产品详情
Dpt Depth是一款基于 Dpt 深度估计和 3D 技术的图像处理工具。它可以通过输入的图像快速估计出深度信息,并根据深度信息生成相应的三维模型。Dpt Depth Estimation + 3D 功能强大,易于使用,可广泛应用于计算机视觉、图像处理等领域。该产品提供免费试用版本和付费订阅版本。
主要功能
适用人群
Dpt Depth Estimation + 3D 适用于计算机视觉、图像处理、三维模型生成等领域。
快速访问
访问官网 →所属分类
相关推荐
发现更多类似的优质AI工具

DreamMesh4D
DreamMesh4D是一个结合了网格表示与稀疏控制变形技术的新型框架,能够从单目视频中生成高质量的4D对象。该技术通过结合隐式神经辐射场(NeRF)或显式的高斯绘制作为底层表示,解决了传统方法在空间-时间一致性和表面纹理质量方面的挑战。DreamMesh4D利用现代3D动画流程的灵感,将高斯绘制绑定到三角网格表面,实现了纹理和网格顶点的可微优化。该框架开始于由单图像3D生成方法提供的粗糙网格,通过均匀采样稀疏点来构建变形图,以提高计算效率并提供额外的约束。通过两阶段学习,结合参考视图光度损失、得分蒸馏损失以及其他正则化损失,实现了静态表面高斯和网格顶点以及动态变形网络的学习。DreamMesh4D在渲染质量和空间-时间一致性方面优于以往的视频到4D生成方法,并且其基于网格的表示与现代几何流程兼容,展示了其在3D游戏和电影行业的潜力。

Flex3D
Flex3D是一个两阶段流程,能够从单张图片或文本提示生成高质量的3D资产。该技术代表了3D重建领域的最新进展,可以显著提高3D内容的生成效率和质量。Flex3D的开发得到了Meta的支持,并且团队成员在3D重建和计算机视觉领域有着深厚的背景。

ViewCrafter
ViewCrafter 是一种新颖的方法,它利用视频扩散模型的生成能力以及基于点的表示提供的粗略3D线索,从单个或稀疏图像合成通用场景的高保真新视角。该方法通过迭代视图合成策略和相机轨迹规划算法,逐步扩展3D线索和新视角覆盖的区域,从而扩大新视角的生成范围。ViewCrafter 可以促进各种应用,例如通过优化3D-GS表示实现沉浸式体验和实时渲染,以及通过场景级文本到3D生成实现更富有想象力的内容创作。

