共找到 100 个AI工具
点击任意工具查看详细信息
Talking Avatar是一款利用人工智能技术,允许用户通过编辑文本来更新旁白,无需重新录制,即可改变声音,包括口音、语调和情感。它支持一键多人唇形同步,确保视频观看体验自然而沉浸。此外,它还支持一句话声音克隆技术,用户只需提供一句话的音频样本,即可克隆任何声音,并用于生成任何语音。这款产品对于视频创作者、广告代理商、市场营销人员和教育工作者等都是一个强大的工具,可以轻松地将经典视频片段转化为新的热门内容,或者为不同平台优化视频内容。
Sieve Eye Contact Correction API 是一个为开发者设计的快速且高质量的视频眼神校正API。该技术通过重定向眼神,确保视频中的人物即使没有直接看向摄像头,也能模拟出与摄像头进行眼神交流的效果。它支持多种自定义选项来微调眼神重定向,保留了原始的眨眼和头部动作,并通过随机的“看向别处”功能来避免眼神呆板。此外,还提供了分屏视图和可视化选项,以便于调试和分析。该API主要面向视频制作者、在线教育提供者和任何需要提升视频交流质量的用户。定价为每分钟视频0.10美元。
TANGO是一个基于层次化音频-运动嵌入和扩散插值的共语手势视频重现技术。它利用先进的人工智能算法,将语音信号转换成相应的手势动作,实现视频中人物手势的自然重现。这项技术在视频制作、虚拟现实、增强现实等领域具有广泛的应用前景,能够提升视频内容的互动性和真实感。TANGO由东京大学和CyberAgent AI Lab联合开发,代表了当前人工智能在手势识别和动作生成领域的前沿水平。
Video Background Removal 是一个由 innova-ai 提供的 Hugging Face Space,专注于视频背景移除技术。该技术通过深度学习模型,能够自动识别并分离视频中的前景和背景,实现一键去除视频背景的功能。这项技术在视频制作、在线教育、远程会议等多个领域都有广泛的应用,尤其在需要抠图或更换视频背景的场景下,提供了极大的便利。产品背景信息显示,该技术是基于开源社区 Hugging Face 的 Spaces 平台开发的,继承了开源、共享的技术理念。目前,产品提供免费试用,具体价格信息需进一步查询。
Coverr AI Workflows是一个专注于AI视频生成的平台,提供多种AI工具和工作流程,帮助用户通过简单的步骤生成高质量的视频内容。该平台汇集了AI视频专家的智慧,通过社区分享的workflows,用户可以学习如何使用不同的AI工具来创作视频。Coverr AI Workflows的背景是基于人工智能技术在视频制作领域的应用日益广泛,它通过提供易于理解和操作的工作流程,降低了视频创作的技术门槛,使得非专业人士也能创作出专业级别的视频内容。Coverr AI Workflows目前提供免费的视频和音乐资源,定位于满足创意工作者和小型企业的视频制作需求。
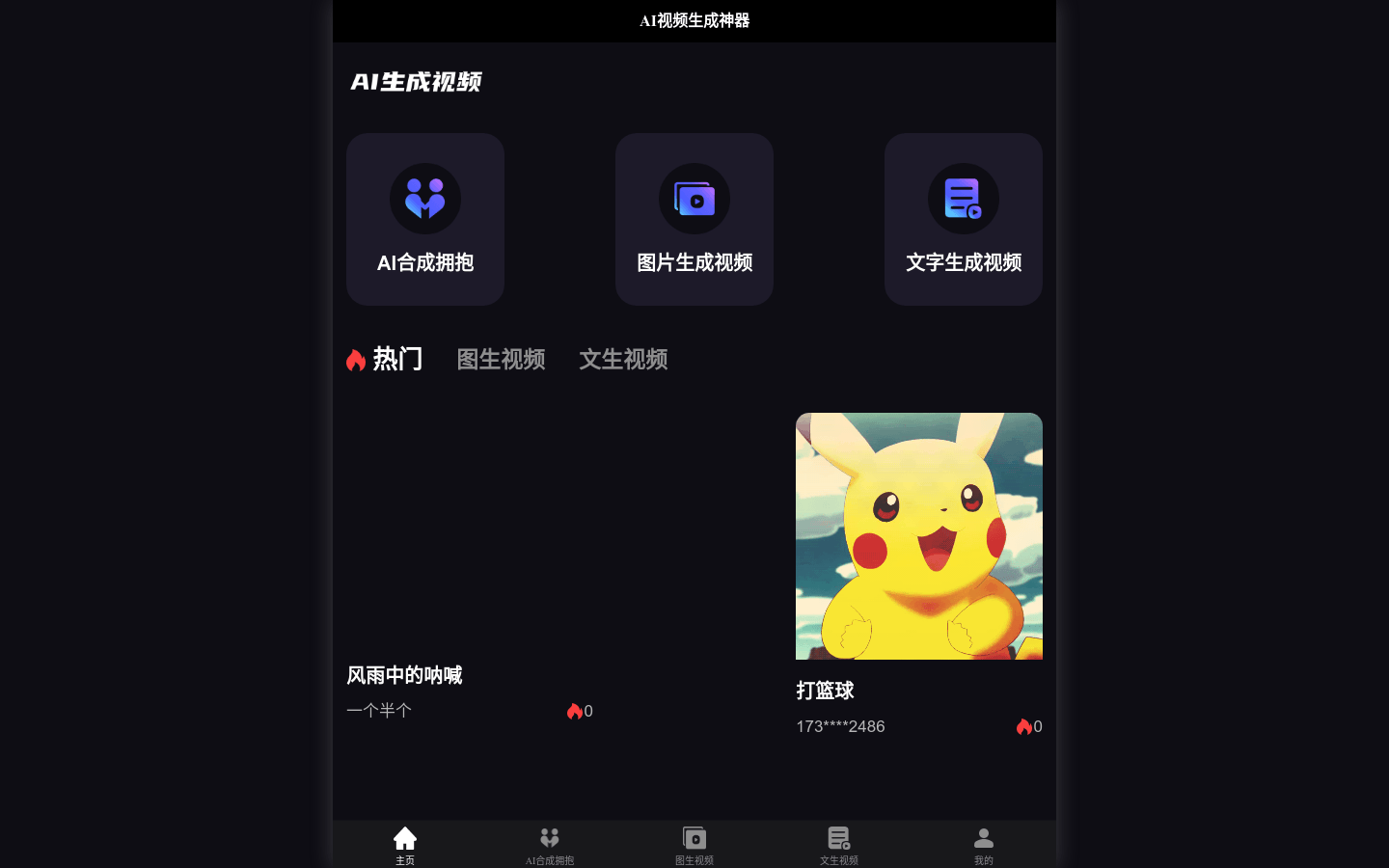
AI视频生成神器是一款利用人工智能技术,将图片或文字转换成视频内容的在线工具。它通过深度学习算法,能够理解图片和文字的含义,自动生成具有吸引力的视频内容。这种技术的应用,极大地降低了视频制作的成本和门槛,使得普通用户也能轻松制作出专业级别的视频。产品背景信息显示,随着社交媒体和视频平台的兴起,用户对视频内容的需求日益增长,而传统的视频制作方式成本高、耗时长,难以满足快速变化的市场需求。AI视频生成神器的出现,正好填补了这一市场空白,为用户提供了一种快速、低成本的视频制作解决方案。目前,该产品提供免费试用,具体价格需要在网站上查询。
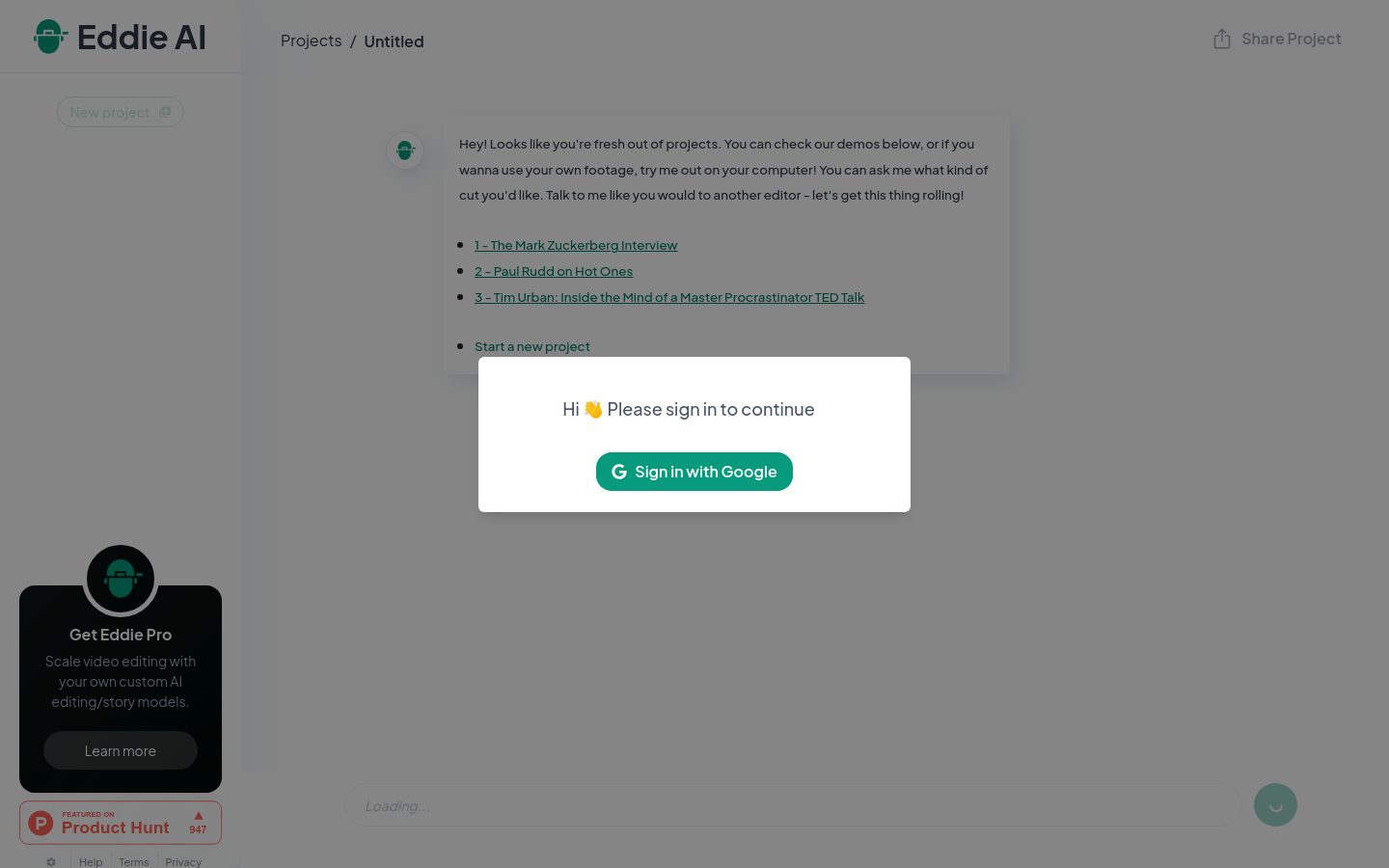
Eddie AI是一个创新的视频编辑平台,它利用人工智能技术帮助用户快速、轻松地编辑视频。这个平台的主要优点是它的用户友好性和高效率,它允许用户像与另一个编辑交谈一样与AI对话,提出他们想要的视频剪辑类型。Eddie AI的背景信息显示,它旨在通过使用自定义的AI编辑/故事模型来扩展视频编辑的规模,这表明它在视频制作领域具有潜在的革命性影响。
光映AI是一个利用人工智能技术帮助用户快速创建热门视频的平台。它通过AI技术简化了视频编辑过程,使得用户无需视频编辑技能也能制作出高质量的视频内容。该平台特别适合需要快速制作视频内容的个人和企业,如社交媒体运营者、视频博主等。
ElevenLabs Video Dubbing Application 是一个用户友好的界面,用于使用 ElevenLabs API 配音视频。该应用允许用户上传视频文件或提供视频网址(来自 YouTube、TikTok、Twitter 或 Vimeo 等平台),并将其配音成各种语言。应用使用 Gradio 提供易于使用的 Web 界面。
Dream Machine API是一个创意智能平台,它提供了一系列先进的视频生成模型,通过直观的API和开源SDKs,用户可以构建和扩展创意AI产品。该平台拥有文本到视频、图像到视频、关键帧控制、扩展、循环和相机控制等功能,旨在通过创意智能与人类合作,帮助他们创造更好的内容。Dream Machine API的推出,旨在推动视觉探索和创造的丰富性,让更多的想法得以尝试,构建更好的叙事,并让那些以前无法做到的人讲述多样化的故事。
