共找到 25 个AI工具
点击任意工具查看详细信息
Animate-X是一个基于LDM的通用动画框架,用于各种角色类型(统称为X),包括人物拟态角色。该框架通过引入姿势指示器来增强运动表示,可以更全面地从驱动视频中捕获运动模式。Animate-X的主要优点包括对运动的深入建模,能够理解驱动视频的运动模式,并将其灵活地应用到目标角色上。此外,Animate-X还引入了一个新的Animated Anthropomorphic Benchmark (A2Bench) 来评估其在通用和广泛适用的动画图像上的性能。
DressRecon是一个用于从单目视频重建时间一致的4D人体模型的方法,专注于处理非常宽松的服装或手持物体交互。该技术结合了通用的人体先验知识(从大规模训练数据中学习得到)和针对单个视频的特定“骨骼袋”变形(通过测试时优化进行拟合)。DressRecon通过学习一个神经隐式模型来分离身体与服装变形,作为单独的运动模型层。为了捕捉服装的微妙几何形状,它利用基于图像的先验知识,如人体姿势、表面法线和光流,在优化过程中进行调整。生成的神经场可以提取成时间一致的网格,或者进一步优化为显式的3D高斯,以提高渲染质量和实现交互式可视化。DressRecon在包含高度挑战性服装变形和物体交互的数据集上,提供了比以往技术更高的3D重建保真度。
FaceFusion是一个行业领先的面部操作平台,专注于面部交换、唇形同步和深度操作技术。它利用先进的人工智能技术,为用户提供高度逼真的面部操作体验。FaceFusion在图像处理和视频制作领域具有广泛的应用,尤其是在娱乐和媒体行业。
PortraitGen是一个基于多模态生成先验的2D肖像视频编辑工具,能够将2D肖像视频提升到4D高斯场,实现多模态肖像编辑。该技术通过追踪SMPL-X系数和使用神经高斯纹理机制,可以快速生成3D肖像并进行编辑。它还提出了一种迭代数据集更新策略和多模态人脸感知编辑模块,以提高表情质量和保持个性化面部结构。
Robust Dual Gaussian Splatting (DualGS) 是一种新型的基于高斯的体积视频表示方法,它通过优化关节高斯和皮肤高斯来捕捉复杂的人体表演,并实现鲁棒的跟踪和高保真渲染。该技术在SIGGRAPH Asia 2024上展示,能够实现在低端移动设备和VR头显上的实时渲染,提供用户友好和互动的体验。DualGS通过混合压缩策略,实现了高达120倍的压缩比,使得体积视频的存储和传输更加高效。
Svd Keyframe Interpolation 是一个基于奇异值分解(SVD)技术的关键帧插值模型,用于在动画制作中自动生成中间帧,从而提高动画师的工作效率。该技术通过分析关键帧的特征,自动计算出中间帧的图像,使得动画更加流畅自然。它的优势在于能够减少动画师手动绘制中间帧的工作量,同时保持高质量的动画效果。
该产品是一个图像到视频的扩散模型,通过轻量级的微调技术,能够从一对关键帧生成具有连贯运动的连续视频序列。这种方法特别适用于需要在两个静态图像之间生成平滑过渡动画的场景,如动画制作、视频编辑等。它利用了大规模图像到视频扩散模型的强大能力,通过微调使其能够预测两个关键帧之间的视频,从而实现前向和后向的一致性。
ComfyUI-AdvancedLivePortrait是一个用于实时预览和编辑人脸表情的高级工具。它允许用户在视频中跟踪和编辑人脸,将表情插入到视频中,甚至从样本照片中提取表情。这个项目通过使用ComfyUI-Manager自动安装,简化了安装过程。它结合了图像处理和机器学习技术,为用户提供了一个强大的工具,用于创建动态和互动的媒体内容。