OmniRe
OmniRe 是一种用于高效重建高保真动态城市场景的全面方法,它通过设备日志来实现。该技术通过构建基于高斯表示的动态神经场景图,以及构建多个局部规范空间来模拟包括车辆、行人和骑行者在内的各种动态行为者,从而实现了对场景中不同对象的全面重建。OmniRe 允许我们全面重建场景中存在的不同对象,并随后实现所有参与者实时参与的重建场景的模拟。在 Waymo 数据集上的广泛评估表明,OmniRe 在定量和定性方面都大幅超越了先前的最先进方法。
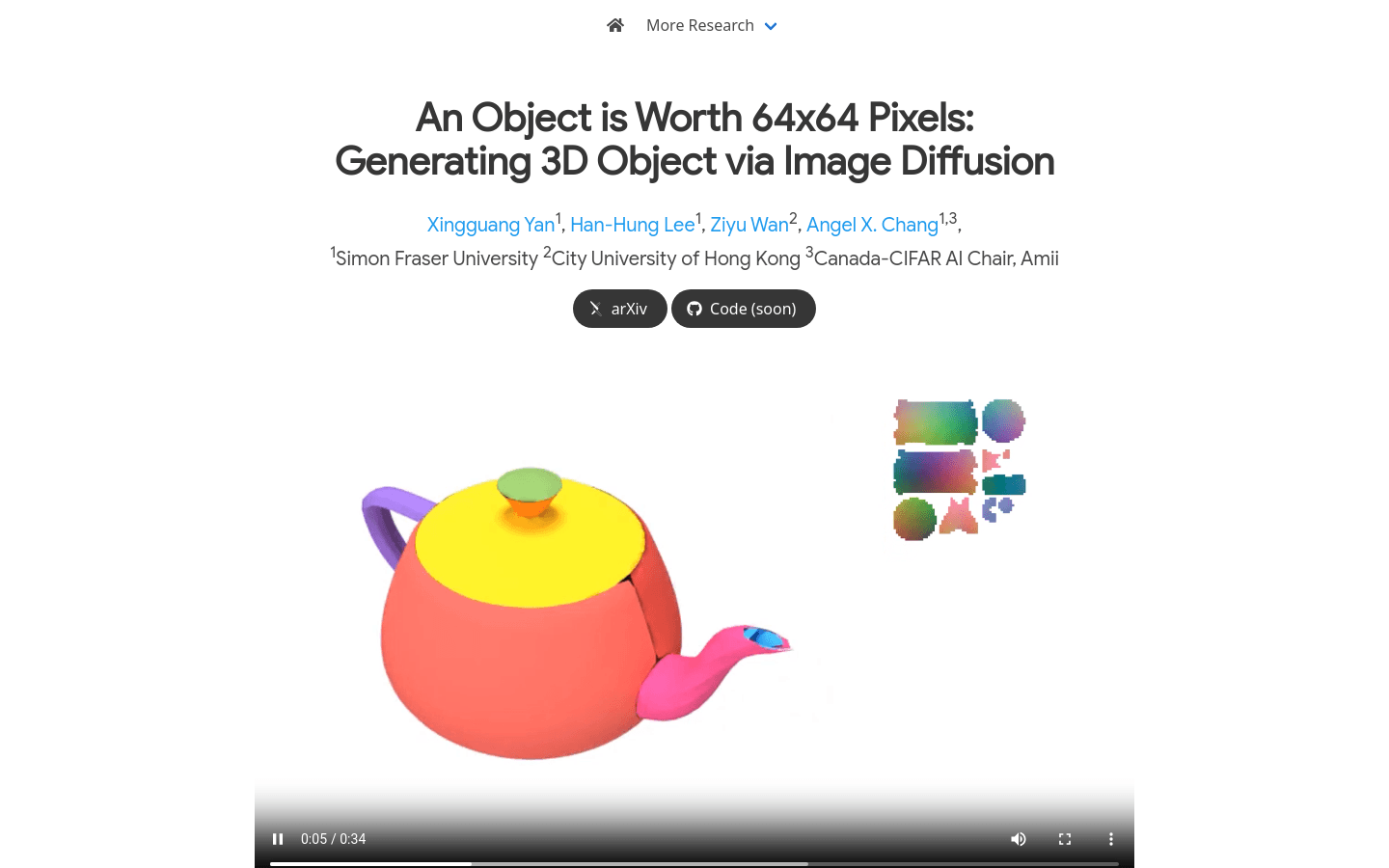
Omages
Object Images是一种创新的3D模型生成技术,它通过将复杂的3D形状封装在一个64x64像素的图像中,即所谓的'Object Images'或'omages',来简化3D形状的生成和处理。这项技术通过图像生成模型,如Diffusion Transformers,直接用于3D形状生成,解决了传统多边形网格中几何和语义不规则性的挑战。

VFusion3D
VFusion3D是一种基于预训练的视频扩散模型构建的可扩展3D生成模型。它解决了3D数据获取困难和数量有限的问题,通过微调视频扩散模型生成大规模合成多视角数据集,训练出能够从单张图像快速生成3D资产的前馈3D生成模型。该模型在用户研究中表现出色,用户超过90%的时间更倾向于选择VFusion3D生成的结果。

SAM-Graph
SAM-guided Graph Cut for 3D Instance Segmentation是一种利用3D几何和多视图图像信息进行3D实例分割的深度学习方法。该方法通过3D到2D查询框架,有效利用2D分割模型进行3D实例分割,通过图割问题构建超点图,并通过图神经网络训练,实现对不同类型场景的鲁棒分割性能。

TexGen
TexGen是一个创新的多视角采样和重采样框架,用于根据任意文本描述合成3D纹理。它利用预训练的文本到图像的扩散模型,通过一致性视图采样和注意力引导的多视角采样策略,以及噪声重采样技术,显著提高了3D对象的纹理质量,具有高度的视角一致性和丰富的外观细节。

