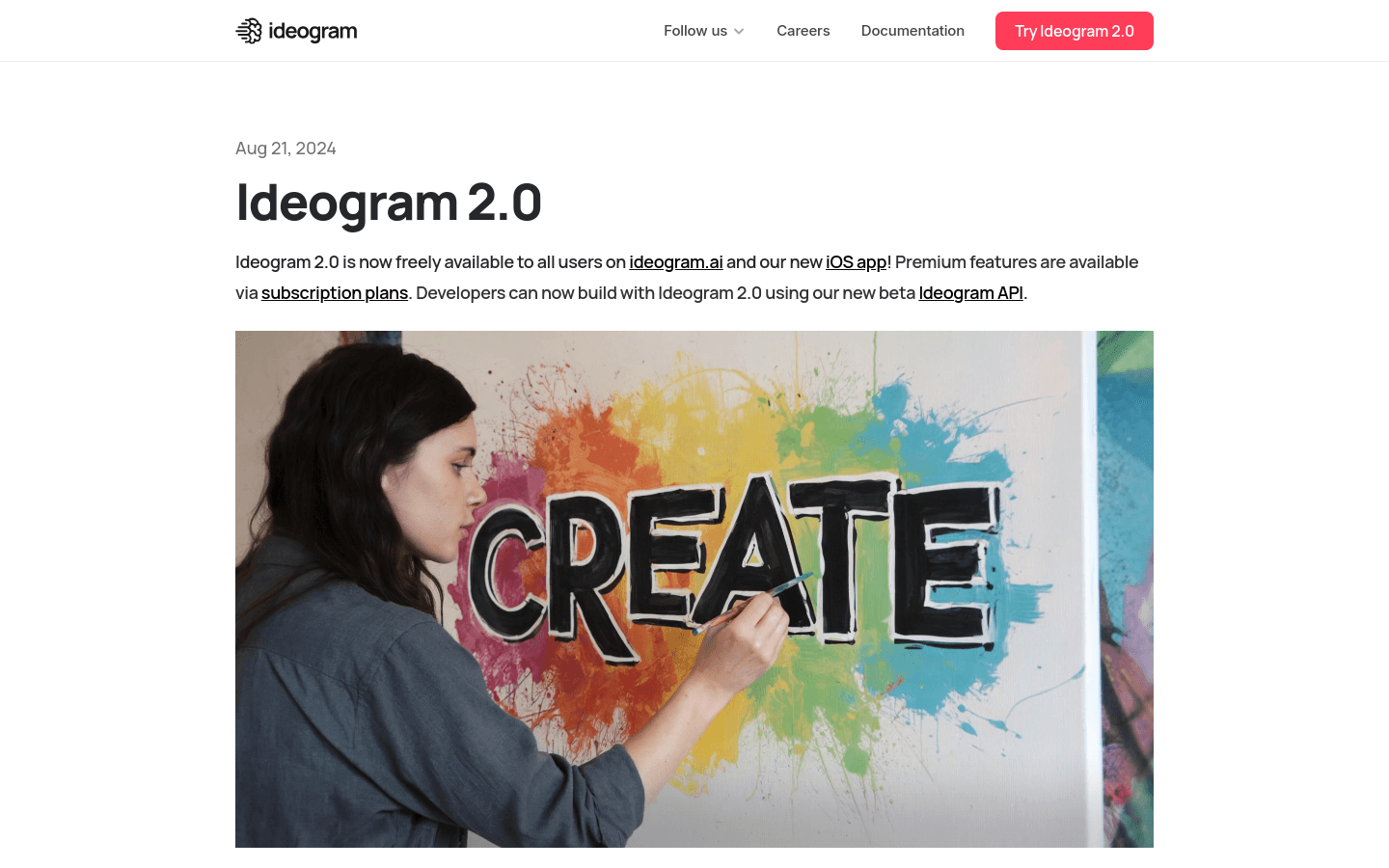
Ideogram 2.0 是一款前沿的文本到图像模型,具备生成逼真图像、平面设计、排版等能力。它从零开始训练,显著优于其他文本到图像模型,在图像文本对齐、整体主观偏好和文本渲染准确性等多个质量指标上表现突出。Ideogram 2.0 还推出了iOS应用,将高端平台带到移动用户手中,并通过API以极具竞争力的价格为开发者提供技术,以增强他们的应用和工作流程。
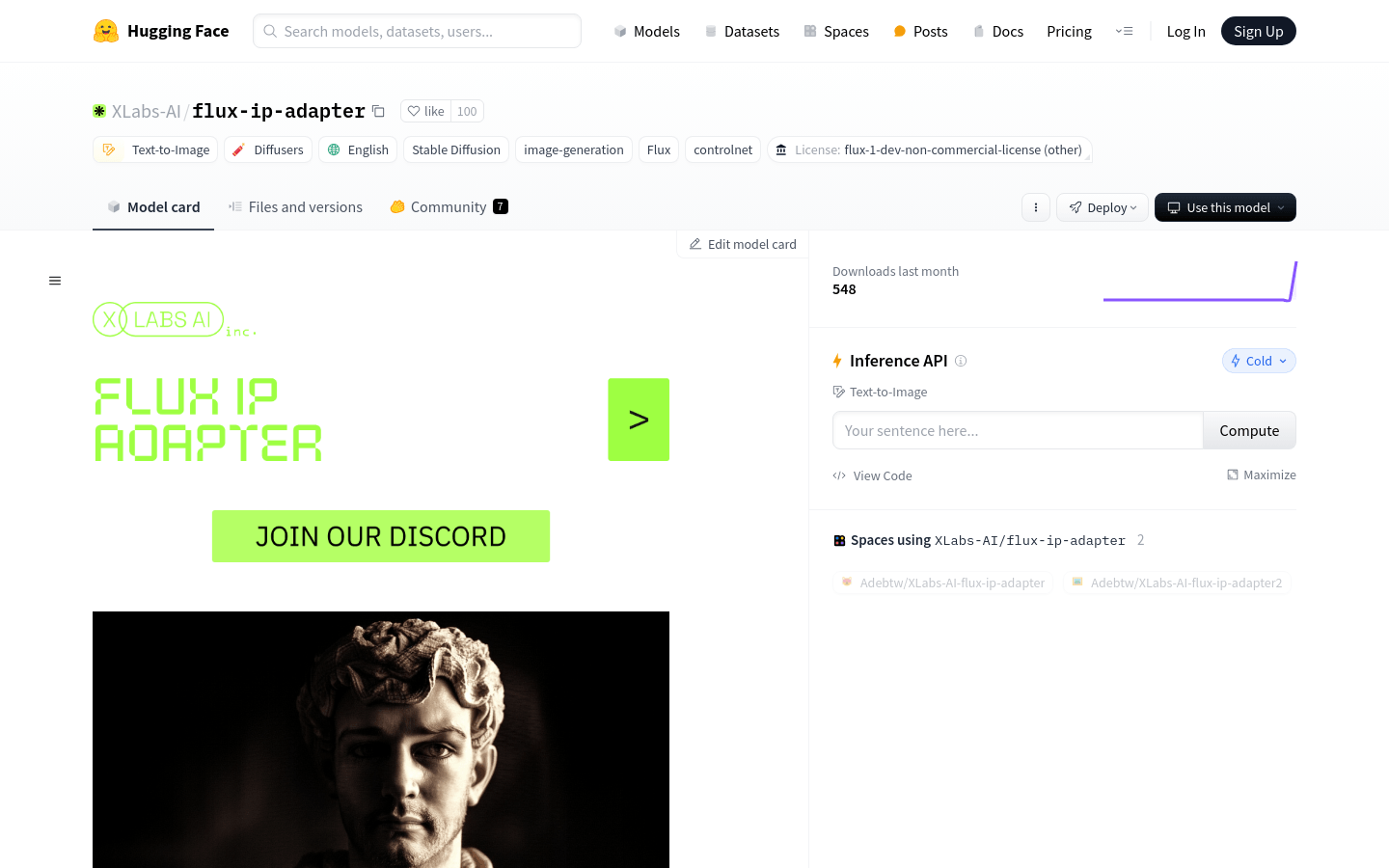
flux-ip-adapter是一个基于FLUX.1-dev模型的图像生成适配器,由Black Forest Labs开发。该模型经过训练,支持512x512和1024x1024分辨率的图像生成,并且定期发布新的检查点。它主要被设计用于ComfyUI,一个用户界面设计工具,可以通过自定义节点进行集成。该产品目前处于Beta测试阶段,使用时可能需要多次尝试以获得理想结果。
