搜索结果

Aya Vision 8B
CohereForAI的Aya Vision 8B是一个8亿参数的多语言视觉语言模型,专为多种视觉语言任务优化,支持OCR、图像描述、视觉推理、总结、问答等功能。该模型基于C4AI Command R7B语言模型,结合SigLIP2视觉编码器,支持23种语言,具有16K上下文长度。其主要优点包括多语言支持、强大的视觉理解能力以及广泛的适用场景。该模型以开源权重形式发布,旨在推动全球研究社区的发展。根据CC-BY-NC许可协议,用户需遵守C4AI的可接受使用政策。

Aya Vision
Aya Vision 是 Cohere For AI 团队开发的先进视觉模型,专注于多语言多模态任务,支持 23 种语言。该模型通过创新的算法突破,如合成标注、多语言数据扩展和多模态模型融合,显著提升了视觉和文本任务的性能。其主要优点包括高效性(在计算资源有限的情况下仍能表现出色)和广泛的多语言支持。Aya Vision 的发布旨在推动多语言多模态研究的前沿发展,并为全球研究社区提供技术支持。

ART
ART 是一种基于深度学习的图像生成技术,专注于生成可变多层透明图像。它通过匿名区域布局和 Transformer 架构,实现了高效的多层图像生成。该技术的主要优点包括高效性、灵活性以及对多层图像生成的支持。它适用于需要精确控制图像层的场景,如图形设计、视觉特效等领域。目前未明确提及价格和具体定位,但其技术特性表明它可能面向专业用户和企业级应用。

CogView4-6B
CogView4-6B 是由清华大学知识工程组开发的文本到图像生成模型。它基于深度学习技术,能够根据用户输入的文本描述生成高质量的图像。该模型在多个基准测试中表现优异,尤其是在中文文本生成图像方面具有显著优势。其主要优点包括高分辨率图像生成、支持多种语言输入以及高效的推理速度。该模型适用于创意设计、图像生成等领域,能够帮助用户快速将文字描述转化为视觉内容。
CogView4
CogView4 是由清华大学开发的先进文本到图像生成模型,基于扩散模型技术,能够根据文本描述生成高质量图像。它支持中文和英文输入,并且可以生成高分辨率图像。CogView4 的主要优点是其强大的多语言支持和高质量的图像生成能力,适合需要高效生成图像的用户。该模型在 ECCV 2024 上展示,具有重要的研究和应用价值。

VDraw
VDraw 是一款基于 AI 的在线设计工具,旨在帮助用户将文本、文件或视频内容快速转化为视觉化的信息图表。它利用先进的 AI 技术,自动将复杂的信息转化为清晰、美观的视觉图像,无需用户具备专业的设计技能。VDraw 的主要优点是操作简单、生成速度快,且支持个性化定制,用户可以根据自己的需求调整颜色、字体和布局。它适用于个人、教育工作者、市场营销人员以及任何需要快速制作专业视觉内容的用户。VDraw 提供免费试用,并有付费订阅计划,以满足不同用户的需求。

UniTok
UniTok是一种创新的视觉分词技术,旨在弥合视觉生成和理解之间的差距。它通过多码本量化技术,显著提升了离散分词器的表示能力,使其能够捕捉到更丰富的视觉细节和语义信息。这一技术突破了传统分词器在训练过程中的瓶颈,为视觉生成和理解任务提供了一种高效且统一的解决方案。UniTok在图像生成和理解任务中表现出色,例如在ImageNet上实现了显著的零样本准确率提升。该技术的主要优点包括高效性、灵活性以及对多模态任务的强大支持,为视觉生成和理解领域带来了新的可能性。