Segment Anything 2 for Surgical Video Segmentation 是一个基于Segment Anything Model 2的手术视频分割模型。它利用先进的计算机视觉技术,对手术视频进行自动分割,以识别和定位手术工具,提高手术视频分析的效率和准确性。该模型适用于内窥镜手术、耳蜗植入手术等多种手术场景,具有高精度和高鲁棒性的特点。
Live_Portrait_Monitor 是一个开源项目,旨在通过监控器或网络摄像头实现肖像动画化。该项目基于LivePortrait研究论文,使用深度学习技术,通过拼接和重定向控制来高效地实现肖像动画。作者正积极更新和改进此项目,仅供研究使用。
LivePortrait是一个用于人像动画的高效工具,它通过拼接和重定向控制技术,能够将静态图片转化为生动的动画。这项技术在图像处理和动画制作领域具有重要意义,可以大幅度提升动画制作的效率和质量。产品背景信息显示,它是由shadowcz007开发,并且与comfyui-mixlab-nodes配合使用,可以更好地实现人像动画效果。
MASA是一个用于视频帧中对象匹配的先进模型,它能够处理复杂场景中的多目标跟踪(MOT)。MASA不依赖于特定领域的标注视频数据集,而是通过Segment Anything Model(SAM)丰富的对象分割,学习实例级别的对应关系。MASA设计了一个通用适配器,可以与基础的分割或检测模型配合使用,实现零样本跟踪能力,即使在复杂领域中也能表现出色。
CameraCtrl 致力于为文本生成视频模型提供精准相机姿态控制,通过训练相机编码器实现参数化相机轨迹,从而实现视频生成过程中的相机控制。产品通过综合研究各种数据集的效果,证明视频具有多样的相机分布和相似外观可以增强可控性和泛化能力。实验证明 CameraCtrl 在实现精确、领域自适应的相机控制方面非常有效,是从文本和相机姿态输入实现动态、定制视频叙事的重要进展。
GoEnhance AI 是一个视频到视频、图像增强和升级的平台。它可以将您的视频转换为多种不同风格的动画,包括像素和扁平动漫。通过 AI 技术,它能够将图像增强并升级到极致的细节。无论是个人创作还是商业应用,GoEnhance AI 都能为您提供强大的图像和视频编辑工具。
Move API能够将包含人体动作的视频转换为3D动画资产,支持将视频文件转换为usdz、usdc和fbx文件格式,并提供预览视频。适用于集成到生产工作流程软件、增强应用动作捕捉能力或创造全新体验。
VisFusion是一个利用视频数据进行在线3D场景重建的技术,它能够实时地从视频中提取和重建出三维环境。这项技术结合了计算机视觉和深度学习,为用户提供了一个强大的工具,用于创建精确的三维模型。
PRISMA是一个计算摄影管道,可以从任何图像或视频中执行多种推断。就像光线通过棱镜折射成不同的波长一样,这个管道将图像扩展成可用于3D重建或实时后期处理操作的数据。它结合了不同的算法和开源的预训练模型,比如单目深度(MiDAS v3.1, ZoeDepth, Marigold, PatchFusion)、光流(RAFT)、分割掩模(mmdet)、相机姿态(colmap)等。结果带存储在与输入文件同名的文件夹中,每个band以.png或.mp4文件的形式单独存储。对于视频,在最后一步,它会尝试执行稀疏重建,可用于NeRF(如NVidia的Instant-ngp)或高斯扩散训练。推断出的深度信息默认导出为可以使用LYGIA的heatmap GLSL/HLSL采样实时解码的热度图,而光流编码为HUE(角度)和饱和度,也可以使用LYGIA的光流GLSL/HLSL采样器实时解码。