SF3D
SF3D是一个基于深度学习的3D资产生成模型,它能够从单张图片中快速生成具有UV展开和材质参数的带纹理3D模型。与传统方法相比,SF3D特别针对网格生成进行了训练,集成了快速UV展开技术,能够迅速生成纹理而不是依赖顶点颜色。此外,该模型还能学习材质参数和法线贴图,以提高重建模型的视觉质量。SF3D还引入了一个去照明步骤,有效去除低频照明效果,确保重建的网格在新的照明条件下易于使用。
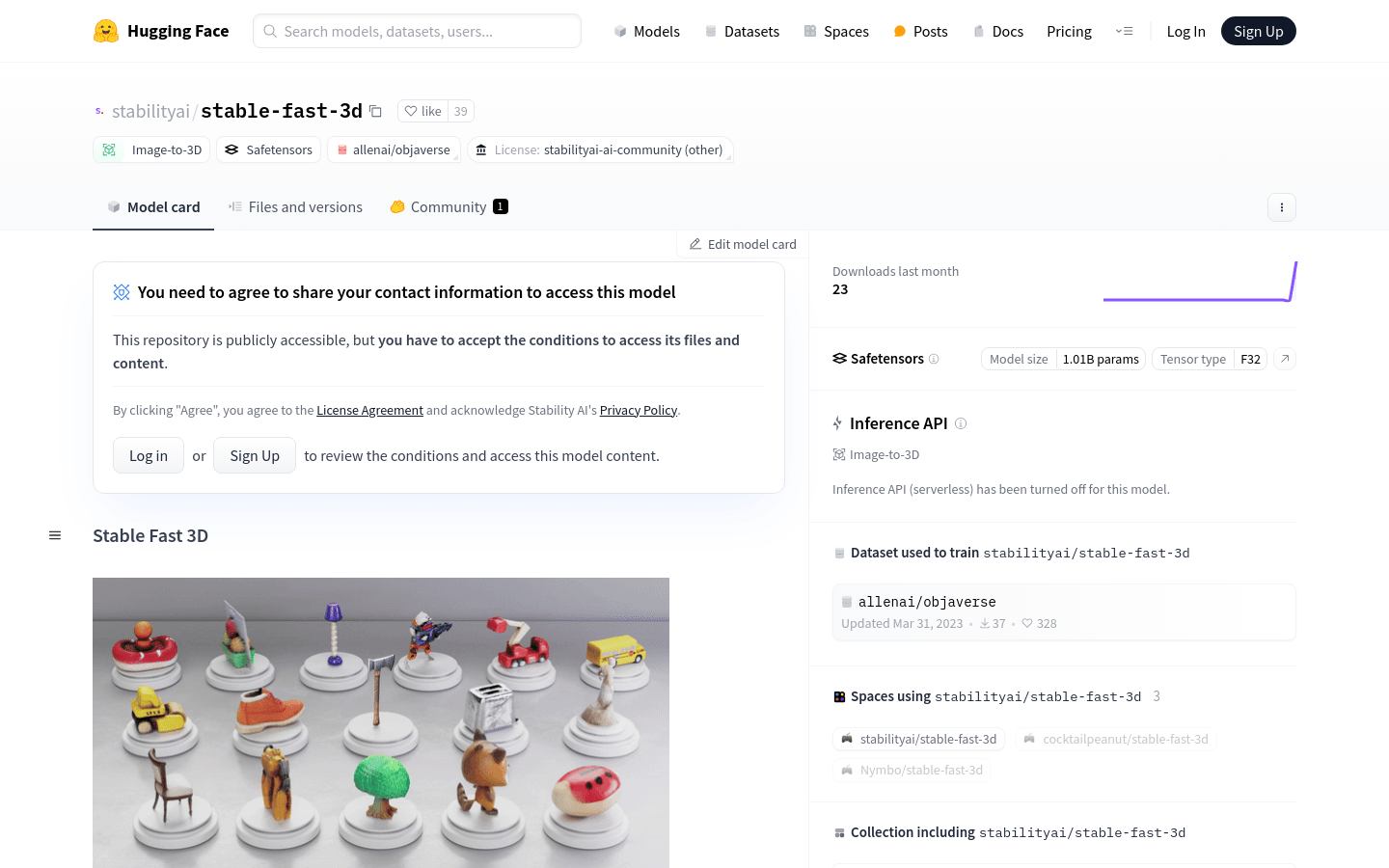
Stable Fast 3D
Stable Fast 3D (SF3D) 是一个基于TripoSR的大型重建模型,能够从单张物体图片生成带有纹理的UV展开3D网格资产。该模型训练有素,能在不到一秒的时间内创建3D模型,具有较低的多边形计数,并且进行了UV展开和纹理处理,使得模型在下游应用如游戏引擎或渲染工作中更易于使用。