
产品详情
Oasis是由Decart AI开发的首个可玩、实时、开放世界的AI模型,它是一个互动视频游戏,由Transformer端到端生成,基于逐帧生成。Oasis能够接收用户键盘和鼠标输入,实时生成游戏玩法,内部模拟物理、游戏规则和图形。该模型通过直接观察游戏玩法学习,允许用户移动、跳跃、拾取物品、破坏方块等。Oasis被视为研究更复杂交互世界的基础模型的第一步,未来可能取代传统的游戏引擎。Oasis的实现需要模型架构的改进和模型推理技术的突破,以实现用户与模型的实时交互。Decart AI采用了最新的扩散训练和Transformer模型方法,并结合了大型语言模型(LLMs)来训练一个自回归模型,该模型可以根据用户即时动作生成视频。此外,Decart AI还开发了专有的推理框架,以提供NVIDIA H100 Tensor Core GPU的峰值利用率,并支持Etched即将推出的Sohu芯片。
主要功能
使用教程
适用人群
目标受众为游戏开发者、AI研究者和对实时交互视频内容感兴趣的用户。Oasis提供了一个全新的平台,使得开发者可以创造和模拟复杂的游戏世界,而AI研究者可以探索和优化大型模型的推理技术。对于普通用户来说,Oasis提供了一个互动视频游戏的新体验,用户可以实时影响游戏世界的发展。
使用示例
游戏开发者使用Oasis创建一个全新的开放世界游戏,玩家可以实时影响游戏环境。
AI研究者利用Oasis进行模型训练和推理技术的研究,优化大型AI模型的性能。
教育机构使用Oasis作为教学工具,让学生体验和学习AI在游戏开发中的应用。
快速访问
访问官网 →所属分类
相关推荐
发现更多类似的优质AI工具

HunyuanVideo
HunyuanVideo是腾讯开源的一个系统性框架,用于训练大型视频生成模型。该框架通过采用数据策划、图像-视频联合模型训练和高效的基础设施等关键技术,成功训练了一个超过130亿参数的视频生成模型,是所有开源模型中最大的。HunyuanVideo在视觉质量、运动多样性、文本-视频对齐和生成稳定性方面表现出色,超越了包括Runway Gen-3、Luma 1.6在内的多个行业领先模型。通过开源代码和模型权重,HunyuanVideo旨在缩小闭源和开源视频生成模型之间的差距,推动视频生成生态系统的活跃发展。

CogVideoX1.5-5B-SAT
CogVideoX1.5-5B-SAT是由清华大学知识工程与数据挖掘团队开发的开源视频生成模型,是CogVideoX模型的升级版。该模型支持生成10秒视频,并支持更高分辨率的视频生成。模型包含Transformer、VAE和Text Encoder等模块,能够根据文本描述生成视频内容。CogVideoX1.5-5B-SAT模型以其强大的视频生成能力和高分辨率支持,为视频内容创作者提供了一个强大的工具,尤其在教育、娱乐和商业领域有着广泛的应用前景。

Mochi in ComfyUI
Mochi是Genmo最新推出的开源视频生成模型,它在ComfyUI中经过优化,即使使用消费级GPU也能实现。Mochi以其高保真度动作和卓越的提示遵循性而著称,为ComfyUI社区带来了最先进的视频生成能力。Mochi模型在Apache 2.0许可下发布,这意味着开发者和创作者可以自由使用、修改和集成Mochi,而不受限制性许可的阻碍。Mochi能够在消费级GPU上运行,如4090,且在ComfyUI中支持多种注意力后端,使其能够适应小于24GB的VRAM。
FasterCache
FasterCache是一种创新的无需训练的策略,旨在加速视频扩散模型的推理过程,并生成高质量的视频内容。这一技术的重要性在于它能够显著提高视频生成的效率,同时保持或提升内容的质量,这对于需要快速生成视频内容的行业来说是非常有价值的。FasterCache由来自香港大学、南洋理工大学和上海人工智能实验室的研究人员共同开发,项目页面提供了更多的视觉结果和详细信息。产品目前免费提供,主要面向视频内容生成、AI研究和开发等领域。

LongVU
LongVU是一种创新的长视频语言理解模型,通过时空自适应压缩机制减少视频标记的数量,同时保留长视频中的视觉细节。这一技术的重要性在于它能够处理大量视频帧,且在有限的上下文长度内仅损失少量视觉信息,显著提升了长视频内容理解和分析的能力。LongVU在多种视频理解基准测试中均超越了现有方法,尤其是在理解长达一小时的视频任务上。此外,LongVU还能够有效地扩展到更小的模型尺寸,同时保持最先进的视频理解性能。

mochi-1-preview
这是一个先进的视频生成模型,采用 AsymmDiT 架构,可免费试用。它能生成高保真视频,缩小了开源与闭源视频生成系统的差距。模型需要至少 4 个 H100 GPU 运行。

genmoai
genmoai/models 是一个开源的视频生成模型,代表了视频生成技术的最新进展。该模型名为 Mochi 1,是一个基于 Asymmetric Diffusion Transformer (AsymmDiT) 架构的10亿参数扩散模型,从零开始训练,是迄今为止公开发布的最大的视频生成模型。它具有高保真运动和强提示遵循性,显著缩小了封闭和开放视频生成系统之间的差距。该模型在 Apache 2.0 许可下发布,用户可以在 Genmo 的 playground 上免费试用此模型。