DiffusionKit是一个开源项目,旨在为苹果硅片设备提供扩散模型的本地推理能力。它通过将PyTorch模型转换为Core ML格式,并使用MLX进行图像生成,实现了高效的图像处理能力。项目支持Stable Diffusion 3和FLUX模型,能够进行图像生成和图像到图像的转换。
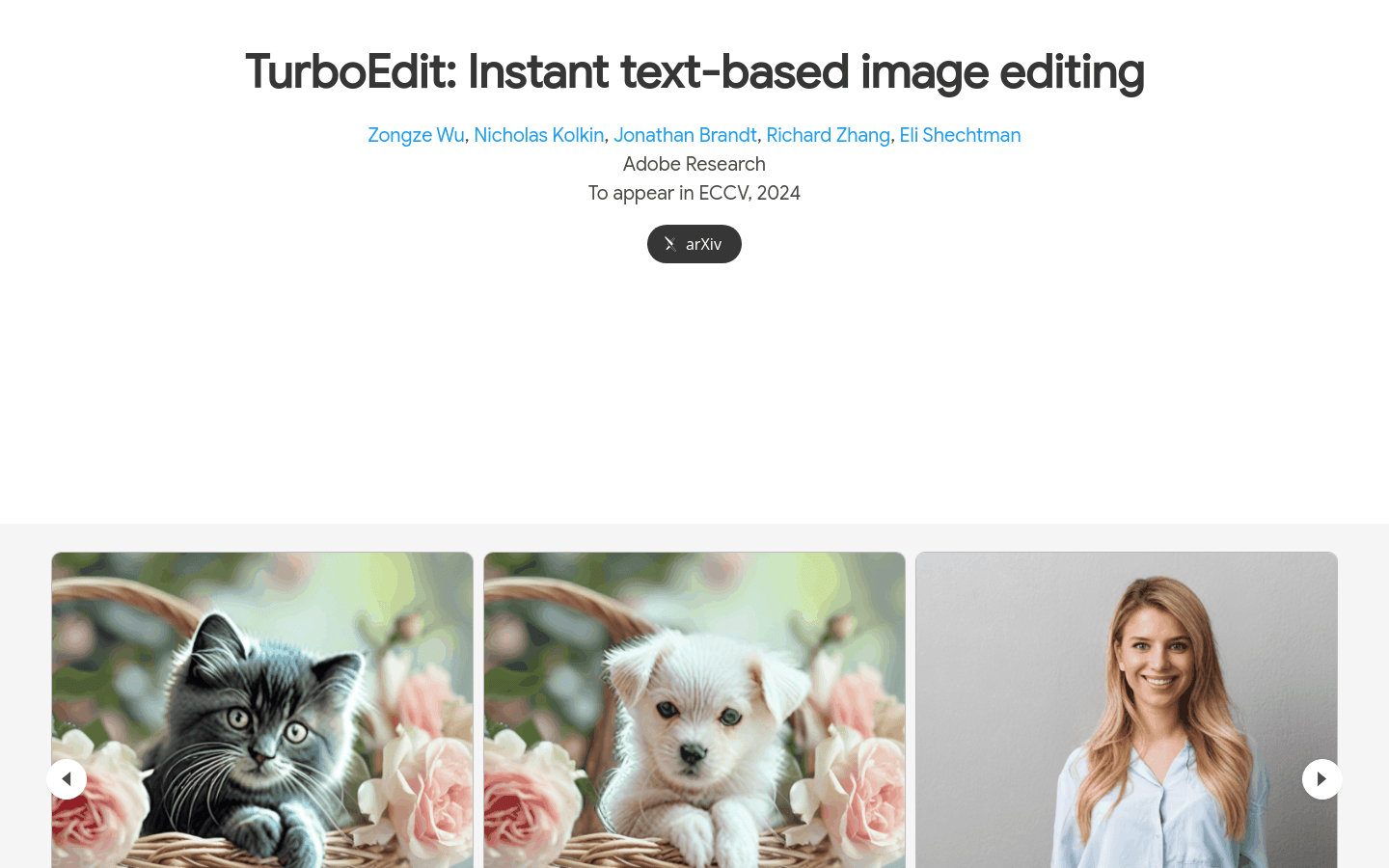
TurboEdit是一种基于Adobe Research开发的技术,旨在解决精确图像反转和解耦图像编辑的挑战。它通过迭代反转技术和基于文本提示的条件控制,实现了在几步内对图像进行精准编辑的能力。这项技术不仅快速,而且性能超越了现有的多步扩散模型编辑技术。
AuraFlow v0.3是一个完全开源的基于流的文本到图像生成模型。与之前的版本AuraFlow-v0.2相比,该模型经过了更多的计算训练,并在美学数据集上进行了微调,支持各种宽高比,宽度和高度可达1536像素。该模型在GenEval上取得了最先进的结果,目前处于beta测试阶段,正在不断改进中,社区反馈非常重要。