AI Youtube Shorts Generator 是一个利用GPT-4和Whisper技术的Python工具,它可以从长视频中提取最有趣的亮点,检测演讲者,并将内容垂直裁剪,以适应短片格式。这个工具目前处于0.1版本,可能存在一些bug。
CaptionKit 是一款为视频创作者设计的应用,它利用先进的AI技术,支持超过100种语言的字幕生成,确保文本识别的高准确度。用户可以选择20多种预设的字幕模板,或自定义风格以适应不同的项目需求。该应用还提供了强大的文本编辑器,允许用户自定义字体、颜色、轮廓、背景等,甚至添加阴影效果。此外,它支持将字幕翻译成不同语言,帮助视频内容触及全球观众。CaptionKit 还具备预览模式,确保在不同社交媒体平台上的显示效果。无论是内容创作者、影响者还是普通用户,CaptionKit 都能够帮助他们在几分钟内创建出专业质量的字幕。
doesVideoContain是一个利用人工智能在浏览器中检测视频内容的模型。它允许用户通过简单的英语句子描述来自动抓取视频截图,识别视频中的重要时刻。这个模型完全在客户端运行,保护用户隐私,无需支付API费用,并且可以处理本地大文件,无需上传至云端。它使用了Web AI生态系统中的Transformers.js和ONNX Runtime Web,结合了自定义逻辑来执行余弦相似度计算。
Runway Staff Picks 是一个展示使用 Runway Gen-3 Alpha 技术创作的精选短片和实验作品的平台。这些作品涵盖了从艺术到科技的多个领域,展示了 Runway 在视频创作和实验艺术方面的前沿技术。Runway 与 Tribeca Festival 2024 合作,通过与 Media.Monks 的合作,进一步扩展了创意的边界。
Video-CCAM 是腾讯QQ多媒体研究团队开发的一系列灵活的视频多语言模型(Video-MLLM),致力于提升视频-语言理解能力,特别适用于短视频和长视频的分析。它通过因果交叉注意力掩码(Causal Cross-Attention Masks)来实现这一目标。Video-CCAM 在多个基准测试中表现优异,特别是在 MVBench、VideoVista 和 MLVU 上。模型的源代码已经重写,以简化部署过程。
DaVinci Resolve 19是一款专业的剪辑、调色、特效和音频后期制作软件,它提供一站式的后期制作解决方案,适用于从新手到好莱坞专业人士的广泛用户群体。该软件以其强大的功能、易用性以及支持多种工作流程而闻名,包括但不限于剪辑、调色、视觉特效、动态图形和音频后期制作。DaVinci Resolve 19新增了DaVinci Neural Engine AI工具,对100多项功能进行了升级,提供了更高效的工作效率和更优质的作品制作能力。
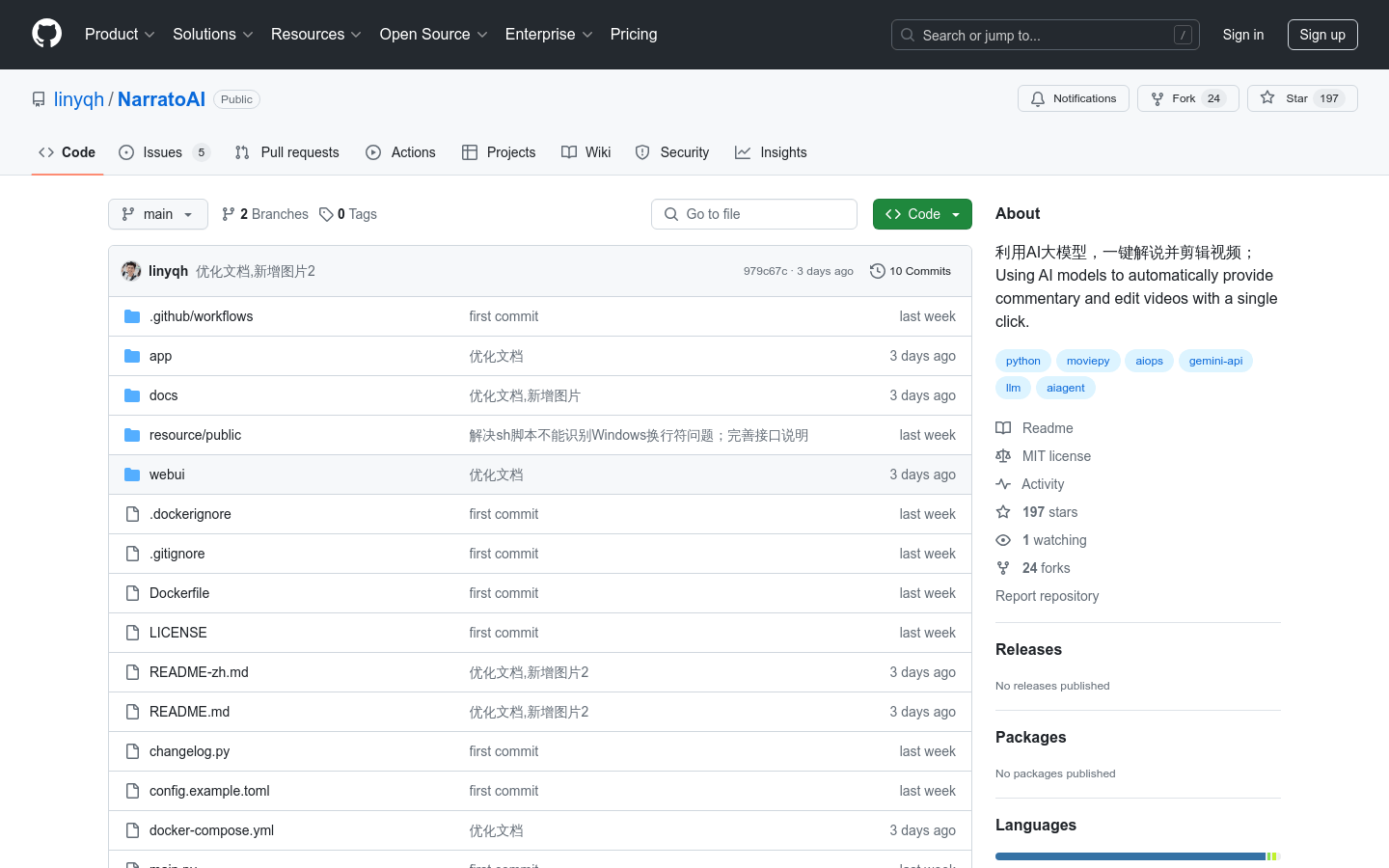
NarratoAI是一个利用AI大模型,一键解说并剪辑视频的工具。它提供了剧本编写、自动视频剪辑、配音和字幕生成的一站式解决方案,由LLM驱动,以提高内容创作的效率。
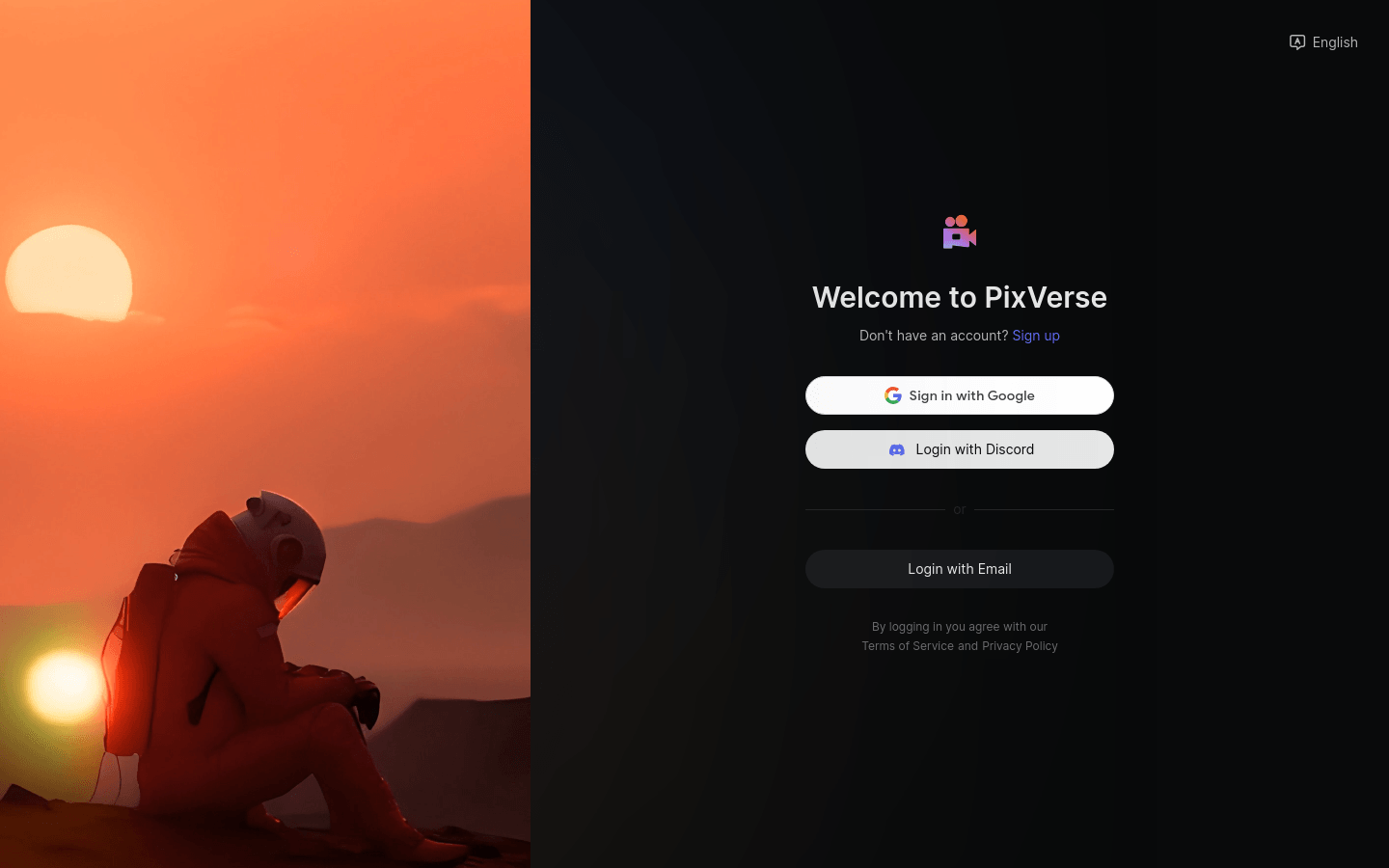
PixVerse 是一款创新的 AI 视频创作平台,旨在帮助用户轻松创建高质量的视频内容。通过先进的生成式 AI 技术,PixVerse 能够将文本、图像和角色转换为生动的视频,极大地提升了创作的效率与灵活性。无论是专业的内容创作者还是普通用户,PixVerse 都提供了强大的工具来实现他们的创意。此平台的易用性和强大的功能使其在市场中独树一帜,适合各类视频制作需求。
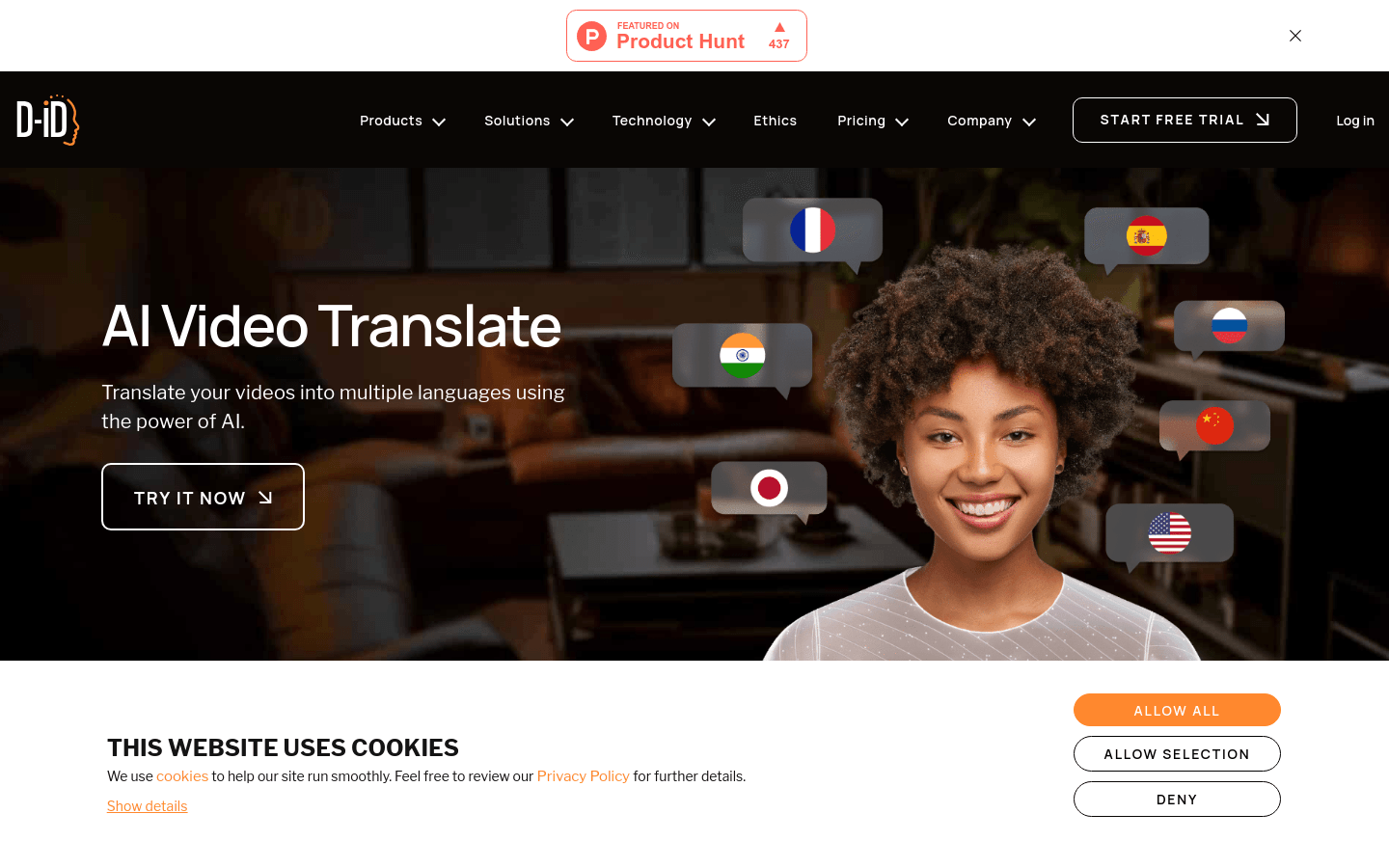
D-ID的AI Video Translate是一款利用人工智能技术,将视频内容自动翻译成多种语言的产品。它通过声音克隆和唇部动作适配技术,确保翻译后的视频在语言和视觉上都能保持自然和真实性。这项技术对于希望扩大全球观众范围的市场营销团队、销售团队、教育工作者和内容创作者来说非常重要。它不仅降低了传统视频制作的麻烦和成本,还通过本地化视频内容,帮助企业扩大影响力。
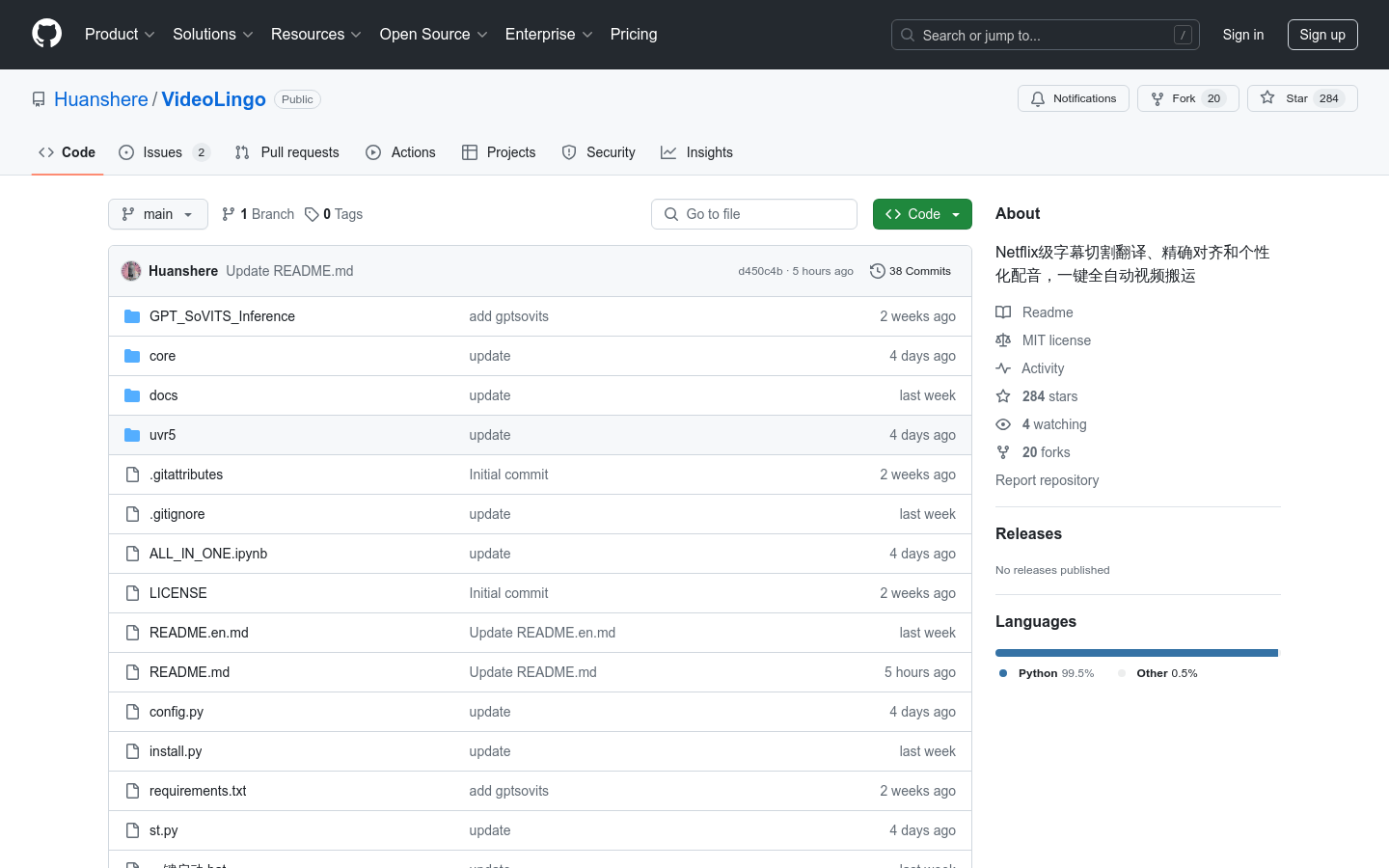
VideoLingo是一个基于人工智能的视频字幕生成工具,它利用自然语言处理(NLP)和大型语言模型(LLM)进行字幕分割和上下文感知翻译。该产品支持一键启动,用户可以在Streamlit界面上轻松操作,实现视频的字幕生成和配音。它具有极低成本、高质量的个性化配音和精确的单词级字幕对齐等特点,非常适合需要跨语言视频内容的创作者和教育工作者。
ReSyncer是一个创新的框架,致力于通过先进的风格注入Transformer技术,实现音频与视频的高效同步。它不仅能够生成高保真的唇形同步视频,还支持快速个性化微调、视频驱动的唇形同步、说话风格的转换,甚至面部交换等特性。这些功能对于创建虚拟主持人和表演者至关重要,能够显著提升视频内容的自然度和真实感。
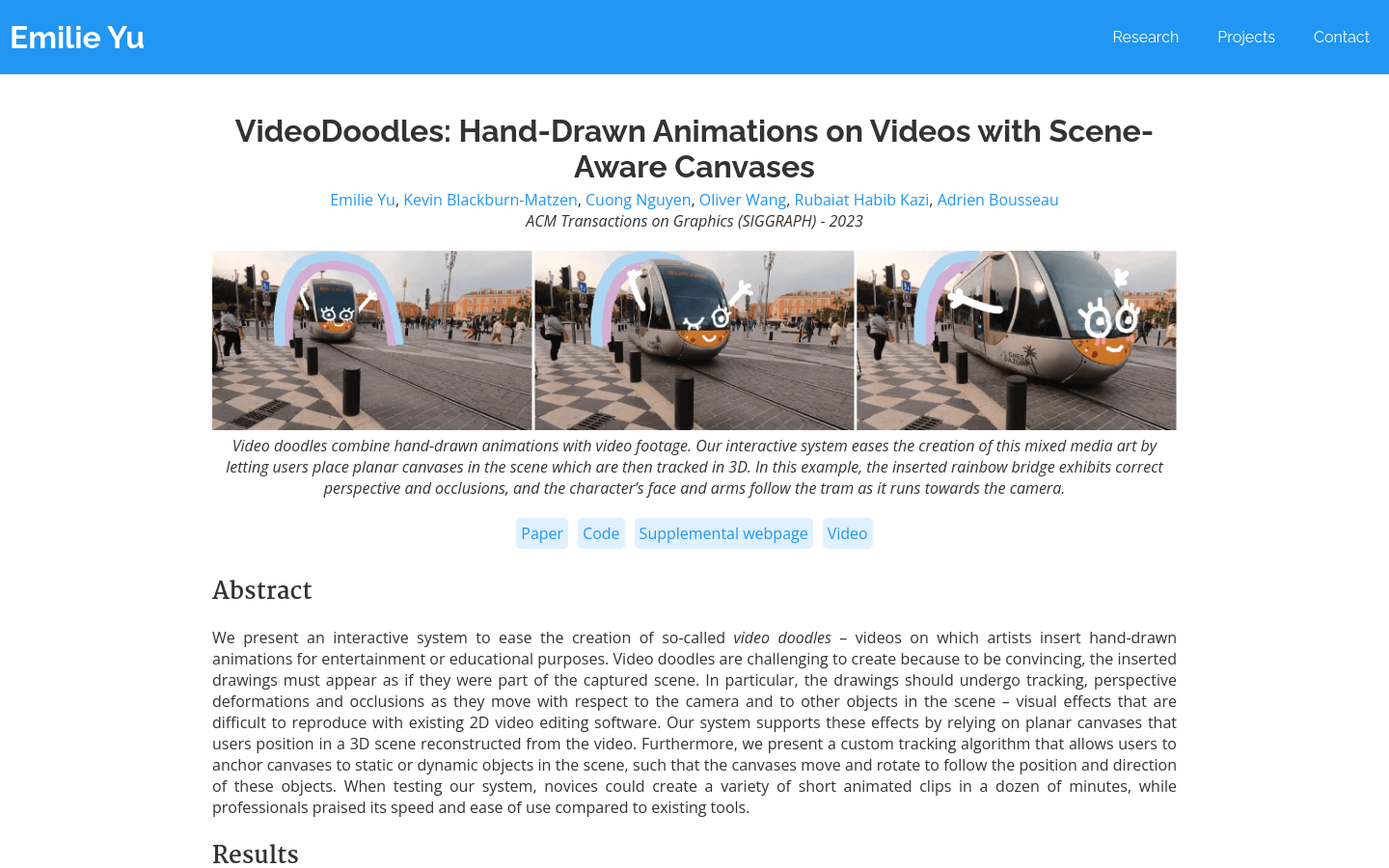
VideoDoodles是一个交互式系统,它通过让用户在3D场景中放置平面画布,然后对这些画布进行追踪,以简化视频涂鸦的创作过程。这种技术允许手绘动画在视频中具有正确的透视变形和遮挡效果,并且能够随着摄像机和其他场景中的对象移动而移动。该系统支持用户通过2D图像空间UI精细控制画布,通过关键帧设置位置和方向,并自动插值关键帧以追踪视频中移动对象的运动。