OpenArt Characters
OpenArt Characters 是一个基于人工智能的图像生成平台,专注于角色创建和管理。用户可以通过文字描述、单张图片或四张以上图片来生成和定制角色。该平台利用先进的生成式AI技术,为用户提供快速、高效的角色创建体验,适用于创作者、设计师和艺术家等。平台提供丰富的角色模板和样式,帮助用户快速启动项目。OpenArt Characters 以免费试用的形式提供服务,旨在降低创作门槛,激发创意。
Migician
Migician 是清华大学自然语言处理实验室开发的一种多模态大语言模型,专注于多图像定位任务。该模型通过引入创新的训练框架和大规模数据集 MGrounding-630k,显著提升了多图像场景下的精确定位能力。它不仅超越了现有的多模态大语言模型,甚至在性能上超过了更大规模的 70B 模型。Migician 的主要优点在于其能够处理复杂的多图像任务,并提供自由形式的定位指令,使其在多图像理解领域具有重要的应用前景。该模型目前在 Hugging Face 上开源,供研究人员和开发者使用。

FakeATweet
FakeATweet是一款在线生成逼真推特/X截图的工具。它利用先进的图像生成技术,能够快速生成与真实推特/X帖子难以区分的截图。该工具的主要优点是没有水印,无需注册,且完全免费。它适用于需要快速生成推特/X截图的用户,无论是用于恶搞朋友、制作梗图还是进行创意项目,都能提供高质量的结果。该工具的界面简洁,操作简单,支持移动和桌面预览,满足不同用户的需求。

神采AI
神采AI是一款专注于图像生成与编辑的AI工具,采用先进的AIGC技术,提供多种设计风格和功能,帮助用户快速生成高质量的图像、视频和动画。其主要优点包括操作简单、功能多样、生成效果逼真。该产品面向设计师、市场营销人员、学生等群体,旨在提升设计效率,降低创作门槛。目前提供免费试用服务,适合各类创意工作者。

爱涂鸭
爱涂鸭是一个以创意绘画为核心的在线平台,用户可以通过简单的操作进行绘画创作,并分享到社区。它结合了绘画工具和社交功能,旨在激发用户的创造力和艺术兴趣。产品主要面向喜欢绘画和创意表达的用户,提供了一个自由创作和交流的空间。

MakeAnything
MakeAnything 是一个基于扩散变换器的模型,专注于多领域程序化序列生成。该技术通过结合先进的扩散模型和变换器架构,能够生成高质量的、逐步的创作序列,如绘画、雕塑、图标设计等。其主要优点在于能够处理多种领域的生成任务,并且可以通过少量样本快速适应新领域。该模型由新加坡国立大学 Show Lab 团队开发,目前以开源形式提供,旨在推动多领域生成技术的发展。