half_illustration是一个基于Flux Dev 1模型的文本到图像生成模型,能够结合摄影和插图元素,创造出具有艺术感的图像。该模型使用了LoRA技术,可以通过特定的触发词来保持风格一致性,适合用于艺术创作和设计领域。
Freepik AI image generator是一个利用人工智能技术,根据用户输入的文本提示自动生成图像的在线工具。它简化了图像创作流程,使得用户即使没有专业的设计技能,也能快速创造出具有个性化和创意的图像。这项技术的应用,不仅提高了设计效率,也拓宽了图像创作的边界,为用户提供了无限的可能性。
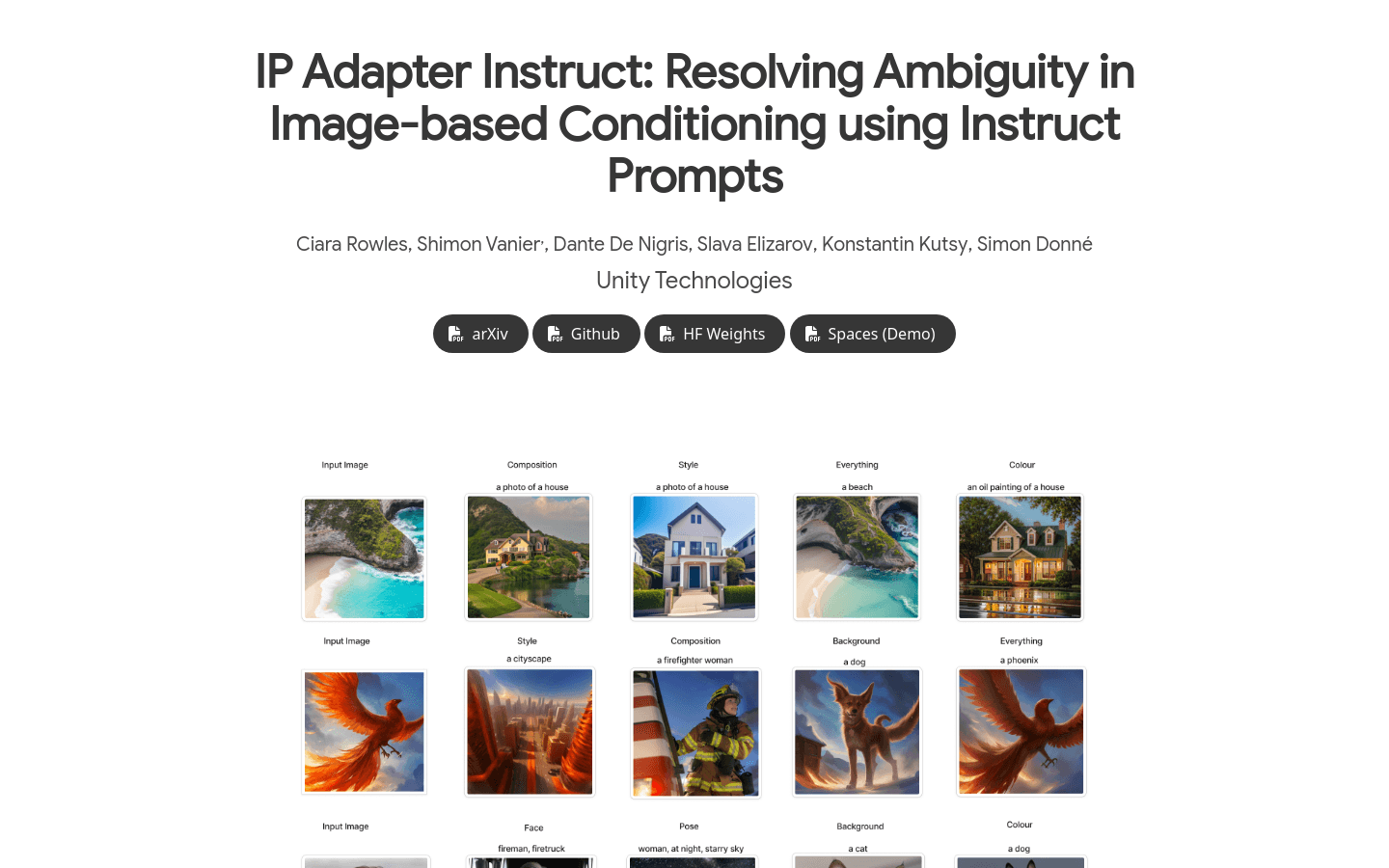
IPAdapter-Instruct是Unity Technologies开发的一种图像生成模型,它通过在transformer模型上增加额外的文本嵌入条件,使得单一模型能够高效地执行多种图像生成任务。