ComfyUI-CogVideoXWrapper 是一个基于Python的视频处理模型,它通过使用T5模型进行视频内容的生成和转换。该模型支持从图像到视频的转换工作流程,并在实验阶段展现出有趣的效果。它主要针对需要进行视频内容创作和编辑的专业用户,尤其是在视频生成和转换方面有特殊需求的用户。
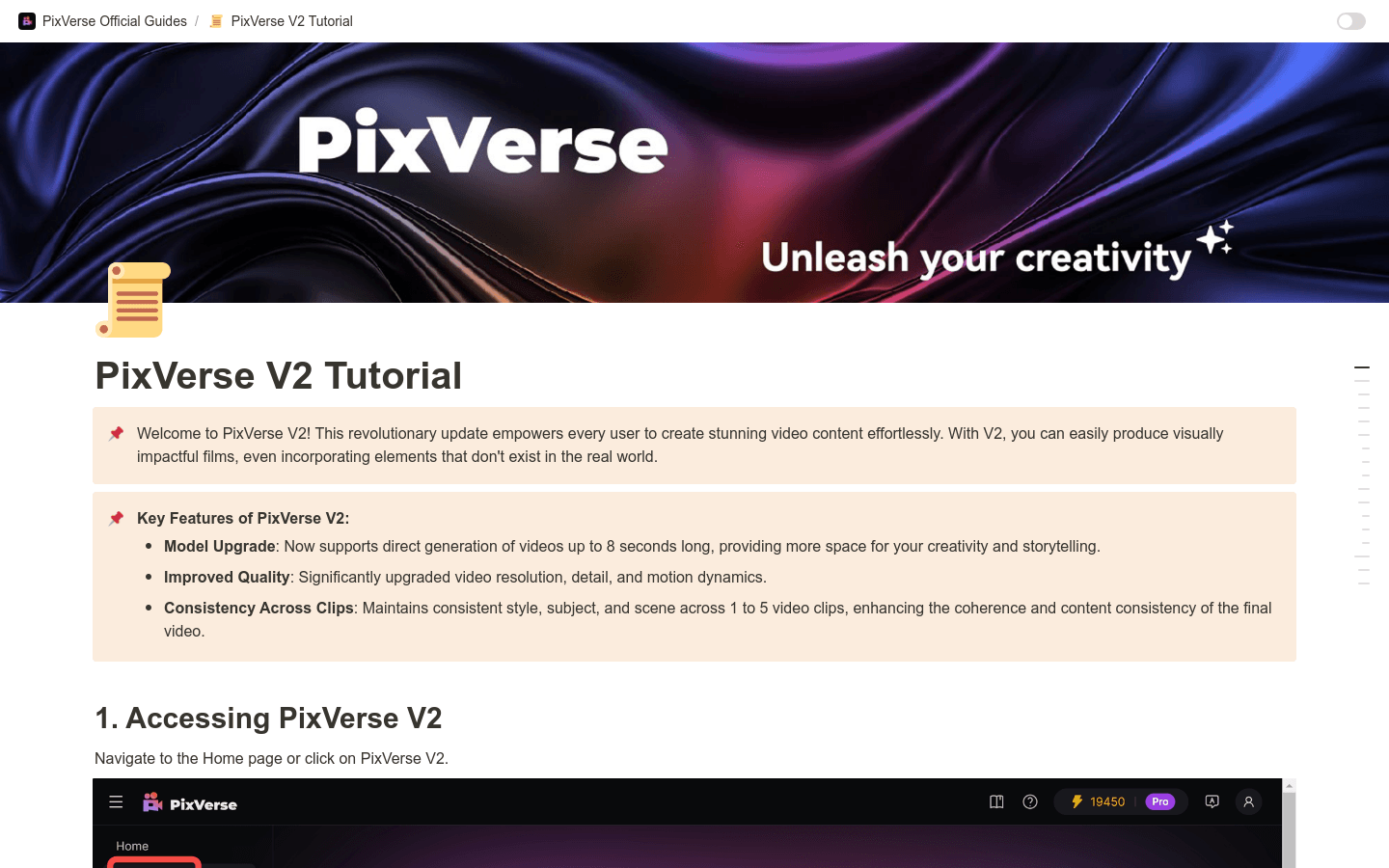
PixVerse V2是一个革命性的更新,它赋予每个用户轻松创建令人惊叹的视频内容的能力。使用V2,您可以轻松制作视觉冲击力强的电影,甚至可以加入现实世界中不存在的元素。主要优点包括模型升级、画质提升、剪辑间的一致性等。
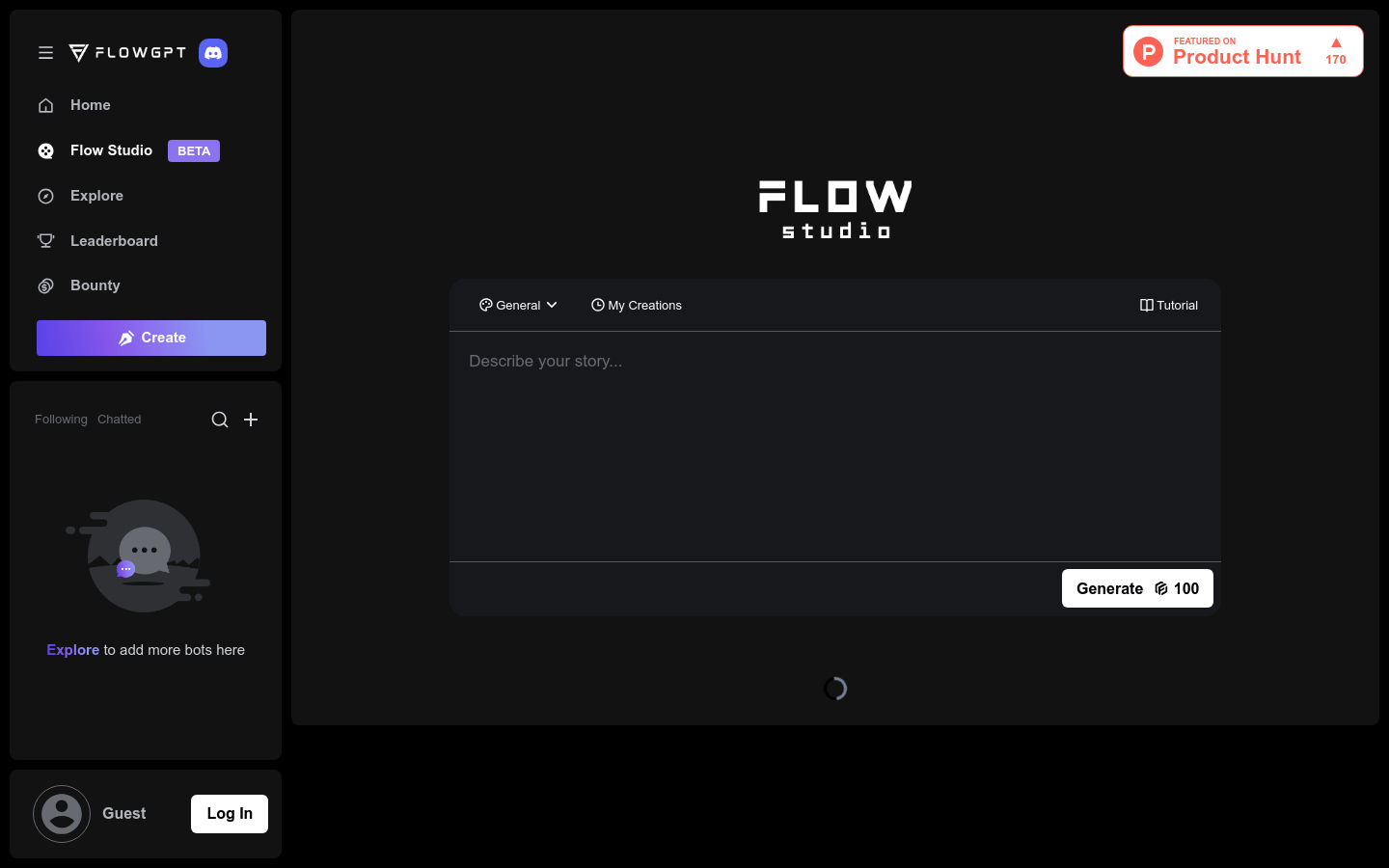
Flow Studio 是一个基于人工智能技术的视频生成平台,专注于为用户提供高质量、个性化的视频内容。该平台利用先进的AI算法,能够在短时间内生成3分钟的视频,效果优于Luma、Pika和Sora等同类产品。用户可以通过选择不同的模板、角色和场景,快速创建出具有吸引力的视频内容。Flow Studio 的主要优点包括生成速度快、效果逼真、操作简便等。
FasterLivePortrait是一个基于深度学习的实时肖像动画化项目。它通过使用TensorRT在RTX 3090 GPU上实现30+ FPS的实时运行速度,包括预处理和后处理,而不仅仅是模型推理速度。该项目还实现了将LivePortrait模型转换为Onnx模型,并在RTX 3090上使用onnxruntime-gpu实现约70ms/帧的推理速度,支持跨平台部署。此外,该项目还支持原生gradio app,速度提升数倍,并支持多张人脸的同时推理。代码结构经过重构,不再依赖PyTorch,所有模型使用onnx或tensorrt进行推理。
Jockey是一个基于Twelve Labs API和LangGraph构建的对话式视频代理。它将现有的大型语言模型(Large Language Models, LLMs)的能力与Twelve Labs的API结合使用,通过LangGraph进行任务分配,将复杂视频工作流程的负载分配给适当的基础模型。LLMs用于逻辑规划执行步骤并与用户交互,而与视频相关的任务则传递给由视频基础模型(Video Foundation Models, VFMs)支持的Twelve Labs API,以原生方式处理视频,无需像预先生成的字幕这样的中介表示。
NVIDIA Broadcast App 是一款利用人工智能技术,为直播和视频会议提供高质量语音和视频效果的应用。它通过智能降噪、虚拟背景、眼神接触增强等功能,为用户提供专业级别的直播体验。这款应用特别适合内容创作者、游戏主播和需要进行远程视频会议的专业人士。它的优势在于能够显著提升视频内容的质量,同时简化直播流程,无需昂贵的硬件设备。
DJI Mimo 是大疆创新为手持稳定设备打造的专属应用,它不仅能够精准控制云台相机,实现实时预览拍摄画面,还提供了一系列智能功能和专业模式,以激发用户的创作灵感。该应用支持蓝牙或Wi-Fi无线连接,具备人脸识别和美颜功能,提供视频剪辑功能,包括字幕、贴纸、特效、音乐等多轨道编辑。AI自动化剪辑能力,智能分析素材提取高光片段,一键成片。此外,DJI Mimo 还提供海量主题模板,丰富的编辑素材资源,以及专业编辑器功能,适合新手和专业用户使用。
FoleyCrafter是一个基于文本的视频到音频生成框架,能够生成与输入视频语义相关且时间同步的高质量音频。该技术在视频制作领域具有重要意义,特别是在后期制作过程中,可以大大提升效率和音频质量。它由上海人工智能实验室和香港中文大学(深圳)共同研发。
PAB 是一种用于实时视频生成的技术,通过 Pyramid Attention Broadcast 实现视频生成过程的加速,提供了高效的视频生成解决方案。该技术的主要优点包括实时性、高效性和质量保障。PAB 适用于需要实时视频生成能力的应用场景,为视频生成领域带来了重大突破。
Diffutoon是一种先进的动漫风格渲染技术,能够将逼真的视频转换成动漫风格,适用于高分辨率和快速运动的视频。源代码已在DiffSynth-Studio发布,同时发布了技术报告。
Final Cut Pro 是 Apple 推出的专业视频编辑软件,适用于 iPad 和 Mac 设备。最新版本利用了 M4 芯片的强大性能,提供了更快的渲染速度和对 ProRes RAW 视频流的增强支持。新增的 AI 功能,包括“优化光线和颜色”和“流畅慢动作”,以及改进的素材管理工具,极大地提升了视频编辑的效率和质量。
DeepFuze是与ComfyUI无缝集成的先进深度学习工具,用于革新面部转换、lipsyncing、视频生成、声音克隆和lipsync翻译。利用先进的算法,DeepFuze使用户能够以无与伦比的真实性结合音频和视频,确保完美的面部动作同步。这一创新解决方案非常适合内容创作者、动画师、开发者以及任何希望以先进的AI驱动功能提升其视频编辑项目的人士。
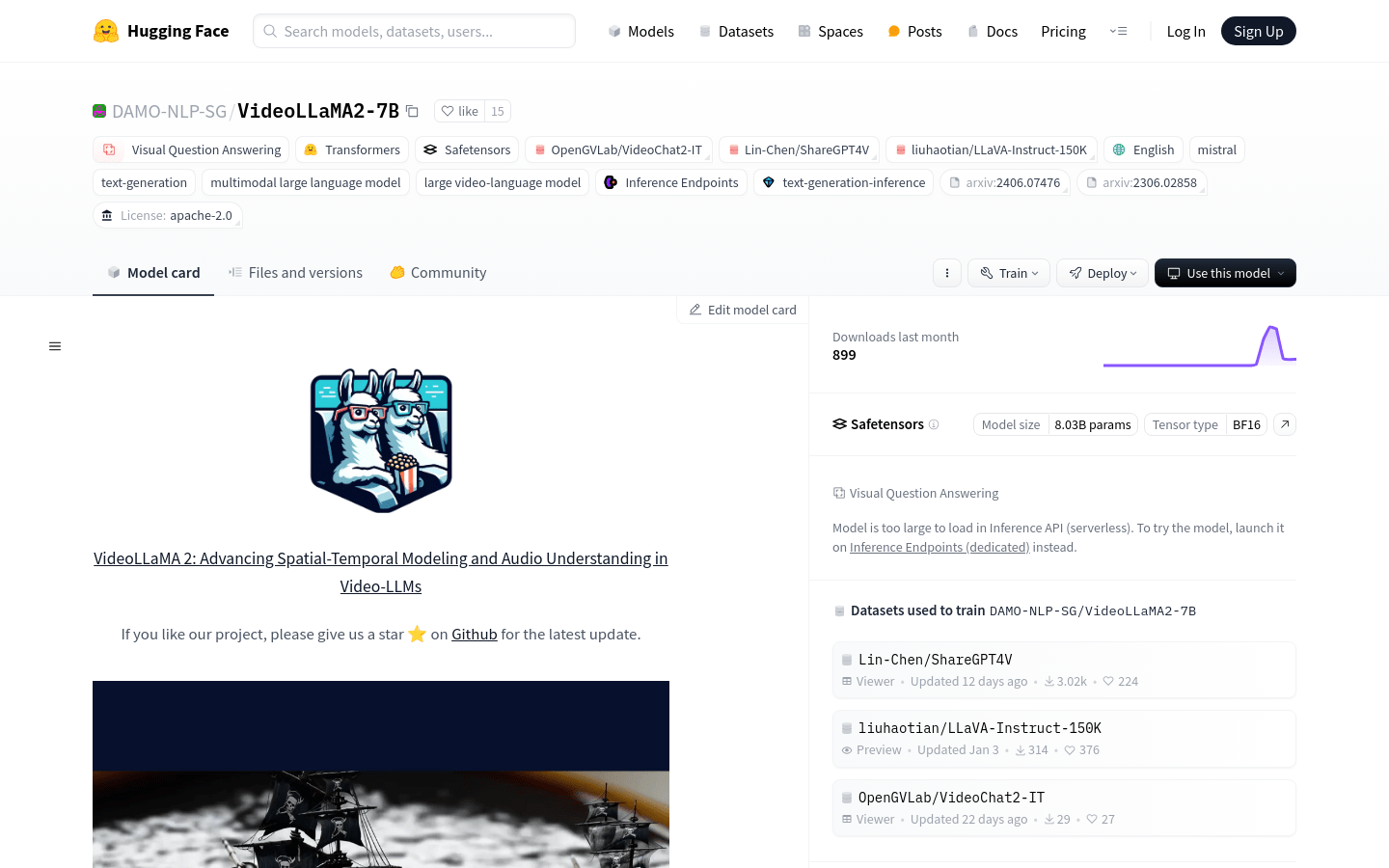
VideoLLaMA2-7B是由DAMO-NLP-SG团队开发的多模态大型语言模型,专注于视频内容的理解和生成。该模型在视觉问答和视频字幕生成方面具有显著的性能,能够处理复杂的视频内容,并生成准确、自然的语言描述。它在空间-时间建模和音频理解方面进行了优化,为视频内容的智能分析和处理提供了强大的支持。