ZColoring
ZColoring 是一款基于人工智能技术的涂色页生成工具。它通过 AI 模型将用户输入的文字描述转化为具体的涂色页轮廓,无需用户具备绘画技能即可快速生成个性化的涂色作品。这种技术不仅降低了艺术创作的门槛,还为用户提供了丰富的创意空间。其主要优点是操作简单、生成速度快,适合家长、教师以及绘画爱好者使用,可用于儿童涂色练习、创意绘画教学等场景。该产品目前提供免费试用,每日可生成 3 张免费图像,无需注册登录,方便用户快速体验。
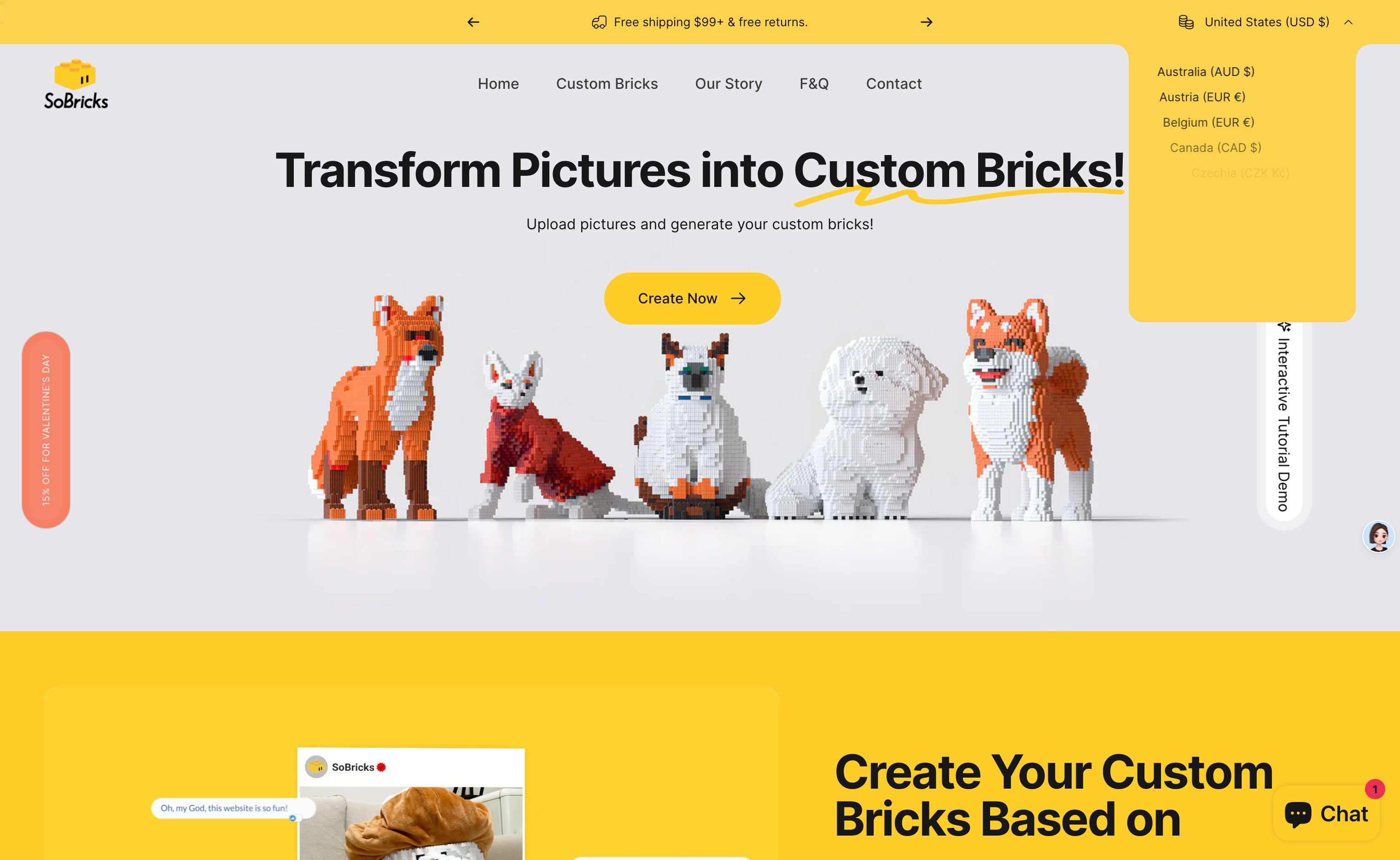
SoBricks
SoBricks 是一款创新的定制积木产品,利用 AI 技术与专业设计优化,将用户上传的图片转化为精美的积木模型。其主要优点包括高度个性化的设计、互动式拼装教程以及免费的物流服务。SoBricks 旨在为用户提供一种全新的创意表达方式,无论是宠物、家人还是其他重要时刻的照片,都能转化为可以亲手拼装的积木作品。产品价格为 $119.00 USD,适合追求个性化和创意体验的用户。

GenColor AI
GenColor AI 采用先进的人工智能技术,能够将用户上传的照片或输入的文字描述快速转换为精美的线稿。其技术的重要性在于为绘画爱好者、艺术创作者以及教育工作者等提供了便捷高效的创作工具,降低了线稿创作的门槛,激发了更多人的创意和想象力。该产品定位为面向广大用户的在线免费工具,旨在满足不同用户群体的个性化需求,无论是儿童的涂色活动、成人的艺术创作,还是教育领域的艺术教学等场景都能适用。其免费使用的特点也使得更多人能够轻松体验和使用该工具,进一步拓展了其应用范围。

Krea Chat
Krea Chat 是一款基于 AI 的设计工具,通过聊天界面提供强大的设计功能。它结合了 DeepSeek 的 AI 技术和 Krea 的设计工具套件,用户可以通过自然语言交互生成图像、视频等设计内容。这种创新的交互方式极大地简化了设计流程,降低了设计门槛,使用户能够快速实现创意。Krea Chat 的主要优点包括易于使用、高效生成设计内容以及强大的 AI 驱动功能。它适合需要快速生成设计素材的创作者、设计师和市场营销人员,能够帮助他们节省时间并提升工作效率。