该模型主要优点在于能够通过'Instruct'提示,在同一工作流中灵活地切换不同的条件解释,例如风格转换、对象提取等,同时保持与特定任务模型相比的最小质量损失。
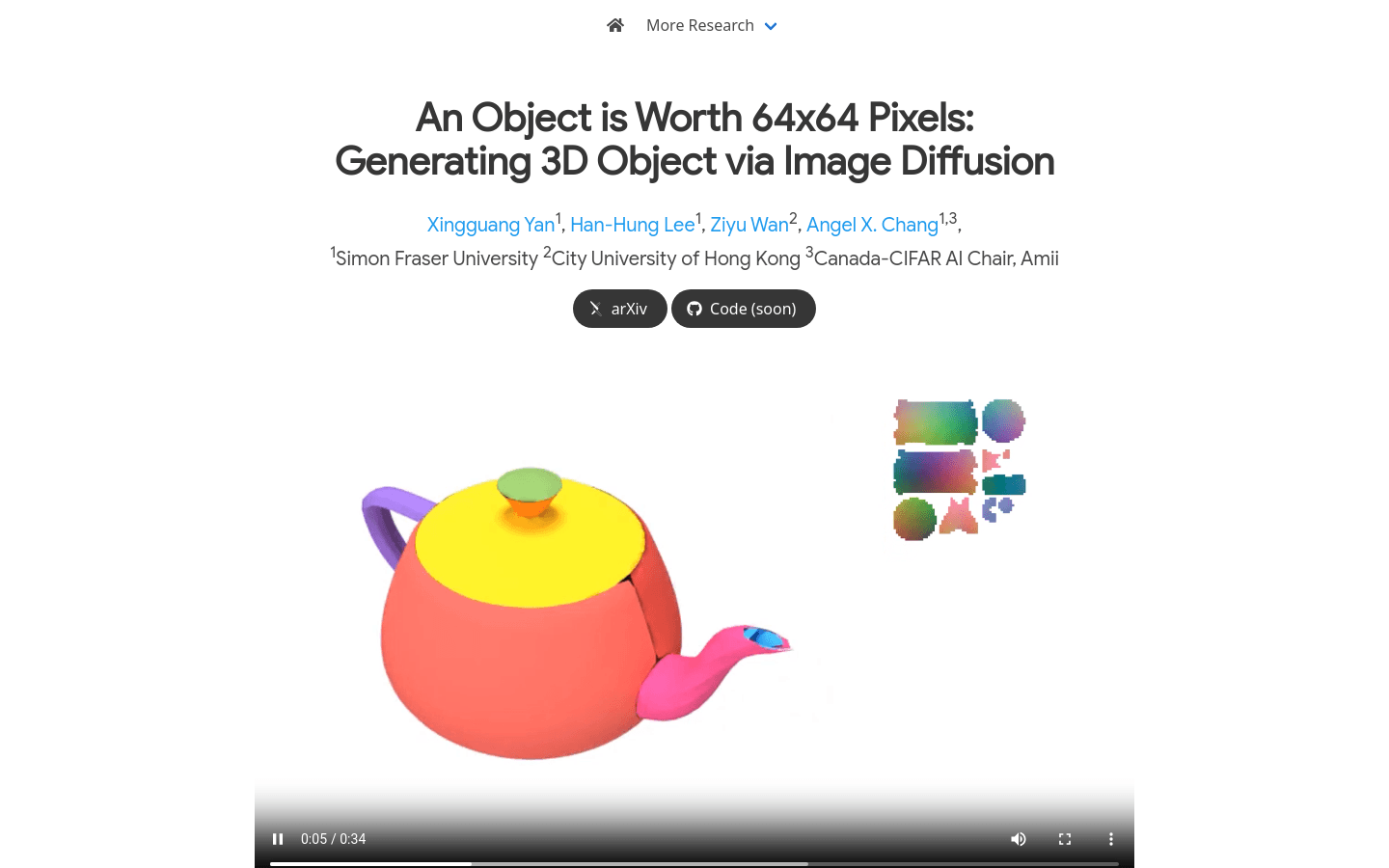
Object Images是一种创新的3D模型生成技术,它通过将复杂的3D形状封装在一个64x64像素的图像中,即所谓的'Object Images'或'omages',来简化3D形状的生成和处理。这项技术通过图像生成模型,如Diffusion Transformers,直接用于3D形状生成,解决了传统多边形网格中几何和语义不规则性的挑战。
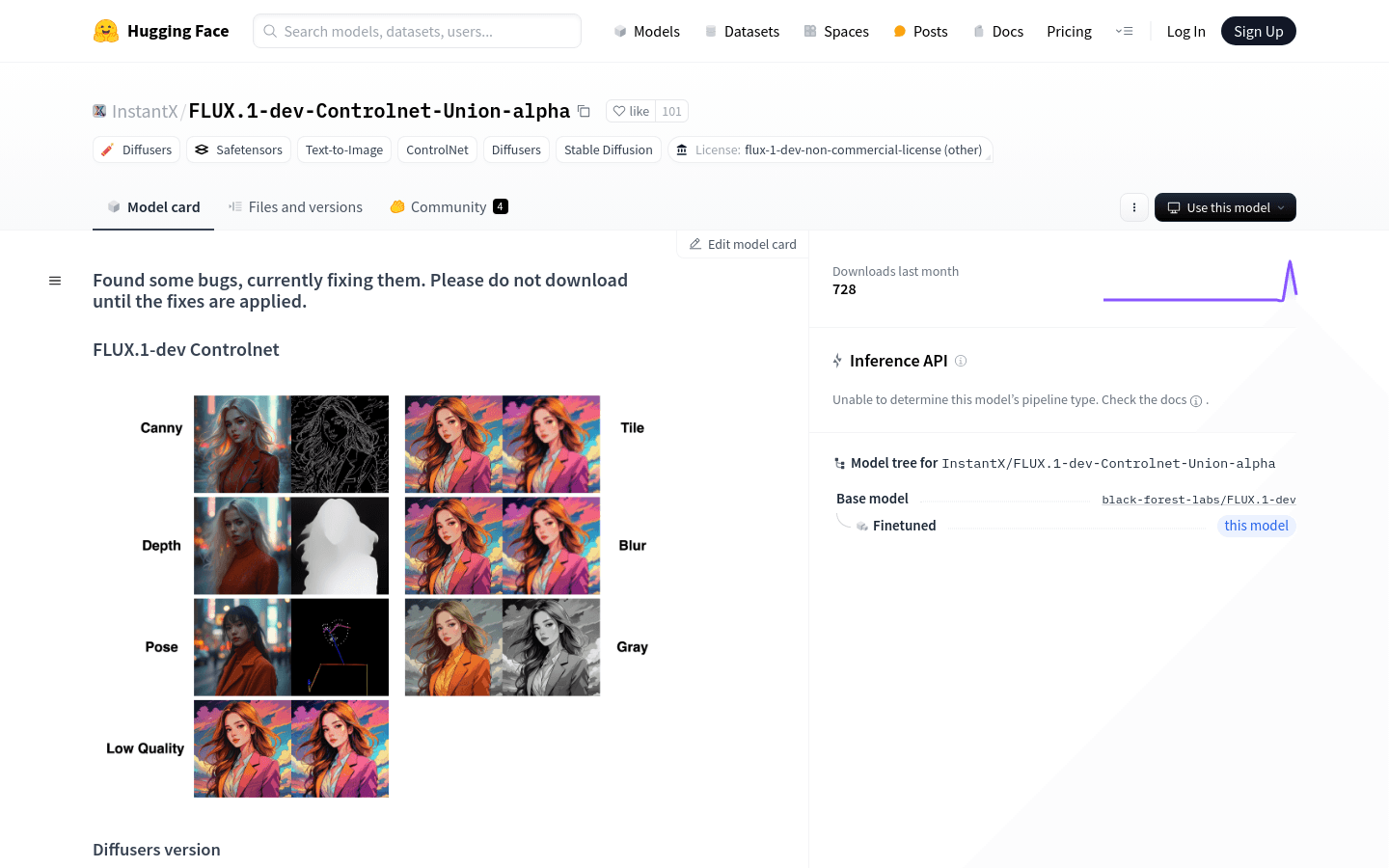
FLUX.1-dev-Controlnet-Union-alpha是一个文本到图像的生成模型,属于Diffusers系列,使用ControlNet技术进行控制。