VideoLLaMA2-7B-Base 是由 DAMO-NLP-SG 开发的大型视频语言模型,专注于视频内容的理解与生成。该模型在视觉问答和视频字幕生成方面展现出卓越的性能,通过先进的空间时间建模和音频理解能力,为用户提供了一种新的视频内容分析工具。它基于 Transformer 架构,能够处理多模态数据,结合文本和视觉信息,生成准确且富有洞察力的输出。
VideoLLaMA2-7B-16F-Base是由DAMO-NLP-SG团队开发的大型视频语言模型,专注于视频问答(Visual Question Answering)和视频字幕生成。该模型结合了先进的空间-时间建模和音频理解能力,为多模态视频内容分析提供了强大的支持。它在视觉问答和视频字幕生成任务上展现出卓越的性能,能够处理复杂的视频内容并生成准确的描述和答案。
MotionFollower是一个轻量级的得分引导扩散模型,用于视频运动编辑。它通过两个轻量级信号控制器,分别对姿势和外观进行控制,不涉及繁重的注意力计算。该模型设计了基于双分支架构的得分引导原则,包括重建和编辑分支,显著增强了对纹理细节和复杂背景的建模能力。实验表明,MotionFollower在GPU内存使用上比最先进的运动编辑模型MotionEditor减少了约80%,同时提供了更优越的运动编辑性能,并独家支持大范围的摄像机运动和动作。
Detail是一款专为iPad设计的APP,适用于TikTok爱好者、播客创作者和Instagram影响者。它集成了强大的视频编辑器、便捷的提词器、智能字幕和尖端的摄像技术,通过AI驱动的编辑功能和即时视频预设,使创建惊人视频变得快速而简单。
快影是快手官方推出的视频剪辑应用,提供全面的视频编辑功能,包括剪辑、音频、字幕、特效等,旨在帮助用户轻松创作出有趣且专业的视频内容。它具备AI动漫视频功能,能够将视频转化为动漫风格,提供多种风格选择,如动漫风、国潮风、日漫风等。此外,快影还拥有AI创作工具,如AI绘画、AI文生图、AI文案库,以辅助用户进行创作。快影还提供创作中心,帮助用户查看数据、寻找灵感,以及提供强大的素材库,包括贴纸、热梗等,以提升用户的网感。
ViViD是一个利用扩散模型进行视频虚拟试穿的新框架。它通过设计服装编码器提取精细的服装语义特征,并引入轻量级姿态编码器以确保时空一致性,生成逼真的视频试穿效果。ViViD收集了迄今为止规模最大、服装类型最多样化、分辨率最高的视频虚拟试穿数据集。
I2VEdit是一种创新的视频编辑技术,通过预训练的图像到视频模型,将单一帧的编辑扩展到整个视频。这项技术能够适应性地保持源视频的视觉和运动完整性,并有效处理全局编辑、局部编辑以及适度的形状变化,这是现有方法所不能实现的。I2VEdit的核心包括两个主要过程:粗略运动提取和外观细化,通过粗粒度注意力匹配进行精确调整。此外,还引入了跳过间隔策略,以减轻多个视频片段自动回归生成过程中的质量下降。实验结果表明,I2VEdit在细粒度视频编辑方面的优越性能,证明了其能够产生高质量、时间一致的输出。
StreamV2V是一个扩散模型,它通过用户提示实现了实时的视频到视频(V2V)翻译。与传统的批处理方法不同,StreamV2V采用流式处理方式,能够处理无限帧的视频。它的核心是维护一个特征库,该库存储了过去帧的信息。对于新进来的帧,StreamV2V通过扩展自注意力和直接特征融合技术,将相似的过去特征直接融合到输出中。特征库通过合并存储的和新的特征不断更新,保持紧凑且信息丰富。StreamV2V以其适应性和效率脱颖而出,无需微调即可与图像扩散模型无缝集成。
ComfyUI ProPainter Nodes 是基于 ProPainter 框架的视频修补插件,利用流传播和时空转换器实现高级视频帧编辑,适用于无缝修补任务。该插件具有用户友好的界面和强大的功能,旨在简化视频修补过程。
video-subtitle-master 是一个基于之前开源项目 VideoSubtitleGenerator 开发的客户端工具,它允许用户批量为视频生成字幕,并支持将字幕翻译成不同的语言。这个工具特别适合需要对视频内容进行本地化处理的个人或团队,无论是为了教育、娱乐还是商业目的。它集成了多种翻译服务,如百度翻译、火山引擎翻译等,并优化了对 Apple Silicon 的支持,提供了快速的生成速度。
ReVideo是一个创新的视频编辑技术,它允许用户在特定区域进行精确的视频编辑,通过指定内容和运动来实现。这项技术通过修改第一帧来实现内容编辑,而基于轨迹的运动控制提供了直观的用户交互体验。ReVideo解决了内容和运动控制之间耦合和训练不平衡的新任务。通过开发三阶段训练策略,逐步从粗到细解耦这两方面,并提出一种时空自适应融合模块,以在不同的采样步骤和空间位置整合内容和运动控制。
KREA Video 是一款在线视频生成和增强工具,它利用先进的人工智能技术,为用户提供实时视频生成和编辑功能。它允许用户上传图片或文本提示,生成具有动画效果的视频,并且可以调整视频的时长和关键帧。KREA Video 的主要优点是操作简便,用户界面友好,能够快速生成高质量的视频内容,适用于内容创作者、广告制作者和视频编辑专业人士。
Slicedit是一种零样本视频编辑技术,它利用文本到图像的扩散模型,并结合时空切片来增强视频编辑中的时序一致性。该技术能够保留原始视频的结构和运动,同时符合目标文本描述。通过广泛的实验,证明了Slicedit在编辑真实世界视频方面具有明显优势。
