
产品详情
Enhance Speech from Adobe是一款免费的AI音频过滤器,可以将口语音频处理得像在声音隔音工作室中录制的一样。它可以自动清除背景噪音,调整音量平衡,提升音频质量。用户可以将录音文件上传到该平台,通过AI算法进行音频优化处理。Enhance Speech from Adobe适用于广播、播客、音频制作等领域。该产品完全免费使用。
主要功能
适用人群
广播、播客、音频制作
快速访问
访问官网 →所属分类
相关推荐
发现更多类似的优质AI工具

Draw an Audio
Draw an Audio是一个创新的视频到音频合成技术,它通过多指令控制,能够根据视频内容生成高质量的同步音频。这项技术不仅提升了音频生成的可控性和灵活性,还能够在多阶段产生混合音频,展现出更广泛的实际应用潜力。

Udio v1.5
Udio v1.5是一个音乐创作平台的高级版本,它在v1的基础上进行了多项改进,包括提高音质、提供音调控制、改善全球语言支持等。它生成48kHz立体声轨道,提供更清晰的音质和更好的乐器分离度。此外,Udio v1.5还提供了一系列新功能,如专用创作页面、音轨下载、音频转音频混音、可分享的歌词视频等,旨在进一步赋能音乐创作者。

ElevenLabs 文本转音效API
ElevenLabs的文本转音效API允许用户根据简短的文本描述生成高质量的音效,这些音效可以应用于游戏开发、音乐制作应用等多种场景。该API利用先进的音频合成技术,能够根据文本提示动态生成音效,为用户提供了一种创新的声音设计工具。

ComfyUI-StableAudioSampler
ComfyUI-StableAudioSampler 是一款集成在 ComfyUI 节点中的音频采样器插件,它允许用户生成音频并输出原始字节和采样率,支持所有原始 Stable Audio Open 参数,并可以保存音频到文件。这个插件是开源的,并且正在积极开发中,旨在为音乐制作者提供一个易于使用且功能强大的工具。

ElevenLabs Text to Sound Effects
Text to Sound Effects是ElevenLabs开发的最新AI音频模型,能够根据文本提示生成各种音效、短音乐曲目、音景和角色声音。它代表了音频制作领域的重大创新,为电影电视工作室、视频游戏开发者和社交媒体内容创作者提供了快速、经济、大规模生成丰富沉浸式音景的工具。该产品通过与Shutterstock的合作,利用其丰富的音频库中的授权曲目,经过精细调整,为现代创作者创造了一个多功能的新工具。

Amped Studio
Amped Studio是一个在线音乐制作平台,提供创建音乐、节拍制作、音频编辑、声音录制和工程等功能。在这里可以找到一切创作音乐所需的工具!

天工SkyMusic
基于昆仑万维「天工3.0」超级大模型打造的AI音乐生成大模型「天工SkyMusic」,支持高质量AI音乐生成、人声合成、歌词段落控制、多种音乐风格和音乐智能表达等功能。目前开放免费邀测,助力用户更好地创作音乐,表达情感。

Adobe Project Music GenAI Control
Adobe Research开发的Project Music GenAI Control是一个实验性的AI音乐生成和编辑工具,它允许创作者通过文本提示生成音乐,并提供精细的编辑控制,以满足特定需求。

MusicFX
MusicFX是一个让用户创造音乐的在线平台。它提供丰富的音效库和创作工具,用户可以选择不同的音效素材,通过拖拽、组合等简单操作,即可创作出属于自己的原创音乐。该平台适合各个年龄段的音乐爱好者,不需要专业的音乐知识,也可以在线创作,体验音乐创作的乐趣。
FreGrad
FreGrad是一款轻量快速的频率感知扩散声码器,旨在生成逼真的音频。其框架包括离散小波变换、频率感知扩张卷积和一系列增强模型生成质量的技巧。在实验中,FreGrad相比基准模型,训练速度提升3.7倍,推理速度提升2.2倍,同时模型大小减少0.6倍(仅178万参数),而不牺牲输出质量。