目前发布的是alpha版本,尚未完全训练完成,但已经展示了其代码的有效性。该模型旨在通过开源社区的快速成长,推动Flux生态系统的发展。尽管完全训练的Union模型可能在特定领域如姿势控制上不如专业模型,但随着训练的进展,其性能将不断提升。
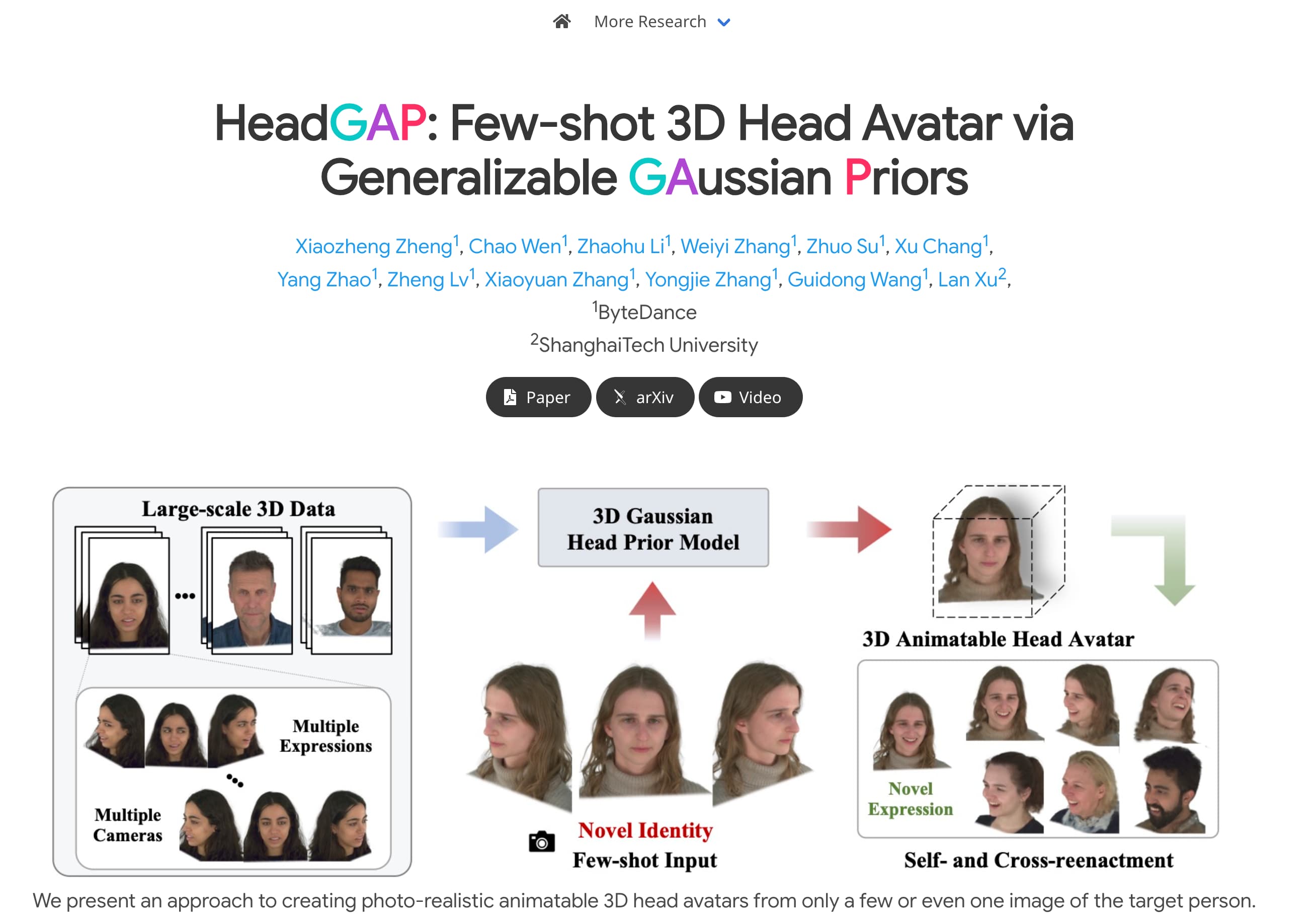
HeadGAP是一个先进的3D头像创建模型,它能够从少量甚至单张目标人物的图片中创建出逼真且可动画化的3D头像。该模型通过利用大规模多视角动态数据集来学习3D头部先验知识,并通过高斯Splatting基础的自解码网络实现动态建模。HeadGAP通过身份共享编码和个性化潜在代码来学习高斯原语的属性,实现了快速的头像个性化定制。
UniPortrait是一个创新的人像个性化框架,它通过两个插件式模块:ID嵌入模块和ID路由模块,实现了高保真度的单ID和多ID人像定制。该模型通过解耦策略提取可编辑的面部特征,并将它们嵌入到扩散模型的上下文空间中。