FunClip是一款完全开源、本地部署的自动化视频剪辑工具,通过调用阿里巴巴通义实验室开源的FunASR Paraformer系列模型进行视频的语音识别,随后用户可以自由选择识别结果中的文本片段或说话人,点击裁剪按钮即可获取对应片段的视频。FunClip集成了阿里巴巴开源的工业级模型Paraformer-Large,是当前识别效果最优的开源中文ASR模型之一,并且能够一体化的准确预测时间戳。
Video Mamba Suite 是一个用于视频理解的新型状态空间模型套件,旨在探索和评估Mamba在视频建模中的潜力。该套件包含14个模型/模块,覆盖12个视频理解任务,展示了在视频和视频-语言任务中的高效性能和优越性。
HitPaw Edimakor是一款功能强大的高级AI视频编辑器,旨在帮助您以简单创意的方式编辑视频。它提供了无限轨道的时间轴上轻松编辑工具,包括贴纸、转场、滤镜、文字等,可以轻松创建令人惊艳的视频。它还具有AI驱动的功能,如语音转文本、AI脚本生成、AI音频编辑等。HitPaw Edimakor适用于创意专业人士和想要将多个视频片段制作成令人难忘的蒙太奇的个人用户。
Video-subtitle-remover (VSR) 是一款基于AI技术,将视频中的硬字幕去除的软件。主要功能包括无损分辨率去除视频中的硬字幕,通过AI算法模型对去除字幕的区域进行填充,支持自定义字幕位置去除,以及批量去除图片水印文本。优势在于无需第三方API,本地实现,操作简便,效果显著。
FocuSee 自动跟踪光标移动,应用动态缩放效果,为您节省宝贵时间和额外的努力。适用于演示,教程,推广视频等多种场景。
VASA-1是由微软研究院开发的一个模型,专注于实时生成与音频相匹配的逼真人脸动画。该技术通过深度学习算法,能够根据输入的语音内容,自动生成相应的口型和面部表情,为用户提供一种全新的交互体验。VASA-1的主要优势在于其高度逼真的生成效果和实时响应能力,使得虚拟角色能够更加自然地与用户进行互动。目前,VASA-1主要应用于虚拟助手、在线教育、娱乐等领域,其定价策略尚未公布,但预计将提供免费试用版本供用户体验。
Ctrl-Adapter是一个专门为视频生成设计的Controlnet,提供图像和视频的精细控制功能,优化视频时间对齐,适配多种基础模型,具备视频编辑能力,显著提升视频生成效率和质量。
Adobe Premiere Pro是一款功能强大的视频编辑软件,集成了AI技术,旨在简化复杂的编辑任务并加速编辑流程。软件提供了文本基础编辑、音频分类标签、语音转文字、增强语音、场景检测、自动色彩调整、形态变换、颜色匹配、音频自动调节、自动重构等功能,大大提高了编辑效率和创作可能性。Premiere Pro适用于社交媒体短视频制作到长片电影的编辑,帮助用户节省时间,专注于创意和故事讲述。今年晚些时候,Adobe Premiere Pro计划推出第三方AI模型功能,使编辑人员能够选择最适合其素材的模型,从而提升编辑体验。这些AI模型包括OpenAI的Sora模型、Runway AI和Pika的视频模型。此外,Premiere Pro还将提供内容验证功能,帮助用户了解他们是否使用了AI以及使用了哪个模型来进行媒体创作。
MA-LMM是一种基于大语言模型的大规模多模态模型,主要针对长期视频理解进行设计。它采用在线处理视频的方式,并使用记忆库存储过去的视频信息,从而可以在不超过语言模型上下文长度限制或GPU内存限制的情况下,参考历史视频内容进行长期分析。MA-LMM可以无缝集成到当前的多模态语言模型中,并在长视频理解、视频问答和视频字幕等任务上取得了领先的性能。
SpatialTracker 是 CVPR 2024 年亮点之一的一项研究成果,致力于在 3D 空间中恢复视频中密集的像素运动。该方法通过将 2D 像素提升到 3D 空间,使用三平面表示表示每一帧的 3D 内容,并迭代更新转换器来估计 3D 轨迹。在 3D 中跟踪允许我们利用刚性约束,同时学习一个刚性嵌入,将像素聚集到不同的刚性部分中。与其他追踪方法相比,SpatialTracker 在质量和量度方面都取得了优异的成绩,尤其是在具有出平面旋转的具有挑战性的情况下。
Google Vids是一款强大的在线视频编辑器,集成了谷歌Gemini技术,为您提供AI驱动的视频创作解决方案。您可以使用它快速创建富媒体视频内容,适用于工作、项目演示、教学等多种场景。Google Vids支持全面的视频编辑功能,包括剪辑、转场特效、字幕添加等,并提供多种模板供您选择,大幅提升视频创作效率。作为Google Workspace的一部分,Google Vids与其他生产力应用无缝协作,为您的数字化办公赋能。
MiniGPT4-Video是为视频理解设计的多模态大模型,能处理时态视觉数据和文本数据,配标题、宣传语,适用于视频问答。基于MiniGPT-v2,结合视觉主干EVA-CLIP,训练多阶段阶段,包括大规模视频-文本预训练和视频问题解答微调。在MSVD、MSRVTT、TGIF和TVQA基准上取得显著提升。定价未知。
AI Webcam Effects + Recorder是一款功能强大的插件,提供视频增强、美颜滤镜、虚拟背景、自定义品牌等多种功能。它适用于Google Meet、Zoom、Discord等在线会议,并且能够在各种主流视频会议平台上使用。用户可以通过这个插件实现背景虚化、更换背景图片或视频、使用专业的滤镜和颜色校正、添加动画表情和GIF等。同时,该插件还支持本地录制、优化网络连接等功能,可以为用户提供更出色的在线会议体验。