Mochi 1
Mochi 1 是 Genmo 公司推出的一款研究预览版本的开源视频生成模型,它致力于解决当前AI视频领域的基本问题。该模型以其无与伦比的运动质量、卓越的提示遵循能力和跨越恐怖谷的能力而著称,能够生成连贯、流畅的人类动作和表情。Mochi 1 的开发背景是响应对高质量视频内容生成的需求,特别是在游戏、电影和娱乐行业中。产品目前提供免费试用,具体定价信息未在页面中提供。
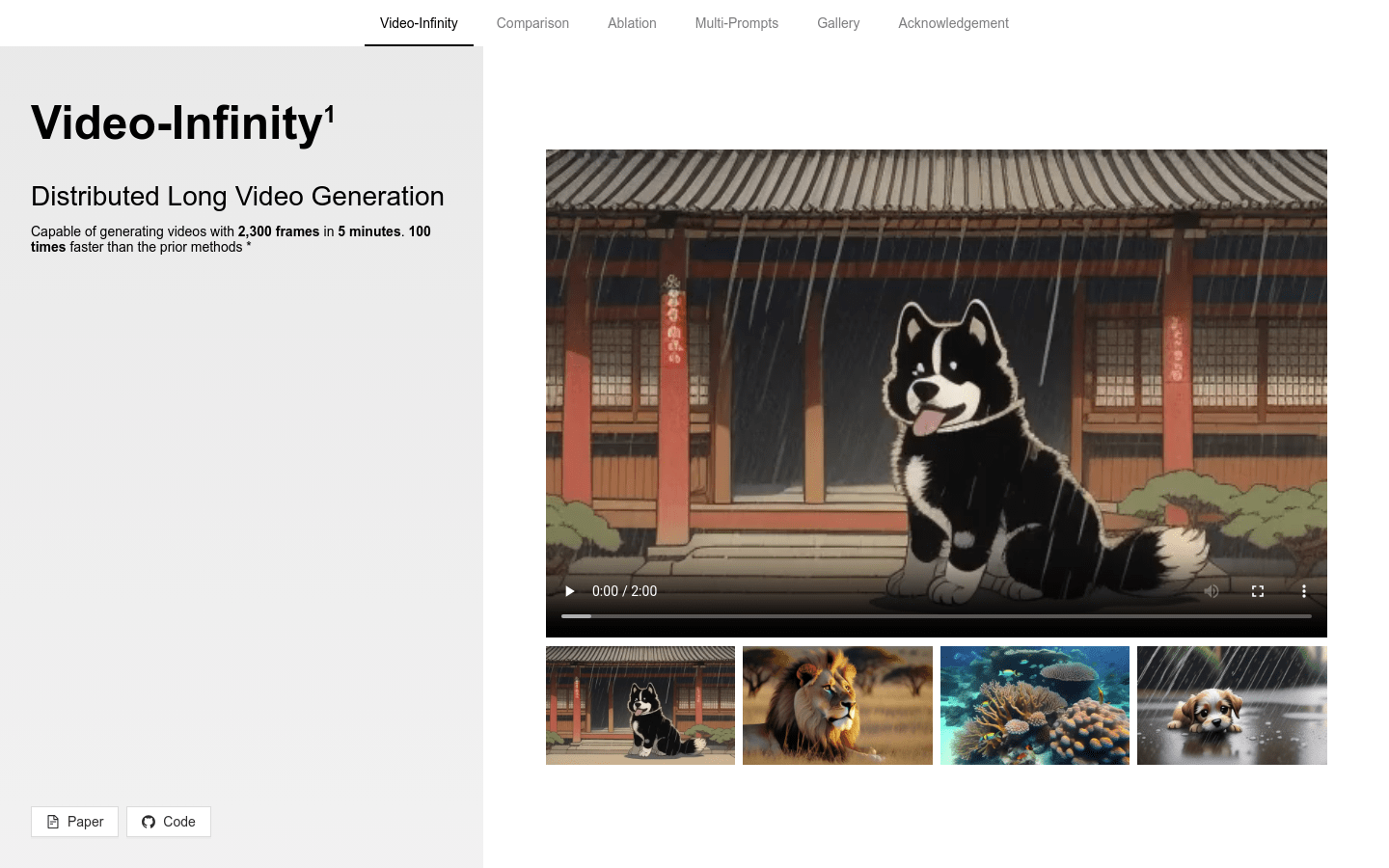
Video-Infinity
Video-Infinity 是一种分布式长视频生成技术,能够在5分钟内生成2300帧的视频,速度是先前方法的100倍。该技术基于VideoCrafter2模型,采用了Clip Parallelism和Dual-scope Attention等创新技术,显著提高了视频生成的效率和质量。

Etna
Etna模型采用了Diffusion架构,并结合了时空卷积和注意力层,使其能够处理视频数据并理解时间连续性,从而生成具有时间维度的视频内容。该模型在大型视频数据集上进行训练,使用了深度学习技术策略,包括大规模训练、超参数优化和微调,以确保强大的性能和生成能力。

Cyanpuppets
Cyanpuppets是一个专注于2D视频生成3D动作模型的AI算法团队。他们的无标记动作捕捉系统通过2个RGB摄像头完成超过208个关键点的捕捉,支持UE5和UNITY 2021版本,延迟仅为0.1秒。Cyanpuppets支持大多数骨骼标准,其技术广泛应用于游戏、电影和其他娱乐领域。