此外,模型还能预测每个物体的材料参数(粗糙度、金属感),在渲染过程中增强反射行为。SF3D适用于需要快速3D建模的领域,如游戏开发、电影特效制作等。
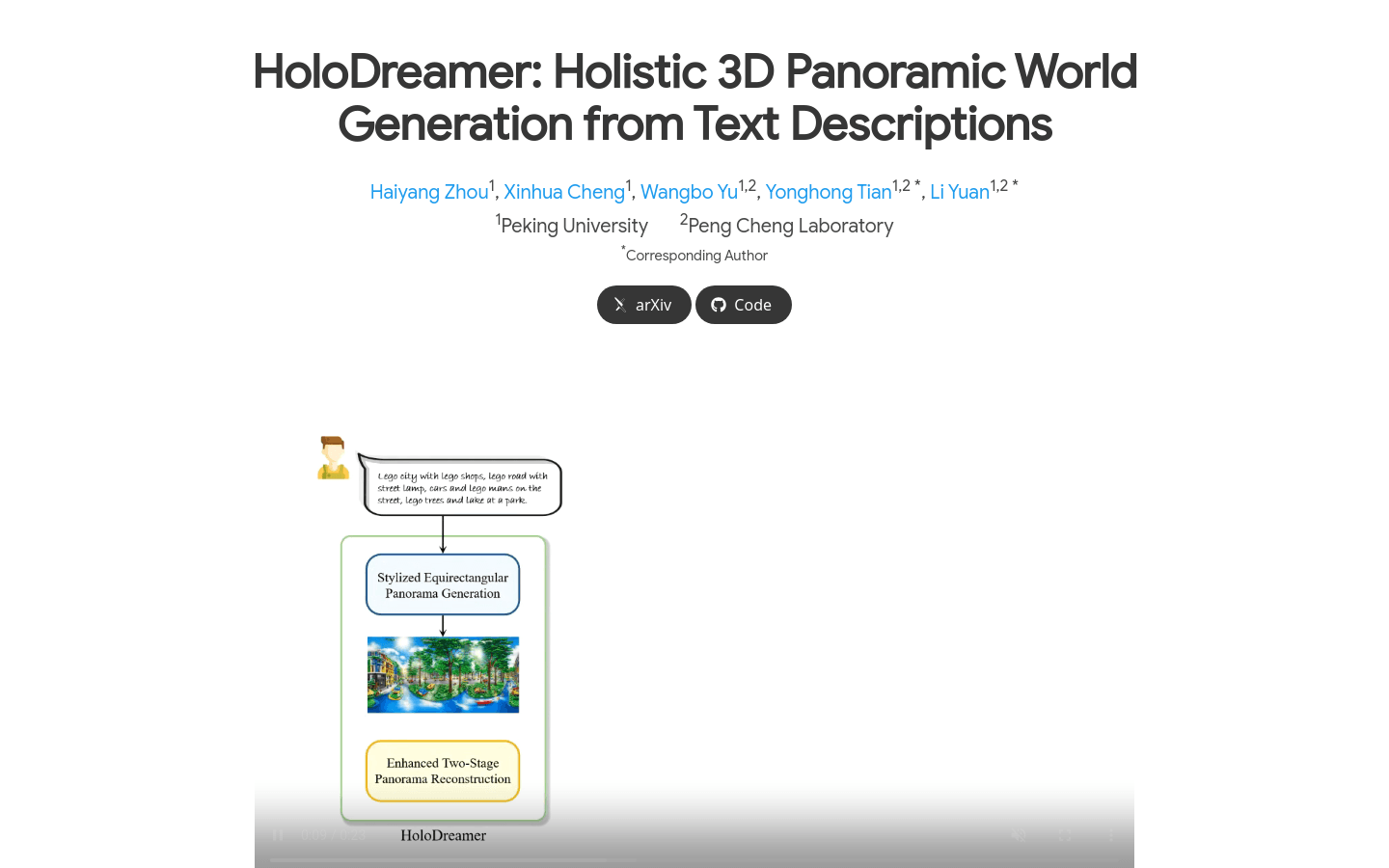
HoloDreamer
HoloDreamer是一个文本驱动的3D场景生成框架,能够生成沉浸式且视角一致的全封闭3D场景。它由两个基本模块组成:风格化等矩形全景生成和增强两阶段全景重建。该框架首先生成高清晰度的全景图作为完整3D场景的整体初始化,然后利用3D高斯散射(3D-GS)技术快速重建3D场景,从而实现视角一致和完全封闭的3D场景生成。HoloDreamer的主要优点包括高视觉一致性、和谐性以及重建质量和渲染的鲁棒性。