Ultimate Vocal Remover GUI
终极人声去除GUI是一款使用深度神经网络技术的人声去除工具。其核心开发者训练了所有提供的模型,除了Demucs v3和v4 4声道模型。该应用使用先进的源分离模型从音频文件中去除人声。无需额外的先决条件即可有效运行。适用于Windows 10及以上版本。
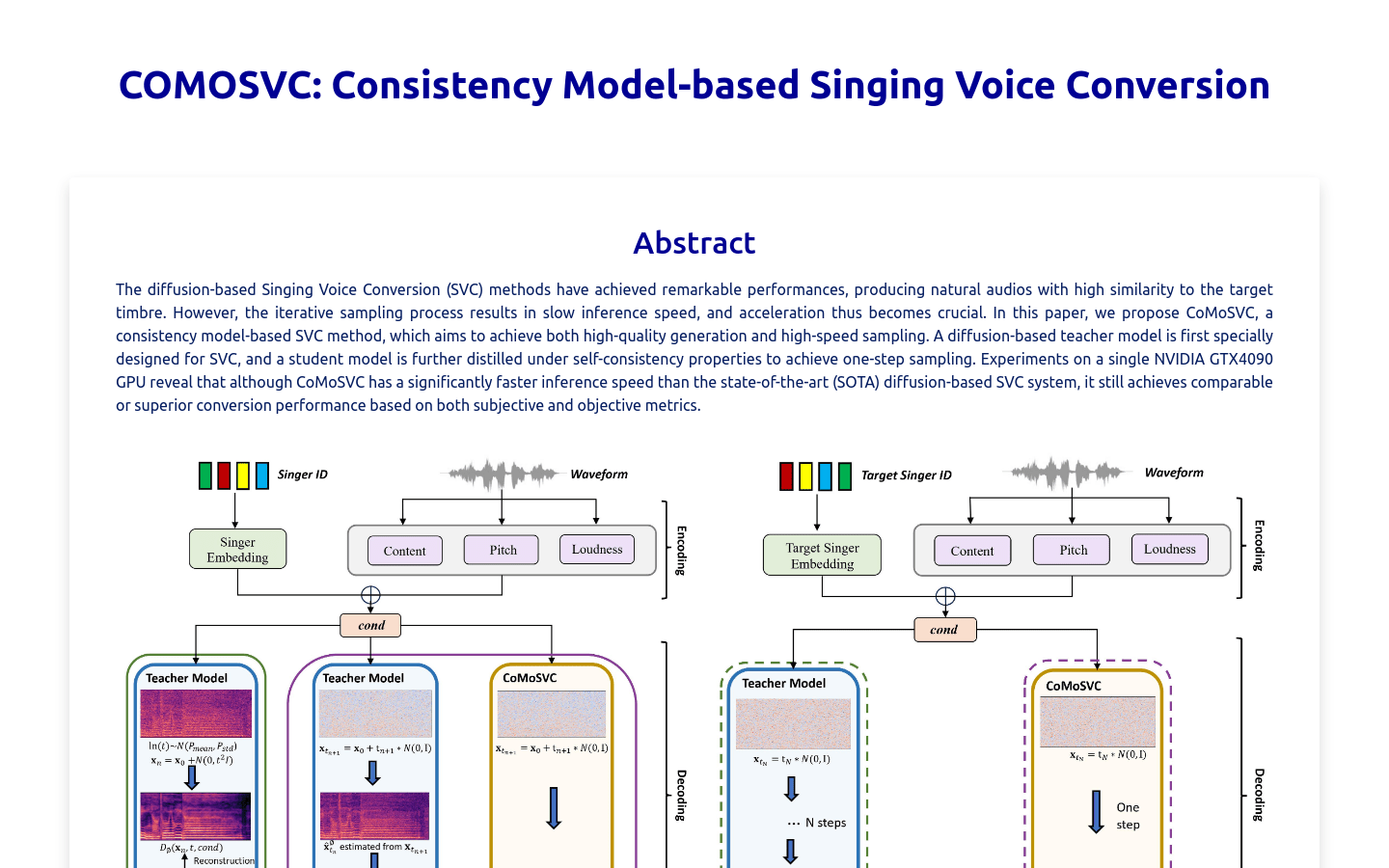
COMOSVC
COMOSVC是一种基于一致性模型的歌唱音高转换技术,它可以实现高质量的转换效果和快速的采样速度。该技术首先设计了一个基于弥散的教师模型,用于歌唱音高转换任务,然后通过自我一致性属性进行知识蒸馏,以实现一步采样。相比当前最先进的基于弥散的歌唱音高转换系统,COMOSVC在保持可比甚至优越的转换性能的同时,也实现了显著更快的推理速度。

music-fx
音乐 FX 是一个在线音乐制作工具,提供丰富的音效和声音素材,用户可以使用它来创作各种类型的音乐。它支持调整音调、节奏和音量,还可以添加混响、回声等音效效果。无论是想要营造舒缓的氛围还是冒险的氛围,音乐 FX 都能满足用户的需求。

Blerp Sound Memes. AI TTS Voices Emotes GIFS
Blerp是一个AI TTS声音模因、表情GIF和声音提示的产品。它提供了最有趣的AI TTS警报、表情和声音包,适用于聊天和直播社区。观众可以在任何流媒体平台上播放最好的声音和AI TTS语音,并可以将表情和GIF附加到它们上。作为观众,您还可以在您最喜欢的主播流媒体上收集频道积分,以及播放属于您自己的WalkOn Sounds。主播可以设置自己的声音,并在任何支持的扩展平台上使用WalkOn Subscriber声音。
Polymath
Polymath利用机器学习将任何音乐库(例如来自硬盘或YouTube)转换为音乐制作样本库。该工具能自动将歌曲分割成节拍、贝斯等音轨部分,将它们量化到相同的速度和节拍格(例如120bpm),分析音乐结构(例如副歌、合唱等),关键(例如C4、E3等)和其他信息(音色、响度等),并将音频转换为MIDI。结果是一个可搜索的样本库,能简化音乐制作人、DJ和ML音频开发者的工作流程。

MusicGen Remixer
MusicGen Remixer是一个基于 MusicGen Chord 的音乐重置模型。它可以接收音频文件作为输入,并使用 MusicGen Chord 生成器将其重置为其他风格的音乐。该模型支持多频带扩散、节奏同步、和弦色度等功能,可以通过调整参数来控制生成的音乐风格和多样性。