ID路由模块则将这些嵌入特征自适应地组合并分配到合成图像中的相应区域,实现单ID和多ID的定制化。UniPortrait通过精心设计的两阶段训练方案,实现了在单ID和多ID定制中的卓越性能。
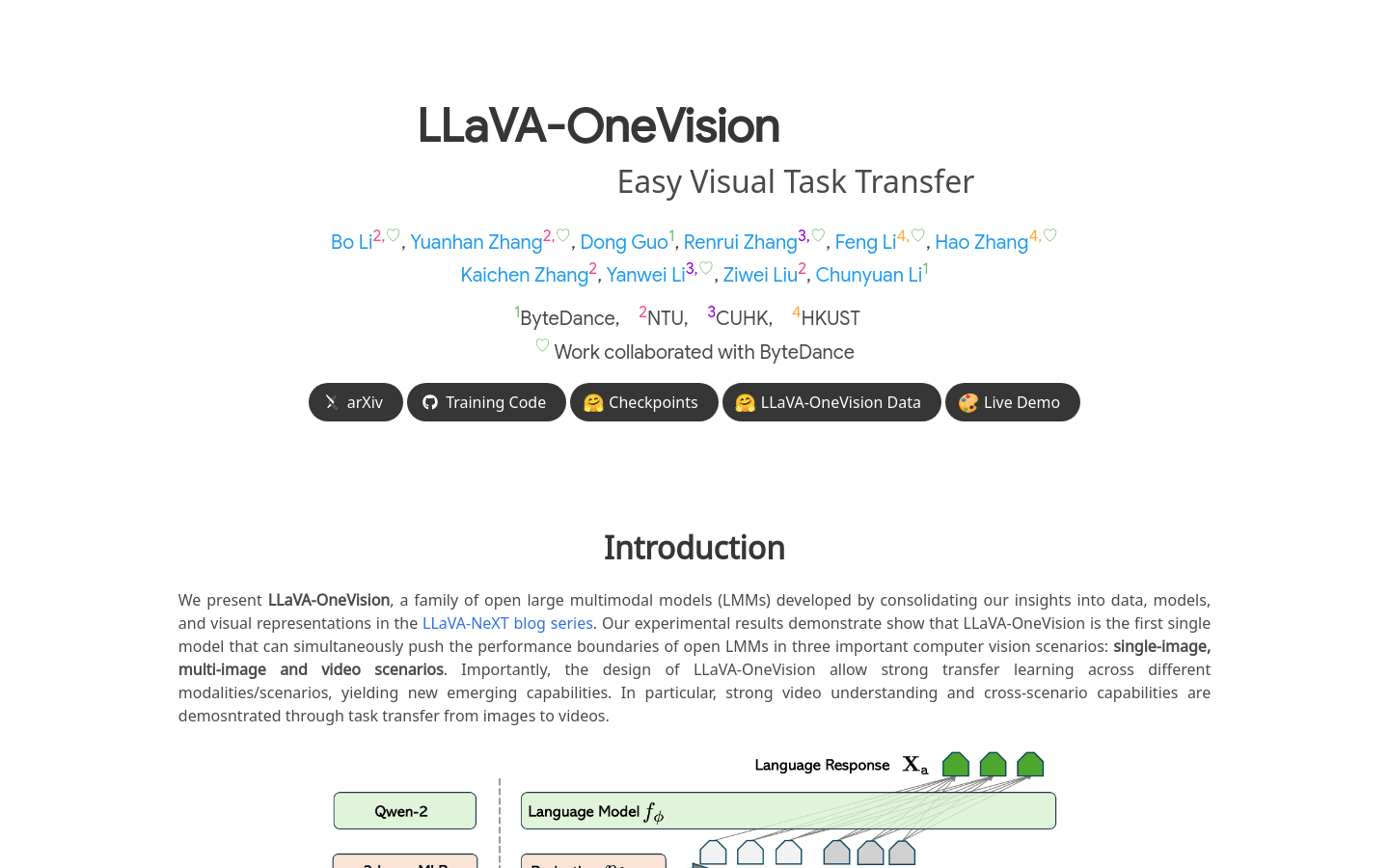
LLaVA-OneVision是一款由字节跳动公司与多所大学合作开发的多模态大型模型(LMMs),它在单图像、多图像和视频场景中推动了开放大型多模态模型的性能边界。该模型的设计允许在不同模态/场景之间进行强大的迁移学习,展现出新的综合能力,特别是在视频理解和跨场景能力方面,通过图像到视频的任务转换进行了演示。
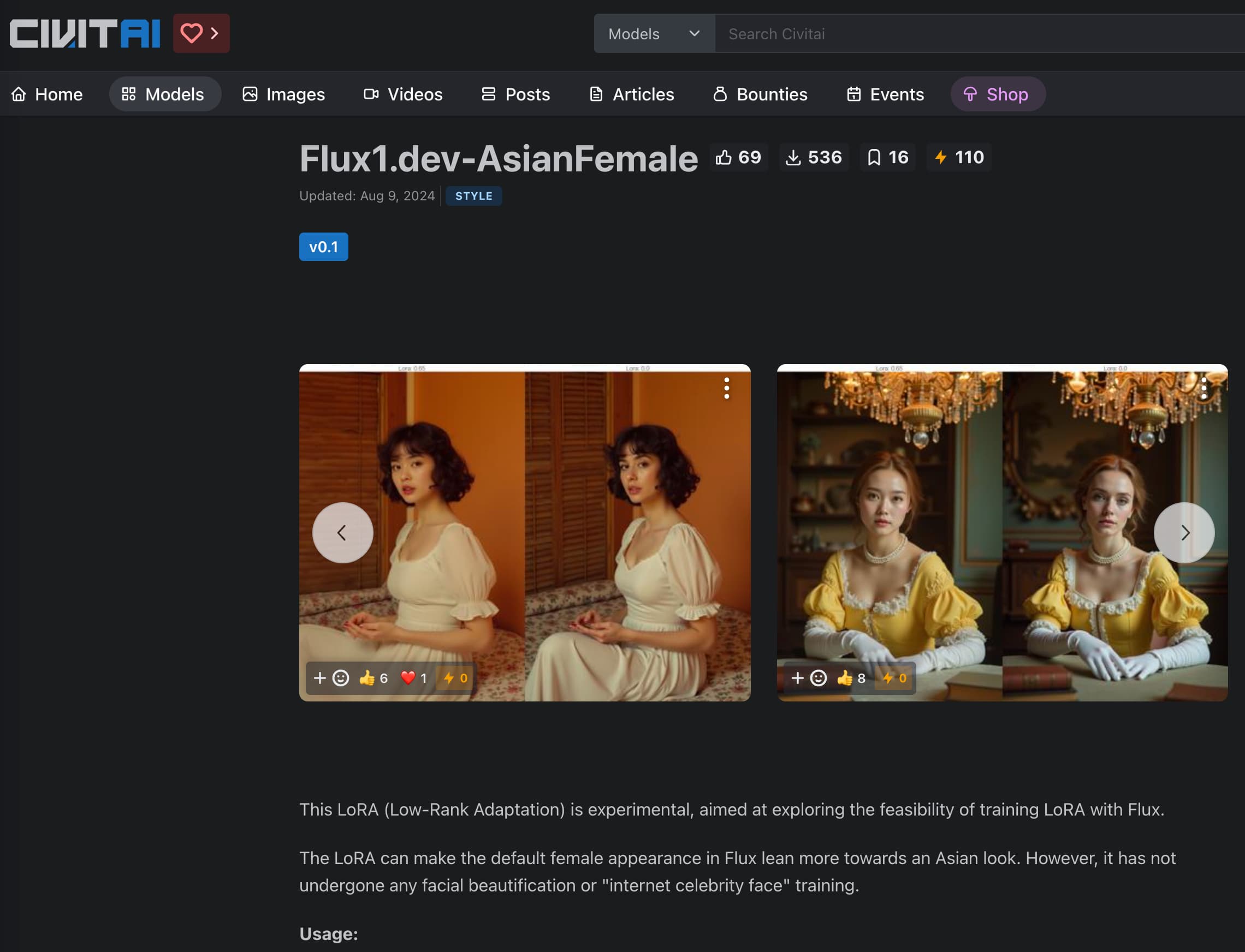
Flux1.dev-AsianFemale是一个基于Flux.1 D模型的LoRA(Low-Rank Adaptation)实验性模型,旨在探索通过训练使Flux模型的默认女性形象更趋向亚洲人的外貌特征。该模型未经面部美化或网络名人脸训练,具有实验性质,可能存在一些训练上的问题和挑战。