VGGSfM
VGGSfM是一种基于深度学习的三维重建技术,旨在从一组不受限制的2D图像中重建场景的相机姿态和3D结构。该技术通过完全可微分的深度学习框架,实现端到端的训练。它利用深度2D点跟踪技术提取可靠的像素级轨迹,同时基于图像和轨迹特征恢复所有相机,并通过可微分的捆绑调整层优化相机和三角化3D点。VGGSfM在CO3D、IMC Phototourism和ETH3D三个流行数据集上取得了最先进的性能。

Animate3D
Animate3D是一个创新的框架,用于为任何静态3D模型生成动画。它的核心理念包括两个主要部分:1) 提出一种新的多视图视频扩散模型(MV-VDM),该模型基于静态3D对象的多视图渲染,并在我们提供的大规模多视图视频数据集(MV-Video)上进行训练。2) 基于MV-VDM,引入了一个结合重建和4D得分蒸馏采样(4D-SDS)的框架,利用多视图视频扩散先验来为3D对象生成动画。Animate3D通过设计新的时空注意力模块来增强空间和时间一致性,并通过多视图渲染来保持静态3D模型的身份。此外,Animate3D还提出了一个有效的两阶段流程来为3D模型生成动画:首先从生成的多视图视频中直接重建运动,然后通过引入的4D-SDS来细化外观和运动。

CharacterGen
CharacterGen是一个高效的3D角色生成框架,能够从单张输入图片生成具有高质量和一致外观的3D姿势统一的角色网格。它通过流线化的生成管道和图像条件多视图扩散模型,有效校准输入姿势到规范形式,同时保留输入图像的关键属性,解决了多样化姿势带来的挑战。它还采用了基于变换器的通用稀疏视图重建模型,以及纹理反投影策略,生成高质量的纹理图。

EgoGaussian
EgoGaussian是一项先进的3D场景重建与动态物体追踪技术,它能够仅通过RGB第一人称视角输入,同时重建3D场景并动态追踪物体的运动。这项技术利用高斯散射的独特离散特性,从背景中分割出动态交互,并通过片段级别的在线学习流程,利用人类活动的动态特性,以时间顺序重建场景的演变并追踪刚体物体的运动。EgoGaussian在野外视频的挑战中超越了先前的NeRF和动态高斯方法,并且在重建模型的质量上也表现出色。

GaussianCube
GaussianCube是一种创新的3D辐射表示方法,它通过结构化和显式的表示方式,极大地促进了三维生成建模的发展。该技术通过使用一种新颖的密度约束高斯拟合算法和最优传输方法,将高斯函数重新排列到预定义的体素网格中,从而实现了高精度的拟合。与传统的隐式特征解码器或空间无结构的辐射表示相比,GaussianCube具有更少的参数和更高的质量,使得3D生成建模变得更加容易。