AnyV2V是一个创新的视频到视频编辑框架,允许用户使用任何现成的图像编辑工具编辑视频的第一帧,然后使用现有的图像到视频生成模型进行图像到视频的重建。这种方法使得各种编辑任务变得简单,包括基于提示的编辑、样式转换、主题驱动的编辑和身份操纵。
HeyGen 5.0是一款下一代AI视频平台。它拥有数字化虚拟人物、语音转文本和视频翻译等技术,任何人都可以轻松制作出工作室级别的高质量视频。该平台的主要特点包括:先进的AI工作室,为用户提供更多音频、元素、动画等灵活控制,轻松创建令人难忘的视频内容。大规模批量化制作个性化视频,适用于获取销售线索、欢迎新员工入职、面向学生等各种场合。站在科技前沿,为团队每个成员赋能视觉讲述能力。HeyGen 5.0致力于让每个人都能创建吸引人的视频内容,成为视觉讲述大师。
MOTIA是一个基于测试时适应的扩散方法,利用源视频内的内在内容和运动模式来有效进行视频外延画。该方法包括内在适应和外在渲染两个主要阶段,旨在提升视频外延画的质量和灵活性。
该产品通过AI技术实现视频语音的自动配音和口型同步,可以轻松实现视频的多语种翻译,并保留原始音色。主要特点包括:1)33%以上的同步精度,媲美人工口型同步;2)无损视频分辨率;3)高保真语音翻译。面向的群体包括:企业培训部门、销售人员、营销团队和内容创作者。提供免费入门版和付费专业版,欢迎体验。
Open-Sora是一个开源项目,旨在高效生成高质量视频,并将模型、工具和内容开放给所有人使用。通过拥抱开源原则,Open-Sora不仅民主化了获取先进视频生成技术的途径,还提供了一个简化了视频制作复杂性的流畅、用户友好的平台。我们的目标是通过Open-Sora来激发创新、创意和内容创作的包容性。该项目目前处于早期阶段,正在积极开发中。Open-Sora支持完整的视频数据预处理、加速训练、推理等流程。提供的权重可在只经过3天训练后生成2秒512x512分辨率的视频。Open-Sora还通过改进训练策略实现了46%的成本降低。
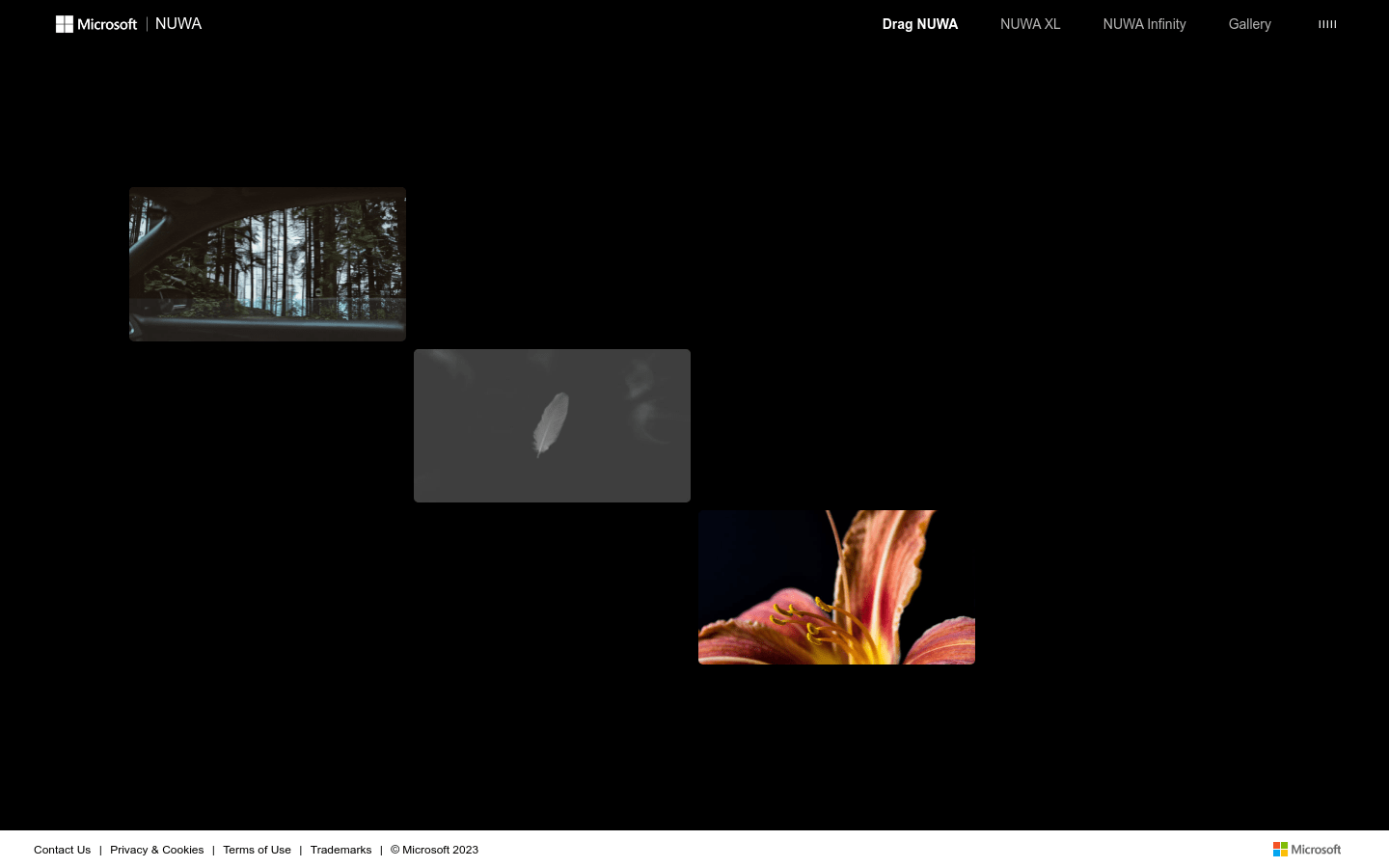
NUWA-XL是微软开发的前沿多模态生成模型,能够根据提供的脚本以“粗到细”的过程生成极长视频。该模型能够产生高质量、多样化且有趣的视频剪辑,并具有真实的镜头变化。
FlexClip AI URL转视频是由FlexClip推出的在线AI 网页生成视频插件,可以提取网页的主要内容,并自动匹配适当的媒体资源来生成视频。在生成过程中,您可以编辑内容并替换视频和图片,以获得更满意的结果。
Anything in Any Scene是一个用于在现有动态视频中无缝插入任何物体的通用框架,强调物理真实性。该框架包含三个关键过程:1) 将真实物体与给定场景视频相结合,确保几何真实性;2) 估计天空和环境光照分布,模拟逼真阴影,增强光照真实性;3) 采用风格迁移网络,提高最终视频输出的逼真度。该框架能生成具有高度几何真实性、光照真实性和逼真度的模拟视频。
Boximator是一款由Jiawei Wang、Yuchen Zhang等人开发的智能视频合成工具。它利用先进的深度学习技术,通过添加文本提示和额外的盒子约束,生成丰富且可控制的视频运动。用户可以通过示例或自定义文本来创造独特的视频场景。Boximator与其他方法相比,使用了来自文本提示的附加盒子约束,提供更灵活的运动控制。
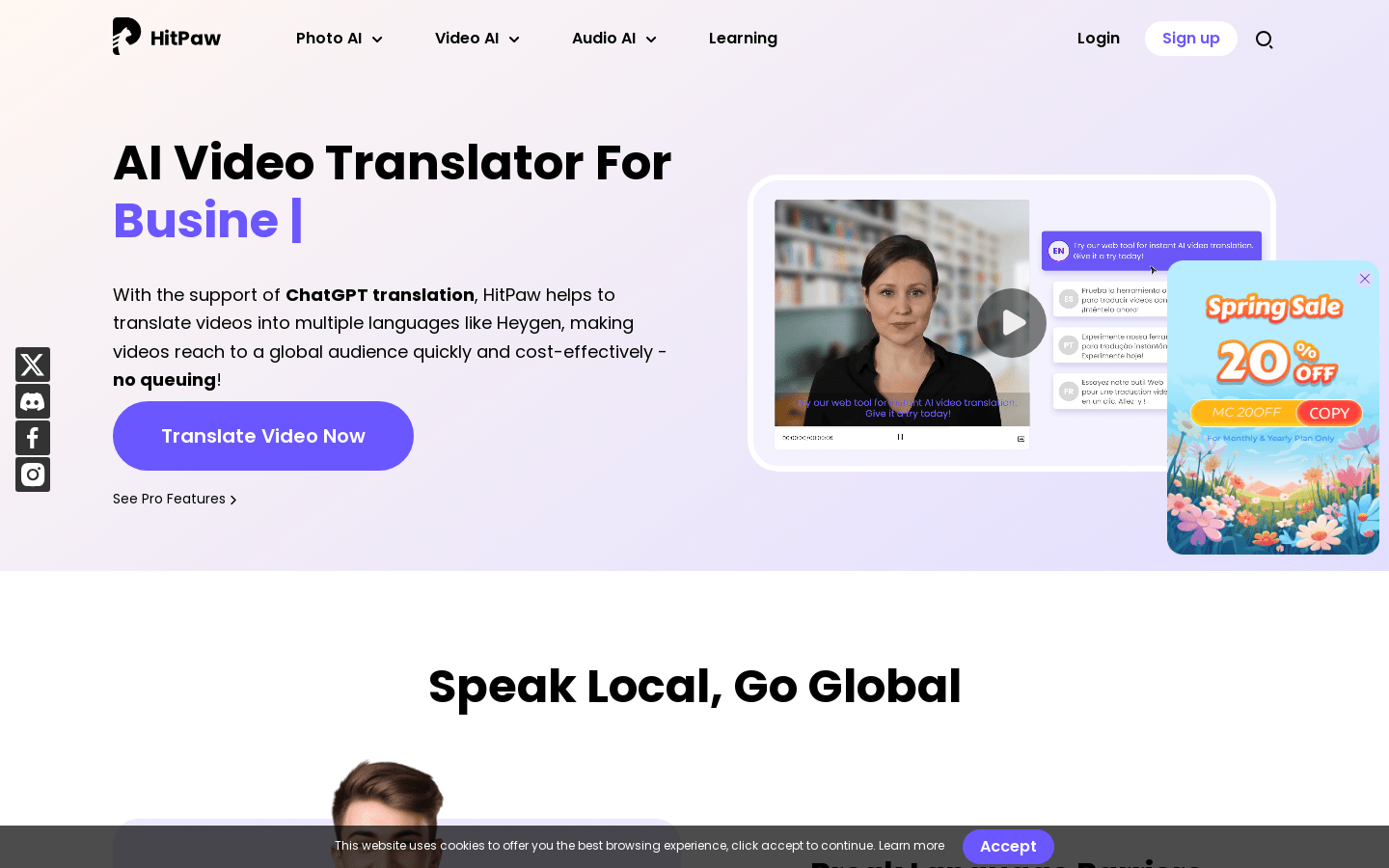
HitPaw Online AI Video Translator是一款先进的AI视频翻译服务,支持多种语言选择,使您的视频内容能够触达全球观众。同时,它还提供语音转文字和文字转语音的在线工具,能够准确地将音频转录为多种语言。产品还包含多项AI功能,如语音克隆、唇语同步、自动生成字幕、AI视频生成器、实时语音变换等。通过自动将视频翻译成多种语言,HitPaw Online AI Video Translator能够帮助视频内容快速、高效、经济地触达全球受众。
HitPaw Online Video Enhancer 4K是一款基于AI训练的视频增强器,可一键去模糊和提升视频分辨率,是最佳的在线视频增强器,支持提高低分辨率视频,将视频分辨率提升至1080P/4K,操作简单,效果显著。
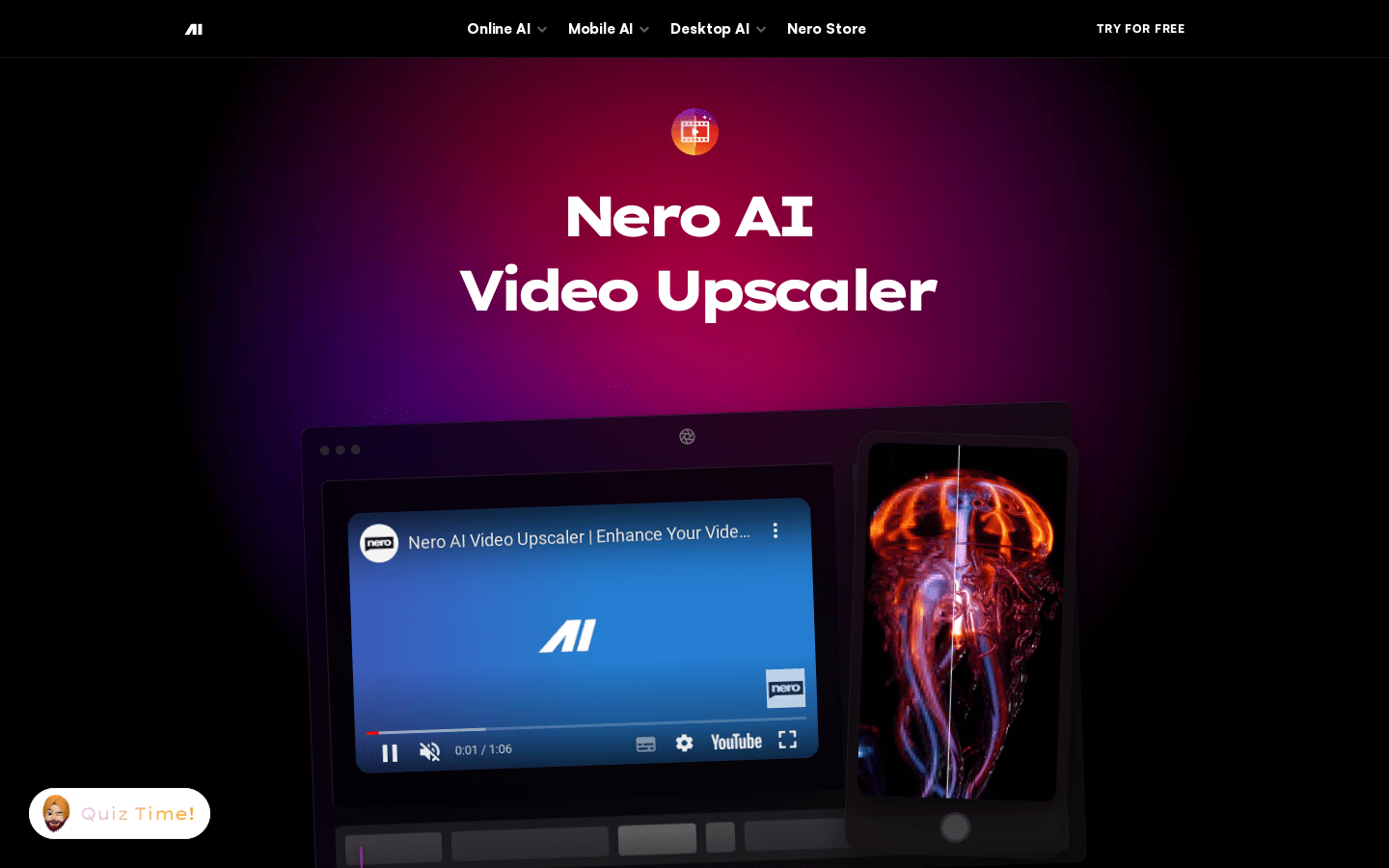
Nero AI视频升频器是一款AI运动跟踪视频编辑工具。可以对视频中的人脸进行模糊处理,隐藏商标,模糊车牌等。在Microsoft商店中体验。
这篇论文研究了视频Transformer表示的概念解释问题。具体而言,我们试图解释基于高级时空概念的视频Transformer的决策过程,这些概念是自动发现的。以往关于基于概念的可解释性的研究仅集中在图像级任务上。相比之下,视频模型处理了额外的时间维度,增加了复杂性,并在识别随时间变化的动态概念方面提出了挑战。在这项工作中,我们通过引入第一个视频Transformer概念发现(VTCD)算法系统地解决了这些挑战。为此,我们提出了一种有效的无监督视频Transformer表示单元(概念)识别方法,并对它们在模型输出中的重要性进行排名。所得的概念具有很高的可解释性,揭示了非结构化视频模型中的时空推理机制和以对象为中心的表示。通过在多样的监督和自监督表示上联合进行这种分析,我们发现其中一些机制在视频Transformer中是普遍的。最后,我们证明VTCD可以用于改善精细任务的模型性能。