ImageFX 是一个在线图像生成工具,利用先进的AI技术,用户可以轻松制作出具有艺术效果的图像。它通过简单的操作界面,让用户输入描述或种子值,快速生成具有特定风格的图像,非常适合需要快速创意和艺术效果的设计师和艺术家。
ai-toolkit是一个研究性质的GitHub仓库,由Ostris创建,主要用于Stable Diffusion模型的实验和训练。它包含了各种AI脚本,支持模型训练、图像生成、LoRA提取器等。该工具包仍在开发中,可能存在不稳定性,但提供了丰富的功能和高度的自定义性。
flux-lora-collection是由XLabs AI团队发布的一系列针对FLUX.1-dev模型的LoRAs训练检查点。该模型集合支持多种风格和主题的图像生成,如动物拟人化、动漫、迪士尼风格等,具有高度的可定制性和创新性。
VFusion3D是一种基于预训练的视频扩散模型构建的可扩展3D生成模型。它解决了3D数据获取困难和数量有限的问题,通过微调视频扩散模型生成大规模合成多视角数据集,训练出能够从单张图像快速生成3D资产的前馈3D生成模型。该模型在用户研究中表现出色,用户超过90%的时间更倾向于选择VFusion3D生成的结果。
ml-mdm是一个Python包,用于高效训练高质量的文本到图像扩散模型。该模型利用Matryoshka扩散模型技术,能够在1024x1024像素的分辨率上训练单一像素空间模型,展现出强大的零样本泛化能力。
探索 图像 分类下的其他子分类
832 个工具
771 个工具
522 个工具
352 个工具
196 个工具
95 个工具
68 个工具
63 个工具
AI图像生成 是 图像 分类下的热门子分类,包含 543 个优质AI工具


































![FLUX1.1 [pro]](https://pic.chinaz.com/ai/2024/10/08/202410081033531725.jpg)