Janus Pro
Janus Pro 是由 DeepSeek 技术驱动的先进 AI 图像生成与理解平台。它采用革命性的统一变换器架构,能够高效处理复杂的多模态操作,实现图像生成和理解的卓越性能。该平台训练了超过 9000 万个样本,其中包括 7200 万个合成美学数据点,确保生成的图像在视觉上具有吸引力且上下文准确。Janus Pro 为开发者和研究人员提供强大的视觉 AI 能力,帮助他们实现从创意到视觉叙事的转变。平台提供免费试用,适合需要高质量图像生成和分析的用户。

SliderSpace
SliderSpace 是一项创新技术,旨在提高扩散模型的可控性和可解释性。它通过自动发现模型内部的视觉知识,将其分解为直观的滑块,用户可以通过这些滑块轻松调整图像生成的方向。该技术不仅能够揭示模型对不同概念的理解,还能显著提高图像生成的多样性。SliderSpace 的主要优点包括自动化发现方向、语义正交性和分布一致性,使其成为探索和利用扩散模型视觉能力的强大工具。该技术目前处于研究阶段,尚未明确具体的价格和商业定位。

hotdog
该产品利用图像识别技术,通过上传图片来判断是否为热狗。它基于深度学习模型,能够快速准确地识别热狗图像。这种技术展示了图像识别在日常生活中的趣味应用,同时也体现了人工智能技术的普及性和娱乐性。产品背景源于对AI技术的趣味探索,旨在通过简单的图像识别功能,让用户感受到AI的魅力。该产品目前为免费使用,主要面向喜欢尝试新技术和追求趣味体验的用户。

Google Imagen 3 API
Google Imagen 3是Google推出的图像生成模型,通过Gemini API向开发者开放。它能够根据用户输入的文本提示生成高质量图像,支持多种艺术风格,如超现实主义、印象派、抽象艺术等。该模型在图像细节和色彩处理上表现出色,适用于艺术创作、广告设计、游戏开发等创意工作。其主要优点包括高效的提示跟踪能力、丰富的自定义选项以及成本效益。此外,为防止误用,所有生成图像均带有不可见水印。定价为每张图像0.03美元,适合需要批量生成图像的开发者和企业。

1Prompt1Story
1Prompt1Story是一种创新的文本到图像生成技术,能够在无需额外训练的情况下,通过单个提示生成一致的图像序列。该技术利用语言模型的上下文一致性,通过单个提示串联所有描述,生成具有身份一致性的图像。它支持多角色生成、空间控制生成以及真实图像个性化等功能,具有广泛的应用前景。该模型主要面向需要高效、一致图像生成的创作者和开发者,可用于故事创作、动画制作等领域。

Animagine XL 4.0
Animagine XL 4.0 是一款基于Stable Diffusion XL 1.0微调的动漫主题生成模型。它使用了840万张多样化的动漫风格图像进行训练,训练时长达到2650小时。该模型专注于通过文本提示生成和修改动漫主题图像,支持多种特殊标签,可控制图像生成的不同方面。其主要优点包括高质量的图像生成、丰富的动漫风格细节以及对特定角色和风格的精准还原。该模型由Cagliostro Research Lab开发,采用CreativeML Open RAIL++-M许可证,允许商业使用和修改。

Janus-Pro-7B
Janus-Pro-7B 是一个强大的多模态模型,能够同时处理文本和图像数据。它通过分离视觉编码路径,解决了传统模型在理解和生成任务中的冲突,提高了模型的灵活性和性能。该模型基于 DeepSeek-LLM 架构,使用 SigLIP-L 作为视觉编码器,支持 384x384 的图像输入,并在多模态任务中表现出色。其主要优点包括高效性、灵活性和强大的多模态处理能力。该模型适用于需要多模态交互的场景,例如图像生成和文本理解。