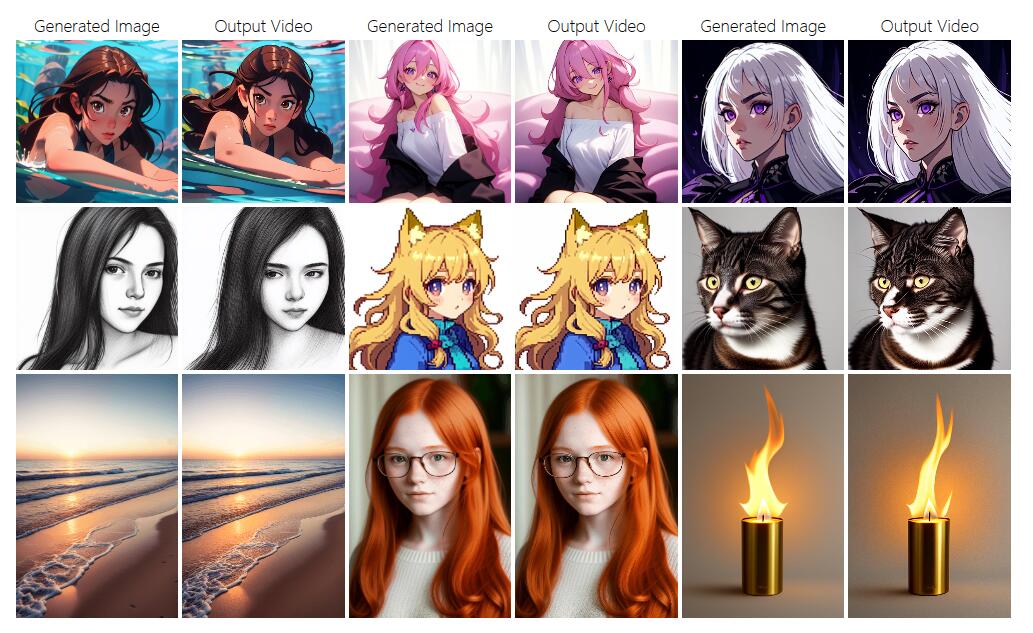
DragNUWA是一款视频生成工具,能够通过直接操作背景或图像,将动作转化为摄像机运动或目标物体运动,生成对应的视频。DragNUWA 1.5基于稳定视频扩散技术,可根据特定路径使图像动起来。DragNUWA 1.0利用文字、图像和轨迹作为三个重要的控制因素,从语义、空间和时间上促进高度可控的视频生成。用户可通过git克隆仓库、下载预训练模型,并在桌面端进行图像拖拽生成动画。
Wild2Avatar是一个用于渲染被遮挡的野外单目视频中的人类外观的神经渲染方法。它可以在真实场景下渲染人类,即使障碍物可能会阻挡相机视野并导致部分遮挡。该方法通过将场景分解为三部分(遮挡物、人类和背景)来实现,并使用特定的目标函数强制分离人类与遮挡物和背景,以确保人类模型的完整性。
AnimateZero是一款零样本图像动画生成器,通过分离外观和运动生成视频,解决了黑盒、低效、不可控等问题。它可以通过零样本修改将预训练的T2V模型转换为I2V模型,从而实现零样本图像动画生成。AnimateZero还可以用于视频编辑、帧插值、循环视频生成和真实图像动画等场景,具有较高的主观质量和匹配度。
FLATTEN是一种用于文本到视频编辑的光流引导注意力插件。它通过在扩散模型的U-Net中引入光流来解决文本到视频编辑中的一致性问题。FLATTEN通过强制在不同帧上的相同光流路径上的补丁在注意模块中相互关注,从而提高了编辑视频的视觉一致性。此外,FLATTEN是无需训练的,可以无缝集成到任何基于扩散的文本到视频编辑方法中,并提高其视觉一致性。实验结果表明,我们提出的方法在现有的文本到视频编辑基准上取得了最新的性能。特别是,我们的方法在保持编辑视频的视觉一致性方面表现出色。
Imitator是一种新颖的个性化语音驱动的3D面部动画方法。通过给定音频序列和个性化风格嵌入作为输入,我们生成具有准确唇部闭合的个人特定运动序列,用于双唇辅音('m','b','p')。可以通过短参考视频(例如5秒)计算主体的风格嵌入。
ProPainter 是一个用于视频修复的先进模型。它结合了增强的传播和 Transformer 机制,能够快速高效地进行视频修复、对象去除、水印去除等任务。ProPainter 通过双域传播和稀疏 Transformer 来提升性能和效率,能够在保持良好效果的同时大幅提升 PSNR 值 1.46 dB。该模型适用于广泛的视频修复场景,定价灵活合理。
帧间插值(Frame Interpolation)是一种高质量的帧间插值神经网络模型。该模型采用统一的单网络方法,不需要额外的预训练网络,如光流或深度网络,但仍能实现最先进的效果。模型使用多尺度特征提取器,在不同尺度上共享相同的卷积权重。该模型仅通过帧三元组进行训练。
Wonder Studio是一个AI工具,它可以自动将CG角色动画化、照明和合成到实景场景中。用户只需要一个摄像头,无需使用复杂的3D软件或昂贵的制作硬件。通过上传CG角色模型到一个或多个镜头,系统会自动检测剪辑并在整个序列中跟踪演员。系统根据单摄像头镜头自动检测演员的表演,然后将该表演传递到用户选择的CG角色上,实现自动动画化、照明和合成。Wonder Studio可广泛应用于电影制作、特效制作等领域。
探索 图像 分类下的其他子分类
832 个工具
771 个工具
543 个工具
522 个工具
352 个工具
196 个工具
95 个工具
68 个工具
AI视频编辑 是 图像 分类下的热门子分类,包含 25 个优质AI工具