FMA-Net是一个用于视频超分辨率和去模糊的深度学习模型。它可以将低分辨率和模糊的视频恢复成高分辨率和清晰的视频。该模型通过流引导的动态过滤和多注意力的迭代特征精炼技术,可以有效处理视频中的大动作,实现视频的联合超分辨率和去模糊。该模型结构简单、效果显著,可以广泛应用于视频增强、编辑等领域。
ANIM-400K是一个包含超过425,000个对齐的日语和英语动画视频片段的综合数据集,支持自动配音、同声翻译、视频摘要、流派/主题/风格分类等各种视频相关任务。该数据集公开用于研究目的。
该产品提供了一种新颖的框架,用于平滑跳切,特别是在对话视频中。它利用视频中主体的外观,通过 DensePose 关键点和面部标志驱动的中级表示来融合其他源帧中的信息。为了实现运动,它在切割周围的端帧之间插值关键点和标志。然后使用图像转换网络从关键点和源帧合成像素。由于关键点可能包含错误,因此提出了一种跨模态注意机制,以选择和为每个关键点挑选最合适的源。通过利用这种中级表示,我们的方法可以比强视频插值基准获得更强的结果。我们在对话视频的各种跳切上展示了我们的方法,例如切除填充词、暂停,甚至随机切割。我们的实验表明,即使在对话头部旋转或剧烈移动的挑战性情况下,我们也可以实现无缝过渡。
Vista-LLaMA是一种先进的视频语言模型,旨在改善视频理解。它通过保持视觉令牌与语言令牌之间的一致距离,无论生成文本的长度如何,都能减少与视频内容无关的文本产生。这种方法在计算视觉与文本令牌之间的注意力权重时省略了相对位置编码,使视觉令牌在文本生成过程中的影响更为显著。Vista-LLaMA还引入了一个顺序视觉投影器,能够将当前视频帧投影到语言空间的令牌中,捕捉视频内的时间关系,同时减少了对视觉令牌的需求。在多个开放式视频问答基准测试中,该模型的表现显著优于其他方法。
FreeInit是一个简单有效的方法,用于提高视频生成模型的时间一致性。它不需要额外的训练,也不引入可学习的参数,可以很容易地在任意视频生成模型的推理时集成使用。
CoTracker是一个基于Transformer的模型,可以在视频序列中联合跟踪稠密点。它与大多数现有的状态最先进的方法不同,后者独立跟踪点,而忽略了它们之间的相关性。我们展示了联合跟踪可以显著提高跟踪精度和鲁棒性。我们还提供了若干技术创新,包括虚拟轨迹的概念,这使CoTracker可以联合跟踪7万个点。此外,CoTracker因果地操作在短时间窗口上(因此适合在线任务),但通过在更长的视频序列上展开窗口进行训练,这使并显著改进了长期跟踪。我们展示了定性印象深刻的跟踪结果,其中点甚至在遮挡或离开视野时也可以跟踪很长时间。从定量上看,CoTracker在标准基准测试上优于所有最近的跟踪器,通常优势显著。
Minta是一个AI产品视频制作器,可以自动化社交媒体促销视频的制作过程。它提供200多个社交视频发布模板,帮助品牌在TikTok、Facebook、Instagram和Pinterest上自动发布产品促销视频。Minta还提供自动翻译的文本、专业版和增长版定价选项。
FlowVid 是一个光流引导的视频合成模型,通过利用光流的空间和时间信息,实现视频帧之间的时序一致性。它可以与现有的图像合成模型无缝配合,实现多种修改操作,包括风格化、对象交换和局部编辑等。FlowVid 生成速度快,4 秒、30FPS、512×512 分辨率的视频只需 1.5 分钟,比 CoDeF、Rerender 和 TokenFlow 分别快 3.1 倍、7.2 倍和 10.5 倍。用户评估中,FlowVid 的质量得分为 45.7%,明显优于 CoDeF(3.5%)、Rerender(10.2%)和 TokenFlow(40.4%)。
HitPaw Online Video Watermark Remover是一款基于浏览器的在线视频水印移除工具。它使用最先进的人工智能技术,可以轻松快速地从视频中去除水印。HitPaw Online Video Watermark Remover简单易用,让您在2023年轻松去除视频水印。
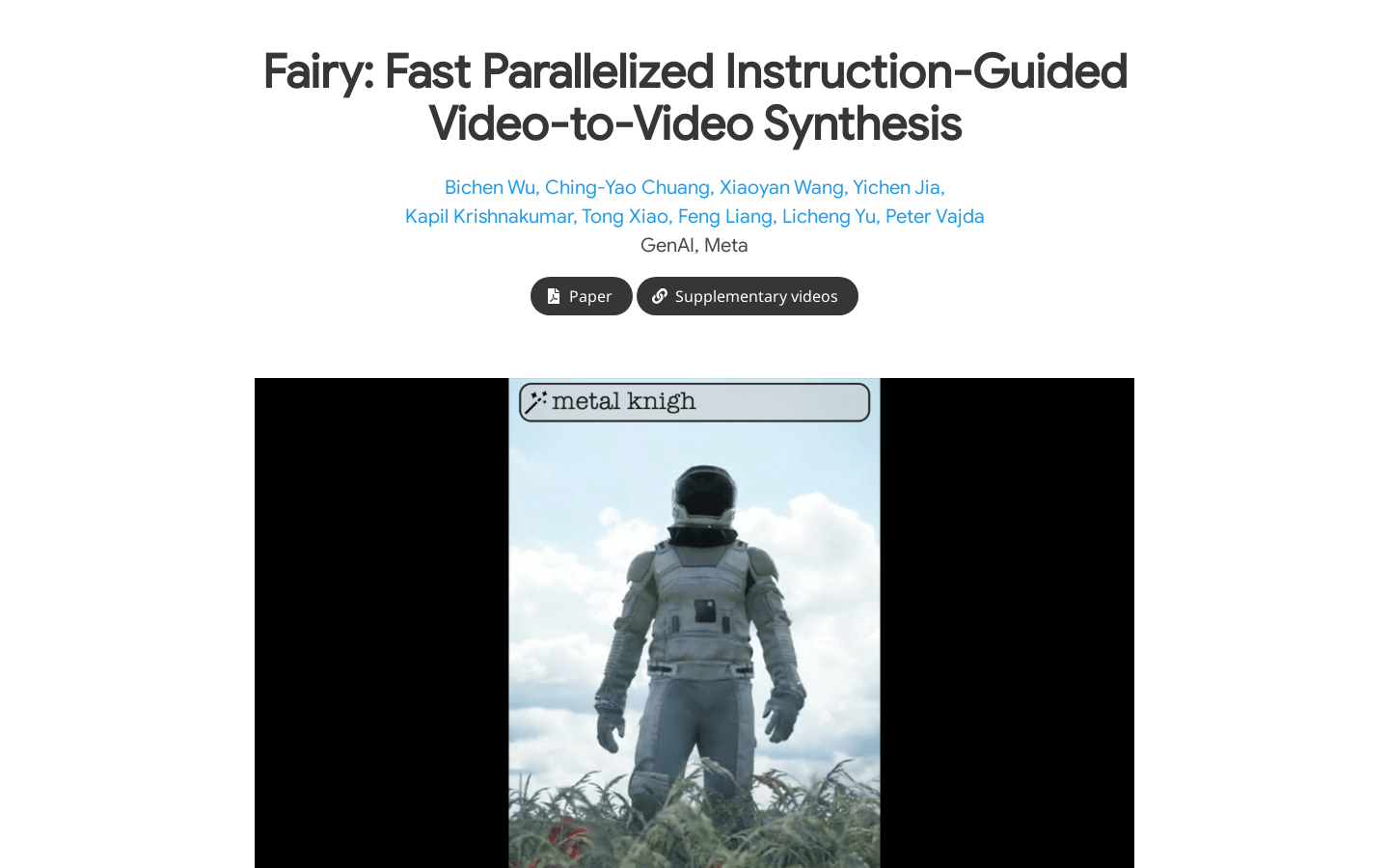
Fairy是一个针对视频编辑应用的简约但强大的图像编辑扩散模型的适应。它的核心是基于锚的跨帧注意机制,这种机制隐式地在帧之间传播扩散特征,确保了更好的时间连贯性和高保真度合成。Fairy不仅解决了以前模型的内存和处理速度限制,还通过独特的数据增强策略改善了时间一致性。
追影-视频生成是一款基于人工智能技术的视频生成工具,能够快速生成高质量的视频内容。其优势在于提供丰富的视频模板和智能编辑功能,用户可以轻松制作出令人印象深刻的视频作品。定价灵活合理,定位于个人用户和小型企业,为用户提供高效的视频创作解决方案。
CapCut 是一款易于使用的视频编辑器,提供基本视频编辑功能、免费字体和特效、高级功能(如关键帧动画、平滑慢动作、色度键和稳定性),帮助您捕捉并剪辑精彩瞬间。您还可以使用其他独特功能创建时尚视频,如自动字幕、文本转语音、运动跟踪和背景去除。让您的个性在 TikTok、YouTube、Instagram、WhatsApp 和 Facebook 上爆红!
Clipchamp 是微软365新推出的视频编辑器,可以简化视频剪辑编辑任务,让用户轻松制作高质量视频。它提供直观的拖拽编辑工具、定制化模板、特效和过渡效果,以及基于AI的语音转文本、自动字幕等功能,助力用户讲述自己的故事。
Clipchamp AI视频编辑是一个使用AI技术增强视频编辑的工具。它包含自动合成、语音转文字、AI音频增强等功能,可以轻松创建各种类型的短视频。Clipchamp还提供免费使用的功能,无需下载。
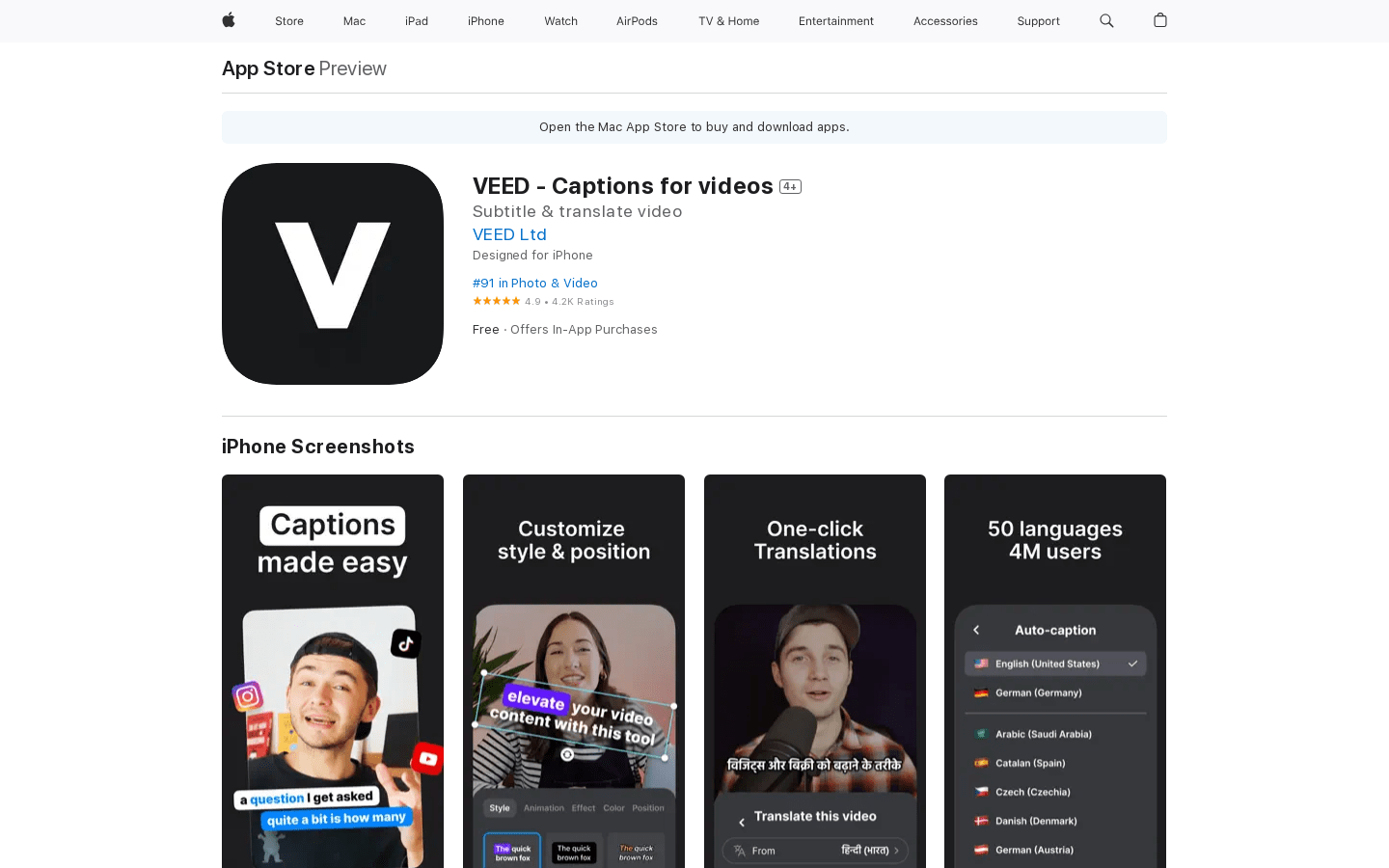
VEED Captions是一个帮助用户为视频添加字幕的APP。它可以自动生成字幕并支持用户进行修正,解决了手动添加字幕的麻烦。用户只需要导入或录制视频,应用会自动生成字幕,用户可以修改错词、选择字幕样式等。该APP使用简单,支持多种字幕样式,可以大幅提高视频的可访问性。
MotionCtrl 是一个统一而灵活的视频生成控制器,能够独立有效地管理相机和物体的运动。它可以根据相机姿态序列和物体轨迹指导视频生成模型,生成具有复杂相机运动和特定物体运动的视频。MotionCtrl 还可以与其他视频生成方法集成,如 SVD。它的优势包括能够精细地控制相机运动和物体运动,使用外观无关的相机姿态和轨迹,适应各种相机姿态和轨迹,生成具有自然外观的视频等。
VidMaskPro是一款AI视频编辑器,可以让您在视频中应用各种滤镜,包括动漫、黑武士等,快速生成视觉效果惊人的视频。使用先进的人工智能算法和深度学习技术,VidMaskPro彻底改变了视频创作的方式,使您可以在几分钟内设计出专业的音像制作。
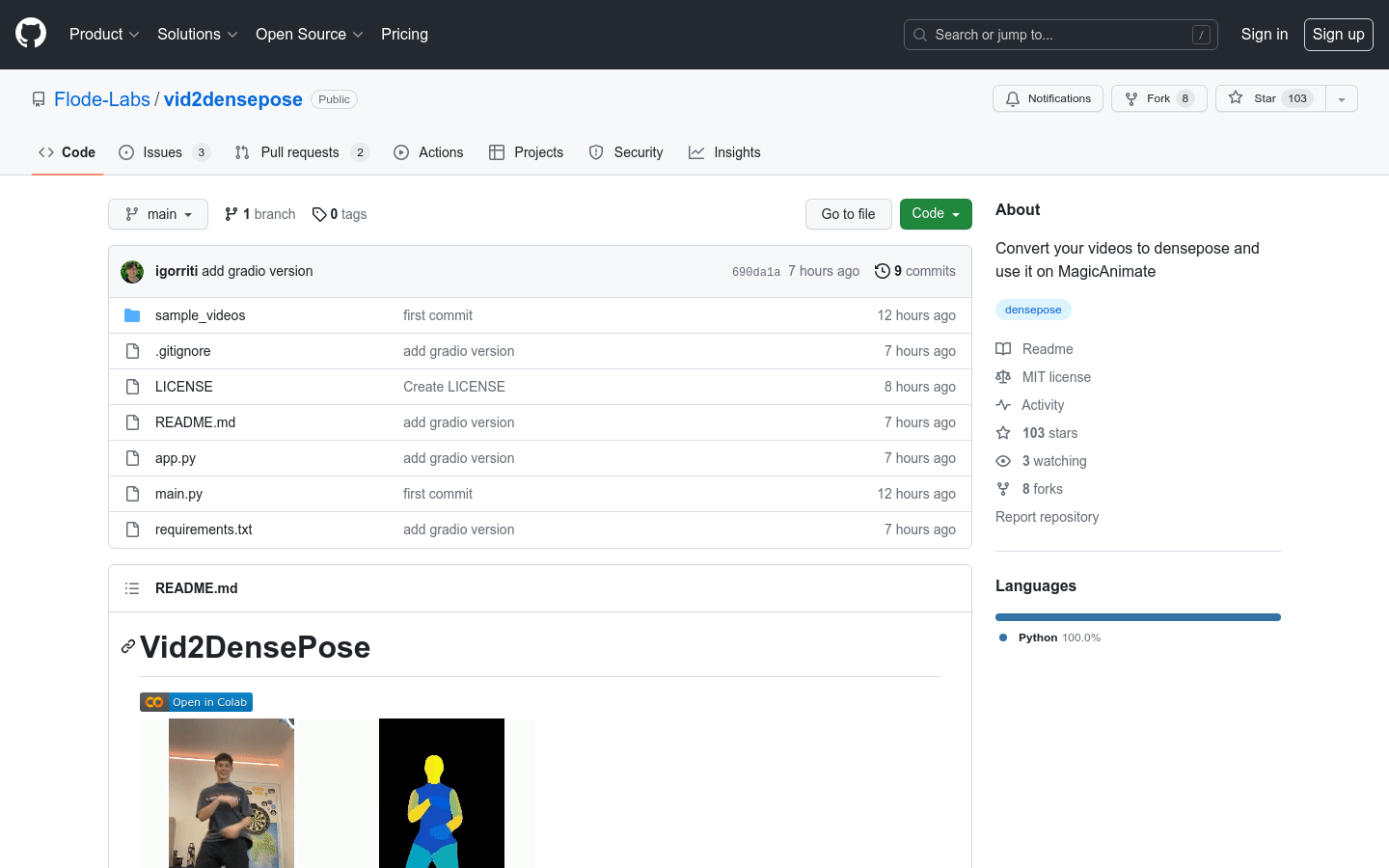
Vid2DensePose是一个强大的工具,旨在将DensePose模型应用于视频,为每一帧生成详细的“部位索引”可视化。该工具在增强动画方面非常有用,特别是与MagicAnimate结合使用时,能够实现时间上连贯的人体图像动画。
MotionDirector是一种能够自定义文本到视频扩散模型以生成具有所需动作的视频的技术。它采用双路径LoRAs架构,以解耦外观和运动的学习,并设计了一种新颖的去偏置时间损失,以减轻外观对时间训练目标的影响。该方法支持各种下游应用,如混合不同视频的外观和运动,以及用定制动作为单个图像添加动画。
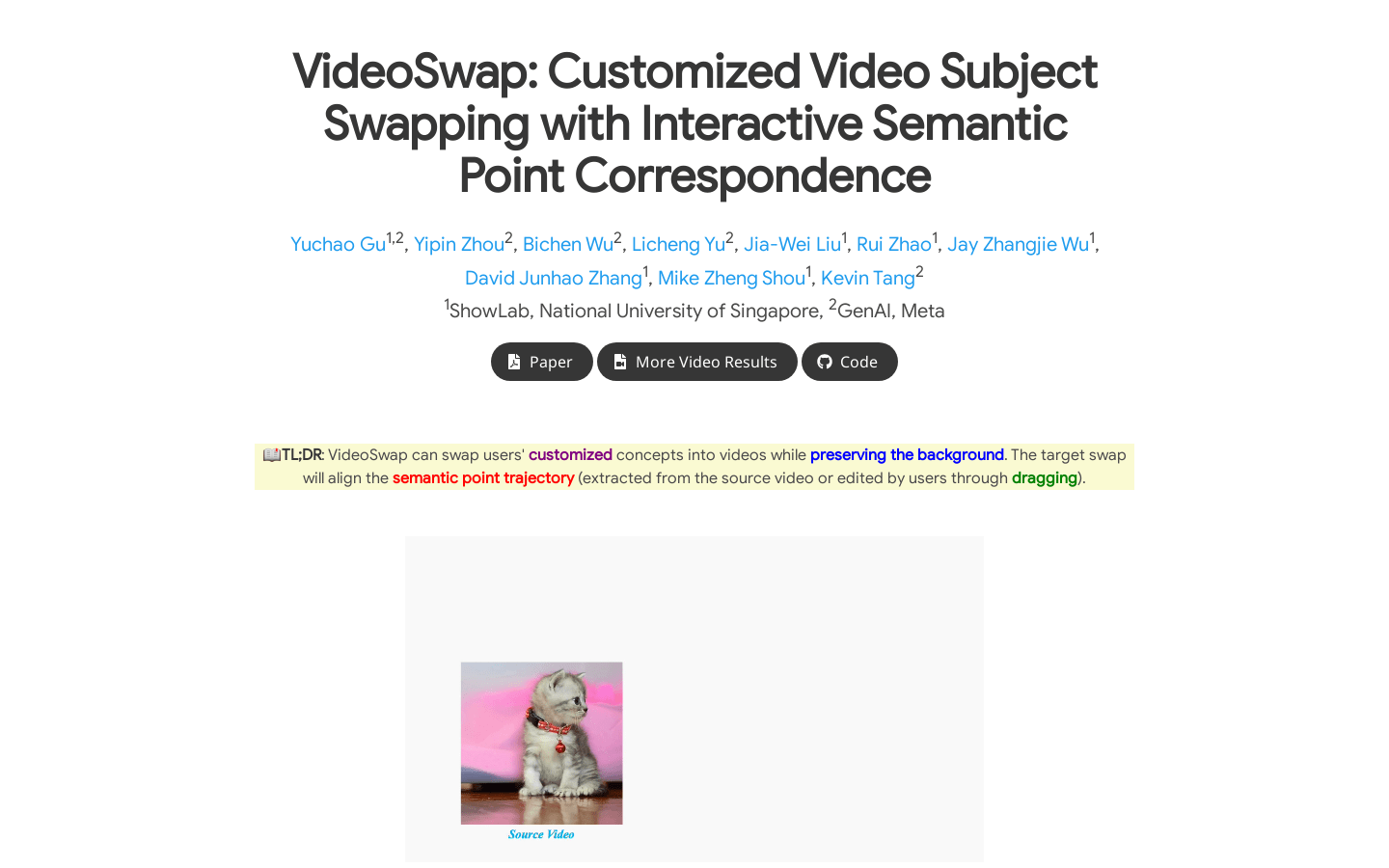
VideoSwap是一款视频编辑工具,可以将用户定制的概念交换到视频中,同时保留背景。通过语义点轨迹对齐和形状修改,实现视频主体的定制化交换。相较于传统方法,VideoSwap利用语义点对齐,可以在不同形状的交换中取得更好的效果。用户可以通过设置语义点和交互式拖拽等方式,实现更精细的视频交换效果。VideoSwap适用于多种场景,包括但不限于影视制作、广告制作、个人视频创作等。定价方面,VideoSwap提供免费试用和付费套餐,用户可以根据需求选择不同的套餐。
MagicAnimate 是一款使用扩散模型实现的时域一致的人体图像动画工具。它可以通过对人体图像进行扩散模型的运算,实现高质量、自然流畅的人体动画效果。MagicAnimate 具有高度的可控性和灵活性,可以通过微调参数来实现不同的动画效果。它适用于人体动画创作、虚拟角色设计等领域。
使用Simplified的免费自动字幕生成器,可以在视频中自动添加字幕。它是一个100%准确的基于AI技术的字幕生成器。您可以上传最多5MB大小的视频,自定义字幕样式,并在几秒钟内创建视觉一致的视频。
Submagic是一款面向内容创作者的人工智能工具,能够在不到2分钟内为短视频生成精彩的带有表情符号的字幕。使用Submagic,您可以创建引人注目的字幕,大幅提升视频的互动效果。Submagic支持48种语言,提供自动生成准确字幕、时尚模板和表情符号、B Rolls、过渡效果、自动放大、音效、描述和标签等功能。快速制作高质量的短视频,增加观众数量和互动,提升内容的可访问性和受众参与度。
TinyStudio是一款免费的Mac应用程序,利用M1/M2芯片的强大性能提供快速高效的字幕生成服务。用户可以一键生成视频和音频文件的字幕,无需任何技术专业知识。同时,TinyStudio采用OpenAI的Whisper技术,可在本地处理数据而无需联网。该应用程序还支持字幕导入和导出,提供基于规则的校正系统以确保准确性和可靠性。TinyStudio具有用户友好的界面,易于使用,适用于提高Vlogger、营销人员和社交媒体爱好者的效率。TinyStudio是一款非常有效的视频编辑工具,适用于Vlogger、营销人员和社交媒体爱好者。立即下载TinyStudio,体验免费、快速、强大的字幕工具!
VideoCrafter是一个开源的视频生成和编辑工具箱,用于制作视频内容。它目前包括Text2Video和Image2Video模型。Text2Video模型用于生成通用的文本到视频的转换,Image2Video模型用于生成通用的图像到视频的转换。详情请访问官方网站。
DualSubs是一个为YouTube提供双语字幕的插件。安装后无需任何配置,即可为移动端启用双语字幕,Web端解锁全部翻译语言选项,选择任一翻译语言,即为原始语言与翻译语言双语字幕。
探索 视频 分类下的其他子分类
399 个工具
346 个工具
323 个工具
181 个工具
130 个工具
64 个工具
49 个工具
39 个工具
AI视频编辑 是 视频 分类下的热门子分类,包含 124 个优质AI工具